
DatabricksのマネージドMCPサーバーを利用してみた
データ事業本部のueharaです。
今回は、DatabricksのマネージドMCPサーバーを利用してみたいと思います。
はじめに
先日、DatabricksからマネージドMCPサーバーが発表されました。
これまでもローカルでDatabricksのMCPサーバーを実装し利用する例はあったのですが、この度プラットフォーム側でマネージドなものが利用できるようになり、より簡単に利用できるようになりました。
提供されているMCPサーバー
提供されているMCPサーバーは以下の通りです。
| MCPサーバー | 説明 | URL |
|---|---|---|
| Vector search | 指定したUnity Catalogのスキーマのベクトル検索インデックスをクエリできる | https://<your-workspace-hostname>/api/2.0/mcp/vector-search/{catalog_name}/{schema_name} |
| Unity Catalog functions | 指定したUnity CatalogスキーマのUnity Catalog関数の実行ができる | https://<your-workspace-hostname>/api/2.0/mcp/functions/{catalog_name}/{schema_name} |
| Genie space | 指定したGenieスペースをクエリできる | https://<your-workspace-hostname>/api/2.0/mcp/genie/{genie_space_id} |
事前準備
記事執筆時点ではベータ版のため、機能有効化の設定から行います。
設定にアクセスするため、Databricksのプロフィールアイコンから『Previews』を選択します。

Previewsの一覧に『Managed MCP Servers』があると思うので、これをONにします。

これで事前準備は完了です。
MCPホスト(クライアント)の作成、設定
マネージドMCPサーバーを利用する設定は済んだので、MCPホスト(クライアント)側の作成や設定を行います。
Databricksの認証設定
OAuthを使用してワークスペースへの認証を行います。
※Databricks CLIが必要になるので、インストールがまだの方はこちらを参考にインストールして下さい。
$ databricks auth login --host https://<your-workspace-hostname>
認証時にプロファイル名の指定を求められるので、任意に設定して下さい。(こちらのプロファイル名は後で利用するので控えておいて下さい)

認証が完了するとブラウザに以下のような画面が表示されるかと思います。

ライブラリのインストール
以下コマンドで、後段のプログラムに必要なDatabricks関連ライブラリをインストールします。
$ pip install -U --pre databricks-mcp "mcp>=1.9" databricks-sdk databricks-agents
クライアントスクリプトの作成
以下のようなスクリプトを作成してみました。
LLMはAmazon Bedrockで Claude 3.7 Sonnet を利用するようにしています。
import asyncio
import json
from contextlib import asynccontextmanager
from typing import Any, Dict, List, Optional
import boto3
from databricks.sdk import WorkspaceClient
from databricks_mcp import DatabricksOAuthClientProvider
from mcp.client.session import ClientSession
from mcp.client.streamable_http import streamablehttp_client
class BedrockMCPAgent:
"""
Databricks MCPサーバーをツールとして利用するBedrock Agent。
BedrockのConverse APIを使用して、ツール利用を含む対話を行う。
"""
def __init__(
self,
databricks_profile: str,
mcp_server_url: Optional[str] = None,
bedrock_model_id: str = "apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
aws_region: str = "ap-northeast-1",
):
self.workspace_client = WorkspaceClient(profile=databricks_profile)
self.host = self.workspace_client.config.host
self.mcp_server_url = (
mcp_server_url or "{host}/api/2.0/mcp/functions/system/ai"
).format(host=self.host)
self.bedrock_client = boto3.client("bedrock-runtime", region_name=aws_region)
self.bedrock_model_id = bedrock_model_id
@asynccontextmanager
async def _mcp_session(self):
"""MCPサーバーとのセッションを非同期で確立"""
async with streamablehttp_client(
url=self.mcp_server_url,
auth=DatabricksOAuthClientProvider(self.workspace_client),
) as (reader, writer, _):
async with ClientSession(reader, writer) as session:
await session.initialize()
yield session
async def _list_mcp_tools(self) -> List[Dict]:
"""MCPサーバーから利用可能なツールを取得し、Bedrockの形式に変換"""
async with self._mcp_session() as session:
tools_response = await session.list_tools()
return [
{
"toolSpec": {
"name": tool.name,
"description": tool.description,
"inputSchema": {"json": tool.inputSchema},
}
}
for tool in tools_response.tools
]
async def _call_mcp_tool(self, tool_name: str, parameters: Dict[str, Any]) -> str:
"""指定されたMCPツールを非同期で実行"""
print(f"--- MCP Tool Call ---")
print(f"Tool: {tool_name}")
# デバッグ用
# print(f"Arguments: {json.dumps(parameters, indent=2)}")
try:
async with self._mcp_session() as session:
response = await session.call_tool(name=tool_name, arguments=parameters)
result = "".join([content.text for content in response.content])
# デバッグ用
# print(f"Result: {result}")
print(f"-----------------------")
return result
except Exception as e:
error_message = f"Error calling MCP tool {tool_name}: {str(e)}"
print(error_message)
return error_message
async def chat(self, user_input: str, session_id: str = "local-session") -> Dict:
"""
Converse APIを使用してチャットを実行する。
ツール利用が必要な場合は、複数回のAPI呼び出しを自動的に行う。
"""
instruction = """あなたはDatabricksのMCPツールを使用できるAIアシスタントです。
ユーザーの質問に対して、必要であれば利用可能なツールを判断して使用し、その結果に基づいて回答してください。
ツールの実行結果はユーザーに直接見せず、結果を解釈して自然な文章で回答を生成してください。"""
try:
# 利用可能なツールリストを取得
mcp_tools = await self._list_mcp_tools()
tool_config = {"tools": mcp_tools}
# 対話履歴の初期化
messages = [{"role": "user", "content": [{"text": user_input}]}]
# ツール呼び出しのループ
final_response_text = ""
tool_calls_executed = []
while True:
# boto3のAPIを非同期で呼び出す
response = await asyncio.to_thread(
self.bedrock_client.converse,
modelId=self.bedrock_model_id,
messages=messages,
system=[{"text": instruction}],
toolConfig=tool_config,
)
model_message = response["output"]["message"]
# モデルの応答を履歴に追加
messages.append(model_message)
# 応答からテキスト部分とツール呼び出し部分を分離
text_content = "".join(
[c["text"] for c in model_message["content"] if "text" in c]
)
tool_use_requests = [
c["toolUse"] for c in model_message["content"] if "toolUse" in c
]
if text_content:
final_response_text += text_content
# ツール呼び出しがなければループを終了
if not tool_use_requests:
break
# ツール実行
tool_results = []
for tool_request in tool_use_requests:
tool_name = tool_request["name"]
tool_input = tool_request["input"]
tool_use_id = tool_request["toolUseId"]
# MCPツールを呼び出す
tool_result_str = await self._call_mcp_tool(tool_name, tool_input)
# Bedrockに返すための結果を作成
tool_results.append(
{
"toolResult": {
"toolUseId": tool_use_id,
"content": [{"text": tool_result_str}],
}
}
)
tool_calls_executed.append(
{
"tool_name": tool_name,
"input": tool_input,
"result": tool_result_str,
}
)
# ツール実行結果を履歴に追加して、次の対話の入力とする
messages.append({"role": "user", "content": tool_results})
return {
"response": final_response_text,
"tool_calls": tool_calls_executed,
"session_id": session_id,
}
except Exception as e:
return {"error": str(e), "session_id": session_id}
async def main():
# 設定
DATABRICKS_PROFILE = "<YOUR_DATABRICKS_CLI_PROFILE>" # Databricksのプロファイル名
try:
agent = BedrockMCPAgent(
databricks_profile=DATABRICKS_PROFILE
)
print("Bedrock MCP Agent を起動しました")
print("利用可能なMCPツールを確認中...")
tools = await agent._list_mcp_tools()
if not tools:
print("利用可能なMCPツールが見つかりませんでした。DatabricksのMCPサーバーの設定を確認してください。")
return
print(f"{len(tools)} 個のツールが利用可能です:")
for tool in tools:
spec = tool["toolSpec"]
print(f" - {spec['name']}: {spec['description']}")
except Exception as e:
print(f"\n[エラー] エージェントの初期化に失敗しました: {e}")
print("Databricksのプロファイル設定 (`~/.databrickscfg`) やMCPサーバーのURLが正しいか確認してください。")
return
print("\nチャットを開始します (終了するには 'quit' と入力)")
print("-" * 50)
session_id = f"local-session-{int(asyncio.get_event_loop().time())}"
while True:
try:
user_input = input("\nYou: ").strip()
if user_input.lower() in ["quit", "exit", "q"]:
break
if not user_input:
continue
print("Assistant: (考え中...)")
result = await agent.chat(user_input, session_id)
if "error" in result:
print(f"\n[エラー]: {result['error']}")
else:
print(f"\nAssistant: {result['response']}")
if result["tool_calls"]:
print("\n[使用されたツール]")
for i, call in enumerate(result["tool_calls"], 1):
print(f" {i}. {call['tool_name']}")
except KeyboardInterrupt:
print("\n\nチャットを中断しました。")
break
except Exception as e:
print(f"\n[予期しないエラー]: {e}")
if __name__ == "__main__":
try:
asyncio.run(main())
except Exception as e:
print(f"プログラムの実行中にエラーが発生しました: {e}")
<YOUR_DATABRICKS_CLI_PROFILE> には、前述の手順で作成したプロファイル名を指定して下さい。
また、MCPサーバーのURLのデフォルト値は公式ドキュメントのサンプルと同様に {host}/api/2.0/mcp/functions/system/ai としています。
Databricksには system.ai.python_exec というPythonコードを動的に利用できる組み込みUnity Catalog関数があるため、特にMCPサーバーのURLが指定されていない場合は上記を利用するためのMCPサーバーにアクセスするようなイメージです。
実行してみた
以下のコマンドで作成したクライアントスクリプトを実行します。
$ python databricks_mcp_test.py
実行すると以下のような画面が表示されます。
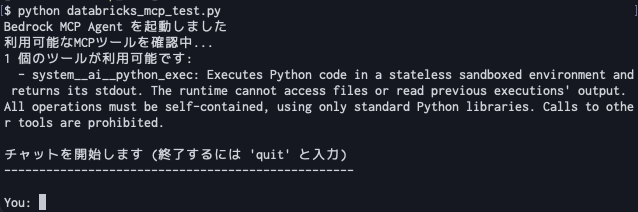
ツールとして、想定通り system__ai__python_exec が利用できることが伺えます。
説明から、Pythonはサンドボックス環境で実行されファイル等にはアクセスできないようなので、適当にFizzBuzzを解いてもらいます。
You: FizzBuzzを15まで実行して下さい。
結果は以下の通りで、 system__ai__python_exec を利用してFizzBuzzを解いてくれました。

他にも試してみます。
私の手元環境にはMovieLensというデータセットをテーブル化し、それを参照するGenieスペースがあります。

先のクライアントスクリプトを修正し、このGenieスペースにアクセスするよう設定します。( <GENIE_SPACE_ID> は要置き換え)
agent = BedrockMCPAgent(
databricks_profile=DATABRICKS_PROFILE,
mcp_server_url="{host}/api/2.0/mcp/genie/<GENIE_SPACE_ID>",
)
これを実行すると以下のように出力されました。
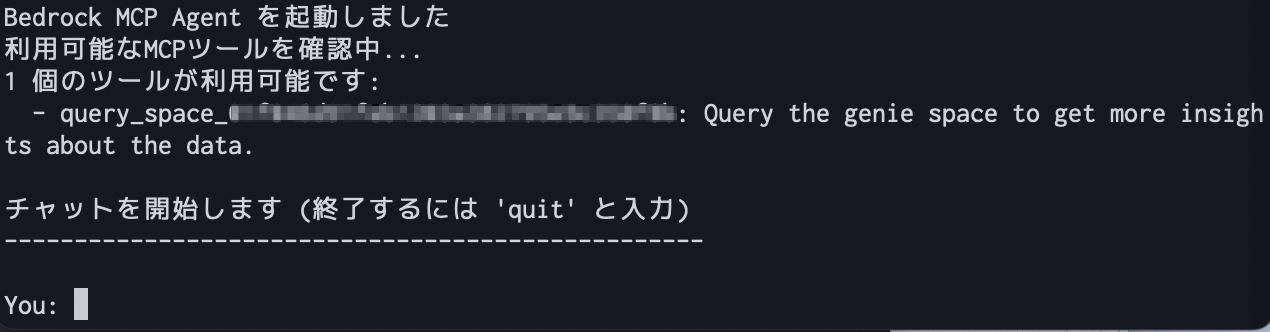
query_space_{genie_space_id} というツールが利用できるようで、これによりスペースにクエリできるようです。
以下のように指定してみました。
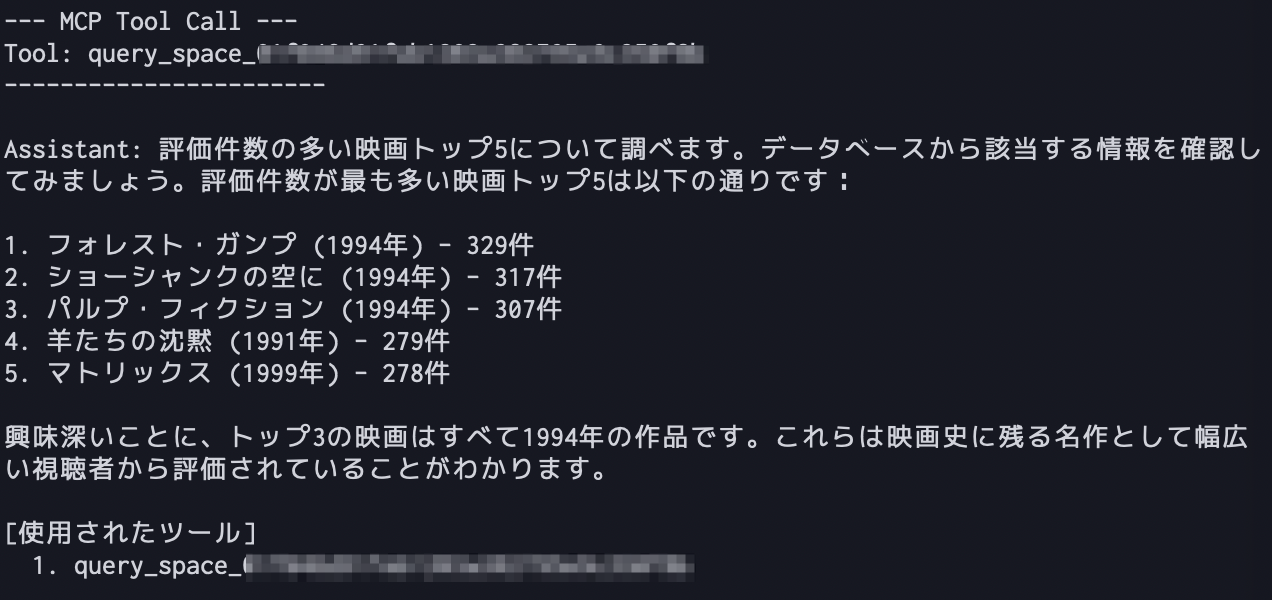
You: 評価件数の多い映画トップ5を教えて
出力結果は次の通りで、データにアクセスできていることが確認できました。
最後に
今回は、DatabricksのマネージドMCPサーバーを利用してみました。
MCPサーバーはDatabricksによってホストおよび保守されるため、簡単に接続を始められて良いなと感じました。
独自のカスタムまたはサードパーティのMCPサーバーをDatabricks Appsとしてホストすることもできるので、気になった方は公式ドキュメントをご確認下さい。
参考になりましたら幸いです。










