
はじめてのGraphDB Amazon Neptune
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
ちょうど触る機会があったのですが、「GraphDB ナニコレおもしろい!」となったのでブログにしました。
GraphDBの概念自体は直観的でとても分かりやすいです。
このブログの内容は15分程度で試せるので、是非やってみてください!
- 参考サイトURL
- TinkerPop Documentation Recipes
- GremlinDocs
- AWS Black Belt Online Seminar Amazon Neptune 資料及び QA 公開
- Work Backwards to Your Graph Data Model & Queries with Amazon Neptune (DAT330) - AWS re:Invent 2018
- Developers.IO 2019 in OSAKAで グラフ型データベース「Amazon Neptune」が丸裸にする クラスメソッド大阪オフィス を話しました #cmdevio
- Gremlin Cheat Sheet 101
GraphDBとは?
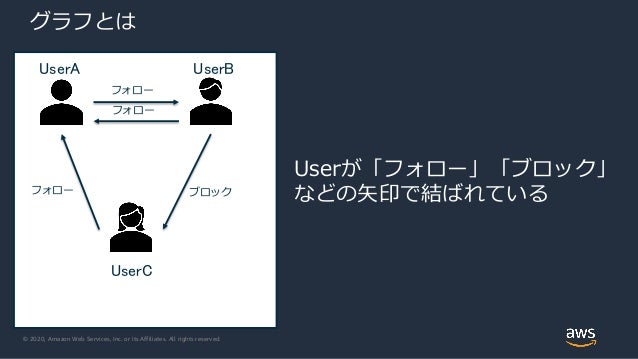
一言でいうと、データモデルとしてグラフ構造を採用しているデータベースのことです。
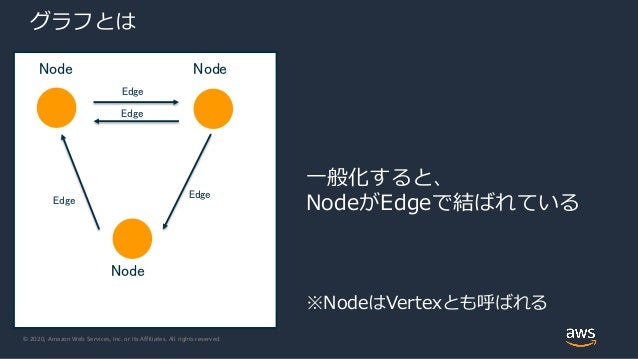
グラフ構造では、ノード(頂点)とエッジ(枝)の集合で構成されるグラフでデータが表現されます。
グラフ構造にも有向/無向グラフやプロパティグラフなどいくつか種類がありますが、ここでは触れません。
一般的に、ソーシャルネットワークのユーザー同士の関係性(フォロー、ブロック)など、多対多のリレーションをもつデータの保存先として有効です。
Amazon Neptuneとは?
Amazon NeptuneもGraphDBの一種です。
Neptune では、ノード (データエンティティ)、エッジ (リレーションシップ)、プロパティなどのグラフ構造を使用して、データを表現および保存します
Amazon Neptuneを利用する上で、下記の用語と意味を理解しておいてください。
- ノード
- 頂点(Vertex)とも言う
- エッジ
- 辺(Edge)とも言う
- ノードとノードを結ぶ線
- ラベル
- ノードやエッジの種類
- ラベル名は初回作成時に複数登録可能 (ただし、イミュータブルなので後から変えれない)
- ラベル名を指定して横断的にクエリを実行できるので便利
- プロパティ
- ノードやエッジに紐づけられる属性情報
- KeyValue形式
- 複数登録可能
とりあえずやってみる
こんな感じのユーザーの関係性を表現するデータベースを作成してみます。

セットアップ
CloudFormatinのデプロイ
公式ドキュメント AWS CloudFormation を使用して、または手動で新しい Neptune DB クラスターを作成するの下の方にCloudFormationのスタックを作成するボタンリンクがあるので、クリックしてデプロイしてください。
細かいやり方はドキュメントに記載してあるので省きます。
Neptuneへ接続
今回はSPARQLとGremlinのから選べるのですが、今回はGremlinを使います。
先ほど作成したEC2インスタンスへSSH接続し、Gremlinコンソールをインストールします。
インストール方法は、公式ドキュメント NeptuneDB インスタンスに接続するように Gremlin コンソールをセットアップするに記載してあるので、ここでの説明は省きます。
Gremlinでのデータ操作
Gremlin を使用したグラフへのアクセスを参考にいくつかクエリを発行していきます。
ちなみに、下記の英語を理解しておくと、ここから先で出てくるGremlinのクエリは読みやすいです。
- g: Graph(グラフ)
- V: Vertex(頂点)
- E: Edge(エッジ)
ユーザー登録
A,B,Cのノードを追加

gremlin> g.addV("person").property(id, "A").property("name", "alice").next() g.addV("person").property(id, "B").property("name", "bob").next() g.addV("person").property(id, "C").property("name", "charlie")
idを指定しない場合は、自動でUUIDが生成されます。
ユーザーのプロパティの変更
Cのプロパティnameを変更
gremlin> g.V("C").property(single, "name", "carol")
フレンド追加

AがBをフレンドに追加
gremlin> g.addE("friend").from(g.V("A")).to(g.V("B"))
本来はフレンド申請というフローがありますが今回は省きます。
また、「BからAへのエッジも必要じゃないの?」と思うかもしれませんが、双方向リレーションを結ぶことは、意味がないのであまり推奨されていないです。
単に方向性を無視すればよいですし、この後出てきますが、そのようなクエリの書き方もできます。
ブロック

AがCをブロック
gremlin> g.addE("block").from(g.V("A")).to(g.V("C"))
ブロックは方向性が必要なリレーションですね。
ユーザー一覧取得
gremlin> g.V().hasLabel('person')
==>v[A]
==>v[B]
==>v[C]
ユーザー一覧取得(ただし、ブロックされているユーザーの情報は返さない)
Cがユーザー一覧取得した場合、Aを表示したくない
gremlin> g.V().hasLabel("person").not(hasId("C")).not(outE("block").where(inV().hasId("C")))
==>v[B]
少しややこしいですが、自分がブロックしているユーザーに対して、自分の情報を表示しないようにシステムで制御したいという意図です。
まず、g.V().hasLabel("person").not(hasId("C"))の部分でC以外のユーザーのノードを取得する。
その後、.not(outE("block").where(inV().hasId("C")))で、blockエッジがCに対して向いているノード以外にフィルタしている。
フレンドであるユーザ一覧の取得
Aのフレンド一覧を取得
gremlin> g.V("A").both("friend")
==>v[B]
このbothが方向性を無視するような書き方
ブロックしているユーザー一覧の取得
Aがブロックしているユーザーの一覧を取得
gremlin> g.V("A").out("block")
==>v[C]
まとめ
いかがでしょうか。
データ同士の複雑な関係性を表現するのにとても便利ですね。
どなたかの役にたてば幸いです。








