
LLM 評価基盤 NeMo Evaluator を DGX Spark で試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
LLM の評価、何を使えばいいか悩んでいる方も多いのではないでしょうか。MMLU だけでは推論は測れても安全性は測れませんし、コード生成を評価するなら HumanEval が欲しくなります。ベンチマークは目的別に乱立していて、それぞれリポジトリも API も違う。モデルを評価するたびに「今回はどれを動かそうか」と調べ直すのは、正直なところ少し消耗する作業です。
そこに NVIDIA が「全部まとめて面倒みる」という構えで出してきたのが NeMo Evaluator です。1 つの設定ファイルから複数のハーネスを呼び出し、同じ条件で並べて評価できる、というのがウリの評価基盤ですね。
ただ、こういう「全部入り」の道具は中身がブラックボックス化しやすくて、いざトラブルが起きると「どこから手を付けていいかわからない」と迷子になりがちです。本記事では、まず NeMo Evaluator の中身を解剖して仕組みを理解する ことに絞って書いていきます。実際に複数モデルで評価を回した実測レポートは、別記事に分けて公開する予定です。
検証環境は手元の DGX Spark(GB10、ARM64、128GB 統合メモリ)です。先に結論を書くと、NeMo Evaluator は「コア評価エンジン + ランチャー」の 2 層構造になっていて、主要ハーネスは DGX Spark の ARM64 でもそのまま動きます。独自ベンチを足す BYOB の仕組みも、最近のバージョンでかなりシンプルになっていました。
NeMo Evaluator とは何か
NeMo Evaluator は、NVIDIA が公開している OSS の LLM 評価基盤です。リポジトリは NVIDIA-NeMo/Evaluator にあり、モノレポとして 2 つのパッケージが並んでいます。
ひとつは nemo-evaluator で、評価のコアエンジンにあたります。こちらはコンテナの中で動くのが前提です。もうひとつが nemo-evaluator-launcher、通称 nel と呼ばれるランチャーで、コンテナの外から呼び出す指揮役ですね。
役割分担を料理にたとえるなら、nel が「レシピを読む料理長」で、コンテナが「包丁も材料もすべて揃った調理場」にあたります。料理長は自分で包丁を握らず、調理場を信頼して仕事を投げる構えですね。
NVIDIA 的な位置づけでは、NeMo Evaluator は NeMo RL(ポストトレーニング)と NeMo Agent Toolkit のちょうど間にいます。学習したモデルを評価して、その結果をエージェント構築に活かす、という流れの真ん中のピースですね。
誰のための道具か、を整理すると、次のような場面で使うと気持ちが楽になるはずです。
- 複数のベンチマーク(MMLU、HumanEval、BFCL、安全性系など)を一気に回したい
- 複数のモデルを同じ条件で並べて比較したい
- 自分たちの独自ベンチマークを他のベンチと同じ基盤に統合したい
特に 3 つ目、独自ベンチを同じ基盤に統合できる話は、社内データでの評価を再現性ある形で回したい場面で効いてきそうです。
アーキテクチャは「コンテナ × パイプライン」でできている
NeMo Evaluator は、外側で指揮を取るランチャーと、中で実際の評価を動かすコンテナの 2 層に分かれています。全体像はこんな感じです。
見てのとおり、nel はコンテナを pull してきて起動する指揮役で、実際に LLM エンドポイントを叩いて評価を回すのはコンテナの中にある nemo-evaluator コアです。
ここで意外なのが、同じリポジトリに並んでいるパッケージなのに nel はコアの Python API を直接呼ばないという点です。nel 側から nemo-evaluator の関数を import して使ったりはしません。かならずコンテナを起動し、コンテナ内で完結させる形を取っています。
これが地味にありがたい設計で、nel のバージョンとコアのバージョンを別々に回していても、依存関係が衝突する心配がありません。評価ジョブ側の Python 環境も、ハーネスごとに必要なバージョンがバラバラでも、コンテナが分けてくれる形です。
Adapter / Interceptor パイプラインが面白い
コンテナ内部の nemo-evaluator を覗いてみると、もうひとつ面白い仕掛けが出てきます。LLM API のリクエストとレスポンスを、Interceptor と呼ばれる部品の連なりで処理しているんですね。packages/nemo-evaluator/src/nemo_evaluator/adapters/interceptors/ に並ぶ実装を数えると、10 個のクラスが登録されています。
| インターセプター | 役割 | 種別 |
|---|---|---|
SystemMessageInterceptor |
システムプロンプトを注入する | Request |
PayloadParamsModifierInterceptor |
リクエスト payload のパラメータ追加・削除・リネーム | Request |
RequestLoggingInterceptor |
リクエストを記録する | Request |
CachingInterceptor |
結果をキャッシュする | RequestToResponse + Response |
EndpointInterceptor |
実際に LLM API を叩く本体 | RequestToResponse |
ResponseLoggingInterceptor |
レスポンスを記録する | Response |
ProgressTrackingInterceptor |
進捗を外部 Webhook に通知する | Response + PostEvalHook |
RaiseClientErrorInterceptor |
クライアントエラーを例外に変換する | Response |
ResponseReasoningInterceptor |
<think> タグなど推論トレース処理 |
Response + PostEvalHook |
ResponseStatsInterceptor |
レイテンシ・トークン数を集計する | Response + PostEvalHook |
これは、Web フレームワークのミドルウェアという考え方をほぼそのまま LLM 評価に持ち込んだ形です。うまくできているのはキャッシュ層がパイプラインの中にある点で、一度評価した結果は再計算されません。途中でクラッシュしても、失敗したサンプルだけ再評価できる、というのは実運用で効いてくる部分ですね。
ちなみに CachingInterceptor だけ種別が 2 つ並んでいるのは、キャッシュヒット時にリクエスト段階でレスポンスを返してショートカットし、ミス時はレスポンス段階で結果を保存する、という二重の役割を果たすためです。実装としては RequestToResponseInterceptor と ResponseInterceptor の多重継承になっています。
表の右端にある PostEvalHook という種別は、「レスポンス処理と評価後のフックを両方担う Interceptor」という意味です。ProgressTracking / ResponseReasoning / ResponseStats の 3 つが該当していて、推論時のメトリクス収集と評価完了後のサマリー生成を同じクラスで受け持ちます。設計として無駄がない形ですね。
ResponseReasoningInterceptor があるのもなかなかの配慮ポイントです。Nemotron や DeepSeek-R1 系のモデルが返す <think>...</think> の中身を本文と分離してくれるので、採点側で余計な前処理を書かずに済みます。
ランチャー側の道具立て
nel 側には、コンテナ起動だけじゃなくてジョブ管理に使うパーツが一通り揃っています。
実行環境を切り替える Executor は、ローカル実行・Slurm クラスタ・Lepton の 3 種類に対応しています。個人の DGX Spark では Local を使うのが普通ですが、社内クラスタに Slurm がある組織ならそのままスケールできるのがありがたいですね。
結果の出力先を選ぶ Exporter は MLflow、Weights & Biases、Google Sheets、ローカルファイルに対応しています。ジョブをたくさん回して横断比較したい場合、最初から MLflow に蓄積しておくとあとが楽です。
実行履歴は SQLite の ExecutionDB に記録されていて、過去のジョブを invocation ID から引っ張ってこられます。再評価したいときやベストチェックポイントを探したいとき、この履歴が効いてきます。
そして、タスク名からコンテナイメージを解決するのが mapping.toml です。「この評価は、あのハーネスのこのコンテナで動く」という中央レジストリで、nel 起動時にここを参照してコンテナを pull してきます。
この他に、学習と評価を連動させる nel-watch という独立コマンドもあります。こちらは運用面のトピックなので、記事の後半でまとめて触れますね。
統合ハーネスは 23 種類・421 タスク
NeMo Evaluator がカバーする評価ハーネスは 23 種類、タスク数にして 421 にのぼります(nel v0.2.4 時点)。まずはカテゴリ別の全景を眺めてみましょう。
| カテゴリ | ハーネス | 代表的に測るもの |
|---|---|---|
| 汎用 LLM | lm-evaluation-harness / simple-evals | MMLU / GSM8K / HellaSwag / GPQA |
| コード | bigcode-evaluation-harness / livecodebench / scicode | HumanEval / MBPP / LiveCodeBench |
| 安全性 | garak / safety-eval | 脆弱性プローブ / バイアス / コンテンツ安全性 |
| エージェント | nemo-skills / bfcl / tooltalk / tau2_bench | BFCL / ツール使用 / 関数呼び出し |
| 会話・指示追従 | mtbench / ifbench | マルチターン対話 / 複雑な指示追従 |
| 多言語 | mmath | 10 言語の数学推論 |
| VLM | vlmevalkit | AI2D / ChartQA / OCRBench / SlideVQA |
| 長文脈 | ruler / AA-LCR | コンテキスト長評価 |
| 専門ドメイン | helm / profbench / hle | 医療 / ビジネス / 学術 |
| 埋め込み | mteb | Embedding モデル評価 |
| データ汚染検出 | codec(contamination-detection) | ベンチデータが学習に混入していないか検出 |
| パフォーマンス | genai-perf | スループット・レイテンシ |
汎用 LLM の 2 大ハーネス、lm-evaluation-harness と simple-evals に始まり、コード・安全性・エージェント・多言語・VLM・長文脈といった具合に、ひととおりの評価軸が揃っている印象です。
実機で 421 タスクを数えてみる
DGX Spark 上で nel をインストールした状態で ls tasks を叩くと、すべてのタスクが一覧できます。
$ nemo-evaluator-launcher ls tasks
[I 2026-04-18] Loaded external tasks from IRs total_tasks=421
[I 2026-04-18] Using merged IRs total_tasks=421 internal_tasks=0 external_tasks=421
...
ハーネス別にタスク件数を集計すると、次のような分布になります。
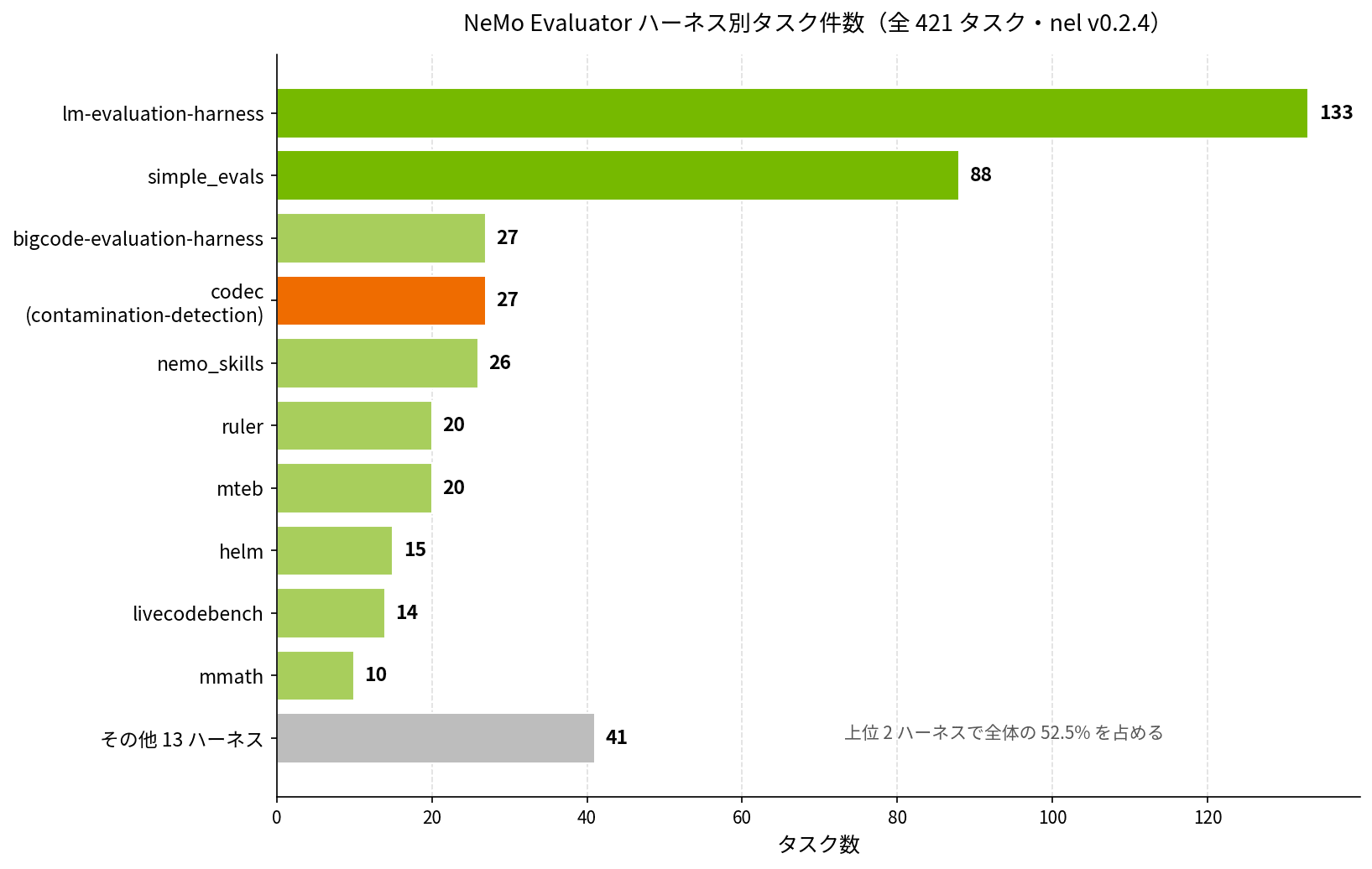
同じ分布を数字で確認すると、こうです。
| ハーネス | タスク数 |
|---|---|
| lm-evaluation-harness | 133 |
| simple_evals | 88 |
| bigcode-evaluation-harness | 27 |
| codec(contamination-detection) | 27 |
| nemo_skills | 26 |
| ruler | 20 |
| mteb | 20 |
| helm | 15 |
| livecodebench | 14 |
| mmath | 10 |
| その他 13 ハーネス(vlmevalkit / bfcl / safety_eval ほか) | 41 |
数を見ると偏りが見えてくる
この分布を眺めていて、いくつか気づく点があります。
まず、lm-eval と simple_evals だけで 221 タスク、全体の半分以上を 2 大ハーネスが占めています。論文でよく見る MMLU や GSM8K、HumanEval あたりはだいたいこの 2 つから入る形ですね。
そしてもうひとつ目を引くのが、codec ハーネスの 27 タスクです。これはベンチデータがモデルの学習データに混入していないかを検出する contamination-detection のためのセットで、評価スコアの健全性を担保する役割を担います。NVIDIA がこの領域に厚く枠を割いているのは、Nemotron や他のモデル評価で「そのスコア、データ漏洩してないですか?」という問いに答えるためでしょう。
次に、adlr_ プレフィックス付きのタスクが 18 件ほど存在します。ADLR は NVIDIA Applied Deep Learning Research の略で、Nemotron 論文で使われた評価条件をそのまま再現できるセットです。ベンチマーク結果を論文と揃えたいときに、かなり重宝しそうな枠です。
多言語系も厚くて、global_mmlu_full_{ja, ko, ar, ...} だけで 40 言語超えをカバーしています。日本語モデルの横断評価にも素直に使える形ですね。
一方、vlmevalkit(VLM 評価)は 7 タスクと控えめです。AI2D / ChartQA / OCRBench / SlideVQA などに絞られていて、この領域はまだ伸びしろがありそうです。
NVIDIA が車輪の再発明をしなかった戦略
23 ハーネスをまとめて面倒みる、と聞くと、NVIDIA が全部自前で書き直したのかと一瞬思うかもしれません。ですが実際はそうではなくて、既存の OSS ハーネスをほぼそのまま使っています。
nel が pull してくるコンテナ nvcr.io/nvidia/eval-factory/lm-evaluation-harness:26.03 を覗いてみると、中身は EleutherAI の lm-evaluation-harness をパッケージングしたもので、NVIDIA が独自に書き直しているわけではありません。
NVIDIA が自前で書いているのは、コンテナの外側を包むコアのアダプタ層と、10 段のインターセプター、それに mapping.toml とランチャー側の CLI だけ。「既存 OSS を信頼する層」と「自前で作る必要がある層」がはっきり分かれているのは、保守性の観点でも面白い設計だなと思います。
DGX Spark(ARM64)で本当に動くのか
ここからが、DGX Spark ユーザーにとっていちばん気になるところです。NeMo Evaluator が配布している NGC コンテナは、ARM64 で本当に動くのでしょうか。
公式ドキュメントを見ても ARM64 対応の明示的な記述が見つからず、DGX Spark 向けに ARM64 の NV-Ingest が未提供だった前例もあるので、少し心配しながら docker manifest inspect で確認してみました。
マニフェストを直接覗いてみる
まずは lm-evaluation-harness のコンテナから確認します。
$ docker manifest inspect nvcr.io/nvidia/eval-factory/lm-evaluation-harness:26.03
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"platform": { "architecture": "amd64", "os": "linux" }
},
{
"platform": { "architecture": "arm64", "os": "linux" }
}
]
}
manifest list に amd64 と arm64 が両方並んでいます。ARM64 ホスト(DGX Spark)で docker pull すると、Docker が勝手に arm64 の方のイメージを取ってきてくれる、という挙動です。
主要ハーネス 5 種の実測結果
同じ確認を主要ハーネスで繰り返して表にまとめるとこうなります。
| ハーネス | amd64 | arm64 |
|---|---|---|
| lm-evaluation-harness | ✅ | ✅ |
| bigcode-evaluation-harness | ✅ | ✅ |
| simple-evals | ✅ | ✅ |
| garak | ✅ | ✅ |
| vlmevalkit | ✅ | ❌ |
vlmevalkit だけが amd64 のみの配布で、それ以外の主要ハーネスは ARM64 の manifest が揃っていました。
意味するところ
この結果をまとめると、DGX Spark(Grace CPU = ARM64)でも標準ハーネスは docker pull するだけで動く、ということですね。nel のローカル実行モードを使えば、追加のクロスビルドなしで評価を回せます。
一方、VLM 評価をしたい場合は vlmevalkit が ARM64 に対応していないため、選択肢が分かれます。BYOB の --platform linux/amd64 オプションでクロスビルドした自前イメージを使うか、x86 サーバーで nel を動かして API 叩き先だけ DGX Spark の LLM に向けるか、のどちらかですね。
どちらを選ぶにせよ逃げ道は用意されている形です。BYOB のクロスビルドについては、次の章で書き方を追っていきましょう。
BYOB で独自ベンチマークを最小構成で足す
LLM の評価基盤を使っていてよくあるのが、「既存ハーネスだけでは足りない」というケースですね。自社データで作った QA セットを評価したい、社内ドキュメントを想定した独自ベンチを回したい。そうしたニーズに応えるのが、NeMo Evaluator の BYOB(Bring Your Own Benchmark)です。
旧方式と新方式
BYOB には実は 2 つの書き方があります。歴史的な経緯で両方が残っているので、どちらを使うかで書き心地がけっこう違います。
| 方式 | 時期 | 書き方 |
|---|---|---|
| FDF YAML + mapping.toml | v0.2.4 以前の主流 | YAML でフレームワーク定義を書き、mapping.toml に登録してコンテナに組み込む |
| nemo-evaluator-byob CLI + デコレータ | v0.2.5 以降の推奨 | Python 1 ファイルに @benchmark と @scorer を書くだけ |
新方式が出てきたのは v0.2.5 からで、これがかなり書き心地が良いのでおすすめですね。本記事でも新方式で進めます。
16 行の Python で書いてみる
SQuAD データセットを使って exact match で採点する、というシンプルなベンチマークを書いてみましょう。
from nemo_evaluator.contrib.byob import benchmark, scorer, ScorerInput
@benchmark(
name="my-qa-bench",
dataset="hf://rajpurkar/squad?split=validation",
prompt="Context: {context}\nQuestion: {question}\nAnswer:",
target_field="answers",
endpoint_type="chat",
requirements=["datasets"],
)
@scorer
def my_qa_scorer(sample: ScorerInput) -> dict:
predicted = sample.response.strip().lower()
gold = sample.target["text"][0].lower() if sample.target["text"] else ""
return {"exact_match": predicted == gold}
たったこれだけ、コメントなしで 16 行です。@benchmark デコレータがデータセットのロードとプロンプト整形を面倒みてくれて、@scorer の関数が採点ロジックになります。
ビルドと実行の流れ
書いたベンチを nel から呼び出せる形にするまでの全体像は、こんな流れです。
書いたファイルを nel から呼び出せる形にするには、nemo-evaluator-byob CLI を使います。まずは構文チェックから始めて、ローカルインストール、コンテナビルドと順に試していきましょう。
# 構文チェックのみ(Docker は不要)
$ nemo-evaluator-byob my_benchmark.py --dry-run
Validation passed. Benchmarks found:
- my-qa-bench (normalized: my_qa_bench)
Dataset: hf://rajpurkar/squad?split=validation
Requirements: datasets
# ローカル環境にインストール
$ nemo-evaluator-byob my_benchmark.py
Benchmark: my-qa-bench
Package: byob_my_qa_bench
Location: /home/morishige/.nemo-evaluator/byob_packages/byob_my_qa_bench
Installed: byob_my_qa_bench (discoverable by nemo-evaluator)
Compiled 1 benchmark(s) successfully.
# eval_type 名を確認する
$ nemo-evaluator-byob --list
Installed BYOB benchmarks (/home/morishige/.nemo-evaluator/byob_packages/):
byob_my_qa_bench.my_qa_bench
ベンチ名 my-qa-bench がハイフンからアンダースコアに正規化されて、byob_<name>.<name> の 2 段構造で eval_type が生成されるのが確認できます。この byob_my_qa_bench.my_qa_bench が、nel の評価設定 YAML に書く name フィールドの値になります。
コンテナビルドを試してみる
DGX Spark(ARM64)でコンテナを作ってみましょう。
$ nemo-evaluator-byob my_benchmark.py \
--containerize \
--tag byob_qa:local-test
...
[I ...] Downloading HuggingFace dataset dataset=rajpurkar/squad split=validation
[I ...] Converted HuggingFace dataset to JSONL records=10570
[I ...] Building Docker image tag=byob_qa:local-test-linux-aarch64 ...
[I ...] Docker image built successfully tag=byob_qa:local-test-linux-aarch64
Docker image built: byob_qa:local-test
約 36 秒で 530MB の ARM64 イメージが完成しました。気の利いているのが、ビルド中に SQuAD データセットを勝手に HuggingFace から取ってきて JSONL(10,570 レコード)に変換し、コンテナに同梱してくれるところです。イメージが自己完結型になるので、あとで別環境に持っていっても外部通信なしで評価を回せます。
もうひとつ細かい発見として、--tag の値には自動でプラットフォーム識別子が付く動きがあります。指定した byob_qa:local-test に対して、実際のタグは byob_qa:local-test-linux-aarch64 になっていました。プラットフォームごとに別イメージとしてレジストリに並べる設計なのが伝わってきますね。
クロスビルドで amd64 向けにも作る
ARM64 非対応の vlmevalkit を DGX Spark で使いたいときの出番が、--platform linux/amd64 フラグです(v0.2.5 の PR #832 で追加)。Docker buildx 経由で別プラットフォーム向けのイメージが生成されます。
nemo-evaluator-byob my_benchmark.py \
--containerize \
--platform linux/amd64 \
--tag byob_qa:cross-amd64
ARM64 ホストから amd64 イメージを作る場合は qemu エミュレーション越しのビルドになるため、ネイティブ(36 秒)と比べてかなり時間がかかります。筆者の環境では 2 分を超えてもまだ途中だったので、実用するなら CI 側(x86 Linux)でビルドするか、時間をかけて待つ覚悟が要ります。
そもそもこのクロスビルドが DGX Spark で効いてくる場面が、前章で触れた vlmevalkit が ARM64 に対応していない問題です。--platform linux/amd64 でクロスビルドした自前イメージを持っておけば、「VLM 評価ができない」という詰みを回避できます。もちろん自社独自のベンチマークを作って Nemotron や Gemma を社内データで評価し、結果を MLflow に蓄積していく、という正攻法の使い方でも便利に使えます。
nel への統合は YAML で
ビルドしたコンテナを nel から呼び出すときは、mapping.toml は触らなくて大丈夫です。新方式では、評価設定 YAML の container フィールドに直接コンテナ URL を書くだけで済みます。
evaluation:
tasks:
- name: byob_my_qa_bench.my_qa_bench
container: registry.example.com/byob_qa:latest
deployment:
target:
api_endpoint:
url: http://localhost:8000
model_id: my-model
type: chat
旧方式だと mapping.toml の管理が案外面倒でしたが、新方式は評価設定 YAML にすべて集約できるのですっきりしますね。
つまずきそうなポイント
実際に BYOB を動かすときに、ハマりそうなところをいくつか挙げておきます。
まず、ちょっと意外なハマりどころとして、--containerize は nemo-evaluator をソースツリーから editable install していないと動きません。pip install nemo-evaluator で入れた wheel 環境だと、ビルド時に COPY nemo_eval_pkg/ ... のステップで not found エラーが出ます。理由は、nemo-evaluator 自体を一緒にコンテナに焼き込むため、ビルド時にソースディレクトリを探しに行くからです。次の手順で回避できます。
git clone --depth 1 https://github.com/NVIDIA-NeMo/Evaluator.git
uv pip install -e ./Evaluator/packages/nemo-evaluator
これで nemo-evaluator-byob --containerize がそのまま動きます。
import 周りもひとつ落とし穴があって、モジュール名は nemo_evaluator のトップ直下ではなく nemo_evaluator.contrib.byob です。from nemo_evaluator import benchmark と書くと import エラーで dry-run 段階から弾かれます。
次に、プロンプトの {field} 名とデータセットの列名が一致しないと、ランタイムで KeyError が出ます。列名が違うときは field_mapping パラメータで名寄せするか、プロンプト側を合わせる形で対処します。
--list で出てくる eval_type 名には byob_ というプレフィックスが付き、ファイル名とベンチ名が正規化されます(小文字化・非英数字をアンダースコアに変換・50 文字切り捨て)。nel YAML の name フィールドにはこの正規化後の名前を指定してください。
クロスビルドで unknown platform のようなエラーが出たら、Docker buildx の multiplatform builder が未設定な可能性があります。docker buildx create --use で有効化できます。qemu-user-static が入っていない環境だと、buildx の PLATFORMS 列が arm64 だけで止まっている場合もあるので、docker buildx ls で確認しておくと安心です。
運用編の道具: nel-watch
運用面で押さえておきたいのが、v0.2.5 で追加された nel-watch コマンド(PR #857)です。指定ディレクトリを定期スキャンして、新しいチェックポイントが出てきたら SLURM ジョブとして評価を自動投入してくれる仕組みで、学習と評価を連動させたい MLOps パイプラインには嬉しい道具ですね。MLflow / W&B / Google Sheets への結果エクスポートも、評価設定 YAML に書いた exporter を経由してそのまま連携できます。
ただし、nel-watch は SLURM 専用で、ローカル Executor や Lepton Executor には現状対応していません。DGX Spark 単体で個人的に使う場合はややオーバーキルな機能で、素直に nel run を手動で叩く方が速い場面も多いでしょう。SLURM クラスタをすでに運用している組織向けの機能、と捉えておくと良さそうです。
まとめ
NeMo Evaluator の中身をざっと解剖しつつ、BYOB のところは実際に手も動かしてみました。改めて振り返ると、「コンテナ化された評価基盤」という骨格が徹底されていて、再現性と依存分離の観点でかなり良くできた設計だなと感じます。
ランチャー(nel)とコア(nemo-evaluator)の 2 層構造、そして 10 段の Interceptor パイプライン、23 ハーネス・421 タスクというカタログ規模。これだけ揃っていて、しかも独自ベンチを 16 行 Python で書いてコンテナ化までできる BYOB まで用意されている、というのはなかなかの充実ぶりですね。
DGX Spark ユーザー目線でいうと、今回の検証で確認できたことは次のような形です。
- 確認した 5 ハーネスのうち 4 つ(lm-eval / bigcode / simple-evals / garak)は ARM64 対応済みで、そのまま動く
- 残る
vlmevalkitだけ amd64 専用だが、BYOB の--platform linux/amd64でクロスビルドすれば回避できる - BYOB の自作ベンチは ARM64 ネイティブビルドが約 36 秒、SQuAD 10,570 件もビルド時に自動で JSONL 化してコンテナに焼き込んでくれる
--containerizeを使うときはpip install -eでソースツリーから入れ直す必要がある点だけ注意nel-watchは SLURM 前提なので、個人の DGX Spark で使うならnel runを直接叩く方が現実的








