
源内 AI アプリリポジトリの Google Cloud 法制度AIアプリ(Lawsy-Custom-BQ)を AWS に移植してみた
いわさです。
先日、源内 AI アプリリポジトリの Google Cloud 版法制度AIアプリ(Lawsy-Custom-BQ)をデプロイして源内 Web から ExApp として使ってみる記事を書きました。
このアプリは法令に関する質問を受け取り、AIが意図を解析して最適化されたレポートを動的に生成するサーバーレス API システムです。
源内を使いたいという時、この法令検索アプリを使いたいケースが多いと思います。
しかし、この法制度 AI アプリは仕組みとして BigQuery ML のベクトル検索と Gemini を組み合わせて、データはアップロードした日本の法令データ(e-Gov)を使っているので、現状のテンプレートどおりに源内をセルフデプロイして使おうとすると、源内 Web は AWSですが、Lawsy-Custom-BQ は Google Cloud を使う必要があるので、マルチクラウド構成が必須になってしまいます。
マルチクラウド構成でもまぁ良いのですが、ひとつにまとめれると嬉しいなぁという時もあると思います。
ということで今回は、Google Cloud 版の Lawsy-Custom-BQ を AWS に移植してみましたので紹介します。
移植方針とアーキテクチャ
まず移行にあたって現状の Lawsy-Custom-BQ で使われているコンポーネントごとに次のように AWS サービスなどを選定しました。
| 役割 | Google Cloud版 | AWS版(LawsyAws) |
|---|---|---|
| レポート生成 AI | Gemini 2.5 Flash | Claude Haiku 4.5(Amazon Bedrock) |
| ベクトル検索 | BigQuery ML | Amazon S3 Vectors |
| テキストのベクトル変換 | Vertex AI Embeddings (gemini-embedding-001) | Amazon Titan Text Embeddings V2 |
| API バックエンド | Cloud Functions | AWS Lambda |
| API エンドポイント | API Gateway (GCP) | Amazon API Gateway + WAF |
| Web検索による法令名補完 | Gemini Web Grounding | (未実装・後述) |
AWS と Google Cloud でサービスごとの機能が違っており、当然ながら完全に互換性があるわけではないです。
特にモデルについてはどうしたらいいか悩みました。
Google Cloud 版で使われている Gemini 2.5 Flash は、Google が「価格性能比に優れたモデル」と位置づけているモデルです。
入力 $0.30/1Mトークン、出力 $2.50/1Mトークンという価格帯で、100万トークンのコンテキストウィンドウを持ち、大量のテキストを高速に処理するユースケースに向いているらしい。
一方、AWS の Bedrock で利用できるモデルの中で、価格帯と速度のバランスが最も近いのは Claude Haiku 4.5 かなぁと思いました。
Sonnet 4 も試しましたが、1リクエストあたり50秒かかり API Gateway のタイムアウト(29秒)を超えてしまいました。
Haiku 4.5 では同じ処理が19秒で完了し、コストも約1/3になるため、今回はこちらを採用してみました。
BigQuery の部分は何かしらベクトル検索できるデータストアが必要だったのですが、Google Cloud 側がサーバーレス構成だったので AWS 側では S3 Vectors を今回は選んでみました。ランニングコストとの兼ね合いになりますが、OpenSearch は候補ではありました。
また、BigQuery では法令データの差分更新やバージョン管理を行うために 3層構造(Source層・DWH層・App層)でデータを管理していたのですが、今回は初回一括投入のみで差分更新は諦めて、以下のようにシンプルな構成にしました。
- S3 Vectors: 法令名のベクトルを格納。ユーザーのクエリから推定した法令名で類似検索し、該当する法令を特定する
- S3: 法令ごとの条文データを JSON ファイルとして格納。特定した法令番号をキーに条文を取得する
ここは改良の余地がありそう。
あとは、Google Cloud 版では Webグラウンディング(インターネット検索した最新知識をベースに回答する)を使って最新の法令名を確認し、その後ベクトル検索に使っています。
これが、調べた感じだとどうやら AWS の Bedrock では Claude に対して同等の Web検索機能が提供されていないようでした。
なお、Amazon Nova には Web Grounding という同等の機能が存在するのですが、本日時点では US リージョン限定で東京リージョンでは利用できないようです。
Web Grounding is currently only available in US regions and supported only by US CRIS profiles.
そのため今回は LLM の学習データに含まれる知識のみで法令名を推定しています。
主要な法令(デジタル社会形成基本法、個人情報保護法、民法など)は問題なく推定できていますが、廃止法令の判定や最新法令への対応は弱い可能性があります。ここも改善したいなぁ。
アーキテクチャ構成
以上から今回構築する構成は以下となります。
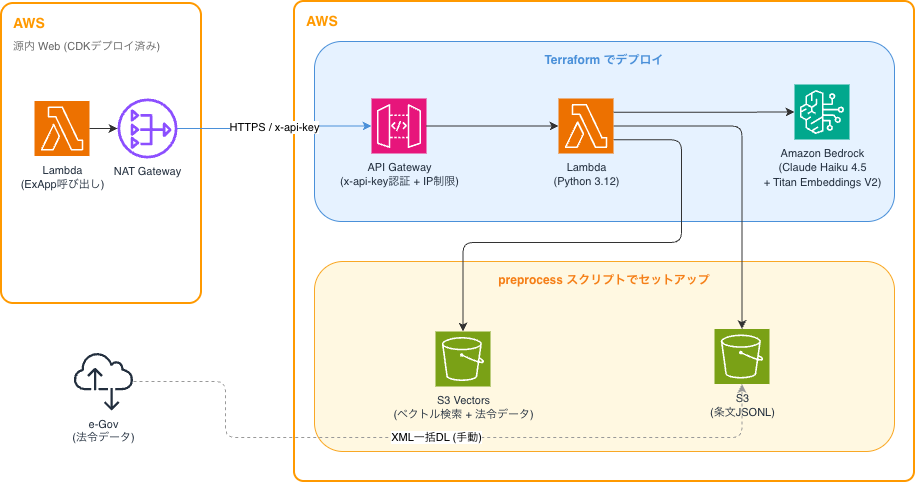
Google Cloud 版と同様に完全サーバーレス構成で、利用していない時間のコストがほぼゼロです。
構成は大きく2つのデプロイ方法に分かれています。CDKにしようか悩みましたが Google にあわせて Terraform + スクリプトで構成してみました。
Terraform でデプロイされる部分:
- API Gateway(x-api-key 認証 + WAF による IP 制限)
- Lambda(Python 3.12)
- IAM ロール・ポリシー
preprocess スクリプトでセットアップされる部分:
- S3 Vectors(法令名のベクトル検索用)
- S3(法令の条文データ格納)
源内 Web のバックエンド Lambda が VPC 内から NAT Gateway 経由で LawsyAws の API Gateway にリクエストを送ります。
移植版を動かしてみる
一応移植して動作確認を軽くしたコード一式を以下のリポジトリに格納しておきました。
細かい手順は割愛しますがデプロイは以下の流れで行います。
- データ準備: e-Gov から法令 XML を一括ダウンロード(約276MB、10,212件)し、preprocess スクリプトで条文データを JSON に変換
- S3 Vectors セットアップ: AWS CLI で S3 Vectors バケット・インデックスを作成し、法令名のベクトル(7,799法令分)を投入。条文データは S3 にアップロード
- Terraform デプロイ: Lambda、API Gateway、WAF、IAM ロール等を
terraform applyで作成
当初は Google Cloud 版の BigQuery のように、S3 Vectors に法令名ベクトル(検索用)と条文データ(検索対象ではないが付随情報として保持したい)を同じインデックスに入れようとしました。
しかし S3 Vectors ではインデックスに格納するすべてのデータに有効なベクトルが必要で、「検索対象ではないがメタデータだけ持たせたい」という使い方ができないようでした。(そうなのか)
そのため、条文データは通常の S3 に JSON ファイルとして格納し、法令番号をキーに取得する方式に変更しています。
機能的には Google Cloud 版と同等で、法令番号で条文を取得できる点は変わりません。
ただし、Google Cloud 版の BigQuery では条文単位でのフィルタ取得が可能ですが、AWS 版では法令単位での一括取得になってしまいました。
源内 Web のチーム管理画面から AWS 版 Lawsy-Custom-BQ を ExApp として登録し、動作確認しました。
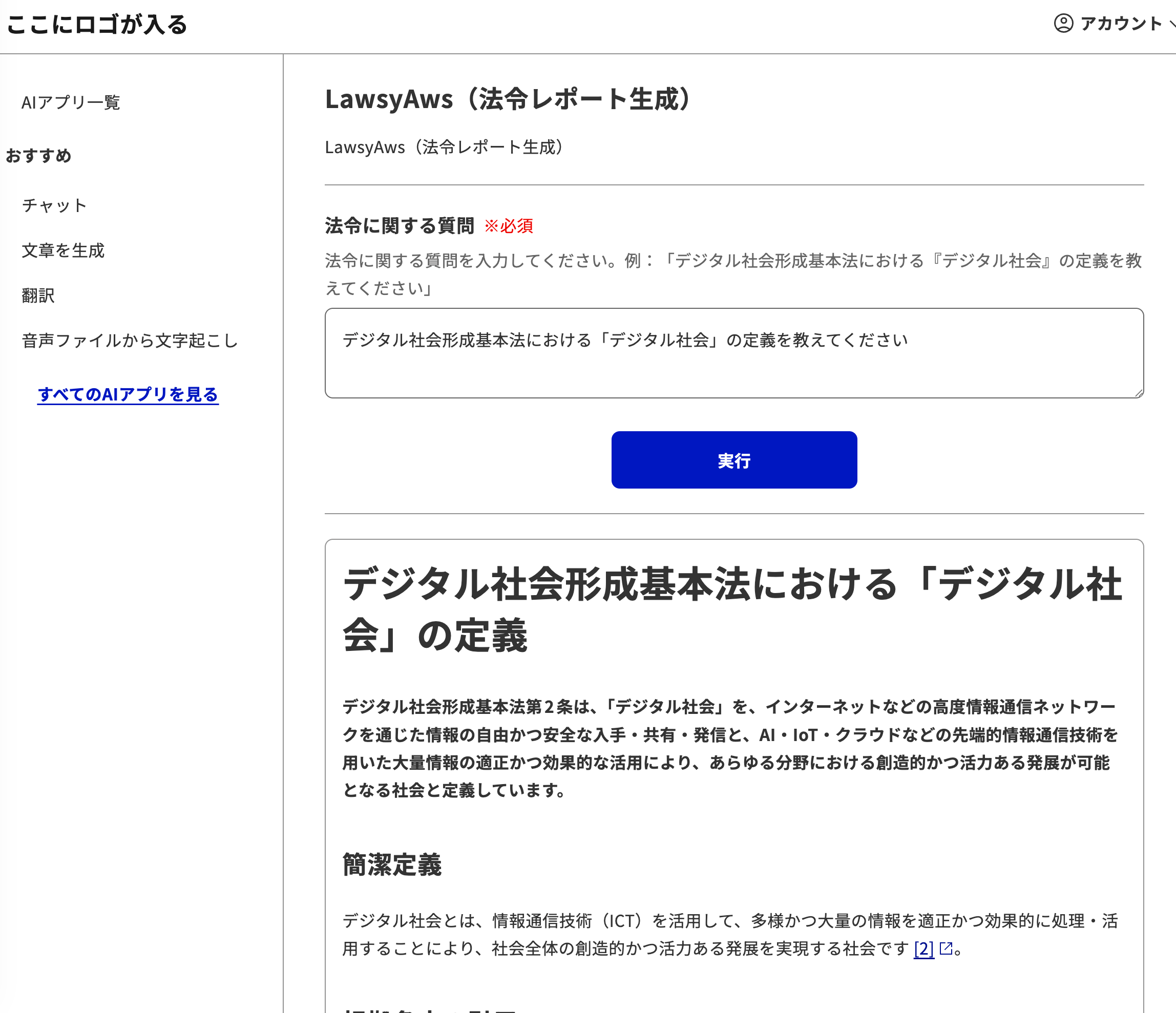
「デジタル社会形成基本法における『デジタル社会』の定義を教えてください」というクエリに対して、法令の条文を正確に引用した構造化されたレポートが返ってきています。
処理時間は約19秒でした。
API Gateway の REST API は統合タイムアウトがデフォルト最大29秒です。
Google Cloud 版では Cloud Functions のタイムアウトが最大540秒、API Gateway にもこのような厳しい制限がないため、問題になりませんでした。
AWS 移植版を最初テストしたところ、大きな法令(個人情報保護法など180条以上)を処理すると29秒を超えることがありました。
対策として、AI が選択した条文の入力を上位20件に制限することで処理時間を短縮しています。
なお、この20件制限は Google Cloud 版にも同様に存在する制限です(_parse_ai_selection で最大20件)。
また、REST API のタイムアウト上限は申請により最大300秒まで緩和可能なので、そのあたりも検討したほうが良いかもしれない。
ランニングコスト試算
ランニングコストの試算もしてみました。
| サービス | 料金体系 | 月額目安(月100リクエスト想定) |
|---|---|---|
| Lambda | リクエスト + 実行時間従量課金 | 無料枠内 |
| API Gateway | $1/100万リクエスト | 無料枠内 |
| S3 Vectors | $0.06/GB(ストレージ)+ クエリ従量 | $0.01未満(32MB) |
| Bedrock (Claude Haiku 4.5) | 入力$1/1M + 出力$5/1Mトークン | 約$5 |
| Bedrock (Titan Embeddings V2) | $0.02/1Mトークン | $0.01未満 |
| S3 (条文データ) | $0.025/GB | $0.03(1.1GB) |
検証用途では月額 $5程度 で運用可能です。
ほとんどが Bedrock の推論コストで、インフラ部分はほぼ無料です。悪くないのではないか。
さいごに
本日は源内 AI アプリリポジトリの Google Cloud 版 Lawsy を AWS に移植して、源内 Web から ExApp として呼び出せるところまで確認してみました。
S3 Vectors + Bedrock + Lambda の完全サーバーレス構成で、Google Cloud 版と近い法令レポート生成機能を AWS 単独で実現できました。
Web検索による法令名補完が使えない点は制限事項として残りますが、実用上は Claude の知識だけでも主要な法令の推定は問題なく動いています。法改正とかに対応できない可能性があるので長期的に利用するのであればこのあたりは解決策の実装を考えないといけないですね。
AWS だけで源内 + 法令検索を完結させたいケースでは選択肢になりそうです。
Nova の Web グラウンディング が東京リージョンに来たら法令名推定の精度も上げられそうなので、そのあたりのアップデートにも期待したいところです。









