
NeMo Agent Toolkit を DGX Spark + vLLM のローカル構成で動かしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
NVIDIA NeMo Agent Toolkit(パッケージ名 nvidia-nat、旧 AIQ Toolkit / Agent Intelligence Toolkit)は、LangChain や CrewAI などの既存エージェントフレームワークを横串で包んで観測・評価・最適化するメタレイヤー型のツールキットです。NIM・NeMo Guardrails・NemoClaw との統合を前提に作られています。
公式チュートリアルは NIM の API キー前提で書かれているものが多く、日本語の入門記事も同様にクラウド推論を使うものが中心です。本記事では DGX Spark の上で NGC vLLM コンテナ + Nemotron 3 Nano 30B-A3B-FP8 をバックエンドにして、エージェント実行・OpenTelemetry 観測・MCP サーバー化までを「クラウド NIM API なし」で完結させる手順を残しておきます。
NeMo Agent Toolkit
最初に押さえておきたいのは、NeMo Agent Toolkit が「もう 1 つのエージェントフレームワーク」ではないという点です。LangChain・LangGraph・CrewAI・Semantic Kernel・Google ADK などを optional extras で取り込み、その上に観測・評価・最適化のメタレイヤーを被せる構造になっています。
開発者が書くのは基本的に workflow.yml だけで、functions / llms / embedders / workflow の 4 セクションに何をぶら下げるかを宣言します。_type フィールドで実装を切り替える素直な DSL なので、NIM から vLLM への載せ替えも数行の差し替えで済みます。
旧名称(Agent Intelligence Toolkit / AIQ Toolkit)からの正式リブランドは 2025 年 6 月で、コア技術とロードマップは引き継がれています。後方互換パッケージとして aiqtoolkit / agentiq が残っていますが、将来削除予定なので新規導入では nvidia-nat を使います。
主要機能一覧
ファーストステップ記事の趣旨で、まずは何が入っているかを表で並べます。
| カテゴリ | 機能 | 概要 |
|---|---|---|
| ワークフロー定義 | YAML 宣言型 | _type で関数・LLM・ワークフローを差し替え |
| エージェント | react_agent ほか |
ReAct / ReWOO / Tool-Calling / Router |
| LLM プロバイダ | _type: nim / openai / bedrock / litellm / huggingface ほか |
OpenAI 互換ならローカル推論サーバーも同じ口で接続 |
| 既存フレームワーク統合 | LangChain / LangGraph / CrewAI / Semantic Kernel / Google ADK / Strands / AutoGen | optional extras で取り込み |
| 観測 | OpenTelemetry ネイティブ | LangSmith / Phoenix / Langfuse / OTel Collector に直送 |
| 評価 | nat eval |
JSONL / CSV / Parquet データセットでバッチ評価 |
| 最適化 | プロンプト・ハイパラ自動チューニング | 遺伝的アルゴリズムベースの Optimizer |
| プロトコル | MCP(クライアント / サーバー)/ A2A | 自分のワークフローを MCP サーバーとして公開可能 |
| 高速化 | Agent Performance Primitives / Dynamo Runtime | LangGraph・CrewAI グラフを並列・投機実行 |
| セキュリティ | PII 防御・プロンプトインジェクション対策ミドルウェア | Red Teaming 機能も同梱 |
「LangChain で書いたエージェントの観測だけ NAT に任せる」「CrewAI のフローを評価駆動で最適化する」といったメタレイヤー的な使い方が想定されています。
DGX Spark で動かす場合の論点
公式チュートリアルは _type: nim で model_name: meta/llama-3.1-70b-instruct を NIM API 経由で呼び出す例から始まります。検証用にはこれが最短ですが、現場での利用を見据えるとローカル推論で完結したいという場面も出てきます。
NeMo Agent Toolkit 側からは、NIM だろうが vLLM だろうが Ollama だろうが、最終的に OpenAI 互換 API として叩ける限り _type: openai + base_url で同じように接続できます。バックエンドの差し替えが config 1 行なのも、エージェント基盤として NAT を選ぶ理由のひとつです。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark(GB10, ARM64, 128GB UMA) |
| OS | Ubuntu 24.04 ARM64 |
| CUDA Toolkit | 13.0 |
| コンテナ | NGC nvcr.io/nvidia/vllm:26.01-py3 / arizephoenix/phoenix:14.8.0 |
| Python | 3.12.12(uv venv) |
| パッケージ | nvidia-nat==1.6.0(extras: langchain, mcp) |
| LLM | nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 |
インストールとハマりポイント
nvidia-nat 本体は pure Python の wheel で配布されているので、ARM64 でも追加コンパイルなしで入ります。uv で venv を切ってから入れる流れがいちばん素直です。
mkdir -p ~/works/nemo-agent-toolkit && cd ~/works/nemo-agent-toolkit
uv venv --python 3.12
source .venv/bin/activate
uv pip install 'nvidia-nat[langchain,mcp]'
nat --version
# nat, version 1.6.0
extras には langchain / crewai / mcp / eval / opentelemetry / langsmith / phoenix などが用意されています。今回は「ローカル LLM で ReAct + MCP + 観測」を目指しているので langchain と mcp だけ指定しました。実際にインストール後の nat info components を眺めると、nvidia-nat-eval と nvidia-nat-opentelemetry も依存解決のなかで一緒に入っています。入門用途では追加指定なしで先に進めてしまって良さそうです。
vLLM ローカル推論で Hello World
vLLM コンテナを起動する
DGX Spark Playbook の手順をベースに、--trust-remote-code を 1 行足したものが今回の起動コマンドです。Nemotron 3 Nano は nemotron_h(Mamba と Transformer のハイブリッド)アーキテクチャで、HF transformers の標準実装ではなくリポジトリ同梱のカスタムコードを必要とするため、このフラグなしでは pydantic ValidationError で API Server 起動前に落ちます。
docker run -d \
--name vllm-nat \
--gpus all \
--shm-size=16g \
-p 8000:8000 \
-v "$HOME/.cache/huggingface:/root/.cache/huggingface" \
nvcr.io/nvidia/vllm:26.01-py3 \
vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--trust-remote-code \
--max-model-len 8192 \
--gpu-memory-utilization 0.85
モデルロードは 30.5 GiB / 約 4 分、torch.compile が約 2 分、その後 KV cache が 34.79 GiB 確保されて 8K コンテキストで 362x まで並列を捌ける構成になりました。
/v1/models を叩いて生きていることを確認します。
curl -s http://localhost:8000/v1/models | python3 -m json.tool
nat workflow create でひな形を生成する
NAT にはプロジェクトのひな形を生成する nat workflow create コマンドが同梱されています。ここから入るのが公式フローです。
mkdir -p workflows
nat workflow create --no-install --workflow-dir ./workflows hello_local \
--description "Hello world workflow"
生成物は Python パッケージの形をしていて、src/hello_local/ 以下にカスタム関数と登録コード、configs/config.yml に NAT の宣言型ワークフロー定義が置かれます。
workflows/hello_local/
├── pyproject.toml
└── src/hello_local/
├── hello_local.py # カスタムツールの実装サンプル
├── register.py # NAT Type Registry への登録
└── configs/config.yml # ワークフロー定義
デフォルトの config.yml は NIM 前提で Llama 3.1 70B Instruct を呼び出す構成になっています。
functions:
current_datetime:
_type: current_datetime
hello_local:
_type: hello_local
prefix: 'Hello:'
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, hello_local]
ローカル vLLM 向けに書き換える
今回は DGX Spark の vLLM で動かしたいので、llms セクションの _type: nim を _type: openai + base_url に差し替えます。紹介として Hello World に絞るため、カスタムツール(hello_local)は使わず組み込みの current_datetime だけで動かす構成に寄せました。ファイルも扱いやすいようにプロジェクトルート直下の workflow.yml に置き換えて使います。
functions:
current_datetime:
_type: current_datetime
llms:
local_vllm:
_type: openai
base_url: http://localhost:8000/v1
api_key: EMPTY
model_name: nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8
temperature: 0.0
workflow:
_type: react_agent
llm_name: local_vllm
tool_names: [current_datetime]
verbose: true
api_key は vLLM 側で要求していないのでダミー文字列で構いません。フィールドごと省略するとバリデーションで弾かれるので、EMPTY のような文字列を入れておきます。
nat run で叩いてみる
nat run --config_file workflow.yml --input "今の日時を教えてください。日本語で回答してください。"
実行すると、ReAct Agent が思考 → ツール呼び出し → 最終回答という流れを 1 サイクル回してくれます。
[AGENT]
Agent's thoughts:
Question: 今の日時を教えてください。日本語で回答してください。
Thought: I need to obtain the current date and time and then present it in Japanese.
Action: current_datetime
Action Input: None
------------------------------
Calling tools: current_datetime
Tool's response:
The current time of day is 2026-04-19 07:01:43 +0000
------------------------------
Agent's thoughts:
Thought: I now know the final answer
Final Answer: 現在の日時は 2026年4月19日 07:01:43(UTC)です。
ReAct テンプレートは英語で組まれているので思考過程は英語ですが、ユーザー指示が日本語の場合は最終回答を日本語で返してくれます。1 クエリあたりの推論レイテンシは ReAct + 1 ツール呼び出しで体感 13 秒前後で、ローカル推論としては許容できる範囲でした。
nat serve を使うと同じ workflow.yml をそのまま FastAPI サーバーとして公開できるので、社内 PoC で「コマンドラインから API へ」と橋渡ししたい場面でも書き直しがほぼ発生しません。
既存フレームワークを観測する(Phoenix 連携)
NeMo Agent Toolkit の旨味のひとつが、OpenTelemetry ベースの観測層を設定 1 ブロックで追加できる点です。general.telemetry.tracing 配下に exporter を宣言するだけで、ReAct Agent の各ステップ・LLM 呼び出し・ツール実行が span として吐き出されます。
今回は手軽にデータを眺められる選択肢として、Arize Phoenix をローカルに立ててみます。
docker run -d --name phoenix-nat \
-p 6006:6006 -p 4317:4317 \
arizephoenix/phoenix:latest
NAT 標準の汎用 OTLP exporter(_type: otelcollector)を使い、Phoenix の OTLP HTTP エンドポイント /v1/traces に向けます。
general:
telemetry:
tracing:
phoenix:
_type: otelcollector
endpoint: http://localhost:6006/v1/traces
project: nat-hello-local
functions:
current_datetime:
_type: current_datetime
llms:
local_vllm:
_type: openai
base_url: http://localhost:8000/v1
api_key: EMPTY
model_name: nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8
temperature: 0.0
workflow:
_type: react_agent
llm_name: local_vllm
tool_names: [current_datetime]
verbose: true
この状態でもう一度 nat run を叩いて、Phoenix 側の /v1/projects/<id>/spans API を確認すると、<workflow> という名前の CHAIN span が記録され、入力テキストと最終回答、所要時間まで取れていました。
{
"name": "<workflow>",
"span_kind": "CHAIN",
"attributes": {
"input.value": "What is today's date?",
"output.value": "Today's date is 2026-04-19."
},
"status_code": "OK"
}
Phoenix の Web UI(http://localhost:6006)にアクセスすると、トレースのツリービュー、各 span の所要時間、LLM の prompt / completion トークン数まで見えるようになります。
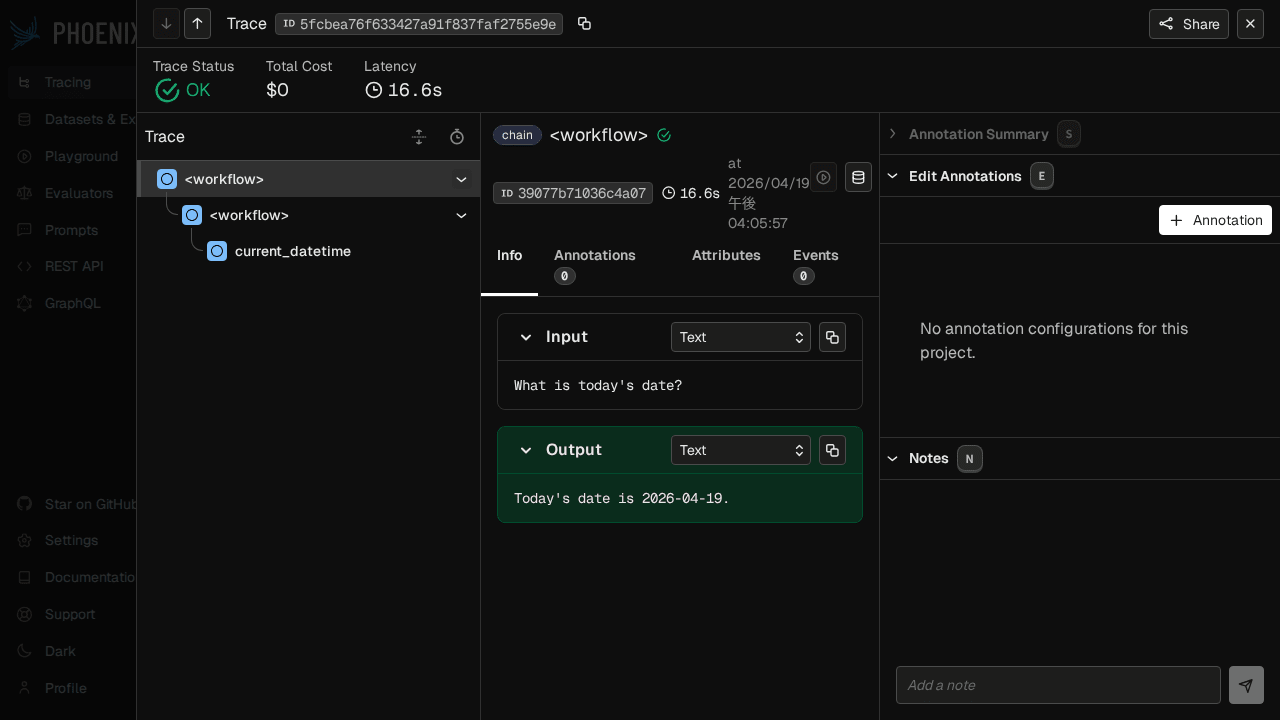
トレース行を 1 つ開くと、ReAct Agent の入れ子構造(外側の <workflow> の中で内側の <workflow> が走り、その中で current_datetime ツールが呼ばれている様子)と、入出力テキスト、所要時間、各 span のステータスまで一気に確認できます。
エージェントの振る舞いを眺める場として十分な装備が、Docker 1 行と config 1 ブロックで整いました。
ひとつだけ注意点として、project: nat-hello-local を指定しても Phoenix 上では default プロジェクトに集約されます。NAT 側は service.name resource attribute として送っているのですが、Phoenix の project 振り分けは別ヘッダーを必要とするため、本格運用ではこの整備が次の宿題になります。入門時点では「動いていることが見える」段階で十分なので、深追いは別記事に回します。
MCP サーバーとして公開する
NeMo Agent Toolkit は、書いた workflow.yml をそのまま MCP(Model Context Protocol)サーバーとして公開できます。nat mcp serve の 1 コマンドで、Claude Code や Claude Desktop、その他の MCP クライアントから叩けるツールに早変わりします。
nat mcp serve --config_file workflow.yml \
--name "NAT Hello Local" \
--host 0.0.0.0 \
--port 9901
デフォルトの transport は streamable-http で、protocol version は 2025-11-25。NAT 同梱の MCP クライアントで疎通確認ができます。
nat mcp client tool list --url http://localhost:9901/mcp --direct
# current_datetime
# react_agent
組み込みの current_datetime だけでなく、ワークフロー本体(react_agent)も自動的に 1 つのツールとして expose されているのがポイントです。引数スキーマは --detail オプションで覗けます。
nat mcp client tool list --url http://localhost:9901/mcp --direct --detail
# Tool: react_agent
# Description: ReAct Agent Workflow
# Input Schema: { "properties": { "query": { "type": "string" } }, ... }
query を渡すだけで ReAct ループ全体を 1 ツール呼び出しとして扱えます。試しに直接呼んでみます。
nat mcp client tool call react_agent \
--url http://localhost:9901/mcp --direct \
--json-args '{"query": "What is the current time?"}'
返ってきたレスポンスは OpenAI ChatCompletion 互換のオブジェクトで、content: "2026-04-19 07:08:21 +0000"、トークン使用量も prompt 5 / completion 3 / total 8 と取れています。
ここまで来ると、NemoClaw のサンドボックス内のエージェントや Claude Code / Claude Desktop から「DGX Spark 上で動いている自作エージェント」を MCP ツールとして呼び出すルートが見えてきます。ローカル LLM を裏で使いつつフロントは Claude というハイブリッド構成のための、いちばん軽い入口になりそうです。実際の MCP クライアント側の設定や、複数ワークフローを 1 サーバーから出し分けるあたりは別の機会に深掘りしたいと思います。
試してみて分かった向き不向き
ファーストステップとして触ってみた範囲の所感をまとめておきます。
向いている場面はわりとはっきりしていて、すでに LangChain や CrewAI で組んだエージェントを「観測したい」「評価駆動で改善したい」「MCP サーバー化したい」というケースです。NAT 自体のコードを書かなくても、設定 1 ブロックで OpenTelemetry・MCP・A2A が利用できるのは、メタレイヤーとして組み込みやすい設計だと感じました。
逆に「単一エージェント + 単純な tool call をひとつ動かすだけ」であれば、素の LangChain や直接 OpenAI SDK を叩いた方が速いです。NAT は複数フレームワークを横断したい、観測や評価のレイヤーを共通化したいというメタな要求があってはじめて真価が出るタイプの基盤なので、出発点としては「既存資産にどう被せるか」を考えるのが現実的です。
まとめ
NeMo Agent Toolkit のファーストステップを、DGX Spark + NGC vLLM の純粋なローカル構成で通してみました。
nvidia-nat==1.6.0は ARM64 でも pure Python wheel で素直に入る- DGX Spark Playbook の NGC vLLM コンテナをバックエンドにすれば、
_type: openai+base_urlの 2 行でローカル推論に切り替わる general.telemetry.tracingを 1 ブロック足すだけで、Arize Phoenix にトレースが流れるnat mcp serveひとつでワークフローが MCP サーバーになり、Claude Code などから叩けるツールに変わる
ローカル LLM × エージェント基盤 × 観測 × MCP の組み合わせが、思っていたより少ない記述量で形になることが分かったので、まずは手元の DGX Spark で workflow.yml を 1 つ書いてみるところから始めてみてください。
nat eval で評価駆動のエージェント開発を回すところや、A2A プロトコルでマルチエージェントに広げるところも、改めて試してみたいと思います。









