
【Databricks】リファレンスアーキテクチャで整理する機能の全体像
データ事業本部のueharaです。
今回は、Databricksが公開しているレイクハウスのリファレンスアーキテクチャから、Databricksで提供される機能の全体像をご紹介したいと思います。
はじめに
Databricksは、公式ドキュメントとして『レイクハウスのリファレンスアーキテクチャ』を公開しています。
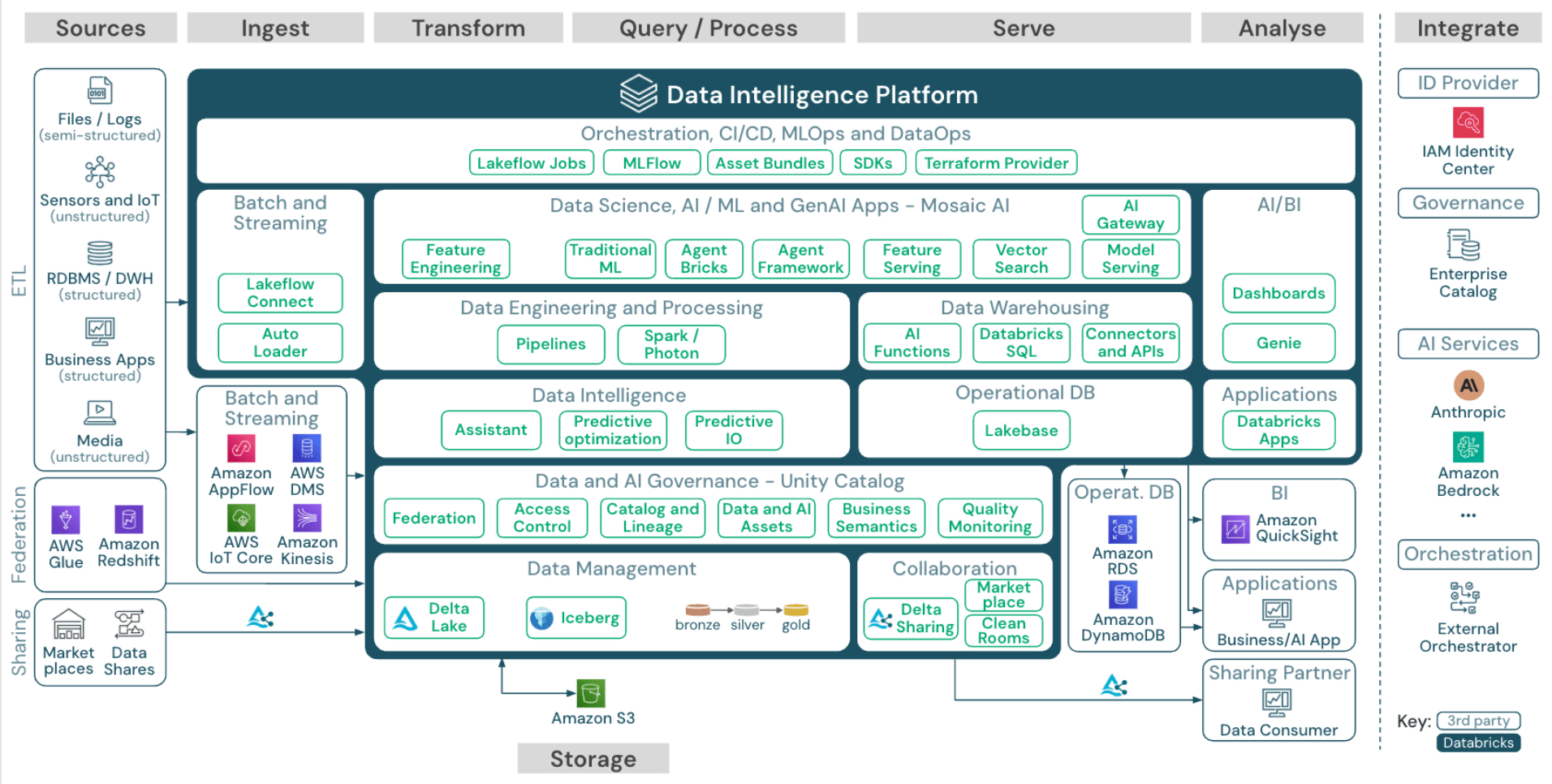
リファレンスアーキテクチャは、 Sources, Ingest, Transform, Query/Process, Serve, Analyse, Integrate, Storage によって構成されています。
上図の通り、Databricksのデータインテリジェンスプラットフォームが、それぞれの領域に対し横断的に機能を提供していることが分かります。
以下で、この図を用いながらDatabricksで提供される機能の全体像をご紹介したいと思います。
なお、弊社技術ブログ(DevelopersIO)の記事があるものについては、要所でご紹介したいと思います。
Databricksの提供機能のご紹介
Batch and Streaming
まずは「Batch and Streaming」です。
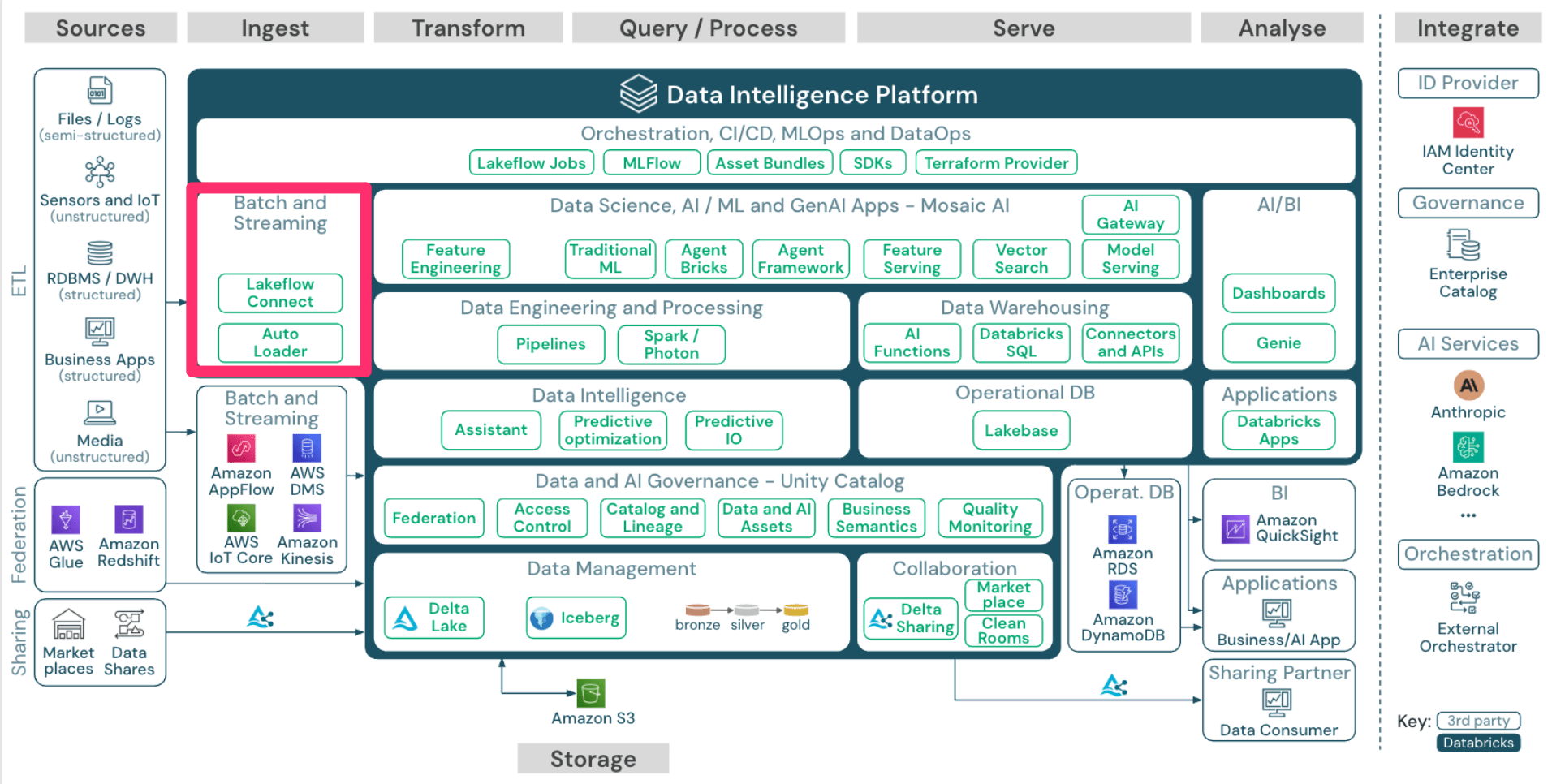
Databricksはバッチ/ストリーミングでレイクハウスにデータを取り込むことができます。
中でも Lakeflow Connect は様々なDBやSaaSアプリケーションからデータを取り込むことができる、Databricksのマネージド機能として提供されているデータ統合のためのコネクタ機能です。
使用感としては、FivetranやAirbyteなどのデータ統合プラットフォームをイメージ頂くと分かりやすいかも知れません。
以下記事で、Salesforceからデータを取り込む例をご紹介しています。
詳しくは上記ブログを確認頂ければと思いますが、設定も簡単であり、非常に便利な機能になります。
標準コネクタでKafkaのストリーミングデータを取り込んだり、「Zerobus Ingest」を用いて、OpenTelemetryで提供されるアプリのメトリクスやログデータの取り込みを行うこともできます。
次に Auto Loader です。
Auto Loaderは一言でいうとクラウドストレージに新しいデータファイルが連携されるケースにおいて、それらデータを段階的かつ効率的に処理するための仕組みです。
以下記事で、S3からデータを取り込む例をご紹介しています。
ファイルの検出方法としては
- ディレクトリ一覧表示モード(デフォルト)
- ファイル通知モード
の2種類があり、クラウドストレージに連携されたファイルに対し前者はスケジュール駆動として、後者はイベント駆動として、両方の方法でデータの取り込みができるものになっています。
Data Management
次に「Data Management」です。
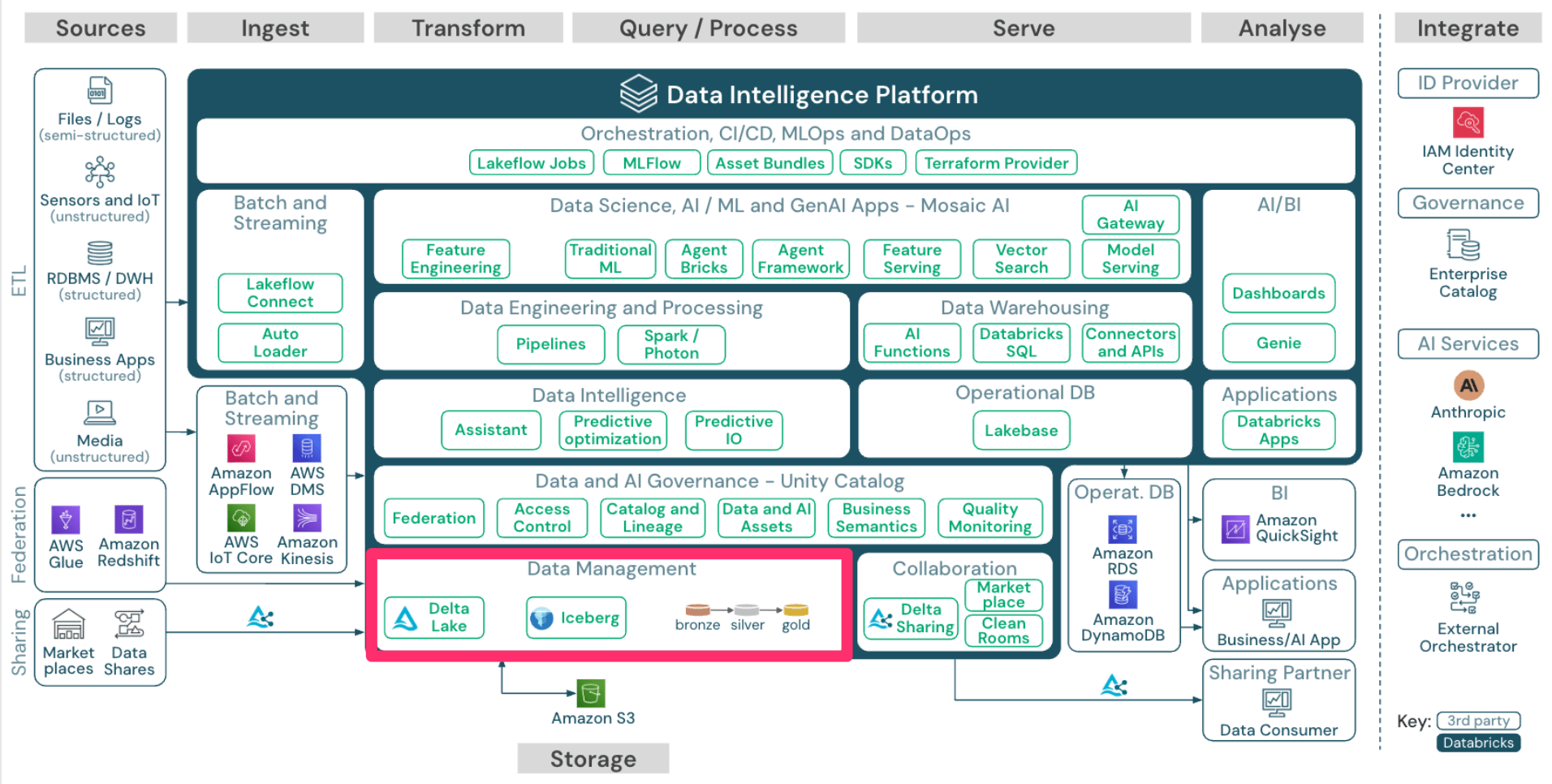
Databricksは、オープンテーブルフォーマット(OTF)として Delta Lake を採用しています。
Delta Lakeは、データレイク上でACIDトランザクションを実現し、DML操作を始め、タイムトラベルやスキーマエボリューションにも対応できるという特徴があります。
また、Delta Lake自体はOSSであり、以下ブログ記事で紹介している通り、S3に作成した外部テーブルにはDatabricksを介さずとも(Pythonなどで)直接アクセスすることができます。
※Databricksのマネージドテーブルとした場合、Unity REST APIを介す必要が出てきます。
この辺りは、「オープンソース技術を基盤とし、ベンダーロックインを排除して、データとAIを民主化する」というDatabricksの思想に沿うものになっています。
また、Databricksは Universal Format (UniForm) という機能により、 Apache Iceberg クライアントからのIceberg読み取りをサポートしています。
以下ブログ記事で、作成したDeltaテーブルにPyIcebergでアクセスした例をご紹介しています。
もちろん、Snowflakeといった他プラットフォームからもアクセスすることができます。
また補足として、DatabricksはデータをBronze(生)、Silver(クレンジング済み)、Gold(集約済み)レイヤーに整理する設計パターンである メダリオンアーキテクチャ を推奨しています。
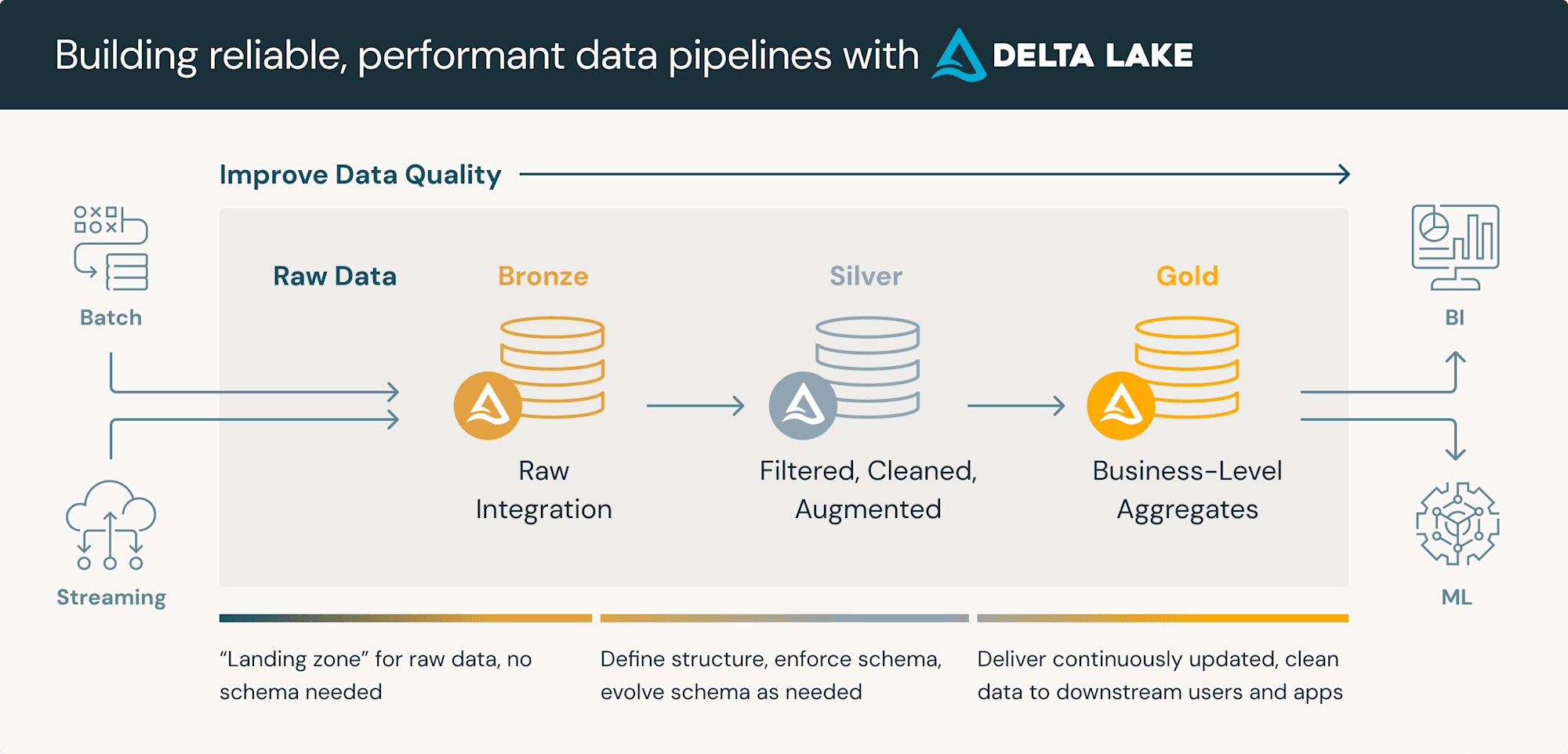
(引用元)
レイクハウスを構築する上で、データの持ち方の参考にすると良いと思います。
Collaboration
次に「Collaboration」です。
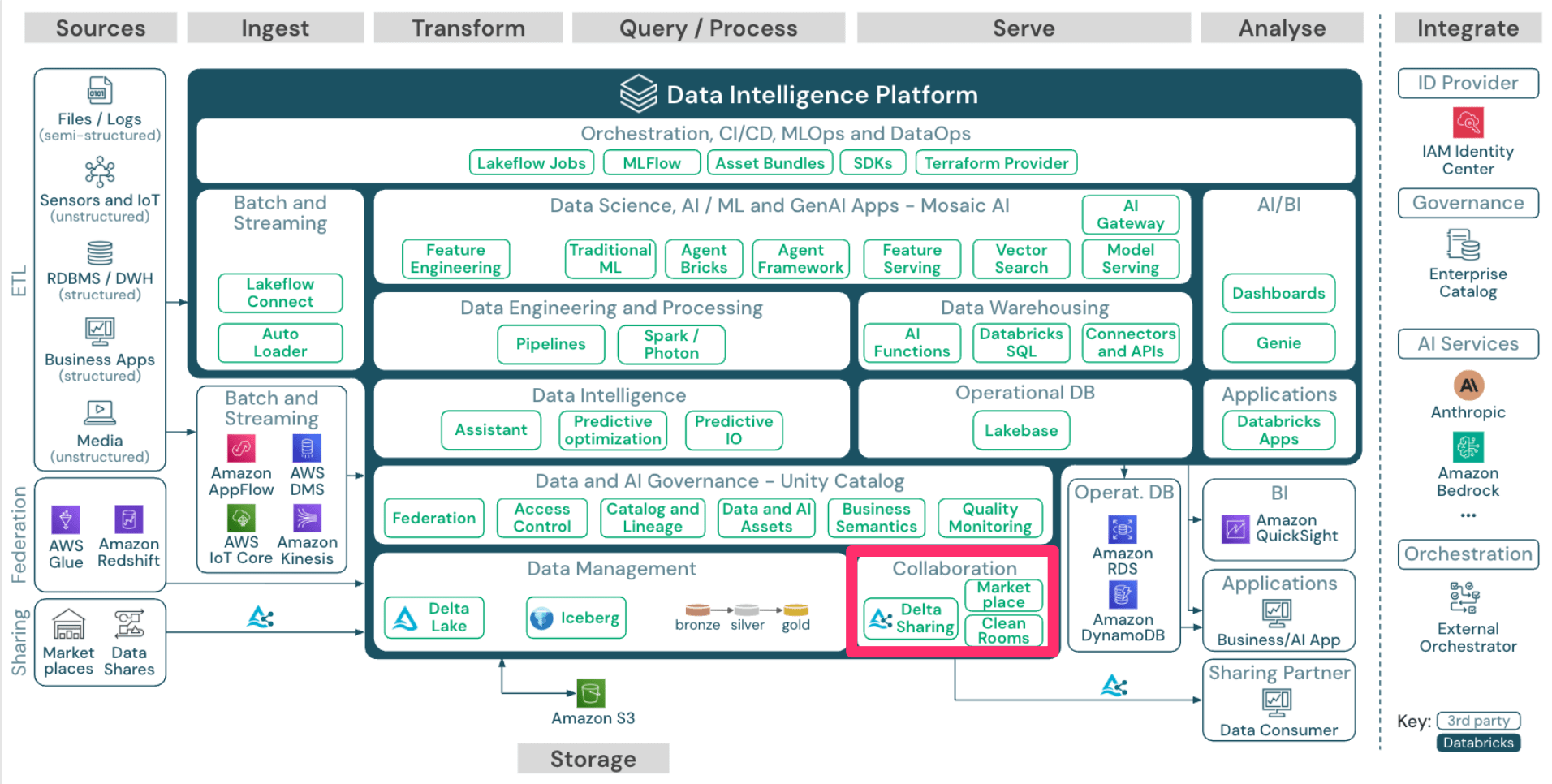
以下のブログ記事でも紹介していますが、Databricksで Delta Sharing を利用すると Databricks to Databricks や Databricks to 任意のコンピューティング でデータの共有をすることができます。
Delta Sharing自体はDelta Lakeをセキュアに共有するためのプロトコルであり、OSSであることから自前でDelta Sharingサーバーを立てることもできますが、Databricksに組み込まれているものを利用すれば特別用意する必要は無く、簡単に利用ができます。
これにより、Databricksを利用していないユーザーに対しても、Databricks上のデータを活用してもらうというコラボレーションを実現することができます。
他にも、Delta Sharingを土台にした機能として、 Clean Rooms という共同分析のための隔離実行環境を提供する機能や、 Marketplace といった分析/AIに活用できるデータのマーケットプレイスも提供されています。
Data and AI Governance
次に「Data and AI Governance」です。
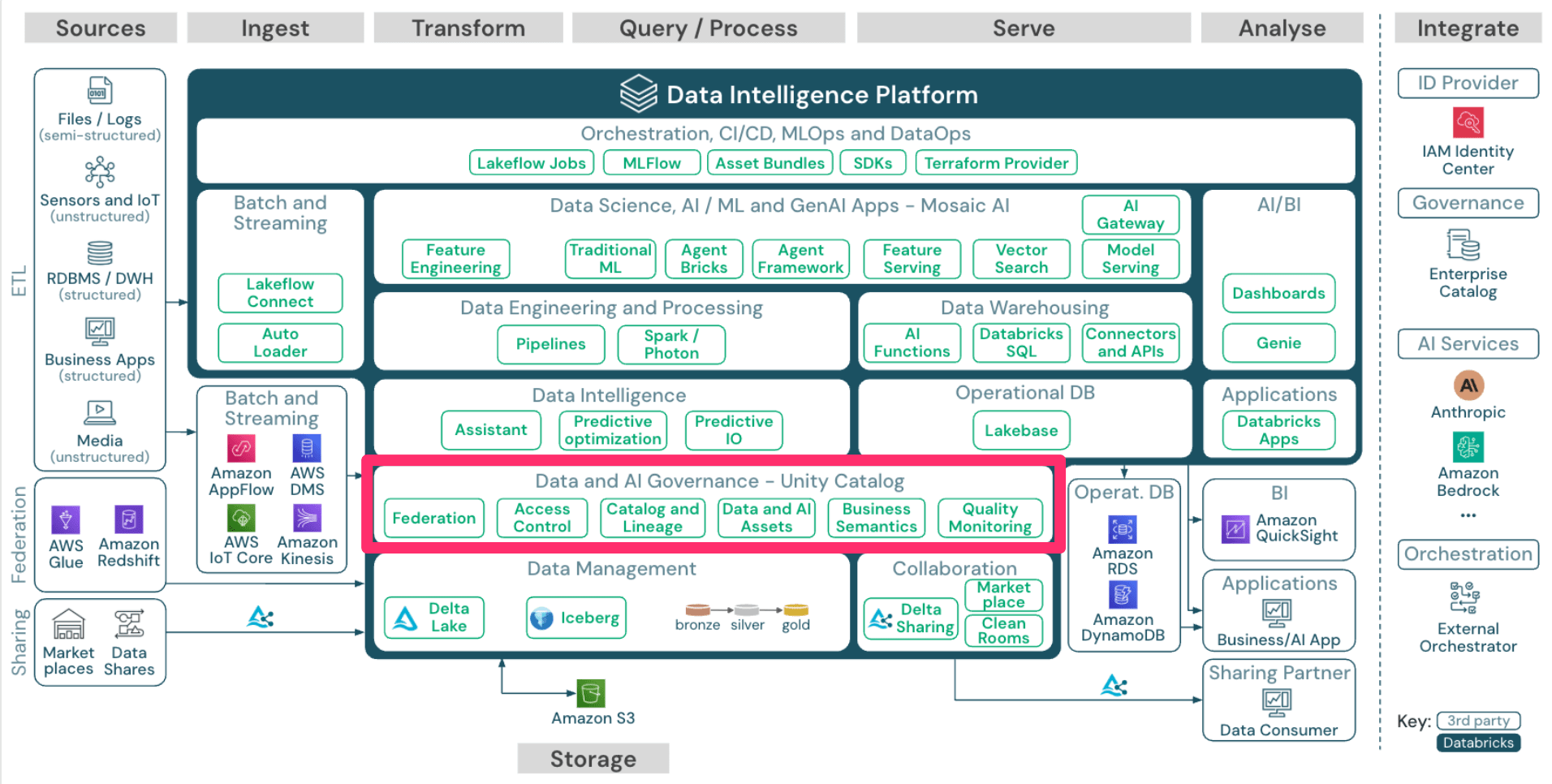
こちらはDatabricksの目玉機能の1つである Unity Catalog によって提供されている機能群になります。
Unity Catalogは、Databricksアカウントのすべてのワークスペースにおけるユーザーやデータへのアクセスを集中的に管理する機能です。
Unity Catalogのセキュリティモデルは標準的なANSI SQLをベースとしているので、馴染みのある文法で既存データレイクに存在するカタログ、データベース、テーブル、ビューのレベルでアクセス権を設定することができます。
また、従来のHive Metastoreと比較しても、きめ細かい権限制御や、データの活用性・可視性の向上、外部連携の簡略化など様々な点で優位性があります。
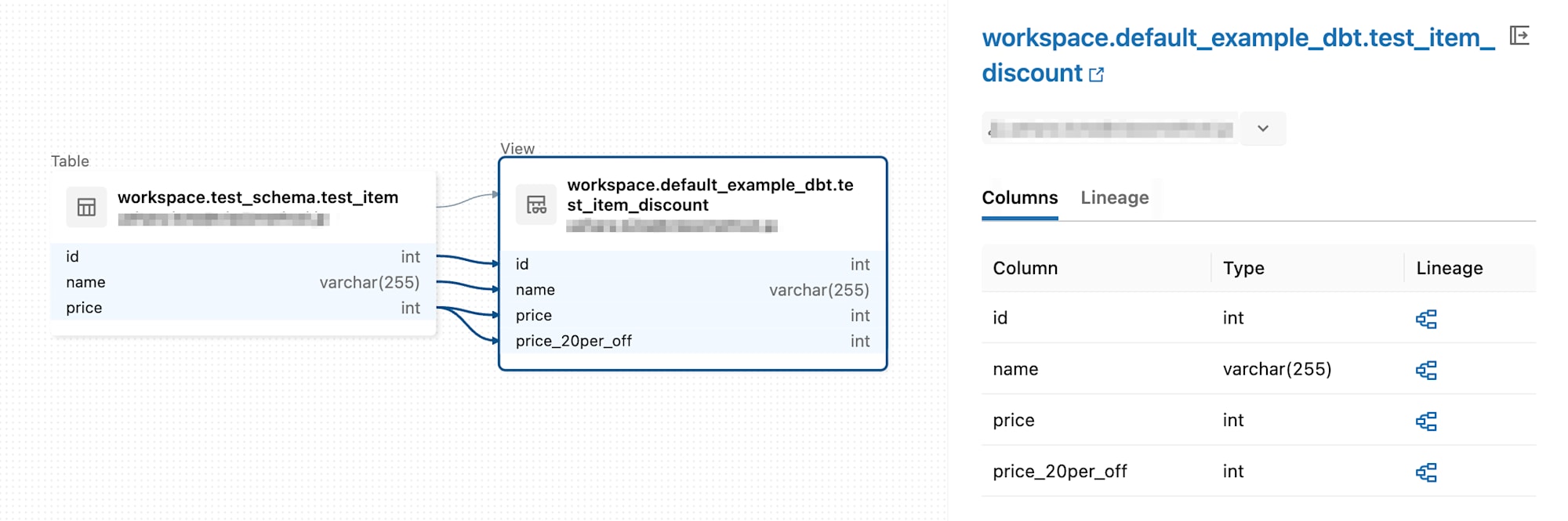
例えばデータの活用性・可視性に寄与するものとして、 Catalog and Lineage 機能があります。
それぞれのテーブルに対しビジネスメタデータやタグを付与することもできますし、

カラムレベルのデータリネージを確認することもできます。
ちなみにこのUnity CatalogもOSS化されています。(凄い)
Data Intelligence
次に「Data Intelligence」です。
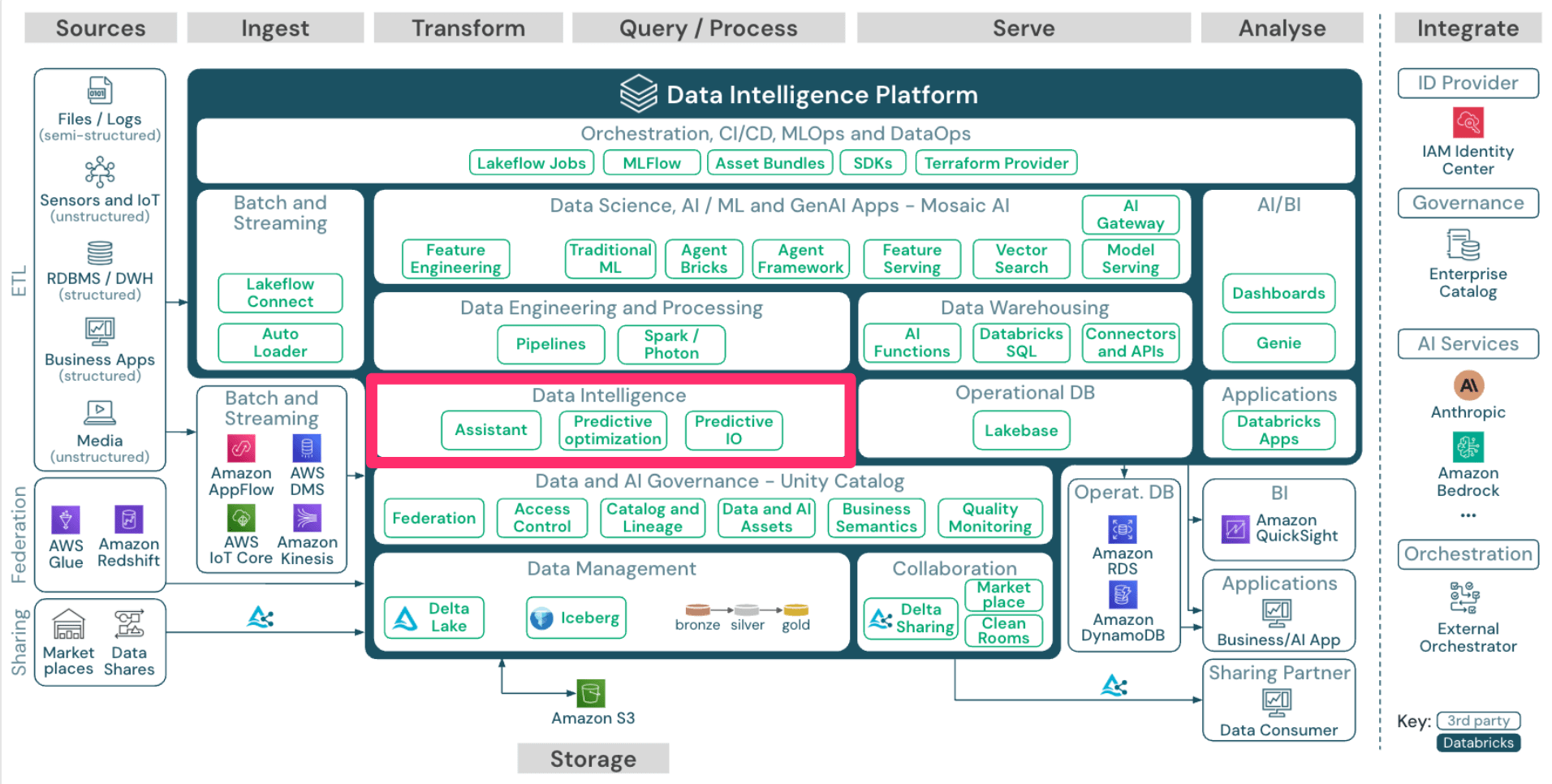
Genie Code (旧 Databricks Assistant) は、ノートブックやSQLエディタ上で動作する生成AIベースの支援機能です。
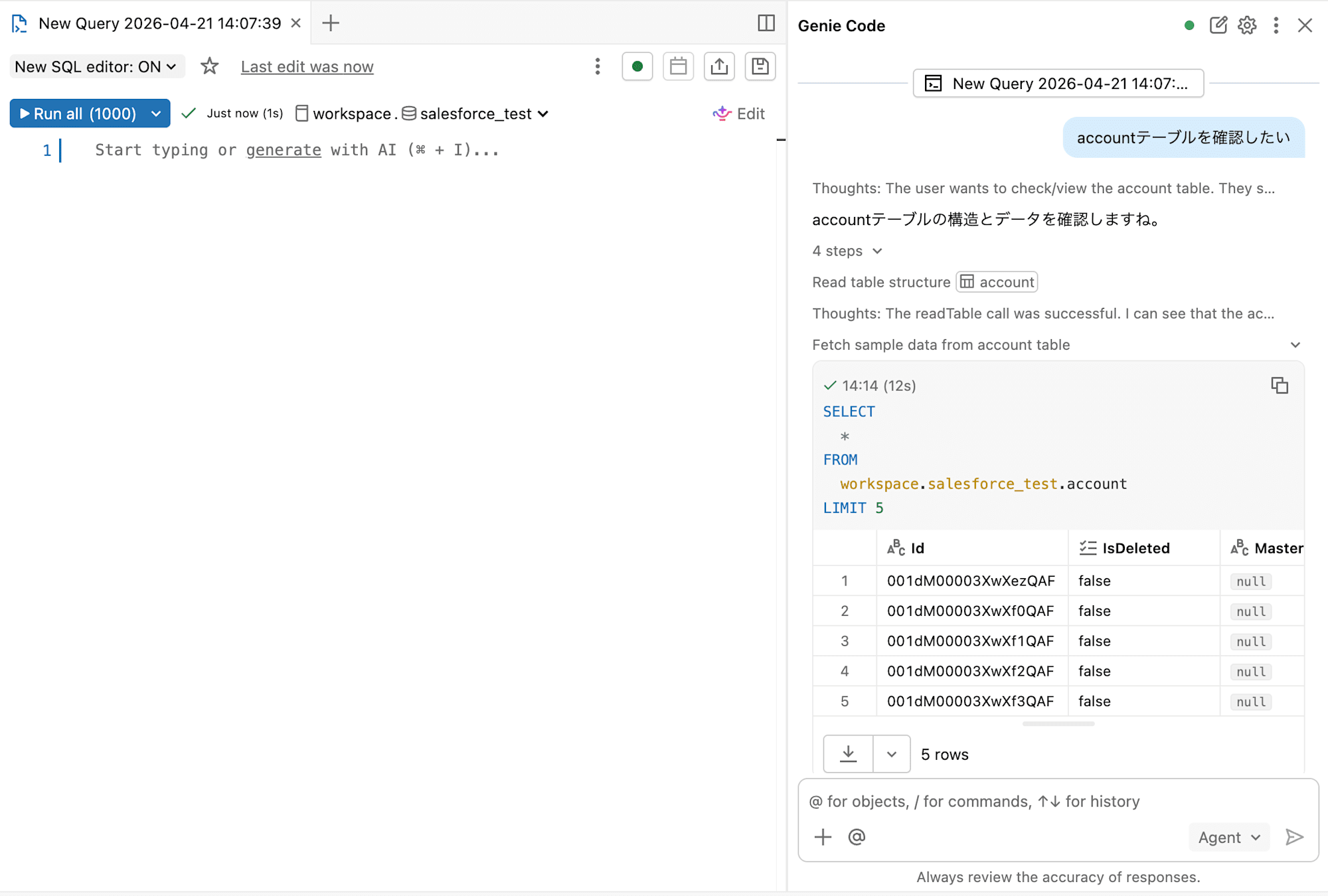
CursorやGitHub Copilotのように、チャット画面からAIにコードを生成してもらったり、データを確認してもらうことができます。
また、Unity Catalogにおける AI生成コメント機能 などもあります。
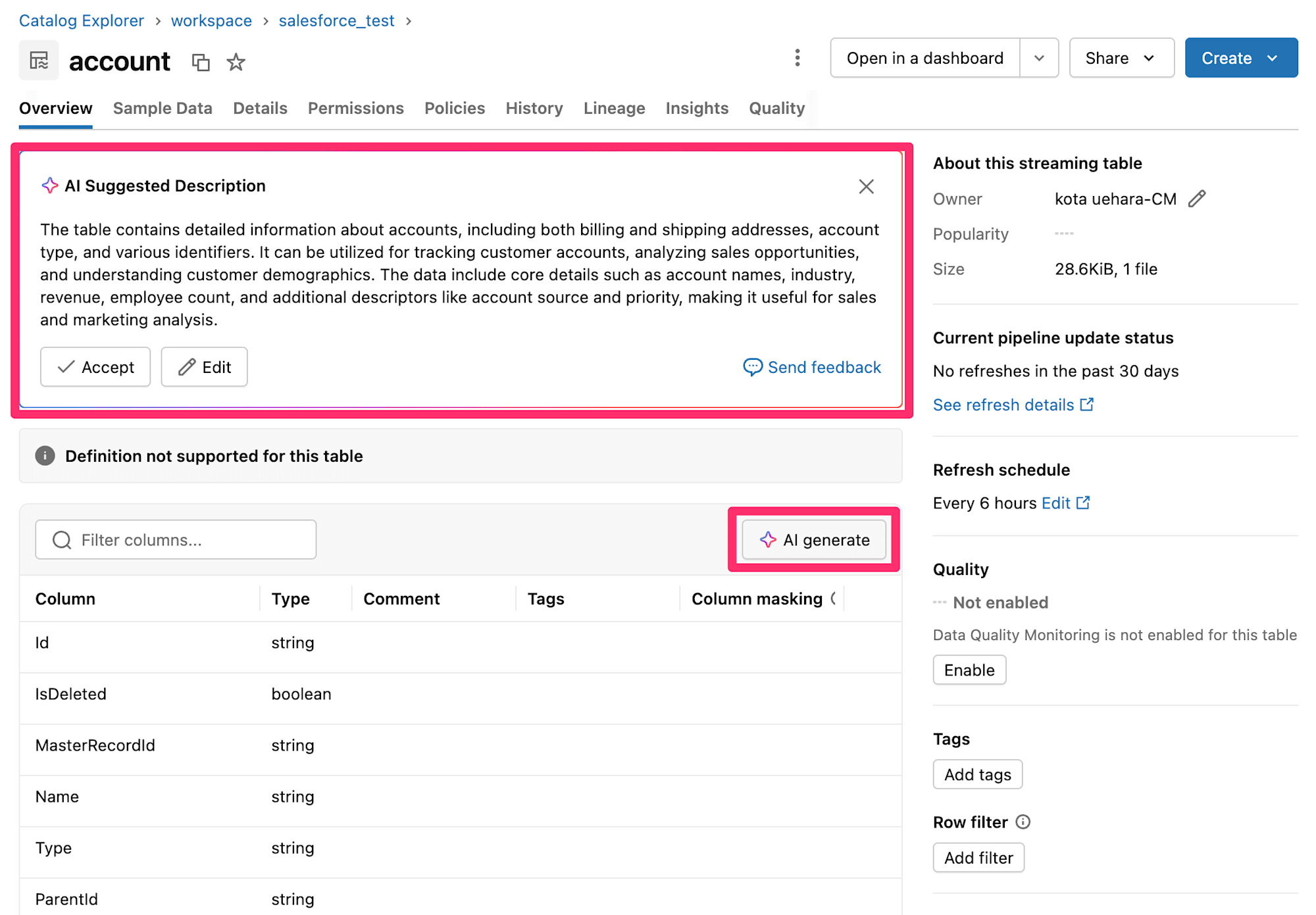
この機能を活用すると、関連するテーブルの説明や、列のコメントをAIにより追加することができます。
実際の使用感などは公式の以下ドキュメントが分かりやすいかも知れません。
上記のような分かりやすい機能以外にも、Unity Catalog管理テーブルに対する Predictive optimization 機能では、データが書き込まれる際に統計情報を収集したり、自動メンテナンスによる不要ファイルの削除やファイルサイズの最適化が実施されていたりと、パフォーマンス向上のための最適化やストレージコストの削減が自動で行われていたりします。
Operational DB
次に「Operational DB」です。
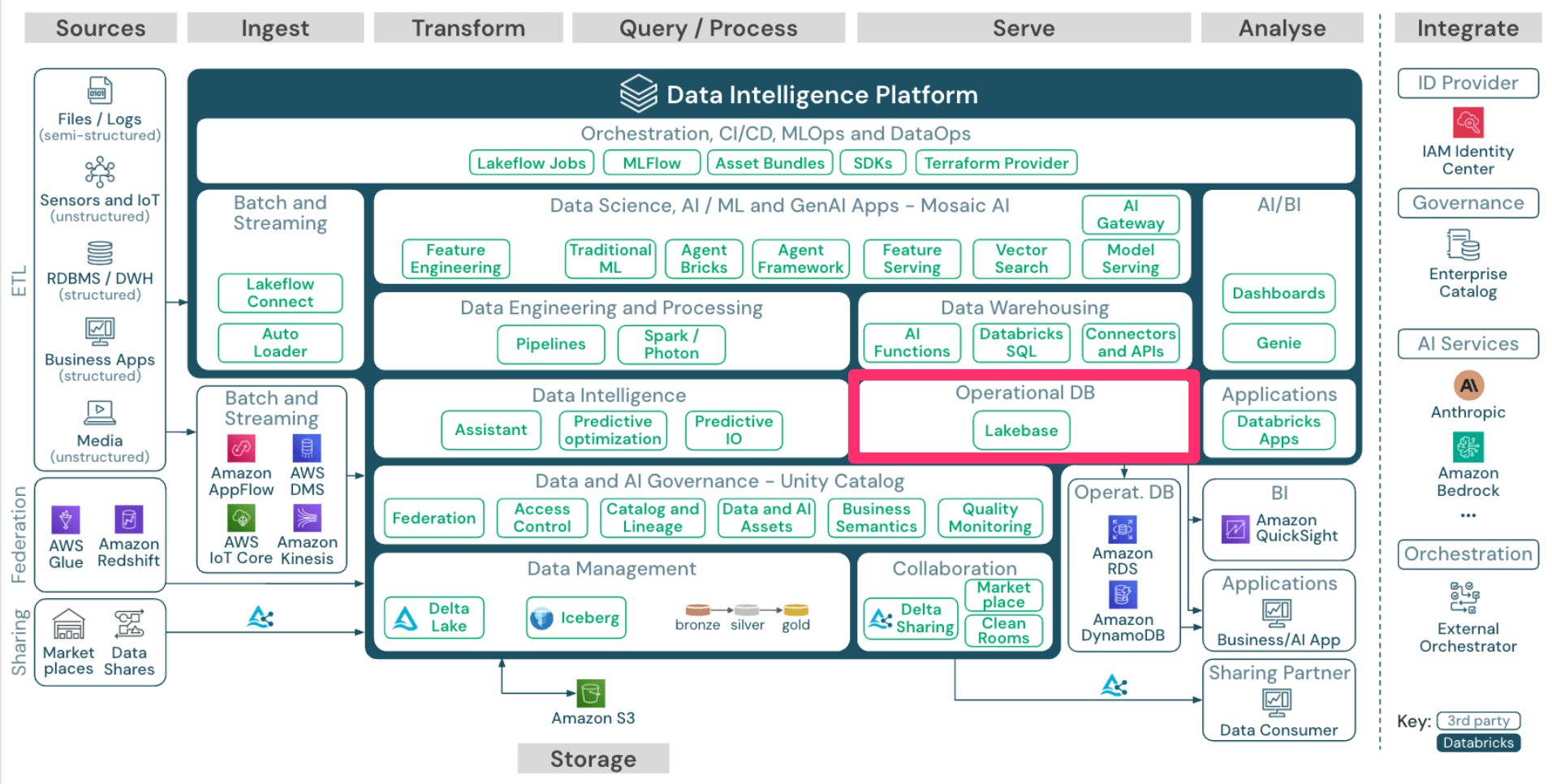
Databricksでは、OLTPデータベースである Lakebase が提供されています。
Lakebaseは、ストレージ層とコンピューティング層が分離したサーバレスなPostgreSQLベースのデータベースです。(Databricksが2025年5月に買収を発表したNeonの技術をベースとしています。)
以下のブログ記事で紹介もしています。
従来のアーキテクチャでは「業務用データベース(OLTP DB)」と「分析基盤のデータベース(OLAP DB)」はサイロ化しており、分析基盤で分析した結果をアプリケーション側で利用したい場合は、アプリケーション側で利用するDBにデータを移動する必要があり、ETLパイプラインの構築や個別のアクセス制御が必要でした。
これに対し、Lakebaseはレイクハウスとの統合により、データのほぼリアルタイムの同期を実現するものとなっています。
※必要に応じて、Unity Catalogを使用してデータへのアクセスを制御することもできます。
このように、Databricksでは分析したデータをアプリケーションで実際に活用することまで考えた機能が提供されています。
Data Engineering and Processing
次に「Data Engineering and Processing」です。
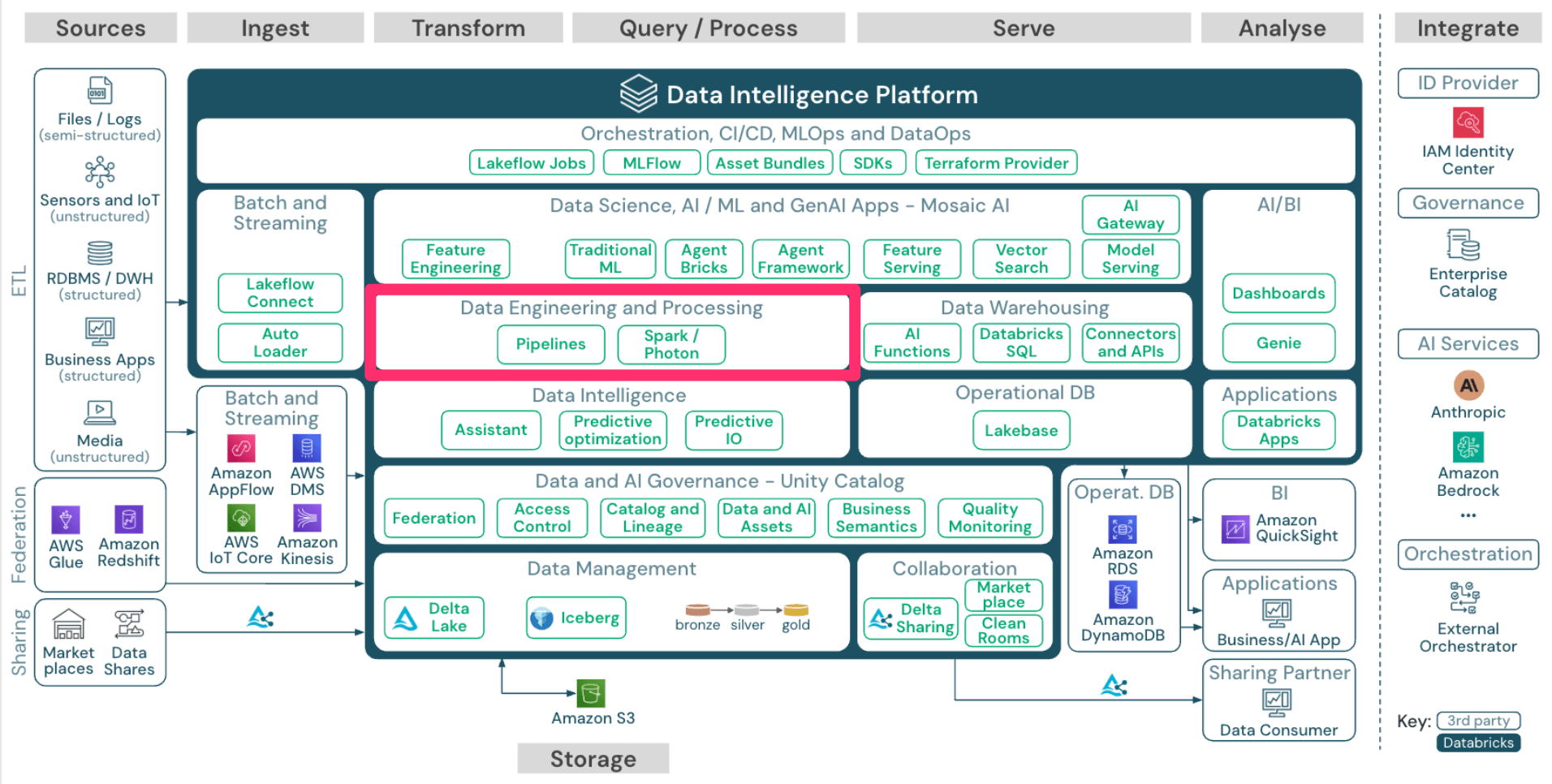
Databricksのパイプライン機能として、 Lakeflow Spark宣言型パイプライン(SDP, 旧 DLT) があります。
「Batch and Streaming」の節でご紹介したAuto Loaderのブログ記事についても、Auto Loaderとパイプラインを組み合わせてテーブルを作成するものになっています。(ブログ記事再掲)
例えば先に示したメダリオンアーキテクチャに則り、Auto Loaderで新規ファイルを読み取り、SDPにより Bronze -> Silver -> Gold へデータを取り込んでいくパイプラインを構築することができます。
またここで Photon エンジンについてもご紹介させて下さい。
Databricksと言うと「Sparkを書かないといけなくて難しそう」という声もたまに聞くのですが、今やDatabricks SQLにより、Sparkはもはや書かなくても問題ない状況です。
(先ほど紹介したGenie Codeを利用すればSparkもほぼ問題なく書ける、というのが実情ではありますが)
Databricksのネイティブベクトル化クエリエンジンであるPhotonは非常に優秀であり、Apache Spark DataFrameおよびSQL APIと互換性があるように設計されており、両者を透過的に高速化しています。
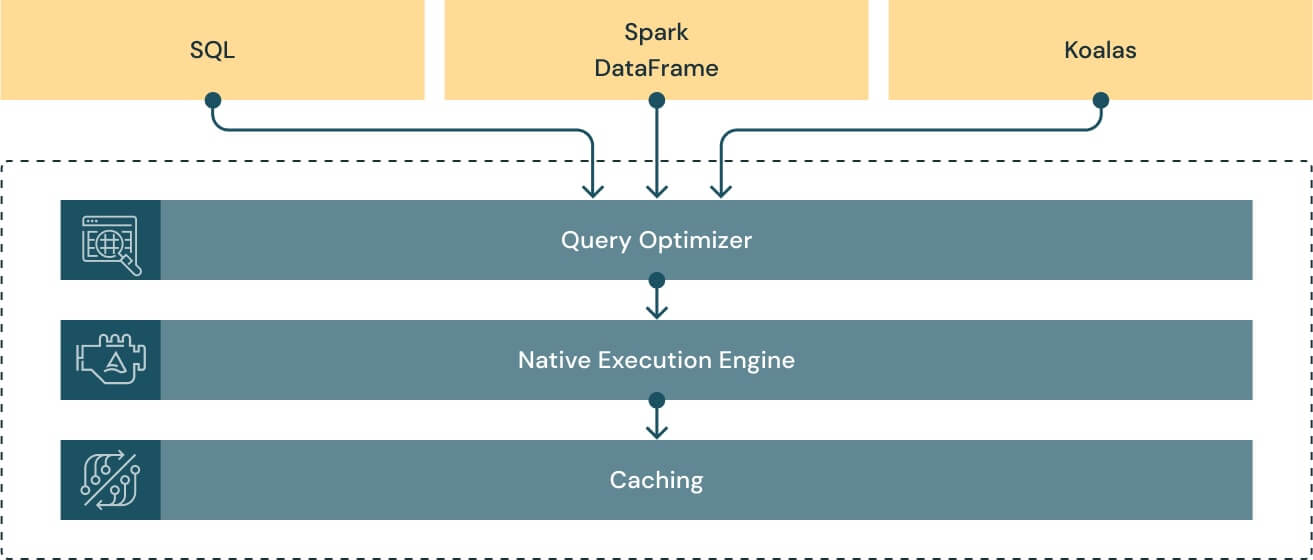
(引用元)
あくまで個人的な体感にはなりますが、他のDWH製品と比較しても大規模データに対してDatabricksは非常に高速に処理ができるように感じています。
Data Warehousing
次に「Data Warehousing」です。
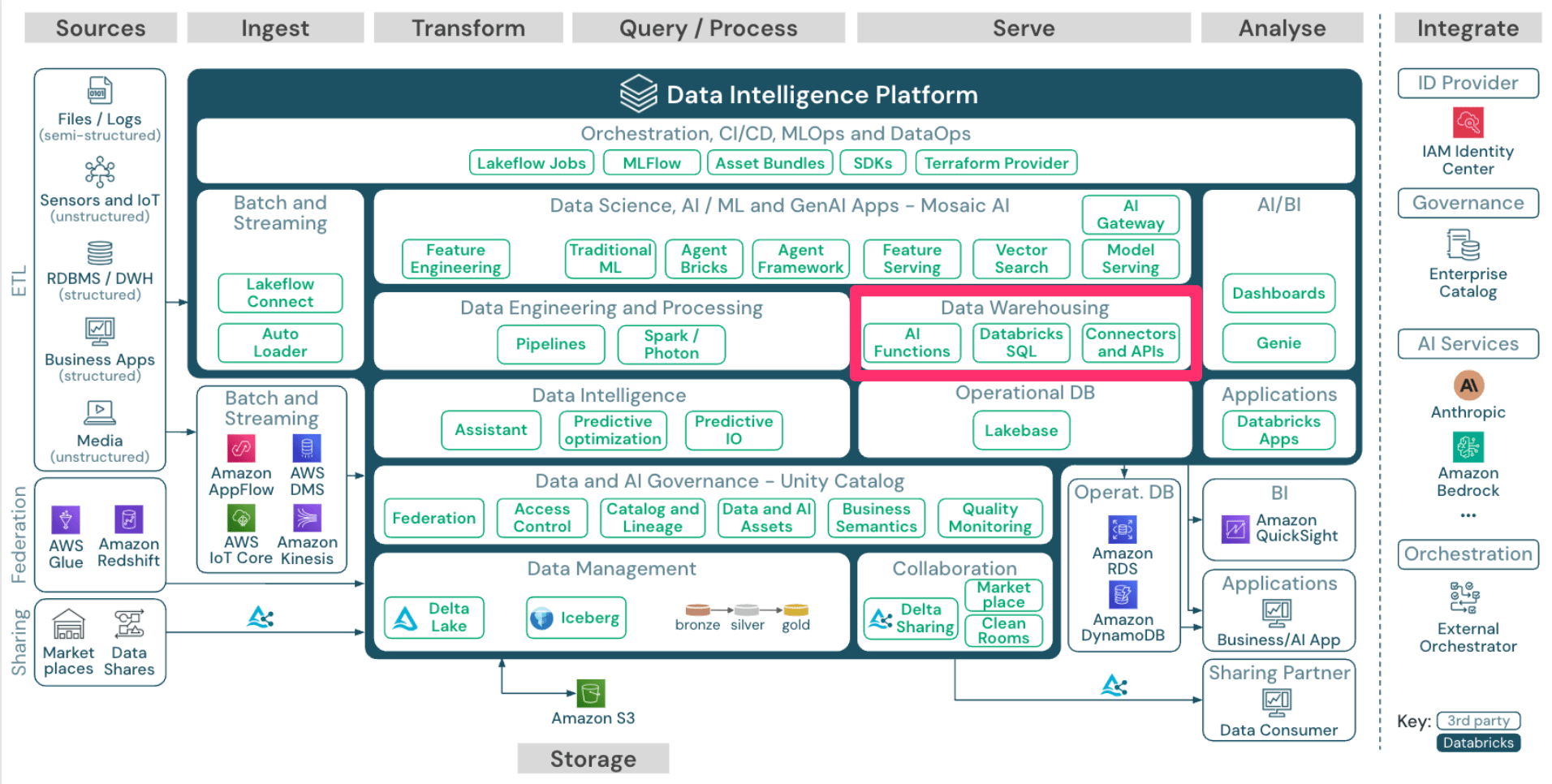
Databricks SQLについては「Data Engineering and Processing」の節でもお話した通りですが、 AI Functions という便利なAI関数機能も存在します。
以下の記事で、PDFやPNGといった非構造化データであるドキュメントファイルから、構造化されたコンテンツを抽出することができるAI関数である ai_parse_document を利用した例をご紹介しています。
レイクハウスアーキテクチャでは非構造化データを扱うケースも非常に多いかと思いますが、このようにAI関数を利用することで簡単に構造化データに変換することができます。
Data Science, AI/ML and GenAI Apps
次に「Data Science, AI/ML and GenAI Apps」です。
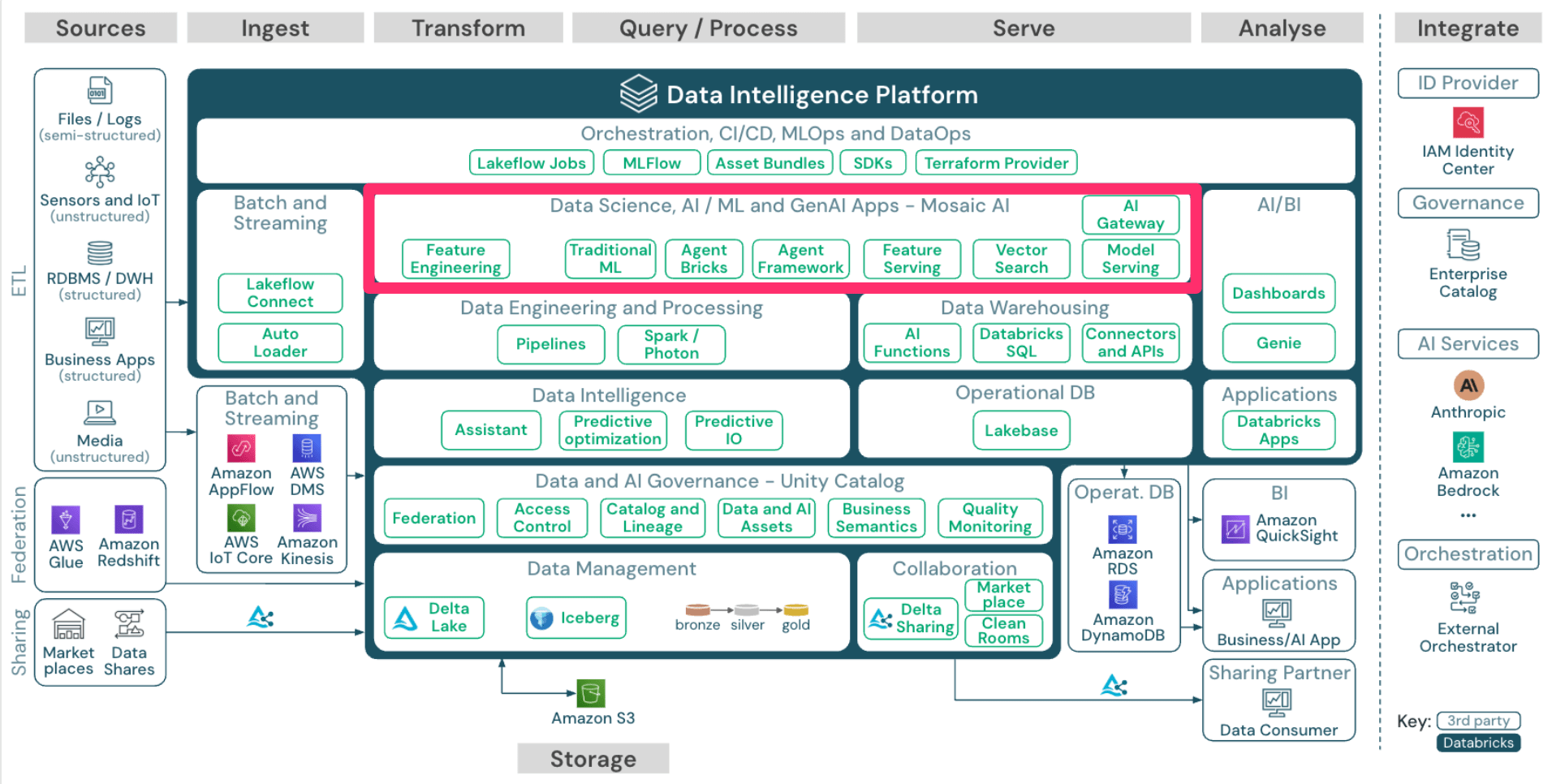
ここで、まず MosaicML という企業について簡単にご紹介させて下さい。
MosaicMLは2023年にDatabricksが買収した企業で、企業向けにジェネレーティブAIモデルを作成し、カスタマイズするためのプラットフォームを開発していました。
買収後、Databricksが自社プラットフォームに統合・拡張してできた現在のAI製品群が Mosaic AI になります。
Feature Serving や Model Serving など、ML/AIモデルを開発・デプロイするために便利な機能が揃っています。
これはDatabricksの大きな強みの1つであると認識しており、元々レイクハウスというアーキテクチャは構造化・非構造化データを一元管理して、BIからML/AIまでをシームレスに実現するためのアーキテクチャです。
したがって、ML/AIモデルをDatabricks上でそのまま開発することができるというのは強いアドバンテージになります。
その他、以下ブログでも紹介されていますがKnowledge Assistantを利用したAIエージェントの作成をすることもできます。
その他にも様々な機能があるので、以下ページを参考にして頂ければと思います。
Applications
次に「Applications」です。
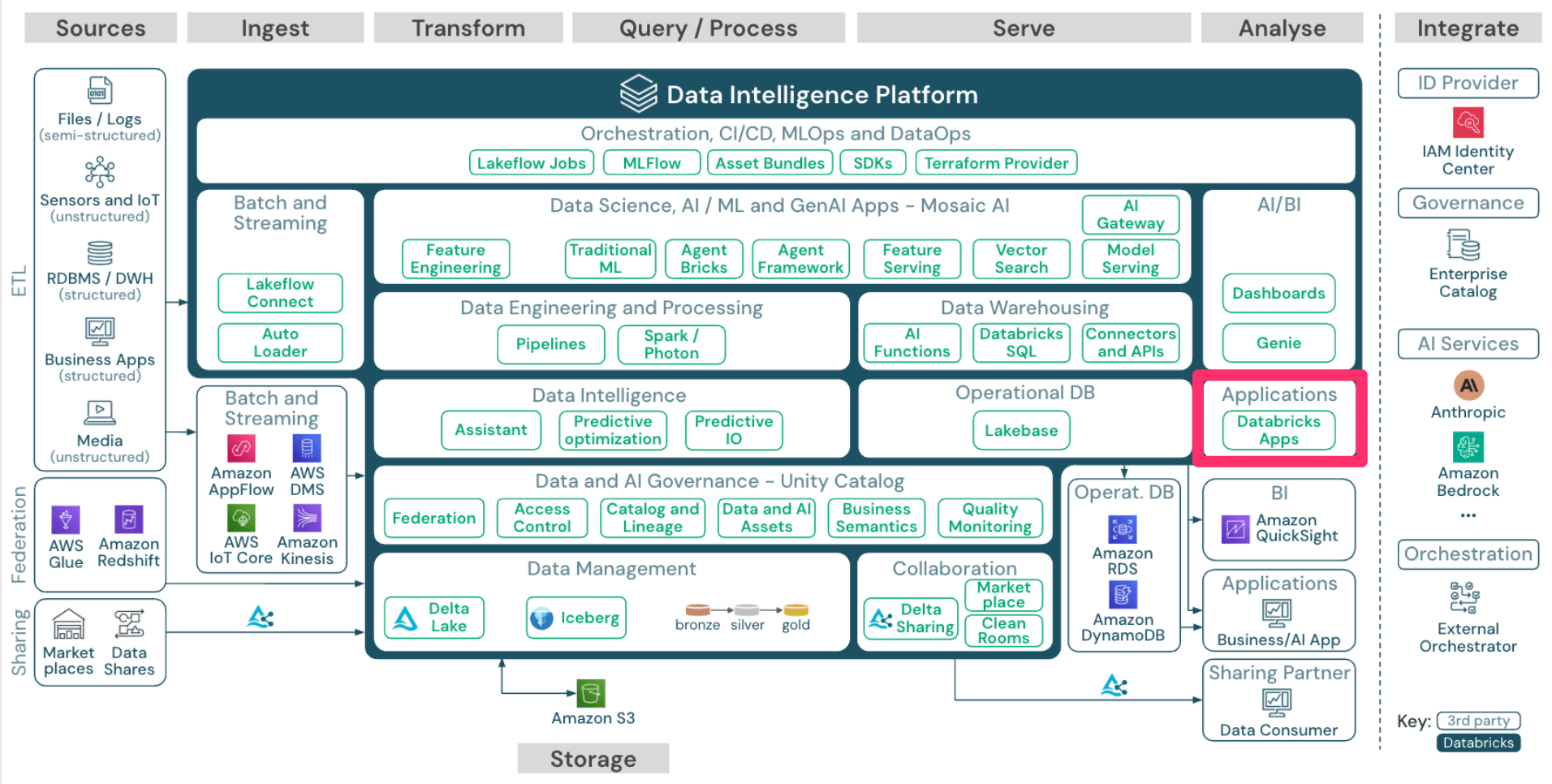
Databricks Apps はその名の通りDatabricks上でアプリケーションを構築する機能です。
Python または Node.js でDatabricks上にアプリケーションを作成することができます。
以下ブログ記事で、Python (Streamlit)でアプリケーションを作成した例を紹介しています。
Pythonを選定したとしても、Streamlitに限らず、Dash/Gradio/Flaskなど様々なモジュールを利用して開発することができます。
生成AIモデルを活用したアプリの作成も可能なので、利用の幅は広いと感じます。
AI/BI
次に「AI/BI」です。
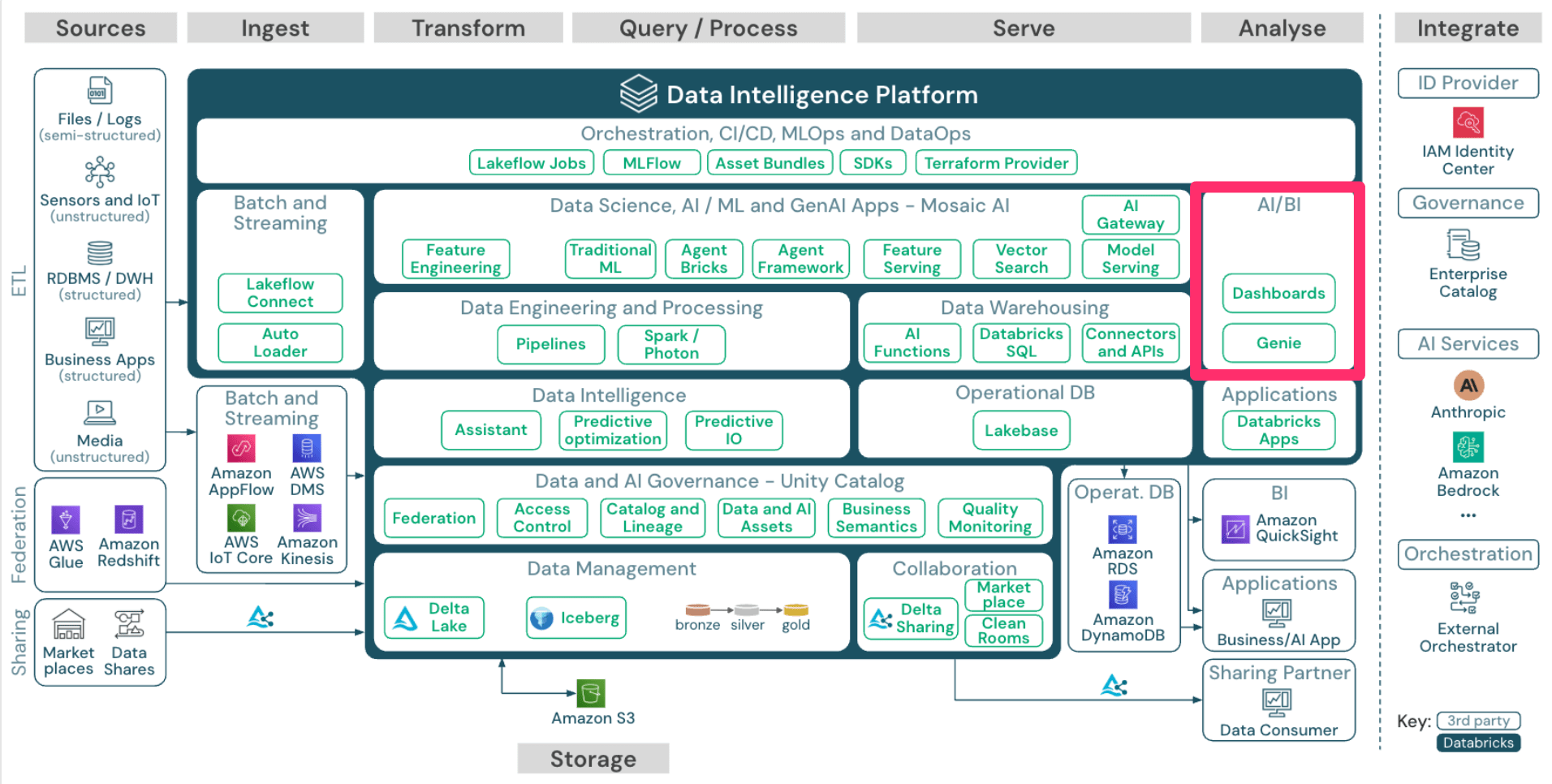
まず BI についてですが、前提としてDatabricksはOSSの人気BIツールを開発していた Redash を2020年に買収しています。
※私が過去いくつか参画した案件でも、BIツールとしてRedashをセルフホスティングしているケースがいくつかありました。
したがって、元々普通にBIツールとして使われていたものがベースとなっているだけあって、Databricksで提供されるBIダッシュボードは機能としては必要十分なものになっている印象を受けます。
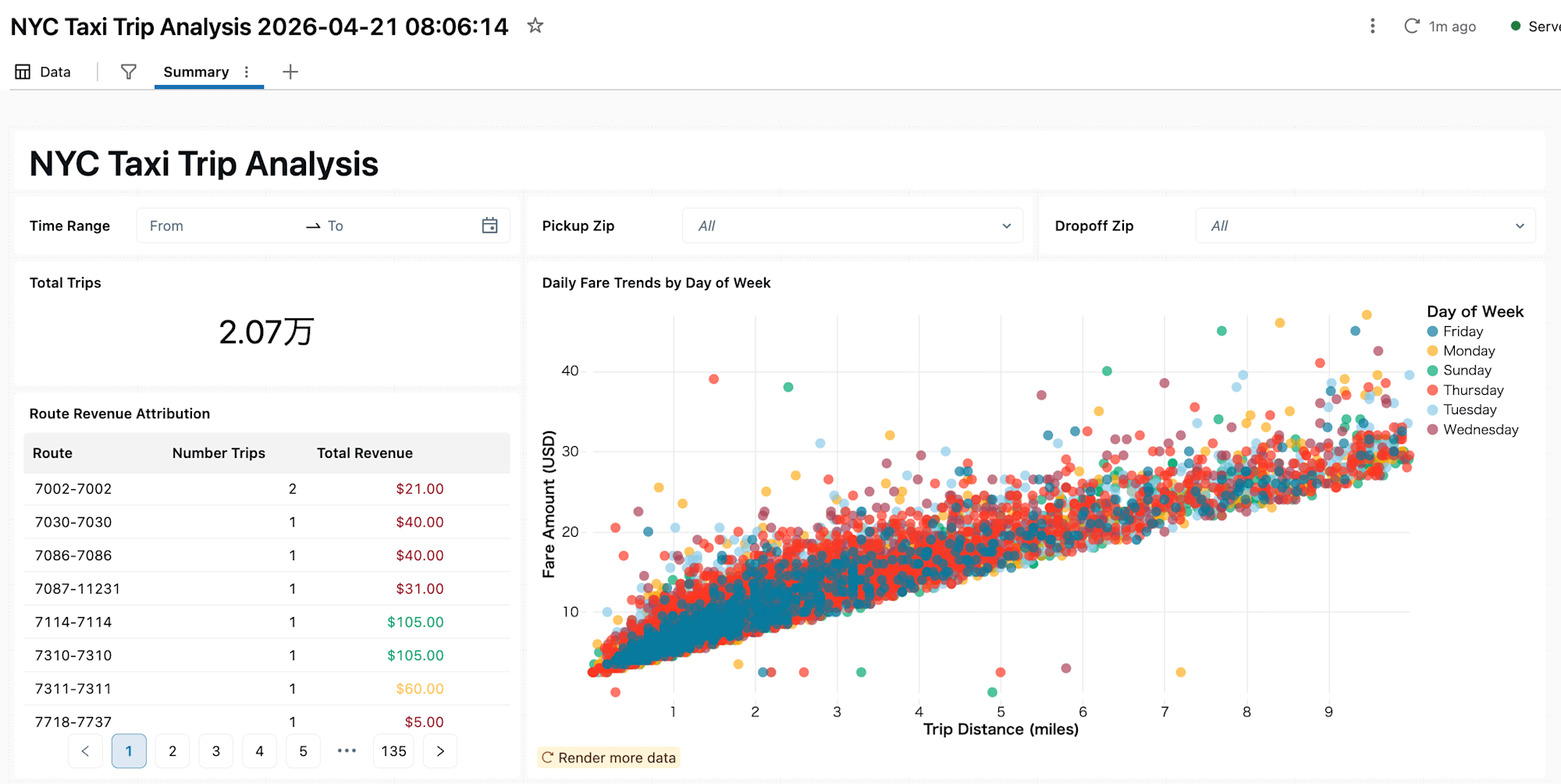
以下のブログ記事でも機能の紹介がされていますので、参考に頂ければと思います。
AI に関しても、Databricks上のデータに対して自然言語を用いて検索、分析、可視化を行うことができます。
このように、DatabricksだけでBIダッシュボードの確認や、AIを利用したデータのインサイトを得ることができるものになっています。
Orchestration, CI/CD, MLOps and DataOps
最後に「Orchestration, CI/CD, MLOps and DataOps」です。
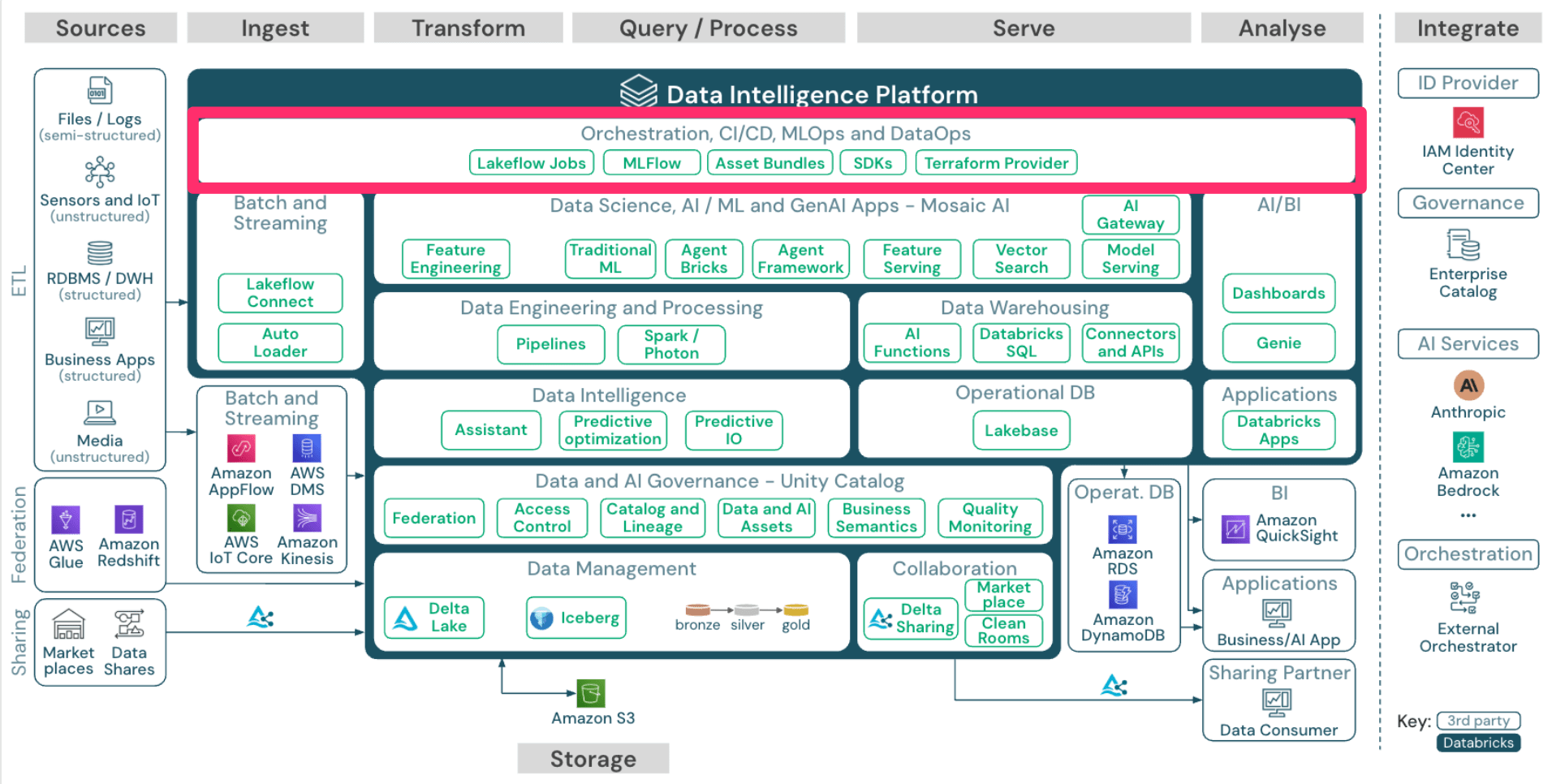
まず、Databricksのジョブ管理機能として Lakeflow Jobs があります。
Lakeflow Jobsを利用することで、「Batch and Streaming」の節で紹介したLakeflow Connectや、パイプラインの実行をオーケストレーションすることができます。
また、以下のブログ記事でも紹介している通り、Lakeflow Jobsを利用してDatabricks上で dbt を実行することも可能です。
ELTパイプラインとしてdbtを利用したいというケースでも、Databricks外にコンピュートリソースを用意することなく、対応することができます。
また、マネージド MLflow についても、Databricksの注目機能の1つです。
今でこそMLflowもOSSになっていますが、元々はDatabricksの創業者により開発が主導されていたフレームワークです。
MLflowにより、モデルの実験、再現性確認、デプロイメント、一元的なモデルのレジストリーなど、機械学習のライフサイクルの管理(MLOps)を容易にすることができます。
またDatabricks上のリソースを定義するためのIaCとして、 Terraform も利用可能ですが、DatabricksのネイティブIaCである Declarative Automation Bundles(旧 Databricks Asset Bundles) も利用可能です。
※Terraformは将来的には廃止予定のようです。(参考)
Declarative Automation Bundlesを利用すれば、以下のようにymlベースでリソースの定義が可能です。
bundle:
name: hello-bundle
resources:
jobs:
hello-job:
name: hello-job
tasks:
- task_key: hello-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: ./hello.py
targets:
dev:
default: true
最後に
今回は、Databricksが公開しているレイクハウスのリファレンスアーキテクチャから、Databricksで提供される機能の全体像をご紹介してみました。
非常に数多くの機能が提供されており、冒頭で述べた通りすべての機能を一つずつ詳細に取り上げるのはこの場では難しいのですが、Databricksという1つのプラットフォームでレイクハウスアーキテクチャがどのように構築されるかのざっくりとした把握をして頂けたのではないでしょうか。
Databricksを「単なるDWHの1製品」として認識するのは勿体ないです。
何となく、「こんなことできるんだ」という理解の一助になりましたら幸いです。









