
Generative AI Use Cases(GenU)でメタデータフィルタリングを設定してみた
はじめに
企業でのRAG(Retrieval-Augmented Generation)システム導入において、回答精度の向上は重要な課題です。
データ品質の向上がもっとも効果的ですが、社内規程や既存文書の制約により、データ自体の修正が困難なケースも多く存在します。
このような状況で有効な解決策の1つが、Amazon Bedrock Knowledge Baseが提供するメタデータフィルタリング機能です。
この機能を活用することで、検索対象となる文書を事前に絞り込み、より関連性の高い情報のみを検索対象とすることが可能です。
メタデータフィルタリングに関しては以下のブログがわかりやすいです。
上記機能はGenerative AI Use Cases (以降、GenU)でも利用可能なので、今回は実際にGenUで設定してみます。
やってみた
前提
- GenUの初回デプロイが完了していること
データの追加、メタデータの設定
まずはじめにドキュメントとメタデータを用意します。
メタデータに関しては以下のドキュメントを元に設定して下さい。
今回はClaude Sonnet 4にサンプルデータを作成してもらいました。
サンプルドキュメント各種
# リモートワーク規定
## 在宅勤務制度
- 対象:正社員(試用期間除く)
- 実施日数:週4日まで
- 申請:前月末までに提出
## 勤務時間
- 基本:9:00-18:00
- フレックス適用可
- コアタイム:11:00-15:00
## 業務環境
- 会社支給PC使用必須
- VPN接続による社内アクセス
- セキュリティソフト導入済み
## コミュニケーション
- 始業・終業時Slack報告
- 定時連絡:10:00、15:00
- 週次進捗会議参加必須
## オンコール対応
- 平日夜間:当番制
- 休日:24時間体制
- 緊急時2時間以内対応
- オンコール手当:3,000円/日
# シフト勤務規定
## 勤務シフト
- 早番:6:00-14:00
- 日勤:8:00-16:00
- 遅番:14:00-22:00
- 夜勤:22:00-6:00(翌日)
## シフト管理
- 週単位ローテーション
- 変更は2週間前まで
- 連続夜勤は最大3日
## 休憩時間
- 各シフト1時間の食事休憩
- 15分の小休憩×2回
- 夜勤時:30分仮眠可
## 安全管理
- 始業前安全確認:15分
- 終業前設備点検:15分
- 危険作業時:2名体制必須
## 特別手当
- 夜勤手当:1回3,000円
- 休日出勤手当:時給×1.35倍
- 危険作業手当:日額1,000円
# 勤務時間規定
## 基本勤務時間
- 標準勤務:9:00-18:00(実働8時間)
- 休憩時間:12:00-13:00(1時間)
- 週休2日制
## フレックスタイム制度
- コアタイム:10:00-15:00
- フレキシブルタイム:7:00-10:00、15:00-22:00
- 在宅勤務:週3日まで可能
## 時間外勤務
- 事前承認制
- 月間上限:45時間
- 深夜勤務(22:00-5:00):25%割増
## 休暇制度
- 年次有給休暇:20日/年
- 夏季休暇:3日連続取得推奨
- 特別休暇:慶弔、育児、介護
## 出勤管理
- タイムカード打刻必須
- 遅刻・早退は事前届出
- 月次勤怠報告書提出
サンプルメタデータ各種
{
"metadataAttributes": {
"department": "システム部",
"work_type": "flexible_remote",
"schedule_type": "flex_remote",
"overtime_limit": 100,
"weekend_work": false,
"title": "システム部勤務規定",
"language": "ja"
}
}
{
"metadataAttributes": {
"department": "製造部",
"work_type": "shift_work",
"schedule_type": "fixed_shift",
"overtime_limit": 60,
"weekend_work": true,
"title": "製造部勤務規定",
"language": "ja"
}
}
{
"metadataAttributes": {
"department": "営業部",
"work_type": "field_work",
"schedule_type": "flexible_field",
"overtime_limit": 80,
"weekend_work": true,
"title": "営業部勤務規定",
"language": "ja"
}
}
以下のようにS3の同一階層に各種ファイルをアップロードし、データソースの同期を行います。
.
├── it-work-policy.md
├── it-work-policy.md.metadata.json
├── manufacturing-work-policy.md
├── manufacturing-work-policy.md.metadata.json
├── sales-work-policy.md
└── sales-work-policy.md.metadata.json
それぞれソースファイル、メタデータファイルとして認識されていればデータの準備は完了です。

GenUの設定変更
従来のcdk.json、parameter.tsで変更可能なオプションと異なり、ソースコードを直接変更する必要があります。
packages/common/src/custom/rag-knowledge-base.ts内の定義を書き換えることで設定可能です。
今回はUI側から制御可能なuserDefinedExplicitFiltersを設定してみます。
以下のように既存の設定を削除して、メタデータに合わせたフィルタリング項目を追記します。
...省略
export const userDefinedExplicitFilters: ExplicitFilterConfiguration[] = [
- // Example 1: Filter by category (string match)
- {
- key: 'category',
- type: 'STRING',
- options: [{ value: 'AWS', label: 'AWS' }],
- description: 'Category',
- },
-
- // Example 2: Filter by tag (string list)
- {
- key: 'tag',
- type: 'STRING_LIST',
- options: [
- { value: 'AWS', label: 'AWS' },
- { value: 'Amazon Bedrock', label: 'Amazon Bedrock' },
- { value: 'Amazon SageMaker', label: 'Amazon SageMaker' },
- ],
- description: 'Tag',
- },
-
- // Example 3: Filter by year (number)
- {
- key: 'year',
- type: 'NUMBER',
- description: 'Year',
- },
-
- // Example 4: Filter by is_public (boolean)
- {
- key: 'is_public',
- type: 'BOOLEAN',
- options: [
- { value: 'true', label: 'Public' },
- { value: 'false', label: 'Private' },
- ],
- description: 'Public',
- },
-
- // Example 5: Filter by language (string match)
- {
- key: 'language',
- type: 'STRING',
- options: [
- { value: 'en', label: 'English' },
- { value: 'ja', label: 'Japanese' },
- ],
- description: 'Language',
- },
-
// Customize Here
+ // 部署フィルター
+ {
+ key: 'department',
+ type: 'STRING',
+ options: [
+ { value: '営業部', label: '営業部' },
+ { value: '製造部', label: '製造部' },
+ { value: 'システム部', label: 'システム部' },
+ ],
+ description: '部署',
+ },
+ // 勤務形態フィルター
+ {
+ key: 'work_type',
+ type: 'STRING',
+ options: [
+ { value: 'field_work', label: '外回り営業' },
+ { value: 'shift_work', label: 'シフト勤務' },
+ { value: 'flexible_remote', label: 'フレックス・在宅' },
+ ],
+ description: '勤務形態',
+ },
];
コードが変更できたらデプロイします。
npm run cdk:deploy
動作確認
最初はフィルターなしで抽象度高めな質問を投げてみます。
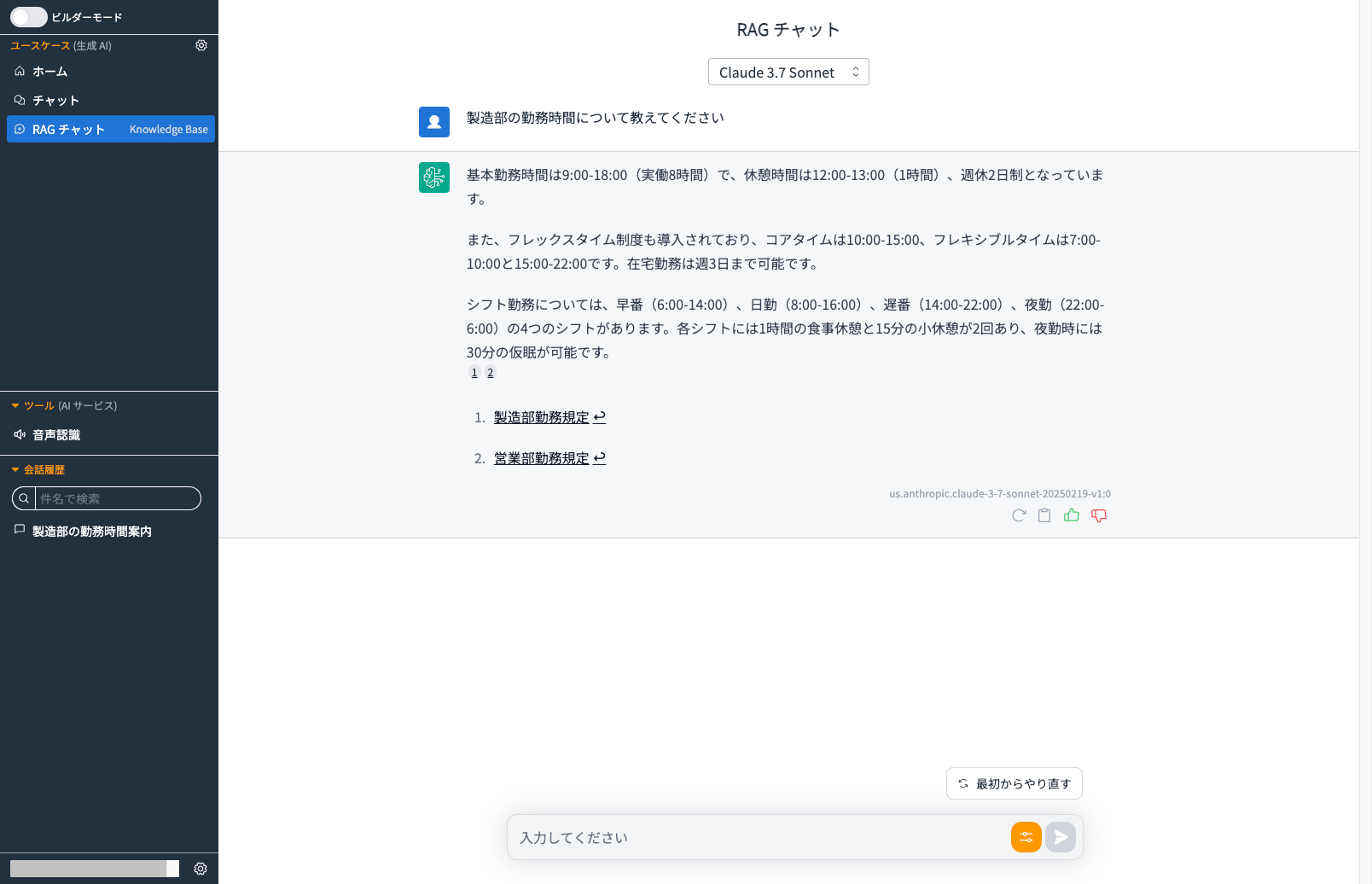
複数のドキュメントを参照した回答が返ってきてしまいました。
では今度はチャット欄にあるメニューからフィルターをかけてみます。
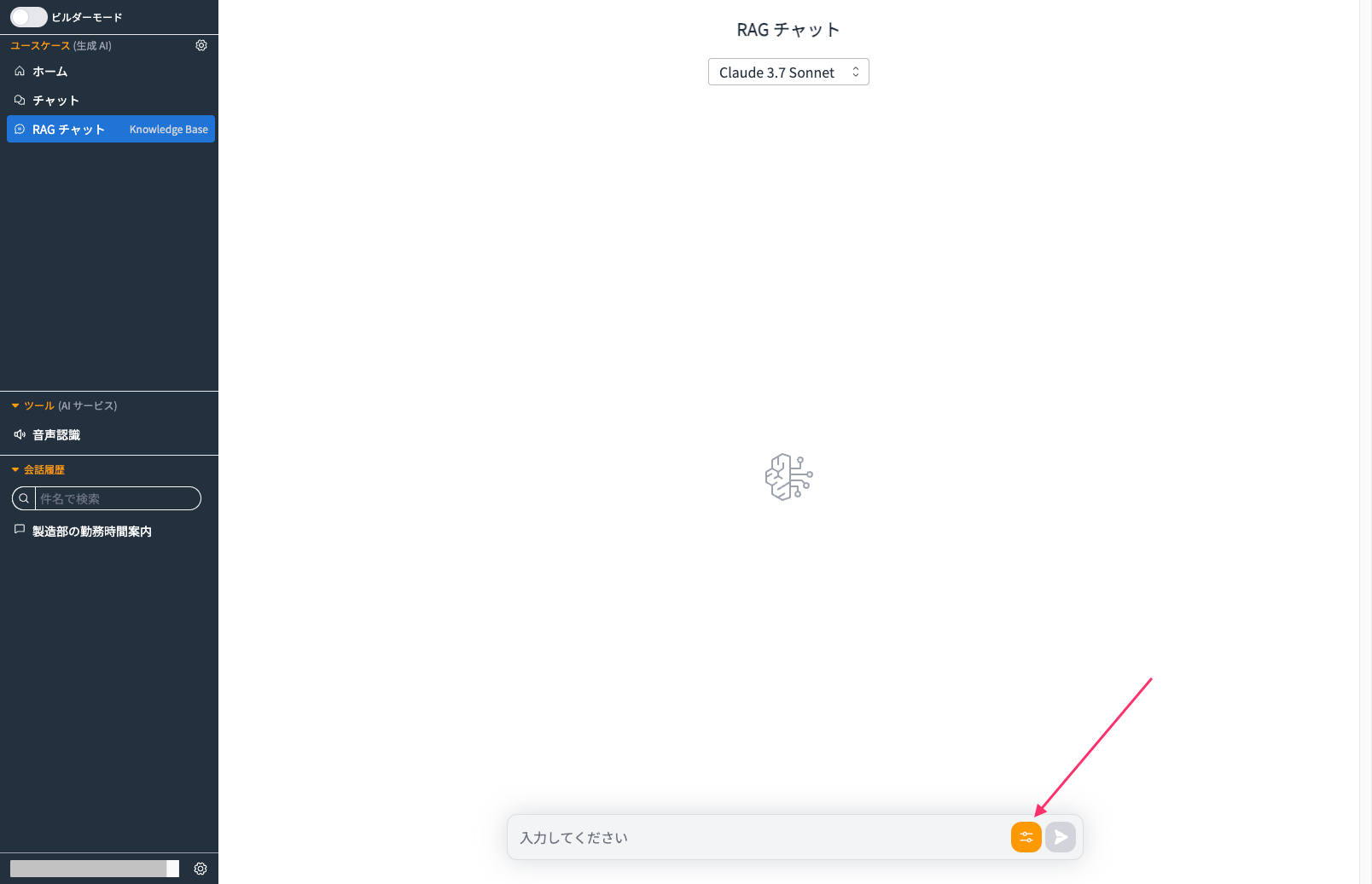
packages/common/src/custom/rag-knowledge-base.tsで設定したフィルターが選択できるようになっています。
試しに部署=製造部で設定してみます。
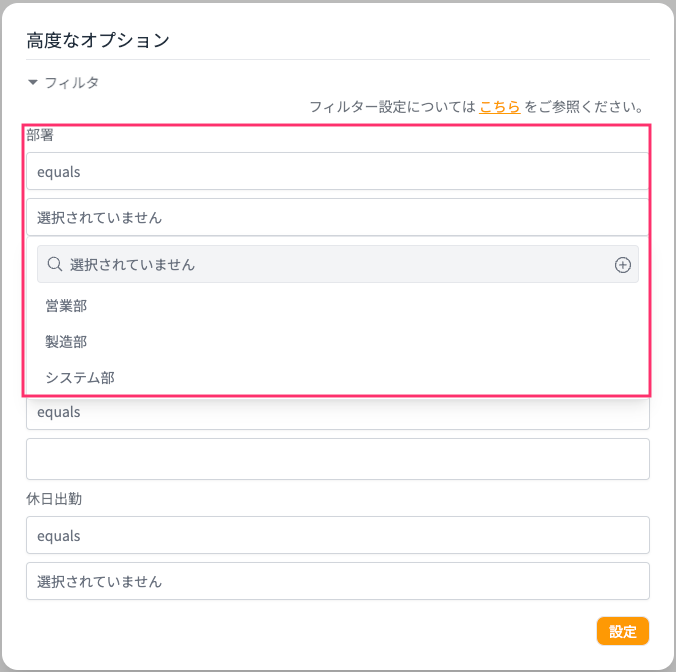
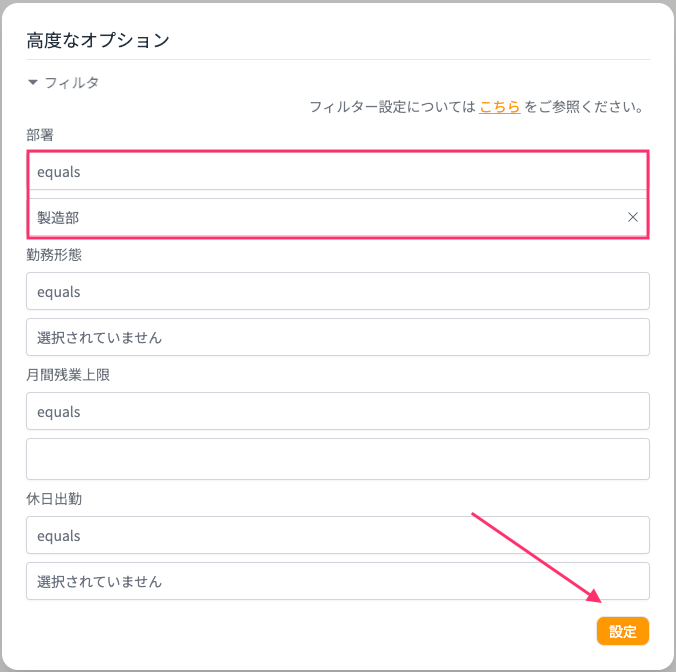
フィルターが効いているようで製造部勤務規定から回答が生成されました。
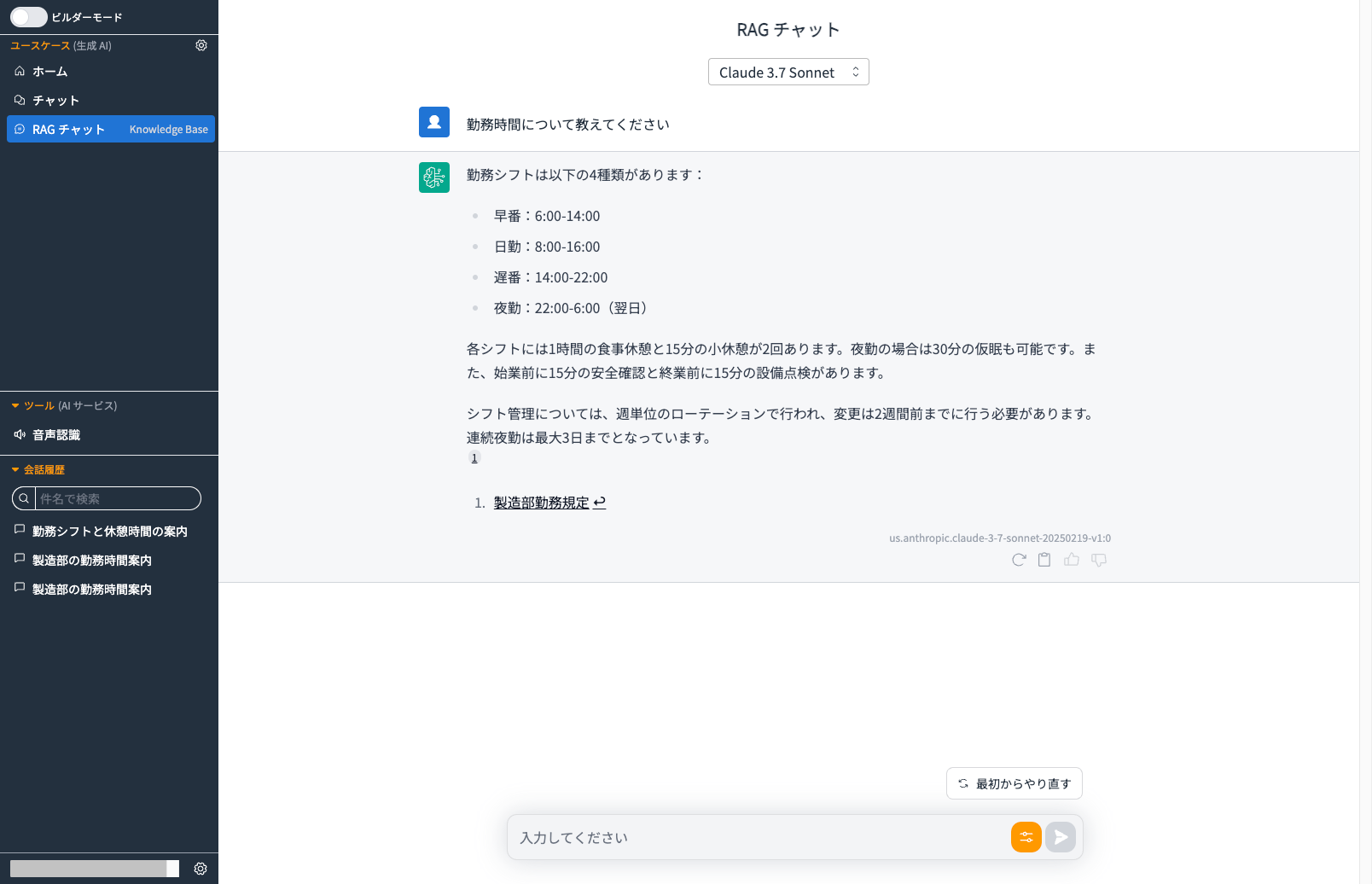
これでユーザーの質問の仕方に依存せずともある程度参照先のドキュメントを絞ることができます。
チャット履歴について
おそらくGenUに限った話になると思われますが、現状メタデータフィルターを有効にするとフィルターを使用した過去のチャット履歴が閲覧できなくなります。
多少利便性は落ちる可能性はあるので、この事象が許容できない場合はデータ品質を改善する等の別の手段で回答精度向上を試みましょう。(その内アップデートで改善されるかも?)
まとめ
今回は回答精度を向上させるべきGenUでメタデータフィルタリングを有効化してみました。
メタデータの用意や管理は割と大変なので、可能なら元データの品質を改善することをお勧めします。
どなたかの参考になれば幸いです。








