
GlueのApache Icebergベースマテリアライズドビューの特徴まとめと、S3 Tables Catalog上での構成手順
はじめに
こんにちは、データ事業本部の渡部です。
今回は、re:invent2025直前に発表されたGlueのApache IcebergベースのMaterialized View(マテリアライズドビュー)機能をまとめつつ、試してみます。
マテリアライズドビューは、SQLクエリの事前計算結果をApache Iceberg形式で保存し、基盤となるソーステーブルが変更されると自動的に更新されるマネージドテーブルです。これにより、複雑なデータ変換パイプラインを簡素化し、クエリパフォーマンスを向上させることができます。
特にS3 Tablesにおいては、以前までビューの作成がLake Formationのresource linkを経由しないとできなかったため、自動更新含むマテリアライズドビューが追加されたことで、ETLの作成負荷も下がるんじゃないかと思いました。
なおS3Tablesをベーステーブルとしたマテビューは正式サポートがまだのようで、一部機能が機能しませんでした。アップデートを待ちます。
Glueのマテリアライズドビューについて
Glueマテリアライズドビューの要点は以下の通りです。
- Apache Iceberg形式でのMaterialized View: AWS Glue Data Catalog/S3Tables CatalogでApache Iceberg形式でのマテリアライズドビューの作成と管理が可能になりました。
- 自動更新機能: ソーステーブルの変更を検出し、自動的にマテリアライズドビューを更新します。最小更新間隔は1時間で、増分更新にも対応しています。
- ベーステーブルへのアクセス権限不要: Lake Formationでマテリアライズドビューに対してSELECT権限を許可をすると、元のベーステーブルへのアクセス権限なくアクセス可能です。
- マルチエンジンアクセス: 作成されたマテリアライズドビューはAmazon Athena、Amazon EMR、AWS Glue、Amazon Redshiftなど複数のクエリエンジンからアクセス可能です。
- 自動クエリ書き換え: Sparkオプティマイザが、パフォーマンス向上のためにクエリを自動的にマテリアライズドビューを使用するように書き換えます。
Apache Iceberg形式でのMaterialized View
Iceberg形式でマテリアライズドビューは保存されます。
Glue Data Catalog・S3 Tables Catalogどちらにでも保存できますが、基本はIcebergメンテナンスが自動化されるS3 Tables上に保存をすると運用負荷が下がるため良いと思います。
どちらのカタログをベーステーブルとしても、マテリアライズドビューの作成は可能です。
2025/12/27時点では、Amazon Athena、Amazon EMR、AWS Glue の Spark エンジンでマテリアライズドビューの作成が可能です。AthenaでS3 Tablesテーブルを作るようにさくっとできるようになれば、さらに嬉しいですね。
なおIceberg形式ということで、Icebergの機能を持ち合わせています。
試しにタイムトラベル機能ですが、以下のようにスナップショットを確認することが可能です。
SELECT * FROM watanabe_namespace."mvsampletable$snapshots"
ORDER BY committed_at DESC;
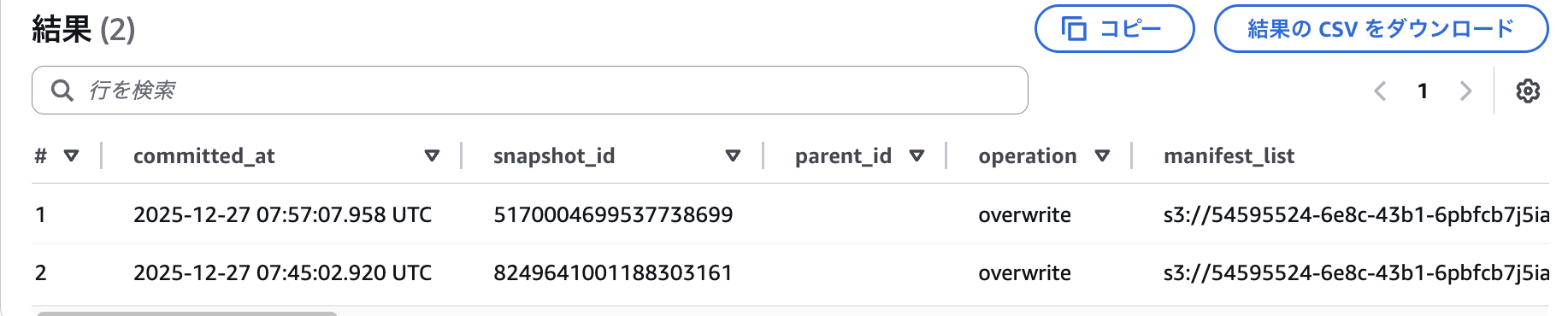
以下は特定時間のデータを取得するクエリです。
SELECT * FROM "s3tablescatalog/watanabetable01"."watanabe_namespace"."mvsampletable"
FOR TIMESTAMP AS OF TIMESTAMP '2025-12-27 07:50:00';
自動更新機能
マテリアライズドビューの自動更新(リフレッシュ)は、マネージド Spark コンピューティングインフラストラクチャを使用してバックグラウンドに行われるようです。
制限はありますが、前回の更新以降にソーステーブルで変更されたデータのみを処理する増分更新にも対応しているため、自分の手で差分抽出ロジックを組まなくてよいのも助かります。
自動クエリ書き換え機能について
自動クエリ書き換え機能は、Sparkオプティマイザがクエリを解析し、既存のマテリアライズドビューを使用することで同じ結果を返せる場合に、自動的にクエリを書き換える機能です。
例えば、以下のようなクエリを実行したとします。
SELECT customer_name, COUNT(*) as order_count, SUM(amount) as total_amount
FROM glue_catalog.sales.orders
GROUP BY customer_name
このクエリと同じ結果を返すマテリアライズドビュー(customer_summary)が既に存在する場合、Sparkは自動的に以下のように書き換えます。
SELECT * FROM customer_summary
自動クエリ書き換え機能の最大のメリットは、既存のクエリを変更することなく自動的にパフォーマンスが向上することです。事前計算済みのデータを使用するため、元のテーブルが大きくても高速にクエリを実行でき、元のテーブル全体をスキャンする必要がなくなるため、処理コストも削減されます。
ただし、いくつか注意点があります。
マテリアライズドビュー作成直後は、Sparkのメタデータキャッシュに反映されるまで数十秒かかることがあり、その間は元のテーブルからクエリが実行されます。
また、公式ドキュメントによると、書き換えは「制限されたSQLサブセット」に定義されたマテリアライズドビューのみが対象となるため、複雑なJOINやサブクエリなどは書き換えの対象外になります。
自動更新中は古いデータを返す可能性があるため、即時の整合性が必要な場合は手動更新が必要です。
制限事項
さてもちろんですが、マテリアライズドビューには普通のテーブルを扱うよりは制限があります。
以下ドキュメントに記載の制限事項で主要なものをピックアップします。
- マテリアライズドビューは、AWS Glue データカタログにベーステーブルとして登録された Apache Iceberg テーブルのみを参照できます。
- 今回S3 Tables Catalogをベースとしたマテビューも作成してみましたが、自動更新が効かず、完全なサポートがされていないことがわかりました。
- ビューの作成と自動クエリ書き換えは、Amazon Athena、Amazon EMR、AWS Glue (バージョン 5.1) 全体の Apache Spark バージョン 3.5.6 以降の Spark エンジンからのみ利用できます。
- マテリアライズドビューの作成・管理には AWS Glue バージョン 5.1 以降が必要です。
- ソーステーブルは、マテリアライズドビューと同じリージョンとアカウントに存在する必要があります。
- すべてのソーステーブルは AWS Lake Formation によって管理される必要があります。IAM のみのアクセス許可とハイブリッドアクセスはサポートされていません。
- 増分更新は、SQL オペレーションの制限されたサブセットをサポートします。ビュー定義は単一の SELECT-FROM-WHERE-GROUP BY-HAVING ブロックである必要があり、セットオペレーション、サブクエリ、SELECT または集計関数の DISTINCT キーワード、ウィンドウ関数、INNER JOIN 以外の結合を含むことはできません。
試してみた
前提
私のAWSアカウント環境についての情報を以下に記載します。
- AWS Glue バージョン 5.1
- AWS分析サービスとの統合有効済み
- Lake Formationでの権限制御適用済み
はじめに試そうとした構成は、S3 Tablesをベースとして、S3 Tables Catalog上にマテリアライズドビューを作成する構成です。
前述のとおりですが、S3 Tablesをベーステーブルとするのは正式にサポートされておらず、自動更新が効かなかったです。
そのため、ベーステーブルをAWS Glue Data CatalogのIcebergテーブルとした以下構成を今回のブログでは載せています。うまく自動更新までいくことを確認しました。
ベーステーブルの作成
AthenaでベースとなるIcebergテーブルを作成し、データを挿入します。
CREATE TABLE watanabe_test_db.sampletable_iceberg (
id INT,
name STRING,
age INT
)
LOCATION 's3://cm-watanabe-gluedata/warehouse/watanabe_test_db/sampletable_iceberg/'
TBLPROPERTIES (
'table_type' = 'ICEBERG'
);
INSERT INTO "AwsDataCatalog".watanabe_test_db.sampletable_iceberg (id, name, age)
VALUES
(1, 'User1', 35),....;
Lake Formation
やることとしては以下です。
- Data lake locationsへのベーステーブルの登録
- Data PermissionでGlue実行ロールに権限付与
マテビューの作成先となるS3 Tables Catalogは分析サービスとの統合時にすでにData Lake Locationには登録済みとなります。
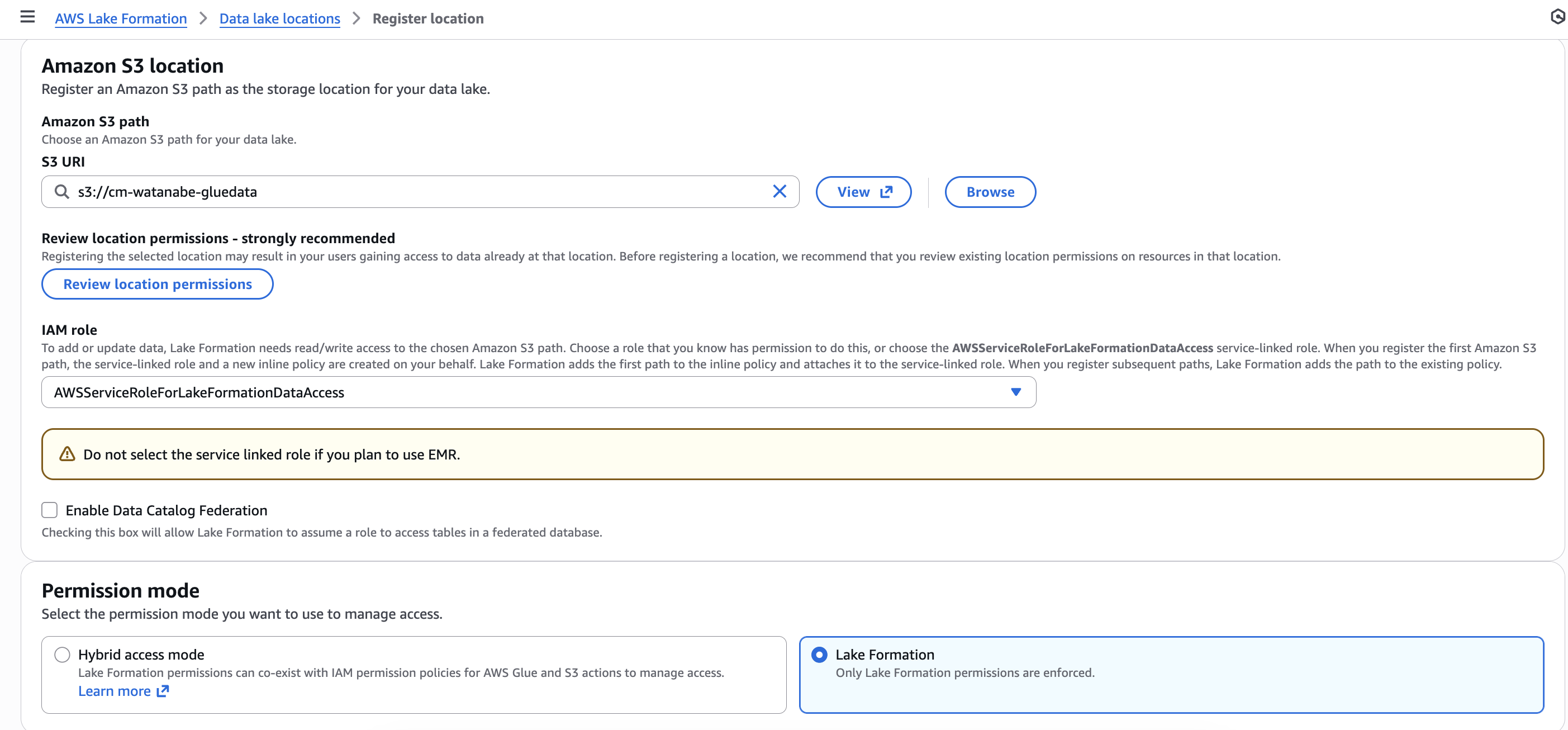
Data PermissionでGlueの実行Roleに対して、Catalog・Database・Tableの権限を割り当てます。
Lake Formationについては以下ブログをご参考ください。
Glueジョブでマテリアライズドビューを作成する
Glueスクリプト
Glue Sparkジョブを構成し、以下のスクリプトを使用しました。
検証用にパラメータはすべてコード上に寄せています。
import sys
import logging
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
from datetime import datetime
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("create_mv_from_glue_catalog_job")
def main():
# --- パラメータ設定 ---
args = {
'JOB_NAME': 'create_mv_from_glue_catalog_job',
's3t_catalog_id': '<account-id>:s3tablescatalog/watanabetable01', # S3 Tables Catalog ID
's3t_warehouse_path': 's3://watanabe-namespace/', # S3 Tables warehouse(S3バケットは存在しなくてもよい)
'glue_account_id': '<account-id>', # Glue Data Catalog用のアカウントID
'glue_warehouse_path': 's3://cm-watanabe-gluedata/warehouse/', # Glue Data Catalog warehouse
'region': 'us-east-1',
}
# --- Spark/Glueコンテキストの初期化 ---
logger.info("Sparkの設定を開始します。")
# 公式ドキュメントのS3 Tablesバケット + クロスカタログ参照の設定例に基づく
# 参考: https://docs.aws.amazon.com/ja_jp/glue/latest/dg/materialized-views.html#materialized-views-creating
spark_conf = SparkSession.builder.appName(args['JOB_NAME']) \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.glue_catalog.type", "glue") \
.config("spark.sql.catalog.glue_catalog.warehouse", args['glue_warehouse_path']) \
.config("spark.sql.catalog.glue_catalog.glue.region", args['region']) \
.config("spark.sql.catalog.glue_catalog.glue.id", args['glue_account_id']) \
.config("spark.sql.catalog.glue_catalog.glue.account-id", args['glue_account_id']) \
.config("spark.sql.catalog.glue_catalog.client.region", args['region']) \
.config("spark.sql.catalog.glue_catalog.glue.lakeformation-enabled", "false") \
.config("spark.sql.catalog.s3t_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.s3t_catalog.type", "glue") \
.config("spark.sql.catalog.s3t_catalog.glue.id", args['s3t_catalog_id']) \
.config("spark.sql.catalog.s3t_catalog.glue.account-id", args['glue_account_id']) \
.config("spark.sql.catalog.s3t_catalog.glue.lakeformation-enabled", "false") \
.config("spark.sql.catalog.s3t_catalog.warehouse", args['s3t_warehouse_path']) \
.config("spark.sql.catalog.s3t_catalog.glue.region", args['region']) \
.config("spark.sql.catalog.s3t_catalog.client.region", args['region']) \
.config("spark.sql.defaultCatalog", "s3t_catalog") \
.config("spark.sql.optimizer.answerQueriesWithMVs.enabled", "true") \
.config("spark.sql.materializedViews.metadataCache.enabled", "true") \
.config("spark.sql.optimizer.incrementalMVRefresh.enabled", "true") \
.config("spark.sql.optimizer.incrementalMVRefresh.deltaThresholdCheckEnabled", "false") \
.config("spark.sql.optimizer.answerQueriesWithMVs.decimalAggregateCheckEnabled", "false") \
logger.info("Sparkの設定を完了しました。")
sc = SparkContext.getOrCreate(conf=spark_conf.getOrCreate().sparkContext.getConf())
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# --- Materialized View作成クエリ ---
# ベーステーブル: glue_catalog.watanabe_test_db.sampletable_iceberg
# MV作成先: s3t_catalog.watanabe_namespace.mvsampletable_iceberg
logger.info("マテリアライズドビューの作成クエリを開始します。")
create_mv_query = """
CREATE MATERIALIZED VIEW s3t_catalog.watanabe_namespace.mvsampletable_iceberg
SCHEDULE REFRESH EVERY 1 HOUR
AS
SELECT
id,
name,
age
FROM glue_catalog.watanabe_test_db.sampletable_iceberg
WHERE age > 30
"""
logger.info("マテリアライズドビューの作成を開始します。")
logger.info(f"SQLクエリを実行します。\n{create_mv_query}")
try:
# --- SQLクエリの実行 ---
spark.sql(create_mv_query)
except Exception:
logger.exception("マテリアライズドビューの作成に失敗しました。")
raise
else:
logger.info("マテリアライズドビューの作成に成功しました。")
job.commit()
logger.info("Jobは完了しました。")
if __name__ == "__main__":
main()
ポイントが2点あります。
1点目はS3 Tablesカタログを使用する場合、glue.idには<account-id>:s3tablescatalog/<bucket-name>の形式で指定する必要があります。
2点目はspark.sql.catalog.glue_catalog.glue.lakeformation-enabledはAWS Glue Data Catalogを指定する際はfalseにしないとエラーとなります。Lake Formationを使用しなければマテリアライズドビューは作成できないと制限事項には書いていますが、設定はこのようにしないと動きません。なおS3 Tablesをベーステーブルとした際はtrueでも動きました。
エラーメッセージ:( Failed to retrieve AWS Lake Formation temporary credentials for table arn:aws:glue:us-east-1:<account_id>:table/watanabe_test_db/sampletable_iceberg with permission SELECT. Error: Access is not allowed. )
さてマテリアライズドビューは標準的なSQL構文で作成できます。自動更新を設定する場合は、SCHEDULE REFRESH EVERY句を使用します。
CREATE MATERIALIZED VIEW s3t_catalog.watanabe_namespace.mvsampletable_iceberg
SCHEDULE REFRESH EVERY 1 HOUR
AS
SELECT
id,
name,
age
FROM glue_catalog.watanabe_test_db.sampletable_iceberg
WHERE age > 30
クロスカタログでマテリアライズドビューを作成する際は、テーブル名を完全修飾(3-part naming: catalog.database.table)で指定する必要があります。
Glueジョブ実行
Worker Type : G 1X、workers : 2で1分強くらいで成功します。
もし失敗する場合は、logsを見てスクリプトを修正ください。
マテリアライズドビューの情報を取得する
別のGlueジョブで、作成したマテリアライズドビューの情報を取得してみました。
SHOW VIEWS
データベース内のマテリアライズドビュー一覧を取得します。
SHOW VIEWS FROM s3t_catalog.watanabe_namespace
実行結果から、watanabe_namespaceデータベース内に4つのマテリアライズドビューが存在することが確認できました。
+------------------+----------------+-----------+
|namespace |viewName |isTemporary|
+------------------+----------------+-----------+
|watanabe_namespace|mvsampletable |false |
|watanabe_namespace|mvsampletable_02|false |
|watanabe_namespace|mvsampletable_03|false |
|watanabe_namespace|mvsampletable_04|false |
+------------------+----------------+-----------+
DESCRIBE EXTENDED
特定のマテリアライズドビューの詳細情報を取得します。
DESCRIBE EXTENDED s3t_catalog.watanabe_namespace.mvsampletable_iceberg
実行結果から、以下の情報が確認できました。
- Provider:
iceberg(Iceberg形式で管理されている) - Table Properties:
isMaterializedView=true(マテリアライズドビューであることが確認できる) - viewOriginalText: マテリアライズドビューの定義SQLがそのまま保存されている
- subObjects: 参照元テーブル(
sampletable)の情報 - schedule:
3600(自動更新間隔が3600秒=1時間で設定されている) - Location: S3 Tables側の管理ストレージにデータが保存されている
SHOW TBLPROPERTIES
テーブルプロパティをキー単位で確認できます。
SHOW TBLPROPERTIES s3t_catalog.watanabe_namespace.mvsampletable_iceberg
重要なプロパティとして以下が確認できました。
isMaterializedView: true(MVであることを示す)schedule: 自動更新間隔(秒)current-snapshot-id/viewVersionId: Icebergのスナップショット管理が機能している証拠lastRefreshType: 最終更新タイプ(FULL または INCREMENTAL)
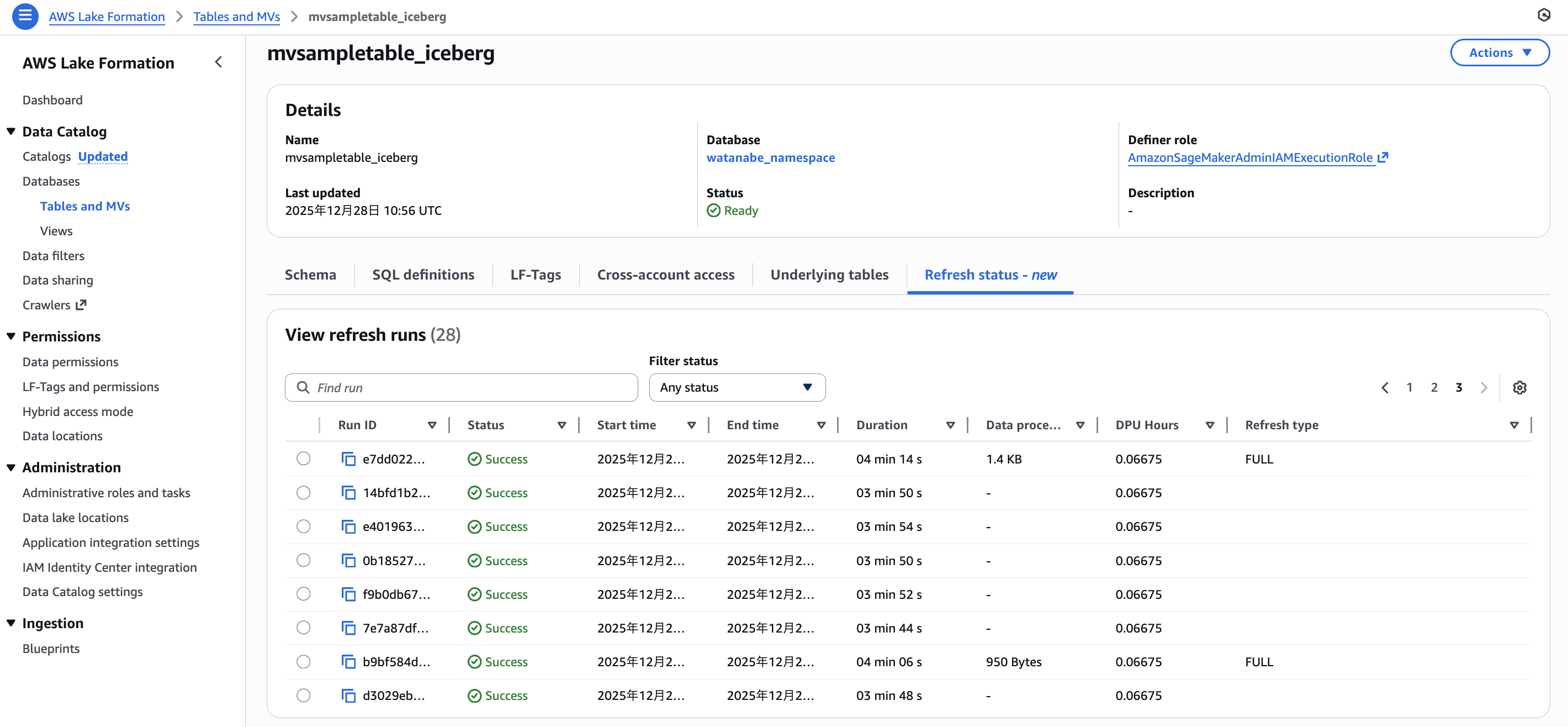
マテリアライズドビュー更新のステータス
Lake Formationコンソールから、マテリアライズドビュー更新のステータスが確認可能です。
自動更新がかかったタイミングや更新タイプが表示されていますね。
さいごに
いかがでしたでしょうか。
AWS Glue 5.1で追加されたApache Iceberg Materialized View機能により、複雑なデータ変換パイプラインを簡素化し、クエリパフォーマンスを向上させることができるようになりました。自動更新機能により、手動でのパイプライン管理が不要になり、運用負荷が大幅に削減されます。
一方で、いくつかの制限事項があるため、実際に使用する際は公式ドキュメントを確認しながら進めることをおすすめします。
以上です。どなたかのご参考になれば幸いです。
参考










