
DatabricksのUnity Catalogを利用してS3にDelta Lakeを構築する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、DatabricksのUnity Catalogを利用してS3にDelta Lakeを構築してみたいと思います。
はじめに
先日、DatabricksのUnity Catalogを利用してS3にHive形式で格納しているParquetファイルを外部テーブルとして読み込むといった記事を公開しました。
今回は、それに引き続きDelta Lakeを構築したいと思います。
※上記記事で設定した、Databricks上でのStorage Credentialや外部ロケーションの設定が既に済んでいることを想定しています。
外部テーブルとして作成
前回、以下の通りS3にある既存のデータ(Hive形式で格納されたParquetファイル)に対し外部テーブルを作成しました。
CREATE EXTERNAL TABLE sample_data (
id BIGINT,
name STRING,
score BIGINT
)
USING PARQUET
PARTITIONED BY (yyyymmdd STRING)
LOCATION 's3://uehara-databricks-test/sample-data/';
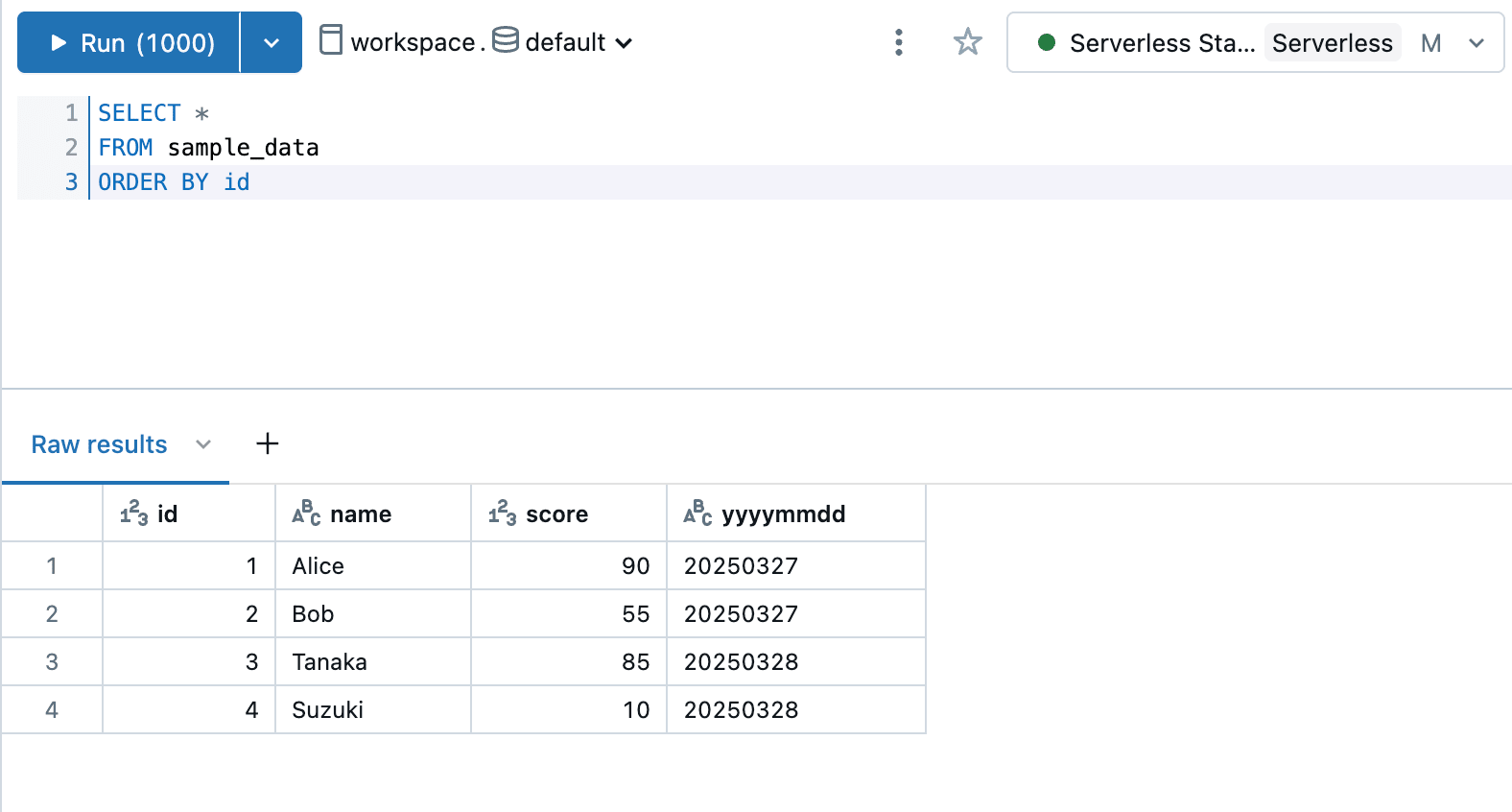
※データの中身は以下の通り
上記外部テーブルを利用して、新たにS3のパス s3://uehara-databricks-test/sample-data-delta/ に対し sample_data_delta という名前の外部テーブルをDelta形式で作成します。
CREATE TABLE sample_data_delta
USING DELTA
PARTITIONED BY (yyyymmdd)
LOCATION 's3://uehara-databricks-test/sample-data-delta/'
AS SELECT * FROM sample_data;
なお、今回CTASを利用してデータを複製(移行)しています。
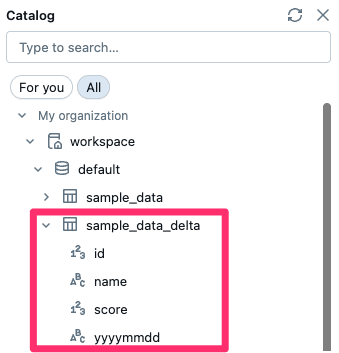
上記クエリを実行すると、以下の通りテーブルが作成できていることが確認できます。
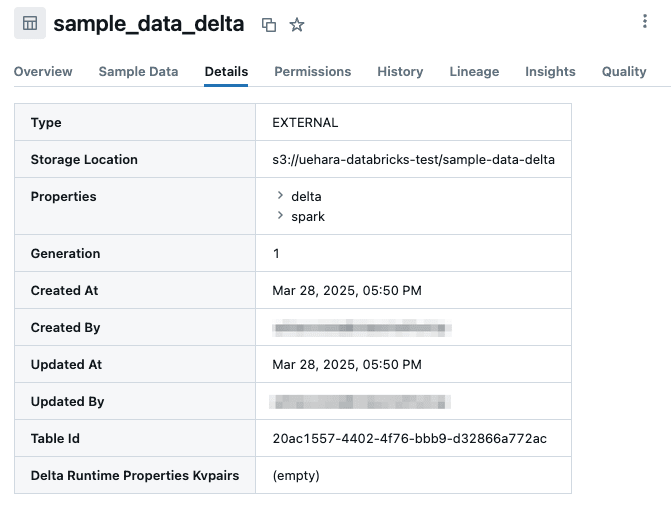
テーブルのプロパティは以下のようになっていました。
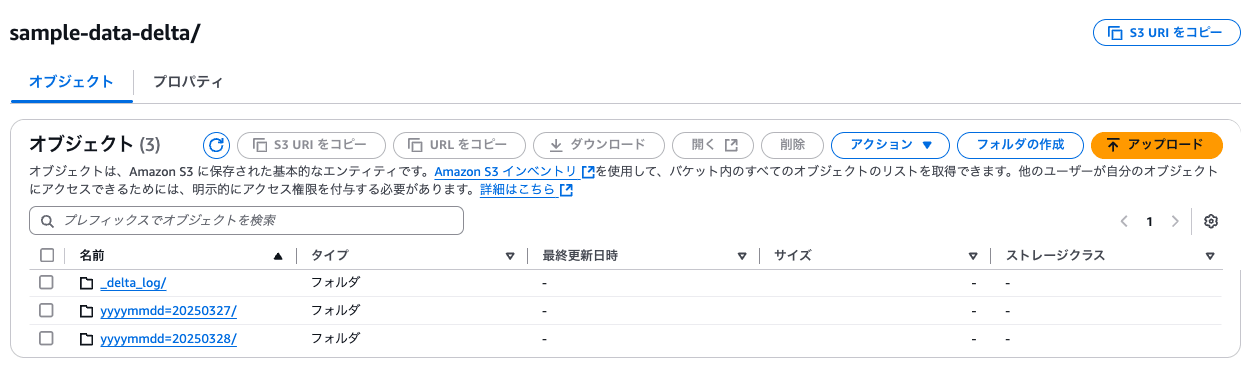
S3( s3://uehara-databricks-test/sample-data-delta/ )を確認すると、以下のようにDelta Lakeが構築されていることが分かります。
マネージドテーブルとして作成
先ほどは外部テーブルとしてDelta Lakeを構築しましたが、今度はマネージドテーブルとして作成してみます。
「マネージド」がどういうものかについては以下の記事をご参考下さい。
今回は以下のようにスキーマに対しマネージドストレージを設定してみます。(S3のパスはご自身の環境に合わせて適宜書き換えて下さい)
CREATE SCHEMA workspace.test_managed_schema
MANAGED LOCATION 's3://uehara-databricks-test/test_managed_schema';
作成が完了すると、以下のようにスキーマが追加されていると思います。
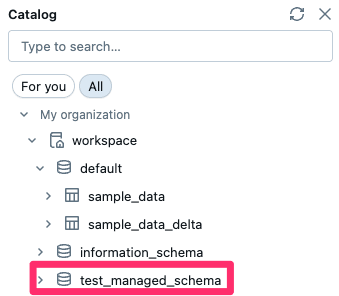
このスキーマを対象に、先程と同じように sample_data テーブルを利用してDelta形式でテーブルを作成します。
CREATE TABLE test_managed_schema.sample_data_delta
USING DELTA
PARTITIONED BY (yyyymmdd)
AS SELECT * FROM sample_data;
作成が完了すると、以下のように test_managed_schema スキーマ配下に作成したテーブルが確認できます。
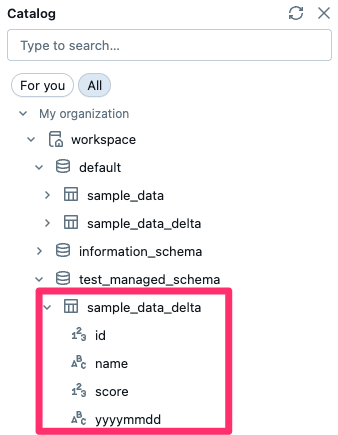
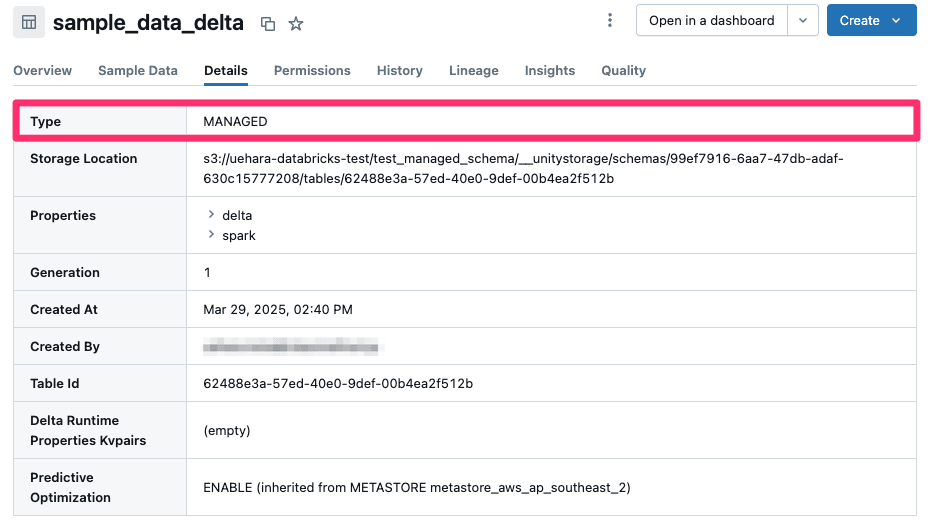
テーブルのプロパティを確認すると、先程作成した外部テーブルとは異なり Type が MANAGED になっていることが分かります。
PySparkを利用してアクセスしてみる
せっかくなので、作成したDelta Lakeに対しPySparkを利用してアクセスしてみたいと思います。
DatabricksのWorkspaceからNotebookを開きます。

Notebookが開いたら、以下の通り yyyymmdd における score の平均を計算するPythonスクリプトを実行してみます。
from pyspark.sql import functions as F
# テーブルの読み込み
df = spark.table("test_managed_schema.sample_data_delta")
# yyyymmddでグループ化し、scoreの平均を計算
result = df.groupBy("yyyymmdd") \
.agg(F.avg("score").alias("average_score")) \
.orderBy("yyyymmdd")
# 結果の表示
result.show()
上記を実行すると、以下の通り結果を確認することができました。

最後に
今回は、DatabricksのUnity Catalogを利用してS3にDelta Lakeを構築してみました。
参考になりましたら幸いです。









