
メタデータ管理をデータベースで担う新しいLakehouseフォーマット「DuckLake」が発表されました
さがらです。
DuckDBの公式ブログにおいて、メタデータ管理をデータベースで担う新しいLakehouseフォーマット「DuckLake」が発表されました。
本記事では、DuckLakeがどういったものか簡単に紹介し、ローカルで軽く触ってみたのでその内容をまとめてみます。
DuckLakeとは
まずDuckLakeですが、DuckDBの開発元が開発したOSSのLakehouseフォーマットとなっております。
昨今のIcebergやDelta Lakeではファイルベースでメタデータを管理するという複雑性があったことを課題認識し、そのメタデータ管理を担うレイヤーをIcebergでいうカタログレイヤーも含めて全てSQLデータベースで担う方向性で実装したプロダクトが、DuckLakeとなっております。
DuckLakeのメリットとして、以下4つが上述のリンク先のブログで言及されています。
- Simplicity
- DuckLakeをラップトップPCで実行するには、DuckDBをインストールしてDuckLakeの拡張機能を使用するだけでOK(この場合はDuckDBのローカルファイルがカタログ管理・メタデータ管理を担う)
- AvroファイルもJSONファイルもなく、すべてのメタデータ管理はデータベースのテーブルで制御
- Scalability
- ストレージ、コンピュート、メタデータ管理、の3つを分離したアーキテクチャ
- Speed
- 従来のOpen Table Formatと異なりファイルI/Oが必要ではない
- 小規模な変更に対して書き込むファイル数を削減、同時に発生した変更も対応可能
- Features
- SQLをベースに操作でき、ACID準拠のトランザクション、列の追加・削除・データ型の変更、が可能
- DuckLakeがストレージに書き込むデータと削除ファイルはIcebergと互換性があるためメタデータのみの移行が可能
- DuckLakeのコンピュートノードについてはDuckDBの拡張機能として同時にリリース済(DuckDB v1.3.0から利用可能)
公式HPとGitHubのリポジトリは、以下からリンク可能です。
試してみた
ローカル環境で簡単に、DuckLakeを試してみます。
下記の公式ドキュメントに沿って試していきます。
検証環境
- Windows 11
- DuckDB v1.3.0
- このブログに沿って、exeファイルで起動
インストール
まず、DuckLakeをインストールします。
INSTALL ducklake;
DuckLakeのデータベースを新規作成
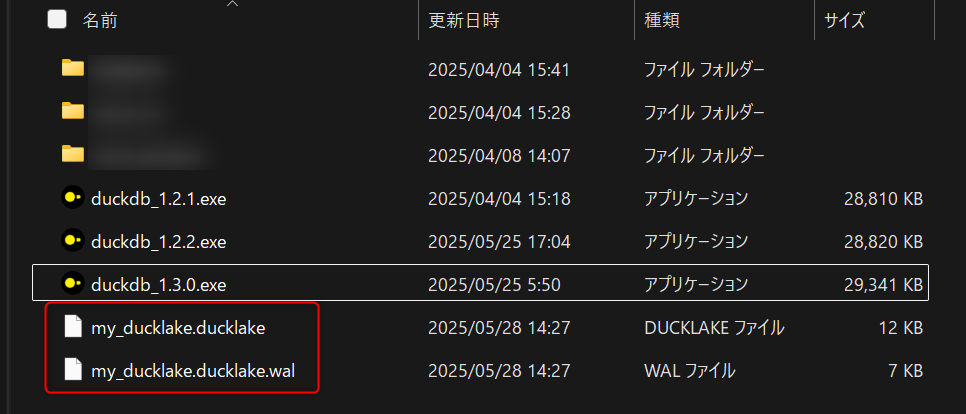
以下のコマンドを実行し、DuckLakeのデータベースを新規作成します。特にパスを指定せずに実行すると、exeファイルを起動した場所にDuckDBのデータベースファイルが作成されます。
ATTACH 'ducklake:my_ducklake.ducklake' AS my_ducklake;
新しいテーブルを作成
以下のコマンドを実行し、公開されているcsvファイルを元にテーブルを作成してみます。
USE my_ducklake;
CREATE TABLE nl_train_stations AS
FROM 'https://blobs.duckdb.org/nl_stations.csv';
この段階で、DuckDBのデータベースファイルが作成された場所と同じ階層に、フォルダが追加されます。フォルダ内を見ると、parquetファイルが作られていることがわかります。
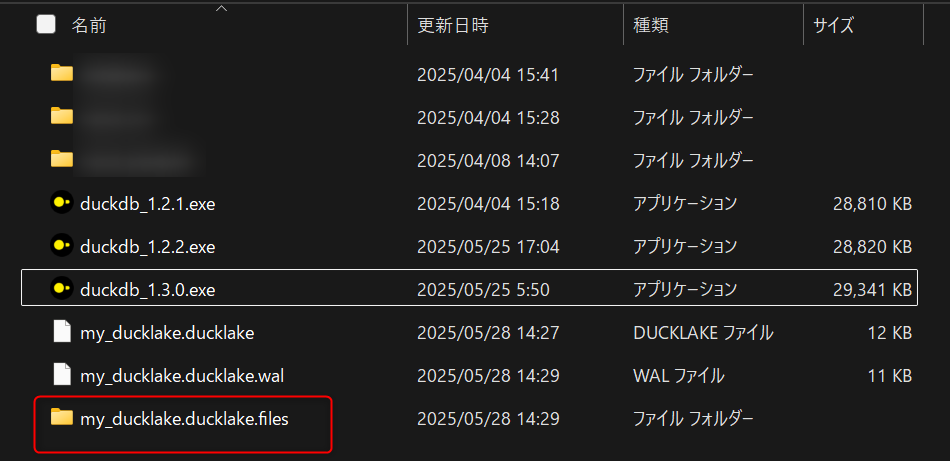

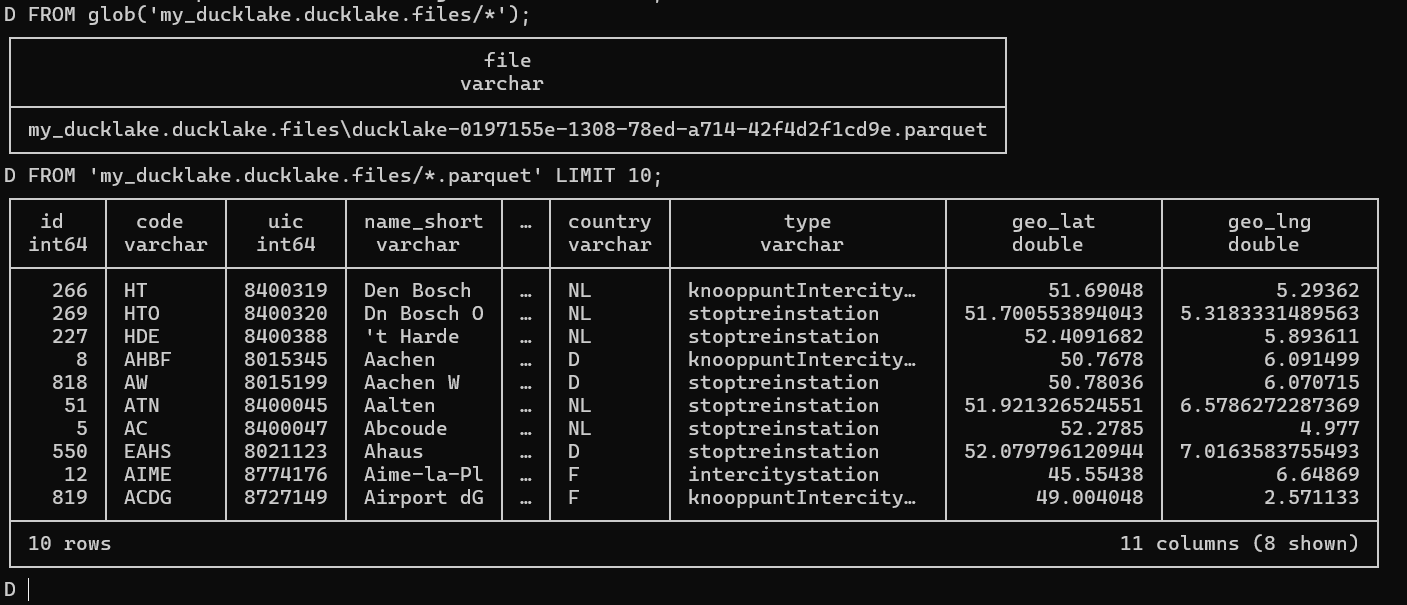
parquetファイルの中身も、以下のクエリで見ることができます。
FROM glob('my_ducklake.ducklake.files/*');
FROM 'my_ducklake.ducklake.files/*.parquet' LIMIT 10;
テーブルに対してUPDATE処理を実行
次に、テーブルに対してUPDATE処理を実行した際にどのような挙動となるかを確認してみます。
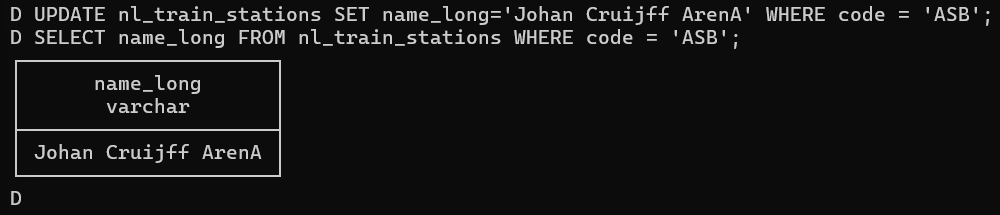
以下のクエリを実行すると、駅名を変更するUPDATE文が実行されます。
UPDATE nl_train_stations SET name_long='Johan Cruijff ArenA' WHERE code = 'ASB';
SELECT name_long FROM nl_train_stations WHERE code = 'ASB';
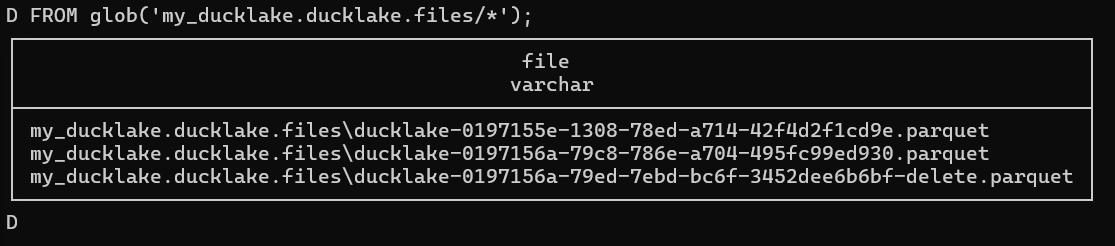
すると、このDuckLakeに関するデータを保持するフォルダ上で、新しいparquetファイルが生成されます。以下のクエリでファイル一覧を確認可能です。
新しいparquetファイルが2つ追加されていますね。UPDATEが行われたので新しいレコードを保持するparquetファイルと、古いレコードを保持するためのparquetファイルが-deleteという接尾詞付きで追加されたことがわかります。
FROM glob('my_ducklake.ducklake.files/*');
DuckLakeでは他のOpen Table Formatと同じく過去の差分を保持するためのSnapshotが記録されます。DuckLakeではテーブルでSnapshotが記録されるため、以下のクエリでSnapshotの内容を確認可能です。
FROM my_ducklake.snapshots();

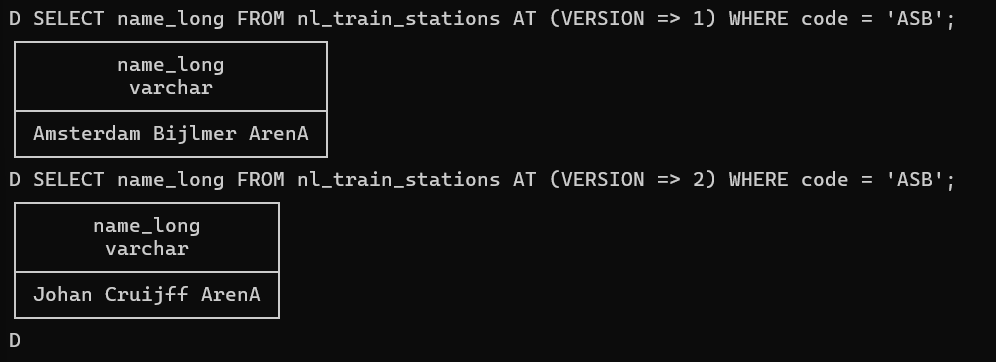
この上で、Snapshotを用いて過去のある時点のテーブルに対してクエリを行うことも可能です。以下のクエリでは、VERSION => 1でUPDATE前、VERSION => 2でUPDATE後、のデータを確認可能です。
SELECT name_long FROM nl_train_stations AT (VERSION => 1) WHERE code = 'ASB';
SELECT name_long FROM nl_train_stations AT (VERSION => 2) WHERE code = 'ASB';
最後に
簡素な内容ではありますが、DuckLakeを紹介しつつ、実際に公式ドキュメントに沿ってDuckLakeを試してみました。
「ストレージ上はparquet、データベースでSnapshot含めたメタデータを全て管理」というシンプルな構成なので、謳い文句どおりSQLで全て確認できるのがとても良いですね!!
今後DuckLakeがどのように発展してエコシステムを構築していくか楽しみです!









