
DatabricksのUnity Catalogを利用してS3のデータを外部テーブルとして読み込んでみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、DatabricksのUnity Catalogを利用してS3のデータを外部テーブルとして読み込んでみたいと思います。
はじめに
データレイクとして、既にS3にてHive形式でParquetファイルを格納しているというケースは多いと思います。
今回は、DatabricksのUnity Catalogを利用して、S3にあるParquetファイルを読み込んでみたいと思います。
事前準備・設定
IAMロールの作成
Databricksから対象のAWSアカウントにあるS3にアクセスするためのIAMロールを作成します。
AWSマネージドコンソールからIAMサービスにアクセスし『ロールの作成』を選択します。
次に『カスタム信頼ポリシー』を選択して、以下の内容を記載します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": ["arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"]
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "0000"
}
}
}
]
}
このポリシーでは、Unity Catalogがバケット内のデータにアクセスするロールを引き受けることができるように、クロスアカウントの信頼関係が記載されています。
いまいまはプレースホルダーとして外部IDを 0000 に設定していますが、こちらは後の手順で環境に合わせ更新します。
アクセス許可ポリシーの構成はスキップし、ロール名を記載してIAMロールを保存します(ポリシーは次のステップで追加します)
次に、作成したIAMロールに対しインラインポリシーを設定します。
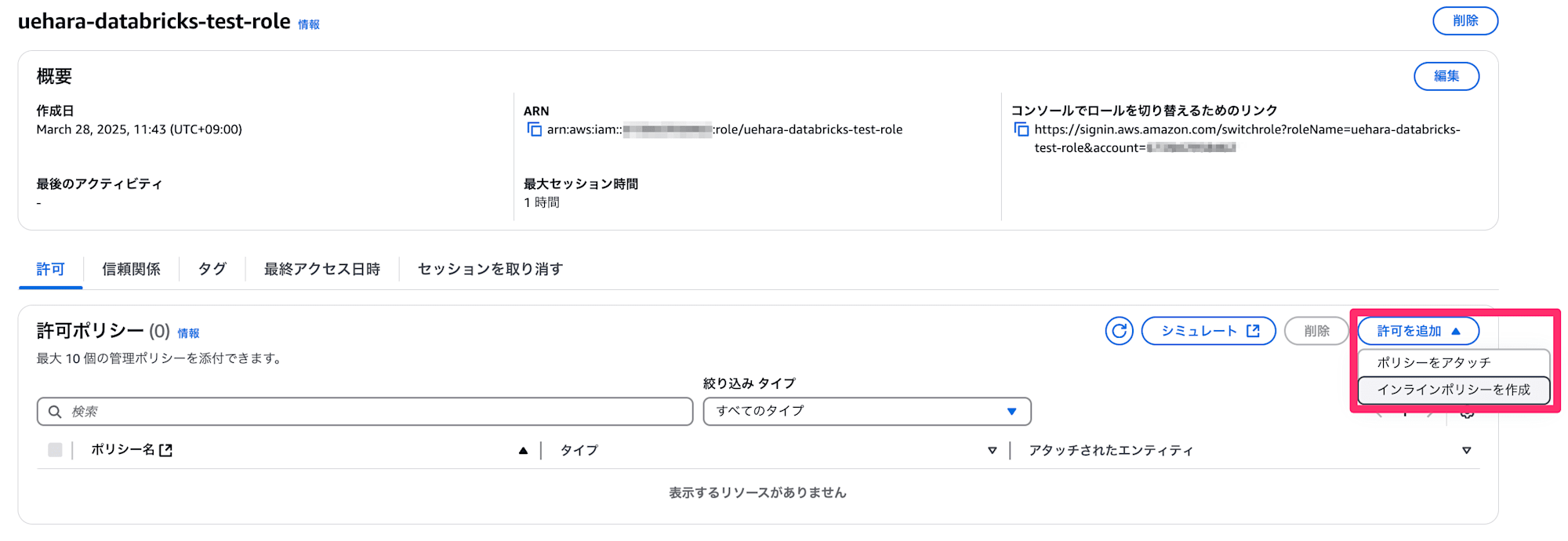
作成するポリシーは以下の通りです。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload"
],
"Resource": ["arn:aws:s3:::<BUCKET>/*", "arn:aws:s3:::<BUCKET>"],
"Effect": "Allow"
},
{
"Action": ["sts:AssumeRole"],
"Resource": ["arn:aws:iam::<AWS-ACCOUNT-ID>:role/<AWS-IAM-ROLE-NAME>"],
"Effect": "Allow"
}
]
}
プレースホルダにしている部分は以下を設定して下さい。
| 項目 | 設定値 |
|---|---|
<BUCKET> |
利用するS3バケットの名前 |
<AWS-ACCOUNT-ID> |
利用しているAWSアカウントのアカウントID |
<AWS-IAM-ROLE-NAME> |
上記で作成したIAMロールの名前 |
なお、今回使用するS3バケットの暗号化にはSSE-S3を利用している想定のため、KMSに関する記載は省略していますが、S3バケットの暗号化にKMSを利用している場合は当該KMSに対する "kms:Decrypt", "kms:Encrypt", "kms:GenerateDataKey*" 権限も付与して下さい。
次に、同じロールに対し以下のポリシーも作成してアタッチします。(※こちらのポリシーの追加は必須ではないのですが、Databricksでファイルイベントを構成する場合に必要となる権限であり、設定が推奨されているため一応この場で作成してアタッチしておきます)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ManagedFileEventsSetupStatement",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"s3:PutBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:SetTopicAttributes",
"sns:CreateTopic",
"sns:TagResource",
"sns:Publish",
"sns:Subscribe",
"sqs:CreateQueue",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:SetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": ["arn:aws:s3:::<BUCKET>", "arn:aws:sqs:*:*:csms-*", "arn:aws:sns:*:*:csms-*"]
},
{
"Sid": "ManagedFileEventsListStatement",
"Effect": "Allow",
"Action": ["sqs:ListQueues", "sqs:ListQueueTags", "sns:ListTopics"],
"Resource": ["arn:aws:sqs:*:*:csms-*", "arn:aws:sns:*:*:csms-*"]
},
{
"Sid": "ManagedFileEventsTeardownStatement",
"Effect": "Allow",
"Action": ["sns:Unsubscribe", "sns:DeleteTopic", "sqs:DeleteQueue"],
"Resource": ["arn:aws:sqs:*:*:csms-*", "arn:aws:sns:*:*:csms-*"]
}
]
}
<BUCKET> は先程のポリシーと同じ値を設定してください。
これでIAMロールの準備は完了です。
DatabricksでStorage Credentialの作成
Databricksにログインした後、左側のタブにある『Catalog』を選択します。
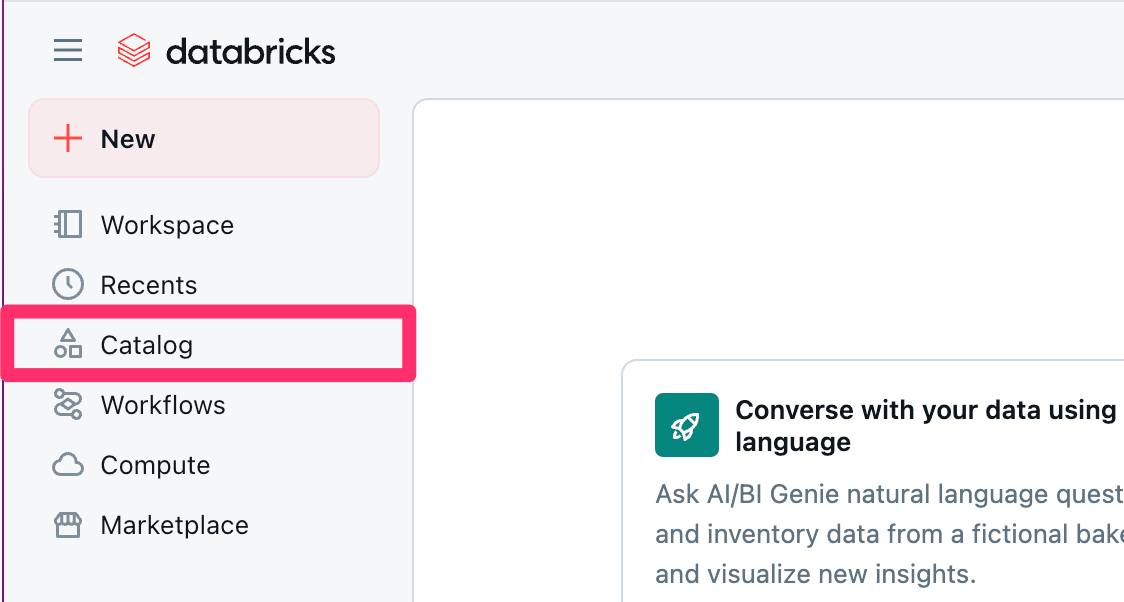
次に、歯車マークから『Credentials』を選択します。
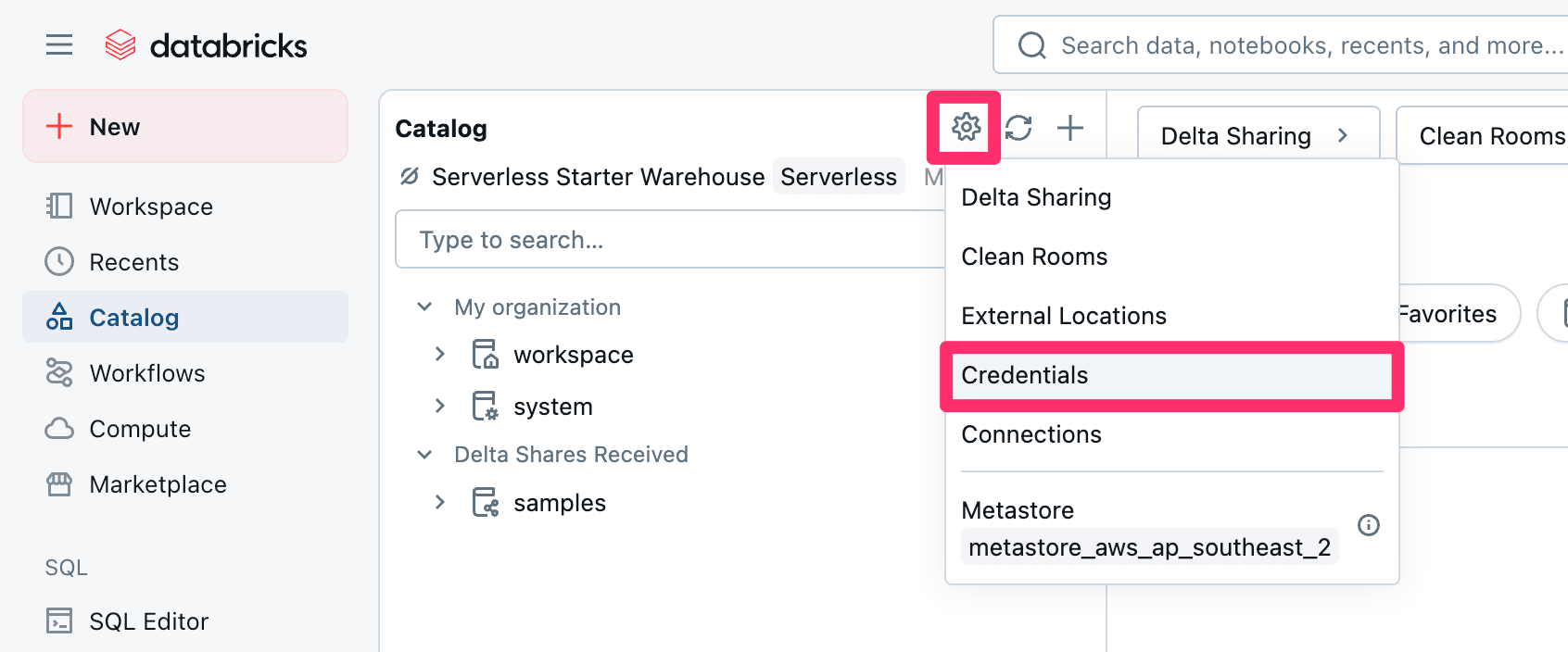
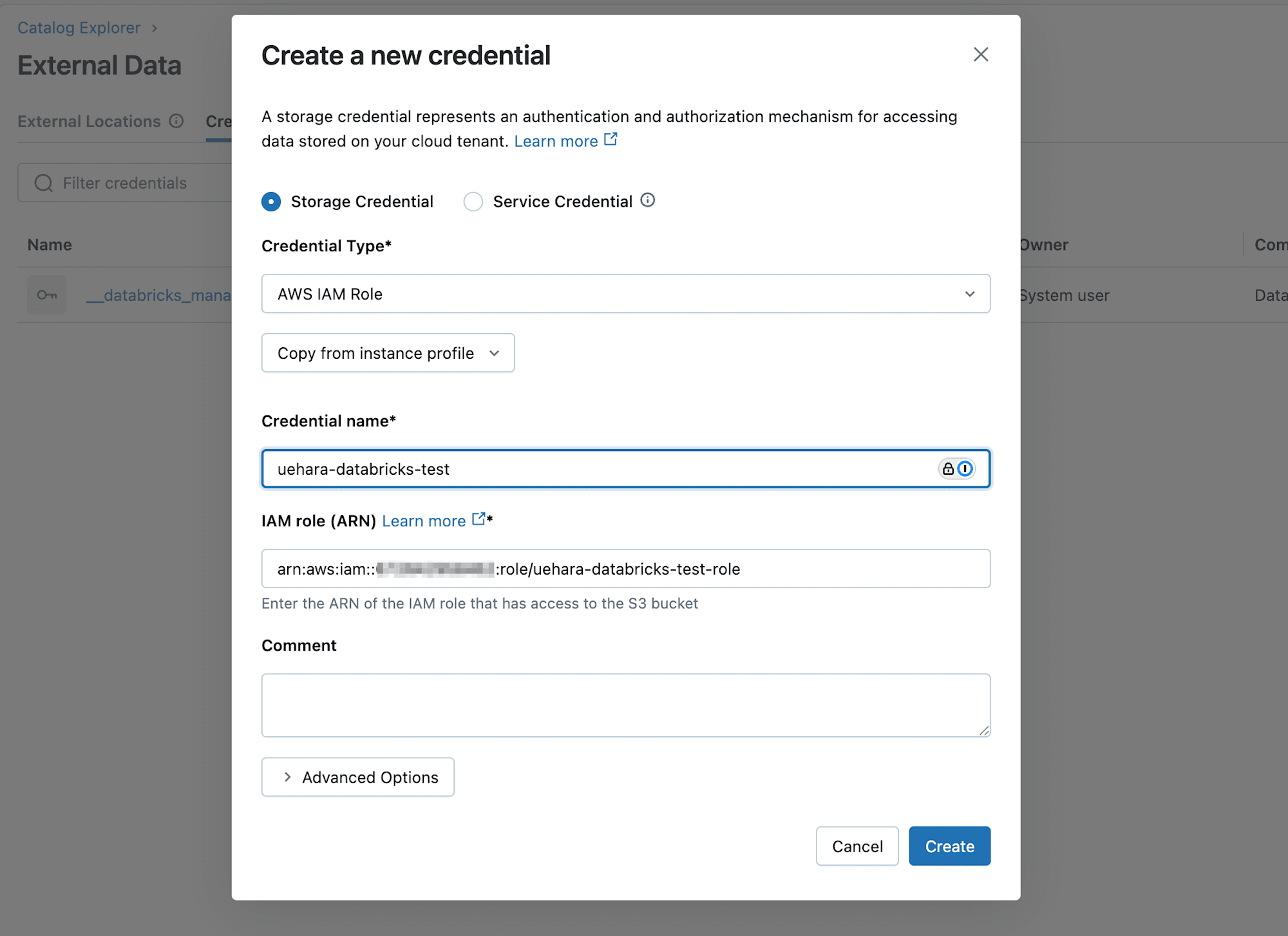
遷移したページから『Create Credential』を選択し、Storage Credentialを選択してCredential TypeはAWS IAM Roleを選択します。
Credential nameと先に作成したIAMロールのARNを設定してCreateを押します。
作成が完了すると、以下のようにIAMロールの信頼ポリシーを更新するようメッセージが表示されますので、External ID(外部ID)と信頼ポリシーを控えておいて下さい。
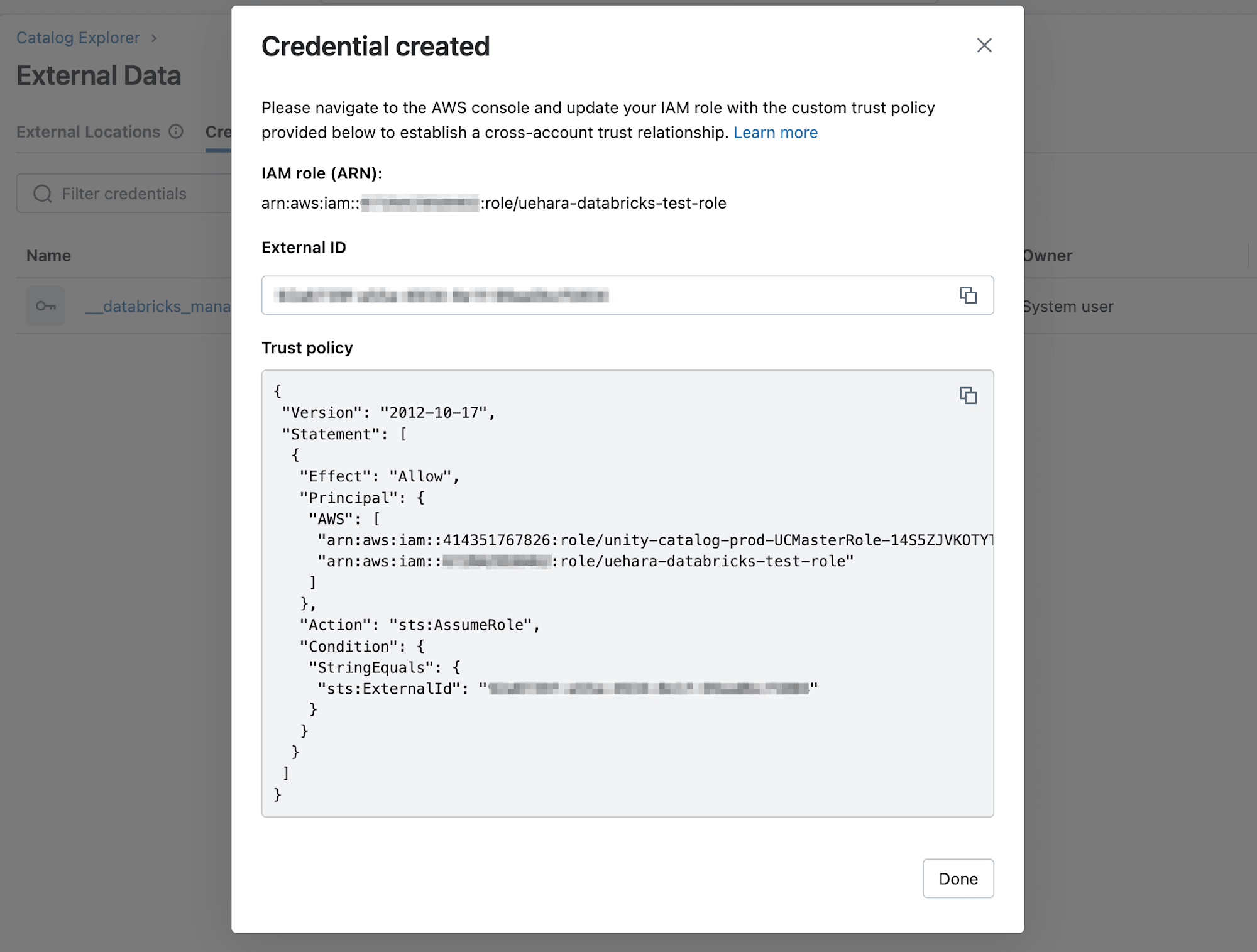
IAMロールの更新
DatabricksでCredentialを作成した際に表示された信頼ポリシーで、最初に作成したIAMロールの信頼ポリシーを更新します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL",
"arn:aws:iam::<AWS-ACCOUNT-ID>:role/<AWS-IAM-ROLE-NAME>"
]
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<EXTERNAL-ID>"
}
}
}
]
}
外部ロケーションの作成
Databricksのホーム画面に戻り、再度『Catalog』を選択し、歯車マークから今度は『External Locations』を選択します。
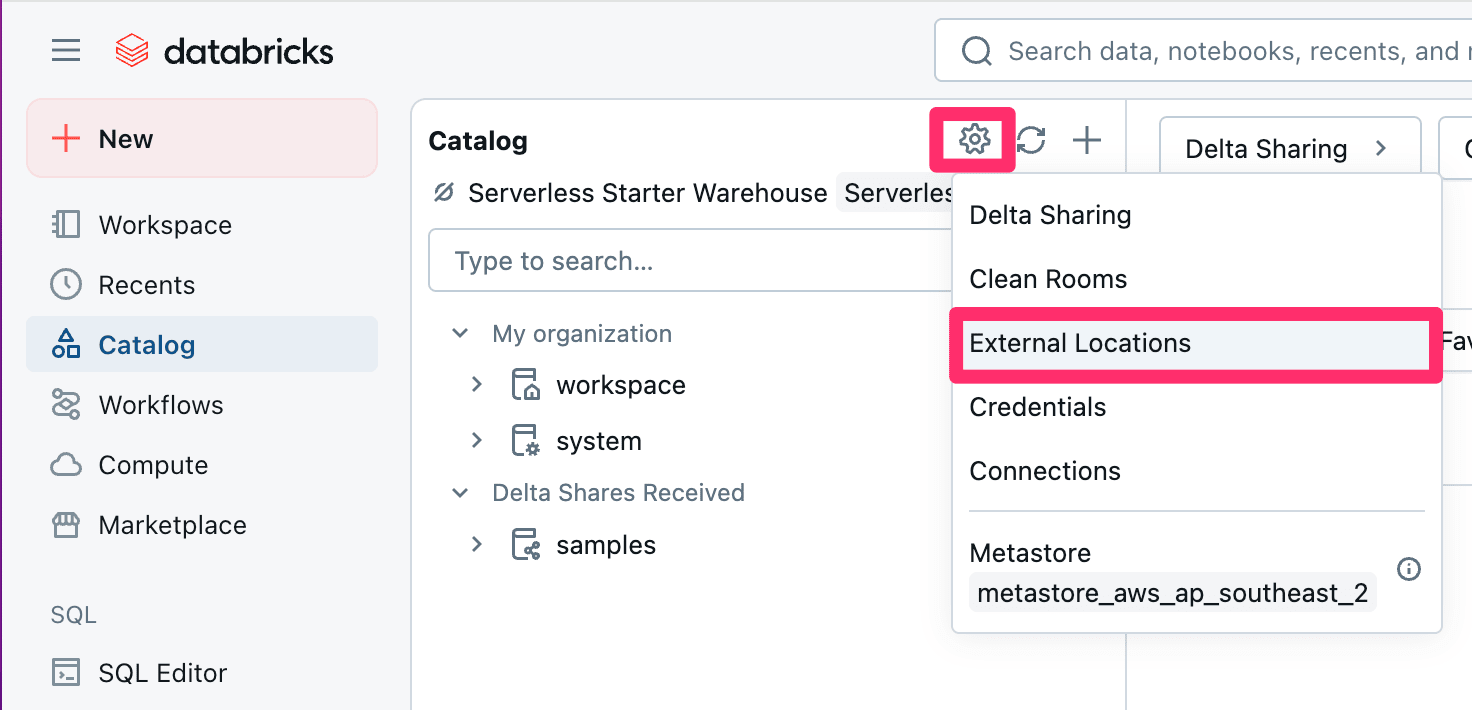
開いた画面で『Create external location』を押下します。
Storage Credentialを既に作成しているため、設定は『Manual』を選択します。
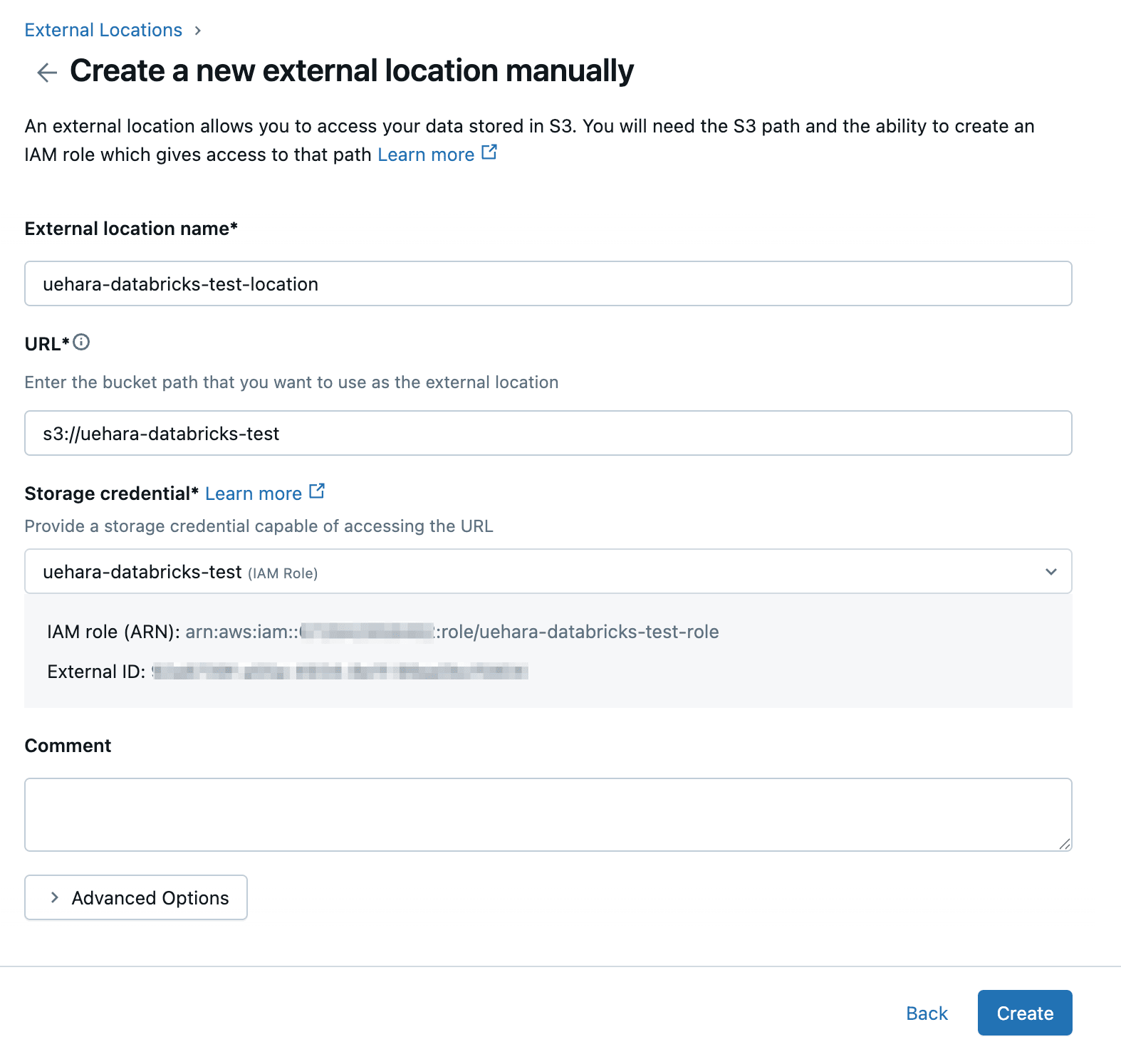
External location nameには任意の名前を設定し、対象のS3バケットのURLと作成したStorage credentialを選択し、『Create』を押します。
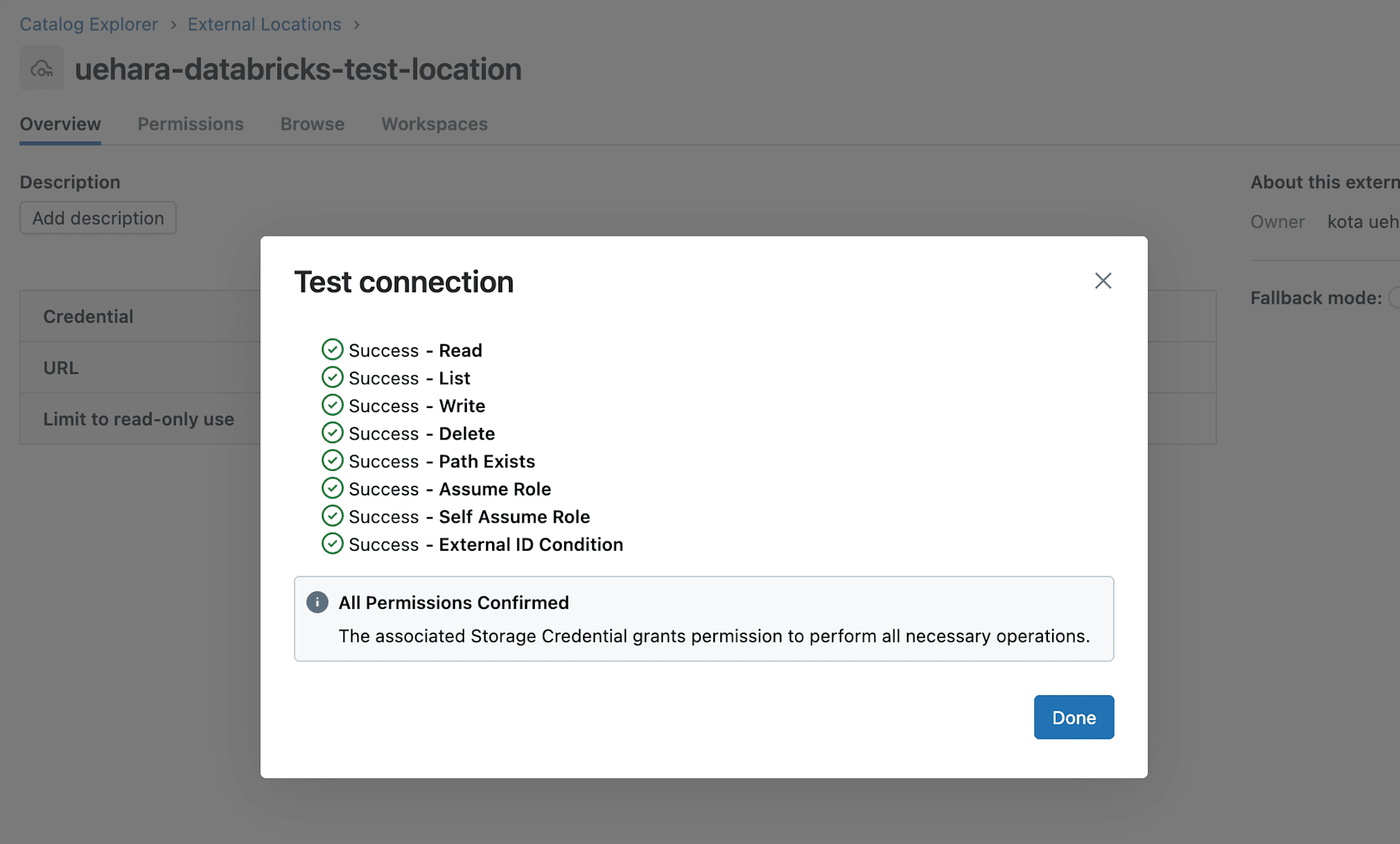
作成した外部ロケーションで『Test connection』を行い、以下のように表示されれば接続は成功です。
動作検証
S3にデータファイルを配置
ターゲットのS3に sample-data というパスを切り、その中で適当にHive形式でパーティションを切ります。
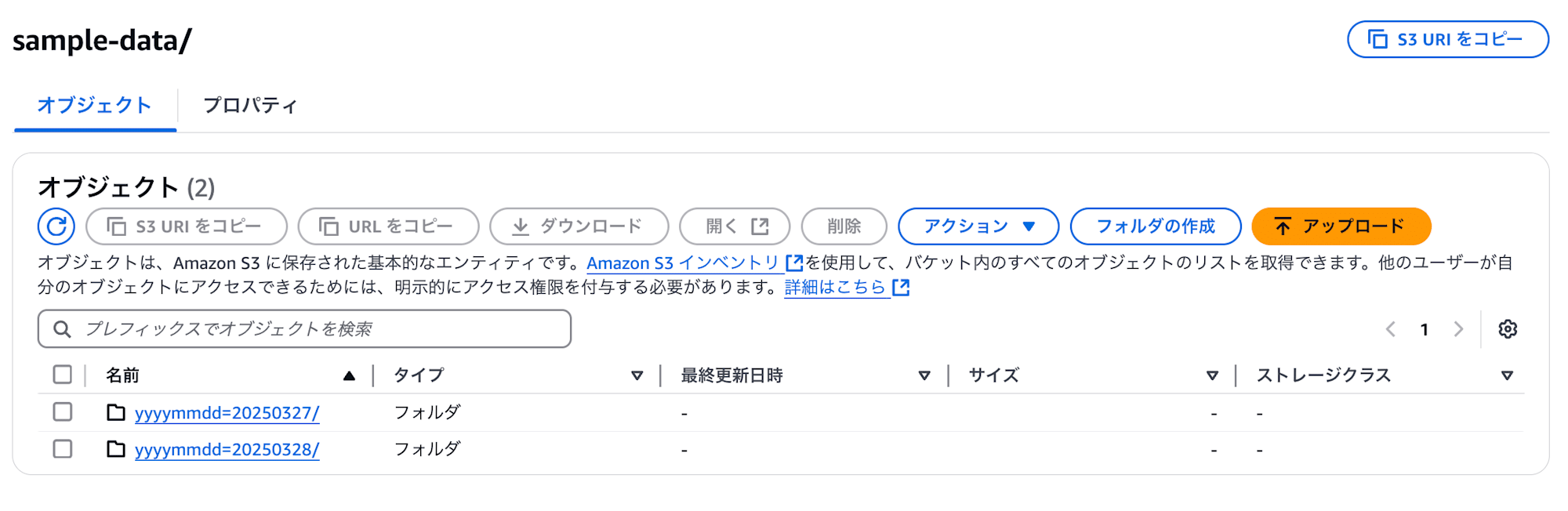
切ったパーティション内に、以下のようなデータ構造のparquetファイルを格納します。
{"id":1,"name":"Alice","score":90}
{"id":2,"name":"Bob","score":55}
テーブルの作成・確認
Databricksの左タブの『SQL Editor』を選択してクエリエディタを開いた後、以下のクエリを実行します。(以下はLOCATIONとして私のS3バケットのURLを指定しているため、ご自身の環境に合わせ変更して下さい)
CREATE EXTERNAL TABLE sample_data (
id BIGINT,
name STRING,
score BIGINT
)
USING PARQUET
PARTITIONED BY (yyyymmdd STRING)
LOCATION 's3://uehara-databricks-test/sample-data/';
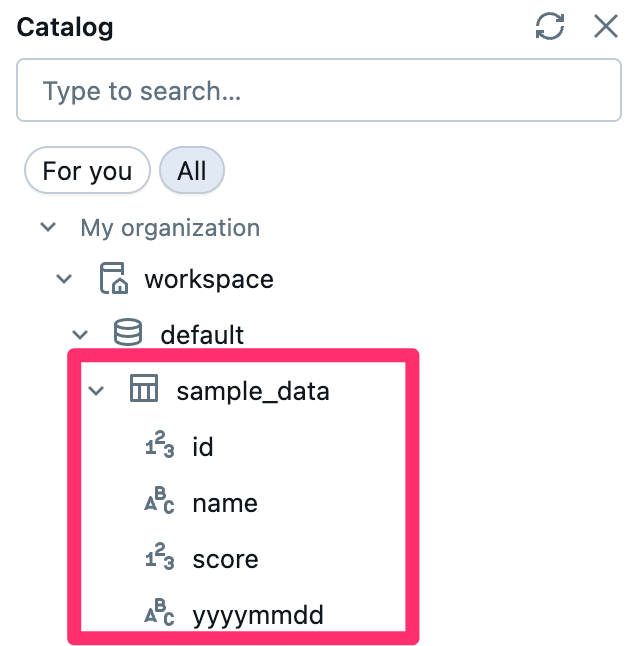
作成が成功すると、以下のようにCatalog配下に作成したテーブルが見れるようになっています。
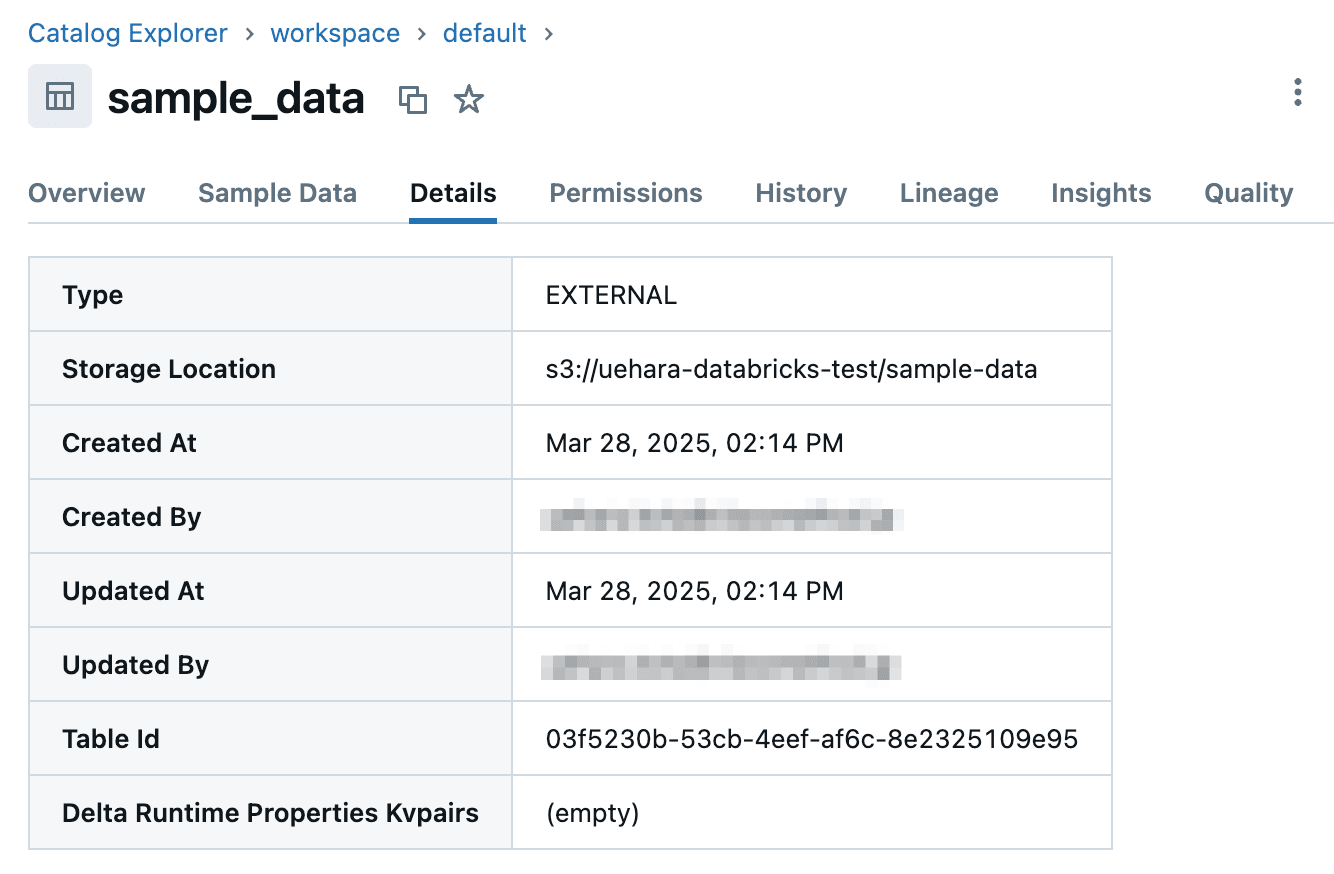
テーブルのプロパティを確認すると以下のようになっていました。
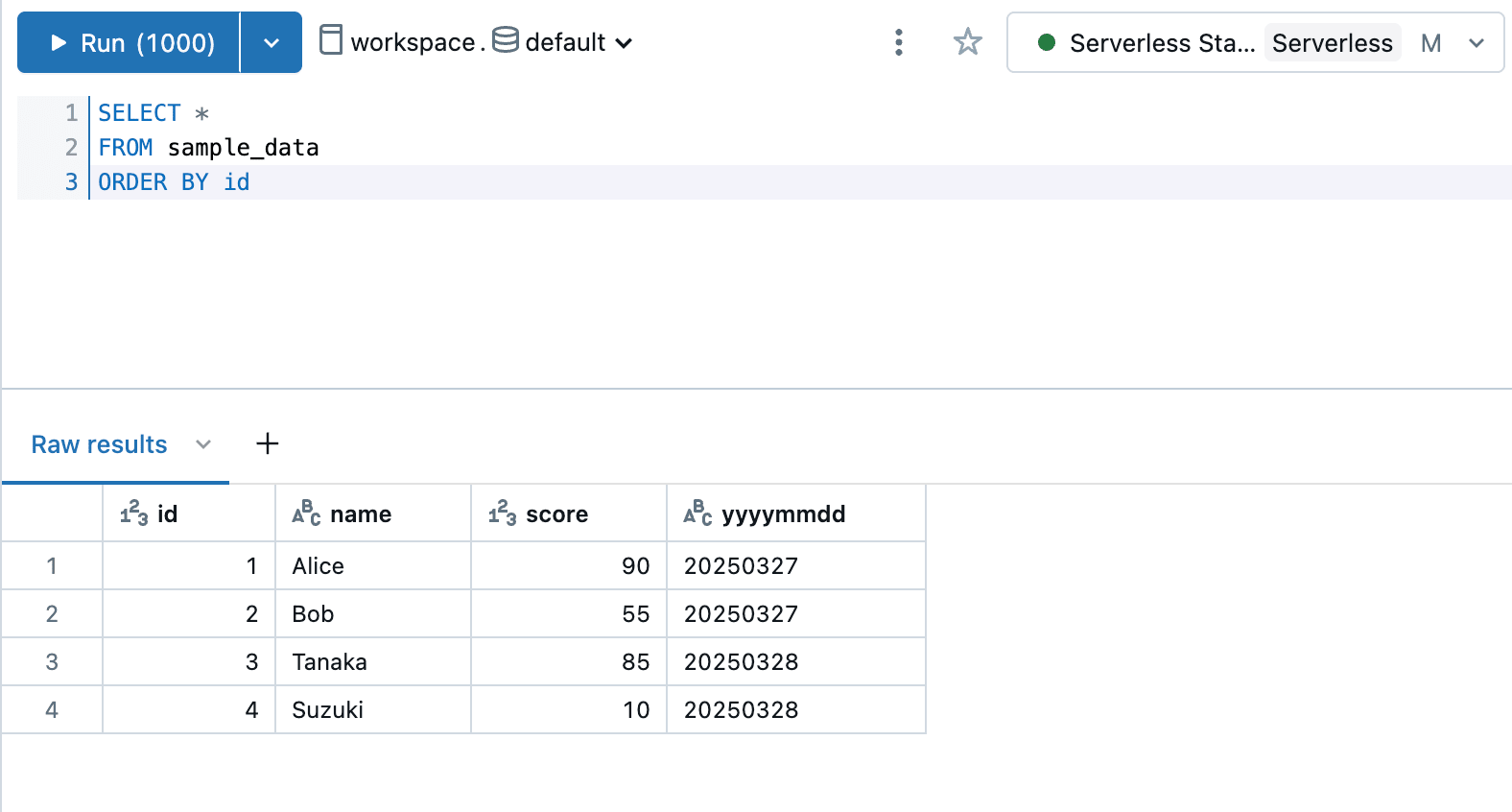
テーブルをSELECTして確認してみたところ、しっかりデータが表示できました。
最後に
今回は、DatabricksのUnity Catalogを利用してS3のデータを外部テーブルとして読み込んでみました。
参考になりましたら幸いです。










