![[レポート] Event-driven architectures at scale: Manage millions of events #API307](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] Event-driven architectures at scale: Manage millions of events #API307
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、リテールアプリ共創部のmorimorikochanです。
現地でセッションを受けたので内容をレポートします。
概要
セッションカタログの内容は以下のとおりです。
タイトル
API307 | Event-driven architectures at scale: Manage millions of events
概要
Enterprises producing billions of events daily across hundreds of developers face unique challenges around schema management, evolution, and observability when scaling event-driven architectures (EDAs). In this session, discover proven patterns for building high-scale, event-driven systems that can be effectively managed and coordinated across a distributed organization with Amazon EventBridge. Learn best practices for enforcing schemas, versioning to evolve schemas without disrupting downstream consumers, and enabling schema discovery. Explore strategies for maintaining observability and monitoring the health of your event-driven systems, even as the number of producers, consumers, and event types grows.
その他
- Session types: Breakout session
- Topic: Serverless Compute & Containers
- Industry : Cross-Industry Solutions
- Area of interest: Application Integration, Event-Driven Architecture
- Level: 300 – Advanced
- Role: Developer / Engineer, IT Professional / Technical Manager, Solution / Systems Architect
Services: Amazon EventBridge
内容


このスライドの目次は上記のようになっていました。
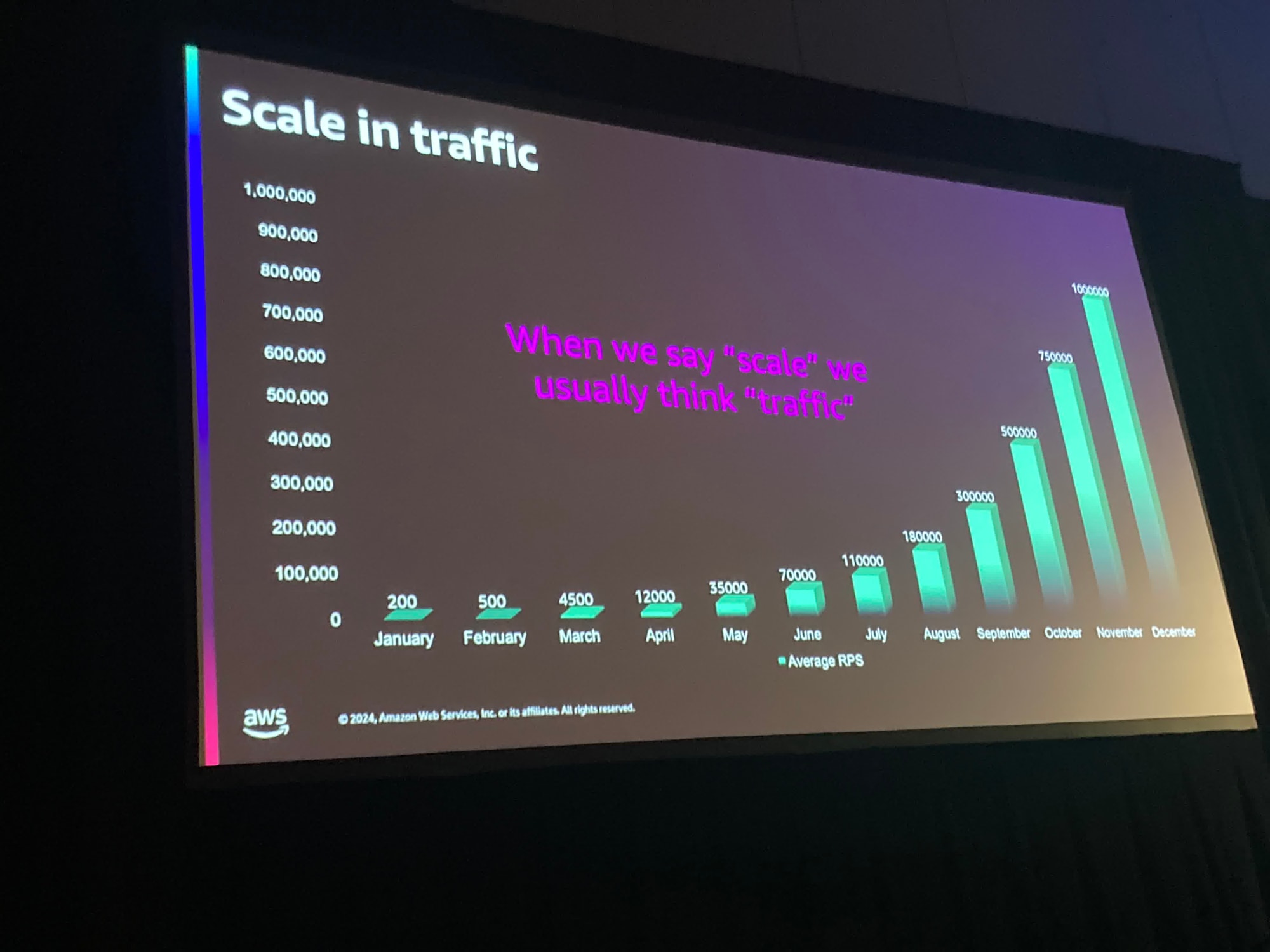

そもそもスケールするとはどういうことか、今までAWSがどのように増えるトラフィックをカバーしてきたかについて説明されていました
ちなみに、
million(=1,000,000) < billion(=1,000,000,000) < trillion(=1,000,000,000,000) となってます
Amazon MSKが数兆件/日のデータをリアルタイムに捌いているというのが数字が大きすぎて全く想像できないですね笑
ここでいうAmazon MSKはServerlessなのかどうかが少し気になりました。



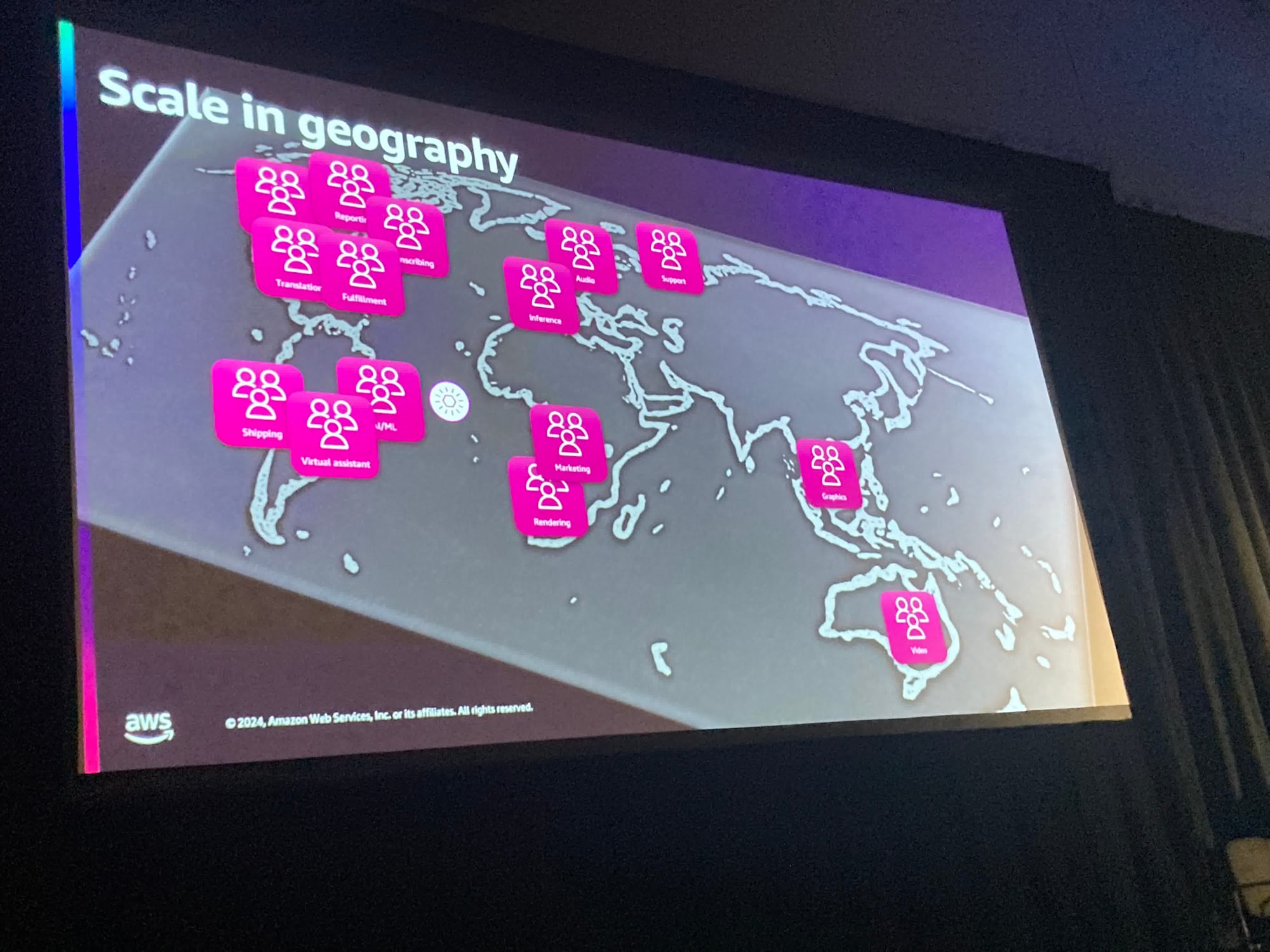

"スケール"とはトラフィックの面だけはなく、システムのアーキテクチャの面も存在しており、また、EDA(event-driven architecture)がある種の全世界に散らばったチームメンバーとのやりとりと似ていることについて話をされていました。
確かに、人間のやりとりは従来のリクエスト・リプライ型(こちらの記事ではそのように呼んでいたので拝借しました)のアーキテクチャというよりかは、イベントを一方的に押し付けるようなEDAの方が近いのかもしれません。
なんにせよ例えからの説明がうまくて面白かったです


"ボタンを押すと反応するだけ"、と、EDAのシンプルさについて語っていました。
"もし何かを書き留めたいならいますぐ鉛筆、ペン、メモ、紙を出した方がいいでしょう。本当に重要です" という前フリの後のこれだったのでめちゃくちゃウケてました😆

イベントとは何であるか、また、イベントスキーマはある種のProducerとConsumerの契約である、という点について説明していました。
こういう文脈の"イベント"は定義がなく感覚的なものだと思っていたのですが、言語化されると意外と定義があるんですね。
ちなみに、お話しされている方は2年半もの間、EDAに取り組んできており、今日のトピックの多くはそこから得た内容のようです

ここからイベントスキーマの話に入っていきます



EDAにはProducerとConsumerがあり、間にEventBrokerがいる、そしてそのEventBrokerは分類できる、と話ししていました。
EventBrokerをPull-based/Push-basedで分類する考え方は初めてでとても刺激的でした。
Push-basedがRoutersであるということもとても納得できます。
なのでこれに従うと、"EventBridgeとKafkaどちらを使うべきですか?"という問いに対する答えとして、その2つは大きく本質から異なっている、とも語っていました。


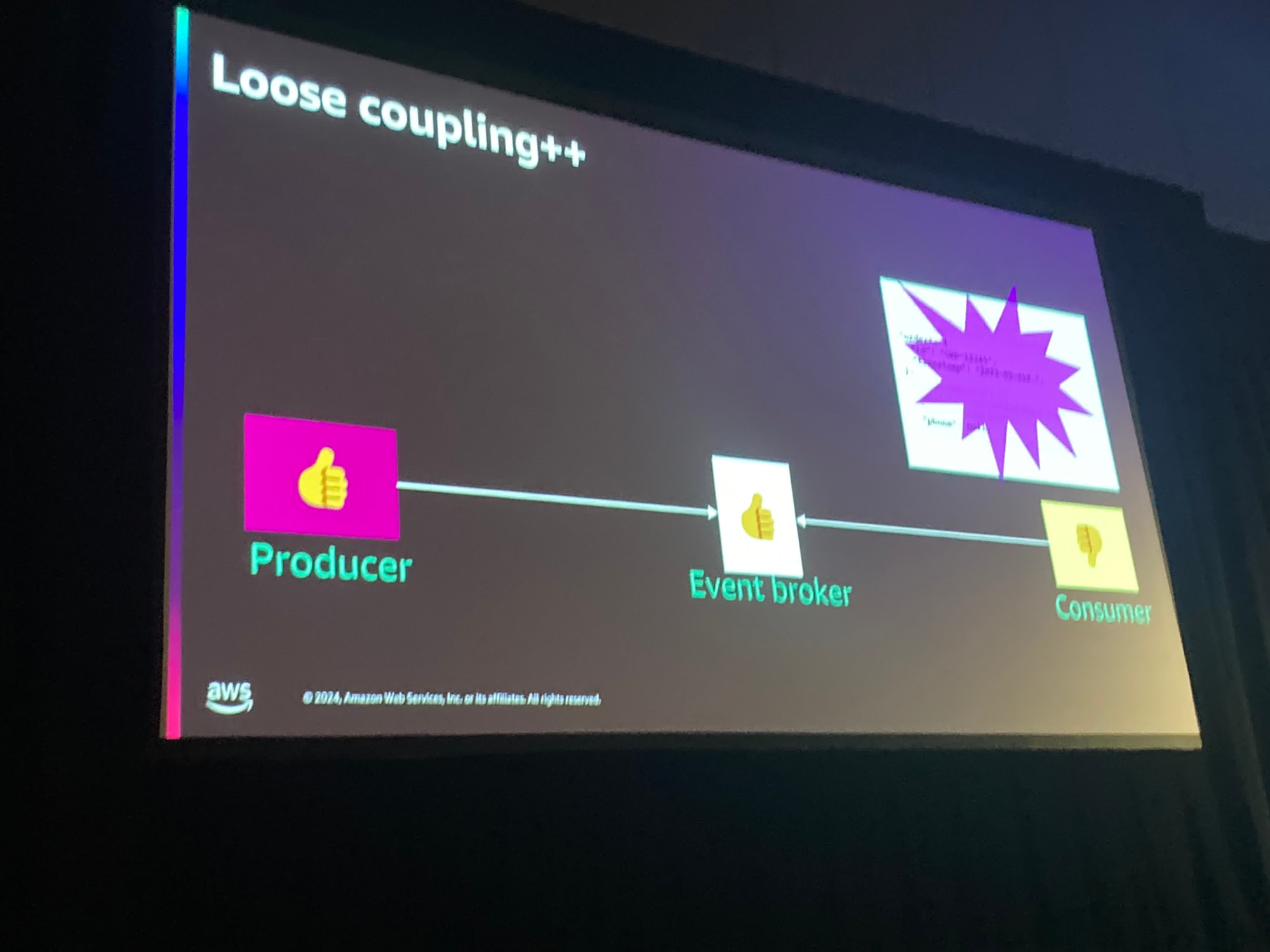

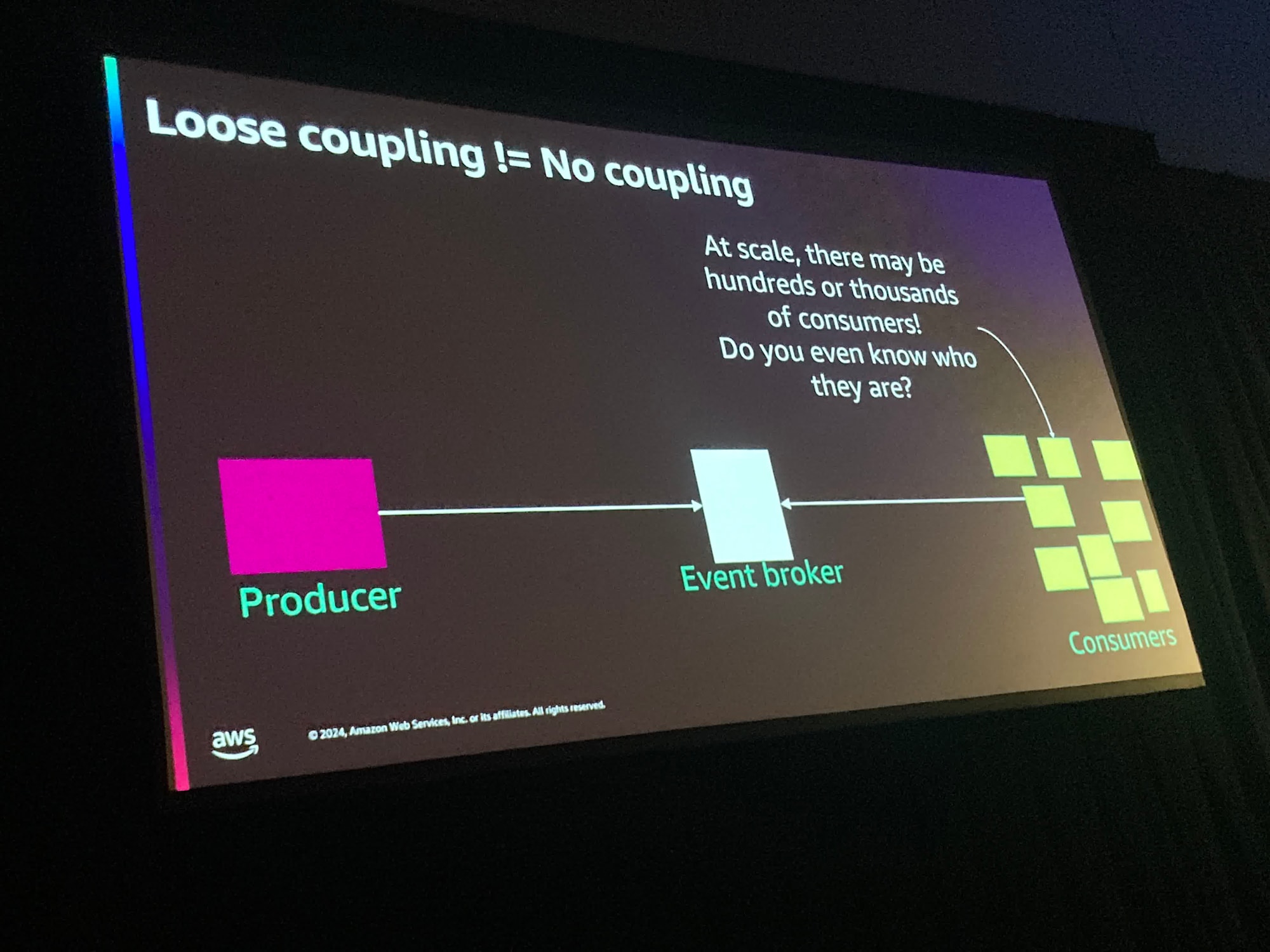
- EventBrokerが間に入ることでProducerとConsumerが疎結合になる
- 結合がなくなったわけではなく実際はイベントスキーマの変化により壊れるが起きる
- また、ひと度イベントの発行が開始されるとその契約(=イベントスキーマ)を遵守しなければならない、
- Consumerが増えて問題が発生した場合、誰がどのようにイベントを使っているのか判断できなくなってしまい、影響が大きくなってしまう
と話ししていました。
実際には、Consumerの管理が十分にできていないことはありえないとは思いますが、Consumerを正確に把握できていなかったりそれによる障害の影響範囲が大きくなったりすることは起こり得るなと聞いていて思いました。

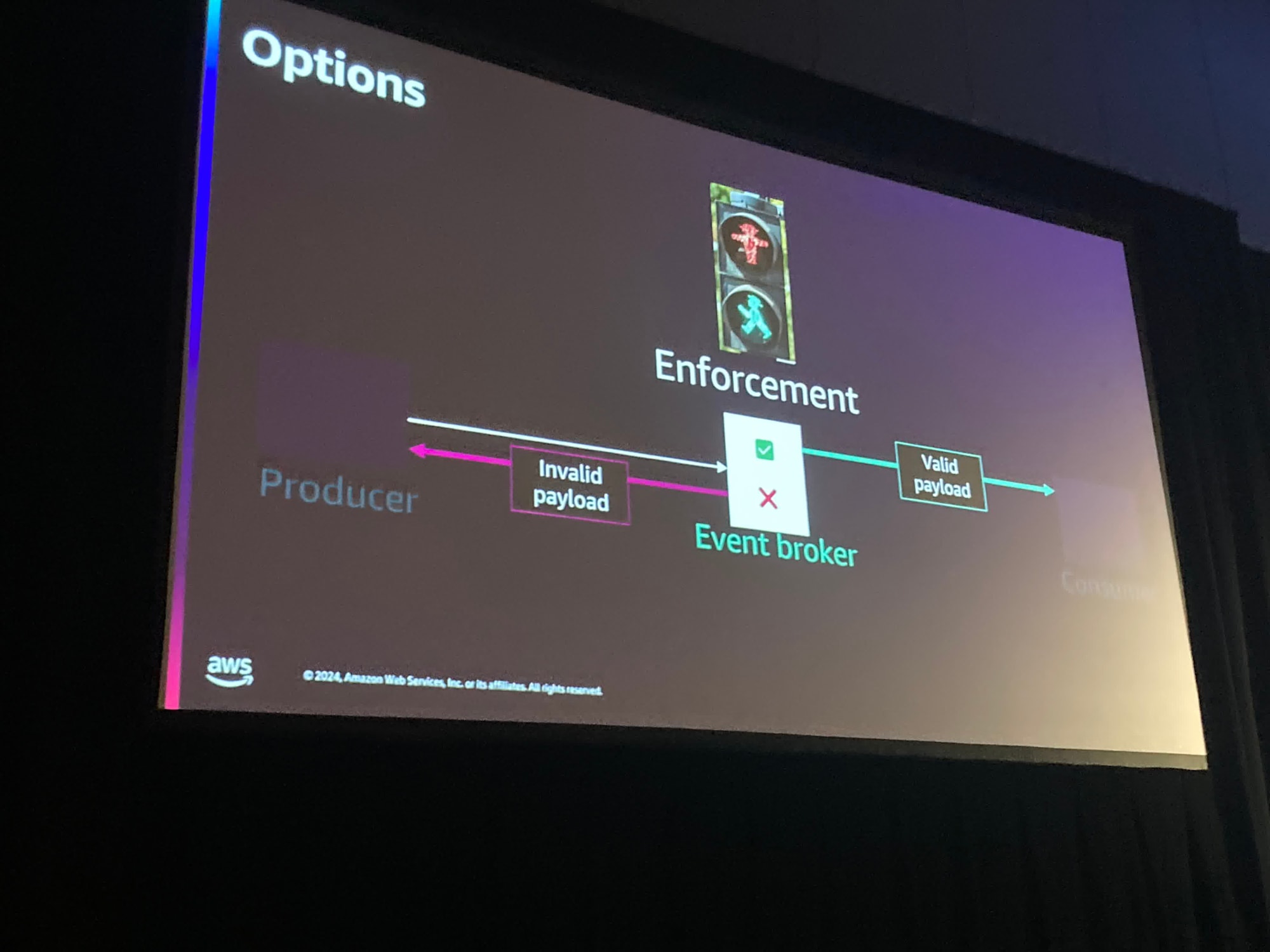
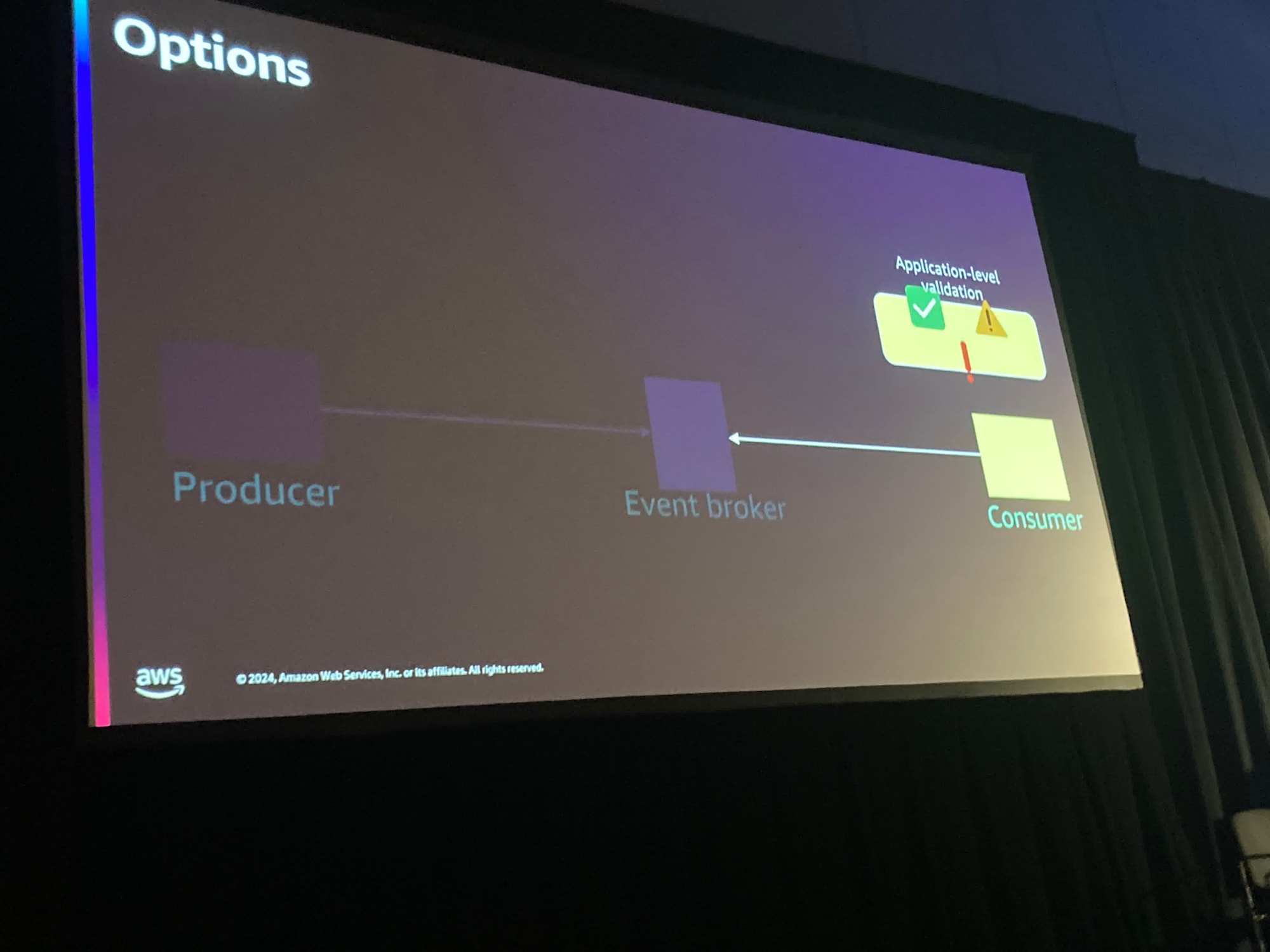
これを解決するための選択肢は、EventBrokerでペイロードが契約になっているかチェックすることだ、と話ししていました。
AWSだとAPI Gatewayのスキーマがそれに当たるのかなと聞いていて思いました

これ以降JSONスキーマに絞った話になっていて、"JSONスキーマを使うことで多くの問題を解決できる"、と話ししていました。
すべての種類のチェックを行うことはJSONスキーマではできないですが、数値の大小や型の不一致などはどのConsumerでも共通なのでEventBrokerが行うのはとても妥当だと感じます。
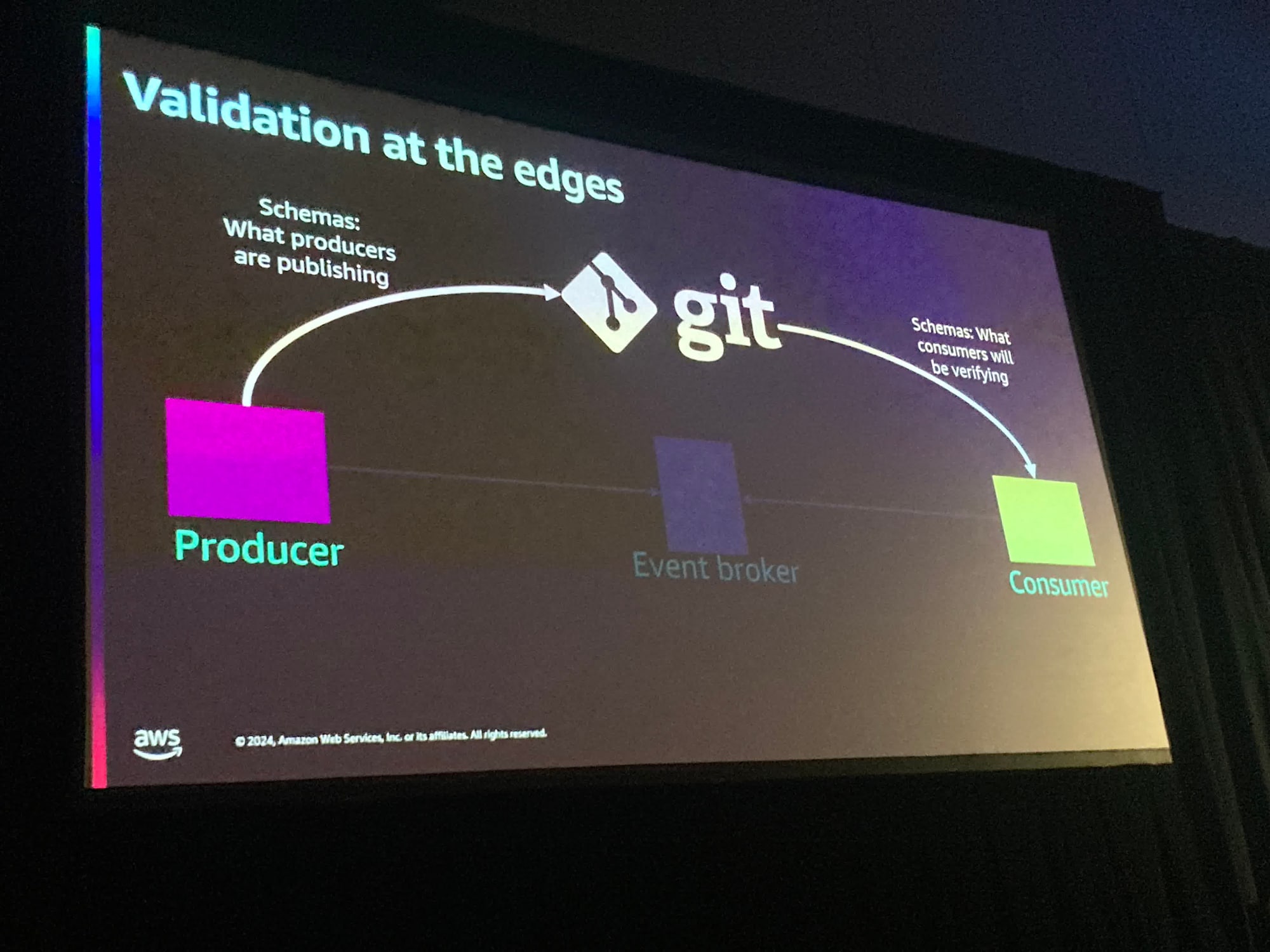
さらにここから、ペイロードの検証をより前方(=Producer)でやるために、イベントスキーマをGitなどを使い別要素として切り出す方法が紹介されていました。
この方法はイベントが公開される前に検証できるので、例えばJSONでないプロトコルバッファでも可能である、とのことでした。
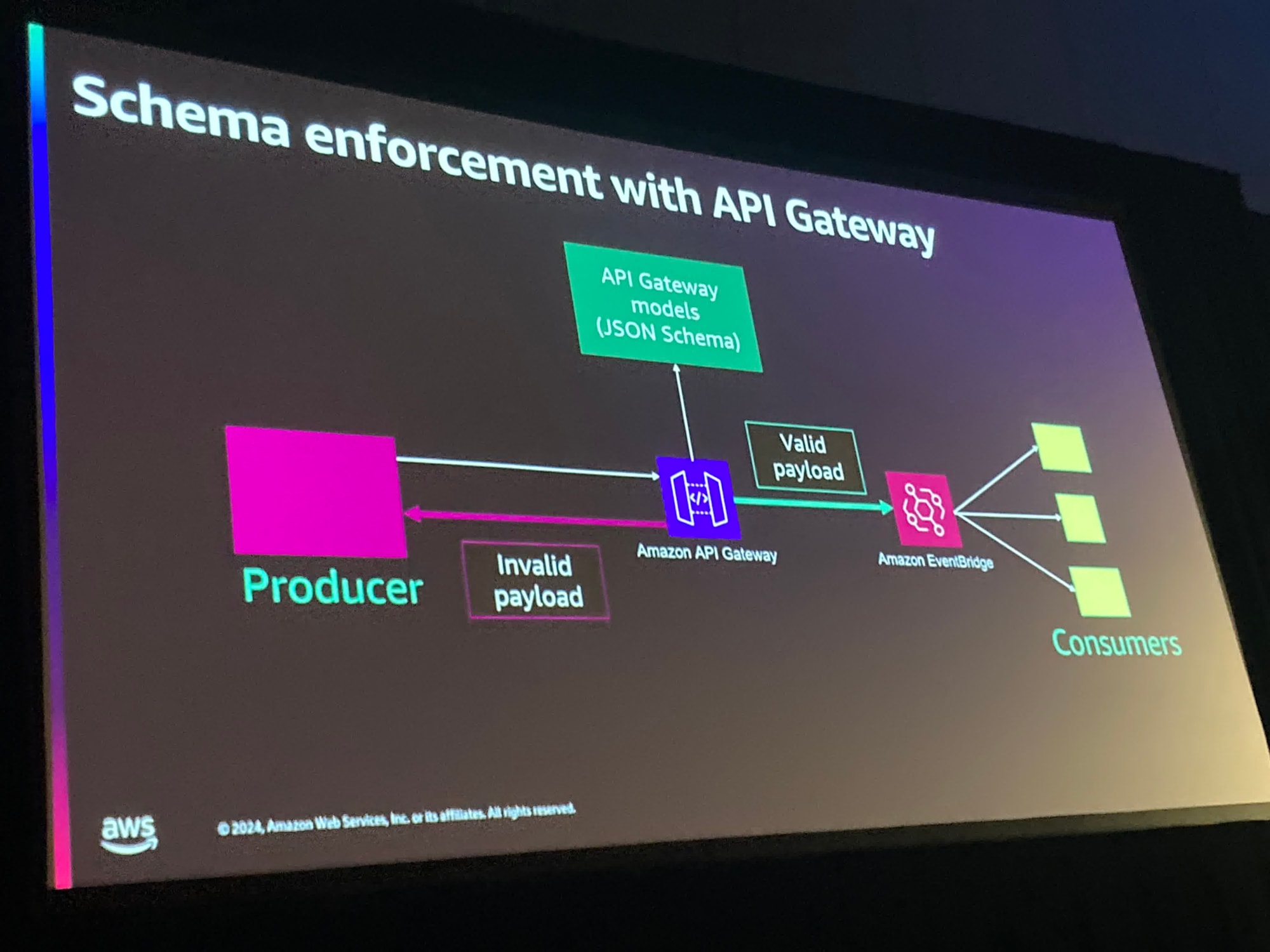
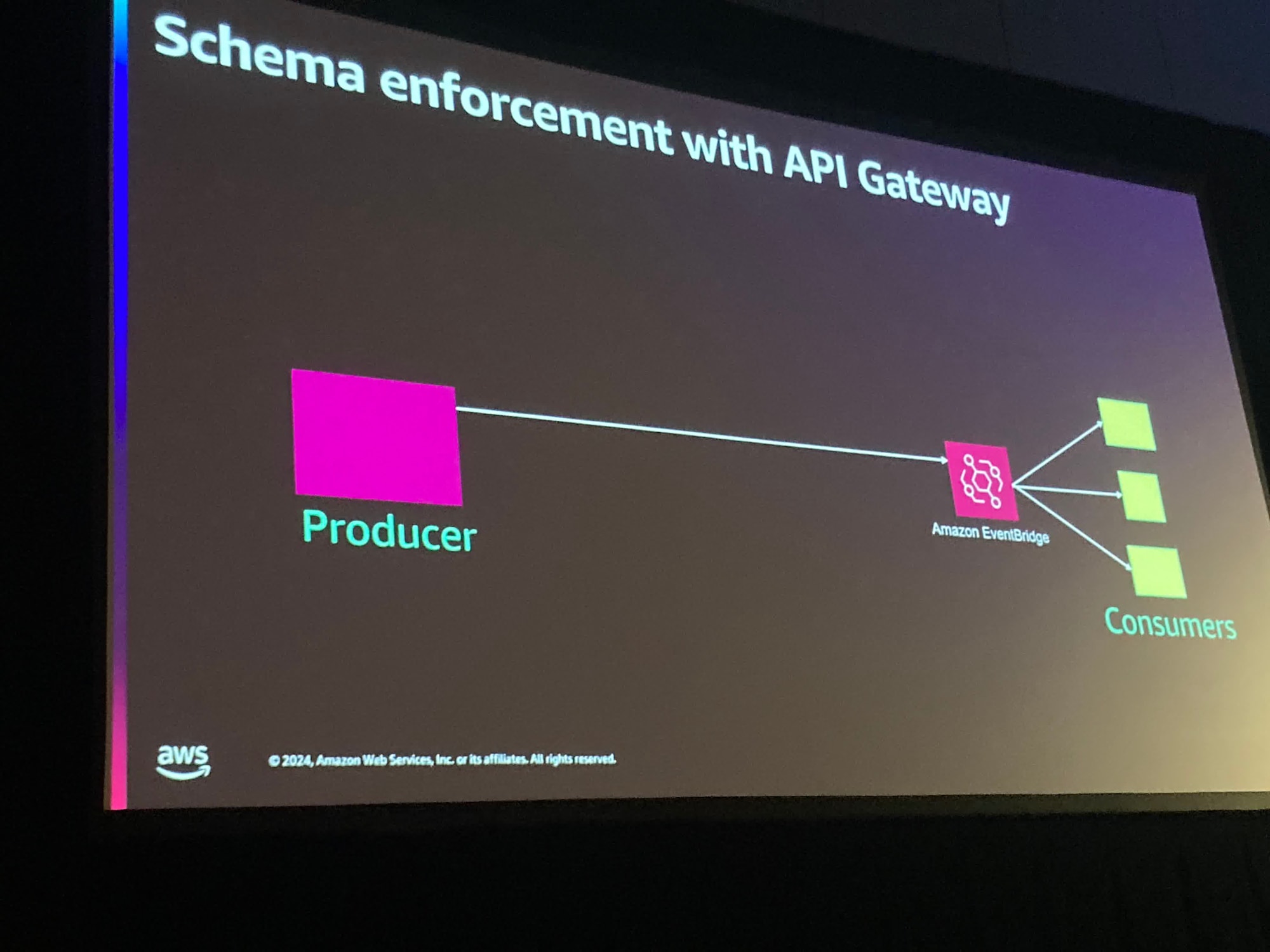
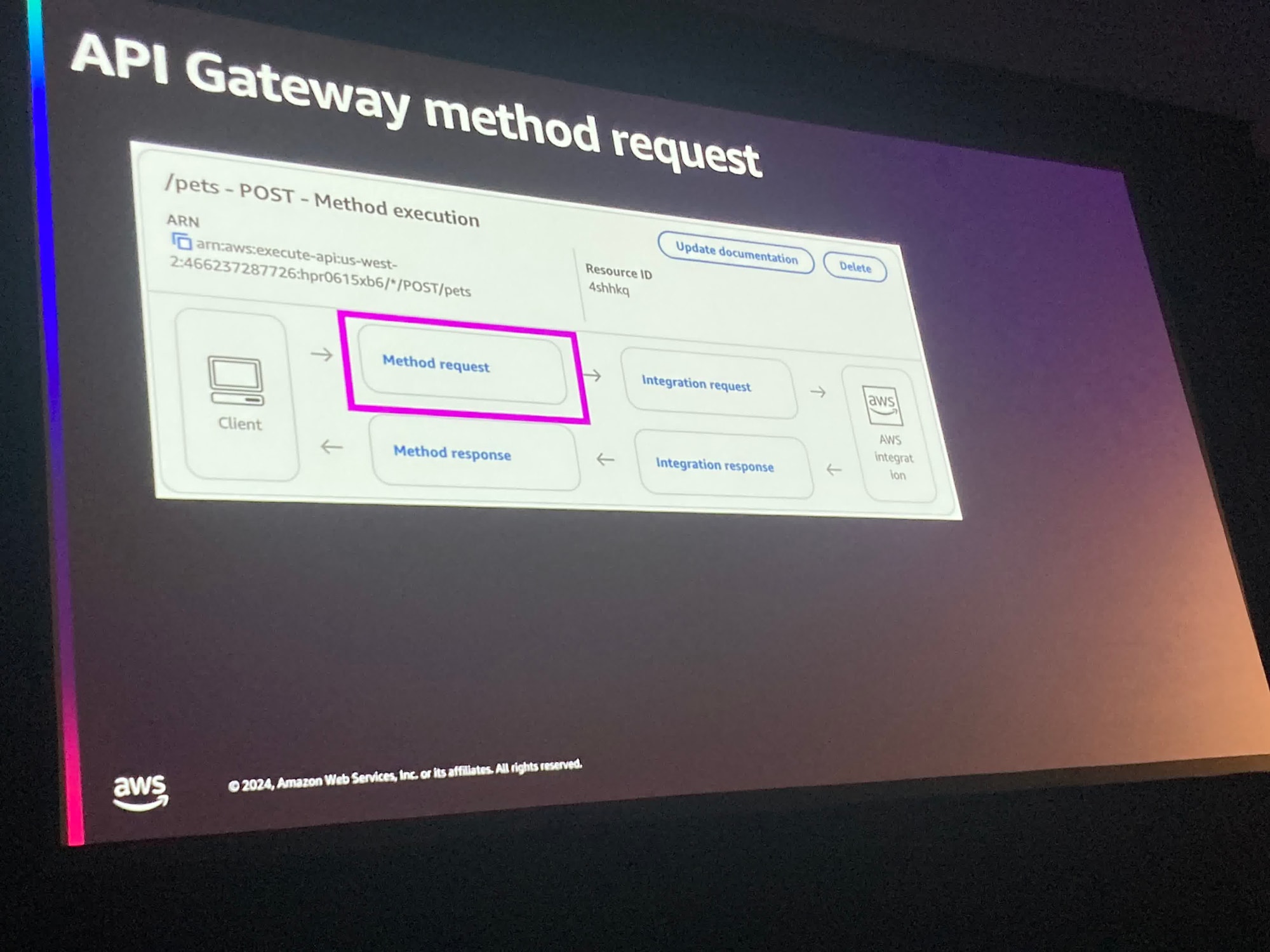
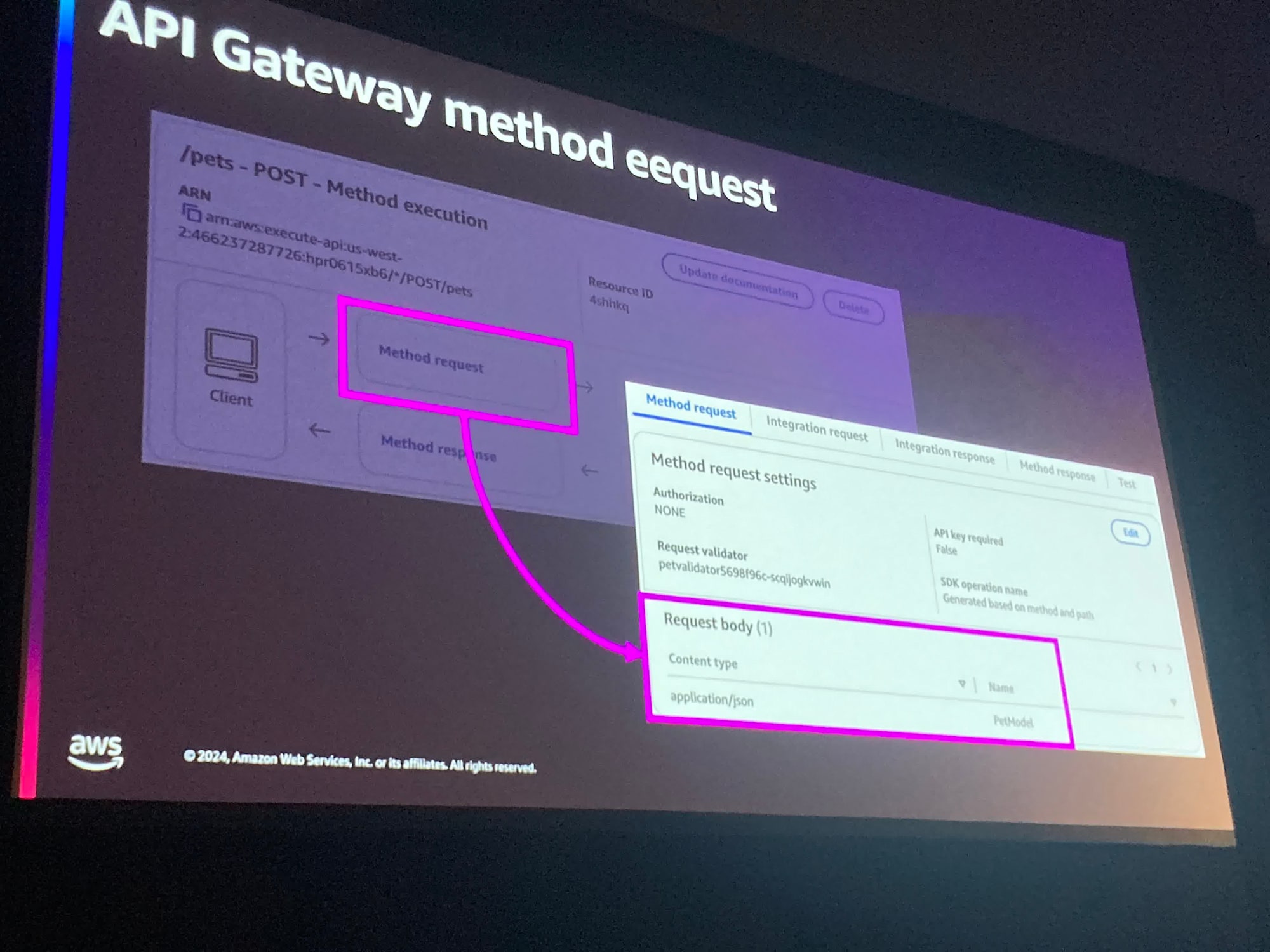
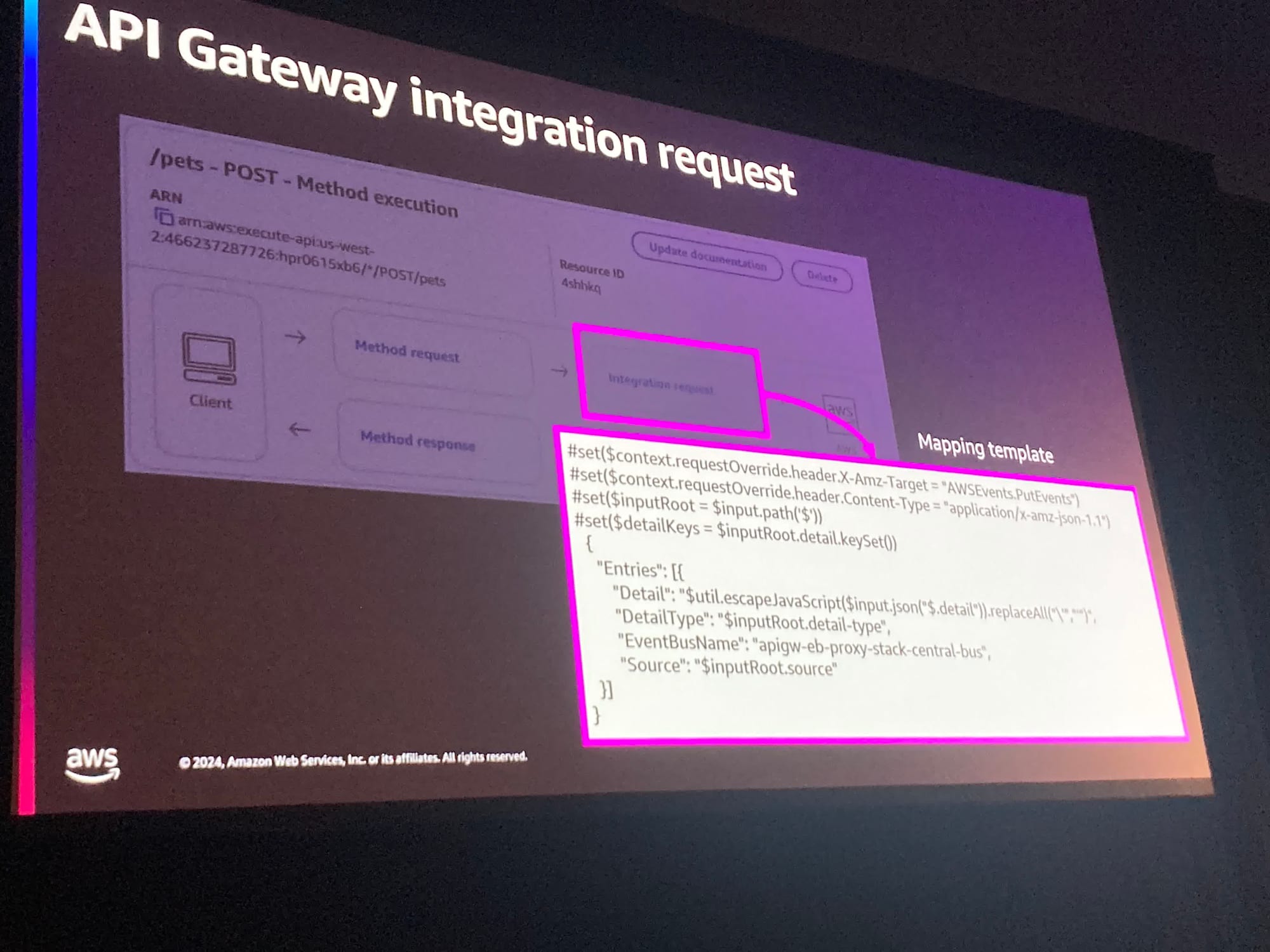
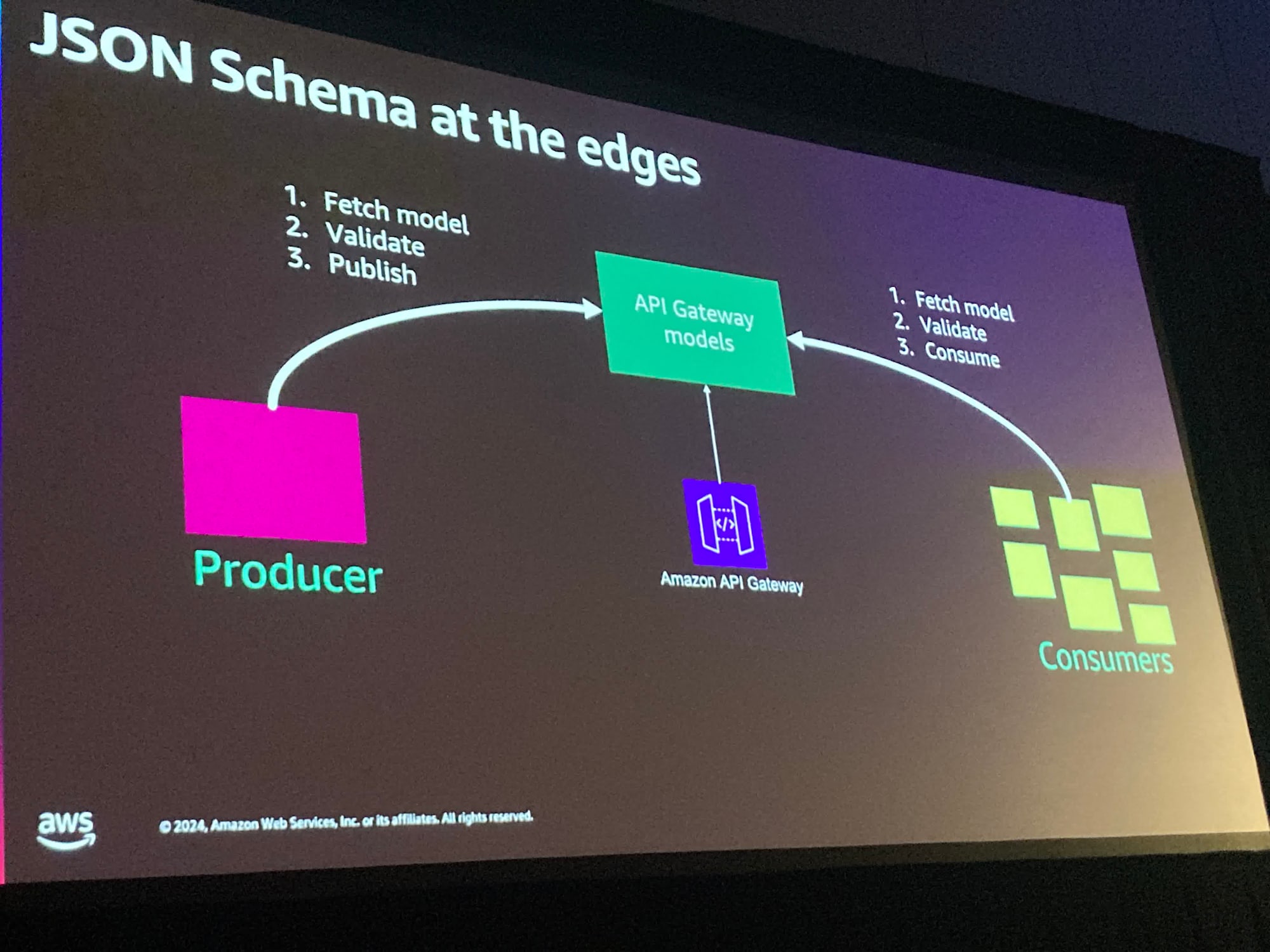
ここで具体的なサービスについての話になりました。
APIGatewayのModel機能を使うことでバリデーションを行うことができ、さらにProducerやConsumerがそれを使ってそれぞれでバリデーションできる、という構成が紹介されました。
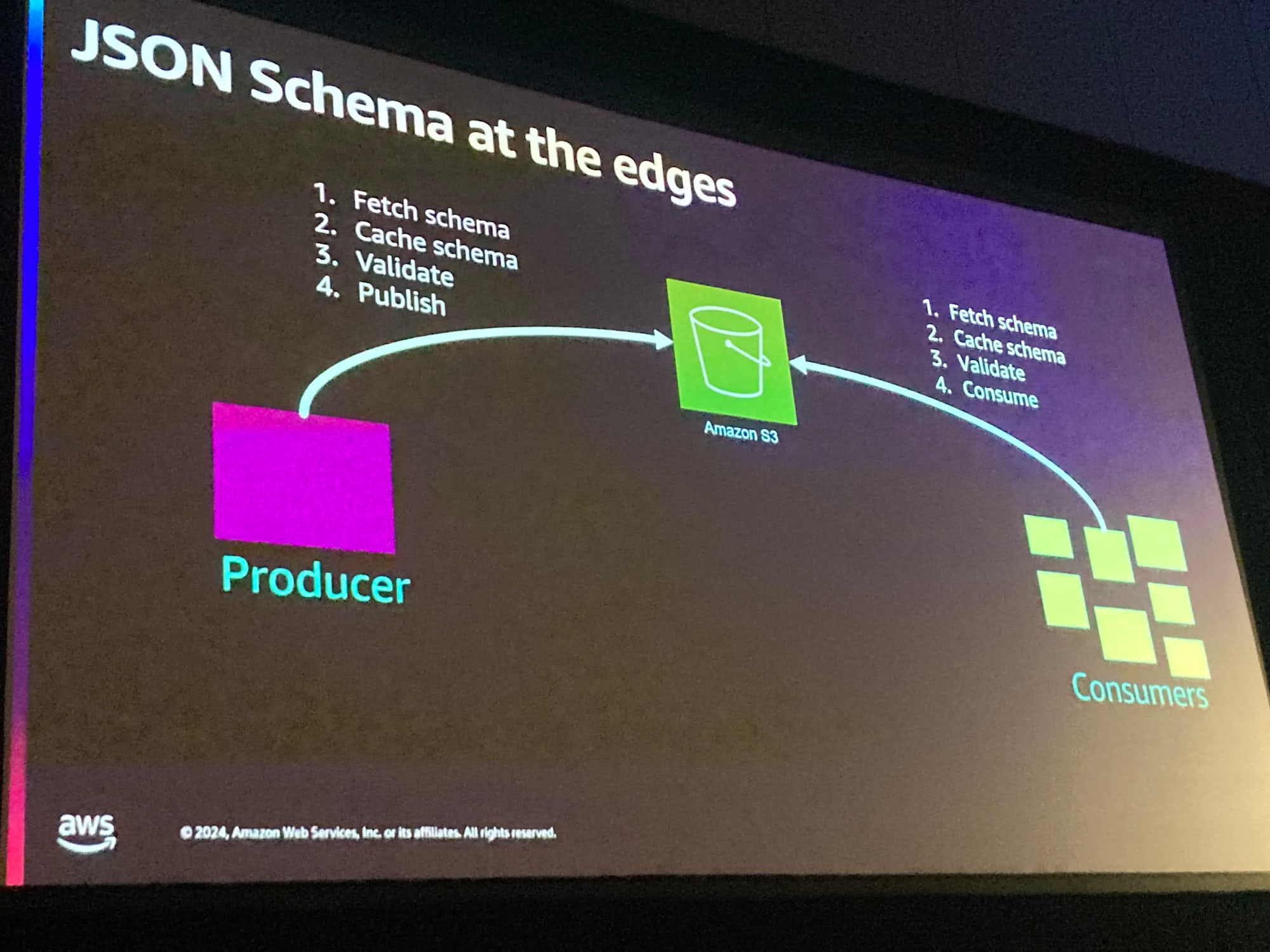
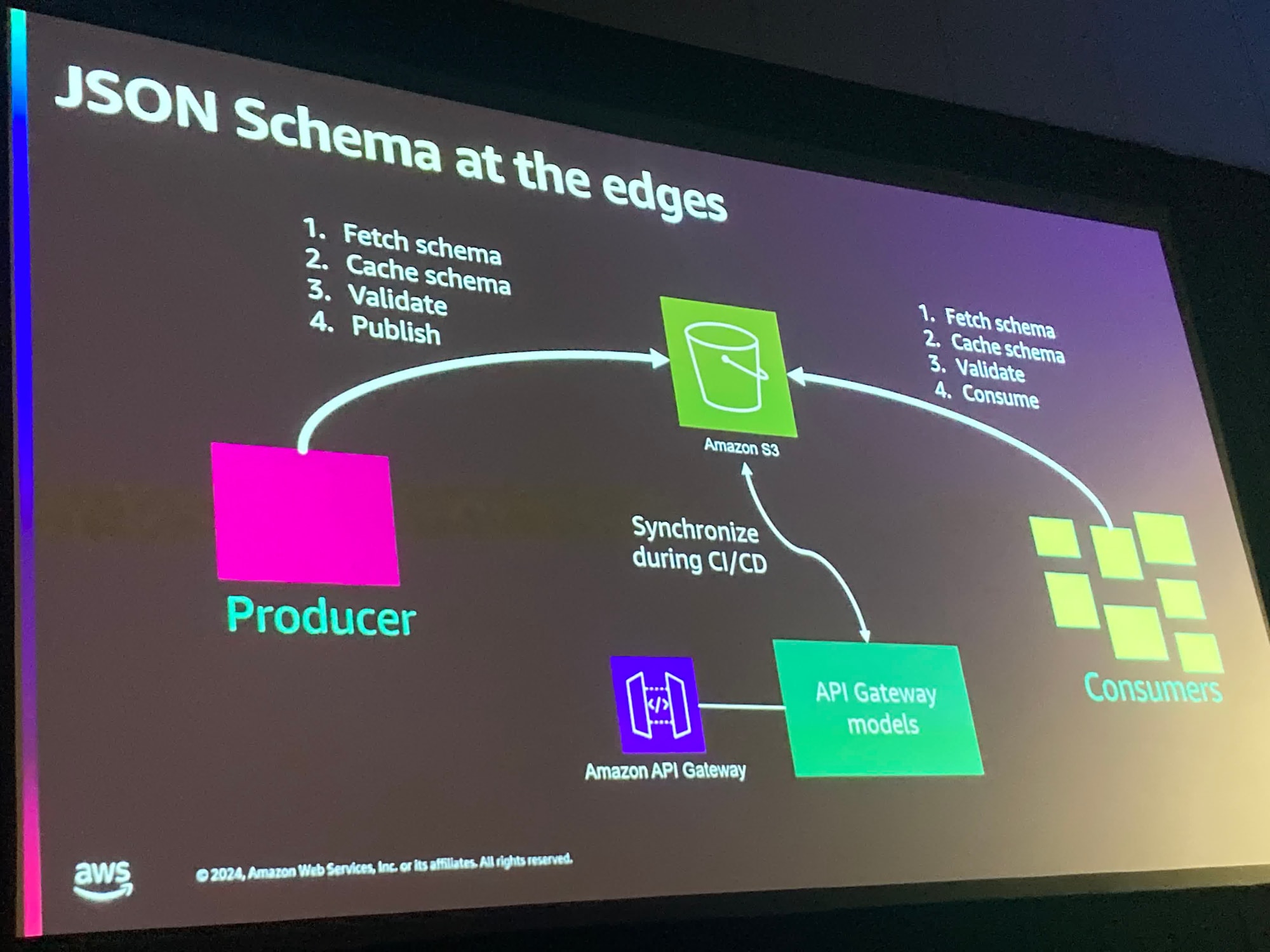
上記構成でAPIGatewayのAPIの呼び出し部分のが気になる場合は、例えばS3や他の場所にスキーマを保存しておくことで解決できるしょう、と話ししていました。

Pythonでのサンプルコードです

ここから、スキーマの変化に関する話です



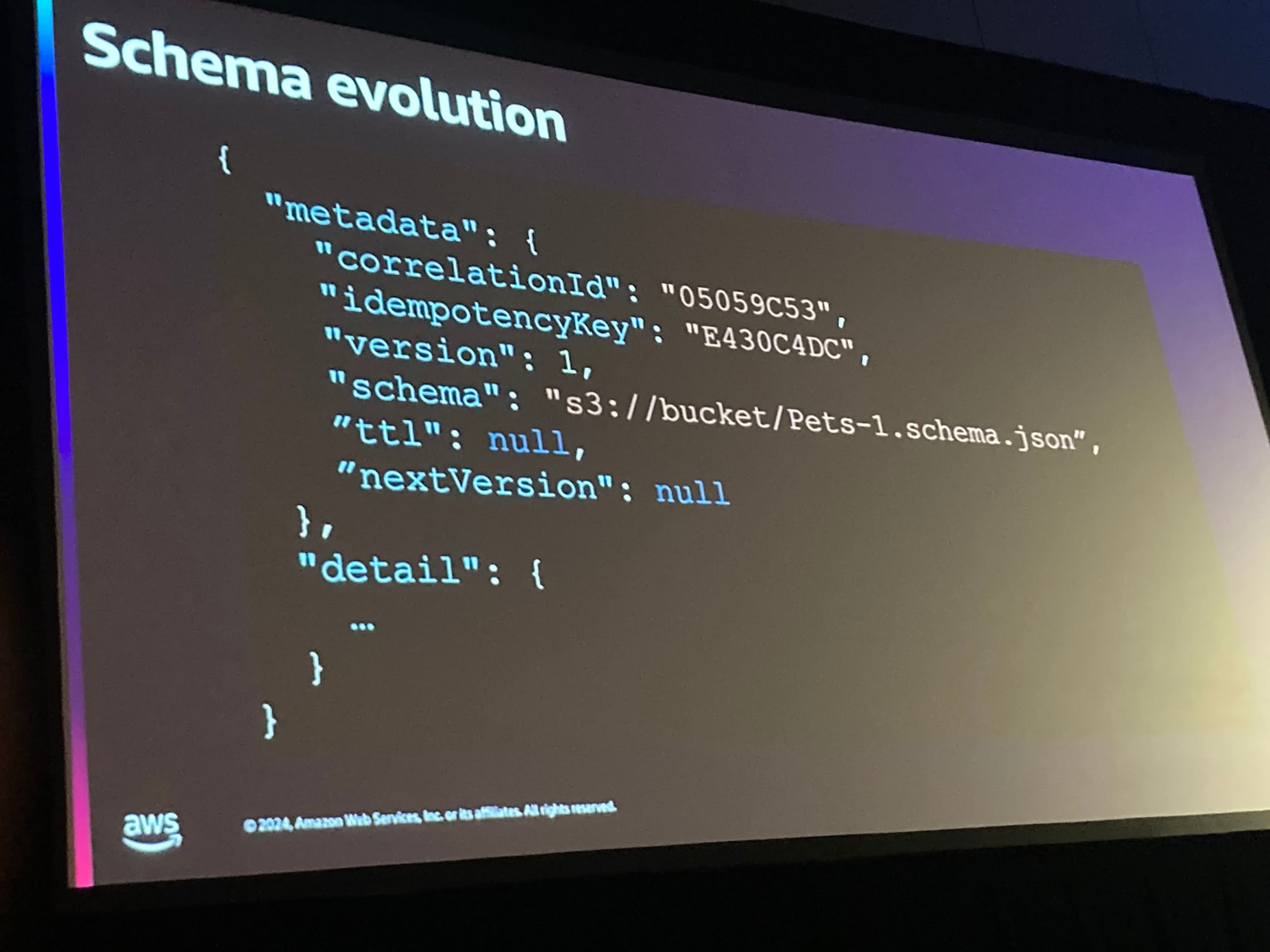

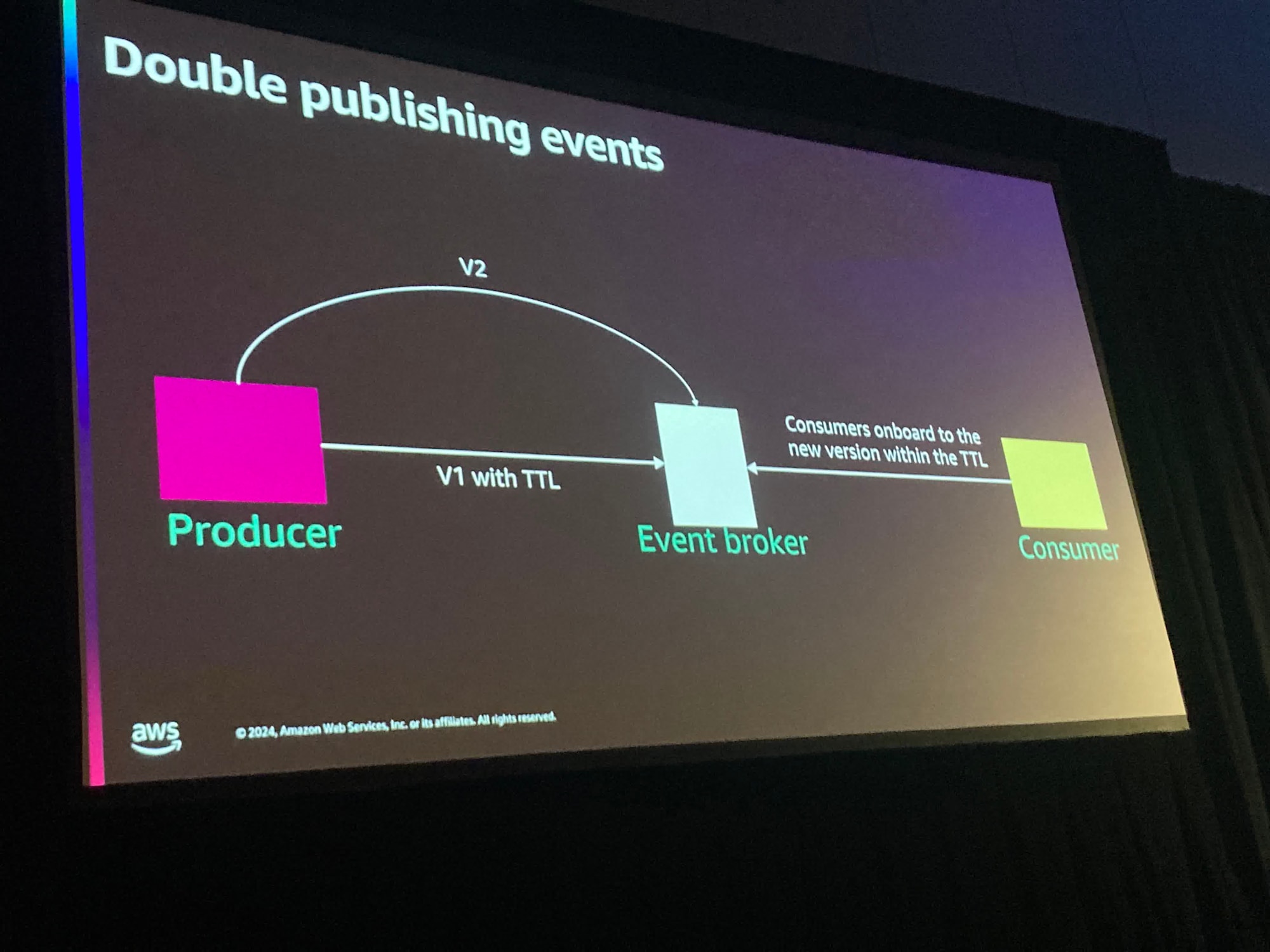
このスライドのように、現在のスキーマのバージョンをProducer側からのリクエストに含むことで、Consumer側からの検証が容易になる、と話していました。
APIリクエストやレスポンスにバージョンが載っているものはSaaSなどでは度々見るものの、ダウンロード可能なスキーマのURLが存在するという点では非常に優れた方法だと思います。
というのも、Consumer側で不可解なバリデーションの問題が起きた際に、どのバージョンの何のスキーマによって引き起こされたかが簡単に開発者がトラッキングできるためです。
"あれ?このスキーマ変わってる?最新じゃなかったの?"と思った経験は多分みんなあるんじゃないでしょうか、

ここからはイベントスキーマのマネジメントについてです

イベントスキーマの管理をAWSで行うには、 "AWS Service Catalog"や"Amazon EventBridge schema registry"であり、さまざまなサービスのイベントスキーマが登録されていることを紹介していました。

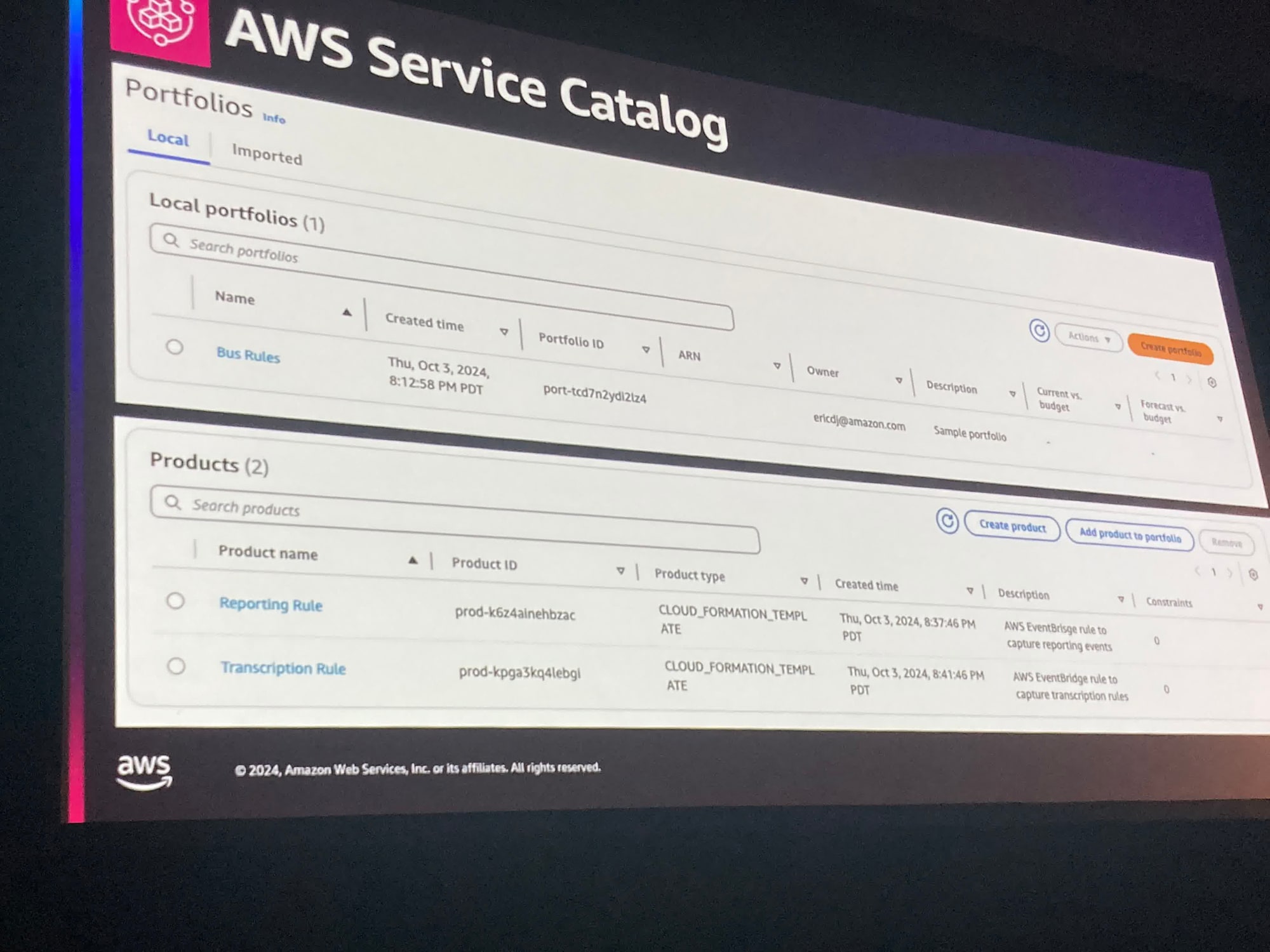
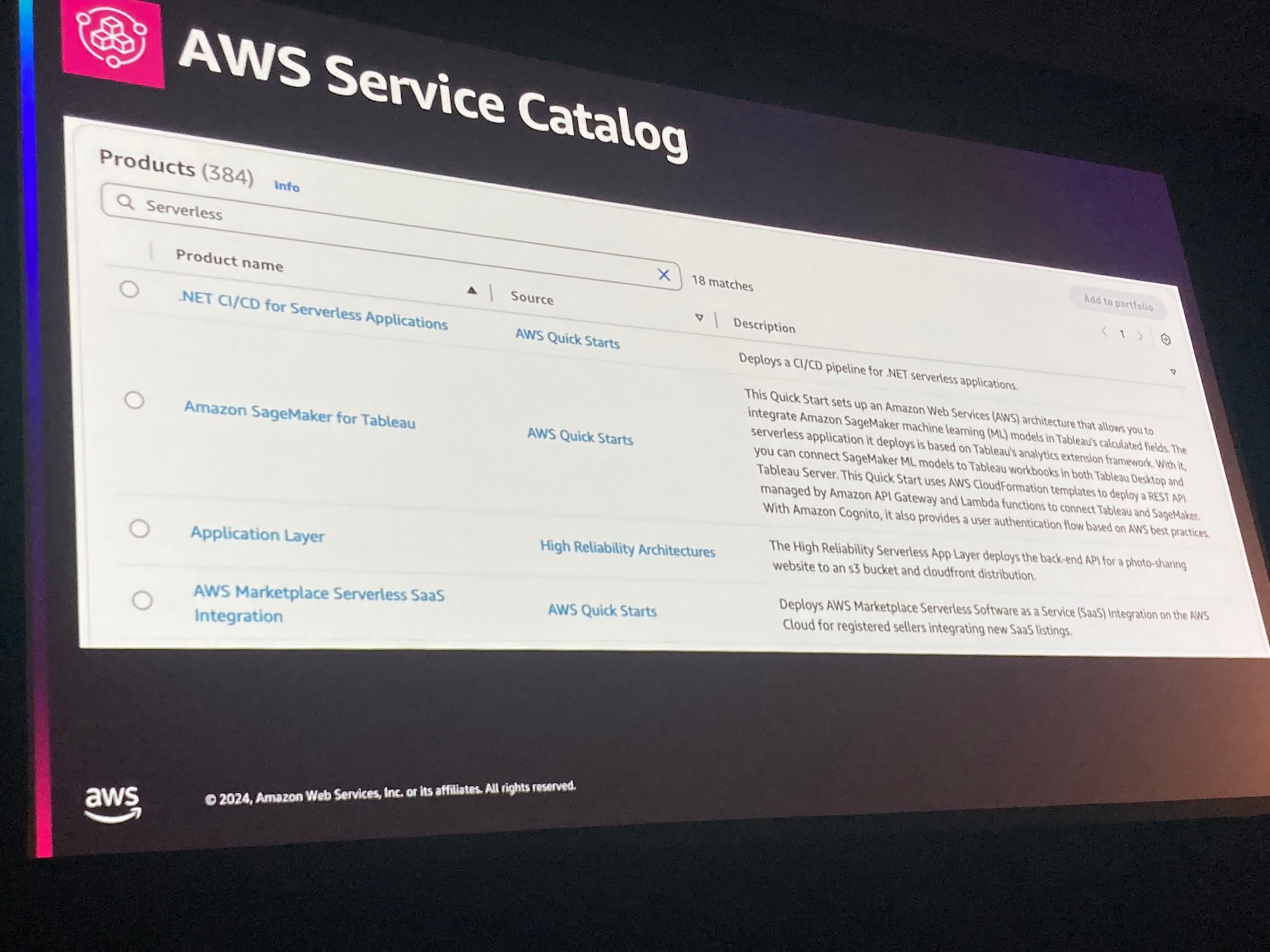



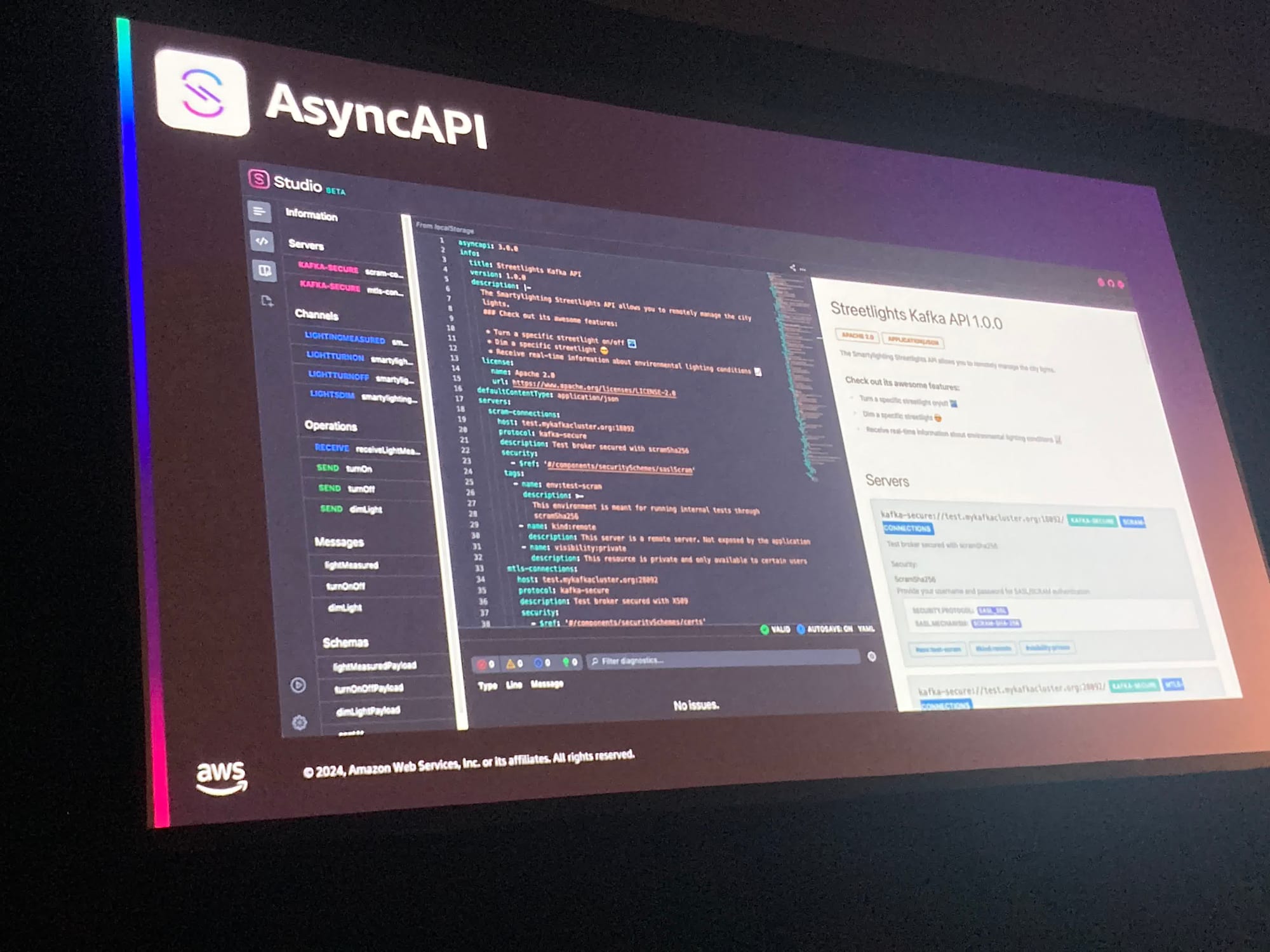
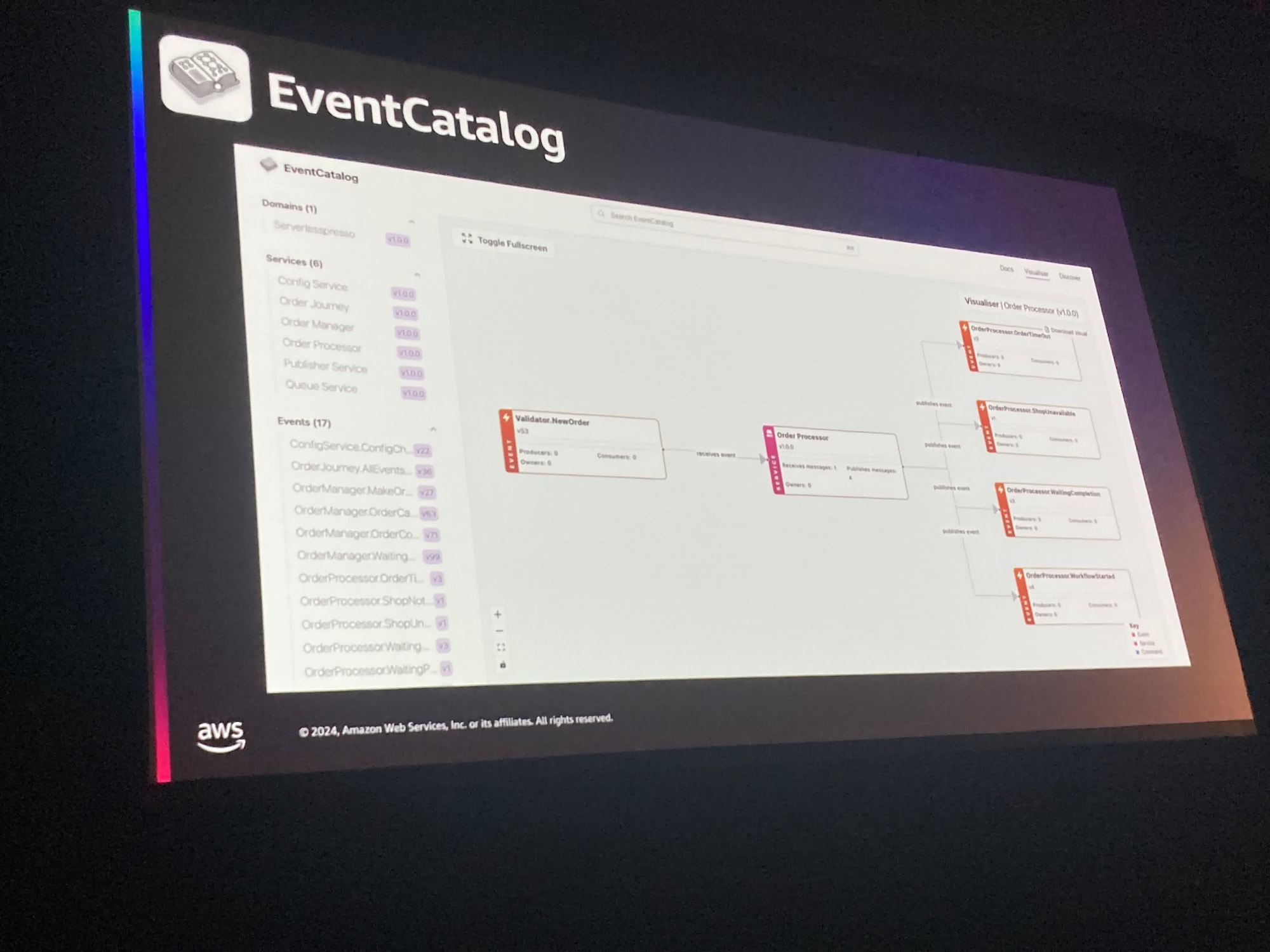


また、EDAのイベントスキーマを定義することに特化したツールのAsyncAPIやEDAのコンポーネントを管理するEventCatalogも紹介されており、これらを組み合わせることで、Amazon EventBridge registoryにAsyncAPIのスキーマを取り込むことができるそうです。
APIGatewayがリクエストのスキーマを定義できるように、EventBridgeでもイベントのスキーマが定義できるようになるのは面白いですね
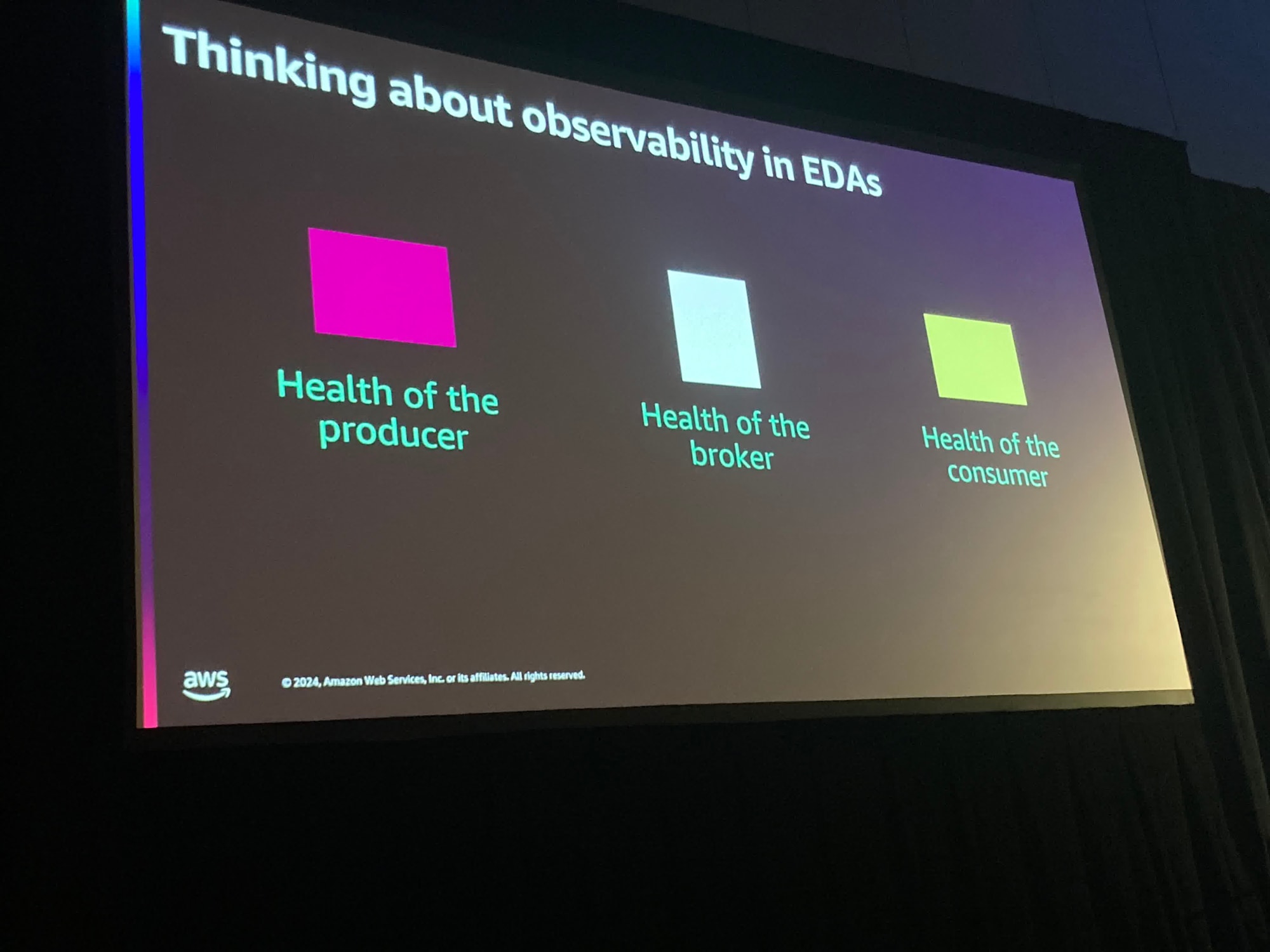

これ以降はEDAのObservabilityについてです。
アプリケーションはいわば船のようであり、イベントの発生地点から最終目的地の間に多くの中継展があり、問題が発生した際にとても複雑になる、と話ししていました。



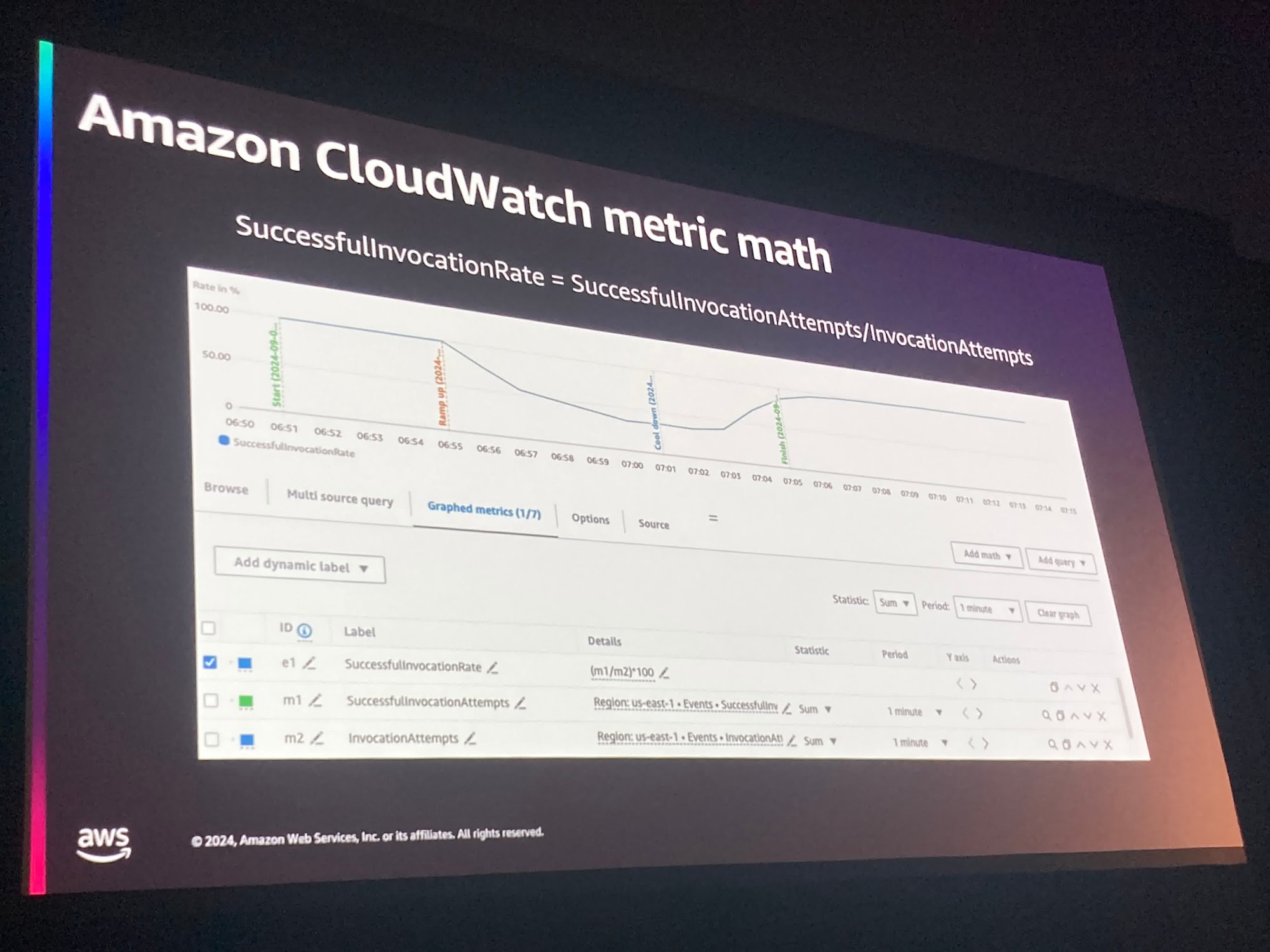
実際にAWSではEventBridgeの健康状態についてAWSがサポートしており、CloudWatchのmetricsをチェックすることができるが、これらはただのカウント数なので、イベントの成功率などのレートを出すにはMetric mathを利用してmetrics同士の計算が必要だと話していました。
実際に上記のスライドでは以下で算出していますね。
(m1/m2)*100
- m1: SuccessfullInvocationAttempts
- m2: InvocationAttempts

処理失敗については3つのメトリクスが存在しているようです。
これらすべてを適切に監視する必要がありそうですね。
特に、InvocationsFailedToBeSentToDlqは極力減らせるようにするべきだと感じます

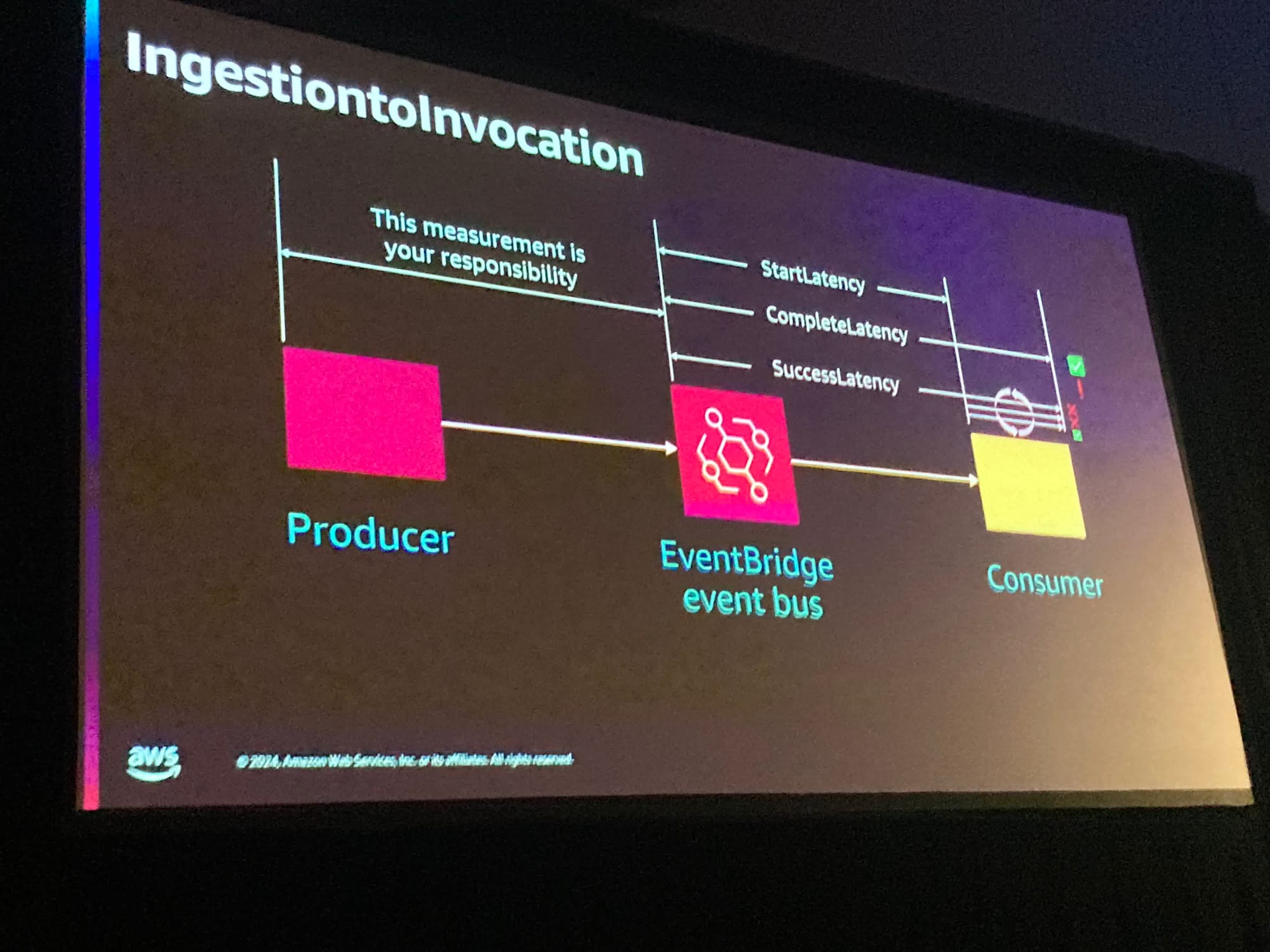
また、EventBridgeからConsumerへのレイテンシーについても同様にいくつかメトリクスが提供されておりこれを使うことができます、とのことでした。
ただし、ProducerからEventBridge event busまでのレイテンシーはProducer側で計測する必要があると注意していました
もしそのように実装した場合、ProducerからEventBridge event busのレイテンシのデータを外部のメトリクスサービスに流してしまうとProducerからConsumereまでのトータルのレイテンシがわかりにくくなってしまうので、基本的にはProducerからCloudWatch metricsへカスタムメトリクスを発行してCloudWatch上でトータルのレイテンシを計算する方がベストなように感じました。

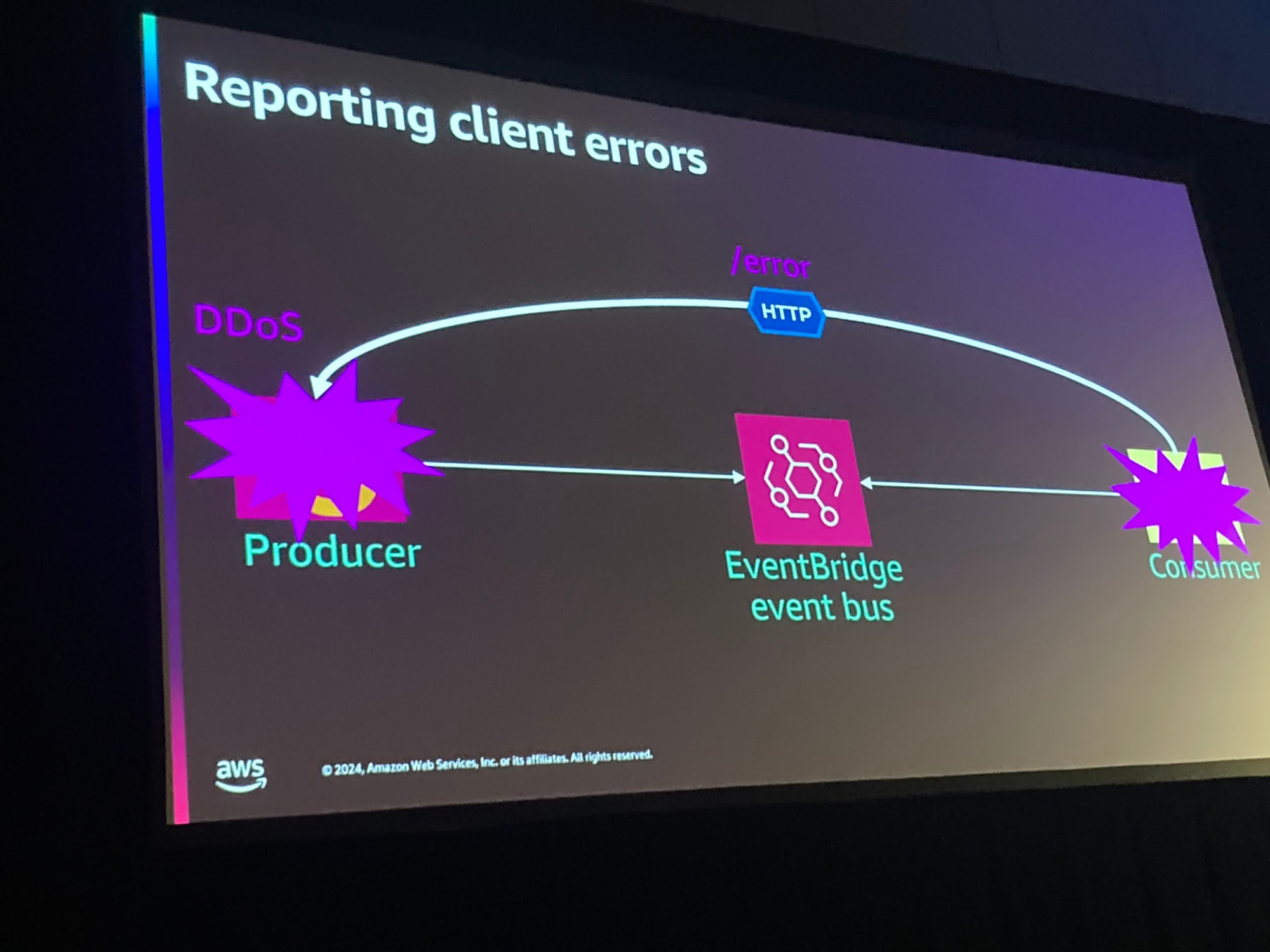
Consumerで問題が発生した場合、どのようにProducerに伝えるのが良いかについて説明していました。
例えばもしProducerに直接エラー内容をHTTPリクエストで伝えていると、自己循環してしまう可能性がある、なのでこのようなConsumerからPrducerへエラーを伝える場合も非同期に処理をしろ、と話ししていました。
ただ、ここで面白かったのが"もしConsumerでイベントが正常に処理されたかを全て知りたいのであれば、それは同期的な処理に戻すことをお勧めします"と主張されていたことです。
確かにProducerがConsumerのことを細かく知りたいのであればそれはもう疎結合ではなく密結合でありそもそもEventBrokerを挟むべきではありません。
ここの割り切りができるかどうかは、EDAを導入するときに注意深く判断する必要があると感じました。
と言っても、ProducerがConsumerのことを気にする必要がないような場面は限られていそうで、思いつく限りでは以下のような場面が想像できました。
- Producerが処理した結果が100%覆らない場面
- オークションや株取引など
- ビジネス上の重要度がConsumerよりProducerの方がはるかに高い
- 例えば、LINEやSlackなどのチャットサービスのwebhook呼び出しとか
- Producer(チャットサービス運営側)とConsumerでは問題発生時の影響範囲が桁違いだと思います
- 例えば、LINEやSlackなどのチャットサービスのwebhook呼び出しとか

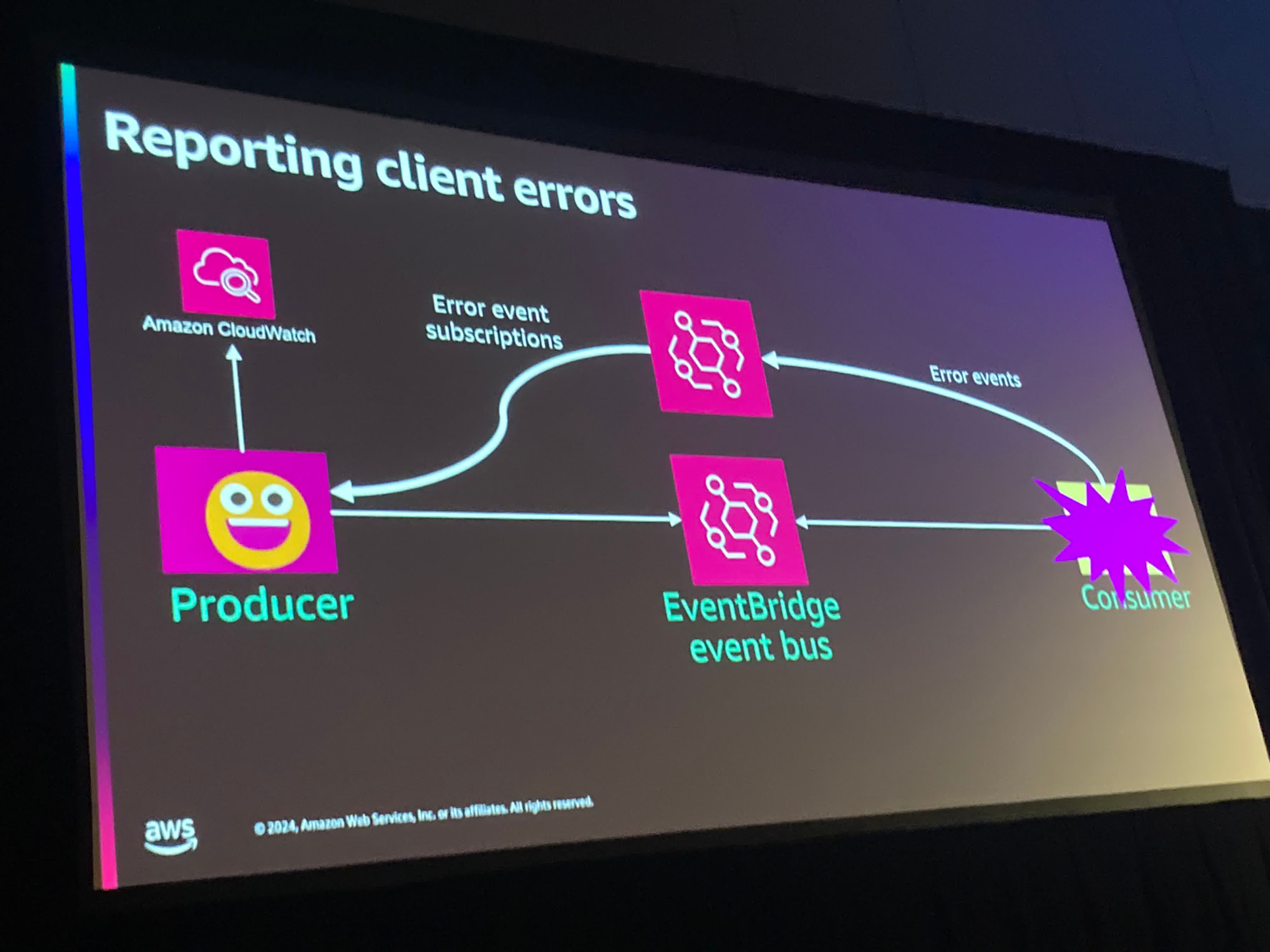
上記の手法ではConsumerがProducerの存在を知っていましたが、知らなくても良いようにConsumerとProducerの間にエラーを集約するコンポーネントを配置し、Proucerからはそのコンポーネントのメトリクスを見に行く方法も紹介されていました。
先ほどと比べて構成が綺麗ですね。


まとめとして以下の4つが挙げられていました
- できるだけ結合を減らす
- スキーマを強制する
- イベントとイベントの変化を理解し計画すること
- オブザーバビリティを念頭に置いてEDAを始めること
感想
- まず、話し方が面白かったです
- 抑揚があってはっきり話されていたのでとても聞きやすかったです
- ちなみに本題に入る前のトークでドッカンドッカン受けてました
- また、話の例えが的確で、EDAに詳しくない私でもすんなり理解できました
- EDAがまるごと理解できた気がします!
- 特に、Event brokerのカテゴライズは腹落ちしました
- 今までこれらがほぼ区別できていなかったのでとても納得できました。僕もこのカテゴライズをどんどん使っていこうと思います
- ただやっぱり、EDAはどんなシステムにも適用できる銀の弾丸ではないし、適用すべきかどうかは本当に吟味が必要に感じます。
- 名前だけのEDAにならないように常に気を配るべきだと感じます
- 例えばエラーをProducerにHTTPリクエストする構成など最短手で考えるとそうなってしまうので
- 名前だけのEDAにならないように常に気を配るべきだと感じます
- 特に、Event brokerのカテゴライズは腹落ちしました








