
GA になった BigQuery の history-based optimizations で SQL が最適化されるか確認してみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、みかみです。
中腰前かがみで缶ビールを選んでいたら、「何かくれるのー?」とばかりに正面から突進してきた犬に、おなかに頭突きされました。
結構痛かったです。。
やりたいこと
- GA になった BigQuery の history-based optimizations で、実際に SQL が最適化されるのか試してみたい
前提
BigQuery の操作に必要な API の有効化と必要な権限は付与済みです。
また、文中、プロジェクトIDなど一部の文字は伏字に変更しています。
history-based optimizations を有効にする
現在のところ、history-based optimizations 機能を使用するには、プロジェクトまたは組織単位で有効化設定する必要があるそうです。
とはいえ、めんどくさい手順は必要なく、SQL 実行で簡単に設定できます。
以下のクエリで、検証するプロジェクトの history-based optimizations を ON に設定しました。
ALTER PROJECT `[PROJECT_ID]`
SET OPTIONS (
`region-us.default_query_optimizer_options` = 'adaptive=on'
);
ちゃんと ON になったか、以下のクエリで確認してみます。
SELECT
option_name,
option_value
FROM
`region-us.INFORMATION_SCHEMA.PROJECT_OPTIONS`
WHERE
option_name = 'default_query_optimizer_options';
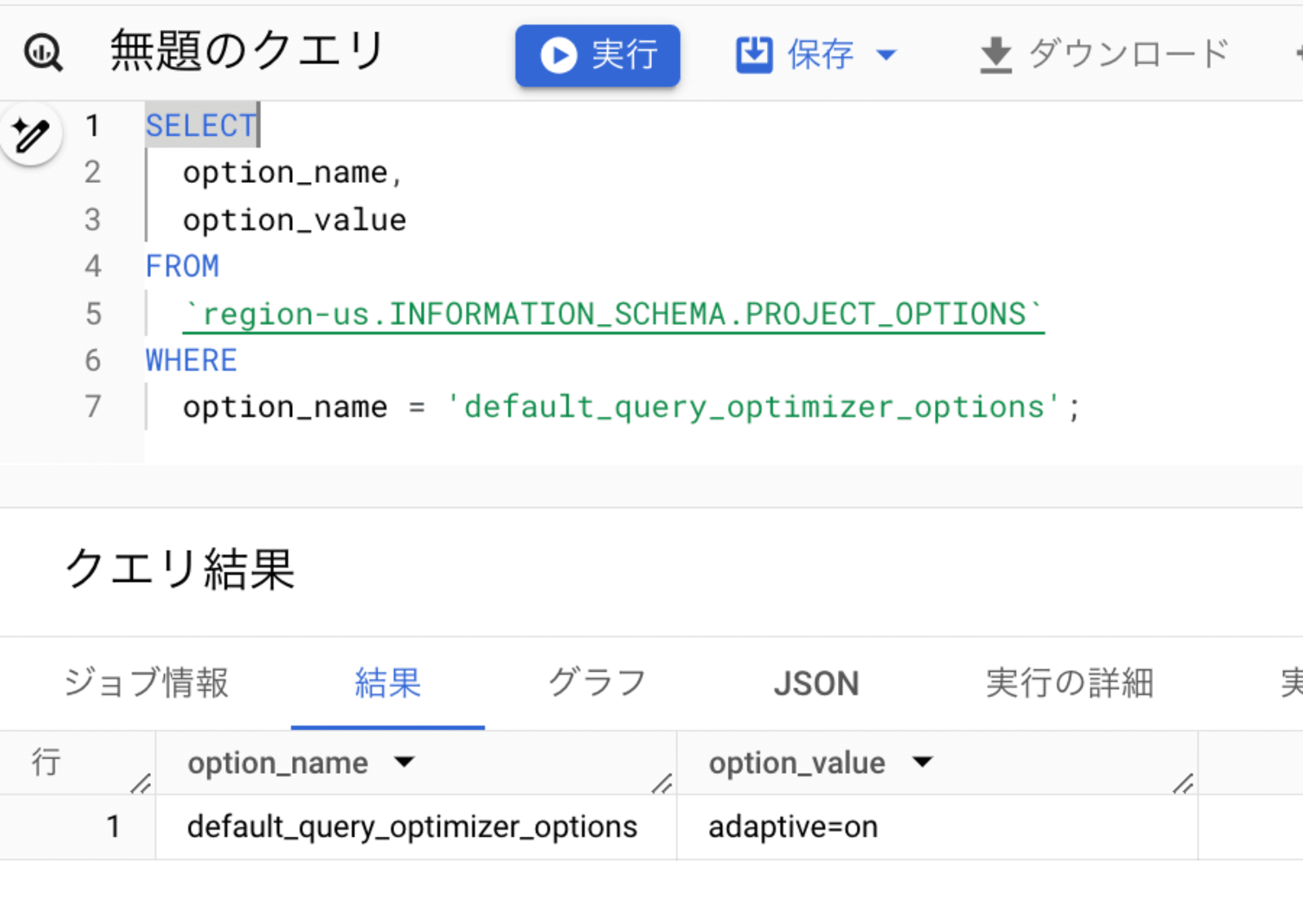
history-based optimizations を ON に設定できました。
問題のある SQL を実行
BigQuery のパブリックデータセットを使用した、以下の SQL を準備しました。
WITH check_name AS (
SELECT 'James' AS name
UNION ALL
SELECT 'William' AS name
UNION ALL
SELECT 'John' AS name
UNION ALL
SELECT 'Elizabeth' AS name
UNION ALL
SELECT 'Mary' AS name
)
SELECT
c.name,
c.year,
SUM(c.number) AS count
FROM
`bigquery-public-data.usa_names.usa_1910_current` c
INNER JOIN `bigquery-public-data.usa_names.usa_1910_2013` h ON c.name = h.name
INNER JOIN check_name AS n ON h.name = n.name
WHERE
c.state IN (
SELECT DISTINCT state
FROM `bigquery-public-data.geo_us_boundaries.states`
)
GROUP BY
c.name, c.year
ORDER BY
c.year, count
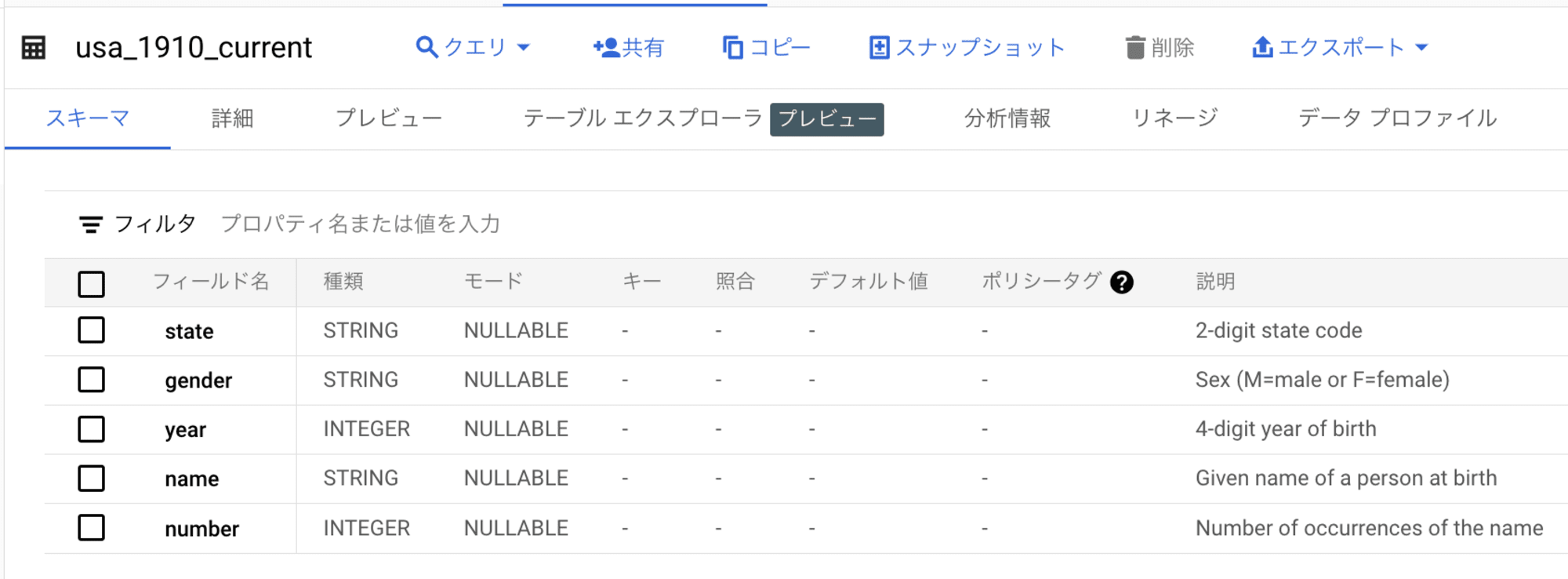
bigquery-public-data.usa_names.usa_1910_current と usa_1910_2013 テーブルは、アメリカの名前の情報を持つ BigQuery パブリックデータセットのテーブルです。
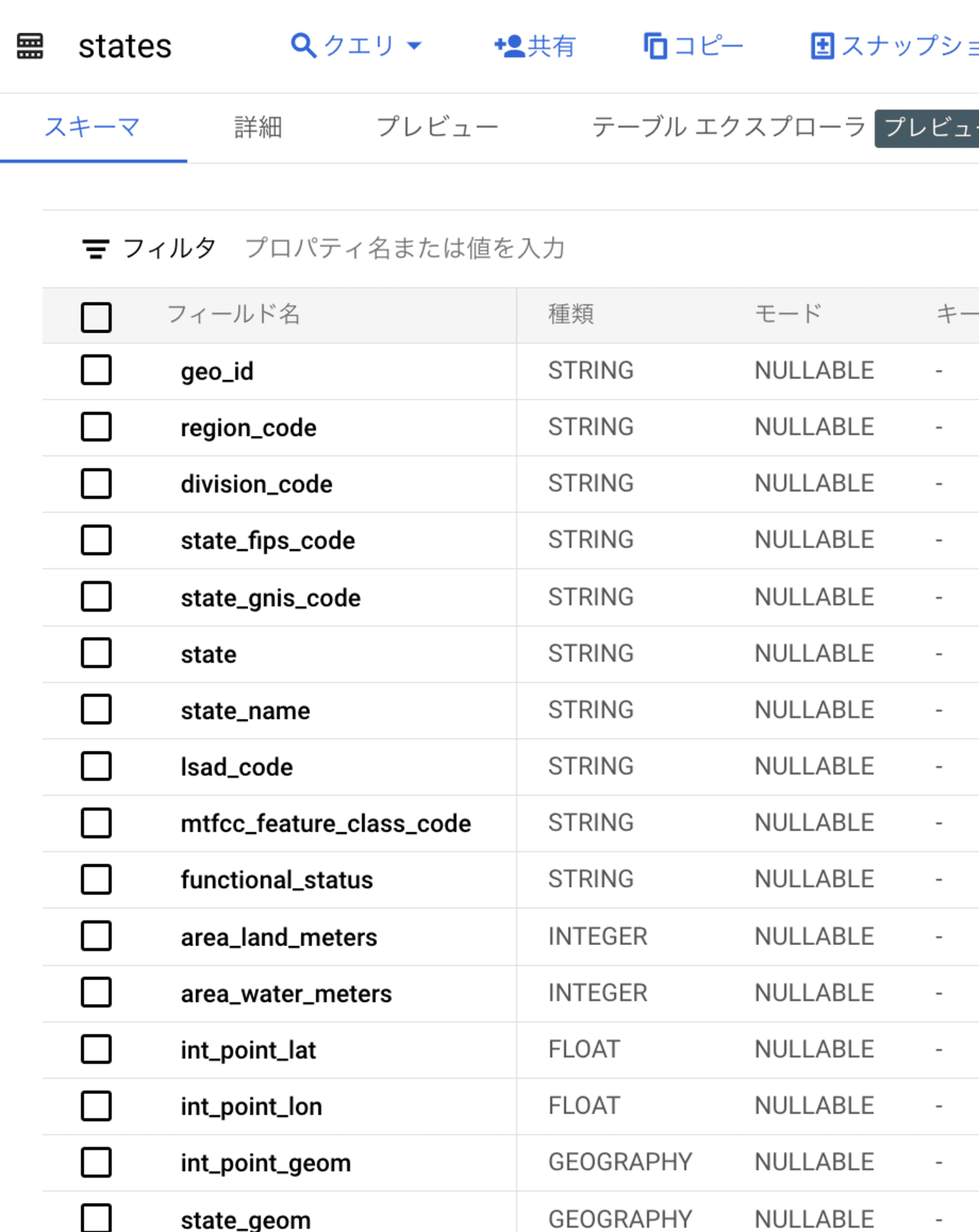
また、bigquery-public-data.geo_us_boundaries.states は、アメリカの地理の境界情報を持つテーブルです。
結合できそうなカラムを持つテーブルを使っただけで、クエリ結果に特に意味はありませんが、以下の点で改善の余地のある SQL です。
- サブクエリ使用:メインクエリの実行ごとにサブクエリが実行される可能性があり非効率
- IN 句の使用:サブクエリの全ての結果を評価するため、一つでも条件一致すれば評価を終了する EXISTS 句と比べて非効率
- JOIN の順番:データ量が多いテーブルから順番に結合しているため、データ量の削減が効率的に行われていない
2回目以降は、全てキャッシュ OFF で、BigQuery 管理コンソールから 10 回程度手動で SQL を実行しました。
最適化されたかどうか確認
以下の SQL を実行して、history-based optimizations が適用されたかどうか確認してみます。
SELECT
job_id,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', creation_time, 'Asia/Tokyo') AS creation_time,
query_info.optimization_details,
FROM
`region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
query like 'with check_name as (%'
AND error_result IS NULL
ORDER BY 2
以下の結果が帰ってきました。
+------------------------------+---------------------+---------------------------------------------------------------------------------------------------+
| job_id | creation_time | optimization_details |
+------------------------------+---------------------+---------------------------------------------------------------------------------------------------+
| bquxjob_4247dce4_19257c69a7b | 2024-10-04 22:44:46 | NULL |
| bquxjob_1875f5ee_19257c7422e | 2024-10-04 22:45:29 | {"optimizations":[{"parallelism_adjustment":"applied"}]} |
| bquxjob_3a28addf_19257c8021d | 2024-10-04 22:46:19 | {"optimizations":[{"parallelism_adjustment":"applied"}]} |
| bquxjob_e572705_19257c92874 | 2024-10-04 22:47:34 | {"optimizations":[{"parallelism_adjustment":"applied"}]} |
| bquxjob_30810f33_19257cbb07e | 2024-10-04 22:50:20 | {"optimizations":[{"parallelism_adjustment":"applied"}]} |
| bquxjob_1ef5b0e1_19257cc5e13 | 2024-10-04 22:51:04 | {"optimizations":[{"parallelism_adjustment":"applied"}]} |
| bquxjob_673bd4d6_19257d12640 | 2024-10-04 22:56:18 | {"optimizations":[{"join_pushdown":"bigquery-public-data.usa_names.usa_1910_2013.name.2,RIGHT"}]} |
| bquxjob_7c2fb990_19257d1bc7e | 2024-10-04 22:56:56 | {"optimizations":[{"join_pushdown":"bigquery-public-data.usa_names.usa_1910_2013.name.2,RIGHT"}]} |
| bquxjob_3eca2e5c_19257dd3dac | 2024-10-04 23:09:30 | {"optimizations":[{"join_pushdown":"bigquery-public-data.usa_names.usa_1910_2013.name.2,RIGHT"}]} |
+------------------------------+---------------------+---------------------------------------------------------------------------------------------------+
初回実行時は、履歴がないので最適化は行われませんが、約1分後に実行した同じクエリでは、すでに parallelism_adjustment の最適化が行われていました。
さらに何度も同じ SQL を実行すると、join_pushdown の最適化が行われるようになりました。
以下の SQL で、実行時間とスキャンデータ量も確認してみます。
SELECT
job_id,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', creation_time, 'Asia/Tokyo') AS creation_time,
TIMESTAMP_DIFF(end_time, creation_time, SECOND) AS execution_time_seconds,
total_bytes_processed / (1024 * 1024) AS total_mb_processed
FROM
`region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
query like 'with check_name as (%'
AND error_result IS NULL
ORDER BY 2
結果は以下でした。
+------------------------------+---------------------+------------------------+--------------------+
| job_id | creation_time | execution_time_seconds | total_mb_processed |
+------------------------------+---------------------+------------------------+--------------------+
| bquxjob_4247dce4_19257c69a7b | 2024-10-04 22:44:46 | 11 | 209.48947143554688 |
| bquxjob_1875f5ee_19257c7422e | 2024-10-04 22:45:29 | 19 | 209.48947143554688 |
| bquxjob_3a28addf_19257c8021d | 2024-10-04 22:46:19 | 18 | 209.48947143554688 |
| bquxjob_e572705_19257c92874 | 2024-10-04 22:47:34 | 16 | 209.48947143554688 |
| bquxjob_30810f33_19257cbb07e | 2024-10-04 22:50:20 | 23 | 209.48947143554688 |
| bquxjob_1ef5b0e1_19257cc5e13 | 2024-10-04 22:51:04 | 273 | 209.48947143554688 |
| bquxjob_673bd4d6_19257d12640 | 2024-10-04 22:56:18 | 26 | 209.48947143554688 |
| bquxjob_7c2fb990_19257d1bc7e | 2024-10-04 22:56:56 | 21 | 209.48947143554688 |
| bquxjob_3eca2e5c_19257dd3dac | 2024-10-04 23:09:30 | 15 | 209.48947143554688 |
+------------------------------+---------------------+------------------------+--------------------+
もともとそれほど時間がかかる SQL ではなく、エディタから単発で何度か SQL を実行した今回の検証ケースでは、処理時間の短縮は確認できませんでした。
なお、途中5分ほど時間がかかっているクエリは、その時間帯 Google Cloud アカウントの再認証が走った記憶があるので、最適化機能とは無関係と思われます。
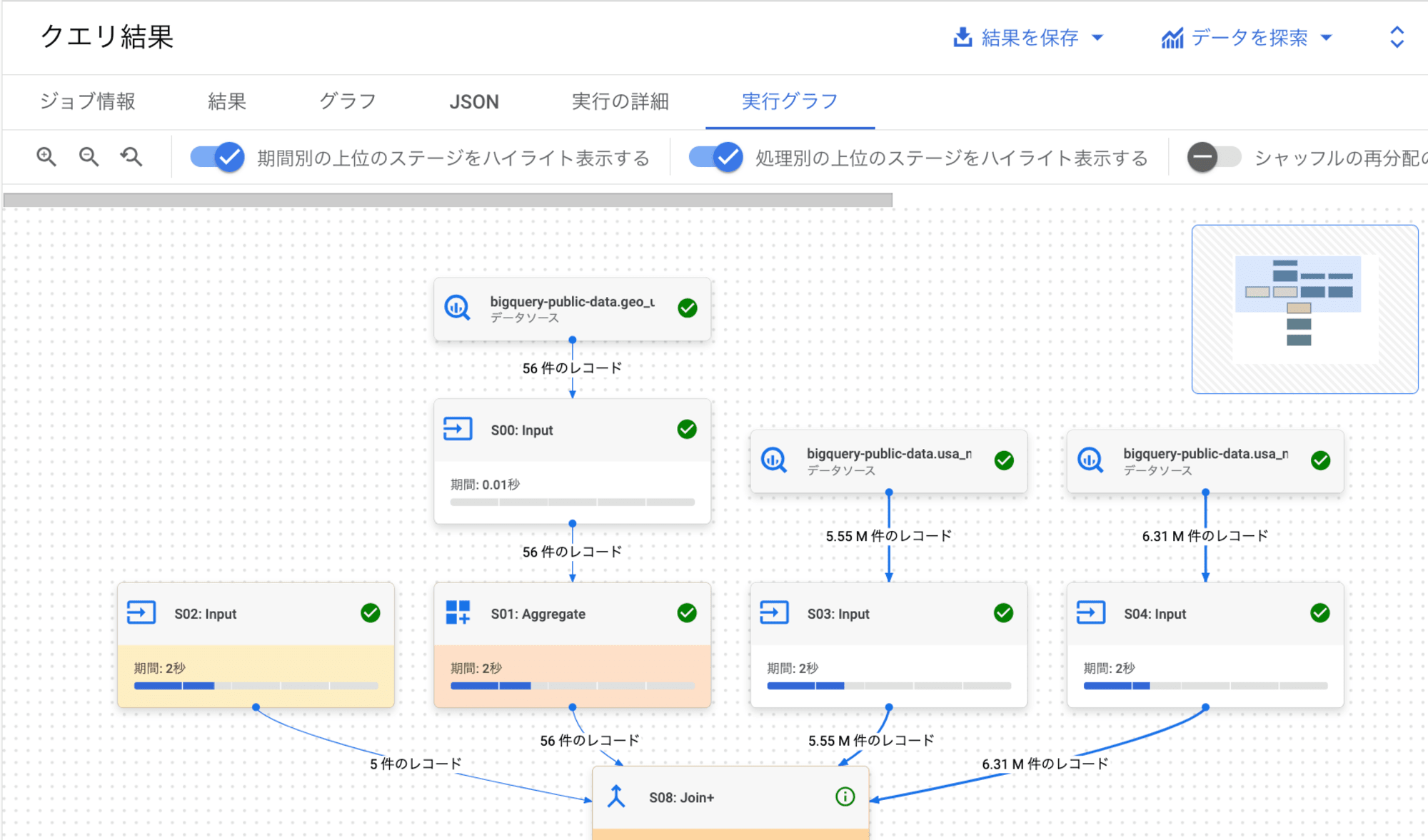
また、BigQuery 管理コンソールから、実行グラフも確認してみます。
- job_id:
bquxjob_4247dce4_19257c69a7b(最適化なし)
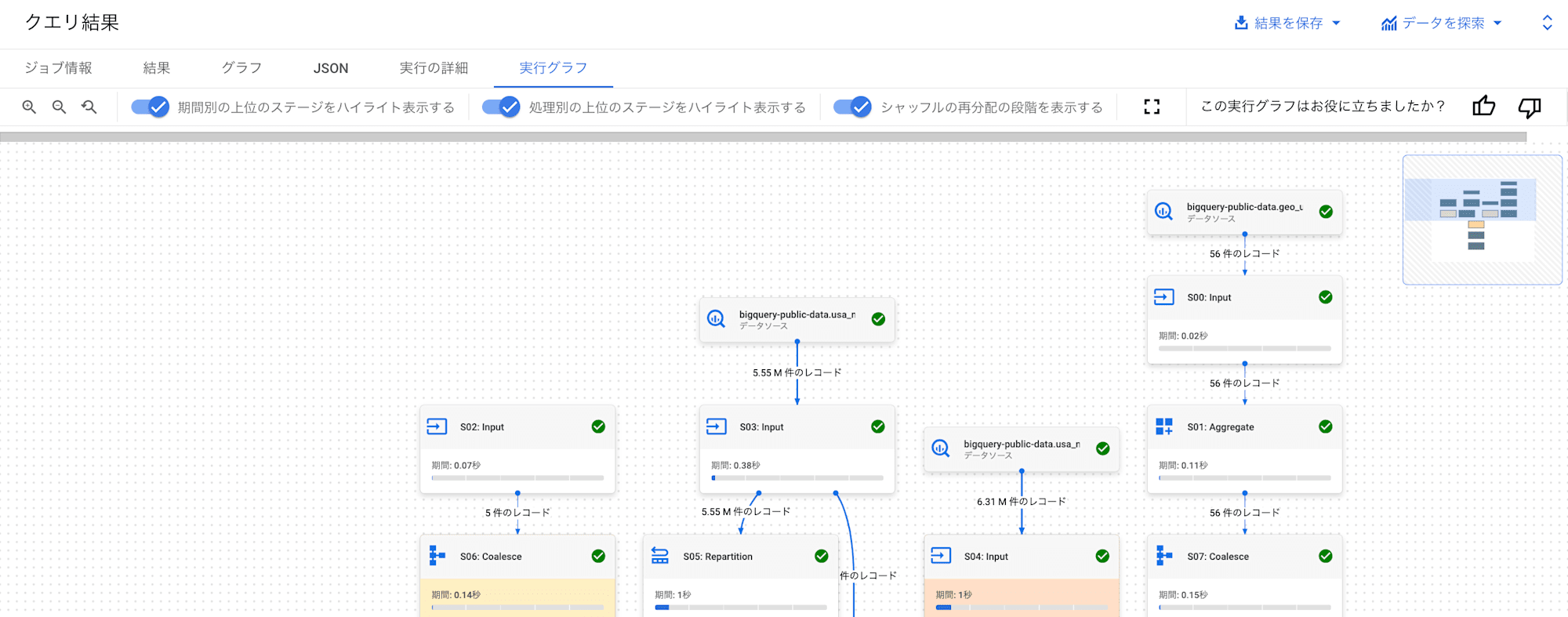
- job_id:
bquxjob_1875f5ee_19257c7422e(parallelism_adjustment)
- job_id:
bquxjob_673bd4d6_19257d12640(join_pushdown)
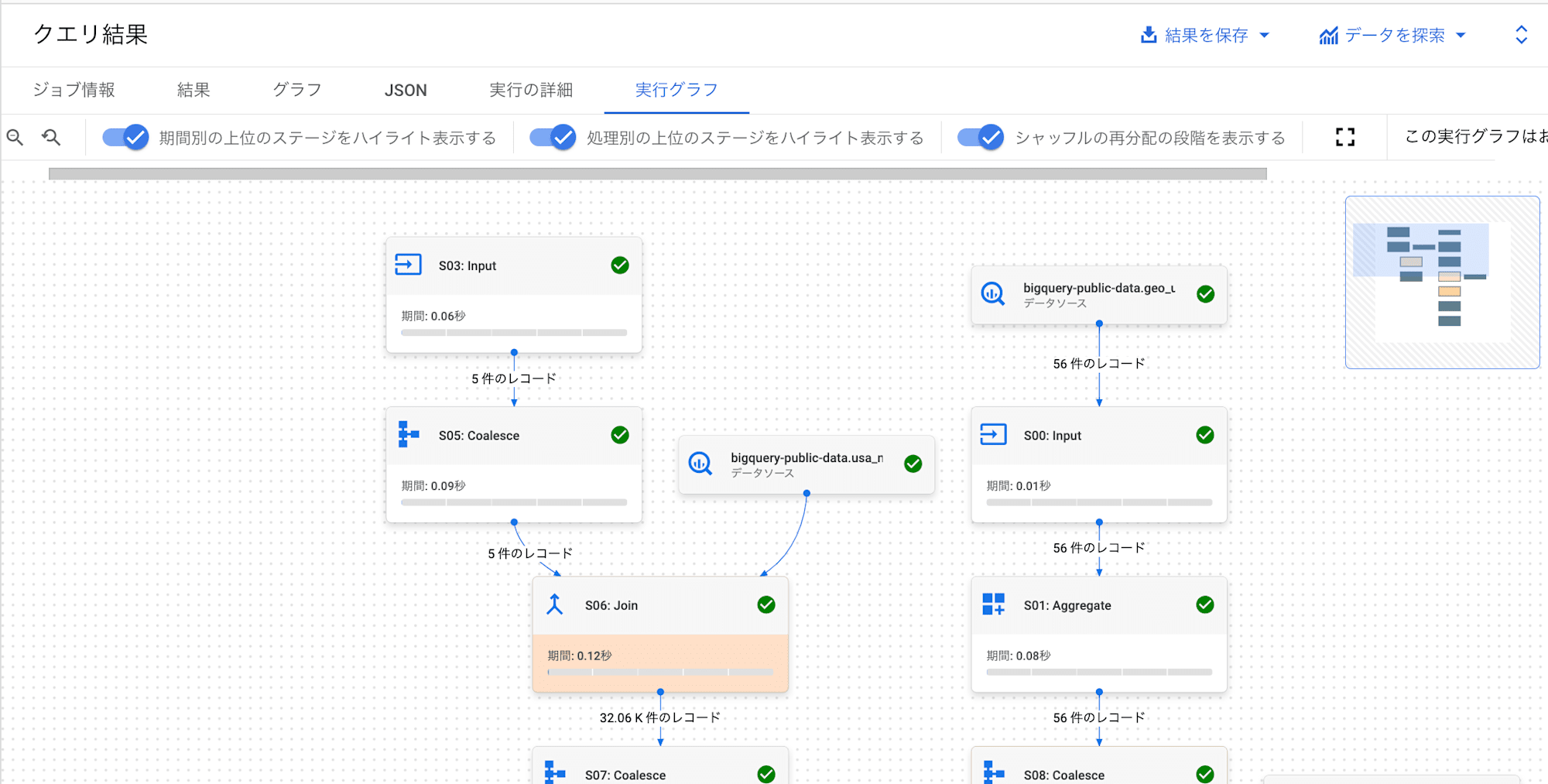
実行プランが変わっていることが確認できます。
「実行の詳細」タブも確認してみます。
- job_id:
bquxjob_4247dce4_19257c69a7b(最適化なし)

- job_id:
bquxjob_1875f5ee_19257c7422e(parallelism_adjustment)

- job_id:
bquxjob_673bd4d6_19257d12640(join_pushdown)

初回実行に比べて、history-based optimizations 適用後、最終的にはスロット時間 ≒ BigQuery の CPU 利用量が最適化されたことが確認できました。
まとめ(所感)
history-based optimizations 機能を ON にすることで、BigQuery のコンピューティングが最適化されることが確認できました。
並列で時間がかかる SQL を多数実行しているケースでは、この機能を ON にするだけで最適化が期待できるのではないかと思います。
特に追加料金がかかるわけでもなく、SQL 1本流すだけで簡単に設定できるので、試してみて損はないのではないでしょうか?
なお、管理コンソールクエリ履歴の「分析情報」からも、問題のある SQL が確認できます。
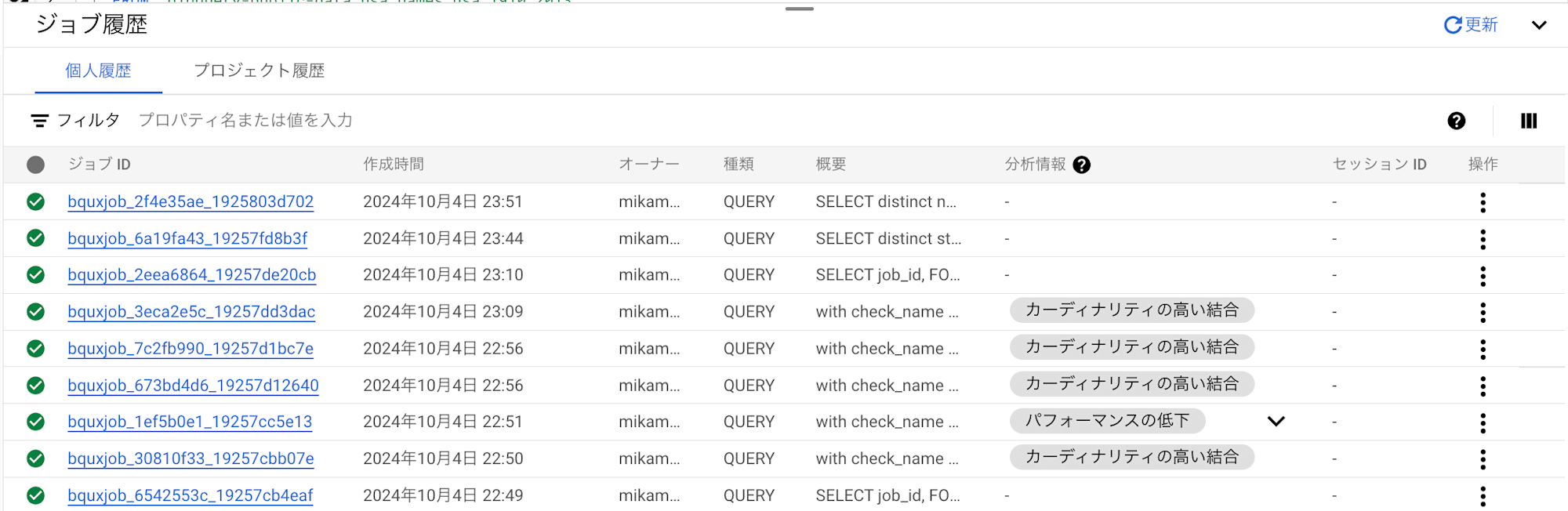
history-based optimizations 機能を ON にしたからといって、まだ SQL チューニングが不要になるわけではありませんが、
他の DWH と比べて、マネージドでチューニングの手間がかからない BigQuery ならではの特徴を後押しする、嬉しい機能だと思いました。
今後もっとマネージドな最適化機能がアップデートされて、SQL チューニングがいらなくなる時代が来たらうれしいなーと思いました!(夢










