![[アップデート] EKS Auto Mode で AWS 管理コンポーネントのログを出力できるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-909b0303176e85a702b92f68e9d7ecba/67a829aa0886839b83f973e123190bd0/amazon-elastic_kubernetes_service?w=3840&fm=webp)
[アップデート] EKS Auto Mode で AWS 管理コンポーネントのログを出力できるようになりました
アップデート概要
EKS Auto Mode では、コントロールプレーンの他に下記コンポーネントのインストールや管理を AWS に委譲することができます。
- Karpenter
- AWS Load Balancer Controller
- EBS CSI driver
非 Auto Mode 構成では該当する Kubernetes リソースを明示的にインストールする必要がありましたが、Auto Mode では AWS 管理領域にインストールされ、管理不要になります。
この際、ユーザーから Kubernetes リソースを確認することはできず、ログを確認することもできません。
管理しなくて良いメリットはあるものの、何かあった際のトラブルシューティングがし辛いという欠点がありました。
今回のアップデートを受けて、これら AWS 管理コンポーネントのログも出力できるようになりました。
設定してみる
新機能の設定時はマネジメントコンソールがわかりやすいだろうということで、予め Terraform で作成した EKS クラスターに対してマネジメントコンソールから設定します。
vpc.tf
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 6.0.1"
name = "eks-vpc"
cidr = "10.0.0.0/16"
azs = ["ap-northeast-1a", "ap-northeast-1c", "ap-northeast-1d"]
public_subnets = ["10.0.0.0/24", "10.0.1.0/24", "10.0.2.0/24"]
private_subnets = ["10.0.100.0/24", "10.0.101.0/24", "10.0.102.0/24"]
enable_nat_gateway = true
single_nat_gateway = true
public_subnet_tags = {
"kubernetes.io/role/elb" = 1
}
private_subnet_tags = {
"kubernetes.io/role/internal-elb" = 1
}
}
eks.tf
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 21.0.4"
name = "test-cluster"
kubernetes_version = "1.35"
endpoint_public_access = true
endpoint_private_access = true
enable_irsa = false
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
authentication_mode = "API"
enable_cluster_creator_admin_permissions = true
compute_config = {
enabled = true
node_pools = ["general-purpose"]
}
}
EKS クラスター詳細ページのオブザーバビリティ欄から設定します。
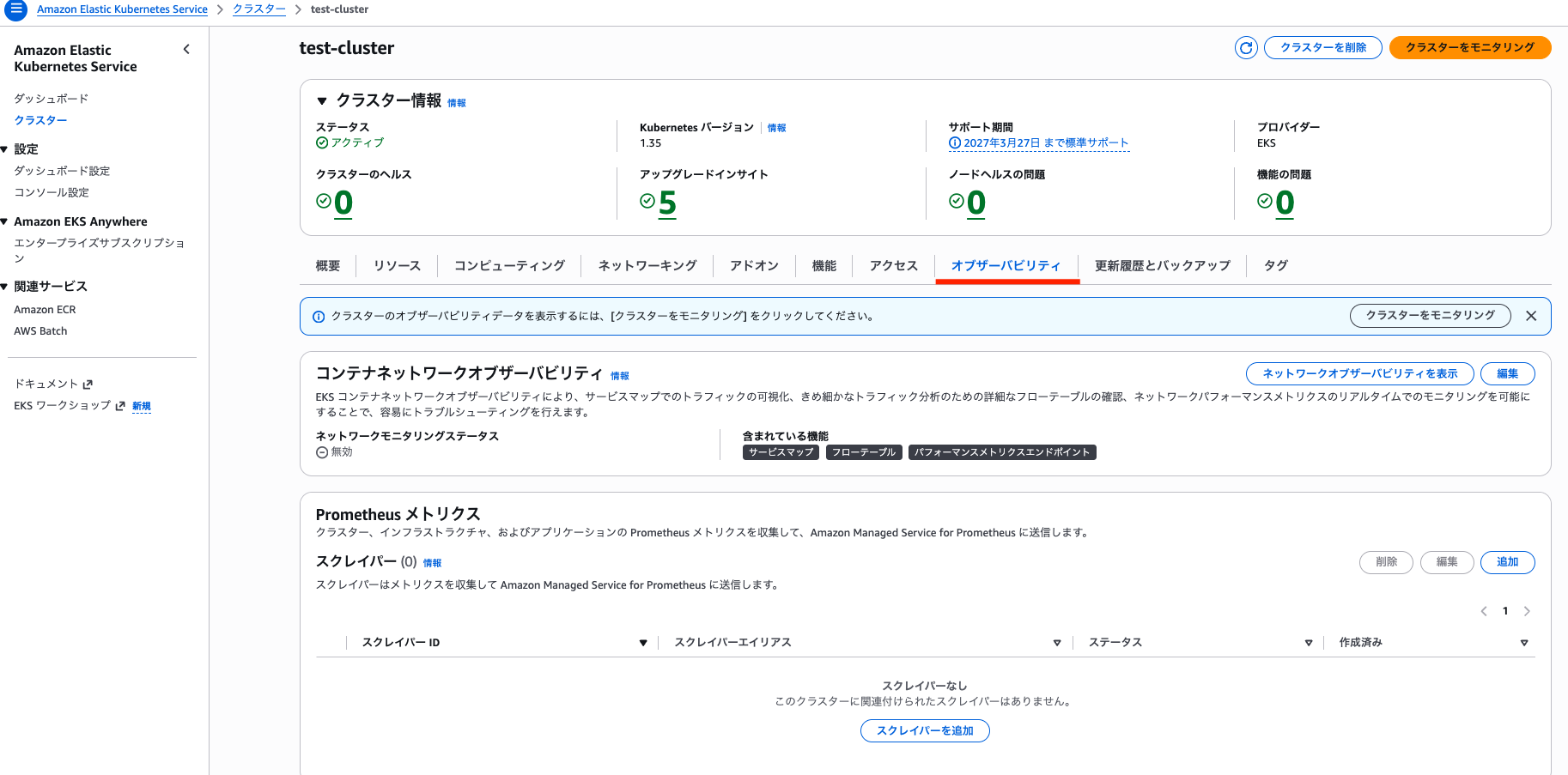
「ログ記録」から設定します。
今回は CloudWatch Logs を選択します。
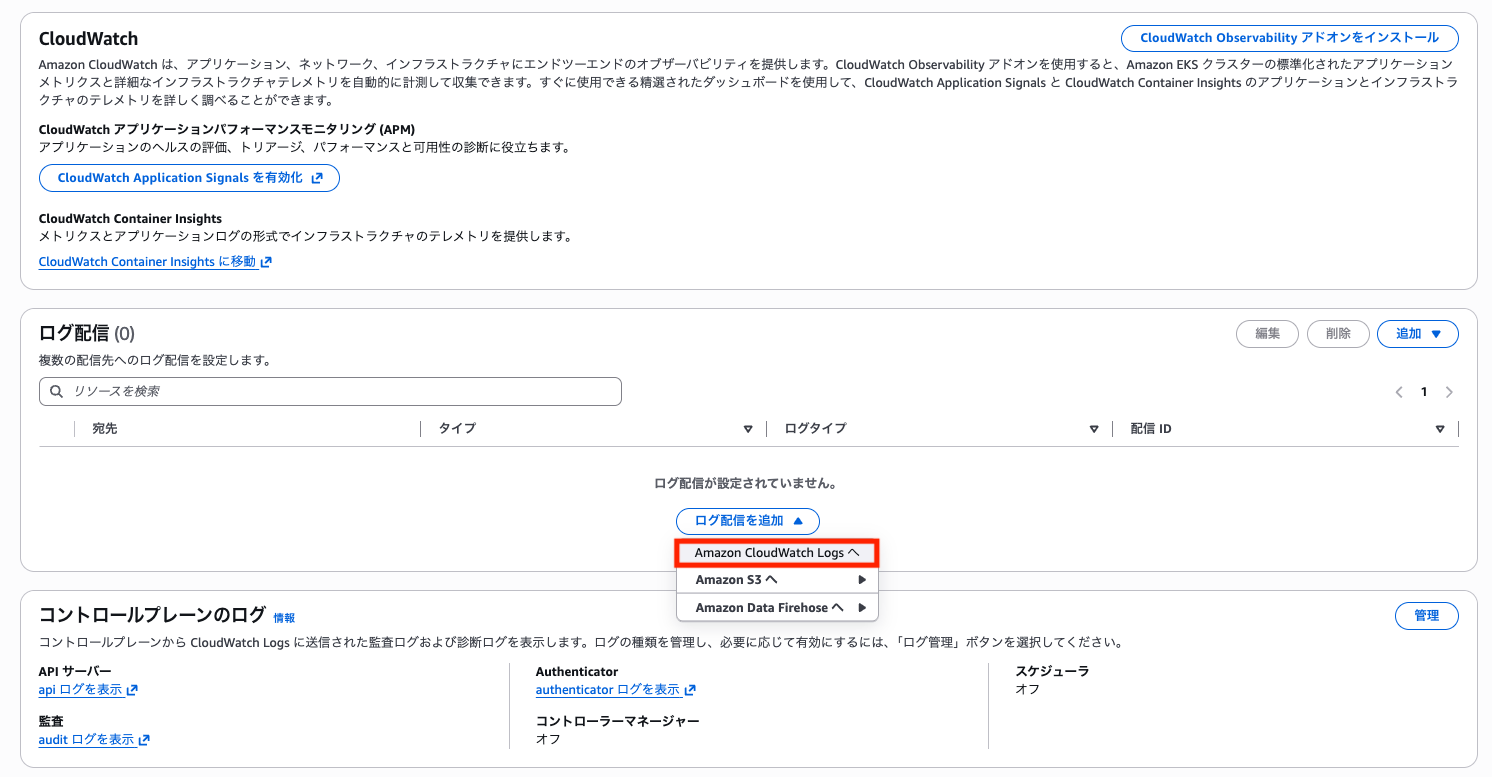
ログタイプを選択します。
ログタイプは下記 4 種類が存在します。
| ログタイプ | 概要 |
|---|---|
| AUTO_MODE_BLOCK_STORAGE_LOGS | EBS CSI driver のログ |
| AUTO_MODE_COMPUTE_LOGS | Karpenter のログ |
| AUTO_MODE_IPAM_LOGS | VPC CNI IP Address Management のイベントログ (IPAM デーモンのログそのものでは無い、詳細は後述) |
| AUTO_MODE_LOAD_BALANCING_LOGS | AWS Load Balancer Controller のログ |
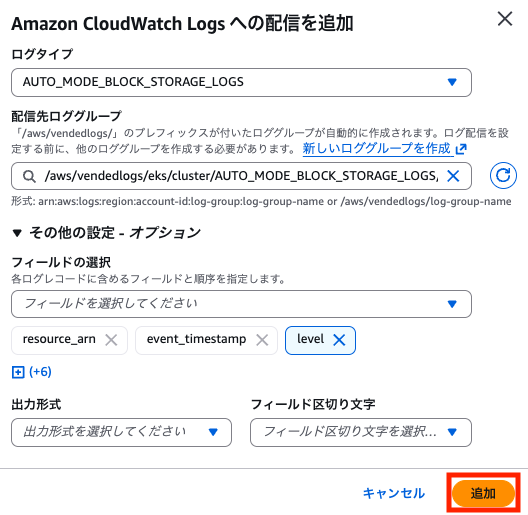
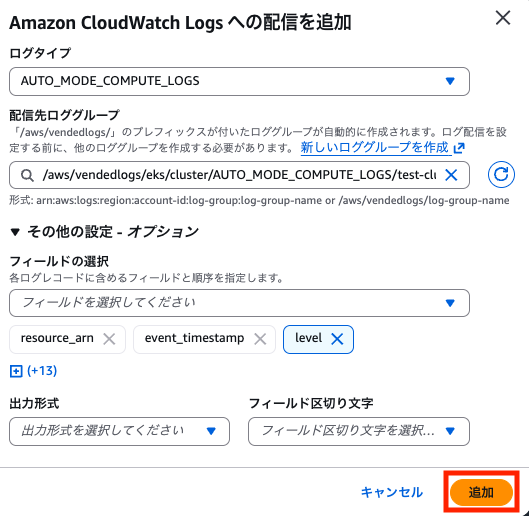
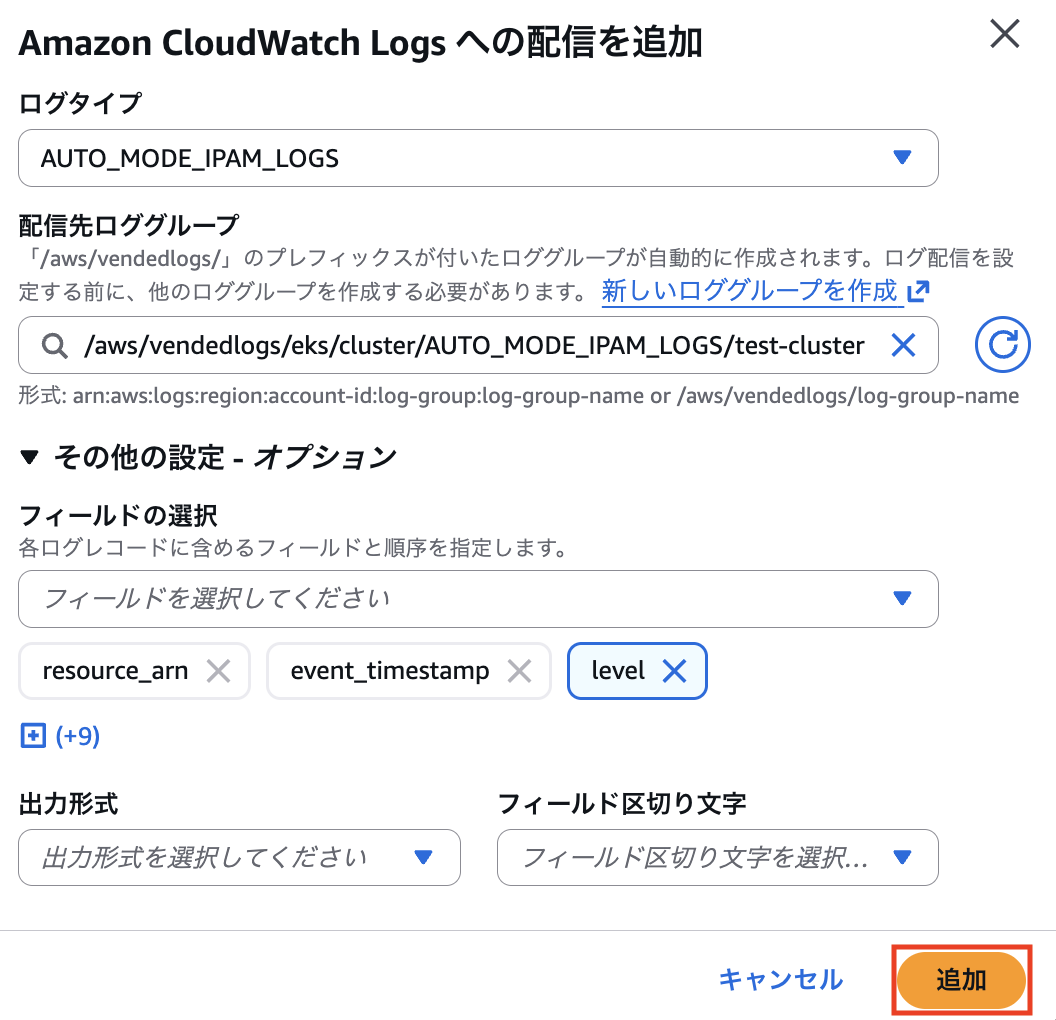
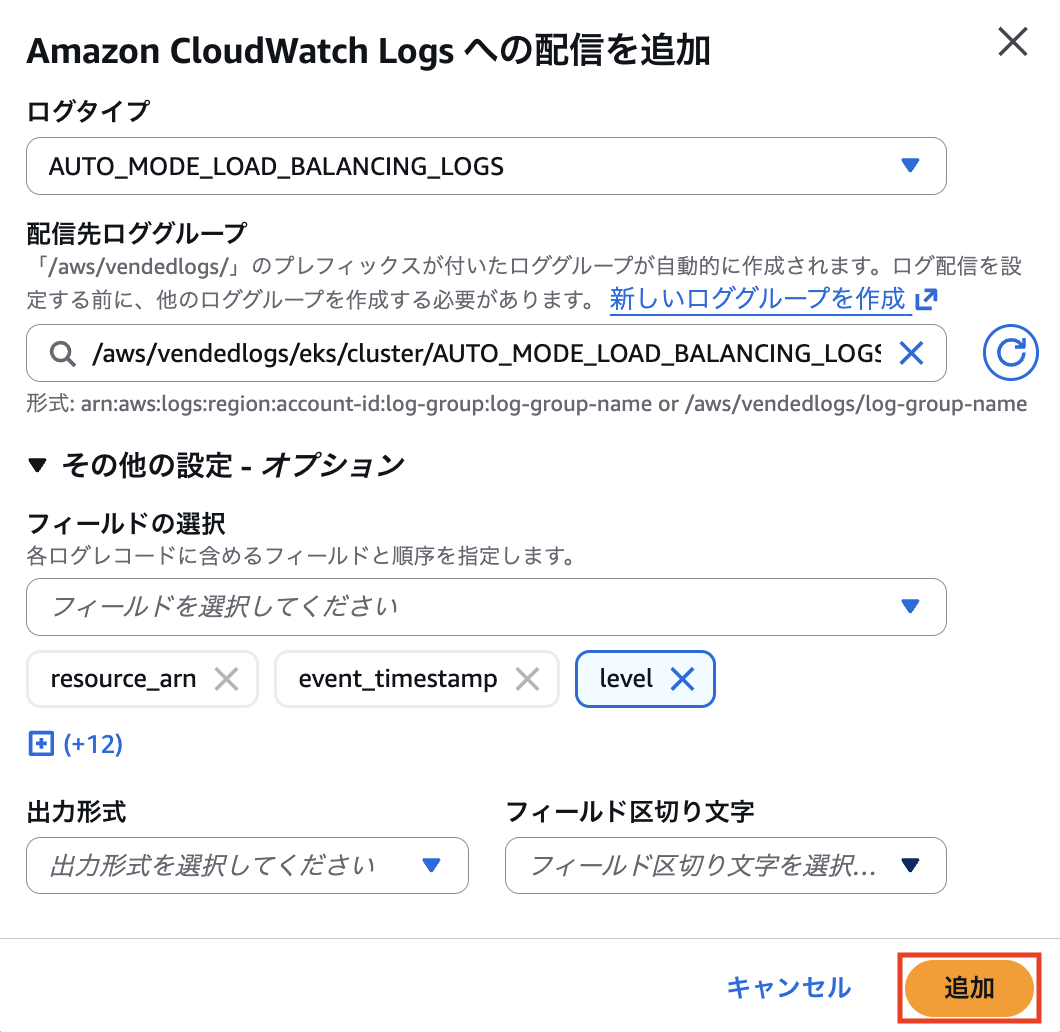
これらのログ出力設定はログタイプごとに設定する必要があり、並列して設定を行うことはできない点に注意が必要です。
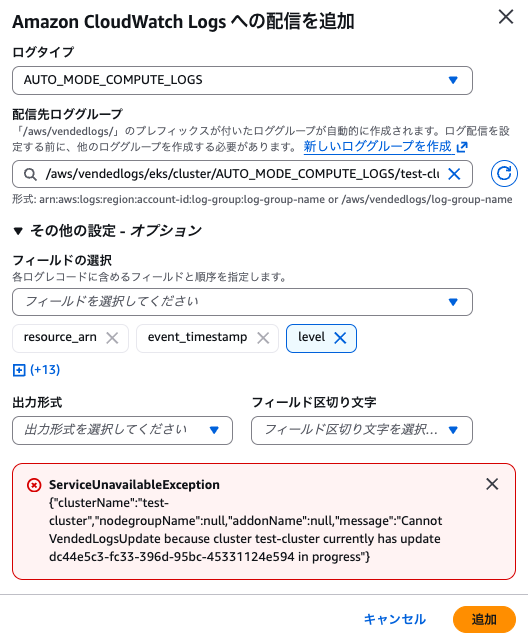
必要なログタイプのみ設定することも可能ですが、今回は全てのログタイプに対して設定しました。
設定時に実行される API を CloudTrail から確認する
CloudTrail から設定の流れを確認すると、下記のようになりました。
- CreateLogGroup
- PutDeliverySource
- PutDeliveryDestination
- DescribeResourcePolicies
- PutResourcePolicy
- CreateDelivery
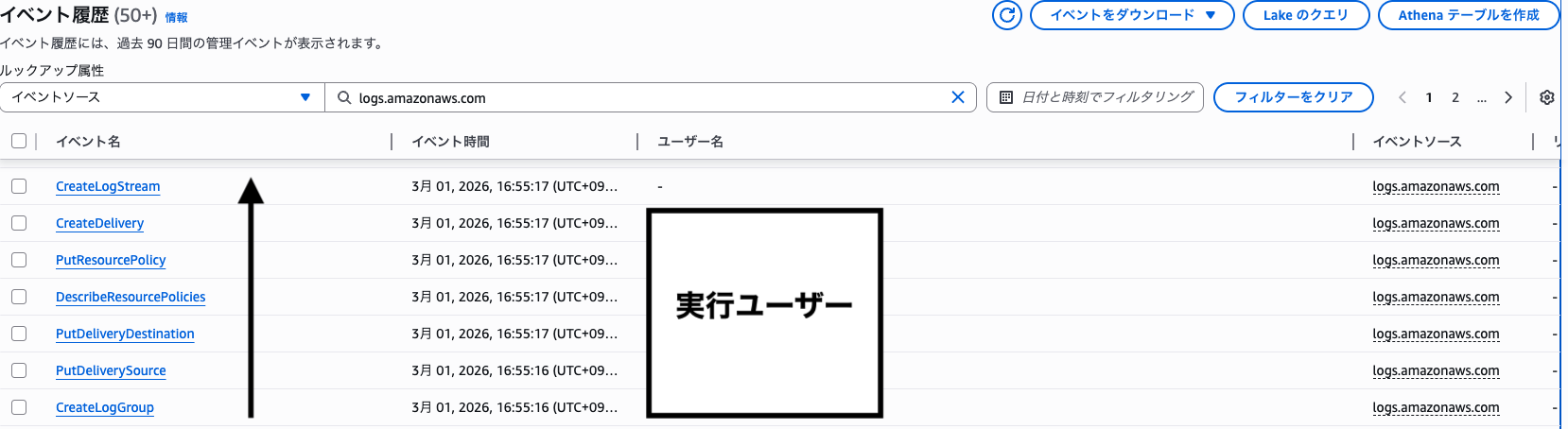
What's New に Vended Logs と記載されていたので予想はできましたが、CloudFront V2 ログなどと同じ V2 形式 の流れですね。
今回はマネジメントコンソールから設定してしまいましたが、 aws_cloudwatch_log_delivery や aws_cloudwatch_log_delivery_source、aws_cloudwatch_log_delivery_destination などを利用すればロギング設定も Terraform で定義できると思います。
ログの確認
CloudWatch に出力されたログを確認してみます。
AUTO_MODE_BLOCK_STORAGE_LOGS
EBS CSI driver のログを確認してみると、ひたすらエラーを吐いてました。
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772205970961,
"stream": "stderr",
"message": "E0227 15:26:10.960925 1 reflector.go:205] \"Failed to watch\" err=\"failed to list *v1.VolumeSnapshotClass: the server could not find the requested resource (get volumesnapshotclasses.snapshot.storage.k8s.io)\" logger=\"UnhandledError\" reflector=\"github.com[FILE-PATH]\" type=\"*v1.VolumeSnapshotClass\""
}
volumesnapshotcontents.snapshot.storage.k8s.io CRD がクラスターに無いためにエラーになっているようです。
EKS Auto Mode においても、スナップショットコントローラーはアドオンとしてインストールする必要があります。
データのポイントインタイムリカバリが不要ならインストールしなくても良さそうですが、エラーログが出続けるのも嫌なのでアドオンを追加します。
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 21.0.4"
name = "test-cluster"
kubernetes_version = "1.35"
endpoint_public_access = true
endpoint_private_access = true
enable_irsa = false
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
authentication_mode = "API"
enable_cluster_creator_admin_permissions = true
compute_config = {
enabled = true
node_pools = ["general-purpose"]
}
+ addons = {
+ snapshot-controller = {}
+ }
}
CSI スナップショットコントローラアドオン追加後、volumesnapshotclasses.snapshot.storage.k8s.io が追加され、無事エラーログもでなくなりました。
% kubectl get crd
NAME CREATED AT
applicationnetworkpolicies.networking.k8s.aws 2026-02-27T14:21:51Z
clusternetworkpolicies.networking.k8s.aws 2026-02-27T14:21:51Z
clusterpolicyendpoints.networking.k8s.aws 2026-02-27T14:21:51Z
cninodes.eks.amazonaws.com 2026-02-27T14:24:57Z
cninodes.vpcresources.k8s.aws 2026-02-27T14:21:52Z
ingressclassparams.eks.amazonaws.com 2026-02-27T14:24:57Z
nodeclaims.karpenter.sh 2026-02-27T14:24:57Z
nodeclasses.eks.amazonaws.com 2026-02-27T14:24:57Z
nodediagnostics.eks.amazonaws.com 2026-02-27T14:24:57Z
nodepools.karpenter.sh 2026-02-27T14:24:57Z
policyendpoints.networking.k8s.aws 2026-02-27T14:21:51Z
securitygrouppolicies.vpcresources.k8s.aws 2026-02-27T14:21:51Z
targetgroupbindings.eks.amazonaws.com 2026-02-27T14:24:57Z
volumegroupsnapshotclasses.groupsnapshot.storage.k8s.io 2026-02-28T08:05:59Z
volumegroupsnapshotcontents.groupsnapshot.storage.k8s.io 2026-02-28T08:05:59Z
volumegroupsnapshots.groupsnapshot.storage.k8s.io 2026-02-28T08:05:59Z
volumesnapshotclasses.snapshot.storage.k8s.io 2026-02-28T08:05:59Z
volumesnapshotcontents.snapshot.storage.k8s.io 2026-02-28T08:06:00Z
volumesnapshots.snapshot.storage.k8s.io 2026-02-28T08:06:00Z
PV/PVC を作成していくつかのログを確認してみます。
PVC のプロビジョニング時には下記のようなログを確認できました。
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772266609053,
"stream": "stderr",
"message": "I0228 08:16:49.053892 1 event.go:389] \"Event occurred\" object=\"default/auto-ebs-claim\" fieldPath=\"\" kind=\"PersistentVolumeClaim\" apiVersion=\"v1\" type=\"Normal\" reason=\"ProvisioningSucceeded\" message=\"Successfully provisioned volume pvc-[UUID]\""
}
ボリュームのアタッチ時には下記ログを確認できました。
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772266612928,
"stream": "stderr",
"message": "I0228 08:16:52.928200 1 csi_handler.go:271] \"Attached\" VolumeAttachment=\"csi-8fc8f087d8b38a8ef1bf350d2cabfe472e501c9cf27b08e7e533052eb610402e\""
}
AUTO_MODE_COMPUTE_LOGS
Karpneter のログになります。
5 分 ~ 10 分に一度くらいの頻度で Unexpected EOF during watch stream event decoding というエラーが発生していました。
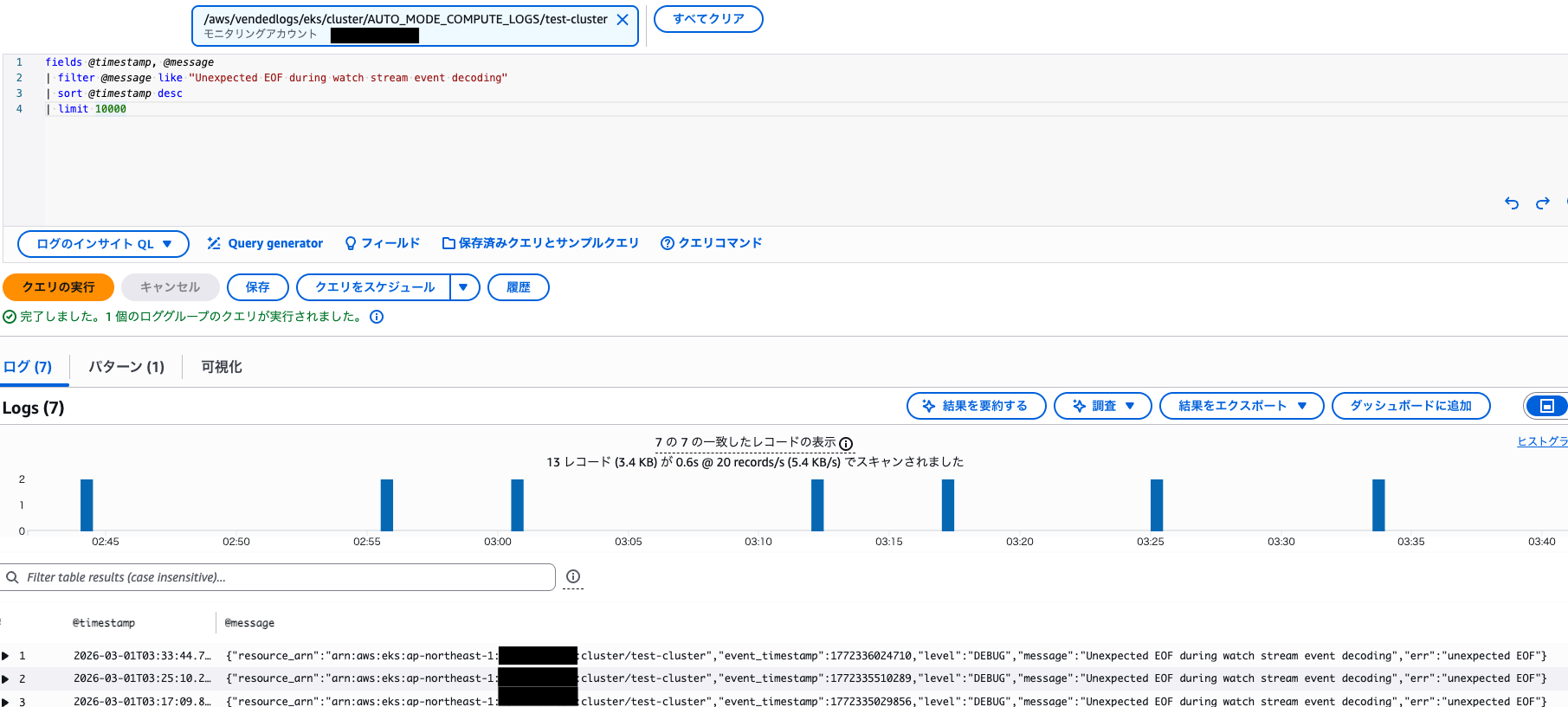
AWS 管理 Karpenter から、Kube API Server への接続が定期的に切れてそうですが、再接続しているから問題は無いってことでしょうか。
ちょっとどうしようも無さそうなので放置しようと思います。
また、30 分に一度程度 created launch template というログも確認できました。
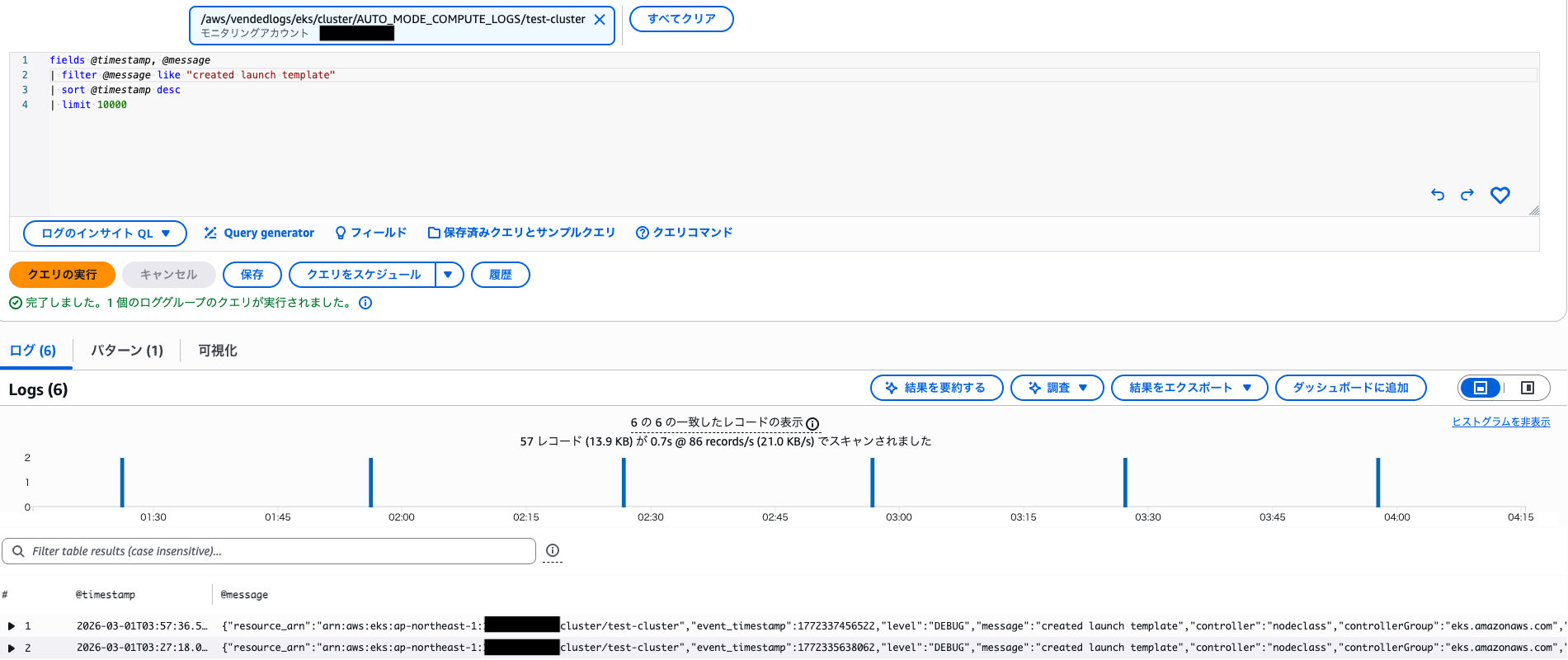
EKS Auto Mode ではユーザーの AWS アカウントに起動テンプレートが作成されることは無いですが、AWS 管理アカウントに適宜作成されているようですね。
試しに SCP によって RunInstance が拒否された際の挙動を見てみます。
今回はコストを理由に GPU インスタンスの起動が禁止されている環境を想定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyG6G5G4dnInstances",
"Effect": "Deny",
"Action": "ec2:RunInstances",
"Resource": "arn:aws:ec2:*:*:instance/*",
"Condition": {
"ForAnyValue:StringLike": {
"ec2:InstanceType": ["g6.*", "g6e.*", "g5.*", "g5g.*", "g4dn.*"]
}
}
}
]
}
組み込みノードプールだと、c 系、m 系、r 系から選択されるので、GPU インスタンスを利用可能な NodePool を作成します。
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: aiml
spec:
template:
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand", "spot"]
- key: eks.amazonaws.com/instance-family
operator: In
values: ["g6", "g5", "g4dn"]
- key: eks.amazonaws.com/instance-size
operator: In
values: ["xlarge", "2xlarge"]
- key: eks.amazonaws.com/instance-gpu-manufacturer
operator: In
values: ["nvidia"]
nodeClassRef:
group: eks.amazonaws.com
kind: NodeClass
name: default
GPU コンテナを起動します。
apiVersion: v1
kind: Pod
metadata:
labels:
role: training
name: training
spec:
nodeSelector:
karpenter.sh/capacity-type: spot
containers:
- command:
- sh
- -c
- sleep infinity
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:2.5.1-gpu-py311-cu124-ubuntu22.04-ec2
name: training
resources:
limits:
nvidia.com/gpu: 1
想定通り Pod の作成に失敗して、下記ログを確認できました。
SCP で拒否されていることまで含めてバッチリ記録されており、権限周りのトラブルシューティングはかなり行いやすくなったと思います。
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772364142487,
"level": "ERROR",
"message": "Reconciler error",
"error": "launching nodeclaim, creating nodeclaim, creating instance, creating nodeclaim, UnauthorizedOperation: You are not authorized to perform this operation. User: [ARN] is not authorized to perform: ec2:RunInstances on resource: [ARN] with an explicit deny in a service control policy:
============= 中略 =============
(aws-error-code=UnfulfillableCapacity, aws-operation-name=CreateFleet, aws-request-id=[UUID], aws-service-name=EC2, aws-status-code=200)",
"controller": "nodeclaim.lifecycle",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"reconcileID": "ebf11c31-25aa-4dde-a15a-ea906fd75cdd"
}
また、リソース利用量低下などを理由とした Node の統合に関するイベントなどを確認できるのは良いなと思いました。
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772266639005,
"level": "DEBUG",
"message": "marking consolidatable",
"controller": "nodeclaim.disruption",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"reconcileID": "d75cb197-3ca8-4192-b1b9-65774958aaa4"
}
AUTO_MODE_IPAM_LOGS
EKS Auto Mode のネットワーキング周りは VPC CNI 固定です。
VPC CNI は 2 つのコンポーネントで成り立っており、Pod のネットワーク設定を行う CNI バイナリと IP アドレスや ENI の管理を担当する IP Address Management deamon があります。
Amazon VPC CNI には 2 つのコンポーネントがあります。
・CNI バイナリ。Pod 間の通信を有効にするように Pod-to-Pod ネットワークを設定します。CNI バイナリはノードルートファイルシステムで実行され、新しい Pod がノードに追加されるか、既存の Pod がノードから削除されると、kubelet によって呼び出されます。
・ipamd は、長時間実行されるノードローカル IP アドレス管理 (IPAM) デーモンであり、以下を担当します。
・ノードでの ENIs の管理
・使用可能な IP アドレスまたはプレフィックスのウォームプールの維持
https://docs.aws.amazon.com/eks/latest/best-practices/vpc-cni.html
では、今回出力できるようになったログは IP Address Management deamon (ipamd) のログなのでしょうか?
EKS Auto Mode にはノードのログを S3 に出力するオプションがあり、そちらで system/ps.txt や system/services.txt を確認してみます。
すると ipamd は systemd デーモンとして起動していることがわかります。
system/ps.txt (抜粋)
root 1673 0.0 1.7 1650268 67124 ? Ssl 06:11 0:04 /usr/bin/ipamd --kubeconfig /etc/kubernetes/ipamd/kubeconfig --metrics-bind-addr 127.0.0.1:8172 --health-probe-bind-addr 127.0.0.1:8173
system/services.txt (抜粋)
ipamd.service
var_log 配下に VPC CNI plugin と一緒にログも出力されています。
var_log
└── aws-routed-eni
├── ebpf-sdk.log
├── ipamd.log
├── network-policy-agent.log
└── plugin.log
var_log/imapd.log を確認してみると下記のようにかなり詳しいログを確認できます。
{"level":"info","ts":"2026-03-01T12:23:32.378Z","caller":"controller/controller.go:216","msg":"Get CNI Node object for: i-0e07e380388e14a9c"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:275","msg":"VPC IPv4 CIDRs: [10.0.0.0/16]"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:281","msg":"Primary ENI ID: eni-0bca62fa2e2c7a551"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:281","msg":"Primary IP: 10.0.101.93"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:287","msg":"SNAT Type: Random"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:293","msg":"Derive CIDRs"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:293","msg":"Deriving Network Interface info for ID: eni-0bca62fa2e2c7a551"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:293","msg":"IP CIDR: 10.0.101.128/28"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:357","msg":"Non Host IP. Return"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:293","msg":"IP CIDR: 10.0.101.93/32"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:293","msg":"Total number of Host CIDRs attached: 1; Prefix CIDRs: 1"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:293","msg":"Total number of Host Cool Down CIDRs: 0; Prefix CIDRs: 0"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:137","msg":"ipamd setup aws conflist file with node ipv4 - 10.0.101.93, ipv6 - false, snat - Random"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"controllers/cninode_controller.go:213","msg":"NetworkPolicy Type: DefaultAllow"}
{"level":"debug","ts":"2026-03-01T12:23:32.380Z","caller":"ipamd/ipamd.go:201","msg":"Start node init"}
{"level":"info","ts":"2026-03-01T12:23:32.380Z","caller":"ipamd/ipamd.go:220","msg":"Setting up host network... "}
{"level":"debug","ts":"2026-03-01T12:23:32.381Z","caller":"netlinkwrapper/netlink.go:143","msg":"netlink operation succeeded on attempt 1 of 5"}
一方、AUTO_MODE_IPAM_LOGS を確認すると下記のようなざっくりとしたイベントしか記録されていません。
created CNINode
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772367813047,
"level": "info",
"message": "created CNINode [INSTANCE-ID]",
"controller": "nodeclaim",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"reconcileID": "4180d8ca-187c-429c-8694-0b671658395c"
}
allocated ips
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772367813730,
"level": "info",
"message": "allocated ips",
"controller": "cninode",
"controllerGroup": "eks.amazonaws.com",
"controllerKind": "CNINode",
"reconcileID": "7e0e1607-f8a3-4999-9d9f-9cf8c9be1a4a"
}
細かい部分までは追えませんでしたが、AUTO_MODE_IPAM_LOGS として出力されるログが iampd のログでは無いことは確かです。
EKS Auto Mode では各ノードの VPC CNI を管理するためのコンポーネントが AWS 管理領域に存在して、そのログということでしょうか。
IP 管理に関するより抽象度の高いイベントが記録される形になるので、トラブルシューティング時はノードのログを S3 エクスポートして確認する形にしてしまっても良いかもしれません。
他 3 つと比較すると使い道が良くわかりませんでした。
AUTO_MODE_LOAD_BALANCING_LOGS
こちらはわかりやすく、AWS Load Balancer Controller のログですね。
試しに Ingress リソースを作成してみると下記のようなイベントを確認できました。
loaded ingGroup
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418634440,
"level": "INFO",
"message": "loaded ingGroup"
}
ResourceGroupTagging enabled, list the load balancers via RGT API
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418634440,
"level": "DEBUG+3",
"message": "ResourceGroupTagging enabled, list the load balancers via RGT API"
}
allocating backend SG
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418635067,
"level": "DEBUG+3",
"message": "allocating backend SG"
}
finding existing backend securityGroup
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418635067,
"level": "DEBUG+3",
"message": "finding existing backend securityGroup"
}
created SecurityGroup
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418635749,
"level": "INFO",
"message": "created SecurityGroup"
}
created loadBalancer
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418638260,
"level": "INFO",
"message": "created loadBalancer"
}
created targetGroup
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418638690,
"level": "INFO",
"message": "created targetGroup"
}
created listener rule
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418639064,
"level": "INFO",
"message": "created listener rule"
}
created targetGroupBinding
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772418639088,
"level": "INFO",
"message": "created targetGroupBinding"
}
ALB LoadBalancer 周りのトラブルシューティングが捗りそうです。
CloudWatch 出力時の出力形式
ログ出力設定を行う際、出力形式で json と plane を選ぶことができます。
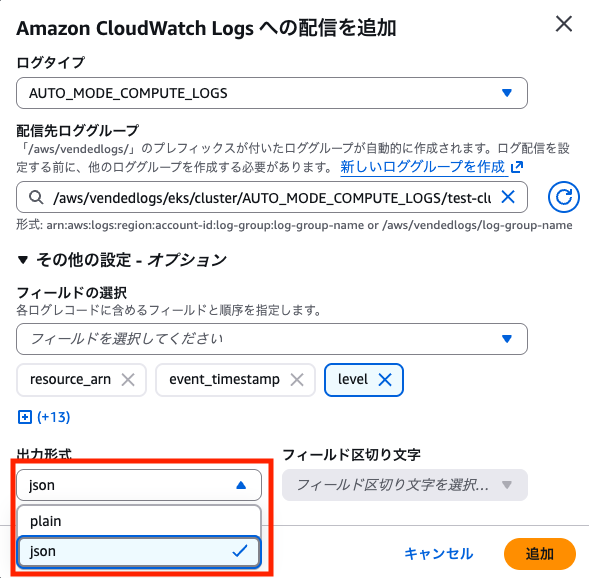
選択しない場合、デフォルト設定として json が選択されるようです。
例えば、EBS CSI driver の場合、json だと下記のようになります。
{
"resource_arn": "arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster",
"event_timestamp": 1772205970961,
"stream": "stderr",
"message": "E0227 15:26:10.960925 1 reflector.go:205] \"Failed to watch\" err=\"failed to list *v1.VolumeSnapshotClass: the server could not find the requested resource (get volumesnapshotclasses.snapshot.storage.k8s.io)\" logger=\"UnhandledError\" reflector=\"github.com[FILE-PATH]\" type=\"*v1.VolumeSnapshotClass\""
}
plain を選択すると下記のようになります。
arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/test-cluster 1772364732292 - stderr E0301 11:32:12.292422 1 reflector.go:205] "Failed to watch" err="failed to list *v1.VolumeSnapshotContent: the server could not find the requested resource (get volumesnapshotcontents.snapshot.storage.k8s.io)" logger="UnhandledError" reflector="github.com[FILE-PATH]" type="*v1.VolumeSnapshotContent" - - - -
CloudWatch Logs Insights との相性から考えて、よほどの拘りが無ければ json を選択すれば良いと思います。
料金
EKS Auto Mode で AWS 管理リソースのログ出力設定を行う際、CloudWatch に Vended Logs 扱いで出力することが可能です。
各 Auto Mode 機能は CloudWatch Vended Logs の配信ソースとして設定でき、標準の CloudWatch Logs と比較して低価格で、組み込みの AWS 認証と承認を備えた信頼性とセキュリティの高いログ配信を実現します。
https://aws.amazon.com/jp/about-aws/whats-new/2026/02/amazon-eks-auto-mode-enhanced-logging/
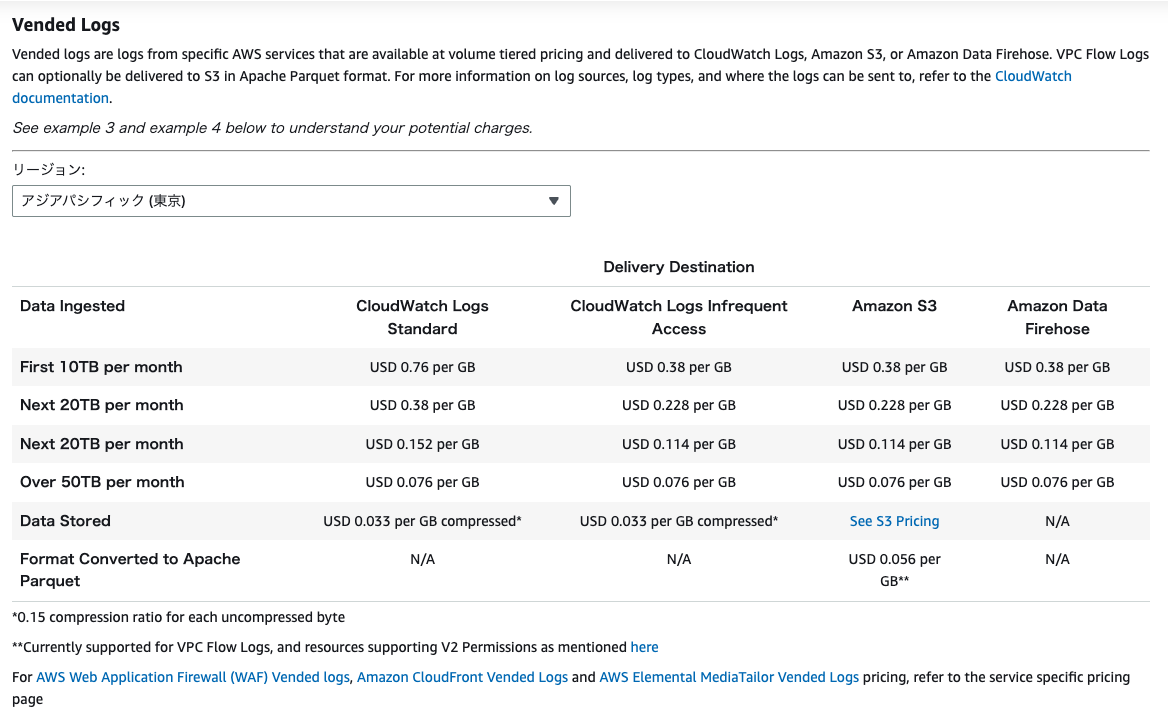
Amazon CloudWatch 料金表 ※画像は 2025 年 3 月 1 日時点
ログの流量が多い場合は CloudWatch Logs の取り込み料金を大きく抑えることができます。
また、Vended Logs 経由の S3 配信を選択することで一番ログ流量が少ない Tier でも取り込み料金を半額にすることができます。
どちらを選択するかは CloudWatch Logs Insights の手軽さとコストを天秤にかけて判断するのが良いと思います。
出力先を CloudWatch Logs から S3 に変更する際に Update 操作はできず、ログ配信設定を作り直す必要がありますが、それでも大した手間では無いので、一旦 CloudWatch に出力してコストが気になるなら S3 といった方針も採れます。
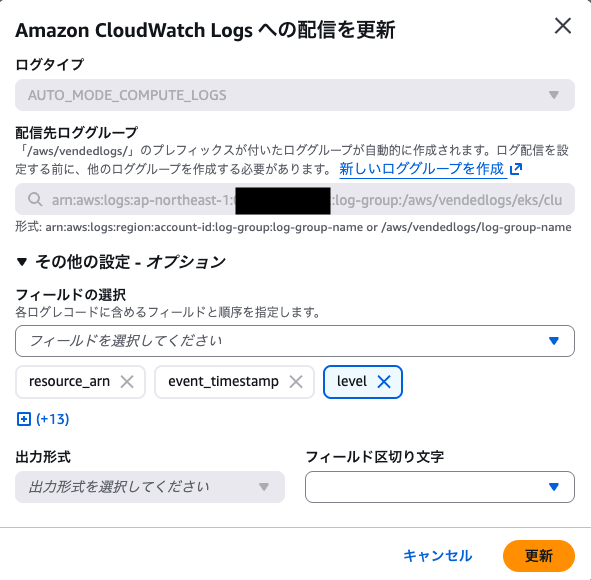
ちなみに、JSON フォーマットを指定しても、Lambda のようなログレベルによる出力ログの選択はできませんでした。
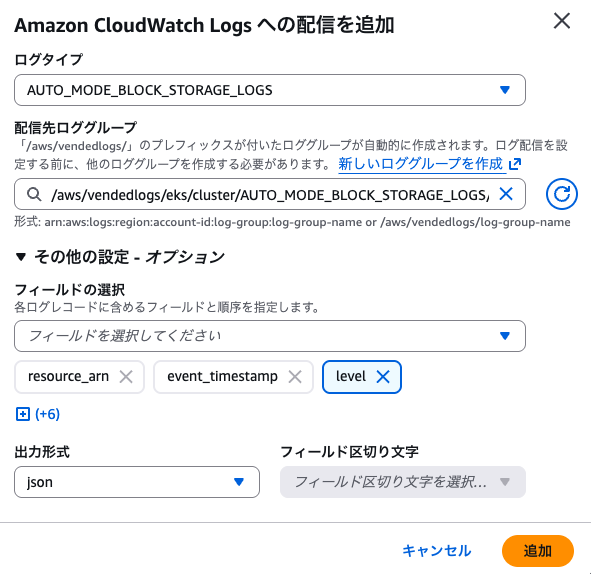
コントロールプレーンログのログレベルによる絞り込みも長らく放置されてますし、現状開発の優先度は高く無さそうですが、ノイズも多いのでできれば対応して欲しい所ですね。
最後に
AWS 管理コンポーネントのログを出力できないことは EKS Auto Mode のトラブルシューティングをやり辛くしていたので、かなり嬉しいアップデートでは無いでしょうか。
再現性のあるエラーであれば、一時的に有効にして調査するようなことも可能です。
EKS Capabilities のトラブルシューティングもかなり戸惑ったので、こちらのログ出力機能にも期待したいです。









