
Nemotron 3 Nano Omni / Gemma 4 / Cosmos-Reason2 を日本語マルチモーダルベンチで比べてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
先日公開した Nemotron 3 Nano Omni を DGX Spark で 4 モダリティ動かしてみた記事 の続編です。前編末尾で予告していた「日本語マルチモーダルの本格評価」を回収する形で、Heron-Bench と JMMMU の 2 ベンチで Nemotron 3 Nano Omni / Gemma 4 / Cosmos-Reason2 を横並びで測ってみました。
検証は DGX Spark 1 台で完結させ、ソースコードと結果データは GitHub にも置いてあります。先に結論をひと言で書くと、自由記述系は Gemma 4 が頭ひとつ抜けて、選択肢系は 3 モデルがほぼ同等、というやや意外な結果になりました。
比較する 3 モデル
3 モデルの特性を簡単にまとめておきます。
| モデル | 構成 | DGX Spark での重み | 強み |
|---|---|---|---|
| Nemotron 3 Nano Omni | 30B-A3B Mamba+Transformer hybrid MoE | NVFP4 約 21GB | テキスト・画像・音声・動画の 4 モダリティ統合 |
| Gemma 4 26B-A4B IT | 26B-A4B MoE (Active 3.8B) | NVFP4 約 17GB | 日本語性能が高い、Apache 2.0 |
| Cosmos-Reason2-8B | 8B Dense VLM | BF16 約 16GB | VLM 特化、構造化出力が得意 |
Gemma 4 は当初 31B Dense を試しましたが、Omni MoE 比で 8 倍遅く本記事の規模では実用に耐えなかったため、同じ MoE アーキの 26B-A4B(Active 3.8B)に切り替えました(31B Dense の数字は末尾のレイテンシ脚注に)。
ベンチマークについて
本記事では 2 つのベンチマークを使いました。
Heron-Bench
turing-motors/Japanese-Heron-Bench は、Turing 社が公開している日本語マルチモーダル評価ベンチマークです。日本に関連した 21 枚の画像(アニメ、和食、ランドマーク、書道など)に対して、「会話」「詳細描写」「複雑推論」の 3 カテゴリで合計 102 問が設定されています。
評価は GPT-4 が事前に作った参照回答とモデル応答を比較し、別の LLM が 1〜5 点で採点する LLM-as-a-Judge 方式です。本記事では judge に Claude Haiku 4.5 を使い、5 段階で採点しました。自由記述の表現力と日本固有の文脈理解度を測るのに向いています。
JMMMU
JMMMU/JMMMU は、画像推論ベンチの定番 MMMU の日本語版です。化学、機械工学、日本史、デザイン、世界史など、28 の専門分野から合計 1,320 問が出題されます。画像と質問文を見て A〜D の選択肢から正解を選ぶ、いわゆる多肢選択方式です。
採点は 正解ラベルと完全一致したかどうか の exact match で、judge は不要です。専門知識ベースの図表理解や論理推論を測るのに向いています。
検証環境
3 モデルとも --max-model-len 8192 / --gpu-memory-utilization 0.4 / --enforce-eager の同条件で揃えています。各起動スクリプトは GitHub を参照ください。
Heron-Bench スコア(自由記述)
102 問を 3 モデルで実行した結果がこちらです。
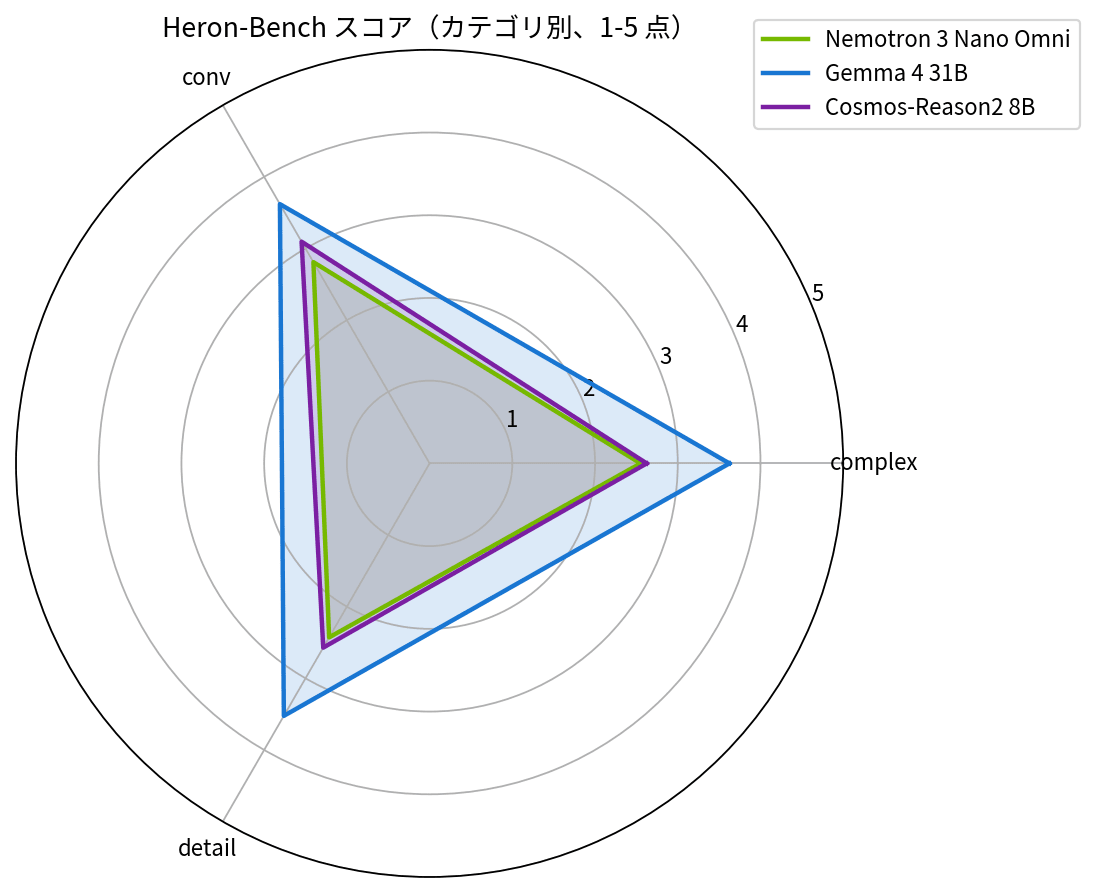
| モデル | 全体平均 | conv(会話) | detail(詳細) | complex(推論) |
|---|---|---|---|---|
| Nemotron 3 Nano Omni | 2.631 | 2.810 | 2.429 | 2.550 |
| Gemma 4 26B-A4B | 3.602 | 3.619 | 3.524 | 3.625 |
| Cosmos-Reason2-8B | 2.806 | 3.095 | 2.571 | 2.625 |
Gemma 4 26B-A4B が 全カテゴリで他 2 モデルに対し +0.8〜1.1 点差を付けて勝ち越し ました。画像カテゴリ別の内訳でも、anime(アニメ)/ food(和食)/ landmark(日本のランドマーク)など全領域で Gemma 4 がトップです。Omni の苦戦は前編で触れた「英語 first」な性格と整合しますが、同じ Active 3-4B の MoE である Gemma 4 がここまで強いのは予想以上で、4 モダリティ統合の代償として日本語性能が削れているのかもしれません。
JMMMU スコア(多肢選択)
続いて 1,320 問の JMMMU です。
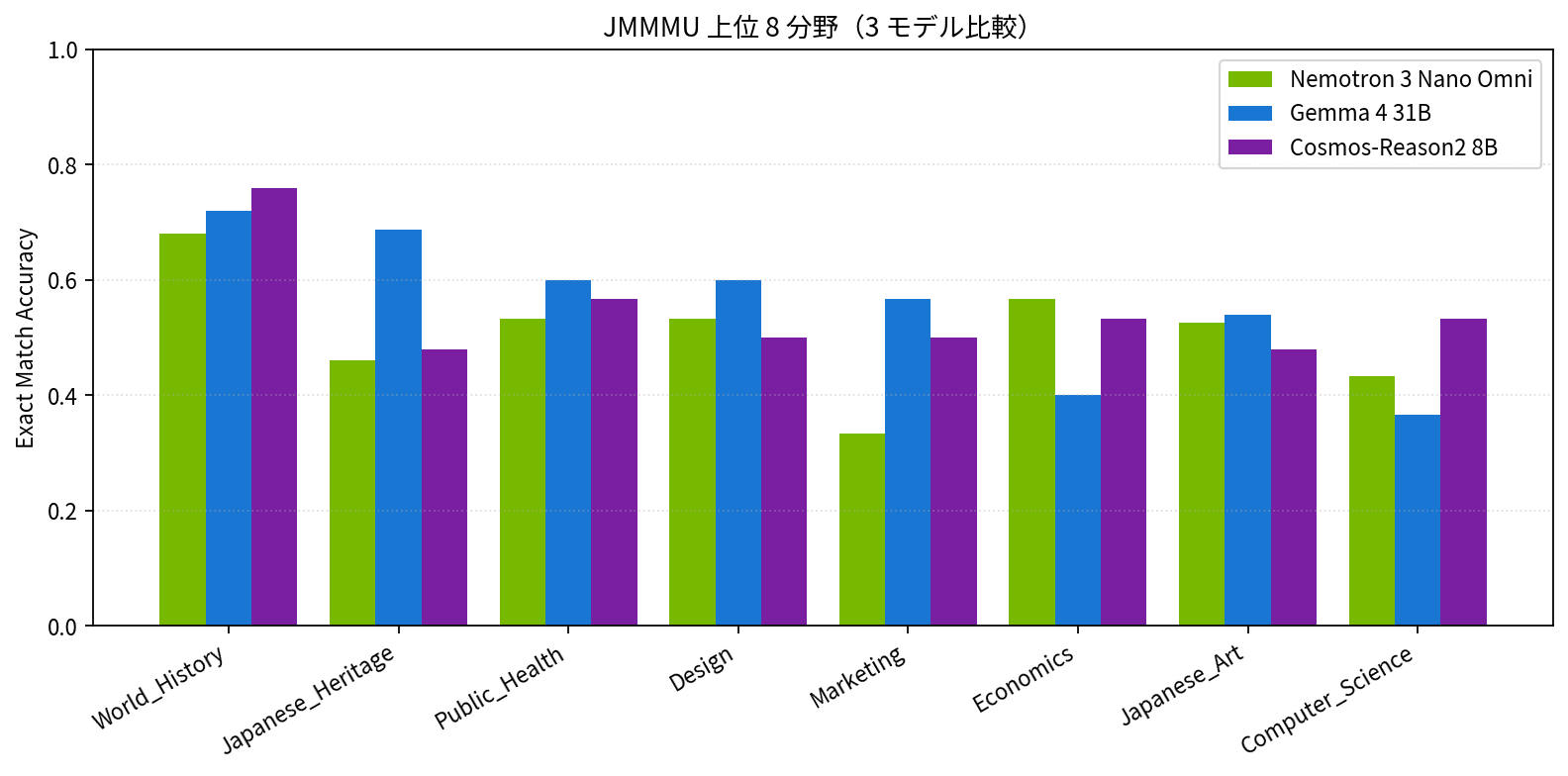
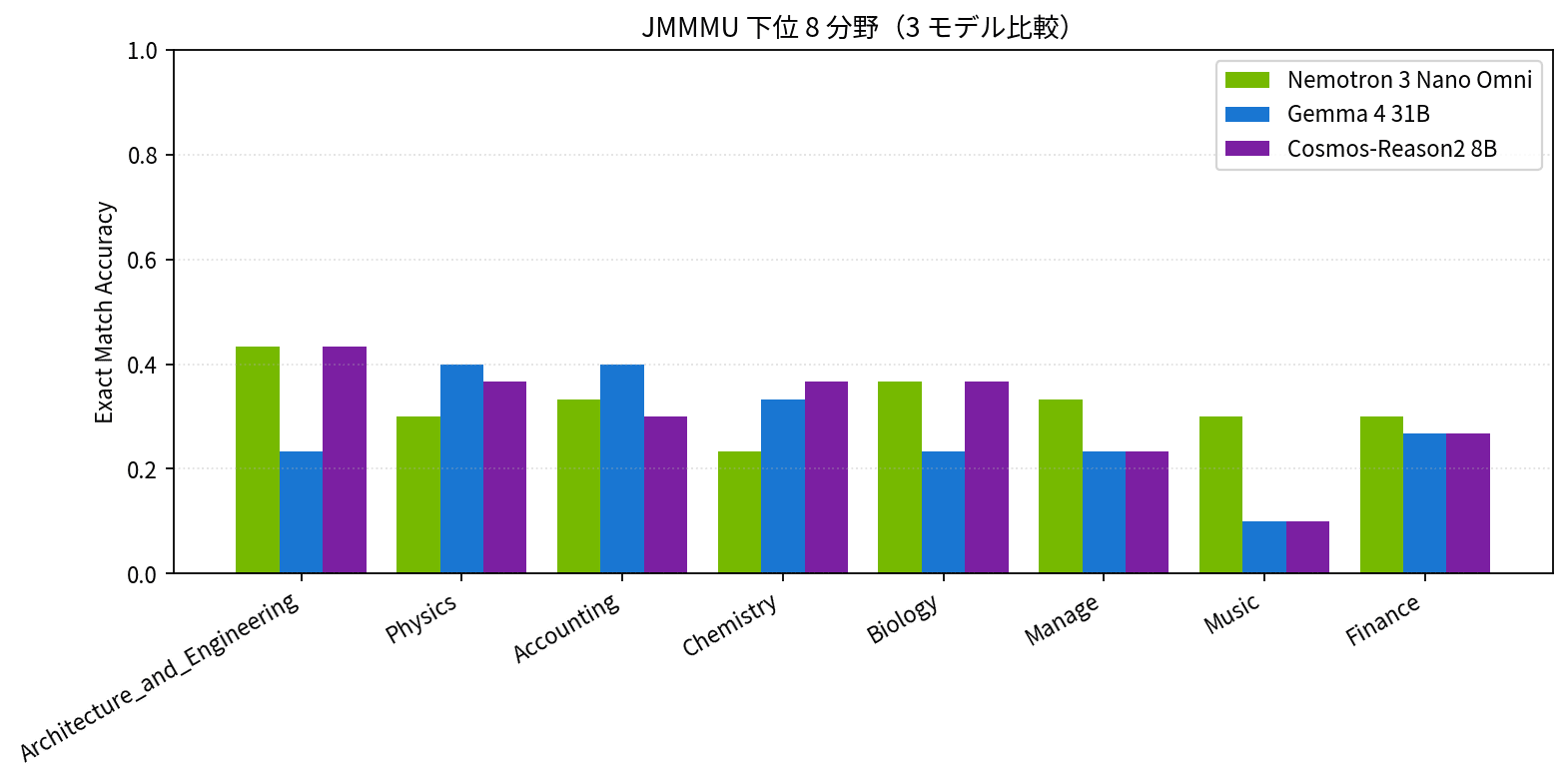
| モデル | 全体 Exact Match |
|---|---|
| Nemotron 3 Nano Omni | 0.458 |
| Gemma 4 26B-A4B | 0.438 |
| Cosmos-Reason2-8B | 0.470 |
こちらは Heron-Bench とは打って変わって、3 モデルがほぼ同等(差は 3.2pt 以内)に収まりました。意外なことに、最小の Cosmos-Reason2-8B が首位で、Active 3-4B クラスの MoE 2 モデルとパラメータ規模ほどのギャップが見えません。
分野別に見ると、World_History(全モデル 0.68 〜 0.76)と Japanese_Heritage(Gemma 4 が 0.687 と突出)といった歴史・文化系が全モデル得意で、Music や Mechanical_Engineering は 3 モデルとも苦戦している様子が見えます。Gemma 4 だけ Energy_and_Power が 0.067 と極端に低く、技術系の図表問題で大きく崩れているのも面白い特徴ですね。
「自由記述では大きく差が付くのに、選択肢ではあまり差が出ない」というのは、画像生成・タグ付け・要約のように モデルが文章を作る用途では Gemma 4 が安全な選択、特定分野の選択肢タスクなら 8B クラスでも十分 という現実的な使い分けの目安になりそうです。
推論レイテンシ
各モデルの 1 問あたり推論時間です(max_concurrency=2 で並列実行した実時間ベース)。
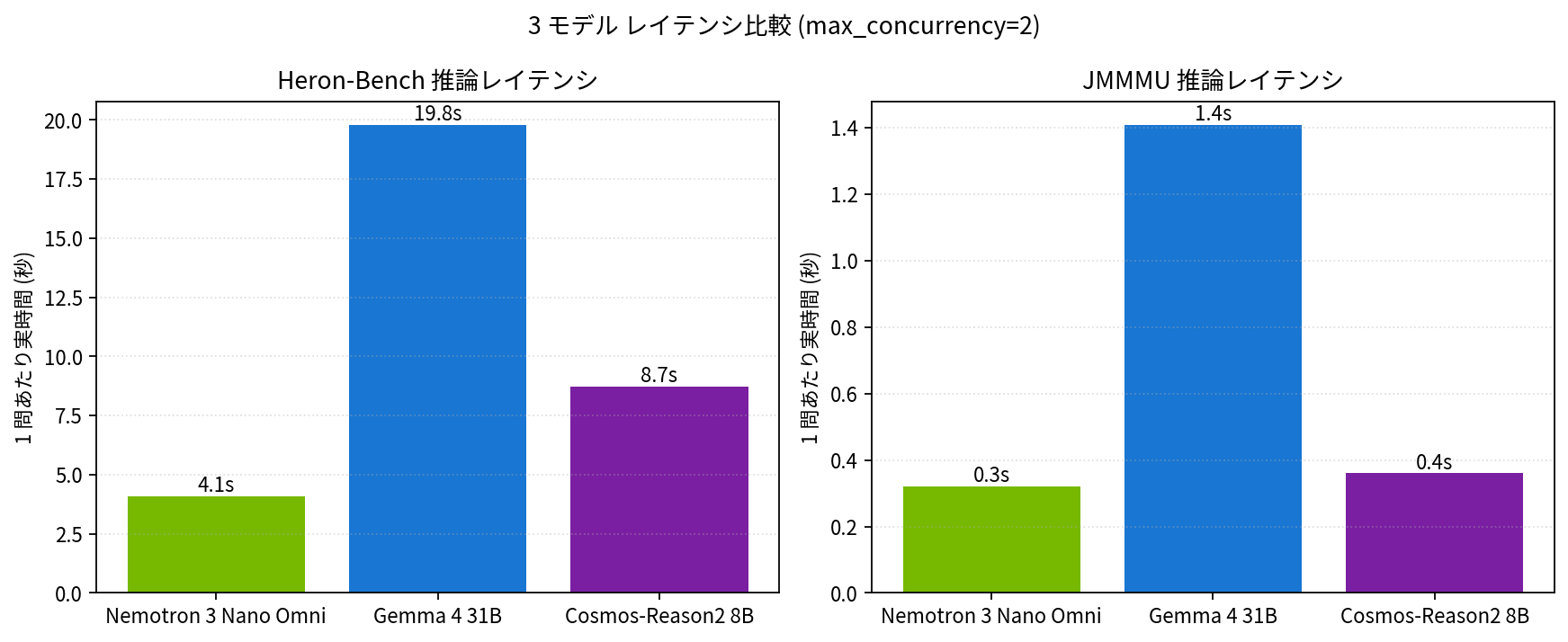
| モデル | Heron 1 問あたり | JMMMU 1 問あたり |
|---|---|---|
| Nemotron 3 Nano Omni | 4.1 秒 | 0.32 秒 |
| Gemma 4 26B-A4B | 19.8 秒 | 1.41 秒 |
| Cosmos-Reason2-8B | 8.7 秒 | 0.36 秒 |
Omni が圧倒的に速く、Gemma 4 26B-A4B が約 5 倍、CR2 がその中間という結果になりました。Active パラメータ規模だけ見ると Omni(3B)と Gemma 4(3.8B)はほぼ同等なので、この差は MoE backend(Omni は flashinfer_cutlass、Gemma 4 は vLLM auto-pick)と activation 関数(SiLU 系 vs GELU 系)の最適化差が主因と思われますが、ここはもう少し深堀りが必要そうです。
出力サンプル比較
参考までに、Heron-Bench の同一問題に対する 3 モデルの応答を 2 件ご紹介します。
単純な事実応答 (heron-101: ニセコまでの距離)
| モデル | 応答 | judge スコア |
|---|---|---|
| Nemotron 3 Nano Omni | 12km | 5 |
| Gemma 4 26B-A4B | 画像から判断すると、ニセコまでは 12 km と表示されています。 | 5 |
| Cosmos-Reason2-8B | 12 km です。 | 5 |
数字を読み取るだけのストレートな問題は 3 モデルとも問題なく正解しています。
複雑な推論 (heron-005: イラストの作品あらすじ)
質問は「このイラストが示す作品のあらすじを詳細に教えてください」、画像は『千と千尋の神隠し』の千尋・カオナシ・湯婆婆が並ぶ有名なシーンです。
| モデル | 応答の要点 | judge スコア |
|---|---|---|
| Nemotron 3 Nano Omni | 『となりトトロ』と作品を誤認、主人公名も「ちっちゃい」と造語化 | 1 |
| Gemma 4 26B-A4B | 『千と千尋の神隠し』を正しく特定、千尋・湯婆婆・カオナシ・油屋まで含めた詳細あらすじを生成 | 5 |
| Cosmos-Reason2-8B | 『千と千尋の神隠し』まで正解、ただし「無」「ティーパーティー」など独自描写で内容が逸脱 | 2 |
このように複雑な情景描写や日本固有の文脈解釈が問われる問題では、Gemma 4 だけが安定して高得点を取り、Omni と CR2 は誤認や逸脱が目立ちました。
使い分けの目安
ここまでの結果を踏まえた、ざっくりした使い分けの目安です。
| 用途 | 推奨モデル | 理由 |
|---|---|---|
| 4 モダリティ統合(音声・動画含む) | Nemotron 3 Nano Omni | 唯一の Omni モデル、推論も速い |
| 日本語の説明文・キャプション生成 | Gemma 4 26B-A4B | Heron-Bench で +1 点差の安定感 |
| VLM 特化、軽量、構造化出力 | Cosmos-Reason2-8B | 8B でも 30B 級と互角の選択肢精度 |
まとめ
DGX Spark 1 台で Heron-Bench と JMMMU を 3 モデル横断で測ってみました。「日本語自由記述では Gemma 4 26B-A4B が頭ひとつ抜けるが、選択肢タスクでは 3 モデルが概ね横並び」というのが今回の結論です。Omni は 4 モダリティ統合という独自ポジションがありつつ、純粋な日本語ベンチでは Gemma 4 に一歩譲る、という形になりました。
次回は、NeMo Agent Toolkit と組み合わせて Omni を perception sub-agent として使う構成を試してみる予定です。前編の Agent Toolkit 記事 NAT1 の続編としてもお楽しみください。
検証の裏側
3 モデル × 1,422 問の Run 管理は、以前の Langfuse Self-host 記事で構築した環境をそのまま流用しました。langfuse.run_experiment() で各モデルを Dataset Run 化し、judge スコアと API コストは Langfuse Trace Cost で自動集計、ブログ用のグラフだけ matplotlib で別途仕上げる、というハイブリッド構成です。実機検証に約 3.5 時間 + judge コストは Anthropic 側で 2 ドル弱で済みました。











