![[小ネタ]EC2に導入したFluentdの設定ファイルを変更し時間階層でファイルを送信してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-25b3f2afad8075b79c0e4f8dd097809f/546be781100260b89d3a350731ca86d8/fluentd_1200_630.png?w=3840&fm=webp)
[小ネタ]EC2に導入したFluentdの設定ファイルを変更し時間階層でファイルを送信してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、こーへいです。
今回はAthenaではなく直接ファイルをダウンロードするなどして直接ログを分析する場合を想定して、EC2に導入したFluentdの設定ファイルを変更し、時間階層でファイルを送信することでログファイルを探しやすくしてみました。
初期導入
EC2にFluentdの導入手順は以下のブログがわかりやすいです。本記事では導入済みを前提に進めます。
サンプルConfig
/etc/fluent/fluentd.confにて上記ブログをベースに設定ファイルを以下の通りカスタマイズしました。
<source>
@type tail
path /var/log/httpd/access_log
pos_file /var/log/fluent/apache2.access_log.pos
<parse>
@type apache2
</parse>
tag s3.apache.access
</source>
<match s3.*.*>
@type s3
s3_bucket [バケット名]
path logs/%Y/%m/%d/%H/%M/%S/
<buffer>
@type file
path /var/log/fluent/s3
timekey 60
timekey_wait 10s
chunk_limit_size 256m
</buffer>
time_slice_format %Y%m%d%H%M%S
</match>
変更点はmatchセクションのpathとtime_slice_formatを秒単位まで区切っただけです。
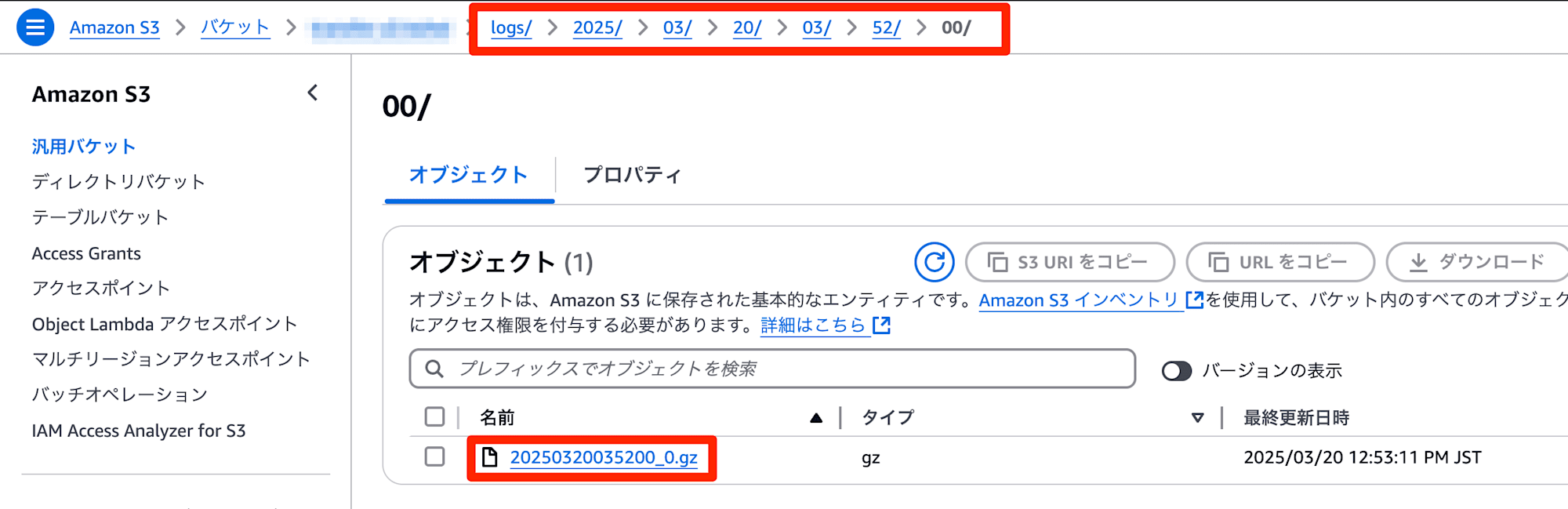
これで目的のログを発見しやすくなりました。
おまけ
こちらに記載の通り、timekeyとtimekey_waitによってS3にログが出力されるタイミングが決定されます。
特にtimekeyの値を大きくすることで、ログファイル1つ当たりの時間範囲を大きくすることができるので直接ファイルから目的のログを見つける際は便利かと思われます。
ただtimekeyの上限値についてはドキュメントの記載が見つけられず、最大どれくらいの時間範囲を指定できるか不明でした(ちなみにデフォルトは1時間で設定されます)。
とはいえ、上記の通り適切にS3に出力するログファイル名やパスを指定することで対象のファイルを探しやすくすることができるため、基本的にはデフォルト値に近い1時間以内の設定にすることをお勧めします。
またこちらの記事に記載の通り、実際にはtimekey以外にもchunk_limit_size等の条件を満たした場合でもS3にログが転送されるため、timekeyの値と同時にchunk_limit_size等にも考慮いただければと思います。
chunkがenqueueされるタイミングは2つあります。
flush intervalもしくはtimekeyの時間ごとのタイミング
chunk sizeが指定したサイズ以上になったタイミング
buffering parametersのように、chunkはsize limitやrecord数を指定でき、その制限を超えたタイミングでenqueueされます。
参考
- 公式ドキュメント
- https://docs.fluentd.org/input/tail
- Input Pluginsのin_tailについて記載
- https://docs.fluentd.org/output/s3
- Output Pluginsのs3について記載
- https://docs.fluentd.org/configuration/buffer-section
- bufferセクションの解説
- https://docs.fluentd.org/how-to-guides/apache-to-s3
- ApacheログをS3に出力する場合について記載
- https://docs.fluentd.org/input/tail
- その他









