
【Databricks】LakeFlow Spark宣言型パイプラインとAI関数を利用してS3上のPDFをパース・蓄積してみた
データ事業本部のueharaです。
今回は、LakeFlow Spark宣言型パイプラインとAI関数を利用してS3上のPDFをパース・蓄積してみたいと思います。
LakeFlow Spark宣言型パイプラインについて
LakeFlow Spark宣言型パイプライン (SDP) は以前は Delta Live Tables (DLT) と呼ばれていたDatabricksの1機能です。
SDPは、一言でいうとSQLおよびPythonでバッチ/ストリーミングデータのパイプラインを開発・実行するための宣言型フレームワークです。
以前執筆した以下の記事にSDPの前身であるDLTについて記載していますので、良ければご確認下さい。
SDPを利用すれば、依存関係を有するテーブルの増分更新がDatabricks内で簡単に実現できます。
DatabricksのAI関数について
Databricksには便利な AI関数 があります。
AI関数はDatabricksに搭載されている組み込み関数で、例えば生成AIを使用して2つの文章の意味的な類似性を評価する ai_similarity や、テキストに対して感情分析を行う ai_analyze_sentiment などがあります。
その中でも、今回はPDFやPNGといった非構造化データであるドキュメントファイルから、構造化されたコンテンツを抽出することができる ai_parse_document を利用します。
対応しているファイル形式や使い方は以下ドキュメントをご確認下さい。
SDPでのai_parse_documentの利用
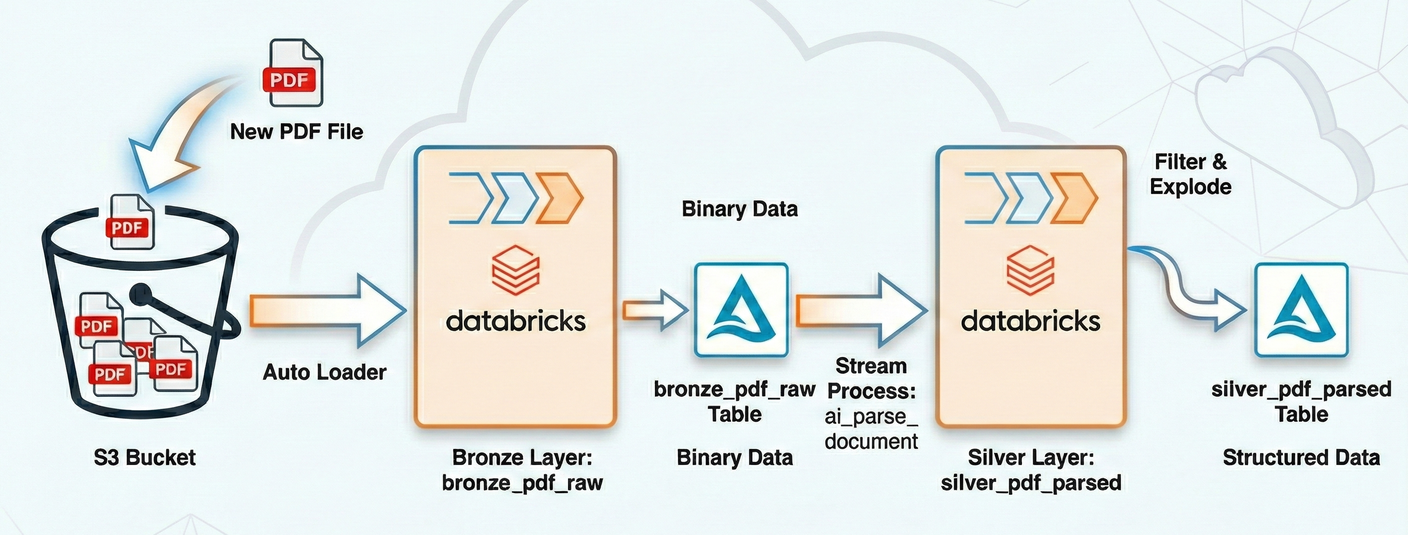
今回はSDPと一緒に ai_parse_document 関数を利用することで、S3にアップロードされるPDFファイルをパースし、増分更新で蓄積していくパイプラインを構築します。
なお、今回は便宜上生データであるバイナリデータをBronzeレイヤー、AI関数でパースした後の構造化データをSilverレイヤーとしたいと思います。
やってみた
前提
今回、前提としてS3へのデータアクセスのため既にStorage Credentialの設定や外部ロケーションの作成が完了していることを想定しています。
パイプラインの作成
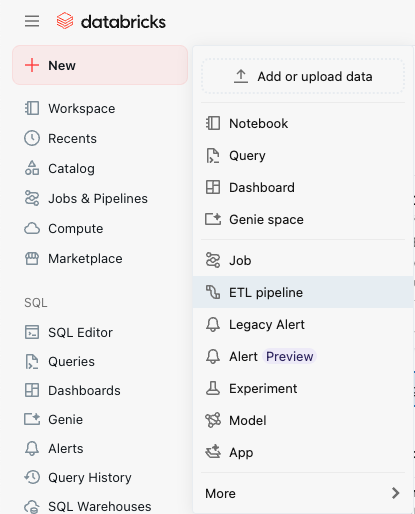
まず、Databricksのトップページの左側のタブから『+ New』 → 『ETL pipeline』を選択します。
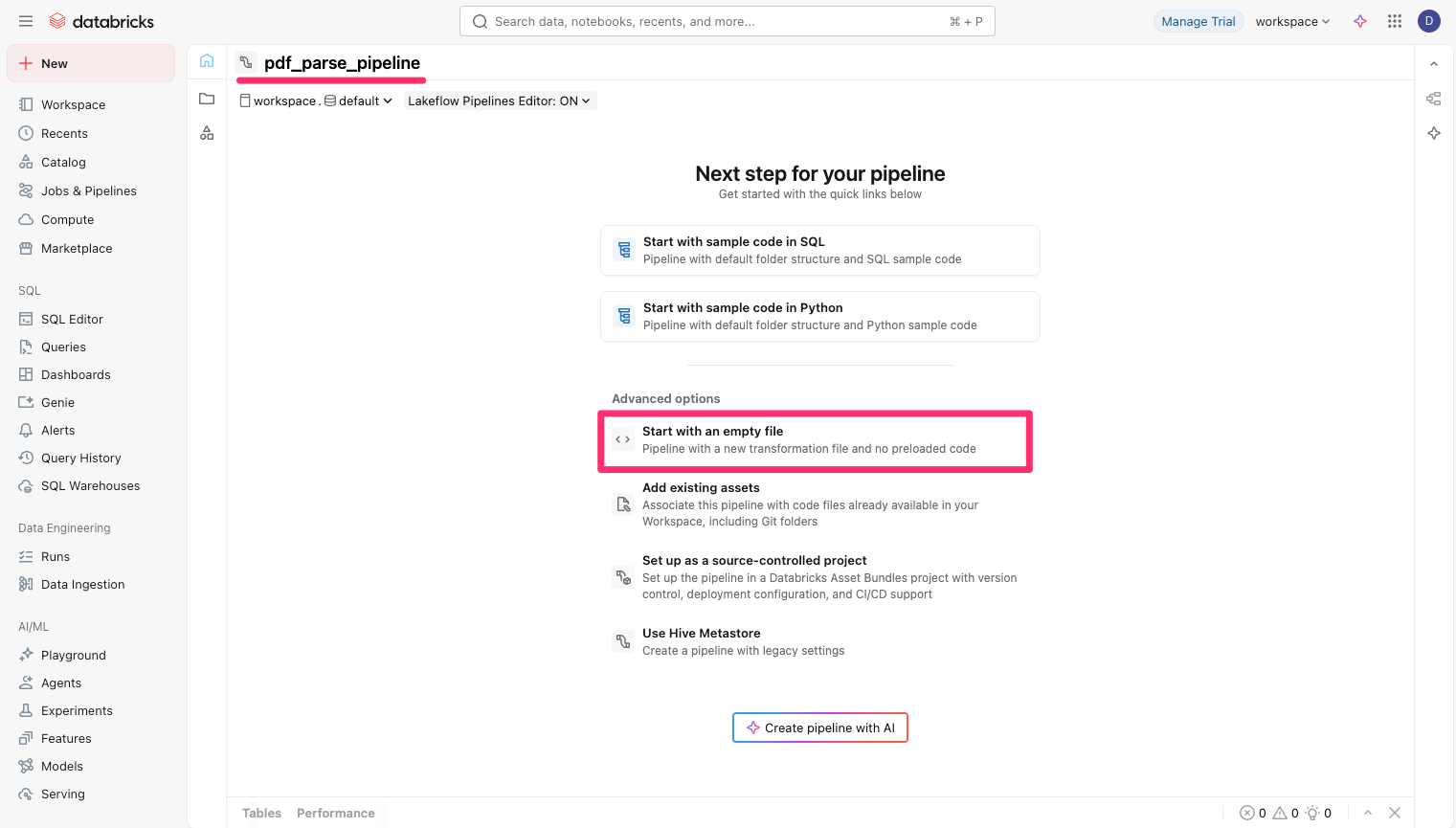
適当なパイプライン名を付け、『Start with an empty file』を選択します。
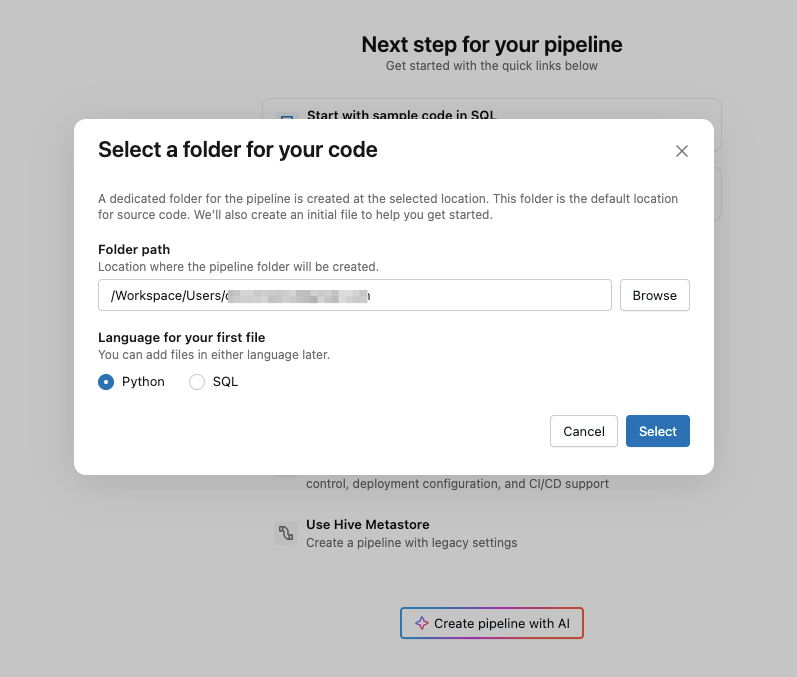
次の画面では『Python』を選択します。
するとPythonファイルが開かれると思うので、以下の通りSDPを構築します。
from pyspark import pipelines as dp
from pyspark.sql import functions as F
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
SOURCE_PATH = "s3://<YOUR_PATH>/"
# -------------------------------------------------------
# Bronze: S3からPDFをAuto Loaderで差分取り込み
# -------------------------------------------------------
@dp.table(
name="bronze_pdf_raw",
comment="S3から差分取り込みしたPDFバイナリデータ"
)
def bronze_pdf_raw():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "binaryFile")
.option("pathGlobFilter", "*.pdf")
.load(SOURCE_PATH)
.select("path", "modificationTime", "length", "content")
)
# -------------------------------------------------------
# Silver: ai_parse_documentでPDFをテキストに変換
# -------------------------------------------------------
@dp.table(
name="silver_pdf_parsed",
comment="ai_parse_documentでパース済みのテキストデータ"
)
def silver_pdf_parsed():
return (
spark.readStream.table("bronze_pdf_raw")
.selectExpr(
"path",
"modificationTime",
"ai_parse_document(content, map('version', '2.0')) AS parsed"
)
.where("try_cast(parsed:error_status AS STRING) IS NULL")
.selectExpr(
"path",
"modificationTime",
"posexplode(filter(try_cast(parsed:document:elements AS ARRAY<VARIANT>), e -> try_cast(e:type AS STRING) IN ('title', 'section_header', 'text', 'table'))) AS (element_index, element)"
)
.selectExpr(
"path",
"modificationTime",
"element_index",
"try_cast(element:type AS STRING) AS element_type",
"try_cast(element:content AS STRING) AS content"
)
)
上記の SOURCE_PATH にはPDFを格納するS3のパスを設定して下さい。
この時点で画面は以下のようになっていると思います。
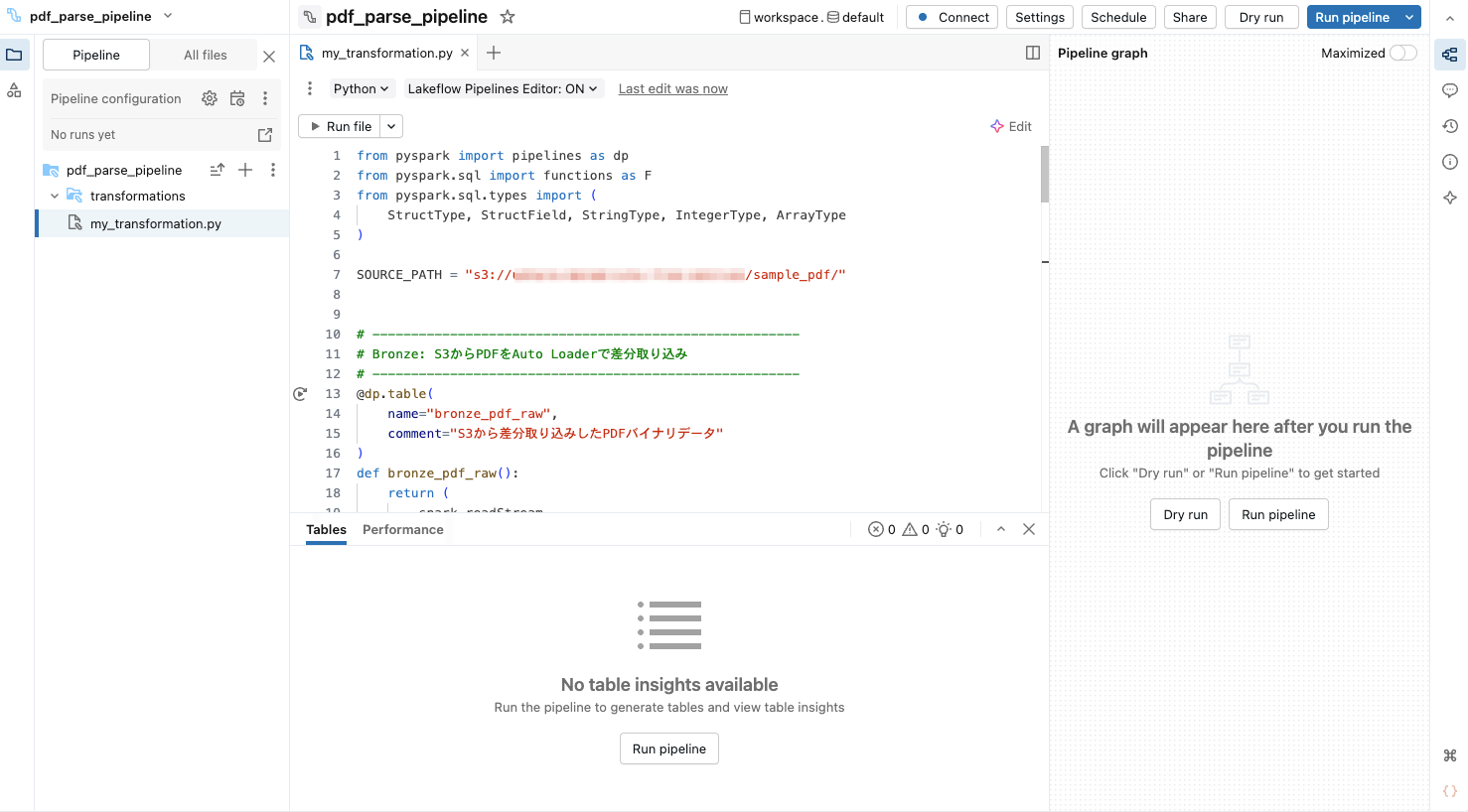
次にパイプラインの設定(『Pipeline configuration』)から『Advanced settings』に進み『Channel』をPreviewに設定して下さい。
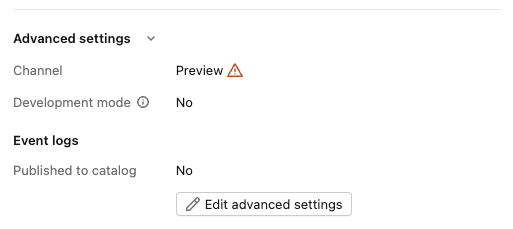
※記事執筆時点では、こちらの設定をしないとSDPで ai_parse_document 関数を利用できませんでした。
これでパイプラインの作成は完了です。
実行・データ確認
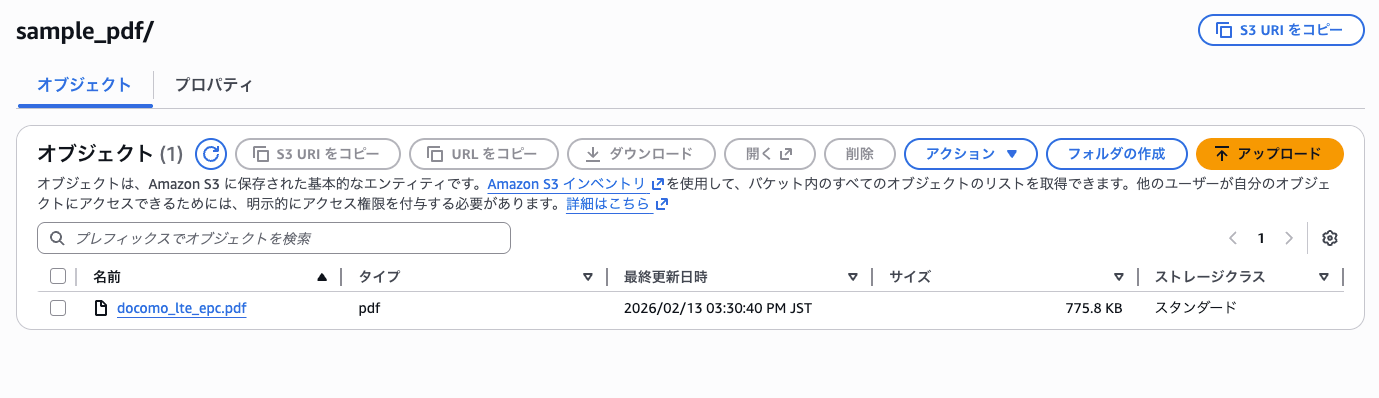
まず、パイプラインで設定したS3のパスにPDFファイルをアップロードします。
特別な理由はありませんが、NTTドコモ様が一般公開されている こちらの資料 をアップロードしてみました。
Databricksに戻り、画面右上の『Run pipeline』ボタンからパイプラインを実行します。(補足:今回は手動でパイプラインを実行していますが、Auto Loaderのファイル通知モードを利用すると、ファイルのアップロード契機でパイプラインを実行することもできます。)
パイプラインの実行が始まると、以下のように実行されるパイプラインがグラフで表示されます。
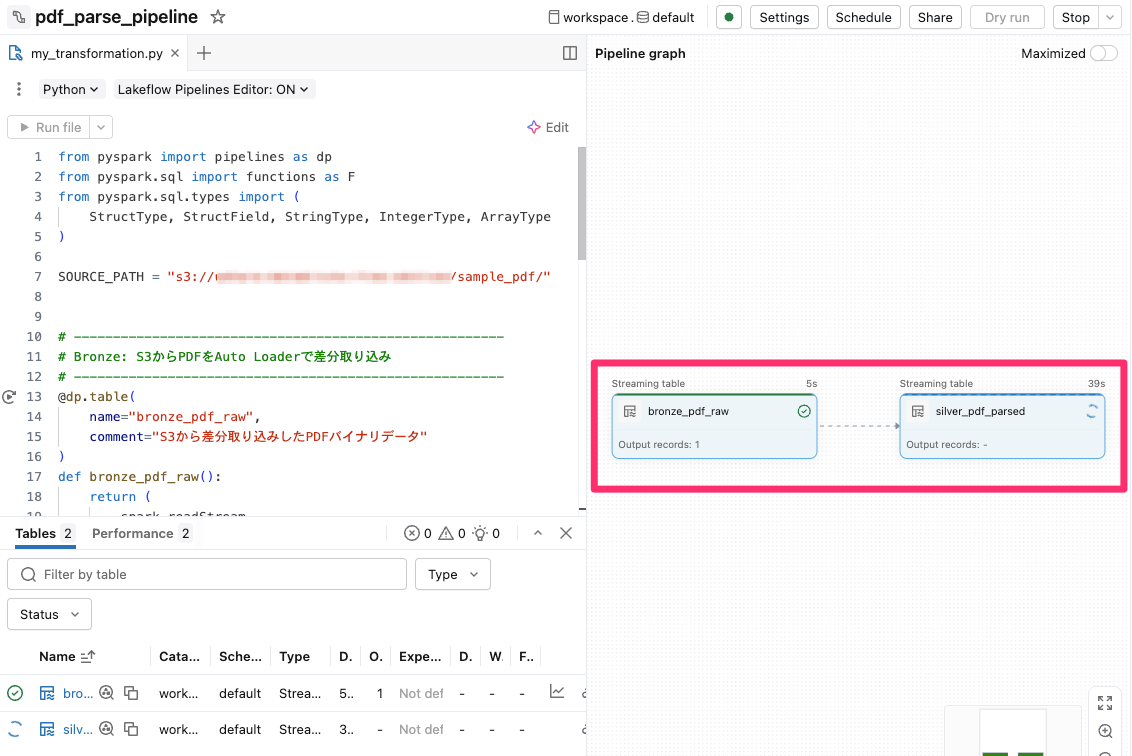
しばらく待ち、パイプラインの実行が正常終了していることを確認します。
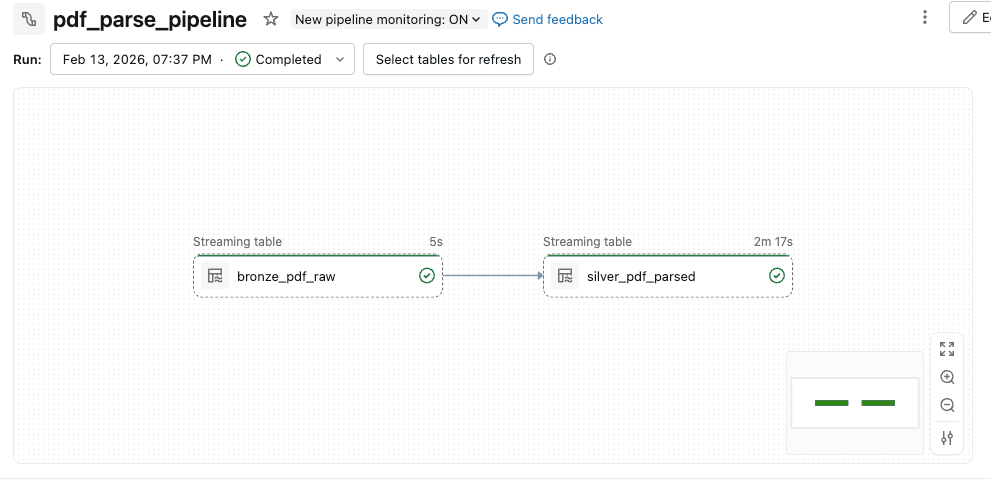
カタログ上でも、今回作成した bronze_pdf_raw テーブルと silver_pdf_parsed テーブルが作成できていることを確認できました。
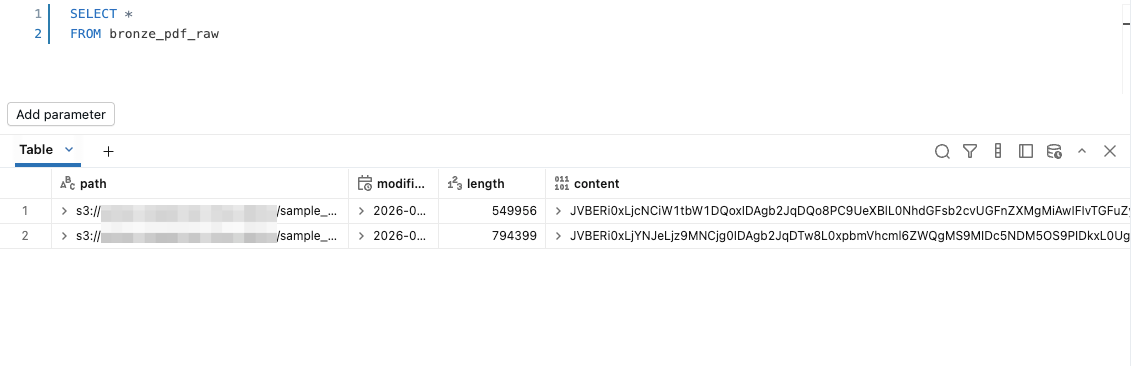
まずは bronze_pdf_raw テーブルの中身を確認します。
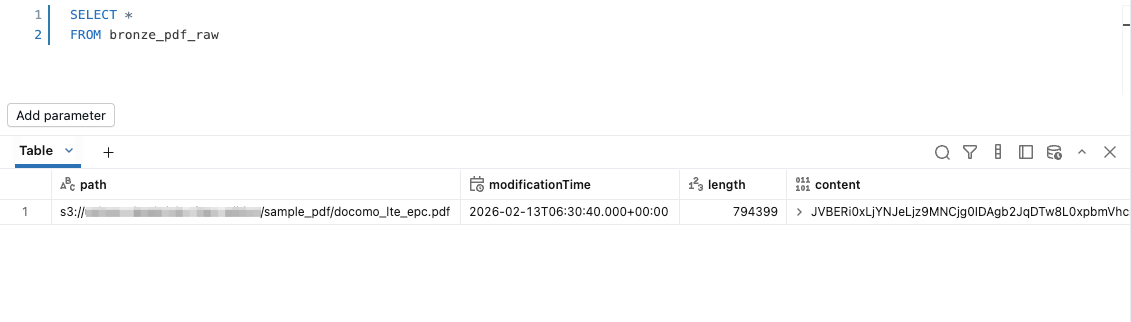
PDFファイルのバイナリデータを確認することができました。
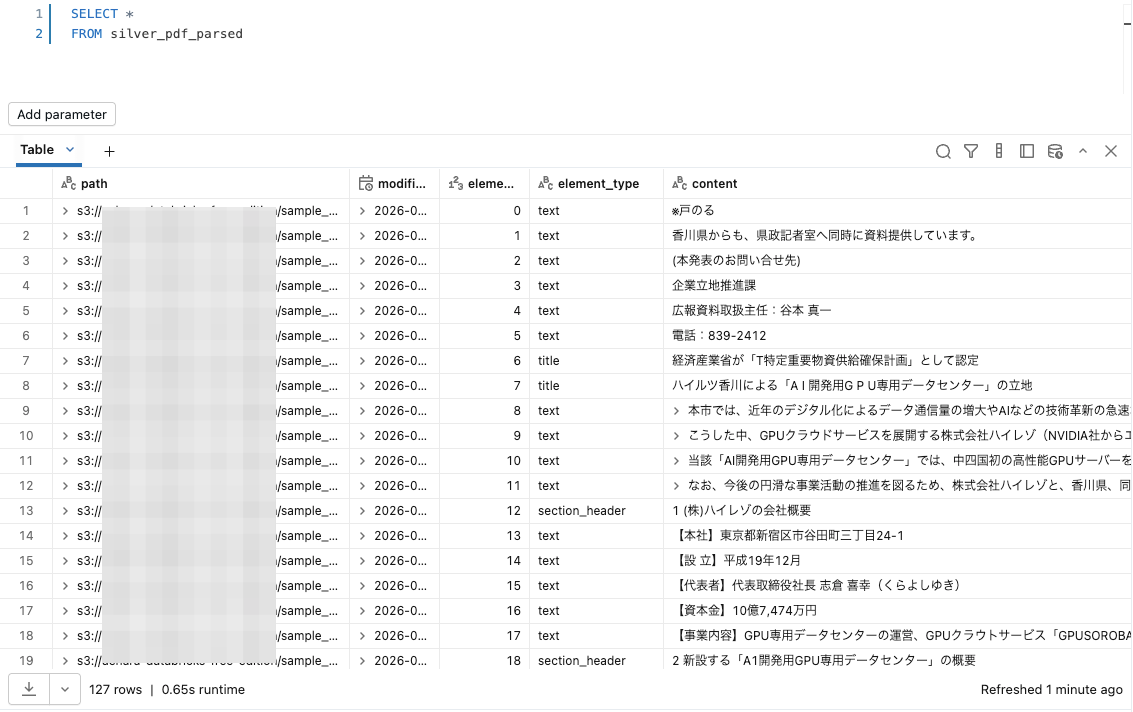
次に、肝心の silver_pdf_parsed テーブルを確認してみます。
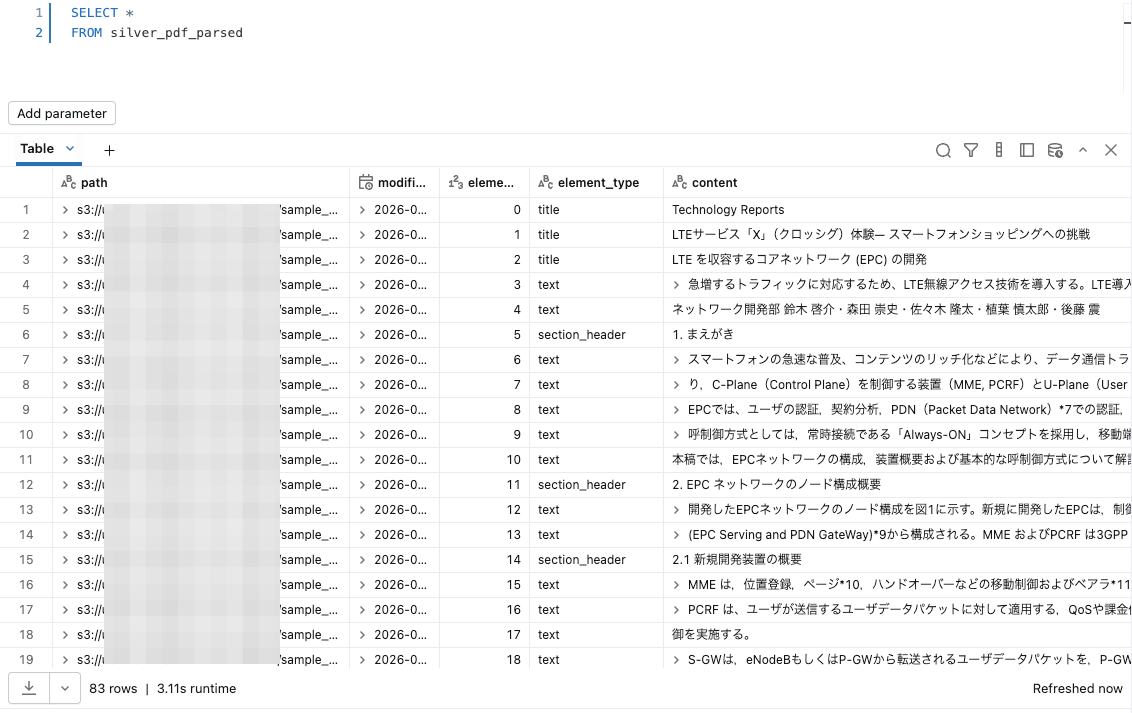
確認するとPDFファイルの中身が概ね正しく読み取れており、 element_type として title や section_header といった情報も良い感じに設定されています。
次に、別のファイルをS3にアップロードしてみます。
こちらも特に理由は無いですが、高松市様がプレスリリースしていた こちらの資料 をアップロードしてみました。
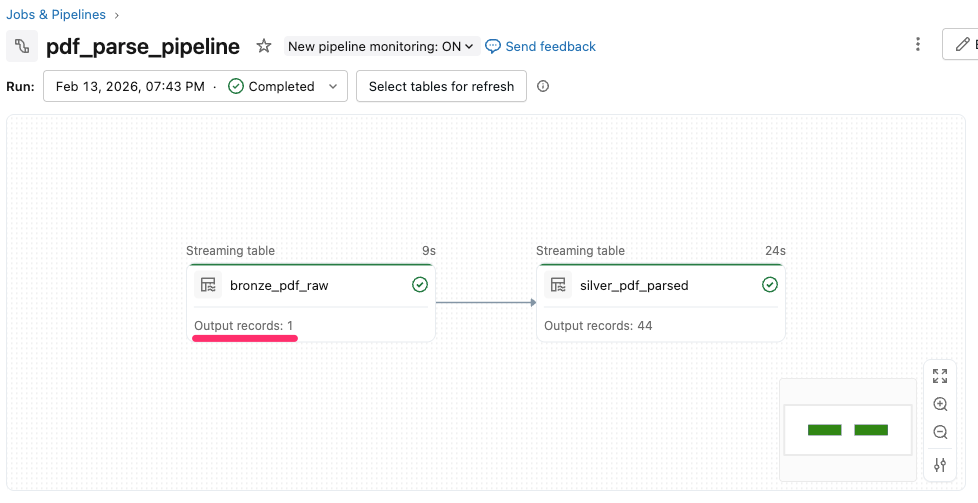
再度Databricksに戻り、パイプラインを実行します。
増分更新のため、既に処理したPDFファイルは処理されず、新たに追加した1ファイルのみが更新対象として実行されることが分かります。
念のためテーブルのデータも確認してみると、bronze_pdf_raw テーブルと silver_pdf_parsed テーブルそれぞれにデータが追加されていることが確認できます。
最後に
今回は、LakeFlow Spark宣言型パイプラインとAI関数を利用してS3上のPDFをパース・蓄積してみました。
今回作成したSilverレイヤーのテーブルについて、今後の展開としてはVector Search用のインデックステーブルのソースとして利用するといったRAGでの利用や、ドキュメントの要約・分析に利用するといったことが考えられるかと思います。
参考になりましたら幸いです。









