
VSS 3.0.0 EA の Warehouse Blueprint を DGX Spark で試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
前回の記事では VSS(Video Search and Summarization)Agent を DGX Spark で動かして、映像検索 AI の基本的な使い方と日本語 LLM への差し替えを試しました。Nemotron 9B-v2-Japanese に切り替えることで、日本語 Q&A の品質がかなり改善されるのを確認できました。
前回は 2.4.x で検証しましたが、VSS にはすでに 3.0.0 Early Access が公開されています。アーキテクチャがモノリシックからマイクロサービスに刷新され、MCP ベースのオーケストレーション、業界別 Blueprint、動画とテキストの統合 Embedding(Cosmos-Embed1)など、かなり中身が変わっています。
EA(Early Access)なので本番利用は推奨されていませんが、だからこそ「今の段階で何が動いて、何が変わったのか」をレポートすることに価値があるかなと思い、DGX Spark 上で先行体験してみることにしました。
VSS 2.4.x と 3.0.0 — 何が変わったのか
まず、前回の 2.4.x と今回の 3.0.0 EA で何が変わったのかを整理しておきます。
アーキテクチャの刷新
2.4.x はモノリシックな構成で、映像のインジェスション(取り込み)からリトリーバル(検索)まで単一の VSS Engine コンテナが担っていました。3.0.0 ではこれが 3 層のマイクロサービスに分解されています。
RTVI(Real-Time Video Intelligence)層でリアルタイムの映像処理を担当し、分析層で行動解析やキャリブレーションを行い、エージェント層が MCP ベースで全体をオーケストレーションする構成です。
主要な変更点
| 項目 | 2.4.x | 3.0.0 EA |
|---|---|---|
| アーキテクチャ | モノリシック(VSS Engine) | 3 層マイクロサービス(RTVI / Analytics / Agent) |
| オーケストレーション | config.yaml ベース | MCP(FastMCP)ベース |
| 検索基盤 | Milvus + Neo4j(CA-RAG) | Elasticsearch + Milvus |
| 映像 Embedding | テキスト Embedding のみ | Cosmos-Embed1(動画 + テキスト統合) |
| CV パイプライン | なし(VLM のみ) | DeepStream 8.0(RT-DETR 物体検出) |
| 行動解析 | なし | Behavior Analytics(安全イベント検出) |
| デプロイ | GitHub リポジトリ + docker compose | NGC パッケージ + docker compose |
| 業界テンプレート | なし | Warehouse / Smart City / Public Safety |
| VLM | Cosmos-Reason2 | Cosmos-Reason2 / Qwen3-VL |
| LLM | Llama 3.1 8B / Ollama 差し替え可 | Nemotron Nano 9B-v2(デフォルト) |
| DGX Spark 対応 | IS_SBSA=1 フラグ |
Warehouse Blueprint で公式サポート |
2.4.x では Embedding や Reranker を差し替えるのに NIM 互換プロキシを自作する必要があったり、CV パイプラインは別途構築しなければならなかったり、差し替えが難しい部分がありました。3.0.0 のマイクロサービス化で、こうした制約が根本的に解消される方向に進んでいます。
業界別 Blueprint
3.0.0 では業界別の Blueprint が 3 種類用意されています。
| Blueprint | 対象領域 | 主なユースケース |
|---|---|---|
| Warehouse | 倉庫・工場・物流 | スペース管理、資産追跡、フォークリフトと人の接近検知 |
| Smart City | 交通・都市監視 | 交通流計測、停車異常検出、逆走検知。CARLA + Cosmos Transfer による Sim2Real |
| Public Safety | 公共安全 | テイルゲーティング検出(認可者に続く無許可通過の検知) |
いずれも共通の VSS コアプラットフォーム上に、業界固有の検出モデルと行動分析ロジック、エージェント構成を積み上げた参照実装です。今回は倉庫向けの「Warehouse Blueprint」を使います。DGX Spark で公式にサポートされていて、NVIDIA が公開しているパフォーマンス実測値によると、4 ストリーム 30fps で E2E レイテンシは 102ms。参考値ですが、IGX Thor(222ms)よりも速い数値が出ています。
利用できるプロファイルは以下の 4 つです。
| プロファイル | BP_PROFILE 値 | 内容 |
|---|---|---|
| 2D Vision AI(Kafka) | bp_wh_kafka |
物体検出と追跡 + Kafka |
| 2D Vision AI(Redis) | bp_wh_redis |
物体検出と追跡 + Redis |
| 2D Vision AI with Agents | bp_wh |
上記に加えて VSS Agent、VLM、LLM を統合 |
| 3D Vision AI | — | Sparse4D による多カメラ 3D 追跡 |
今回は Warehouse Operations Blueprint、「2D Vision AI with Agents」(bp_wh)プロファイルを使います。DeepStream による物体検出から Behavior Analytics によるイベント検出、さらに VSS Agent による自然言語での問い合わせまで、フルスタックで動かせる構成です。

DGX Spark へのデプロイ準備
前提条件
DGX Spark で 3.0.0 EA を動かすために必要な環境を確認しました。
| 項目 | 要件 | DGX Spark(実測) | 判定 |
|---|---|---|---|
| OS | Ubuntu 24.04 | Ubuntu 24.04.4 LTS | OK |
| NVIDIA Driver | 580.105.08 以上 | 580.126.09 | OK |
| Docker | 27.2.0 以上 | 29.1.3 | OK |
| Docker Compose | v2.29.0 以上 | v5.0.1 | OK |
| NGC CLI | 4.10.0 以上 | 4.14.0(手動インストール) | OK |
| ディスク | 十分な空き | 2.3TB | OK |
NGC CLI だけ DGX Spark にインストールしていなかったので、NGC の公式サイトから ARM64 版をダウンロードしてインストールしました。
# NGC CLI のインストール(ARM64)
curl -sL "https://api.ngc.nvidia.com/v2/resources/nvidia/ngc-apps/ngc_cli/versions/4.14.0/files/ngccli_arm64.zip" \
-o /tmp/ngccli_arm64.zip
unzip /tmp/ngccli_arm64.zip -d /tmp/ngc-cli-install
mkdir -p ~/.local/bin
cp -r /tmp/ngc-cli-install/ngc-cli ~/.local/ngc-cli
ln -sf ~/.local/ngc-cli/ngc ~/.local/bin/ngc
# 設定
ngc config set
NGC パッケージの取得
Warehouse Blueprint の compose パッケージを NGC からダウンロードします。
ngc registry resource download-version \
"nvidia/vss-warehouse/vss-warehouse-compose:3.0.0"
46.72MB のパッケージがダウンロードされます。展開するとこのような構成です。
vss-warehouse-compose_v3.0.0/
├── deployments/
│ ├── compose.yml # メインの Compose 定義
│ ├── foundational/ # Kafka, Elasticsearch, Redis 等
│ ├── monitoring/ # Prometheus / Grafana
│ ├── vst/ # Video Storage Tool
│ ├── warehouse/ # Warehouse Blueprint 本体
│ │ ├── .env # 環境変数(ここを編集)
│ │ ├── warehouse-2d-app/ # 2D パイプライン
│ │ └── vss-agent/ # VSS Agent 設定
│ ├── nim/ # LLM / VLM の NIM 定義
│ ├── agents/ # Agent + UI
│ ├── rtvi/ # RTVI マイクロサービス
│ ├── lvs/ # Long Video Summarization
│ └── auto-calib/ # カメラキャリブレーション
└── modules/ # ユーティリティスクリプト
2.4.x では GitHub リポジトリをクローンして中の compose.yaml を読み解く形でしたが、3.0.0 では NGC パッケージとして整理されています。compose.yml はモジュールごとに分割されていて、メインの compose.yml が include で各サービスを読み込む構成です。
DGX Spark 向けの .env 設定
ここが今回のデプロイで一番手間がかかったところです。.env ファイルには DGX Spark 固有の設定がいくつか必要で、デフォルトのままでは動きません。
# ハードウェアプロファイル(H100 → DGX-SPARK に変更)
HARDWARE_PROFILE='DGX-SPARK'
# 単一 GPU のため shared モードを使用
LLM_MODE=local_shared
VLM_MODE=local_shared
# デバイス ID(DGX Spark は GPU 0 のみ)
LLM_DEVICE_ID='0'
VLM_DEVICE_ID='0'
# パス設定
MDX_SAMPLE_APPS_DIR="/path/to/deployments"
MDX_DATA_DIR="/path/to/vss-warehouse-app-data"
HOST_IP='<DGX Spark の IP アドレス>'
# NGC API Key
NGC_CLI_API_KEY='<your-ngc-api-key>'
DGX Spark(ARM64 / SBSA)では、コンテナイメージのタグも変更が必要です。.env ファイルの中にコメントアウトされた DGX-SPARK 用の設定がありました。
# Perception(DeepStream)のイメージタグ
PERCEPTION_TAG="3.0.0-sbsa" # x86 は "3.0.0"
# VST 系コンテナのイメージタグ(7 つ全て -sbsa に変更)
VST_SENSOR_IMAGE_TAG="3.0.0-sbsa"
VST_RTSPSERVER_IMAGE_TAG="3.0.0-sbsa"
VST_RECORDER_IMAGE_TAG="3.0.0-sbsa"
VST_STORAGE_IMAGE_TAG="3.0.0-sbsa"
VST_REPLAYSTREAM_IMAGE_TAG="3.0.0-sbsa"
VST_LIVESTREAM_IMAGE_TAG="3.0.0-sbsa"
NVSTREAMER_IMAGE_TAG="3.0.0-sbsa"
EA パッケージの DGX Spark 対応状況
compose.yaml を読んでいて気づいたのですが、EA パッケージの DGX Spark サポートはまだ手作業が必要な部分が残っていました。公式ドキュメントには「DGX-SPARK: Supported」と記載されているものの、そのまま動かすにはいくつか追加の対応が必要です。
| 問題 | 詳細 | 対処 |
|---|---|---|
| NIM 用 hw env ファイル欠落 | hw-DGX-SPARK.env が Nemotron Nano V2、Cosmos Reason2 ともに存在しない |
DGX-THOR の env を参考に手動作成 |
| VLM プロファイル未定義 | Cosmos Reason2 の compose に DGX-SPARK プロファイルがない |
compose.yml に手動追加 |
| デバイス ID のデフォルト | LLM_DEVICE_ID='1', VLM_DEVICE_ID='2'(マルチ GPU 前提) |
'0' に変更 |
EA(Early Access)段階なので、このあたりは GA に向けて整備されていくのだと思います。今回は DGX-THOR(同じ ARM64 / Grace Hopper アーキテクチャ)の設定を参考に、DGX Spark 用の hw プロファイルを手動で作成して対応しました。
デプロイ
起動
設定が済んだら、compose up で全サービスを起動します。
cd /path/to/vss-warehouse-compose_v3.0.0/deployments
docker compose -f compose.yml \
--env-file warehouse/.env \
up --detach --pull always --force-recreate --build
初回は 36 種類!?のコンテナイメージを pull するため、ネットワーク速度によっては 30 分以上かかります。DGX Spark の場合は -sbsa タグ付きのイメージが自動的に選択されます。
ハマりポイント
実際に起動してみると、いくつかの追加対応が必要でした。
NVIDIA Container Runtime の登録
DGX Spark の Docker デーモンに NVIDIA ランタイムが登録されていない場合があります。unknown or invalid runtime name: nvidia というエラーが出たら、以下のコマンドで登録します。
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
データディレクトリの事前作成
Elasticsearch や Redis のバインドマウント先ディレクトリが存在しないとコンテナが起動しません。compose の volume 定義を読み解いて、必要なディレクトリを事前に作成しました。
mkdir -p /path/to/data/data_log/{elastic/{logs,data},kafka,redis/{data,log}}
mkdir -p /path/to/data/videos/nv-warehouse-4cams
mkdir -p /path/to/data/models
ディレクトリの権限
Docker が root でディレクトリを作成してしまうケースがあり、Redis が Permission denied で起動できないことがありました。chown と chmod でユーザー権限に修正して解決しています。
LLM NIM の ARM64 問題
ここが今回の検証で一番大きなハマりポイントでした。
VLM(Cosmos-Reason2-8B)の NIM は ARM64 に正式対応しており、問題なく起動しました。ところが LLM(Nemotron-Nano-9B-v2)の NIM は exec format error で起動できません。
exec /opt/nvidia/nvidia_entrypoint.sh: exec format error
Docker のマルチアーキテクチャマニフェストには arm64/linux が含まれていて、docker image inspect でも Architecture: arm64 と表示されるのですが、コンテナ内のバイナリが実際には x86 向けにビルドされているようです。/bin/bash すら実行できない状態でした。
EA 段階のイメージビルドの問題と思われます。
NGC vLLM で代替
NIM が動かないならということで、NVIDIA が NGC で公開している vLLM コンテナ(nvcr.io/nvidia/vllm)を代替として使いました。こちらは ARM64 に正式対応しています。
docker run -d --name vllm-nemotron-nano \
--runtime nvidia \
-p 30081:8000 \
--shm-size 16g \
-e NVIDIA_VISIBLE_DEVICES=0 \
-e HF_TOKEN=$HF_TOKEN \
nvcr.io/nvidia/vllm:26.01-py3 \
python3 -m vllm.entrypoints.openai.api_server \
--model nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--served-model-name nvidia/nvidia-nemotron-nano-9b-v2 \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--gpu-memory-utilization 0.2 \
--max-model-len 16384 \
--max-num-seqs 4
--served-model-name を NIM と同じ nvidia/nvidia-nemotron-nano-9b-v2 にすることで、VSS Agent の設定を変更せずにそのまま接続できます。OpenAI 互換 API のエンドポイント形式が同じなので、ドロップイン置き換えが可能です。
ただし注意点が一つ。NGC vLLM 26.02 は CUDA 13.1 / Driver 590+ を要求するため、DGX Spark の Driver 580.126.09 では互換性エラーになります。26.01(CUDA 13.0 対応)を使う必要がありました。
起動結果
最終的に、41 の compose サービス + vLLM コンテナの合計 42 サービスが稼働しました。ds-configurator は設定生成後に終了するため、稼働中のサービス数としては 41 です。
NAME STATUS
alert-bridge Up 35 minutes
bp-configurator-2d Up 45 minutes (healthy)
cosmos-reason2-8b-shared-gpu Up 39 minutes (healthy)
mdx-elastic Up 45 minutes (healthy)
mdx-kafka Up 45 minutes (healthy)
mdx-kibana Up 45 minutes (healthy)
mdx-nvstreamer-2d Up 9 minutes
metropolis-vss-ui Up 35 minutes
perception-sdr-2d Up 45 minutes
vss-agent Up 35 minutes (healthy)
vss-auto-calibration Up 45 minutes (healthy)
vss-behavior-analytics-2d Up 45 minutes
vss-va-mcp Up 44 minutes (healthy)
vss-video-analytics-api-2d Up 45 minutes
vss-video-analytics-ui Up 44 minutes
vst-mcp-2d Up 44 minutes
# ... 他 25 サービス省略
GPU メモリの使用状況はこのようになっています。
| プロセス | VRAM |
|---|---|
| VLM(Cosmos-Reason2-8B NIM) | 約 32 GB |
| LLM(Nemotron-Nano-9B-v2 vLLM) | 約 31 GB |
| VST(映像ストリーミング × 2) | 約 350 MB |
| 合計 | 約 64 GB / 128 GB |
GB10 の 128 GB 統合メモリのうち約半分を使用しています。2.4.x のときは VLM + LLM で 20 GB 程度だったので、3.0.0 ではかなり余裕を持ったメモリ確保をしている印象です。vLLM 側の --gpu-memory-utilization を調整すれば、さらにメモリ消費を抑えることも可能です。
サービス構成
bp_wh(2D with Agents)プロファイルで起動すると、以下のサービスが立ち上がります。
| サービス | ポート | 役割 |
|---|---|---|
| Agentic UI | 3000 | VSS Agent のチャット UI |
| Video Analytics UI | 3002 | 映像分析ダッシュボード |
| Kibana | 5601 | Elasticsearch のダッシュボード |
| Phoenix UI | 6006 | エージェントのトレーシング |
| Video Analytics API | 8081 | 分析データの REST API |
| Calibration Toolkit | 8003 | カメラキャリブレーション |
| Nemotron NIM | 30081 | LLM(Nemotron Nano 9B-v2) |
| Cosmos Reason2 NIM | 30082 | VLM(Cosmos-Reason2-8B) |
| NvStreamer | 31000 | 映像ストリーミング |
| VIOS | 30888 | Video Storage Tool |
2.4.x では Web UI(:9100)とバックエンドの VSS Engine だけでしたが、3.0.0 では用途ごとに専用の UI が分かれています。
動かしてみる
UI を開いてみる
全サービスが起動すると、3 つの Web UI にアクセスできます。Next.js ベースで、2.4.x のシンプルな UI と比べるとかなり洗練された印象です。
VSS Agent UI(:3000)
ChatGPT ライクなインターフェースで、「Hi, I'm Warehouse Agent」と表示されます。Chat / Alerts / Dashboard / Video Management の 4 タブ構成で、動画のドラッグ & ドロップアップロードにも対応しています。左下には「Version 3.0-EA」の表記があります。
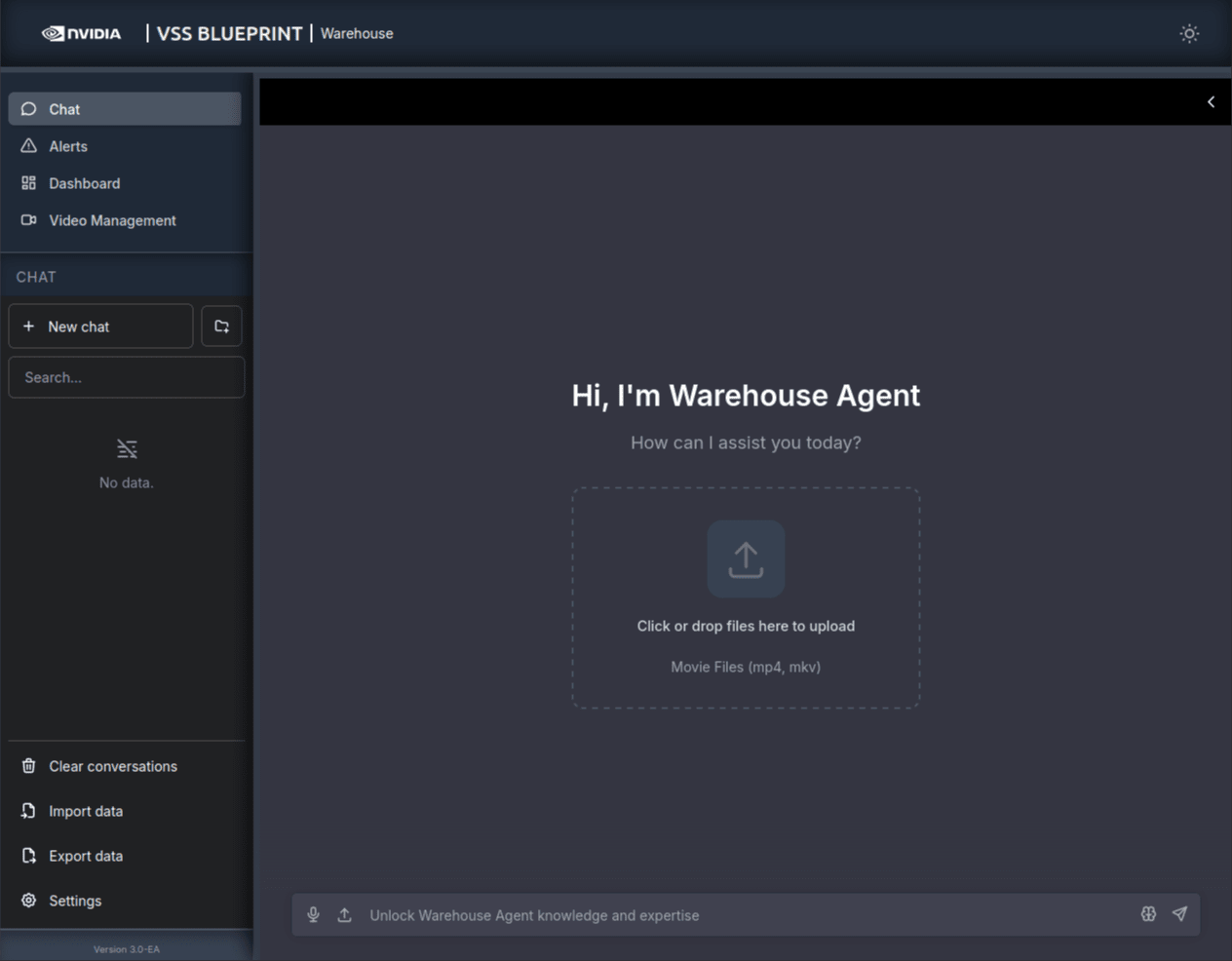
Video Analytics UI(:3002)
NVIDIA Metropolis ベースの映像分析ダッシュボードです。DeepStream の検出結果をリアルタイムで確認できます。
Kibana(:5601)
Elasticsearch のダッシュボードで、Behavior Analytics が検出したイベントデータの可視化に使います。
Agent とチャットしてみる
VSS Agent UI のチャット欄、もしくは API 経由で Agent に問い合わせてみました。
curl -s -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "Hello, can you describe what you can do?"}]}'
Agent は以下のような応答を返してくれました。
I can help with several tasks related to warehouse video surveillance:
- Sensor/Camera Information
- Occupancy Monitoring
- Snapshots/Pictures
- Incident Reporting
2.4.x では映像のベクター検索と Q&A がメインでしたが、3.0.0 ではセンサー管理、占有率モニタリング、インシデントレポート生成など、より実践的な機能が MCP ツール経由で提供されています。
ただし、ここで一つ問題が発生しました。
tool calling の壁とその解消
VSS Agent は内部で LLM の tool calling 機能を使って MCP ツールを呼び出します。最初にハマったのが、Nemotron-Nano-9B-v2 のツール呼び出しフォーマットと vLLM の組み込みパーサーとの不一致です。
Nemotron は <TOOLCALL>[{...}, {...}]</TOOLCALL> という配列形式を使いますが、vLLM の hermes パーサーは <tool_call>{...}</tool_call> という個別タグ形式を期待します。そのまま起動すると、raw な TOOLCALL タグがそのまま応答として返ってしまいました。
解決策は、vLLM の --chat-template オプションでカスタムテンプレートを適用することです。モデルのデフォルトテンプレートをベースに、タグ名を <tool_call> に統一し、ツール呼び出しを配列ではなく個別タグで出力するよう修正しました。
# カスタムテンプレートを指定して起動
python3 -m vllm.entrypoints.openai.api_server \
--model nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--chat-template /tmp/chat_template.jinja \
--enable-auto-tool-choice \
--tool-call-parser hermes \
...
この修正により、VSS Agent のツール連携が正常に動作するようになりました。「Show me available sensors」と聞くと、Agent が get_sensor_ids ツールを自動的に呼び出し、5 つのカメラストリームの一覧を返してくれます。
Here are the available sensors:
1. warehouse_cam4
2. warehouse
3. warehouse_cam3
4. warehouse_cam1
5. warehouse_cam2
NGC vLLM + カスタムテンプレートという組み合わせで、NIM が使えない環境でも tool calling を含むフルスタックの Agent 機能が動作することを確認できました。
Perception パイプラインの復旧
DeepStream による Perception パイプライン(物体検出・追跡)は、最初の起動では動きませんでした。エラーログを確認すると、物体検出モデルが見つからないというメッセージが出ています。
ERROR: Cannot access ONNX file '/opt/storage/rtdetr_warehouse_v1.0.fp16.onnx'
ERROR: failed to build network since parsing model errors.
調べてみると、起動スクリプト ds-start.sh がベースイメージ内の models/mtmc/*.onnx を作業ディレクトリにコピーする設計なのですが、Perception のベースイメージにはこのディレクトリ自体が存在しませんでした。ITS(Intelligent Traffic Systems)向けの別モデル(resnet50_market1501.etlt)が models/rtdetr-its/ に入っているだけで、Warehouse 向けの RT-DETR ONNX モデルはまだバンドルされていないようです。EA 段階なので、このあたりは今後整備されていくのでしょう。
ただ、モデル自体は NGC カタログに公開されていました。nvidia/tao/rtdetr_2d_warehouse という名前で、TAO Toolkit で学習された RT-DETR + EfficientViT/L2 バックボーンのモデルです。7 クラス(Person、Humanoid ×2、Nova Carter、Transporter、Forklift、Pallet)を検出する倉庫特化モデルで、NVIDIA Open Model License(商用利用可)で提供されています。
# NGC から RT-DETR Warehouse モデルをダウンロード
ngc registry model download-version \
nvidia/tao/rtdetr_2d_warehouse:deployable_efficientvit_l2_v1.0
# FP16 ONNX モデル(136MB)をマウントディレクトリに配置
cp rtdetr_2d_warehouse_vdeployable_efficientvit_l2_v1.0/rtdetr_warehouse_v1.0.fp16.onnx \
$MDX_DATA_DIR/models/mtmc/
# パーミッションを修正(コンテナは UID 1000 で実行されるため読み取り権限が必要)
chmod 644 $MDX_DATA_DIR/models/mtmc/rtdetr_warehouse_v1.0.fp16.onnx
# Perception コンテナを再起動
docker restart perception-2d
初回起動時には TensorRT のエンジンビルドが走ります。ログを見ると、明示的な FP16 フラグでのビルドがまず失敗し、strongly typed mode(モデル内蔵の FP16 演算をそのまま使う方式)にフォールバックして成功しました。RT-DETR を DeepStream で FP16 実行すると LayerNorm のオーバーフローで nan が出るケースがフォーラムで報告されているので、strongly typed mode での自動フォールバックはむしろ都合が良い結果です。
エンジンビルド完了後、パイプラインが正常に稼働しました。
** INFO: <bus_callback:623>: Pipeline running
**PERF:
30.00000 (31.19770) source_id : 0 stream_name warehouse
warehouse ストリームを 30fps で処理しています。NGC モデルカードに記載されている DGX Spark のパフォーマンス(30fps で 3 ストリーム対応)とも一致する値です。
なお、この Perception パイプラインは 3.0.0 で新たに追加されたレイヤーです。前回の 2.4.x では映像理解を VLM だけで処理していたのに対し、3.0.0 の Warehouse Blueprint は VLM に加えて DeepStream の CV パイプラインをリアルタイム物体検出・追跡に使うハイブリッド構成になっています。
動いたもの、動かなかったもの
今回の検証結果をまとめると、こうなりました。
| コンポーネント | 状態 | 備考 |
|---|---|---|
| VLM NIM(Cosmos-Reason2-8B) | 正常稼働 | ARM64 正式対応、約 32 GB VRAM |
| LLM NIM(Nemotron-Nano-9B-v2) | 起動不可 | ARM64 イメージが壊れている |
| LLM(NGC vLLM 代替) | 正常稼働 | カスタムテンプレートで tool calling 解消 |
| NvStreamer(映像配信) | 正常稼働 | 5 ストリーム RTSP 配信 |
| VSS Agent(MCP オーケストレーション) | 正常稼働 | LLM 接続 OK、ヘルスチェック通過 |
| VA-MCP Server | 正常稼働 | Video Analytics MCP 提供 |
| Perception(DeepStream) | 正常稼働 | NGC モデル手動配置で復旧、30fps |
| Behavior Analytics | 正常稼働 | perception 復旧により稼働 |
| Kafka / Elasticsearch / Kibana | 正常稼働 | インフラ層は問題なし |
| 各種 UI(:3000 / :3002 / :5601) | 正常稼働 | アクセス可能 |
| Alert Bridge(VLM-as-Verifier) | 正常稼働 | 4 箇所パッチ適用で復旧(後述) |
| Agent レポート生成 | 正常稼働 | Markdown / PDF + スナップショット |
LLM NIM の ARM64 イメージと Alert Bridge の設定にそれぞれ対処が必要でしたが、代替手段やパッチ適用でほぼフルスタックで動作する結果になりました。
UI とパイプラインの全体像
実際にデプロイされたサービスの関係を公式のアーキテクチャ図で見てみましょう。ブラウザから各 UI にアクセスし、裏では Perception → Behavior Analytics → Elasticsearch のデータパイプラインが 30fps で回り続けている構成です。
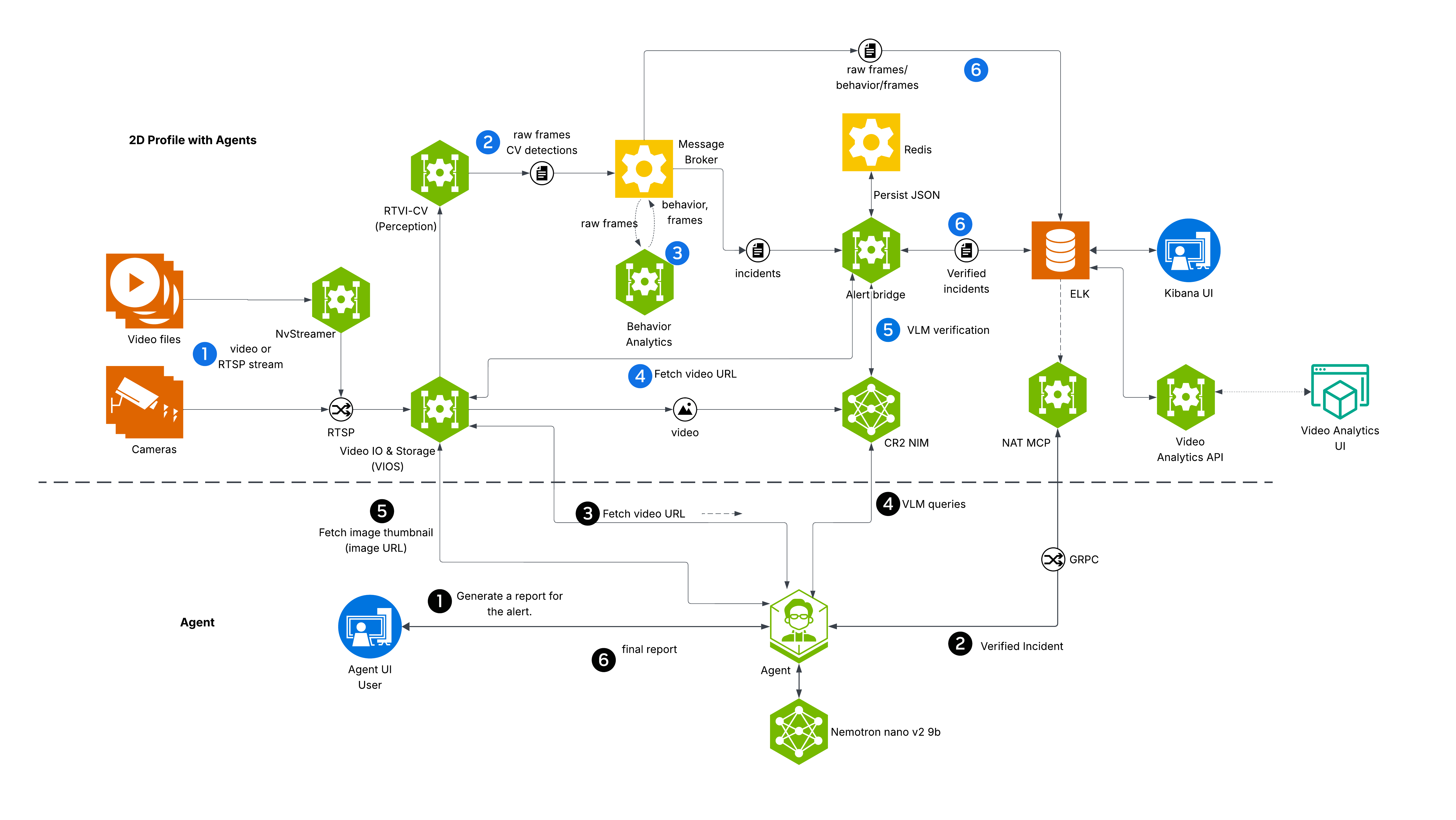
出典: NVIDIA VSS 3.0.0 Warehouse Blueprint - 2D Vision AI with Agents Profile
左側の Input Source(NvStreamer)から映像が VIOS を経由して DeepStream(Perception)に流れ、検出メタデータが Kafka 経由で Behavior Analytics に渡されます。分析結果は ELK Stack(Elasticsearch + Kibana)に蓄積され、右側の各 UI から参照できます。
VSS UI(:3000)が全体の入り口です。Chat タブから Warehouse Agent に質問すると、Agent が VA-MCP 経由で Elasticsearch のデータを引き、LLM で回答を生成します。Dashboard タブは Kibana を iframe で埋め込んでいて、Perception の検出データをリアルタイムで可視化しています。
MCP サーバーの構成
3.0.0 の目玉機能の一つが MCP(Model Context Protocol)ベースのオーケストレーションです。VSS Agent は内部で VA-MCP Server(Video Analytics MCP Server)と通信し、映像分析の結果を取得しています。
VSS Agent の config.yml を見ると、MCP クライアントとして video_analytics_mcp と vst_mcp の 2 つが定義されています。
function_groups:
video_analytics_mcp:
_type: mcp_client
server:
transport: streamable-http
url: ${VIDEO_ANALYSIS_MCP_URL}/mcp
include:
- video_analytics.get_incidents
- video_analytics.get_incident
- video_analytics.get_fov_histogram
- video_analytics.get_sensor_ids
vst_mcp:
_type: mcp_client
server:
transport: streamable-http
url: ${VST_MCP_URL}/mcp
2.4.x では config.yaml で静的にパイプラインを定義していたのに対し、3.0.0 では MCP ツールとして機能が公開されています。エージェントが状況に応じて「どのツールを使うか」を判断する構成です。
VLM-as-Verifier パイプラインを動かす
ここまでは基本的なデプロイと各コンポーネントの動作確認でした。ここからは 3.0.0 の Warehouse Blueprint の目玉である VLM-as-Verifier パイプラインを動かしてみます。
2 段階検知の仕組み
Warehouse Blueprint の安全監視は、2 段階の検知設計になっています。
- ルールベース検知(Behavior Analytics): DeepStream の物体検出結果をもとに、ROI(関心領域)やトリップワイヤーへの侵入・通過を検知。閾値ベースでインシデント候補を生成
- VLM 視覚検証(Alert Bridge → Cosmos-Reason2-8B): インシデント候補に対して、該当時刻の映像を VLM に渡して「本当にインシデントか?」を視覚的に検証
CV で広く・速く候補を絞り、VLM で深く・正確に検証するハイブリッド構成ですね。
Perception が 30fps で検出したメタデータは Kafka 経由で Behavior Analytics に渡り、インシデント候補として再び Kafka に送信されます。Alert Bridge がそれを受け取り、Redis で重複排除した上で VST から該当映像を取得し、VLM(Cosmos-Reason2-8B)で視覚検証を行います。検証結果は Elasticsearch の mdx-vlm-incidents インデックスに蓄積される流れです。
インシデント検知の設定
Behavior Analytics でインシデントを生成するには、calibration.json に ROI やトリップワイヤーを設定します。今回は公式のサンプル calibration を使い、倉庫の通路にトリップワイヤーを設置しました。
# Calibration UI(:8003)で設定、もしくは直接 JSON を編集
# 設定後は Behavior Analytics を再起動
docker restart vss-behavior-analytics-2d
Perception パイプラインが 30fps で動いている状態で calibration を反映すると、Person がトリップワイヤーを通過するたびにインシデントが Kafka に送信されます。Kibana の Dashboard でリアルタイムに確認できます。
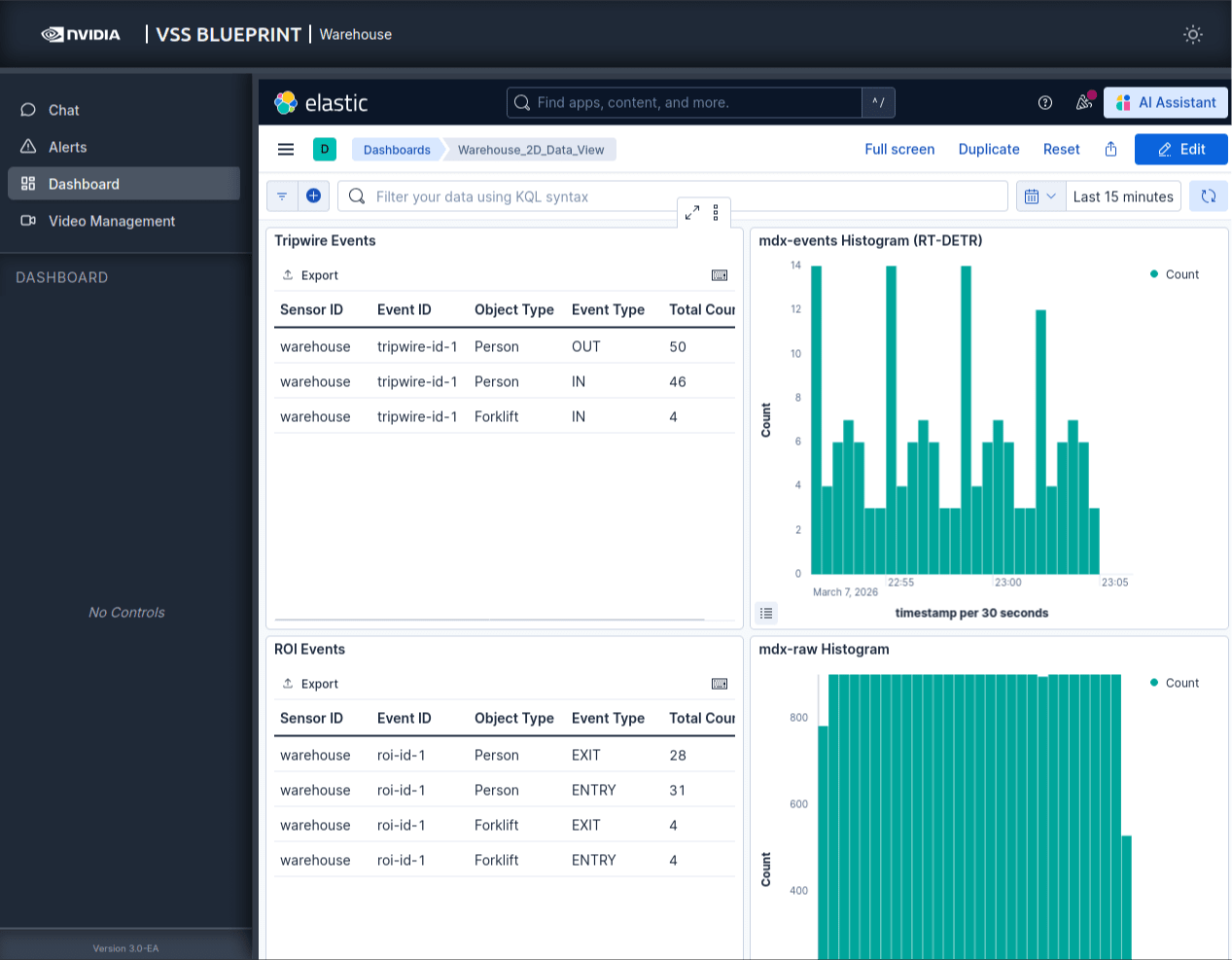
VLM パイプラインのハマりポイント
ところが、Behavior Analytics がインシデントを生成しているのに VLM の分析結果が Elasticsearch に届かない。ここからが EA ならではのデバッグです。原因を一つずつ潰していきました。
VST ストリーム ID ヘッダーの不正
Alert Bridge が VST から映像を取得する際、HTTP ヘッダーに streamId を付与するコードがあるのですが、このヘッダーが原因で VST が 503 を返していました。
- headers = {"streamId": stream_id}
- response = await client.get(url, headers=headers)
+ response = await client.get(url)
streamId は URL パラメータで渡すべきところが、ヘッダーとして二重送信されていたようです。
video_url の未初期化
Alert Bridge の enhance_alert_with_vlm.py で、VST から映像 URL を取得できなかった場合に video_url 変数が未定義のまま後続処理に渡り、UnboundLocalError で落ちていました。
+ video_url = None
try:
video_url = await get_video_from_vst(...)
except Exception as e:
logger.error(f"Failed to get video: {e}")
典型的な変数スコープの問題ですが、正常系でしかテストされていなかったのかも?
VLM エンドポイントの設定ミス
Alert Bridge の config.yaml で VLM のエンドポイントが外部 IP(デフォルト値のまま)を向いていて、接続タイムアウトになっていました。また、モデル名も旧版の cosmos-reason1-7b のままでした。
vlm:
base_url: "http://localhost:30082/v1" # ← コンテナはホストネットワーク
model: "nvidia/cosmos-reason2-8b"
num_frames: 5
num_workers もデフォルトの 10 から 1 に変更しました。単一 GPU 環境では VLM の並列処理数を抑えておいた方が安定します。
削除済みセンサーによるストリーム ID 解決の失敗
VSS Agent からインシデントレポートを生成しようとすると、VST MCP の sensor_list API が返すセンサー一覧に state: "removed" の古いセンサーが含まれていて、Agent が「warehouse」という名前で検索したときに削除済みのセンサーの stream ID を掴んでしまう問題がありました。
for sensor in result:
if isinstance(sensor, dict) and "sensorId" in sensor:
+ if sensor.get("state") == "removed":
+ continue
sensor_id = sensor["sensorId"]
sensor_objects[sensor_id] = sensor
4 カメラから 1 カメラに構成を変更した際に削除されたセンサーが API レスポンスに残り続けていたのが原因です。
加えて、Redis の dedup キー(TTL 300 秒)が再起動後も残っていて、同じインシデントの再処理がブロックされていました。redis-cli で vlm:warehouse:* キーを手動削除して解消しています。
VLM 分析結果
4 つのパッチを適用した結果、VLM-as-Verifier パイプラインが動き始めました。Cosmos-Reason2-8B が倉庫の映像を分析し、Elasticsearch の mdx-vlm-incidents インデックスに結果が蓄積されていきます。
推論時間は 1 件あたり 19〜30 秒程度。5 フレームを抽出して VLM に渡し、PPE(個人防護具)やヘルメットの着用状況、作業者の行動を分析しています。VLM は棚のラベル(C〜F)まで読み取って位置情報をレポートに含めてくれました。
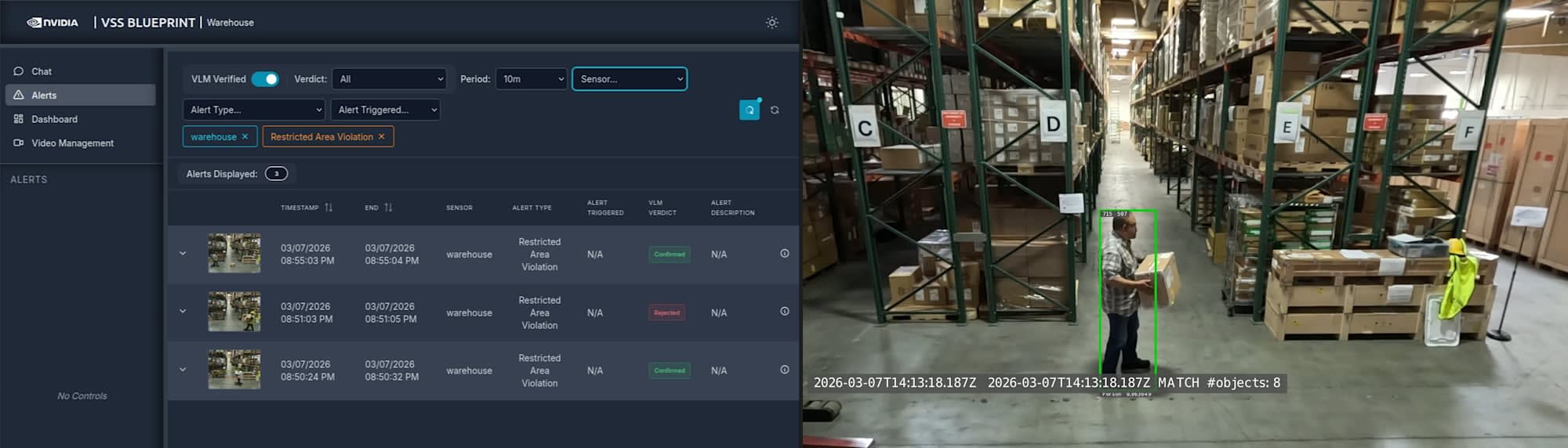
Agent によるインシデントレポート生成
VLM-as-Verifier で検証されたインシデントに対して、VSS Agent の Chat UI からレポートを生成できます。
Generate a report for incident <incident_id> with sensor id warehouse.
Agent は内部で複数の MCP ツールを呼び出し、インシデントの詳細情報、該当時刻のスナップショット、映像クリップを収集してレポートを生成します。
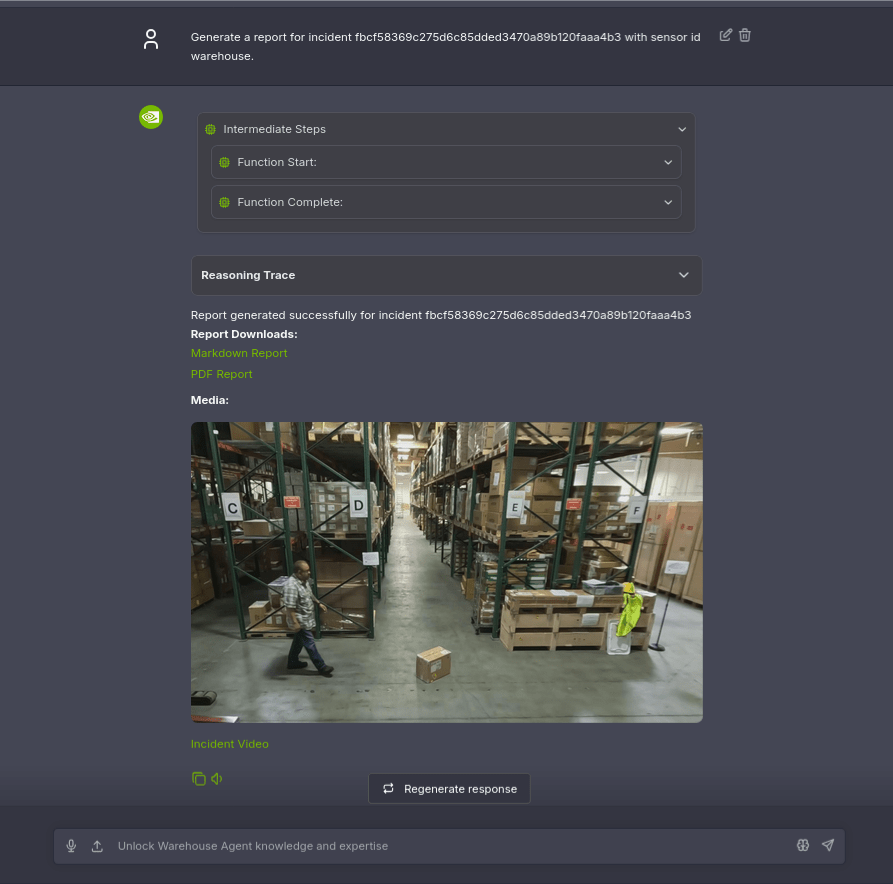
生成されたレポートは Markdown / PDF 形式でダウンロードでき、映像のスナップショットとクリップへのリンクも含まれます。VLM が「Box Retrieval」というインシデントタイプを判定し、棚 D 付近で作業者が段ボール箱を回収する状況を詳細に記述してくれました。床面のコンディション(smooth concrete)や照明条件(bright artificial lighting)まで含む構造化されたレポートです。
Agent が生成したレポートの抜粋
| Field | Value |
|---|---|
| Type of Incident | Box Retrieval |
| Detailed Description | A worker in a warehouse aisle (between shelves labeled "D" and "E") notices a cardboard box lying on the concrete floor. He retrieves it, carries it to shelf "D," and places it there before exiting the scene. |
| Location Description | Warehouse aisle flanked by tall green metal shelving units labeled alphabetically (C to F). |
| Light Condition | Bright artificial lighting. |
| Floor Condition | Smooth concrete. |
2.4.x では映像のベクター検索と自然言語 Q&A がメインの機能でした。3.0.0 ではルールベース検知 → VLM 検証 → 構造化レポート生成という安全監視ワークフローが MCP ベースで統合されていて、より実用的な方向に進化しています。
日本語 LLM への差し替え
今回は NIM の代わりに NGC vLLM を使っているので、--model パラメータを変えるだけで HuggingFace 上の任意のモデルに切り替えられます。せっかくなので、V1 でも使った Nemotron 9B-v2-Japanese に差し替えて試してみました。
docker run -d --name vllm-nemotron-jp \
--runtime nvidia --network host --shm-size 16g \
-e NVIDIA_VISIBLE_DEVICES=0 -e HF_TOKEN=$HF_TOKEN \
nvcr.io/nvidia/vllm:26.01-py3 \
python3 -m vllm.entrypoints.openai.api_server \
--model nvidia/NVIDIA-Nemotron-Nano-9B-v2-Japanese \
--served-model-name nvidia/nvidia-nemotron-nano-9b-v2 \
--trust-remote-code \
--enable-auto-tool-choice --tool-call-parser hermes \
--chat-template /tmp/nemotron_hermes_template.jinja \
--gpu-memory-utilization 0.2 --max-model-len 16384 --max-num-seqs 4 \
--port 30081
--served-model-name をデフォルトの Nemotron と同じにしておけば、VSS Agent 側の設定変更は不要です。
日本語で「あなたができることを教えてください」と聞いてみると、Agent が完全な日本語で応答してくれました。
こんにちは。私は倉庫のビデオ監視システムにおけるインシデント報告をサポートするルーティングエージェントです。以下のことが可能です:
- センサー/カメラの一覧表示
- リアルタイムの混雑状況の確認
- スナップショットの取得
- インシデントの一覧表示
- 詳細なインシデント報告
V1 では質問内容によって英語に戻ってしまうことがありましたが、3.0.0 + vLLM の構成では日本語が安定して維持されています。
インシデントレポートの日本語生成
Elasticsearch に蓄積されたインシデントデータを日本語モデルに渡してレポートを生成してみました。Nemotron 9B-v2-Japanese は thinking モードを持っているので、レポート生成時は /no_think でレスポンス全体をレポート本文に使えるようにしています。
結果はかなり実用的でした。立入禁止区域違反のインシデントデータを渡すと、以下のようなレポートが返ってきます。
インシデント概要
2026 年 3 月 8 日 午前 2 時 17 分 56 秒(UTC)に、倉庫施設内の限定エリア(Room-1)において、立入禁止区域違反のインシデントが発生しました。センサー「warehouse」により検知され、オブジェクト ID「329」が ROI 内に侵入したことが確認されました。推奨対応策
- 該当映像を速やかに関係者に共有し、侵入者の特定と動機の調査を実施してください。
- 立入禁止区域の監視範囲を拡大し、死角を解消するための追加カメラ設置を検討してください。
- アクセス権限の自動チェック機能を強化し、無許可エリアへの接近をリアルタイムで検知・警告するシステムの導入を推奨します。
UTC → JST の変換や、即時対応・中長期対策・法的対応の分類まで日本語で出力してくれました。9B パラメータでこの品質なら、現場向けの簡易レポートとしては十分使えそうです。
ただし、今回の検証では DGX Spark 1 台に 42 のマイクロサービスと vLLM を同居させているため、リソースが常にギリギリの状態です。Agent の Chat UI で回答が返ってくるまでに数分かかったり、ツールコールの途中でサービス間のタイムアウトが発生することもありました。
LLM 単体のレポート生成能力には問題がないので、これはモデルの限界というよりも 1 台にすべてを載せている環境の制約ですね。LLM や VLM を別ノードに分散配置できれば、日本語環境でも安定した運用ができそうです。
EA ならではの注意点
実際に動かしてみて気づいた EA 段階の制約をまとめます。
DGX Spark は単一 GPU(GB10)で動作するため、local_shared モードで LLM と VLM が同じ GPU を共有します。メモリ管理がシビアで、2.4.x のときと同様 Ollama 経由で LLM のメモリ消費を抑える工夫が有効かもしれません。
3.0.0 の新機能である Cosmos-Embed1(動画 + テキスト統合 Embedding)は英語のみで訓練されていて、日本語テキストでの検索は性能が劣化する可能性が高い点には注意が必要です。テキストの最大トークン数も 128 と短めです。この Cosmos-Embed1 を使ったベクター検索を行う search プロファイルも Alpha 状態で、今回の Warehouse Blueprint(bp_wh)ではデフォルトで Behavior Analytics による CV ベースのイベント検出が使われます。
2.4.x の config.yaml や REST API は 3.0.0 と互換性がなく、マイグレーションガイドも現時点では未提供です。2.4.x で構築した環境をそのまま移行することはできません。DGX Spark 固有の問題としては、前述のとおり LLM NIM の ARM64 イメージが動作しないのがデプロイのブロッカーでした。NGC vLLM + カスタムテンプレートで代替できましたが、Perception モデルの手動配置も含めて EA ならではの手作業は覚悟が必要です。
公式リリースノートに記載されている既知の問題もいくつかあります。VA-MCP の初期化遅延は、HuggingFace に未認証でリクエストすると HTTP 429(Rate Limit)が返ってくることが原因で、.env に HF_TOKEN を設定すれば解消します。スナップショットのタイムスタンプにもフレーム抽出の実装制限による若干のズレが生じることがあるようで、次リリースで修正予定とのことです。
まとめ
VSS 3.0.0 EA を DGX Spark で動かしてみました。
2.4.x で感じていた「モノリシックゆえの融通の利かなさ」が、マイクロサービス化と MCP ベースのオーケストレーションで解消に向かっています。42 サービスが連携する構成は初見では複雑に見えますが、compose プロファイルで必要な機能だけを選べる設計は良い方向ですね。
EA 段階ならではのハマりどころもいくつかありました。LLM NIM の ARM64 イメージが壊れていたり、Perception 用モデルがパッケージに含まれていなかったり、Alert Bridge に 4 箇所のコードバグがあったり。ただ、NGC vLLM + カスタムテンプレートでの LLM 代替、NGC からのモデル手動配置、Alert Bridge のパッチ適用と、それぞれ回避策を見つけることで DGX Spark 単体で映像 AI パイプラインを一通り動かすところまで持っていけました。
個人的に一番手応えがあったのは VLM-as-Verifier パイプラインです。CV でインシデント候補を高速に絞り込み、VLM で映像を見て検証するという 2 段階構成は、誤検知を減らしつつ深い分析を行うアプローチとして実用性が高いと感じています。Agent によるレポート生成まで含めて一気通貫で動いたのは、かなり完成度が高い印象でした。
一方で、DGX Spark 1 台にすべてを載せる運用の限界も見えました。42 サービス + LLM + VLM が同居する環境では GPU メモリも CPU も常に高負荷で、Agent のチャット応答に数分かかったり、サービス間通信のタイムアウトが発生することがありました。
ただ、これは 3.0.0 のマイクロサービス構成がうまく効いている裏返しでもあります。2.4.x のモノリシック構成では分散配置自体が難しかったのに対し、3.0.0 なら LLM や VLM を別ノードに切り出すだけでボトルネックを解消できます。複数台構成で負荷を分散すれば、現場投入にもかなり近づくのではと感じました。










