![[アップデート] ECS マネージドインスタンスで NVIDIA GPU メトリクスがサポートされました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-6d4fdf3578638cab4e6e4655b3d692aa/15a803840d72679e6593006354d5766b/amazon-elastic-container-service?w=3840&fm=webp)
[アップデート] ECS マネージドインスタンスで NVIDIA GPU メトリクスがサポートされました
アップデート概要
ECS マネージドインスタンスが GPU メトリクスをサポートしました。
ECS マネージドインスタンスは、AWS にインスタンス管理を委譲しながら、ECS on EC2 のような細かい基盤部分のカスタマイズを可能にする機能です。
GPU 利用時など、ハードウェア制約で Fargate を使えない場面でも、EC2 インスタンスの管理負荷を抑えながらコンテナアプリケーションを実行できます。
一方で、AWS 管理の EC2 インスタンスにはシェルアクセスできないため、CloudWatch エージェントによる GPU メトリクスの収集が困難でした。 ※1
今回のアップデートにより、エージェント不要で ECS ネイティブな形で GPU メトリクスを収集できるようになりました。
※1 1ヶ月前に発表されたマネージドデーモン機能を使えば CloudWatch エージェントもかなり扱いやすくなりましたが、エージェント自体が不要になる点が今回のアップデートの嬉しいポイントです。
GPU メトリクスを収集するための条件について
For Amazon ECS Managed Instances running NVIDIA GPU-enabled Amazon EC2 instance types, Container Insights with enhanced observability collects GPU metrics from NVIDIA Data Center GPU Manager (DCGM) at the container, task, and instance levels. GPU metrics are not collected with basic Container Insights; enable enhanced observability to access GPU telemetry.
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/monitoring-managed-instances.html#gpu-monitoring-managed-instances
GPU 関連のメトリクスを確認するには Container Insights with enhanced observability を有効にしている必要があります。
通常の Container Insights では GPU メトリクスが収集されないことに注意が必要です。
追加されたメトリクス
ドキュメントを確認する限りでは、下記メトリクスが増えていました。
| メトリクス名 | 説明 |
|---|---|
ContainerGPUUtilization |
コンテナに割り当てられた GPU の使用率(%) |
ContainerGPUMemoryUtilization |
コンテナに割り当てられた GPU のフレームバッファメモリ使用率(%) |
ContainerGPUMemoryTotal |
コンテナに割り当てられた GPU のフレームバッファメモリ総量(バイト) |
ContainerGPUMemoryUsed |
コンテナに割り当てられた GPU のフレームバッファメモリ使用量(バイト) |
ContainerGPUPowerDraw |
コンテナに割り当てられた GPU の消費電力(ワット) |
ContainerGPUTemperature |
コンテナに割り当てられた GPU の温度(℃) |
ContainerGPURestartAppXidCount |
コンテナに割り当てられた GPU で発生した NVIDIA Xid エラーの内、即時対応として再起動が必要なものの回数 |
TaskGPUUtilization |
タスクに割り当てられた GPU の使用率(%) |
TaskGPUMemoryUtilization |
タスクに割り当てられた GPU のフレームバッファメモリ使用率(%) |
TaskGPUMemoryTotal |
タスクに割り当てられた GPU のフレームバッファメモリ総量(バイト) |
TaskGPUMemoryUsed |
タスクに割り当てられた GPU のフレームバッファメモリ使用量(バイト) |
TaskGPUPowerDraw |
タスクに割り当てられた GPU の消費電力(ワット) |
TaskGPUTemperature |
タスクに割り当てられた GPU の温度(℃) |
TaskGPURestartAppXidCount |
タスクに割り当てられた GPU で発生した NVIDIA Xid エラーの内、即時対応として再起動が必要なものの回数 |
InstanceGPULimit |
インスタンスで利用可能な GPU の総数 |
InstanceGPUUsageTotal |
インスタンスで実行中のタスクに割り当てられている GPU の数 |
Amazon ECS Container Insights with enhanced observability metrics - Amazon CloudWatch
試してみる
実際に GPU を利用したコンテナを起動してメトリクスを確認してみます。
比較的安い料金設定で GPU インスタンスを使いやすいため、今回は us-east-1 で試してみます。
キャパシティプロバイダー設定で NVIDIA の GPU を指定します。
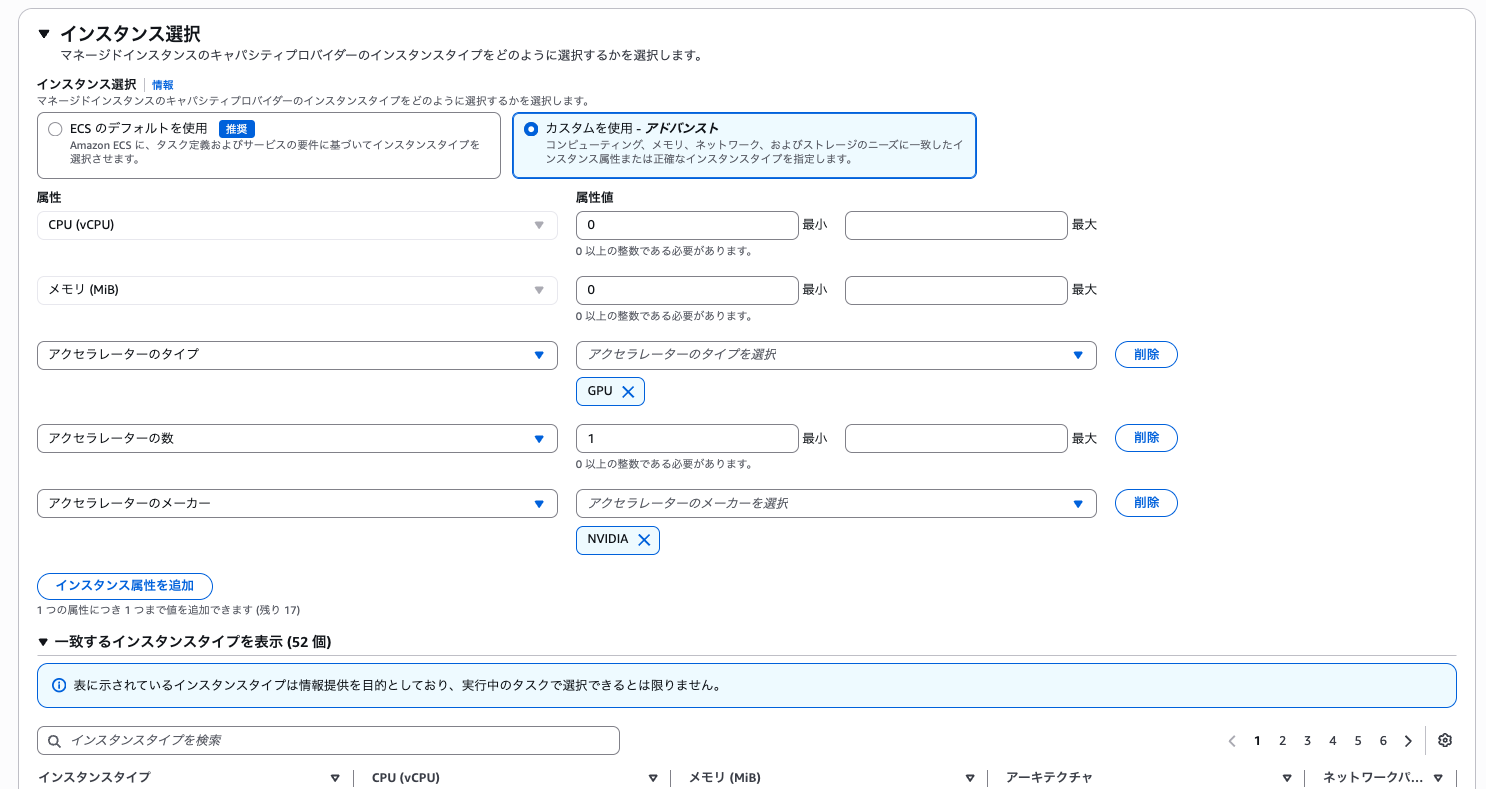
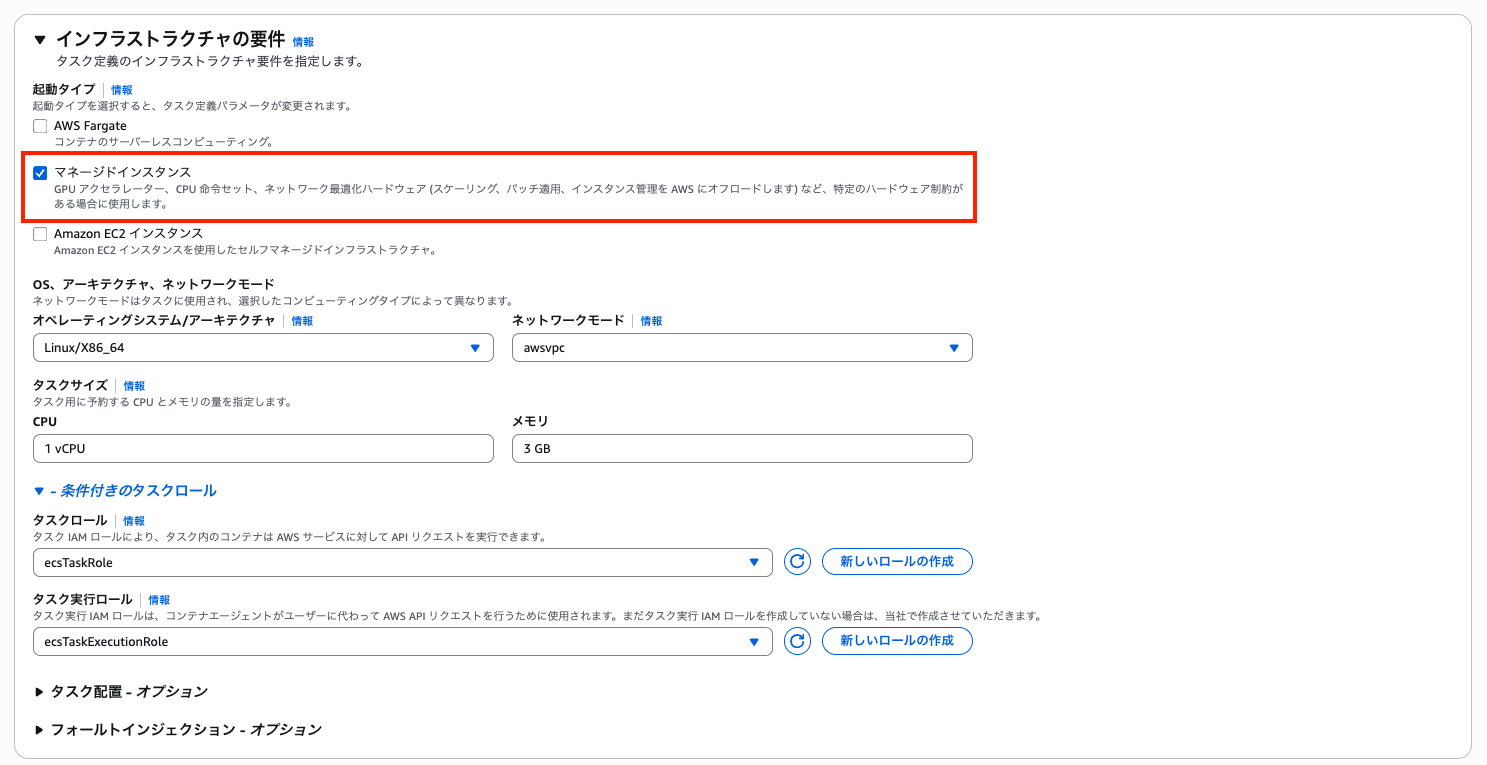
タスク定義では、起動タイプとして「マネージドインスタンス」を指定します。
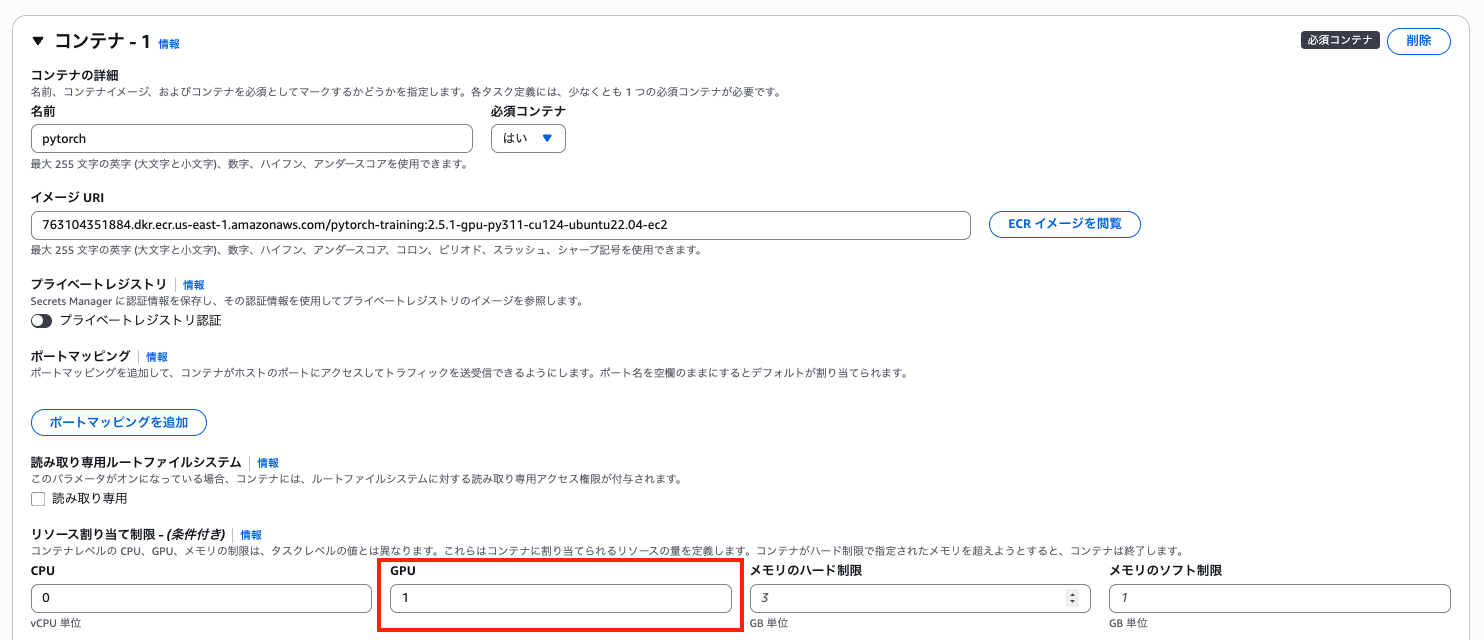
GPU の割り当てを指定します。
起動すると ECS サービスの「正常性とメトリクス」タブから各種メトリクスを確認できました。
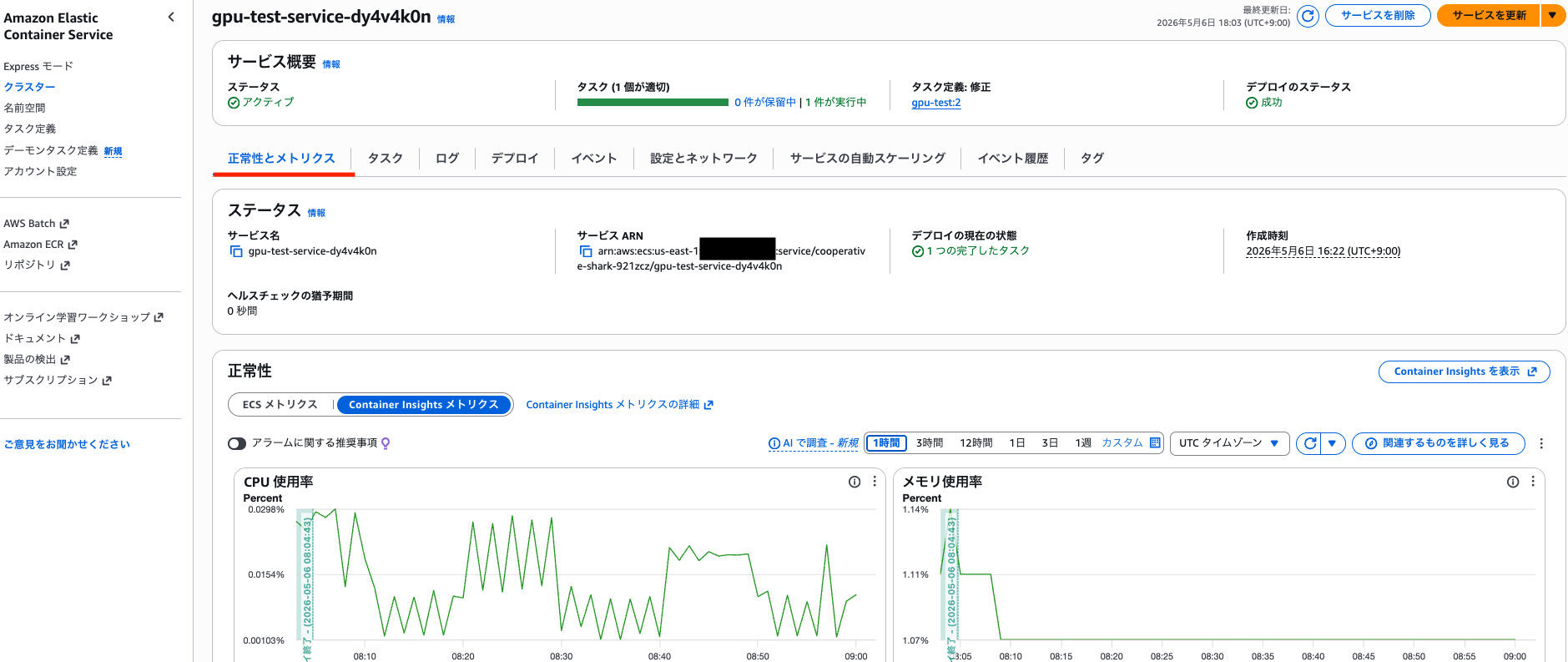
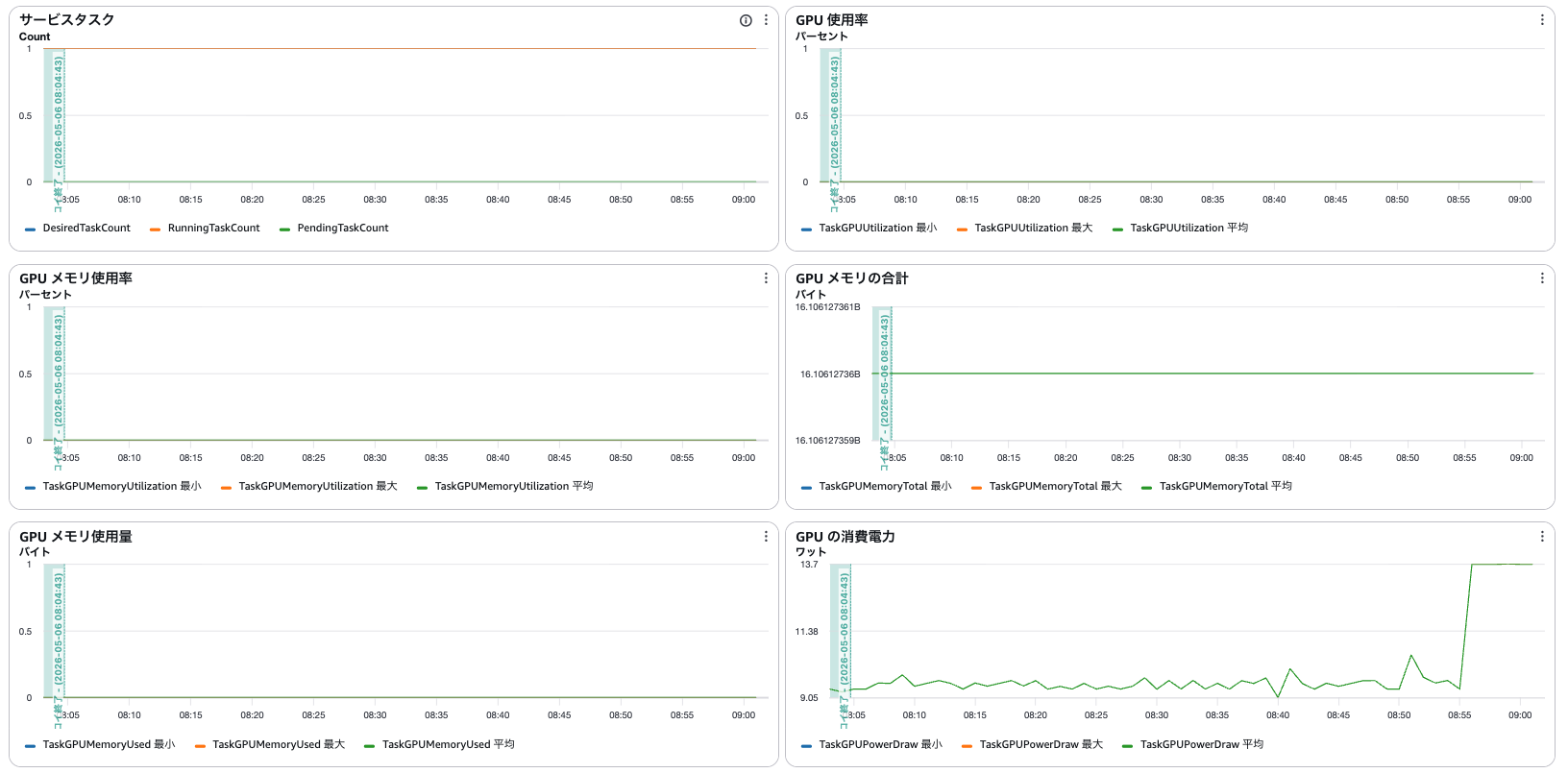
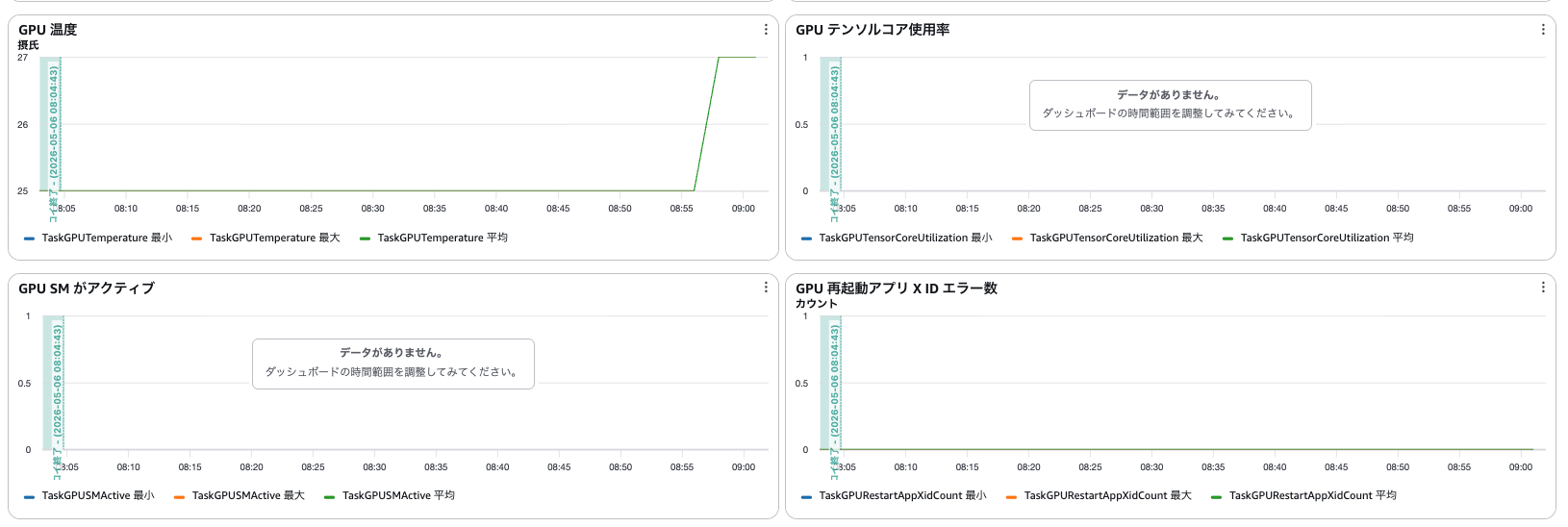
ダッシュボードには SM Active やテンソルコア利用率などの GPU メトリクスを表示するグラフが追加されていましたが、データは収集されていないようでした。
ドキュメントにも記載が無かったので、今後のアップデートで追加されるのかもしれません。
また、コンテナインスタンス側の「メトリクス欄」からは GPU メトリクスを確認できませんでした。
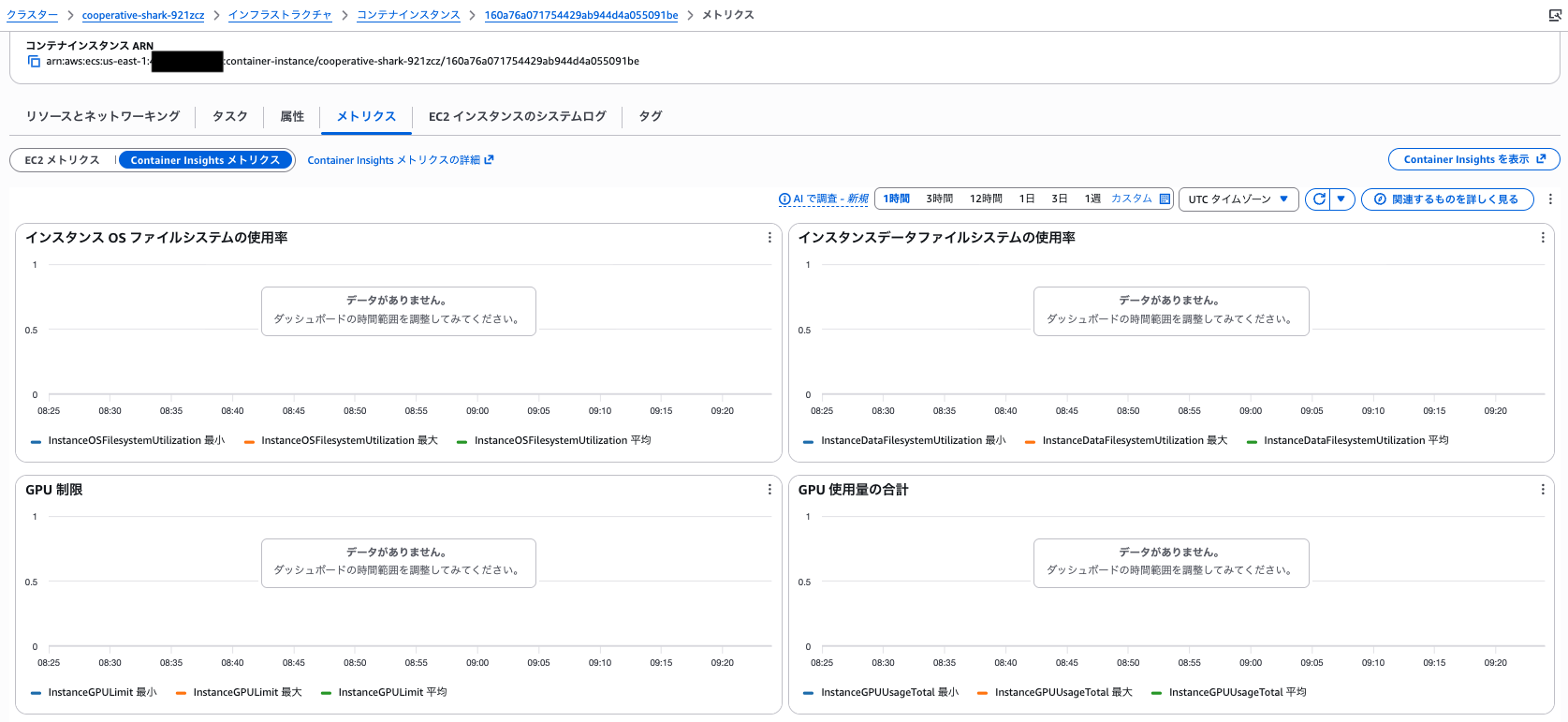
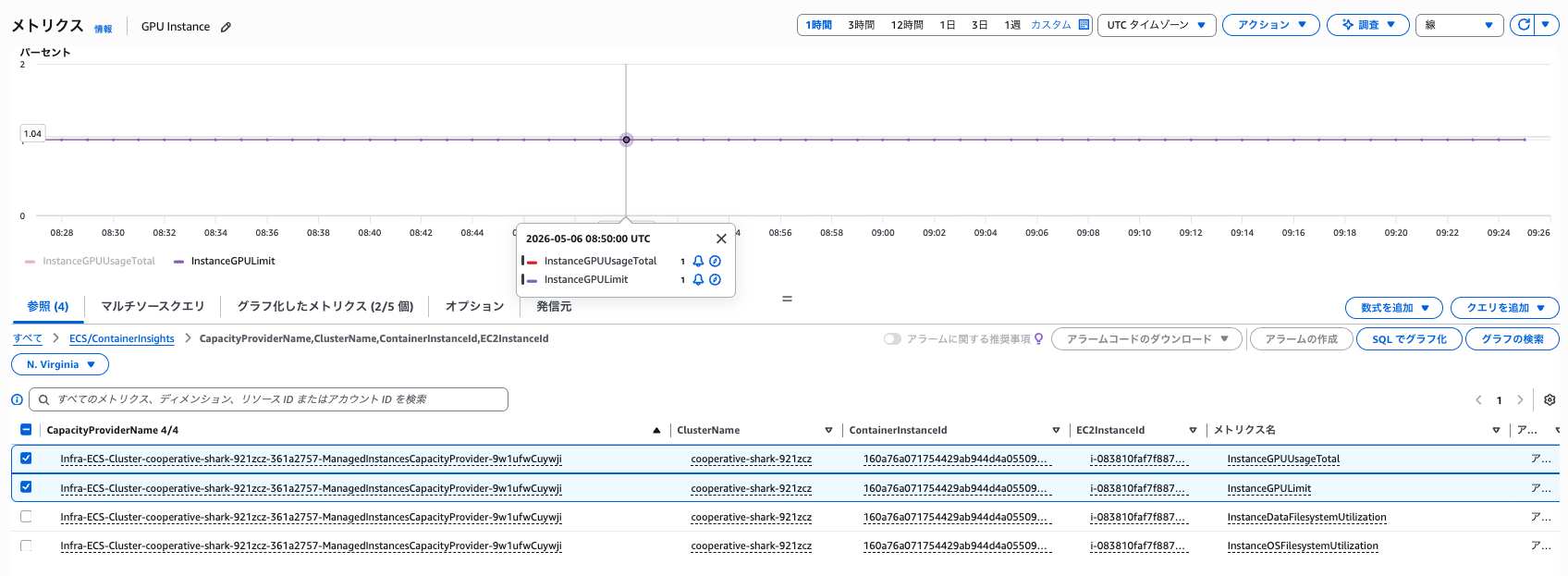
CloudWatch 側にはきちんと届いていたので、その内解消されるかもしれません。
最後に
ECS マネージドインスタンスが GPU メトリクスをサポートしました。
特別なセットアップも不要かつエージェント不要で GPU メトリクスを収集できるのは嬉しいですね。
GPU を利用したちょっとしたコンテナアプリケーションを実行するのであれば、ECS マネージドインスタンスはかなり魅力的だと思いました。











