EC2 × ComfyUI × Flux.1 dev で、お手頃に「可愛い赤ちゃんペンギン」画像を出力してみた
はじめに
最近、4 歳の息子が AI で生成された赤ちゃんペンギンのショート動画にハマっています。
見ているうちに私もそのかわいさに引き込まれ、自分でも作ってみたいと思い、試してみることにしました。
今回は動画ではなく画像までで、高精度な出力ができると評判の Flux.1 dev モデルを使って、画像生成 AI 用 UI の ComfyUI 上で試してみることにしました。
手元の Mac ではスペック不足だったため、AWS EC2 の GPU インスタンスを活用しています。
構成
画像生成用ソフトウェア・モデル
ComfyUI
Comfy UI はローカルで画像・動画生成 AI モデルを動かすための UI を提供する OSS アプリケーションです。
ノードを組み合わせて、視覚的にワークフローを構築できます。
機械学習や画像生成 AI について専門的に勉強したことがないため私が自力でワークフローを組むのは難しいですが、
インターネット上で識者によるワークフロー設定が配布されているため非常に助かりました。
Flux.1 dev
Flux.1 は、Black Forest Labs によって開発された Text to Image で画像を生成するためのローカルで使える高品質な AI モデルです。
Flux.1 の中で最高品質である Flux.1 pro は有償ですが、dev は非商用であれば無償で使うことができます。
サーバー
Amazon EC2(g6.2xlarge)
Flux.1 dev を手持ちの Mac 端末で動かすのは厳しかったため クラウドのコンピュートリソース を使って立ち上げることにしました。
インスタンスタイプ g6.2xlarge であれば、メモリ 32 GiB のマシンを時間単価約$1.4(東京リージョン・2025.4 現在) で使用することができます。
また、セットアップ完了後は AMI を作って使いたいときにスポットインスタンスで起動することができれば更なるコスト削減も狙えます。
サーバー構築
先人のブログをヒントに EC2 を構築します。
クォータ値の引き上げ
G 系インスタンスを起動するには AWS へ申請が必要です。
今回利用したい g6.2xlarge インスタンスは 1 台あたり 8 VCPU 割り当てのため、
Service Quotas から 以下のクォータ値を 8 に引き上げるリクエストを事前に済ませておく必要があります。
- Running On-Demand G and VT instances
- All G and VT Spot Instance Requests (スポットインスタンス利用予定がある場合)
この申請をしないと、インスタンスの起動時に VcpuLimitExceeded エラーが発生し、インスタンスを起動することができません。
引き上げには数時間〜数日かかる可能性もあります。
間違えた場合のタイムロスが大きいため、必ず EC2 を利用する予定のリージョンでリクエストしていることを確認してください。

Service Quotas 画面から現在の制限を確認(初期は0)
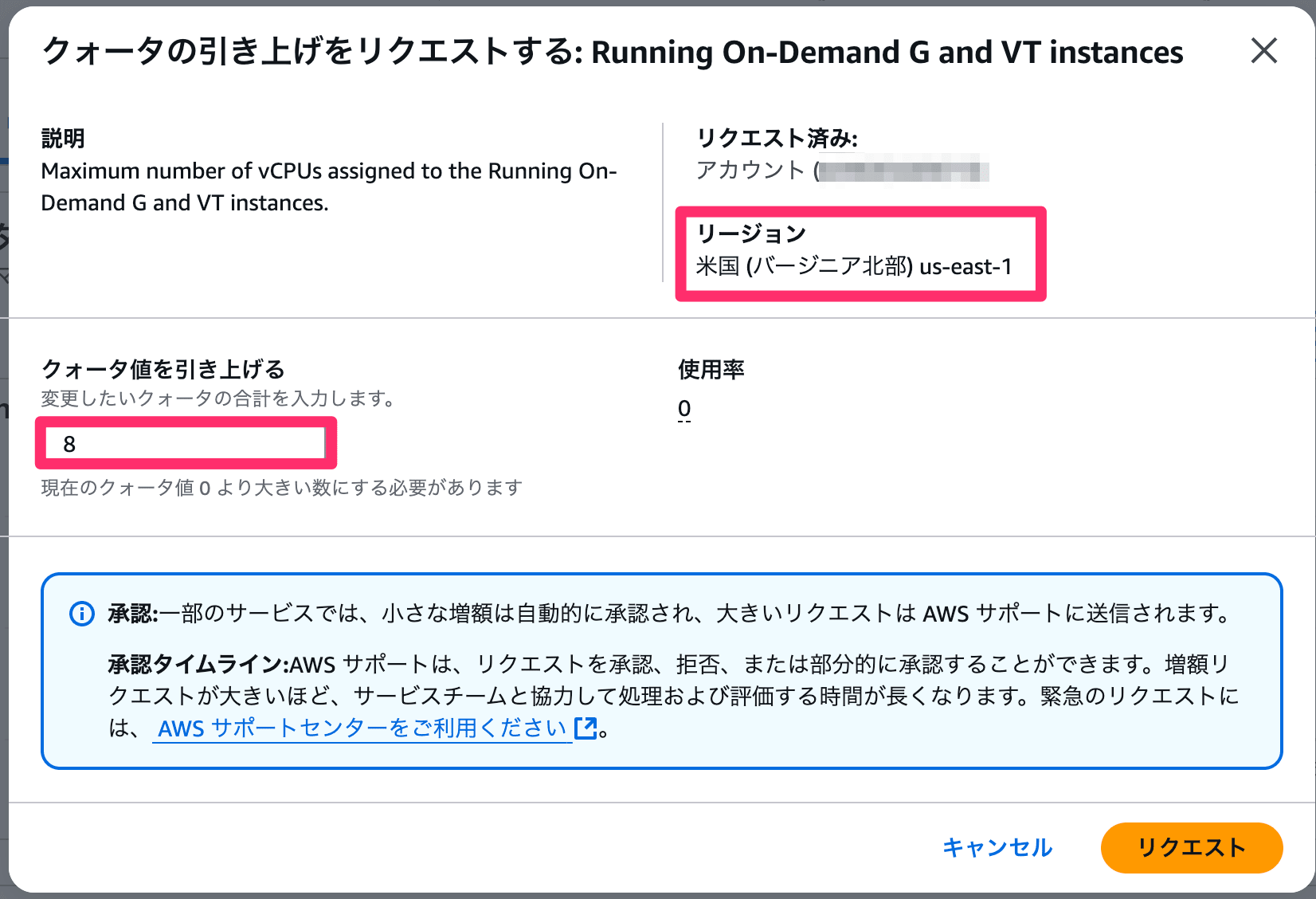
VCPU数とリージョンをよく確認してください
インスタンス起動
本記事は Amazon EC2 を構築したことある人を対象としているため具体的な手順は割愛しますが、
はじめて EC2 を構築する方は公式ドキュメントを参照しながらやってみてください。
(g6.2xlarge インスタンスは無料利用枠対象外となり、有料です)
今回の設定パラメータは以下のとおりとしました。
| 項目 | 設定内容 |
|---|---|
| インスタンスタイプ | g6.2xlarge |
| AMI | Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.3.1 (Amazon Linux 2) 20250323 |
| セキュリティグループ(インバウンド) | SSH (TCP 22)、カスタム (TCP 8188) |
| ストレージ | 120GB |
セットアップ
ComfyUI のインストール
EC2 に SSH で接続したら、GitHub リポジトリから ComfyUI をインストールします。
$ git clone https://github.com/comfyanonymous/ComfyUI.git
$ cd ComfyUI
$ python -V
Python 3.12.9 # 3.12推奨
$ pip install -r requirements.txt
Flux.1 dev モデル・関連ファイルの入手
ComfyUI の起動前に Flux.1 dev モデルおよび関連ファイルを導入しておきます。
※ CLIP ファイルを配布している comfyanonymous 氏は ComfyUI の開発者です。
| 種類 | ファイル名 | ダウンロード URL(Hugging Face) | 配置ディレクトリ | サイズ |
|---|---|---|---|---|
| モデル本体 | flux1-dev.safetensors |
black-forest-labs/FLUX.1-dev | ComfyUI/models/diffusion_models/ |
23G |
| VAE | ae.safetensors |
black-forest-labs/FLUX.1-dev | ComfyUI/models/vae/ |
320M |
| CLIP | t5xxl_fp16.safetensors |
comfyanonymous/flux_text_encoders | ComfyUI/models/clip/ |
9.2G |
| CLIP | clip_l.safetensors |
comfyanonymous/flux_text_encoders | ComfyUI/models/clip/ |
235M |
CLIP ファイル は認証不要で手に入るため 直接 EC2 から wget コマンドで DL しました。
# EC2の中から
$ wget -P ~/ComfyUI/models/clip/ https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors
$ wget -P ~/ComfyUI/models/clip/ https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors
モデル本体と VAE ファイルは認証が必要なため、一度ローカル端末に落としてから SCP でコピーしました。
# ローカル端末のDLフォルダから
$ scp -i "~/.ssh/MyKeyPair.pem" flux1-dev.safetensors ec2-user@ec2-xx-xx-xx-xx.ap-northeast-1.compute.amazonaws.com:/home/ec2-user/ComfyUI/models/diffusion_models
$ scp -i "~/.ssh/MyKeyPair.pem" ar.safetensors ec2-user@ec2-xx-xx-xx-xx.ap-northeast-1.compute.amazonaws.com:/home/ec2-user/ComfyUI/models/vae
ComfyUI 起動・接続
$ cd ~/ComfyUI
$ python main.py --listen
サーバーが起動し、ローカル端末のブラウザからインターネット経由で アクセスすることができました。
http://(EC2のグローバルIPアドレス):8188/
ワークフローの設定
上記参考ページの一番上にある狐の女の子の画像を保存し、
ComfyUI の画面にドラッグするだけで Flux.1 dev 用のワークフローが読み込めます。
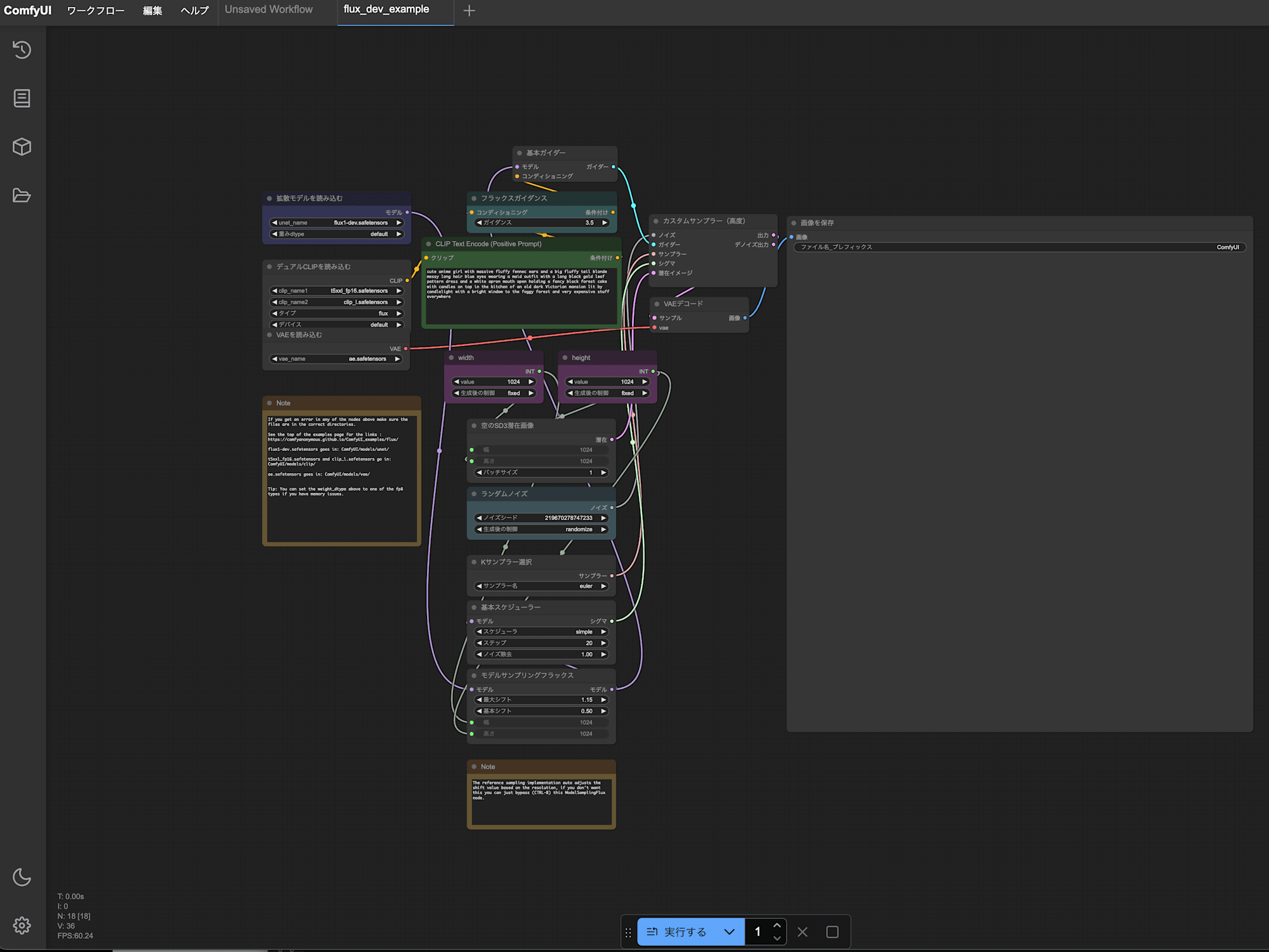
このまま実行したところ VRAM 不足でエラーが発生したため、
モデルの重みdtype設定をより軽量な fp8_e4m3fn_fastに変更しました。

画像生成してみた
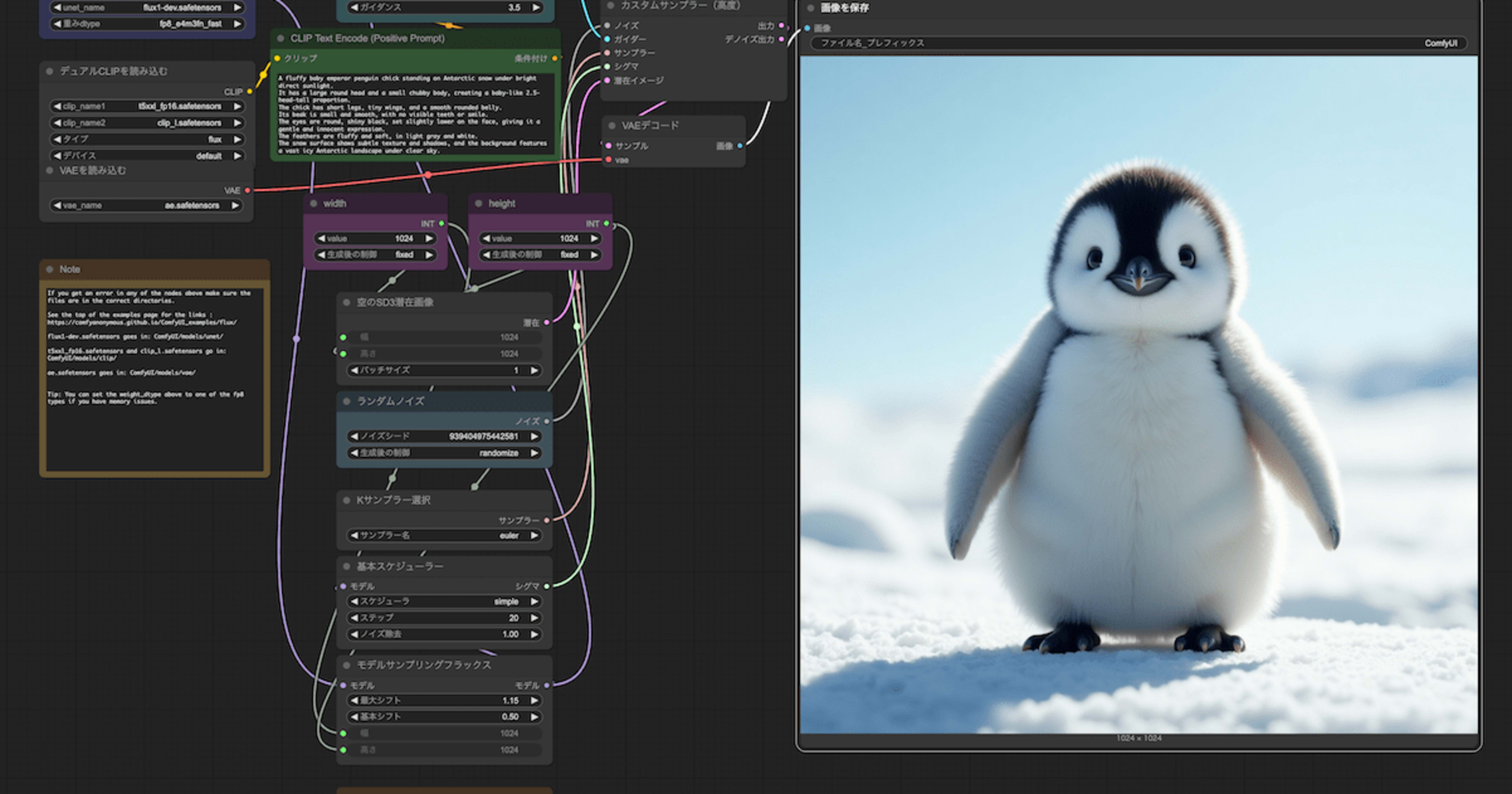
CLIP Text Encode欄に ChatGPT に手伝ってもらって作ったプロンプトを入れて「実行」をクリック。
しばらく待てば生成されました。
A fluffy baby emperor penguin chick standing on Antarctic snow under bright direct sunlight.
It has a large round head and a small chubby body, creating a baby-like 2.5-head-tall proportion.
The chick has short legs, tiny wings, and a smooth rounded belly.
Its beak is small and smooth, with no visible teeth or smile.
The eyes are round, shiny black, set slightly lower on the face, giving it a gentle and innocent expression.
The feathers are fluffy and soft, in light gray and white.
The snow surface shows subtle texture and shadows, and the background features a vast icy Antarctic landscape under clear sky.
Cinematic shallow depth of field.
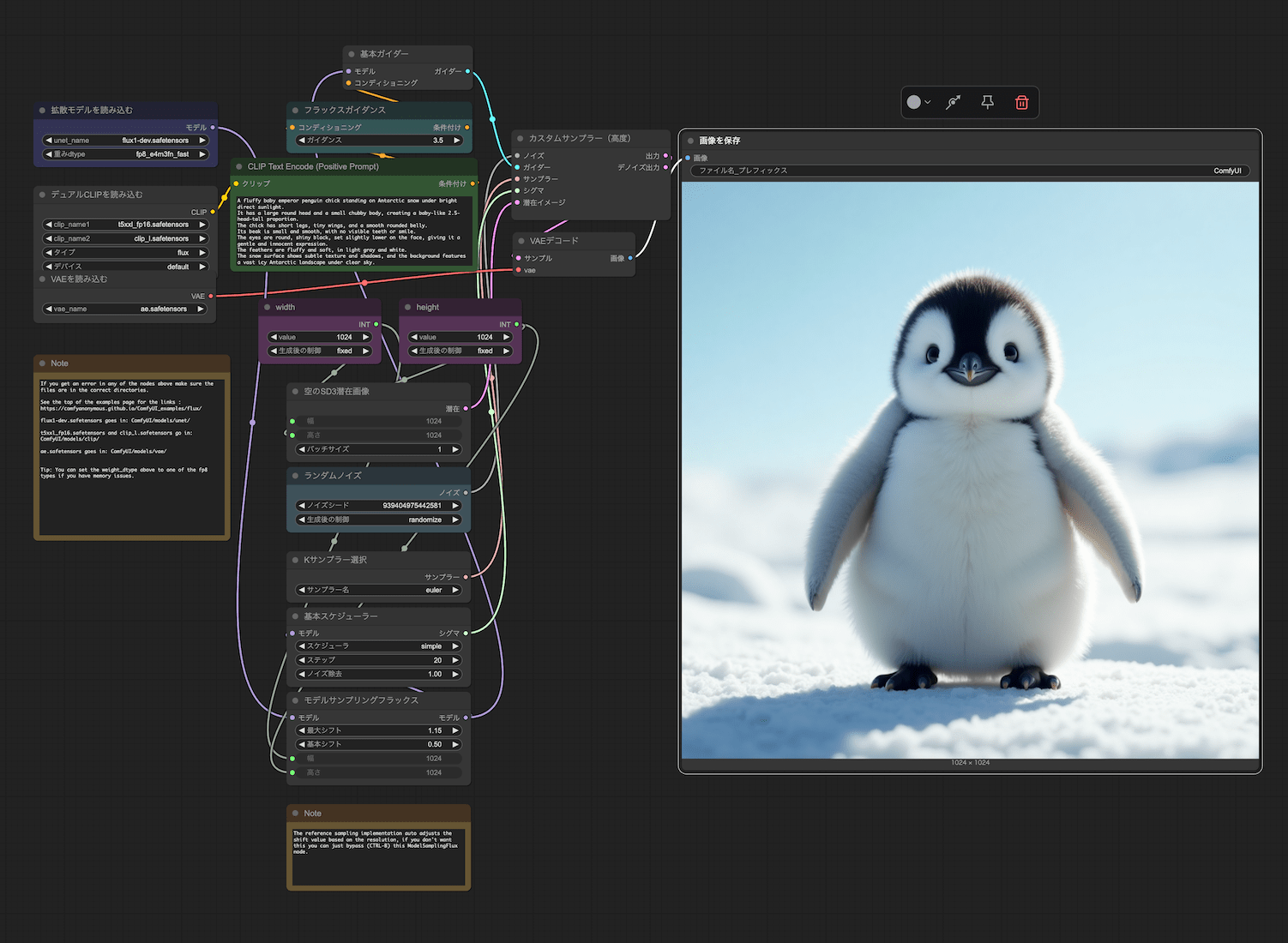
かわいい!
初回のみモデルの読み込みに時間がかかり 生成に 330 秒ほど要しました。
2 回目以降は 80 秒前後で生成完了するようになりました。
成果物のクオリティを多少下げて良ければ、より低リソースで利用できる fp8 用モデルを使うことでより高速な画像生成ができそうです。

サムネ用に作った他の画像など
スポットインスタンスの設定
ここまで設定したインスタンスから AMI を作成しておきました。
お遊び用途ということで予期しないサーバ停止も許容できるのであれば、かつAWS側にインスタンスリソースの空きがあれば
次回以降の起動時にはこの AMI をスポットインスタンスとして起動することでより低コストで画像生成を楽しめます。
まとめ
EC2 を使って手元の PC のリソースが心もとなくとも画像生成を楽しむことができました。
今回作った画像を元に Image to Video で動画の生成にもチャレンジしてみたいと思います!









