
Gemini Enterprise のカスタムコネクタで Backlog Wiki をデータソースにする
はじめに
クラスメソッド Google Cloud Advent Calendar 2025 - Adventar 22日目の記事です!
もうすぐクリスマスとなりアドベントカレンダーも佳境を迎えております。最後まで見届けていただけましたら幸いです。
本記事では Gemini Enteprise でカスタムコネクタを作成し、標準コネクタライブラリに含まれない外部データソースを取り込む方法を試してみます。
検証の目的
Gemini Enterprise では Gmail や Google ドライブといった Google サービス、BigQuery や Cloud Storage といった Google Cloud サービス、Microsoft サービスや Confluence といった 3rd Party サービスをデータソースとすることができます。
これらのデータソースとの接続は標準のコネクタにより容易に実装することができますが、標準で用意されていない外部データソースについても カスタムコネクタ の作成により連携することができます。
本ブログでは、外部のデータソースを取得して Gemini Enterprise から検索できるようにするまでの手順や仕組みを確認する目的 で検証をしていきます。
先日公開した以下ブログと同様に、外部のデータソースとして Backlog を利用することにしました。
Backlog の Wiki の情報を取得し、Gemini Enterprise で検索結果を回答できるようにします。
コネクタは、指定したデータソースから直接情報を取得する「データ連携」と、データを Vertex AI Search インデックスにコピーして検索品質を向上させる「データ取り込み」をサポートします。今回は 「データ取り込み」 で実装してみます。
「コネクタ」や「データソース」の用語定義や仕様については以下をご参照ください。
なお、実際の運用ではユーザーがアクセス可能な権限の範囲内でデータを検索できるようにする実装が重要となります。これらはデータソースに対して ACL を実装することで実現できます。
しかし、本ブログでは ACL の実装はせず、カスタムコネクタで外部データソースを連携させる動作や仕組みにフォーカスして確認していきます。 ACL の実装については別の機会でお伝えする予定です。
検証手順概要
以下の手順で検証していきます。
- Backlog API を利用し Wiki のデータを取得
- 取得したデータをデータストアで取り扱う構造化データに変換
- Google Cloud にデータストアを作成
- データストアにドキュメントをアップロード
- Gemini Enterprise にデータストアを接続
手順は以下を参考にしています。
Backlog の Wiki の情報は構造化データとして扱います。「4. データストアにドキュメントをアップロード」の手順でこの構造化データをアップロードします。アップロード方法として Cloud Storage、BigQuery からのインポートに加え、API を利用したローカル JSON データの直接アップロードをサポートしています。
アップロード対象のデータ数が少ないことと、構造化データを準備する流れを確認したかったことから、今回はローカル JSON データを直接アップロードする手順で検証しました。
カスタムコネクタの作成は Gemini Enterprise API のクライアントライブラリを利用します。本検証では公式ドキュメントと同様に Python ライブラリを利用して確認していきます。それぞれの手順での実行結果や仕組みがわかるよう Google Colab を利用して関数を手順に沿って一つずつ実行していくこととします。
やってみた
0. 環境準備
Backlog API キー準備
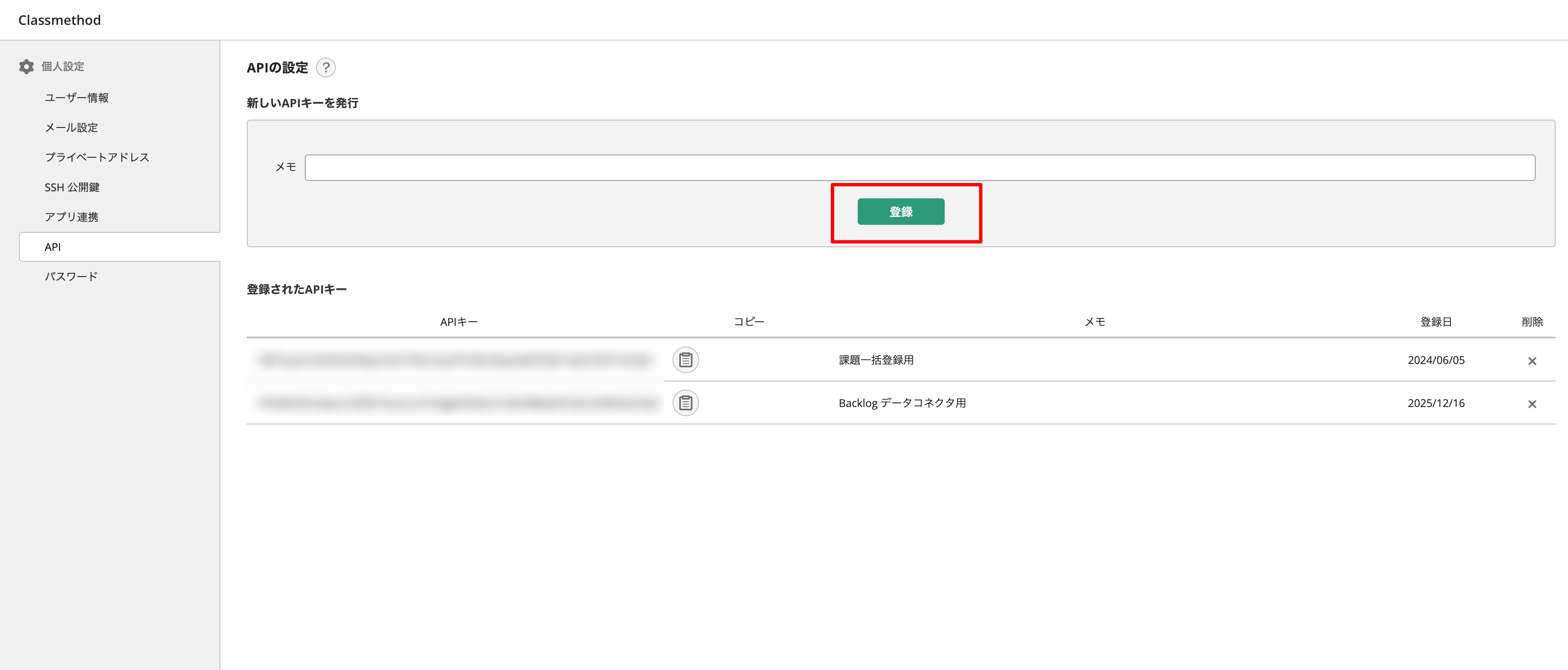
Backlog API を利用して Wiki データを取得するために API キーを取得します。
Backlog の [個人設定] -> [API] -> [登録] から発行できます。
Google Cloud プロジェクト準備
Gemini Enteprise を有効化した Google Cloud プロジェクトを準備します。
なお、本検証ではオーナーロールを使用して Google Cloud 上の作業をしていきます。
Google Colab 認証/環境準備
前述したように本検証では Google Colab で一つずつ動作を確認していきます。Google Colab 認証設定と環境準備を行います。
ADC(アプリケーションのデフォルト認証情報) を利用したユーザー認証により、ライブラリからの API 操作をユーザー権限で認可します。
!gcloud auth application-default login
!gcloud auth application-default set-quota-project <PROJECT_ID>
Backlog の情報を環境変数に入力します。
BACKLOG_SPACE = "<SPACE_ID>.backlog.jp"
API_KEY = "<API_KEY>"
PROJECT_KEY = "7NM_SECURITY"
BASE_URL = f"https://{BACKLOG_SPACE}/api/v2"
1. Backlog API を利用し Wiki のデータを取得
Backlog API を利用して対象 Backlog プロジェクトの Wiki ID を取得、Wiki ID をキーに全ての Wiki データを取得していきます。詳細は以下を参照しています。
Wikiページ一覧の取得 | Backlog Developer API | Nulab
Wikiページ情報の取得 | Backlog Developer API | Nulab
Wiki データ取得用の関数を定義します。
import requests
import json
from typing import List
def fetch_wiki_ids(base_url: str, api_key: str, project_key: str) -> List[int]:
"""Fetch all wiki IDs from the given project."""
url = f"{base_url}/wikis"
params = {
"apiKey": api_key,
"projectIdOrKey": project_key
}
resp = requests.get(url, params=params)
resp.raise_for_status()
wiki_list = resp.json()
wiki_ids = [wiki["id"] for wiki in wiki_list]
return wiki_ids
def fetch_wiki_detail(base_url: str, api_key: str, wiki_id: int) -> dict:
"""Fetch wiki detail by wiki ID."""
url = f"{base_url}/wikis/{wiki_id}"
params = {"apiKey": api_key}
resp = requests.get(url, params=params)
resp.raise_for_status()
return resp.json()
def fetch_wikis(base_url: str, api_key: str, project_key: str) -> List[dict]:
"""Fetch all wikis with details from the given project."""
wiki_ids = fetch_wiki_ids(base_url, api_key, project_key)
print(f"Found {len(wiki_ids)} wikis: {wiki_ids}")
wikis: List[dict] = []
for wiki_id in wiki_ids:
print(f"Fetching wiki {wiki_id}...")
wiki = fetch_wiki_detail(base_url, api_key, wiki_id)
wikis.append(wiki)
return wikis
Backlog Wiki を取得し wikis に格納します。
wikis = fetch_wikis(BASE_URL, API_KEY, PROJECT_KEY)
print(f"\nFetched {len(wikis)} wikis successfully.")
Wiki データの内容をピックアップして確認してみます。
print(json.dumps(wikis[0], ensure_ascii=False, indent=2))
以下のようなデータが格納されています。(抜粋)
{
"id": 1075345751,
"projectId": <PROJECT_ID>,
"name": "Home",
"content": "# Backlog利用ルール\r\n\r\n## Wiki 管理\r\n\r\nWiki はプロジェクトごとに Top ページを作成してその配下に関連ページをまとめる\r\nTop ページは「yyyy_プロジェクト名」とする\r\n\r\n## 課題管理\r\n\r\n### 課題の種別\r\n\r\n- QA:質問、問い合わせ\r\n- タスク:ToDo、実施予定作業\r\n- その他:上記以外、契約関連など\r\n\r\n
...
"createdUser": {
"id": xxxxxxxx,
"userId": null,
"name": xxxxxxxx,
"roleType": 1,
"lang": "ja",
"mailAddress": "xxxxxxxx@xxxxxxxx.jp",
...
},
"created": "2022-03-11T00:32:58Z",
"updatedUser": {
...
}
}
2. 取得したデータの変換
取得した Backlog Wiki データは、データストアにアップロードするために discoveryengine_v1.Document 型に変換する必要があります。データ変換のための関数を定義します。
from google.cloud import discoveryengine_v1
def convert_wikis_to_documents(wikis: List[dict]) -> List[discoveryengine_v1.Document]:
"""Convert Backlog wikis into Discovery Engine Document messages."""
docs: List[discoveryengine_v1.Document] = []
for wiki in wikis:
# Discovery Engine で検索対象となるペイロードを作成
payload = {
"id": wiki.get("id"),
"name": wiki.get("name"),
"content": wiki.get("content", ""),
"projectId": wiki.get("projectId"),
"tags": wiki.get("tags", []),
"created": wiki.get("created"),
"updated": wiki.get("updated"),
"createdUser": {
"name": wiki.get("createdUser", {}).get("name"),
"mailAddress": wiki.get("createdUser", {}).get("mailAddress"),
},
"updatedUser": {
"name": wiki.get("updatedUser", {}).get("name"),
"mailAddress": wiki.get("updatedUser", {}).get("mailAddress"),
},
# Backlog の Wiki URLを構築(検索結果からアクセスできるように)
"url": f"https://{BACKLOG_SPACE}/wiki/{PROJECT_KEY}/{wiki.get('id')}",
}
# discoveryengine_v1.Document インスタンスを作成
doc = discoveryengine_v1.Document(
id=str(wiki["id"]), # ID は文字列である必要がある
json_data=json.dumps(payload, ensure_ascii=False),
)
docs.append(doc)
return docs
前述したように Wiki のデータをデータストアにアップロードするために discoveryengine_v1.Document 型に変換します。このクラスのコンストラクタに以下の引数を渡します。
id: ドキュメントの一意の識別子。文字列型とする必要があります。今回は Backlog の Wiki ID をそのまま利用します。json_data: 検索対象となるフィールドを JSON 文字列化したデータ。検索に必要な任意の Key-Value ペアを含めることができます。今回の検証では Backlog の Wiki データから以下のフィールドを利用してjson_dataとしました。
| Backlog Wiki フィールド | 説明 |
|---|---|
| name | Wiki ページ名 |
| content | Wiki コンテンツ本文 |
| projectId | プロジェクト ID |
| tags | タグ |
| created | 作成日時 |
| updated | 更新日時 |
| createdUser | 作成者情報 |
| updatedUser | 更新者情報 |
| - | Wiki ページ URL |
discoveryengine_v1.Document クラスについては以下リファレンスをご参照ください。
データ変換を実行します。
docs = convert_wikis_to_documents(wikis)
print(f"Converted {len(wikis)} wikis to {len(docs)} documents.")
3. Google Cloud にデータストアを作成
ドキュメントをアップロードするために Google Cloud 上にデータストアを作成します。
まずは Google Cloud のパラメータを環境変数に設定します。データストアに設定する任意のデータストア ID もここで指定しておきます。
PROJECT_ID = "<PROJECT_ID>"
LOCATION = "global"
DATA_STORE_ID = "backlog-wiki-datastore-0001"
データストアを作成(作成済みの場合は取得)する関数を定義します。
def get_or_create_data_store(
project_id: str,
location: str,
display_name: str,
data_store_id: str,
) -> discoveryengine_v1.DataStore:
"""Get or create a DataStore."""
client = discoveryengine_v1.DataStoreServiceClient()
ds_name = client.data_store_path(project_id, location, data_store_id)
try:
# 既存のデータストアを取得
result = client.get_data_store(request={"name": ds_name})
return result
except:
# 新規データストアを作成
parent = client.collection_path(project_id, location, "default_collection")
operation = client.create_data_store(
request={
"parent": parent,
"data_store": discoveryengine_v1.DataStore(
display_name=display_name,
acl_enabled=False,
industry_vertical=discoveryengine_v1.IndustryVertical.GENERIC,
),
"data_store_id": data_store_id,
}
)
result = operation.result()
print(f"✓ 新規データストアを作成しました: {result.name}")
return result
データストアは collection と呼ばれるリソース上に作成されます。カスタムで作成する場合は default_collection という collection 上に作成します。
acl_enable=False でデータストアを作成すると ACL によるユーザーアクセス制御は無効になります。本検証では無効にしてデータストアを作成して動作を試します。
IndustryVertical は特定の業種(MEDIA や HEALTHCARE_FHIR など)に合わせて動作をカスタマイズすることができます。公式ドキュメントによると今回指定した GENERIC はほとんどのシナリオに適した値になるとのことです。
ではデータストアを作成します。
data_store = get_or_create_data_store(
PROJECT_ID,
LOCATION,
"Backlog Wiki データストア(ACL無し)", # display_name
DATA_STORE_ID
)
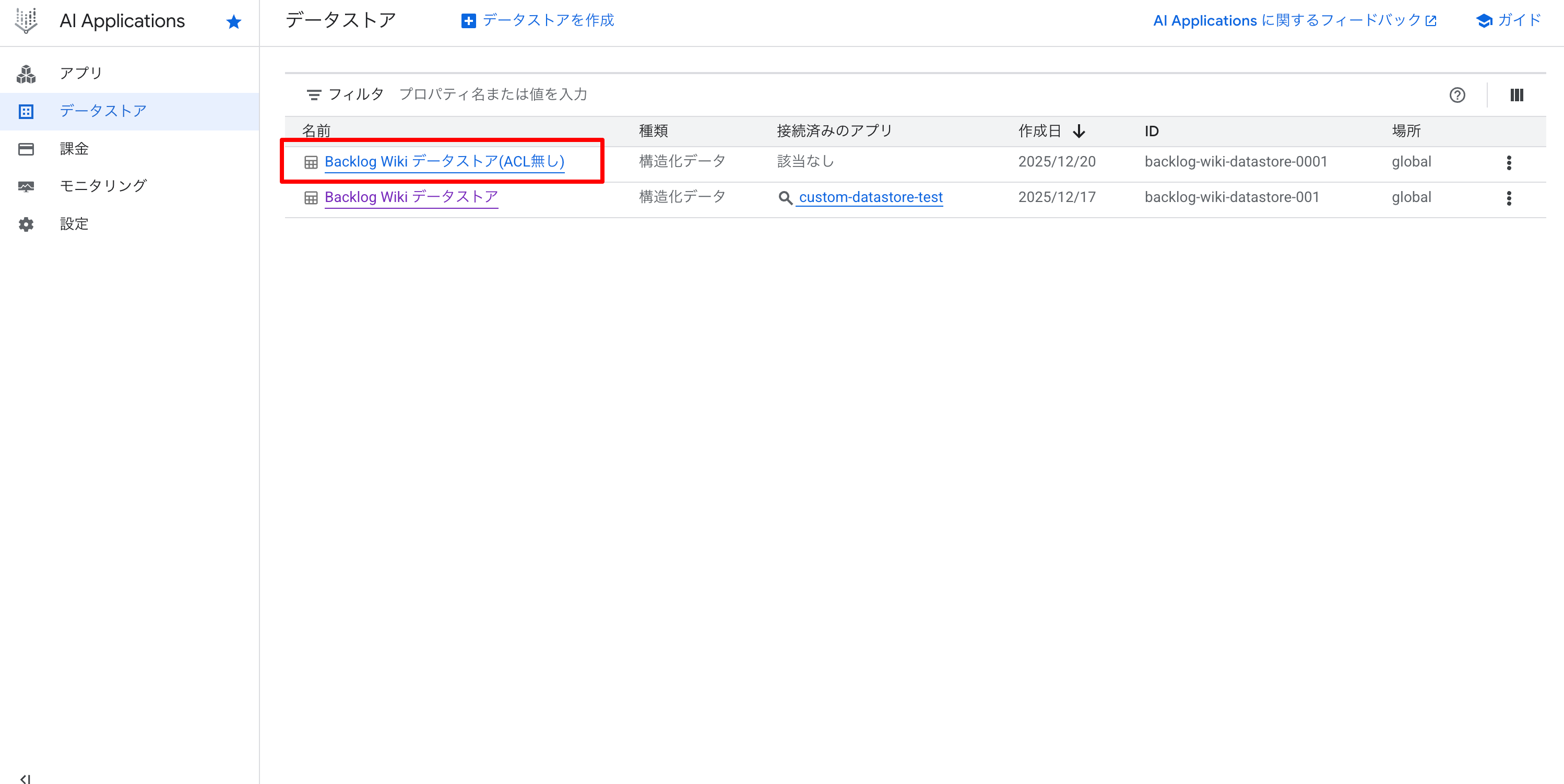
Cloud Console からデータストアの状態を確認してみます。検索窓で「ai application」と検索し [AI Application] を選択します。
[データストア] を選択すると、作成したデータストアが確認できます。
4. データストアにドキュメントをアップロード
「2. 取得したデータの変換」の手順で用意したドキュメントをデータストアにアップロードします。
今回は「インラインアップロード」という手法でデータストアに直接アップロードしていきます。インラインアップロードでは「増分調整モード」により、新しいドキュメントの追加や既存ドキュメントの更新は行われますが、ソースに存在しなくなったドキュメントは削除されません。
Cloud Storage や BigQuery からインポートする場合は「完全調整モード」をサポートします。こちらの手法ではデータ全体の完全性を維持できます。
def upload_documents_inline(
project_id: str,
location: str,
data_store_id: str,
branch_id: str,
documents: list,
) -> discoveryengine_v1.ImportDocumentsMetadata:
"""Inline import of Document messages."""
client = discoveryengine_v1.DocumentServiceClient()
# データストアのブランチのパスを構築
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch=branch_id,
)
# インポートリクエストを作成
request = discoveryengine_v1.ImportDocumentsRequest(
parent=parent,
inline_source=discoveryengine_v1.ImportDocumentsRequest.InlineSource(
documents=documents,
),
)
print(f"Uploading {len(documents)} documents to {parent}...")
# ドキュメントをインポート
operation = client.import_documents(request=request)
response = operation.result() # これが完了まで待機
# メタデータを取得
result = operation.metadata
print(f"✓ Document upload completed!")
print(f" Success count: {result.success_count}")
print(f" Failure count: {result.failure_count}")
return result
公式ドキュメントによるとデータストアの branch_id は通常 "0" を指定するとのことです。
インラインアップロードを実行します。
BRANCH_ID = "0" # 通常は "0" を使用
result = upload_documents_inline(
PROJECT_ID,
LOCATION,
DATA_STORE_ID,
BRANCH_ID,
docs # 「2. 取得したデータの変換」の手順で用意したドキュメント
)
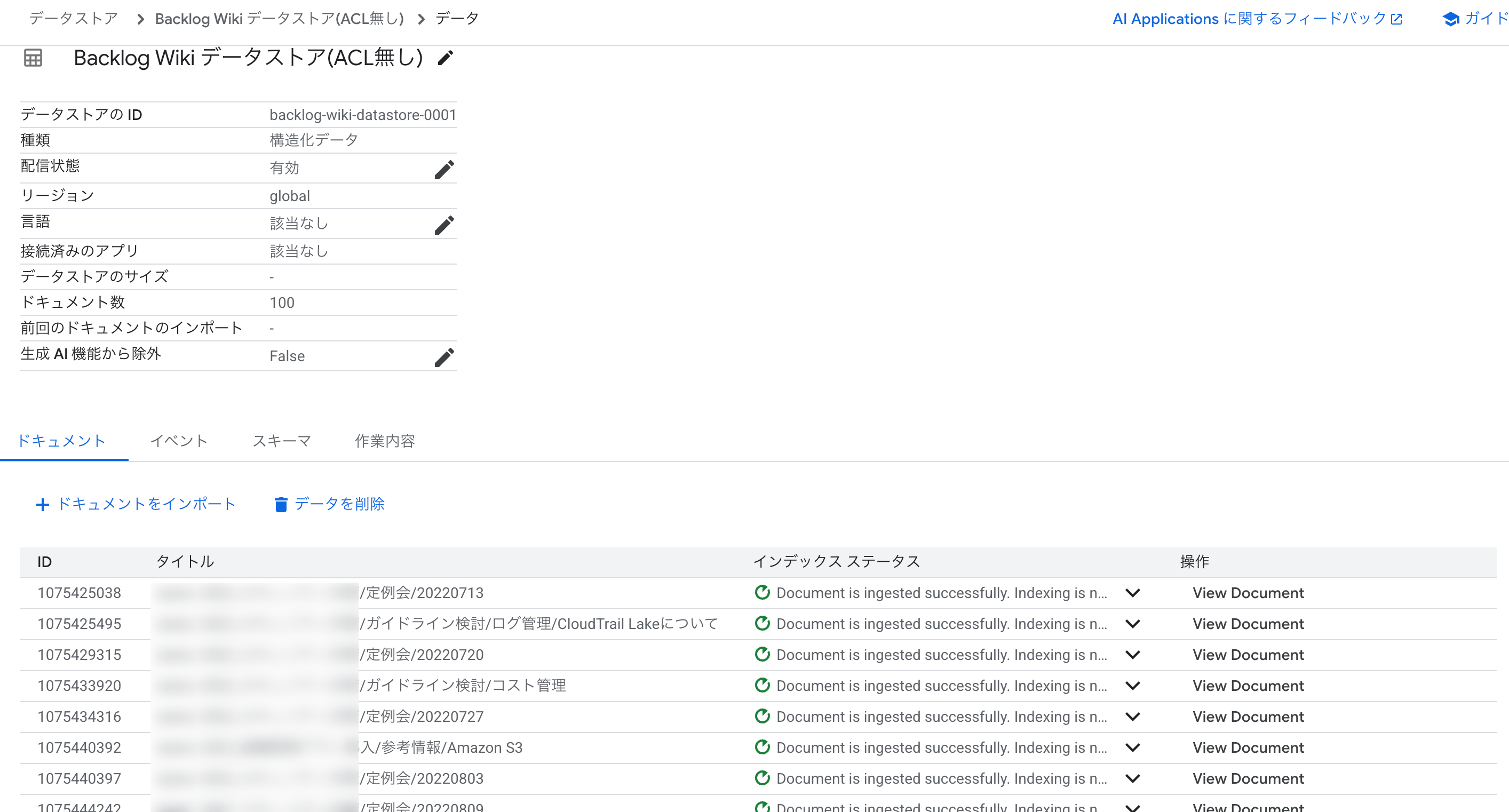
Cloud Console でデータストアを確認すると、以下のようにドキュメントがアップロードされていることがわかります。
5. Gemini Enterprise にデータストアを接続
Gemini Enterprise からデータストアのドキュメントを検索できるよう、Gemini Enterprise にデータストアを接続します。
Cloud Console の検索窓に「gemini enterprise」と入力し、[Gemini Enterprise] を選択します。
[アプリ] から対象のアプリを選択します。
[接続されたデータストア] -> [既存のデータストアを追加] をクリックします。
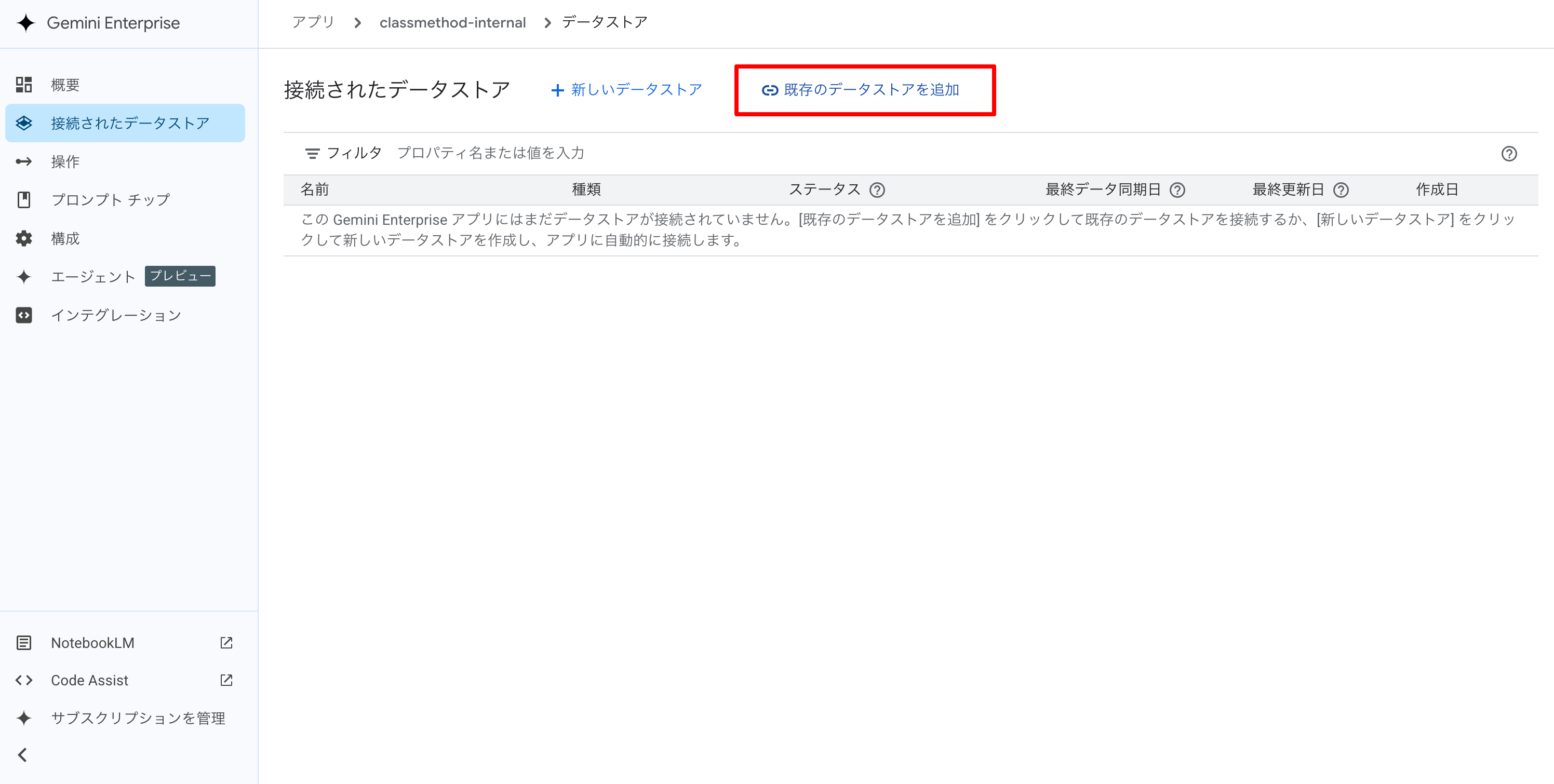
対象のデータストアにチェックをし、[接続] をクリックします。
データストアが接続されると以下が画面上に表示されます。
1 個のデータストアが正常に接続されました。検索結果の変更は約 10 分後に確認できます。 データストアをインデックスに登録する必要がある場合は、最終的な検索結果の動作が完了するまでに数時間待つ必要がある場合があります。
試してみる
前述の出力の通り 10 分程度待って検索してみます。
結果をわかりやすくするため、コネクタの選択から「Backlog Wiki データストア(ACL 無し)」のみを有効にしてチャットをスタートします。
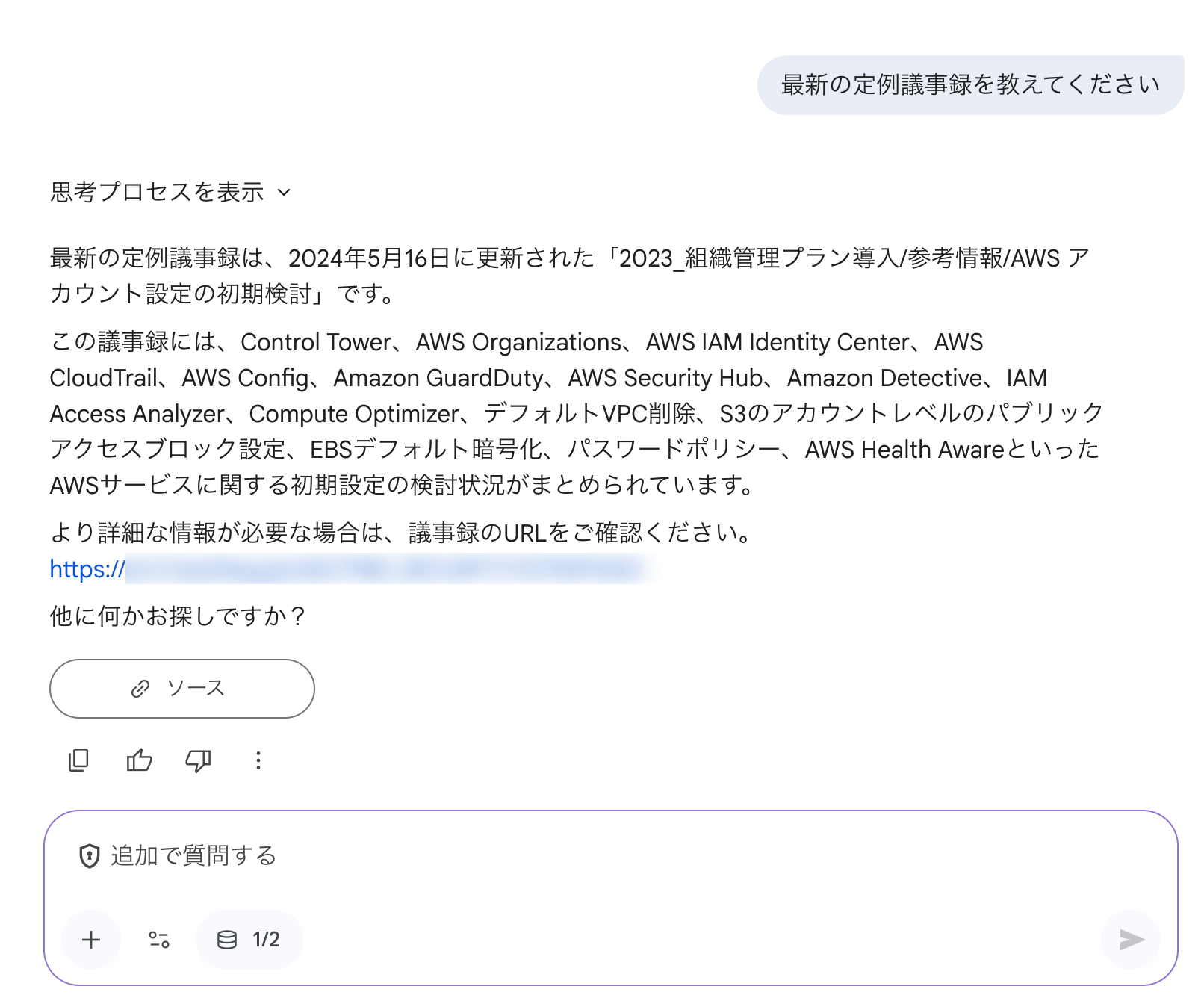
最新の定例議事録について聞いてみます。以下のように Wiki の情報をもとに回答してくれました。
おわりに
カスタムコネクタを作成し Gemini Enterprise から Backlog Wiki のデータを検索する手順を試してみました。
カスタムコネクタの作成方法にフォーカスして説明しました。
冒頭でもお伝えしたようにユーザーアクセス制御の実装は運用上極めて重要であることから、こちらについても検証結果を近いうちに公開できればと考えています。
また、効率的なデータ取得方法や検索結果の品質向上といった点でも調査や検証をしておりますので、こちらも調査・検証結果をブログで公開できればと考えています。










