
【アップデート】Gemini 3.5 Flashがリリースされました
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
2026年5月19日、Google I/O 2026 にて Gemini 3.5 Flash が発表されました。
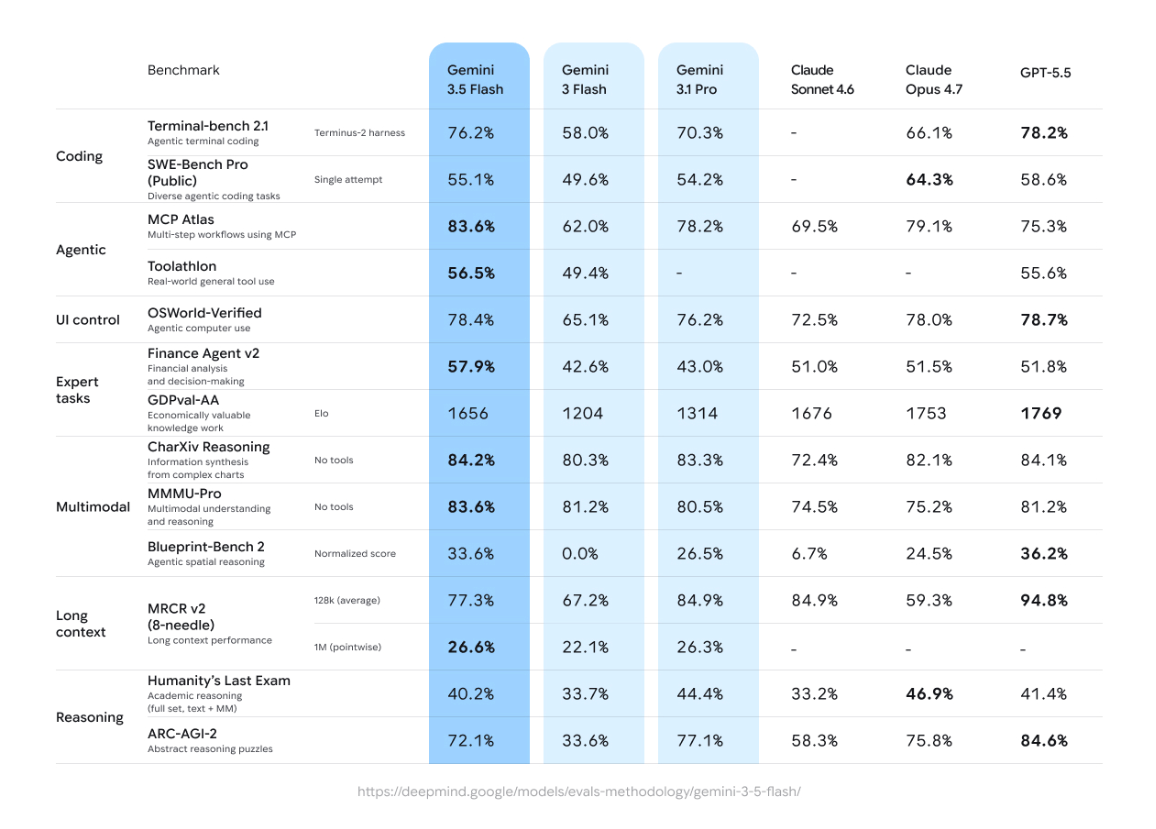
Gemini 3.5 Flash は、Flashシリーズに求められる「スピード・コスト効率」を維持しながら、フロンティアモデル級の推論性能を実現した最新モデルです。Gemini 3.1 Pro をほぼ全ベンチマークで上回りながらも、他のフロンティアモデル比で 4倍高速 という驚異的な性能を持ちます。
本記事では、Gemini 3.5 Flash の概要・特徴と、実際に Gemini Enterprise Agent Platform を使って試してみる手順をご紹介します。
Gemini 3.5 Flash とは
Gemini 3.5 Flash は、Google が Google I/O 2026 で発表した Flash シリーズの最新世代モデルです。Googleは今回のモデルを「フロンティアインテリジェンス with アクション(frontier intelligence with action)」と表現しており、エージェント型ワークフローへの対応を強く意識した設計になっているようです。
Flash シリーズの位置づけ
Gemini モデルファミリーにおける Flash シリーズは、コストと性能のバランスが取れたモデルです。Gemini 3.5 Flash はその最新版として、これまで Pro モデルにしか期待できなかった高度な推論・コーディング能力を Flash の速度・価格帯で提供します。
| モデル | 特徴 | 位置づけ |
|---|---|---|
| Gemini 3.1 Pro | 最高品質の推論・マルチモーダル理解 | フラッグシップ |
| Gemini 3.5 Flash | Pro 超えのコーディング・エージェント性能 + 4倍速 | 高コストパフォーマンス |
| Gemini 3.1 Flash-Lite | 超低コスト・低レイテンシ | スループット重視 |
主な新機能・特徴
1. Gemini 3.1 Pro を超えるコーディング・エージェント性能
Gemini 3.5 Flash は、複雑なエージェント型タスクやコーディングベンチマークで Gemini 3.1 Pro を上回ります。
2. Dynamic Thinking(思考機能)がデフォルト有効
Gemini 3.5 Flash は Gemini 3.x シリーズの思考機能(Thinking) を継承しており、Dynamic Thinking(MEDIUM レベル)がデフォルトで有効です。thinking_level パラメータで思考量を制御できます。
| thinking_level | 動作 | 向いているユースケース |
|---|---|---|
MINIMAL |
思考をほぼ無効化 | チャット・高スループット処理 |
LOW |
少量の思考 | 簡単な指示実行、低レイテンシ重視 |
MEDIUM |
バランス型 (デフォルト) | 一般的なタスク |
HIGH |
深い推論 | 複雑なコーディング・マルチステップ計画 |
3. 4倍の処理速度
他のフロンティアモデルと比較して、出力トークン毎秒が約4倍高速です。これにより、エージェント型ワークフローやリアルタイムアプリケーションでの実用性が大幅に向上しています。
4. マルチモーダル対応
| 項目 | 内容 |
|---|---|
| 入力モダリティ | テキスト、コード、画像、音声、動画、PDF |
| 出力モダリティ | テキスト |
| 最大入力トークン | 1,048,576(約100万トークン) |
| 最大出力トークン | 65,535(デフォルト) |
| ナレッジカットオフ | 2025年1月 |
5. 対応機能と非対応機能
Gemini Enterprise Agent Platform における対応状況は以下の通りです。
対応機能
| 機能 | 概要 |
|---|---|
| Google 検索グラウンディング | 最新情報を検索結果と組み合わせた回答生成 |
| コード実行 | モデルが生成したコードをサンドボックス上で実行 |
| システム指示 | モデルの動作をシステムプロンプトで制御 |
| 関数呼び出し | 外部ツール・API との連携 |
| 構造化出力 | JSON など特定フォーマットでの出力 |
| 思考モード(Thinking) | Dynamic Thinking による深い推論 |
| 暗黙的・明示的コンテキストキャッシュ | 入力トークンのキャッシュによるコスト削減 |
| チャット補完(Chat completions) | OpenAI 互換 API からの移行 |
非対応機能
- Gemini Live API(リアルタイム音声/映像)
- Content Credentials(C2PA)
6. 利用可能なプラットフォーム
Gemini 3.5 Flash は発表と同時に広く一般提供(GA)されており、以下のプラットフォームから利用できます。
- 一般ユーザー向け: Gemini アプリ、Google 検索の AI Mode
- 開発者向け: Google Antigravity、Gemini API(Google AI Studio)
- エンタープライズ向け: Gemini Enterprise Agent Platform
7. エンタープライズ向けセキュリティコントロール
Gemini Enterprise Agent Platform では、以下のセキュリティ機能がオンライン予測・コンテキストキャッシュですべて利用可能です。
バッチ予測・チューニングでは、AXT(アクセス透過性ログによる監査)のみ非対応です。
| セキュリティ機能 | 概要 |
|---|---|
| データ所在地(Data Residency) | データの保存・処理リージョンを指定 |
| CMEK | 顧客管理の暗号化キーによるデータ保護 |
| VPC Service Controls | VPC 境界によるデータ漏洩防止 |
| AXT | アクセス透過性ログによる監査 |
実際に試してみる
Gemini Enterprise Agent Platform を使って Gemini 3.5 Flash を呼び出してみます。
前提条件
- Google Cloud プロジェクトが作成済みであること
gcloudCLI がインストール・認証済みであること- Gemini Enterprise Agent Platform API が有効化済みであること
- Python 3.9 以上がインストール済みであること
STEP 1: 認証と SDK のインストール
# Application Default Credentials を設定
gcloud auth application-default login
# SDK のインストール
pip install google-genai
STEP 2: 基本的な呼び出し(デフォルト設定)
Dynamic Thinking(HIGH)がデフォルトで有効な状態で呼び出します。YOUR_PROJECT_ID をご自身のプロジェクト ID に置き換えてください。
import os
from google import genai
client = genai.Client(
vertexai=True,
project="YOUR_PROJECT_ID",
location="global",
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Pythonで非同期処理を使ったWebスクレイパーを実装してください。",
)
print(response.text)
実行結果
Pythonで非同期処理(非同期I/O)を使ったWebスクレイパーを実装する方法を解説します。
非同期処理を使用することで、複数のウェブページへのリクエストを同時に(非ブロッキングで)行うことができ、大量のページをスクレイピングする際の速度が劇的に向上します。
### 必要なライブラリのインストール
非同期HTTPクライアントである `aiohttp` と、HTML解析のための `BeautifulSoup4`(および高速な解析器 `lxml`)を使用します。
pip install aiohttp beautifulsoup4 lxml
---
### 実装サンプル
このコードは、スクレイピング練習用サイト(Books to Scrape)から、本のタイトルと価格を同時に(非同期で)取得するスクレイパーです。
import asyncio
import time
import aiohttp
from bs4 import BeautifulSoup
# 同時接続数を制限するためのセマフォ(ターゲットサーバーへの負荷を抑えるため)
MAX_CONCURRENT_REQUESTS = 5
semaphore = asyncio.Semaphore(MAX_CONCURRENT_REQUESTS)
async def fetch_and_parse(session, url):
"""個々のページをダウンロードして解析する非同期関数"""
async with semaphore: # 同時実行数を制限
try:
timeout = aiohttp.ClientTimeout(total=10)
print(f"[Start] Fetching: {url}")
async with session.get(url, timeout=timeout) as response:
if response.status != 200:
print(f"[Error] Status {response.status} for {url}")
return []
html = await response.text()
print(f"[Done] Fetched: {url}")
soup = BeautifulSoup(html, "lxml")
books = []
for article in soup.select("article.product_pod"):
title = article.h3.a["title"]
price = article.select_one(".price_color").text
books.append({"title": title, "price": price})
return books
except asyncio.TimeoutError:
print(f"[Timeout] {url}")
return []
except Exception as e:
print(f"[Exception] {url}: {e}")
return []
async def main():
base_url = "https://books.toscrape.com/catalogue/page-{}.html"
urls = [base_url.format(i) for i in range(1, 11)]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
async with aiohttp.ClientSession(headers=headers) as session:
tasks = [fetch_and_parse(session, url) for url in urls]
results = await asyncio.gather(*tasks)
all_books = []
for r in results:
all_books.extend(r)
print(f"\n--- 取得完了。合計 {len(all_books)} 冊の本が見つかりました ---")
for i, book in enumerate(all_books[:10], 1):
print(f"{i}: {book['title']} ({book['price']})")
if __name__ == "__main__":
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"\n実行時間: {end_time - start_time:.2f} 秒")
---
### コードのポイント解説
1. **`aiohttp` の使用**: 通常の `requests` ライブラリは「同期(ブロッキング)」処理であるため、
1つのリクエストが終わるまで次のリクエストを送れません。`aiohttp` を使うことで、
レスポンスを待つ間に次のリクエストを送信できます。
2. **`asyncio.Semaphore` による流量制限**: `MAX_CONCURRENT_REQUESTS = 5` で同時にリクエストを
送る数を制限しています。これがないと、100ページあれば100リクエストを一瞬で送信してしまい、
相手のサーバーをダウンさせたり、IPアドレスがブロックされたりします。実務でのスクレイピングでは必須の処理です。
3. **`asyncio.gather`**: 作成した複数の非同期タスクを並行して一斉に実行します。
4. **タイムアウトの設定 (`ClientTimeout`)**: 相手サーバーが応答しない場合にプログラムが
無限に待機するのを防ぐため、タイムアウト処理を明示的に入れています。
STEP 3: Thinking Level を指定した呼び出し
ユースケースに応じて thinking_level を明示的に指定できます。
from google import genai
from google.genai import types
client = genai.Client(
vertexai=True,
project="YOUR_PROJECT_ID",
location="global",
)
# 低レイテンシが必要な場合(チャットボット等)
response_low = client.models.generate_content(
model="gemini-3.5-flash",
contents="Cloud Run と Cloud Functions の使い分けを教えてください。",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level=types.ThinkingLevel.LOW
)
),
)
# 複雑な推論が必要な場合(コード生成・計画立案等)
response_high = client.models.generate_content(
model="gemini-3.5-flash",
contents="マイクロサービスアーキテクチャの設計における分散トランザクション管理のベストプラクティスを説明してください。",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level=types.ThinkingLevel.HIGH
)
),
)
print("LOW thinking:", response_low.text[:200])
print("HIGH thinking:", response_high.text[:200])
実行結果
=== LOW thinking ===
Google Cloud(GCP)における **Cloud Run** と **Cloud Functions** は、どちらもサーバー管理が不要な
「サーバーレス(Serverless)」サービスですが、その設計思想や最適なユースケースには明確な違いがあります。
一言で言うと、**「コンテナを動かすなら Cloud Run」、「コード(関数)を動かすなら Cloud Functions」**です。
### 1. 2つのサービスの特徴
#### ■ Cloud Run とは?(コンテナベース)
Dockerなどの**コンテナイメージ**をそのままデプロイして実行するサービスです。
- **特徴:** WebアプリケーションやWeb APIの構築に最適。
- **メリット:** 言語やライブラリの制限が一切ない。1インスタンスで複数のリクエストを同時に処理できる(高効率・低コスト)。
#### ■ Cloud Functions とは?(イベント駆動型・FaaS)
特定のイベント(ファイルのアップロード、データベースの更新、Webhookなど)をトリガーにして、
**特定の関数(コード)を実行する**サービスです。
- **特徴:** 小さな単一機能の処理(マイクロサービス、バッチ処理)に最適。
- **メリット:** コンテナを作成・管理する必要がなく、ソースコードを書くだけで即座に動かせる。
### 2. 比較表
| 項目 | Cloud Run | Cloud Functions (第2世代) |
| :--- | :--- | :--- |
| **デプロイ単位** | コンテナイメージ (Docker) | ソースコード (Zip、またはGit) |
| **対応言語** | 制限なし | サポートされた言語のみ (Node, Python, Go, Java等) |
| **主な用途** | Webアプリ、Web API、マイクロサービス | イベント連携、軽量バッチ、Webhook |
| **並行処理数** | 1インスタンスあたり最大250リクエスト | 1インスタンスあたり最大1,000リクエスト(設定による) |
| **最大実行時間** | 60分 | 60分 (HTTPイベントの場合) |
### 3. どちらを選ぶべきかの判断基準
#### Cloud Run を選ぶべきケース
1. WebアプリケーションやWeb API(REST/GraphQL)を作りたい場合
2. 言語、ランタイム、システムライブラリにこだわりがある場合
3. アクセス数が多く、コストを抑えたい場合
#### Cloud Functions を選ぶべきケース
1. GCP内のイベント(トリガー)に連動させたい場合
- 「Cloud Storageに画像がアップロードされたら、自動でサムネイルを作成する」
- 「Firestoreのデータが更新されたら、管理者に通知メールを送る」
2. サクッと動く簡単なスクリプトやWebhookを作りたい場合
### まとめ
- **迷ったら:** まず **Cloud Run** を検討してください。特にWebサイトやAPIサーバーを作るならCloud Run一択です。
- **特定イベントの処理:** GCPの他サービスのイベントをトリガーに動かす「接着剤」のような処理を作るなら **Cloud Functions** が最適です。
=== HIGH thinking ===
マイクロサービスアーキテクチャにおける分散トランザクション管理は、システム設計において最も複雑で
困難な課題の一つです。モノリス(単一)アプリのように単一のデータベースでACID特性を保証することが
できないため、アプローチを根本から変える必要があります。
### 1. 設計思想の転換:ACID から BASE(結果整合性)へ
マイクロサービスでは、強力な一貫性(ACID)を諦め、**結果整合性(Eventual Consistency)**を受け入れる
「**BASE**(Basically Available, Soft state, Eventual consistency)」思想にシフトすることが基本です。
### 2. 主要なデザインパターン
#### パターンA:Saga パターン(強く推奨)
Sagaは、分散トランザクションを「ローカル(各サービス内)トランザクションの連鎖」として扱うパターンです。
処理が失敗した場合、**「補償トランザクション(Compensating Transaction)」**を逆順に実行してロールバックします。
- **コレオグラフィ(振付型):** 中央集権的なコントローラーを置かず、各サービスがイベントをpub/subして自律的に連携。
- **オーケストレーション(管弦楽型):** 「オーケストレーター」が中央でワークフローをコントロール。
#### パターンB:Transactional Outbox パターン
DBの更新とメッセージブローカーへのイベント送信をアトミックに行うパターンです。
同一のローカルDBトランザクション内でビジネスデータとOutboxテーブルへの挿入を同時に行い、
別プロセスの「Message Relayer」がOutboxテーブルを監視してメッセージブローカーに非同期で送信します。
### 3. 実装における極めて重要なベストプラクティス
- **冪等性(Idempotency)の確保:** 同じメッセージが複数回届くことを前提に設計。一意の「冪等キー」を付与してDBでチェックしてから処理を行う。
- **2相コミット(2PC)の回避:** すべてのノードがロックを保持するため、パフォーマンスが劇的に低下しアンチパターン。
- **補償トランザクションの設計:** 単純な削除ではなく、ビジネスルールに則った「逆アクション」として設計する。
### 4. 運用・監視のベストプラクティス
- **相関ID(Trace ID)の導入:** すべてのサービス呼び出し、イベント、ログにIDを伝播させる(Jaeger、Zipkinなどの分散トレーシングツールを活用)。
- **デッドレターキュー(DLQ)の活用:** 処理できない異常なメッセージを退避させ、アラートを上げて管理者が手動リカバリーできるようにする。
### まとめ:選択の指針
1. 原則として、サービスを跨ぐトランザクションが不要な設計にする(最優先)。
2. どうしても跨ぐ場合は「Saga + Outbox」パターンを採用する。
3. すべてにおいて「冪等性」と「監視性(相関ID)」を徹底する。
STEP 4: トークン使用量の確認
思考トークンは出力トークンとして課金されます。使用量を確認してコストを把握しましょう。
from google import genai
client = genai.Client(
vertexai=True,
project="YOUR_PROJECT_ID",
location="global",
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="フィボナッチ数列の実装方法を3つ教えてください。",
)
print(f"入力トークン: {response.usage_metadata.prompt_token_count}")
print(f"出力トークン(思考除く): {response.usage_metadata.candidates_token_count}")
print(f"思考トークン: {response.usage_metadata.thoughts_token_count}")
print(f"合計トークン: {response.usage_metadata.total_token_count}")
実行結果
フィボナッチ数列を実装する代表的な3つの方法を、Pythonのコード例とともに紹介します。
それぞれ**「処理速度」「メモリ効率」「コードの分かりやすさ」**に特徴があります。
---
### 1. ループ(反復)処理による実装
**最も実用的で推奨される方法です。**
def fibonacci_loop(n):
if n < 0:
raise ValueError("nは0以上の整数を指定してください。")
if n == 0:
return 0
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
print(fibonacci_loop(10)) # 出力: 55
- **メリット:** 非常に高速で、メモリの消費も最小限(変数2つ分のみ)です。
- **計算量:** 時間計算量 O(n) / 空間計算量 O(1)
---
### 2. 再帰+メモ化による実装
from functools import lru_cache
@lru_cache(maxsize=None)
def fibonacci_memo(n):
if n < 0:
raise ValueError("nは0以上の整数を指定してください。")
if n == 0:
return 0
if n == 1:
return 1
return fibonacci_memo(n - 1) + fibonacci_memo(n - 2)
print(fibonacci_memo(10)) # 出力: 55
- **メリット:** 数学的な定義に近く、コードが非常にシンプルで直感的です。
- **デメリット:** 再帰の回数が多すぎると `RecursionError` が発生します(Pythonのデフォルトではn=1000付近で限界)。
- **計算量:** 時間計算量 O(n) / 空間計算量 O(n)
---
### 3. ジェネレータによる実装(ストリーム生成)
def fibonacci_generator():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
gen = fibonacci_generator()
for _ in range(10):
print(next(gen), end=" ")
# 出力: 0 1 1 2 3 5 8 13 21 34
- **メリット:** メモリ効率が極めて高い。無限に続く数列を扱う場合でもメモリをほぼ消費しません。
- **デメリット:** 特定の第n項だけをピンポイントで求める用途には不向き。
- **計算量:** 次の値を出すごとの時間計算量 O(1) / 空間計算量 O(1)
---
### まとめ
| 実装方法 | おすすめの用途 | 長所 | 短所 |
| :--- | :--- | :--- | :--- |
| **1. ループ** | 一般的な利用(最もおすすめ) | 高速、省メモリ、制限なし | コードがやや機械的 |
| **2. メモ化再帰** | アルゴリズムの学習など | 数学的定義に近く美しいコード | メモリを消費し、大きいnでエラー |
| **3. ジェネレータ** | 順番に要素を処理したい時 | 無限数列をメモリほぼゼロで扱える | 特定の第n項だけを求めるのは遅い |
--- トークン使用量 ---
入力トークン: 14
出力トークン(思考除く): 1166
思考トークン: 1613
合計トークン: 2793
料金の目安
最新の料金は公式料金ページを参照してください。
| 区分 | 料金(Standard tier) |
|---|---|
| 入力トークン | $1.50 / 1M トークン |
| 出力トークン(思考トークン含む) | $9.00 / 1M トークン |
| キャッシュ済み入力トークン | $0.15 / 1M トークン |
まとめ
Gemini 3.5 Flash は、Flash シリーズで初めて Pro モデルを超えるコーディング・エージェント性能を実現した画期的なモデルです。Gemini 3.1 Pro を超える推論・コーディング性能を備えながら、従来 Pro モデルが必要だったエージェント型ワークフローを Flash の価格帯で実現できる点は特筆に値します。また、Dynamic Thinking のデフォルト有効化と thinking_level による細かな制御によって、レイテンシ・コスト・品質のトレードオフをユースケースに合わせて柔軟にチューニングできます。さらに他のフロンティアモデル比4倍の処理速度は、リアルタイム性が求められる AI エージェントやチャットアプリケーションへの組み込みを現実的なものにしています。
エージェント型アプリケーションや高度なコーディング支援を Google Cloud 上で構築しようとしている開発者・エンタープライズの方は、ぜひ Gemini 3.5 Flash への移行を検討してみてはいかがでしょうか。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!










