
LiteLLMとLangGraphで作ったAIエージェントをLangSmithで観測・評価してみる
はじめに
データ事業本部のkobayashiです。
エージェントが本番に乗ると、「なぜこの応答になったのか」を後から追跡できないと運用が成り立ちません。今回はLangChain純正の観測プラットフォーム LangSmith をLangGraph + LiteLLMの構成に組み込んで、トレース可視化とデータセット評価を行う方法を紹介します。
LangSmith でできること
- トレース可視化: LLM呼び出し・ツール実行・ノード遷移を階層構造で表示
- データセット管理: 期待入出力のペアを蓄積
- オフライン評価: データセット × エージェントで一括評価し、スコアを比較
- オンラインフィードバック: 本番ユーザーの 👍 / 👎 を集約
- バージョン比較: 「GPT-5-mini → Claude Sonnet 4.6 に変えたら品質はどう変わったか」を定量比較
料金プラン
LangSmith は Developer プランの月5,000トレースまで無料で試せます。本番運用するなら Plus、組織導入なら Enterprise を選ぶ構成です。
| プラン | 月額(USD) | 含まれるトレース | 主な制限・特徴 |
|---|---|---|---|
| Developer | $0/座席 + 従量課金 | 月5,000件まで無料 | 1座席のみ、コミュニティサポート、Fleet 1エージェント・月50回実行 |
| Plus | $39/座席 + 従量課金 | 月10,000件まで無料 | 座席無制限、メールサポート、Dev環境1つ無料、ワークスペース最大3個 |
| Enterprise | カスタム(年間請求) | カスタム | 専任サポート・SLA・セルフホスト/ハイブリッド対応・カスタムSSO/RBAC |
最新の料金は LangSmith Pricing を参照してください。本記事の検証は Developer プランの無料枠で完結する範囲です。
環境
Python 3.13
litellm 1.83.14
langgraph 1.1.10
langchain-litellm 0.6.4
langsmith 0.4.0
$ uv pip install litellm langgraph langchain-litellm langsmith
# 環境変数で有効化
$ export LANGSMITH_TRACING=true
$ export LANGSMITH_API_KEY="ls_..."
$ export LANGSMITH_PROJECT="litellm-langsmith-demo"
トレースの最小サンプル
LangSmithは環境変数を設定するだけで自動的にすべてのLLM・ツール呼び出しを送信してくれます。コードに追加修正は不要です。
"""LangSmith に LangGraph 実行をトレース送信する基本サンプル。
事前に下記の環境変数を設定しておく:
LANGSMITH_TRACING=true
LANGSMITH_API_KEY=ls_...
LANGSMITH_PROJECT=litellm-langsmith-demo
設定すると、すべての LLM/ツール呼び出しが自動的に LangSmith に送られる。
"""
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_litellm import ChatLiteLLM
@tool
def search_doc(query: str) -> str:
"""社内ドキュメントを検索します。"""
docs = {
"有給": "有給休暇は入社6ヶ月後に10日付与されます。",
"リモート": "リモートワークは週3日まで可能です。",
}
for k, v in docs.items():
if k in query:
return v
return "情報が見つかりませんでした"
llm = ChatLiteLLM(model="openai/gpt-5-mini")
agent = create_agent(model=llm, tools=[search_doc])
# 環境変数 LANGSMITH_TRACING=true が設定されていれば、これだけで自動トレース
result = agent.invoke(
{"messages": [{"role": "user", "content": "有給休暇のルールを教えて"}]}
)
print(result["messages"][-1].content)
print("\nLangSmith のダッシュボードでトレースを確認してください。")
実行後、ターミナルに最終回答が表示されつつ、LangSmithダッシュボード(https://smith.langchain.com)の指定したプロジェクトに階層トレースが送信されます。
$ LANGSMITH_TRACING=true LANGSMITH_PROJECT=litellm-langsmith-demo python basic_trace.py
日本の「年次有給休暇(有給休暇)」の主なルールを簡潔にまとめます。
1. 付与要件
- 原則:同一の会社で継続して6か月以上勤務し、かつその6か月間の出勤率が8割(80%)以上であること。
- 要件を満たすと最初に「10日」付与されます(以降は勤続年数に応じて増加)。
(中略:勤続年数別の日数、時季変更、5日ルール、消滅時効、退職時精算など)
LangSmith のダッシュボードでトレースを確認してください。
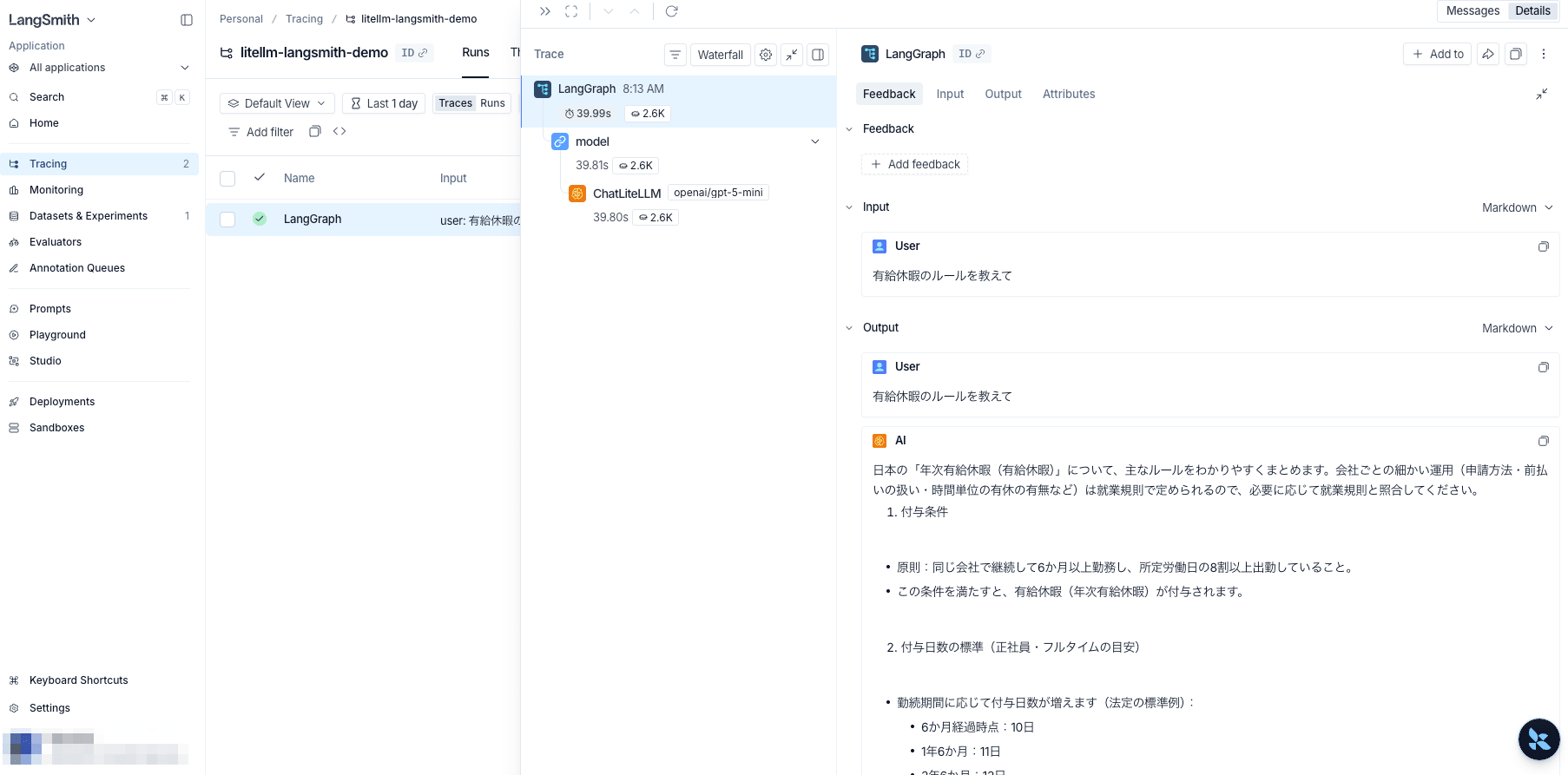
LangSmith側のトレースは概ね以下の階層構造で残ります。
各ノードにかかった時間、入出力のJSON、トークン使用量、コスト(LiteLLM由来)まで一覧できます。
なお、langchain_litellm の ChatLiteLLM をトレース送信する際、Pydanticのシリアライズ警告(PydanticSerializationUnexpectedValue: Expected 'Generation' / 'BaseMessage')が標準エラーに出ます。これはLangSmithのスキーマ期待と LiteLLM 経由の型差異から来るもので、トレース送信自体は成功するため実害はありません。ノイズが気になる場合は warnings.filterwarnings("ignore", category=UserWarning) で抑制できます。
データセット評価
LangSmithでは「期待入力と期待出力のペア」のデータセットを作って、エージェントを一括評価できます。
"""LangSmith でデータセットを使った評価を実行するサンプル。
1. データセットを LangSmith に作成
2. evaluate() で各 example に対して agent を実行
3. evaluator が複数の観点でスコアを付ける(substring 一致 + LLM-as-judge)
"""
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_litellm import ChatLiteLLM
from langsmith import Client
from langsmith.evaluation import evaluate
@tool
def search_doc(query: str) -> str:
"""社内ドキュメントを検索します。"""
docs = {
"有給": "有給休暇は入社6ヶ月後に10日付与されます。",
"リモート": "リモートワークは週3日まで可能です。",
}
for k, v in docs.items():
if k in query:
return v
return "情報が見つかりませんでした"
llm = ChatLiteLLM(model="openai/gpt-5-mini")
agent = create_agent(model=llm, tools=[search_doc])
# 評価専用の judge LLM。応答用と独立させて差し替えしやすくする。
judge_llm = ChatLiteLLM(model="openai/gpt-5-mini")
# =============================================
# 1. データセット作成(初回のみ)
# =============================================
DATASET_NAME = "company-faq-dataset"
client = Client()
if not client.has_dataset(dataset_name=DATASET_NAME):
dataset = client.create_dataset(DATASET_NAME)
client.create_examples(
inputs=[
{"question": "有給休暇のルールは?"},
{"question": "リモートワークは何日できる?"},
],
outputs=[
{"expected": "入社6ヶ月後に10日付与"},
{"expected": "週3日まで可能"},
],
dataset_id=dataset.id,
)
# =============================================
# 2. ターゲット関数: example.input -> agent 出力
# =============================================
def target(inputs: dict) -> dict:
result = agent.invoke(
{"messages": [{"role": "user", "content": inputs["question"]}]}
)
return {"answer": str(result["messages"][-1].content)}
# =============================================
# 3a. Evaluator (素朴): 期待値を substring として含むかでスコア
# =============================================
def contains_expected(outputs: dict, reference_outputs: dict) -> dict:
expected = reference_outputs["expected"]
answer = outputs["answer"]
return {
"key": "contains_expected",
"score": 1.0 if expected in answer else 0.0,
}
# =============================================
# 3b. Evaluator (LLM-as-judge): 表現ゆらぎを許容して意味で判定
# =============================================
def llm_judge(outputs: dict, reference_outputs: dict) -> dict:
expected = reference_outputs["expected"]
answer = outputs["answer"]
response = judge_llm.invoke(
[
{
"role": "system",
"content": (
"あなたは厳密な評価者です。回答が期待される情報を意味的に"
"含んでいるかを Yes / No のみで答えてください。"
"表現の言い換えや句読点・漢字/かなの違いは許容します。"
),
},
{
"role": "user",
"content": f"期待される情報: {expected}\n\n回答: {answer}\n\n判定:",
},
]
)
verdict = str(response.content).strip()
return {
"key": "llm_judge",
"score": 1.0 if verdict.lower().startswith("yes") else 0.0,
"comment": verdict,
}
# =============================================
# 4. 評価実行(2種類の evaluator を並列)
# =============================================
results = evaluate(
target,
data=DATASET_NAME,
evaluators=[contains_expected, llm_judge],
experiment_prefix="gpt-5-mini-baseline",
)
print(f"\n評価完了: {results}")
print("結果は LangSmith の Experiments タブで確認できます。")
ポイントを整理します。
target 関数
データセットのinputsを受け取り、エージェントを実行して出力dictを返す関数です。LangSmithが各 example に対して並列実行してくれます。
2種類の evaluator を並列で動かす
evaluator は outputs(target が返した値)と reference_outputs(期待値)を受け取り、スコアを返す関数です。今回は性質の異なる2つを evaluators=[...] に並べて、同じ実験で並列に評価しています。
contains_expected: 期待文字列が実出力に substring として含まれるかを 1.0 / 0.0 で判定する素朴な evaluator。llm_judge: 別の LLM(judge)に「期待される情報が意味的に含まれているか」を Yes / No で判定させる LLM-as-judge。表現の言い換えや漢字/かなの違いを許容する。
substring 一致はゼロコストで実装できますが、日本語業務での「ヶ↔か」「週3日の前後に修飾語が挿入される」といった表現ゆらぎでスコアが落ちやすいという落とし穴があります。LLM-as-judge はそれを意味レベルで吸収してくれるかわりに、評価のたびに LLM 呼出コストが発生します。両方を同時に走らせて並べると、「素朴 evaluator では失敗しているように見える example が、意味的には正解だった」というギャップが LangSmith のダッシュボード上で即座に確認できます。
experiment_prefix
実験ごとに名前を付けることで、LangSmith上で「GPT-5-mini版」「Claude Sonnet 4.6版」「プロンプト改善版」などを並べて比較できます。LiteLLMの恩恵で、モデルを変えるのは1行(ChatLiteLLM(model=...))なので、同じデータセットで複数モデルの性能比較が非常に楽です。
実行結果は以下のようになります。
$ LANGSMITH_TRACING=true LANGSMITH_PROJECT=litellm-langsmith-demo python dataset_eval.py
View the evaluation results for experiment: 'gpt-5-mini-baseline-d76d7d68' at:
https://smith.langchain.com/o/.../datasets/.../compare?selectedSessions=...
2it [00:30, 15.26s/it]
評価完了: <ExperimentResults gpt-5-mini-baseline-d76d7d68>
結果は LangSmith の Experiments タブで確認できます。
evaluate() を呼ぶと実験URLが標準出力に出力されるので、そこから直接LangSmithの評価ビューに飛べます。今回のデモでは2件のexampleを評価し、約30秒で完了しました(agent + judge LLM の両方が走るため、contains_expected 単独より遅くなります)。contains_expected と llm_judge のスコアはどちらも LangSmith 側で集計され、実験間で横並びに比較できます。
ダッシュボードで実験結果を比較する
LangSmith の Datasets & Experiments → company-faq-dataset を開くと、同じデータセットに対して実行した複数の experiment が一覧で並び、contains_expected / llm_judge(Feedback)/Latency(P50/P99)/Tokens(Input/Output)が実験ごとに横並びの棒グラフで可視化されます。プロンプトやモデルを変えて再実行する度にバーが追加されていくので、改善前後の差分が一目で見えるのが大きな利点です。
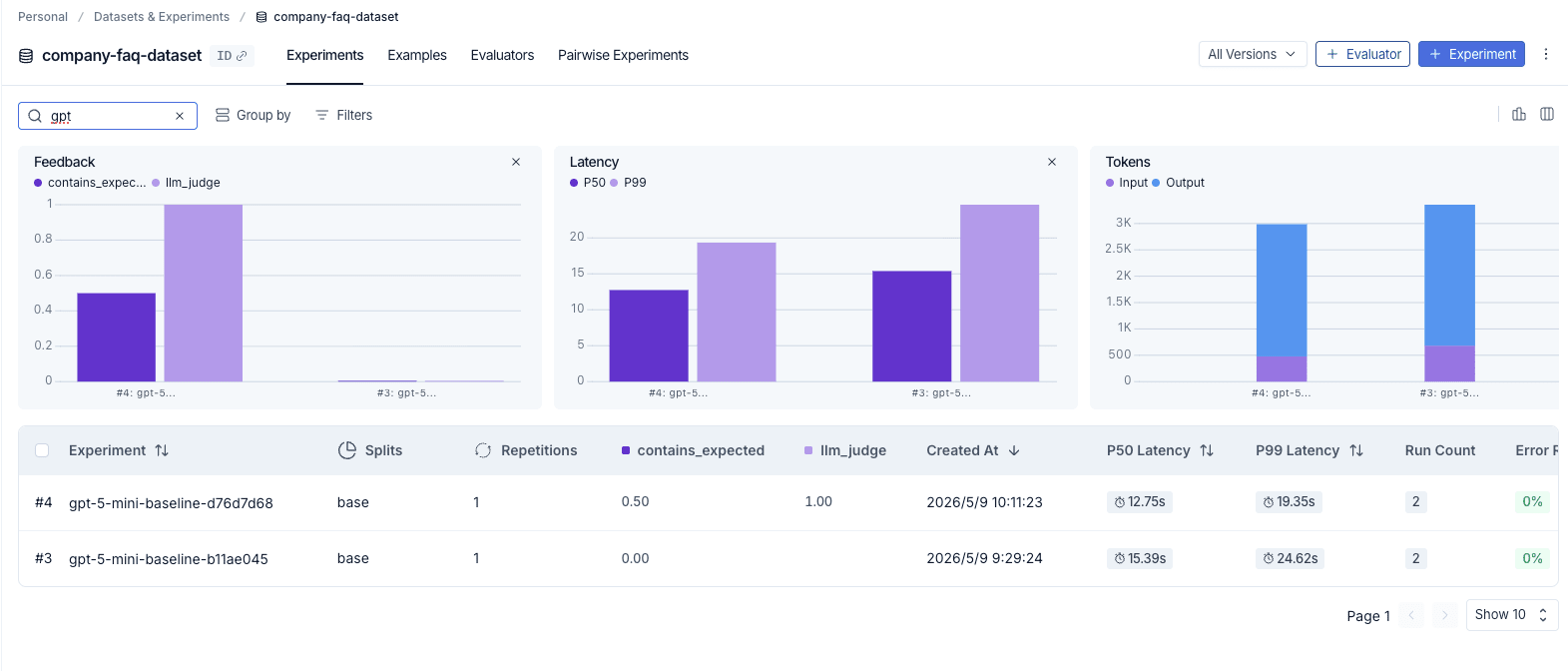
今回の gpt-5-mini-baseline-d76d7d68 実験は、contains_expected が 0.50 に対し llm_judge が 1.00 という結果になりました。個別の実験名をクリックして run-level を見ると理由がはっきりします。
- 「有給休暇のルールは?」: 期待値は
入社6ヶ月後に10日付与、実際の出力は…入社6か月後に10日付与…。「ヶ」と「か」のコードポイント違い で substring が一致しないためcontains_expected = 0.00、しかし意味は完全に正解なのでllm_judge = 1.00。 - 「リモートワークは何日できる?」: 期待値は
週3日まで可能、実際の出力は…リモートワークは「1週間あたり最大3日まで」可能です。。間に「1週間あたり最大」が挿入されて substring が崩れcontains_expected = 0.00、llm_judge = 1.00。
このように、ダッシュボード上で 「素朴 evaluator のスコア低下が品質劣化なのか表現ゆらぎなのか」を切り分けられる のが、LLM-as-judge を併走させる最大のメリットです。

LiteLLMでのモデル使い分け
| ロール | モデル | 理由 |
|---|---|---|
| ReActエージェント | openai/gpt-5-mini |
tool_use 安定性。LangSmithで複数モデル比較する際の 基準ライン (baseline) として使い、別実験でClaude等に切替 |
| LLM-as-judge | openai/gpt-5-mini |
判定精度とコストのバランス。応答用と独立変数にしているので、judge だけ Claude Sonnet 4.6 に切替えてバイアス比較もできる |
LangSmith は「プロバイダーを切替えたときに品質がどう変わるか」を定量的に測れるツールです。LiteLLMで ChatLiteLLM(model=...) を anthropic/claude-sonnet-4-6 に変えるだけで実験を再実行でき、experiment_prefix="claude-sonnet" などで別実験として比較できます。同じ仕組みで judge 側を切り替えれば、「judge を変えると評価結果が変わる」というバイアスチェックもデータセットを再利用して並列実行するだけで完結します。
まとめ
LangChain純正の観測プラットフォーム LangSmith を LiteLLM × LangGraph エージェントに組み込み、トレース可視化とデータセット評価を実装する方法を紹介しました。
トレース可視化は LANGSMITH_TRACING=true などの環境変数を設定するだけでLLM・ツール呼び出し・ノード遷移が階層構造で自動収集され、コードの追加修正は一切不要です。データセット評価は client.create_dataset() で期待入出力のペアを蓄積し、evaluate() に target 関数と evaluator を渡すだけで一括採点でき、experiment_prefix で実験単位を分けることでモデルやプロンプトの差を横並びで比較できます。LiteLLM で ChatLiteLLM(model=...) を切り替えるだけで実験を再実行できるため、評価駆動でモデル選定を進められる点が、本構成の大きな利点です。
最後まで読んでいただきありがとうございました。










