
ECS Managed Instances のイメージキャッシュでタスク起動はどれだけ速くなるのか Fargate と比較してみた
はじめに
クラウド事業本部、あきやまです。
先月AWS summit 2026 に参加し以下セッションに参加してきました。
セッションを聴講していて、ふとECS managed Instance と Fargate ではどれくらいタスク起動に差があるのか疑問にもちました。ということで今回はmanaged Instances の起動済みインスタンス上のキャッシュを利用したタスク起動とFargate のタスク起動でどの程度差があるか検証していきたいと思います!
環境
| 項目 | 値 |
|---|---|
| リージョン | ap-northeast-1 |
| Terraform | v1.15.4 |
| AWS Provider | v6.53.0 |
| AWS CLI | v2.32.32 |
| Python / boto3 | 3.14 / 1.43.38 |
| コンテナイメージ | public.ecr.aws/docker/library/gradle:jdk21(約434MB) |
| タスクサイズ | 1 vCPU / 2GB メモリ |
| Managed Instances インスタンスタイプ | m7i.large(固定) |
結論
Managed Instances のイメージキャッシュが効いた状態では、タスクの総起動時間が Fargate の約3分の1になりました。
| 条件 | 総起動時間 中央値 (min–max) | pull 時間 中央値 | 試行回数 |
|---|---|---|---|
| Fargate | 32.1 秒 (28.3–34.9) | 15.7 秒 | 10 |
| Managed Instances(キャッシュあり) | 10.9 秒 (8.5–13.4) | 2.1 秒 | 10 |
| (参考)Managed Instances(初回・インスタンス起動込み) | 37.5 秒 | 9.0 秒 | 1 |
差の主因は pull 時間です。Fargate は毎回 11〜22 秒かけてイメージを pull するのに対し、キャッシュヒット時の Managed Instances は全10回とも約 2.1 秒で安定していました。
検証の設計
比較条件
公平な比較のため、ネットワーク条件を以下のとおり揃えました。
- 同一 VPC・同一 AZ の同一パブリックサブネットに 2 つのクラスターを配置(AZ 差を排除)
- イメージはパブリック ECR(public.ecr.aws)から取得。NAT Gateway や VPC エンドポイントは使わず条件を統一
- Fargate 側は
assignPublicIp=ENABLED(NAT なしでパブリック ECR から pull するために必要) - Managed Instances 側はサブネットの自動パブリック IP 付与でインスタンスに pull 経路を確保
計測区間
総時間だけでは「なぜ差が出たのか」を説明できないため、describe-tasks のタイムスタンプで内訳まで分解します。
| 指標 | 計算式 |
|---|---|
| 総起動時間 | RunTask API 発行時刻 → startedAt |
| プロビジョニング時間 | pullStartedAt − createdAt |
| イメージ pull 時間 | pullStoppedAt − pullStartedAt |
| コンテナ起動時間 | startedAt − pullStoppedAt |
キャッシュヒットの証拠は「pull 時間が数秒に縮む」ことで示せる、という設計です。
キャッシュの仕込み方
Managed Instances 上にイメージキャッシュを作るため、計測前にウォームアップとして同一タスクを 1 回実行 → 停止します。この初回実行の記録は「キャッシュなし + インスタンス起動込み」の参考値としてそのまま使えるので一石二鳥です。
注意点として、Managed Instances のインスタンスが入れ替わるとキャッシュは消えます。今回は 2 つの対策を入れました。
- キャパシティプロバイダーの
infrastructure_optimization.scale_in_after = -1でアイドルインスタンスの自動回収を無効化 - 計測スクリプトで各試行の
containerInstanceArnを記録し、全試行が同一インスタンス上で行われたことを確認
やってみた
Step 1: Terraform で環境構築
VPC、パブリックサブネット、2 つの ECS クラスター(Fargate 用 / Managed Instances 用)、タスク定義を作成します。ポイントとなる Managed Instances のキャパシティプロバイダーはこちらです。
resource "aws_ecs_capacity_provider" "mi" {
name = "${var.name_prefix}-mi-cp"
cluster = aws_ecs_cluster.mi.name
managed_instances_provider {
infrastructure_role_arn = aws_iam_role.ecs_infrastructure.arn
propagate_tags = "CAPACITY_PROVIDER"
# アイドルインスタンスの自動回収を無効化。
# 計測中にインスタンスが入れ替わるとイメージキャッシュが消えるため必須
infrastructure_optimization {
scale_in_after = -1
}
instance_launch_template {
ec2_instance_profile_arn = aws_iam_instance_profile.ecs_instance.arn
capacity_option_type = "ON_DEMAND"
network_configuration {
subnets = [aws_subnet.public.id]
security_groups = [aws_security_group.task.id]
}
storage_configuration {
storage_size_gib = 50
}
# インスタンスタイプ固定(タイプ差のノイズ排除)。m7i.large = 2 vCPU / 8 GiB
instance_requirements {
allowed_instance_types = [var.mi_instance_type]
vcpu_count {
min = 2
max = 2
}
memory_mib {
min = 8192
max = 8192
}
}
}
}
}
タスク定義は Fargate / Managed Instances で requires_compatibilities 以外を完全に同一にしています。
locals {
container_definitions = jsonencode([{
name = "app"
image = var.container_image
essential = true
command = ["sleep", "3600"]
}])
}
resource "aws_ecs_task_definition" "fargate" {
family = "${var.name_prefix}-fargate"
requires_compatibilities = ["FARGATE"]
network_mode = "awsvpc"
cpu = "1024"
memory = "2048"
container_definitions = local.container_definitions
}
resource "aws_ecs_task_definition" "mi" {
family = "${var.name_prefix}-mi"
requires_compatibilities = ["MANAGED_INSTANCES"]
network_mode = "awsvpc"
cpu = "1024"
memory = "2048"
container_definitions = local.container_definitions
}
※ IAM は 2 つ必要です。ECS がインスタンスを管理するためのインフラストラクチャロール(AmazonECSInfrastructureRolePolicyForManagedInstances)と、インスタンスプロファイルです。マネージドポリシーを使う場合、インスタンスロール名は ecsInstanceRole で始める必要があります(PassRole が role/ecsInstanceRole* にスコープされているため。違反すると RunTask 時に認可エラーになります)。
Step 2: 計測スクリプト
boto3 で RunTask → ポーリング → タイムスタンプ収集 → CSV 出力するスクリプトを用意しました。核となる計測部分はこちらです。
def measure_once(ecs, args, trial):
run_task_called_at = datetime.now(timezone.utc)
resp = ecs.run_task(**build_run_task_params(args))
if resp.get("failures"):
raise RuntimeError(f"RunTask failed: {resp['failures']}")
task_arn = resp["tasks"][0]["taskArn"]
try:
task = wait_for_task_status(
ecs, args.cluster, task_arn, "RUNNING", RUNNING_TIMEOUT_SEC
)
finally:
ecs.stop_task(cluster=args.cluster, task=task_arn, reason="measurement done")
row = {
"total_sec": diff_sec(task.get("startedAt"), run_task_called_at),
"provisioning_sec": diff_sec(task.get("pullStartedAt"), task.get("createdAt")),
"pull_sec": diff_sec(task.get("pullStoppedAt"), task.get("pullStartedAt")),
# MI でインスタンス入替(=キャッシュ消失)がないことの確認用
"container_instance_arn": task.get("containerInstanceArn", ""),
# ...
}
各条件とも逐次実行(並列だとスロットリングや容量競合がノイズになるため)、各タスクは RUNNING 確認後に停止しています。
Step 3: 計測実行
Fargate 10 回、Managed Instances 11 回(初回はウォームアップ兼キャッシュなし参考値)を実行します。
# Fargate: 10回
python3 measure.py --mode fargate --cluster cm-ta-fargate \
--task-definition <taskdef-arn> --subnet <subnet-id> --security-group <sg-id> \
--runs 10 --csv results_fargate.csv
# Managed Instances: 11回(1回目 = キャッシュなし参考値)
python3 measure.py --mode mi --cluster cm-ta-mi \
--task-definition <taskdef-arn> --capacity-provider cm-ta-mi-cp \
--subnet <subnet-id> --security-group <sg-id> \
--runs 11 --csv results_mi.csv
Step 4: 結果
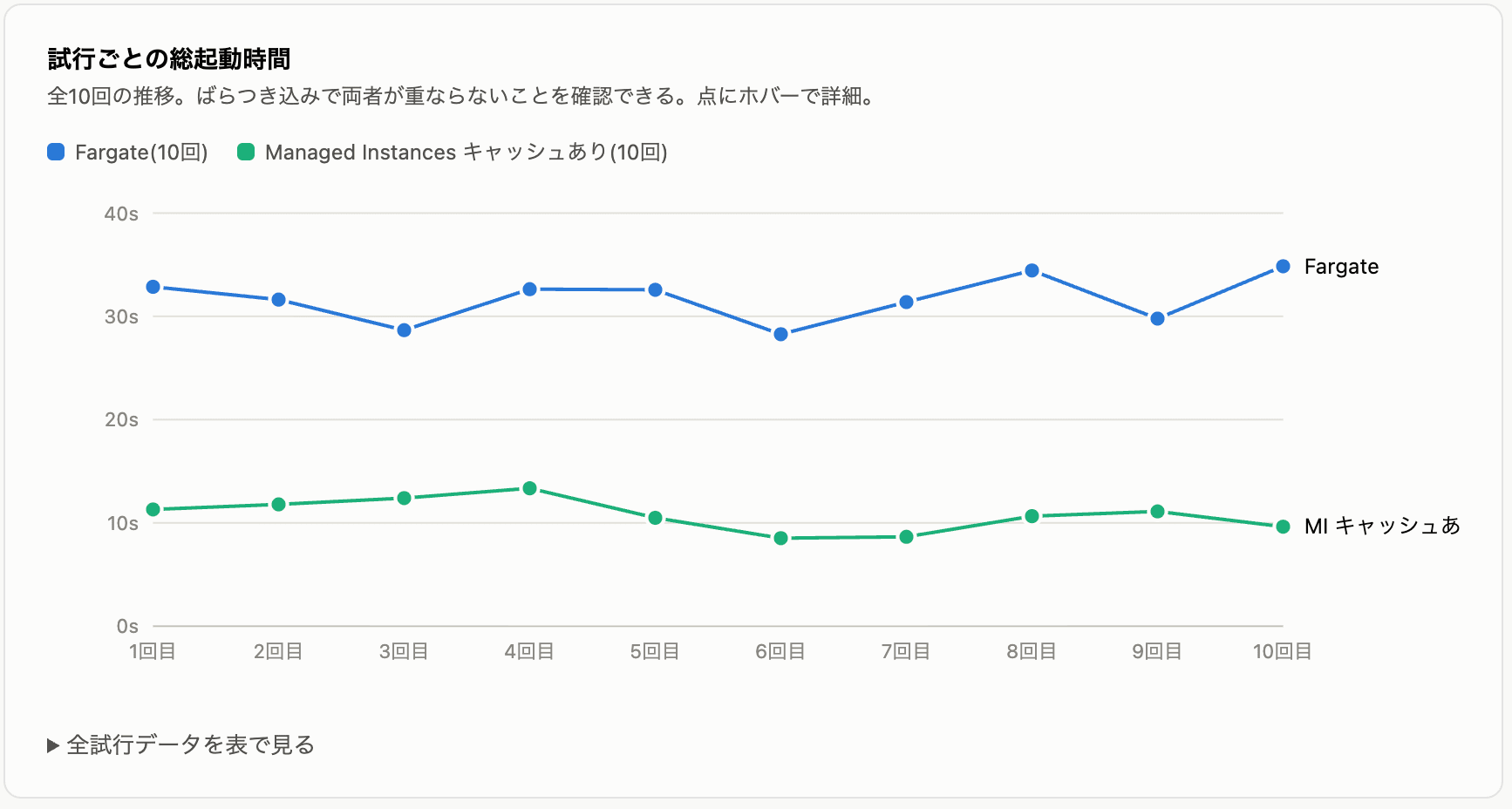
Fargate(10 回):
| 試行 | 総起動時間 | プロビジョニング | pull |
|---|---|---|---|
| 1 | 32.86 | 16.71 | 12.39 |
| 2 | 31.62 | 13.09 | 15.98 |
| 3 | 28.66 | 13.75 | 11.90 |
| 4 | 32.63 | 13.25 | 16.52 |
| 5 | 32.57 | 14.44 | 15.79 |
| 6 | 28.27 | 14.21 | 11.07 |
| 7 | 31.38 | 16.67 | 11.02 |
| 8 | 34.44 | 10.55 | 22.07 |
| 9 | 29.78 | 12.22 | 15.59 |
| 10 | 34.85 | 17.04 | 15.79 |
Managed Instances(初回 = キャッシュなし参考値、2〜11 回目 = キャッシュあり):
| 試行 | 総起動時間 | プロビジョニング | pull |
|---|---|---|---|
| 1(参考) | 37.52 | 22.79 | 9.03 |
| 2 | 11.30 | 9.07 | 2.07 |
| 3 | 11.79 | 9.71 | 2.08 |
| 4 | 12.40 | 10.13 | 2.07 |
| 5 | 13.35 | 11.28 | 2.08 |
| 6 | 10.49 | 8.13 | 2.07 |
| 7 | 8.52 | 6.39 | 2.03 |
| 8 | 8.65 | 6.79 | 2.07 |
| 9 | 10.65 | 8.93 | 2.08 |
| 10 | 11.11 | 9.13 | 2.04 |
| 11 | 9.63 | 7.51 | 2.07 |
(単位: 秒)
読み取れるポイントは 3 つです。
- キャッシュヒット時の pull は全 10 回とも約 2.1 秒で安定。Fargate の 11〜22 秒に対し圧倒的に短く、これが総起動時間の差の主因です
container_instance_arnは全 11 回同一で、キャッシュが維持されたまま計測できたことを確認しました- 興味深いのは初回(キャッシュなし)の Managed Instances でも pull が 9.0 秒と、Fargate の中央値 15.7 秒より速かった点です。m7i.large のネットワーク帯域が 1 vCPU の Fargate タスクより太いことが効いていると考えられます
注意点・制約
- Managed Instances では
describe-tasksのコンテナ単位のタイムスタンプ(containers[].startedAt等)が返されません。また、キャッシュヒット時にstartedAtがpullStoppedAtよりわずかに(1 秒未満)早い逆転が観測されました。検証したところ pull 系タイムスタンプの刻印が実イベントより約 1 秒遅れる挙動によるもので、開始・完了が同量ずれるため pull 所要時間や総起動時間の比較には影響ありません - キャッシュはインスタンスのライフサイクルに紐づきます。インスタンスが入れ替われば初回 pull が発生するため、「常にキャッシュが効く」前提の設計は禁物です。
infrastructure_optimization.scale_in_afterの調整でアイドルインスタンスの保持時間をコントロールできます - 本検証は特定イメージ(約434MB)・特定リージョン・特定時間帯の計測です。Fargate の起動時間はばらつきがあるため、絶対値ではなく傾向として参考にしてください
まとめ
- 同一条件の比較で、Managed Instances(キャッシュあり)のタスク起動は Fargate の約 3 分の 1(中央値 10.9 秒 vs 32.1 秒)でした
- 差の主因はイメージ pull 時間(2.1 秒 vs 15.7 秒)で、キャッシュの効果が数値で確認できました
- スパイクに素早く追従したいワークロードや、大きめのイメージを使うワークロードでは、Managed Instances のキャッシュは起動速度の面で明確なアドバンテージになりそうです
参考になれば幸いです。









