
【新機能】DatabricksのLakeflow Designerがパブリックプレビューとなったので試してみた
かわばたです。
2026年4月22日にLakeflow Designerがパブリックプレビューとなりました。
LakeFlow Designerは、コードを書かずにビジュアルキャンバス上でデータパイプラインを構築できるツールです。
本記事では、CSVファイルの取り込みから変換(フィルタ、結合、集計等)、Unity Catalog への出力、スケジュール設定まで、基本操作を一通り検証します。
【公式ドキュメント】
概要
背景
データ分析の現場では、以下のようなニーズが増えています。
- SQL や Python を書かずにデータの加工・準備を行いたい
- ETL/ELT パイプラインのプロトタイピングを素早く行いたい
- ビジュアルな操作でデータフローを直感的に把握したい
LakeFlow Designer を使えば、これらを Databricks のビジュアルキャンバス上 でドラッグ&ドロップ操作により実現できます。
LakeFlow Designer の基本概念
LakeFlow Designer は、演算子(オペレーター) をキャンバス上に配置し、接続することでデータパイプラインを構築します。データは DAG(有向非巡回グラフ)として 左から右 へ流れます。
主な特徴は以下の通りです。
| 特徴 | 内容 |
|---|---|
| ビジュアルキャンバス | ドラッグ&ドロップで演算子を配置・接続 |
| 演算子ベース | フィルタ、結合、集計など各種演算子を連結してワークフローを構築 |
| Genie Code 統合 | 自然言語プロンプトから変換コードを自動生成 |
| プレビュー機能 | 各ステップの結果を最大 1,000 行のサンプルデータで即座に確認可能 |
| データプロファイリング | 出力データの統計情報やグラフを表示 |
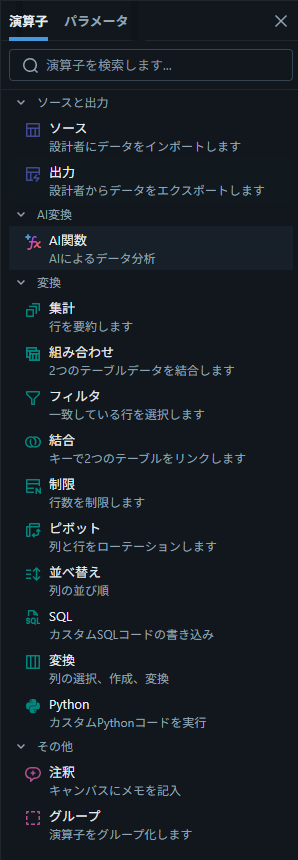
組み込みオペレーター一覧
LakeFlow Designer には、以下の組み込みオペレーターが用意されています。
| カテゴリ | オペレーター | 概要 |
|---|---|---|
| ソースと出力 | ソース | Unity Catalog テーブルやファイルからデータを取り込み |
| ソースと出力 | 出力 | Unity Catalog テーブルへの書き込み |
| 変換 | フィルター | 条件指定で行を選別 |
| 変換 | 結合(Join) | 内部結合、左結合、右結合、完全結合に対応 |
| 変換 | 集計 | GROUP BY + 集計関数(AVG, COUNT, MAX, SUM 等) |
| 変換 | 組み合わせ | Union, Intersect, Except による複数テーブルのマージ |
| 変換 | ピボット | 行→列(ピボット)/ 列→行(アンピボット)の変形 |
| 変換 | ソート | 1つ以上の列で ASC/DESC 順序指定 |
| 変換 | 制限 | 処理対象の最大行数を指定 |
| 変換 | 変換(Transform) | 列の選択・作成・変換。自然言語でのカスタム列定義も可能 |
| 変換 | SQL | カスタム SQL コードによる変換 |
| 変換 | Python | カスタム PySpark 処理 |
| AI | ai_analyze_sentiment 等 | 感情分析、分類、抽出、要約、翻訳など 9 種類の AI 機能 |
| 組織 | 注記 | Markdown 対応のメモをキャンバスに追加 |
| 組織 | グループ | 演算子を視覚的にグルーピング |
前提条件
LakeFlow Designer を使用するには、以下の条件を満たす必要があります。
- Unity Catalog 対応の Databricks ワークスペース
- コンピュートリソース(サーバレスまたは汎用クラスター)への
CAN USE権限 - Databricks AI 支援機能の有効化
使用するデータ
今回はdbtのサンプルデータjaffle-shopを活用しています。
LakeFlow Designer の基本操作検証
以降の検証では、1本のパイプラインを段階的に構築していきます。CSV の取り込みからフィルタ、結合、集計、変換、SQL、出力、スケジュール設定までを一連の流れで検証します。
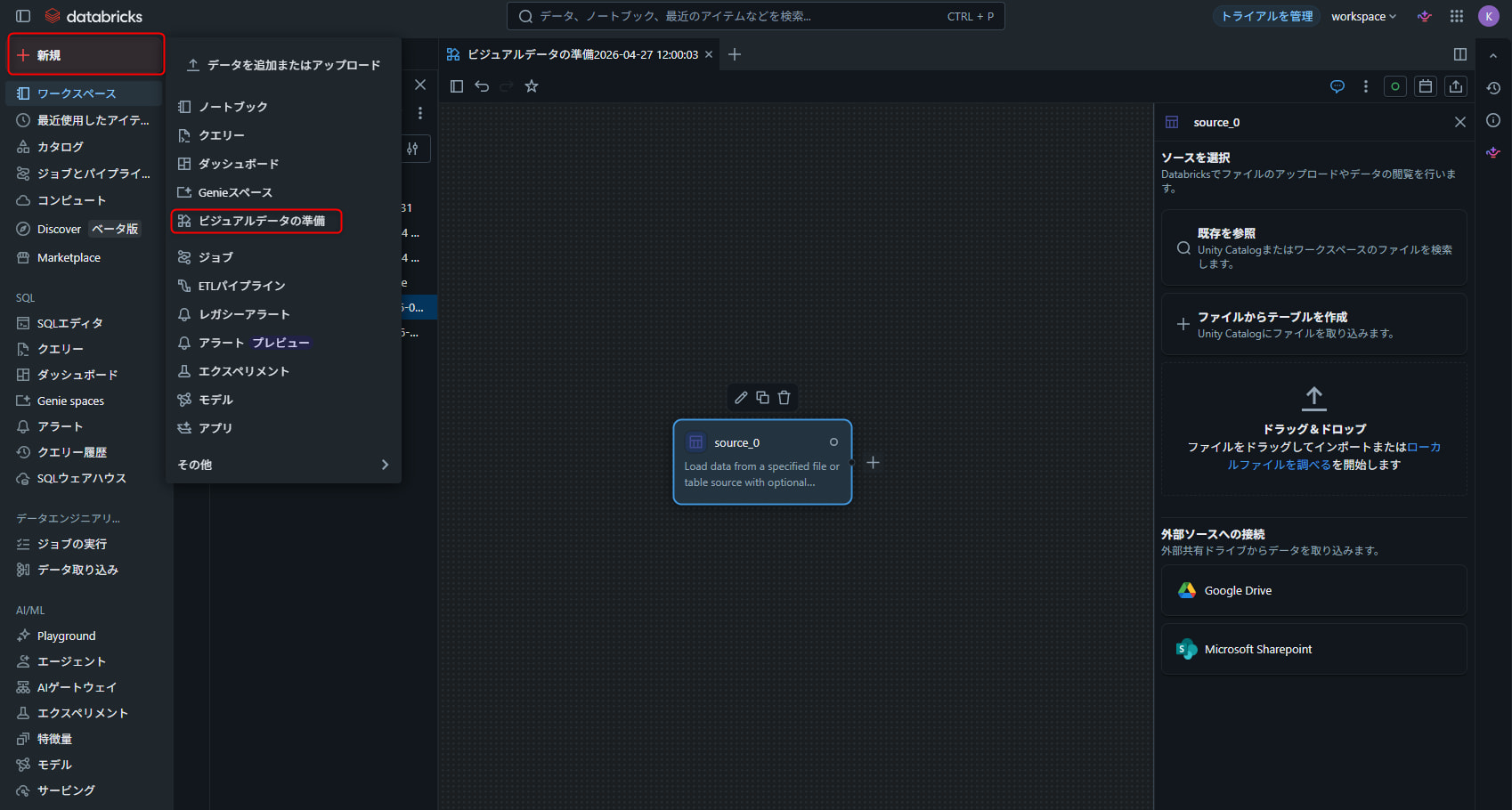
プロジェクトの作成
サイドバーの「新規」から「ビジュアルデータ準備」を選択してプロジェクトを作成します。
- Databricks ワークスペースのサイドバーで 「新規」 をクリック
- 「ビジュアルデータ準備」 を選択
- ウェルカム画面が表示され、空のキャンバスが開く
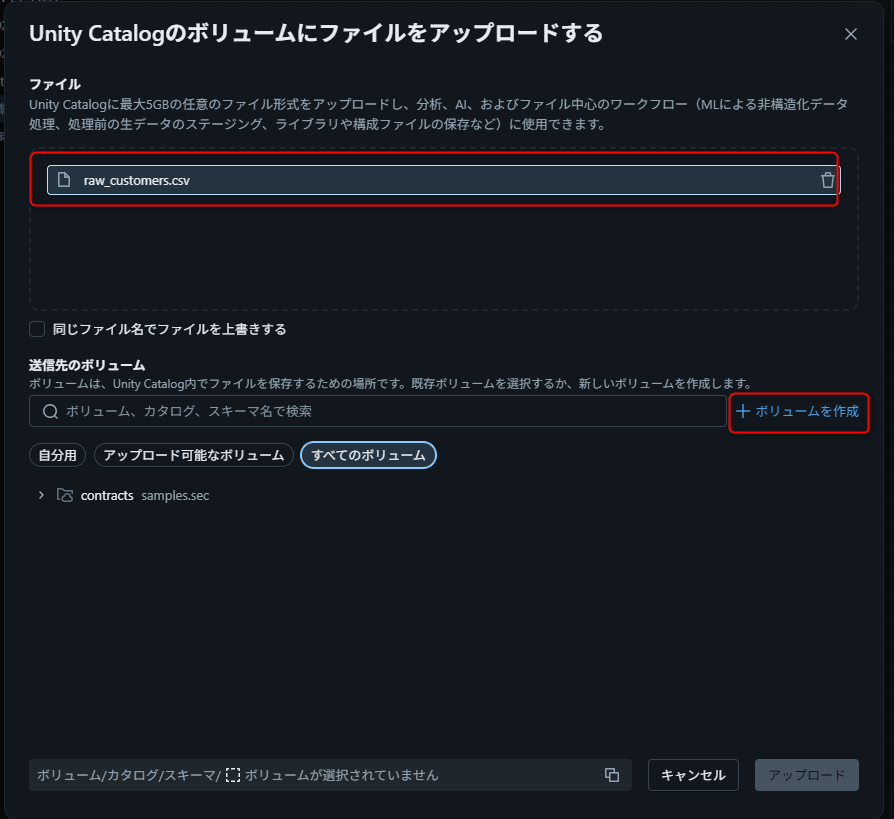
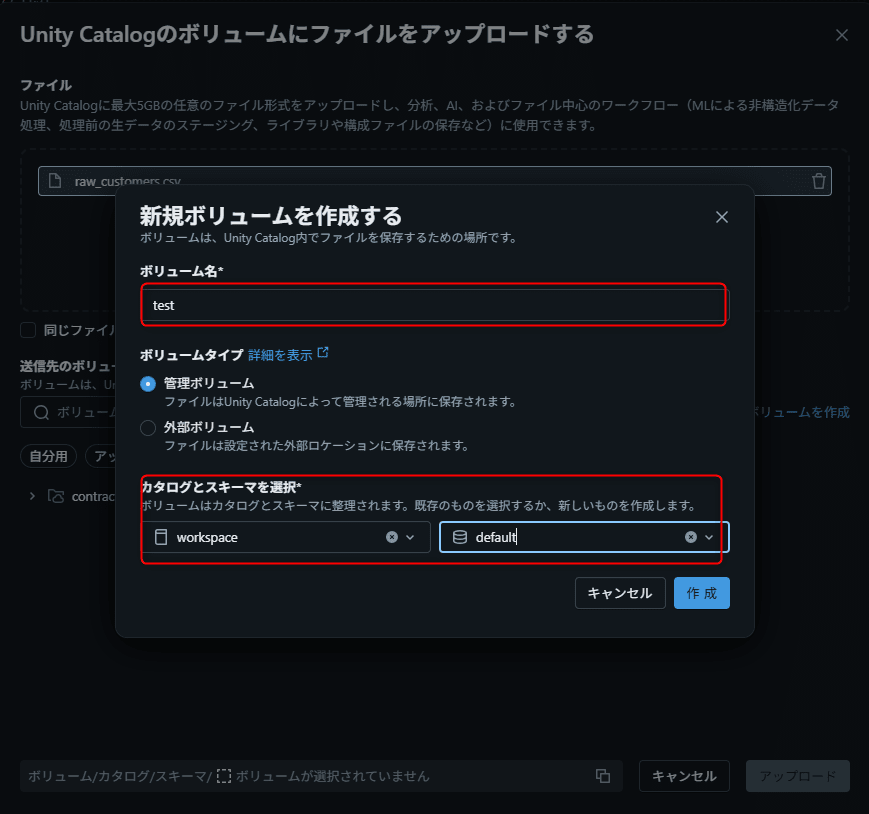
データ取り込み(CSV アップロード)
ローカルの CSV ファイルをキャンバスにドラッグ&ドロップしてデータを取り込みます。
- ローカルの
raw_customers.csv、raw_orders.csvをキャンバス上にドラッグ&ドロップ - LakeFlow Designer が自動的にワークスペースファイルシステムにアップロード
- ソース演算子 が自動作成される
- 演算子を選択すると、画面下部の出力ペインにプレビューが表示される
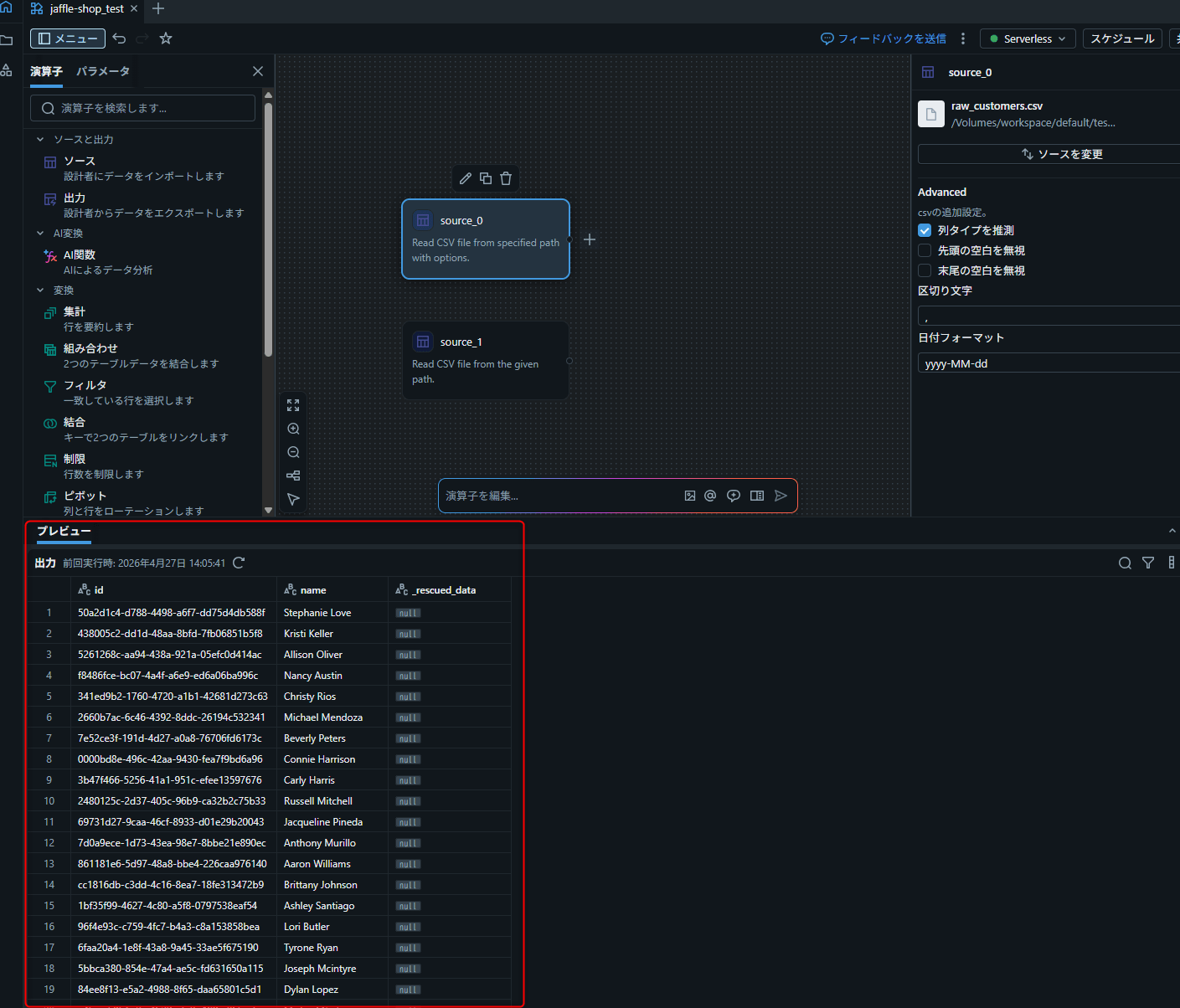
補足: CSV以外にも、Unity Catalog の既存テーブル、Google Drive、SharePoint からのインポートにも対応しています(Google Drive / SharePoint からのインポートには、対象サービスへアクセス可能な Unity Catalog 接続が必要です)。Salesforce や Workday などの外部ソースについては、LakeFlow Connect を利用します。
なお、大量データを扱う場合は、ドラッグ&ドロップではなく 「ファイルからテーブルを作成」 を選択し、Unity Catalog のマネージドテーブルとして取り込む方法が推奨されています。この方法のほうがパフォーマンスが高くなります。
フィルター演算子
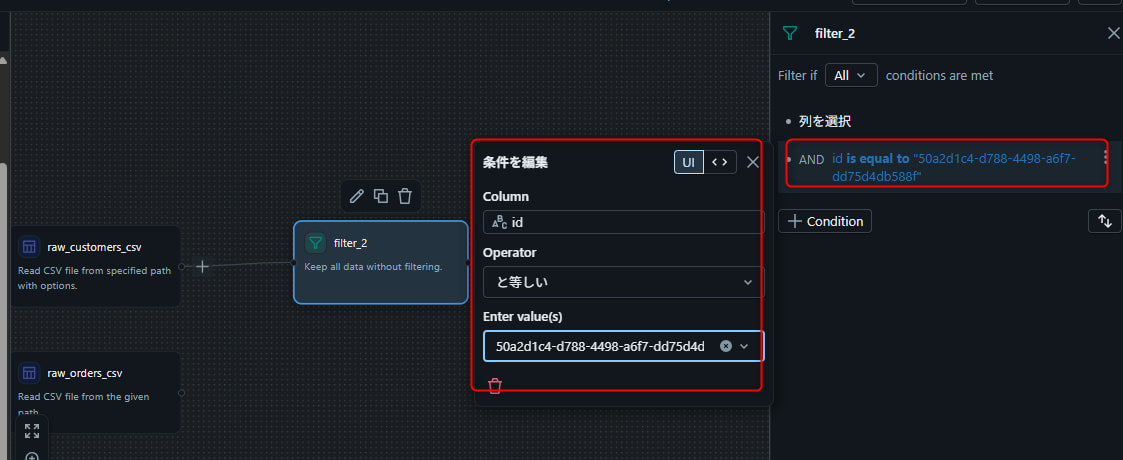
取り込んだ顧客データに対して、顧客 ID によるフィルタリングを行います。
raw_customers.csvのソース演算子の出力ハンドル(右端の円)をドラッグ- 左サイドパネルから 「フィルター」 演算子を選択してキャンバスに配置し、接続
- フィルター演算子をダブルクリックして設定ペインを開く
- 条件ビルダーで以下を設定:
- 列:
ID - 条件: と等しい
- 値:
50a2d1c4-d788-4498-a6f7-dd75d4db588f
- 列:
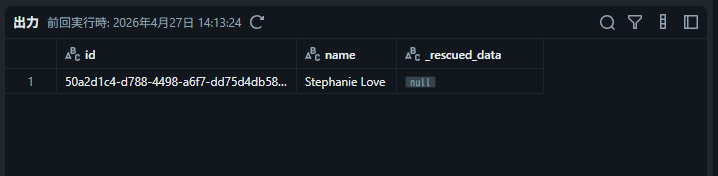
プレビュー
補足: 条件ビルダーでは「等しい」「含む」「始まる」「終わる」「大小比較」など 7 種類の条件タイプが使用できます。複数条件を AND/OR で組み合わせることも可能です。
結合(Join)演算子
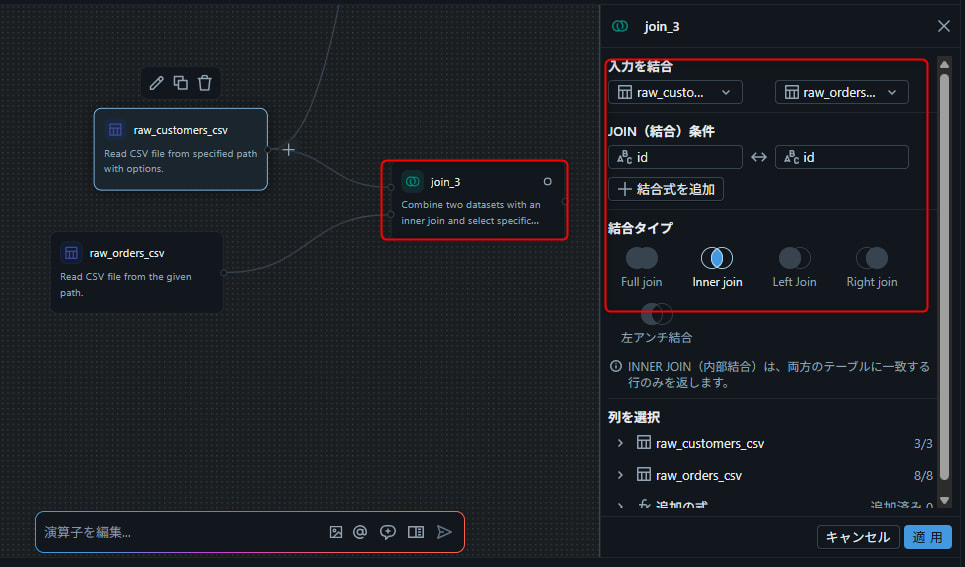
raw_customers.csv、raw_orders.csvを結合します。
- 左サイドパネルから 「結合(Join)」 演算子をキャンバスに配置
- フィルター演算子の出力 と
raw_orders.csvソースの出力ハンドルを、それぞれ Join 演算子の入力に接続 - Join 演算子をダブルクリックして設定:
- 結合タイプ: 内部結合(Inner Join)
- 結合条件:
raw_customers.id = raw_orders.customers
プレビュー
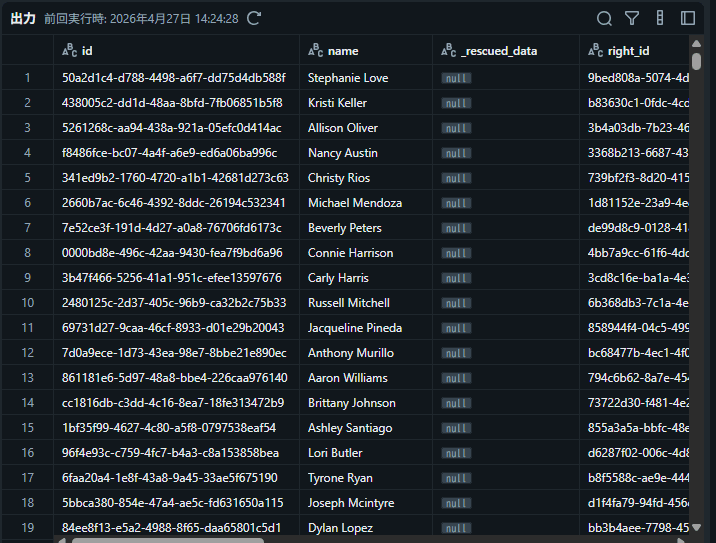
補足: 内部結合の他に、左結合、右結合、完全結合にも対応しています。
集計演算子
結合したデータに対して、顧客ごとの注文金額合計を集計します。
- Join 演算子の出力から 「集計」 演算子に接続
- 集計演算子をダブルクリックして設定:
- グループ化列:
customer - 集計関数:
SUM(order_total)→ 列名total_amount - 集計関数:
COUNT(raw_orders.id)→ 列名order_count
- グループ化列:
プレビュー
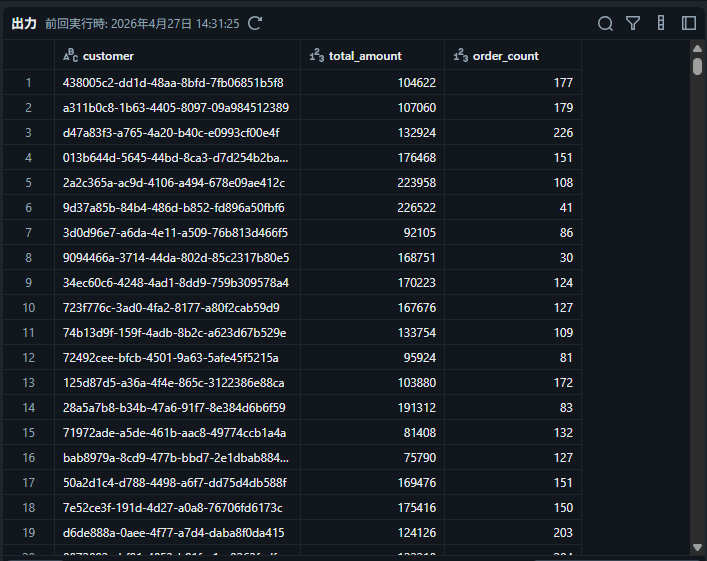
補足: 集計関数は AVG、COUNT、MAX、MEAN、MEDIAN、MIN、PERCENTILE、STDDEV、SUM、VARIANCE に対応しています。
変換(Transform)演算子
列の選択やカスタム列の追加を行います。
- 集計演算子の出力から 「変換(Transform)」 演算子に接続
- 変換演算子をダブルクリックして設定:
- 必要な列だけを残し、カスタム列 avg_order_value = total_amount / order_count を追加
Genie Code による自然言語変換
変換演算子では、Genie Code を使って自然言語プロンプトからカスタム列を自動生成することもできます。
例: 「order_totalの合計が5000以上の顧客を'高額顧客'、それ以外を'一般顧客'としてラベル付けしてください」
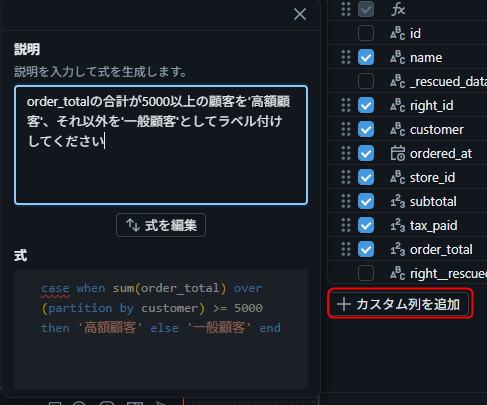
プレビュー
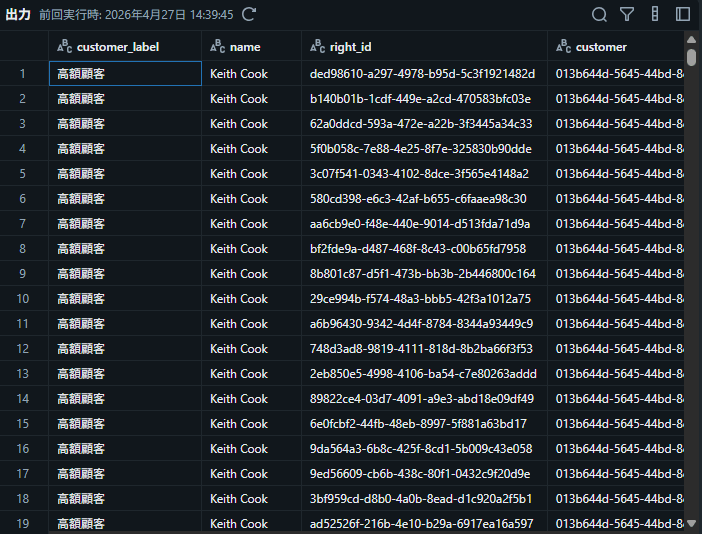
結果: GUI での列操作に加え、自然言語プロンプトからカスタム列の定義コードが自動生成された。
SQL 演算子
組み込みオペレーターでカバーされない変換には、カスタム SQL を使用できます。
- 左サイドパネルから 「SQL」 演算子をキャンバスに配置
- 上流の演算子と接続
- SQL 演算子をダブルクリックしてエディタを開く
- 上流の演算子名をテーブル名として参照し、SQL を記述
SELECT *
FROM aggregate_4
WHERE order_count >= 100
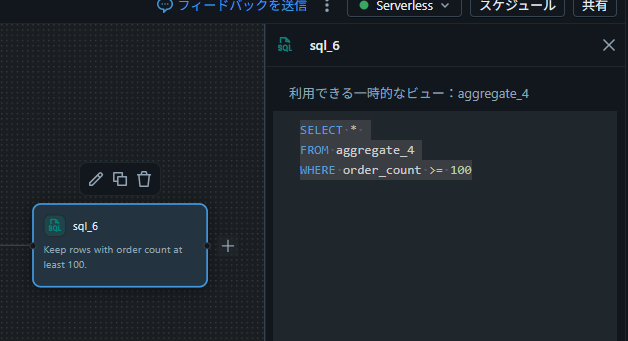
補足: SQL の他に Python 演算子 も用意されており、カスタム PySpark 処理を記述できます。上流の入力は
inputs["data"]のリストとして Spark DataFrame で渡され、最終結果となる単一の DataFrame をresultに代入します。
出力(Unity Catalog への書き込み)
変換結果を Unity Catalog のテーブルに書き込みます。
- 最終段の演算子の出力から 「出力」 演算子に接続
- 出力演算子をダブルクリックして設定:
- テーブル名:
customer_order_summary - カタログ: workspace
- スキーマ: default
- テーブル名:
- 画面上部の 「実行」 ボタンをクリック
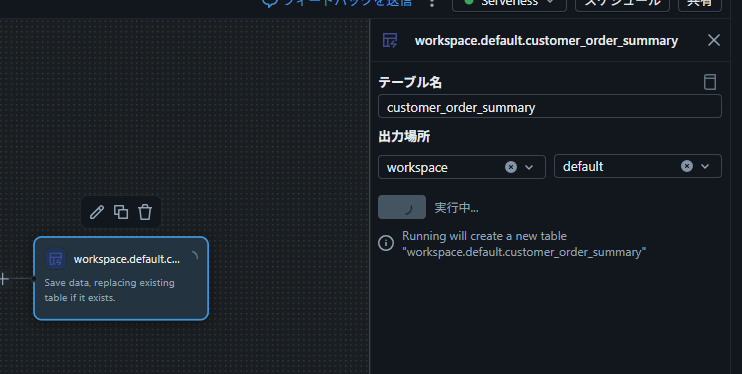
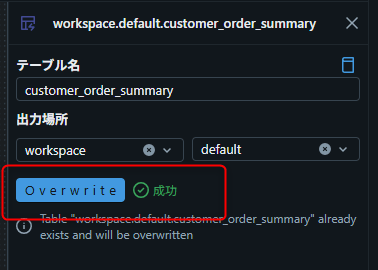
結果: 変換結果が Unity Catalog テーブルとして書き込まれた。
スケジュール設定
作成したパイプラインを定期的に自動実行するスケジュールを設定します。
- 画面上部の 「スケジュール」 ボタンをクリック
- 実行頻度やタイミングを設定
- スケジュールを保存
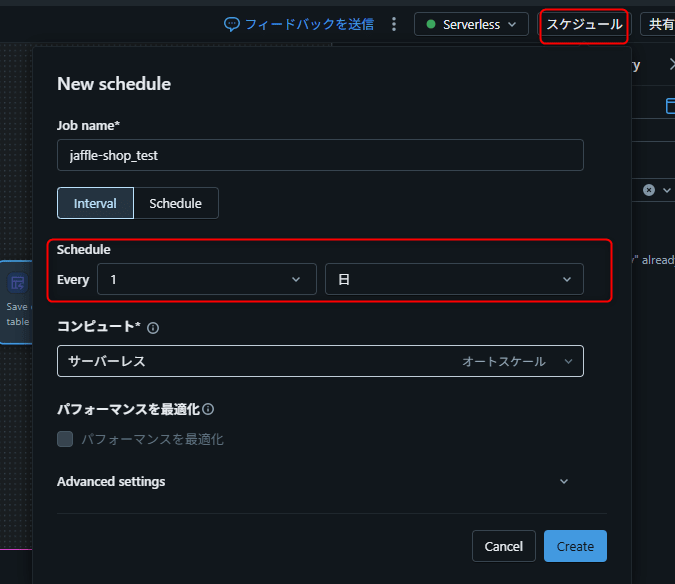
結果: ビジュアルデータ準備のパイプラインを Databricks ジョブとしてスケジュール実行できることを確認した。
補足: 「スケジュール」ボタンからの直接設定の他に、Databricks ジョブのタスクとして組み込むことも可能です。既存のジョブパイプラインの一部として利用する場合はこちらが適しています。
所感・注意点
| 項目 | 内容 |
|---|---|
| パブリックプレビュー | 2026 年 4 月時点でパブリックプレビュー段階。本番適用は十分な検証のうえで判断を推奨 |
| プレビューの行数制限 | デフォルトは 1,000 行サンプル。完全データセット実行も可能だが処理時間が増加する |
| Genie Code | 自然言語からの変換コード自動生成は便利だが、複雑な要件では手動調整が必要な場合がある |
| ノーコード + ローコード | GUI 操作だけで完結できる一方、SQL / Python 演算子でコードも書けるため、幅広いスキルレベルに対応 |
| キャンバス操作 | Cmd/Ctrl+Z で元に戻す、Cmd/Ctrl+C→V で演算子の複製、DAG アイコンで自動レイアウトなど、便利なショートカットが用意されている |
まとめ
| 検証項目 | 結果 |
|---|---|
| プロジェクト作成 | サイドバーから「ビジュアルデータ準備」で数クリックで作成 |
| CSV インポート | ドラッグ&ドロップで即座に取り込み、ソース演算子が自動作成 |
| フィルター | 条件ビルダーで直感的に条件設定。7 種類の条件タイプ対応 |
| 結合(Join) | GUI で結合条件・タイプを指定。内部/左/右/完全結合に対応 |
| 集計 | GROUP BY + 集計関数を GUI で設定。AVG, COUNT, SUM 等に対応 |
| 変換(Transform) | 列操作やカスタム列を GUI / 自然言語(Genie Code)で定義 |
| SQL | カスタム SQL で柔軟な変換が可能。上流演算子名をテーブルとして参照 |
| 出力 | Unity Catalog テーブルへの書き込みをワンクリックで実行 |
| スケジュール | Databricks ジョブとしてスケジュール実行が可能 |
LakeFlow Designer は、コードを書かずにデータパイプラインを構築できるため、SQL や Python に馴染みのないアナリストにとって強力なツールです。一方で、SQL / Python 演算子も用意されているため、必要に応じてコードによる柔軟な変換も行えます。
パブリックプレビュー段階ではありますが、データの取り込みから変換、出力、スケジュール設定まで一通りの操作が直感的に行えることを確認できました。GA 後の正式リリースに期待です。
参考
この記事が何かの参考になれば幸いです!









