
Cloud Run のエフェメラルディスク機能を使ってみる #GoogleCloudNext
はじめに
Google Cloud Next' 26 で、 Cloud Run に エフェメラルディスク という機能が追加されました(※執筆時点でプレビューの機能)。インスタンスに一時ディスクストレージを割り当てられるというシンプルな機能です。今回はこの機能を、実際に触って動作を確認してみました。
従来の Cloud Run のストレージ
Cloud Run では通常は /tmp にファイルを書き込めます。しかし、この /tmp は tmpfs(インメモリファイルシステム) であり、 /tmp へのファイル書き込みは実際にはメモリを消費します。
大容量ファイルを処理したい場合、このシステムが制約になるケースがあります。1GB のファイルを /tmp に展開すると、それだけでメモリが 1GB 消費されます。Cloud Run のメモリはコストに直結するリソースなので、一時ファイルのためだけに積むのはコスト効率が良くありません。
エフェメラルディスクとは
エフェメラルディスクは、Cloud Run インスタンスに メモリとは独立した一時ディスクストレージ を割り当てる機能です。
執筆時点でパブリックプレビュー(GA前) の機能 であるため、注意してください
簡単ですが、以下のような特徴があります。
- インスタンスの起動時に自動プロビジョニングされ、ext4 でフォーマットされる
- メモリを消費しない
- Cloud Run 第2世代実行環境のみ対応
Cloud Storage ボリュームマウントと違い、ローカルディスクとして動作するためレイテンシが低く、ネットワーク通信が不要な点がメリットです。
ただし、エフェメラルという名前の通り、あくまで一時保存用のディスクです。永続化をする必要がある場合は、 Cloud Storage や Firestore など外部のサービスを使う必要がある点は従来と変わりません。
エフェメラルディスクの仕様
それぞれの仕様は以下のようになっています。(値は公式ページ、公式ドキュメントより引用)
| メモリ(RAM) | エフェメラルディスク | |
|---|---|---|
| 料金単価(東京リージョン) | $0.000002 / GiB秒 | $0.000109589 / GiB時間 |
| 無料枠 | 毎月最初の 450,000 GiB秒 | なし |
| インスタンスあたりの最大サイズ | 32GiB | 10 GB(引上げ可) |
| プロジェクト/リージョンあたりのクォータ | - | 100 GB |
料金単価は単位が違うので、具体的な数値での比較もしておきます。
1GiB のメモリ/エフェメラルディスクを確保した場合の、1時間あたりの料金はそれぞれ以下の料金になります。(いずれも東京リージョンの場合)
- メモリ:$0.0072 /h
- エフェメラルディスク:$0.000109589 /h
これを比較すると、同じ使用量であればエフェメラルディスクはメモリの 約15% の利用料金になることがわかります。かなり安いですね。
ただし、現時点ではエフェメラルディスクには無料利用枠がないため、必ず安くなるわけではない点は注意してください。
では、この特徴を踏まえて実際に検証していきます。
検証すること
同じ 1GB のファイルを GCS からダウンロードして、
/tmp(インメモリ)に置く場合- エフェメラルディスクに置く場合
でメモリ消費量とディスク使用量がどう変わるかを確認します。
具体的には、以下の方法で検証します。
- GCS バケットに 1GB のダミーファイルを配置
- Cloud Run サービス(第2世代)を 2 パターンでデプロイ
- パターン A:ダウンロード先を
/tmp(インメモリ)、メモリ 2GiB - パターン B:エフェメラルディスク(10GiB)をマウント、ダウンロード先を
/mnt/data、メモリ 512MiB
- パターン A:ダウンロード先を
/downloadエンドポイントを叩いてダウンロードを実行し、ファイルシステムの使用状況とコンテナのメモリ使用量を返す
やってみる
では、早速検証してみます。
Cloud Storage にテスト用ファイルを用意する
まず、Cloud Storage にダミーのファイルを作成します。
# ダミーファイル作成
dd if=/dev/zero of=testfile.bin bs=1M count=1024
# バケット作成
gcloud storage buckets create gs://${GOOGLE_CLOUD_PROJECT}-ephemeral-test --location=asia-northeast1
# ファイルをアップロード
gcloud storage cp testfile.bin gs://${GOOGLE_CLOUD_PROJECT}-ephemeral-test/testfile.bin
Cloud Run 用のサービスアカウントを作成し、バケットへの読み取り権限を付与します。
# サービスアカウントを作成
gcloud iam service-accounts create cr-ephemeral-test-sa \
--display-name="Cloud Run Ephemeral Disk Test SA"
# バケットへの読み取り権限を付与
gcloud storage buckets add-iam-policy-binding gs://${GOOGLE_CLOUD_PROJECT}-ephemeral-test \
--member="serviceAccount:cr-ephemeral-test-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/storage.objectViewer"
アプリを作成する
ダウンロード後にファイルシステムとコンテナのメモリ使用状況を返すシンプルな Flask アプリを用意します。DOWNLOAD_PATH 環境変数で /tmp とエフェメラルディスクを切り替える形で、コードは同一のものを利用します。
app.py
import os
import subprocess
import time
from flask import Flask, jsonify
from google.cloud import storage
app = Flask(__name__)
BUCKET_NAME = os.environ["BUCKET_NAME"]
FILE_NAME = "testfile.bin"
DOWNLOAD_PATH = os.environ.get("DOWNLOAD_PATH", f"/tmp/{FILE_NAME}")
BENCH_SIZE_MB = 512
def get_df(path):
result = subprocess.run(["df", "-m", path], capture_output=True, text=True)
lines = result.stdout.strip().split("\n")
fields = lines[1].split()
return {
"filesystem": fields[0],
"total_mb": int(fields[1]),
"used_mb": int(fields[2]),
"available_mb": int(fields[3]),
}
def benchmark_io(directory):
bench_file = os.path.join(directory, "bench.bin")
chunk = b"\x00" * (1024 * 1024)
start = time.time()
with open(bench_file, "wb") as f:
for _ in range(BENCH_SIZE_MB):
f.write(chunk)
f.flush()
os.fsync(f.fileno())
write_mbps = round(BENCH_SIZE_MB / (time.time() - start), 1)
start = time.time()
with open(bench_file, "rb") as f:
while f.read(1024 * 1024):
pass
read_mbps = round(BENCH_SIZE_MB / (time.time() - start), 1)
os.remove(bench_file)
return {"write_mbps": write_mbps, "read_mbps": read_mbps}
@app.route("/download")
def download():
client = storage.Client()
bucket = client.bucket(BUCKET_NAME)
blob = bucket.blob(FILE_NAME)
blob.download_to_filename(DOWNLOAD_PATH)
download_dir = os.path.dirname(DOWNLOAD_PATH)
return jsonify({
"download_path": DOWNLOAD_PATH,
"filesystem": get_df(download_dir),
})
@app.route("/benchmark")
def benchmark():
download_dir = os.path.dirname(DOWNLOAD_PATH)
return jsonify({
"directory": download_dir,
"io_benchmark": benchmark_io(download_dir),
})
@app.route("/")
def index():
return "ok"
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
requirements.txt
flask
google-cloud-storage
Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY app.py .
CMD ["python", "app.py"]
3つのファイルを作成したら、デプロイに進みます。
Cloud Run サービスをデプロイする(通常のメモリ)
まずは、今までの方法である /tmp にファイルを配置する方法のサービスを作っていきます。
/tmp はインメモリのため、1GB のファイルを置けるようメモリを 2GiB に設定します。
gcloud run deploy cr-tmp-test \
--source . \
--region asia-northeast1 \
--execution-environment gen2 \
--memory 2Gi \
--service-account="cr-ephemeral-test-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--set-env-vars "BUCKET_NAME=${GOOGLE_CLOUD_PROJECT}-ephemeral-test,DOWNLOAD_PATH=/tmp/testfile.bin" \
--allow-unauthenticated
Cloud Run サービスをデプロイする(エフェメラルディスク)
次に、エフェメラルディスクをマウントしたサービスも同様にデプロイします。メモリは 512MiB に設定し、1GB のファイルが乗らないサイズに抑えます。
その上で、 --add-volume オプションでエフェメラルディスクを追加し、 --add-volume-mount によってマウント先のパスを指定します。
この2つのパラメータを追加することで、サービスでエフェメラルディスクを使用することができます。
なお、エフェメラルディスクはプロジェクト/リージョンあたり 100GB のクォータがあります。max-instances × ディスクサイズ がクォータを超えないよう、--max-instances を明示的に指定します。今回は 3 インスタンス × 10GiB = 30GiB で収まるよう設定します。
gcloud beta run deploy cr-disk-test \
--source . \
--region asia-northeast1 \
--execution-environment gen2 \
--memory 512Mi \
--min-instances=0 \
--max-instances=3 \
--service-account="cr-ephemeral-test-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--add-volume name=data,type=ephemeral-disk,size=10Gi \
--add-volume-mount volume=data,mount-path=/mnt/data \
--set-env-vars "BUCKET_NAME=${GOOGLE_CLOUD_PROJECT}-ephemeral-test,DOWNLOAD_PATH=/mnt/data/testfile.bin" \
--allow-unauthenticated
2つのサービスのデプロイが完了すると、コンソール上では以下のように確認できます。
ダウンロードを実行してメモリ・ディスクの使用状況を確認する
# /tmp パターン
TMP_URL=$(gcloud run services describe cr-tmp-test --region asia-northeast1 --format='value(status.url)')
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" ${TMP_URL}/download
# エフェメラルディスクパターン
DISK_URL=$(gcloud run services describe cr-disk-test --region asia-northeast1 --format='value(status.url)')
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" ${DISK_URL}/download
リクエストに成功すると、以下のようなレスポンスが返ってきます。ファイルシステムそれぞれで、1GiB のファイルがダウンロードできたことが読み取れます。

メトリクスを確認する
メモリの消費状態をコンソールのメトリクスで確認してみます。
/tmp に配置したパターン
まず従来の方法で、/tmp にファイルを配置したパターンを確認してみます。
コンソール上からは、以下のようなメトリクスが確認できました。ダウンロードが完了したタイミングから、メモリが 約50%(2GB に対する 1GB) 消費されていることがわかります。
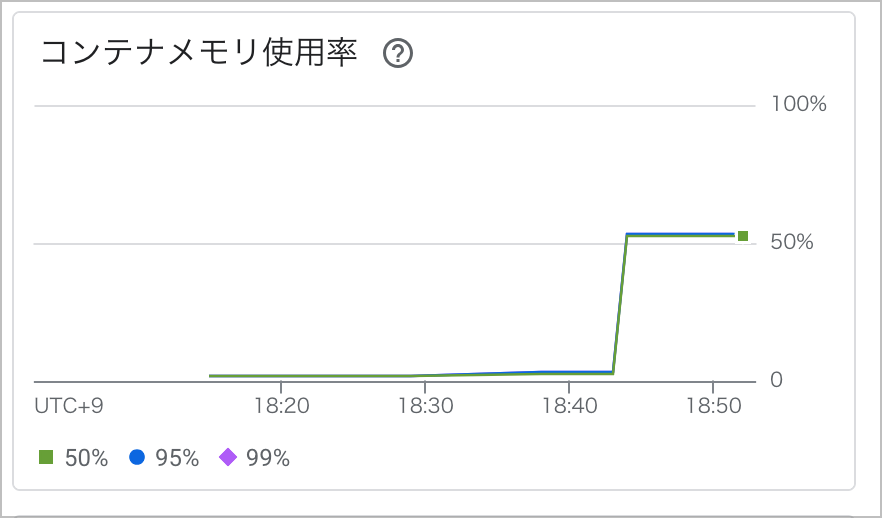
つまり、処理に必要なファイルをコンテナ内にダウンロードする必要がある場合、そのファイルサイズ分のメモリが常に使用される形になります。
エフェメラルディスクのパターン:メモリは消費されず、ディスクに乗る
次に、今回の新機能であるエフェメラルディスクを使ったパターンです。
ダウンロードのタイミングでメモリ使用率は上がっていますが、8% → 9% と 1% の上昇しかありませんでした。
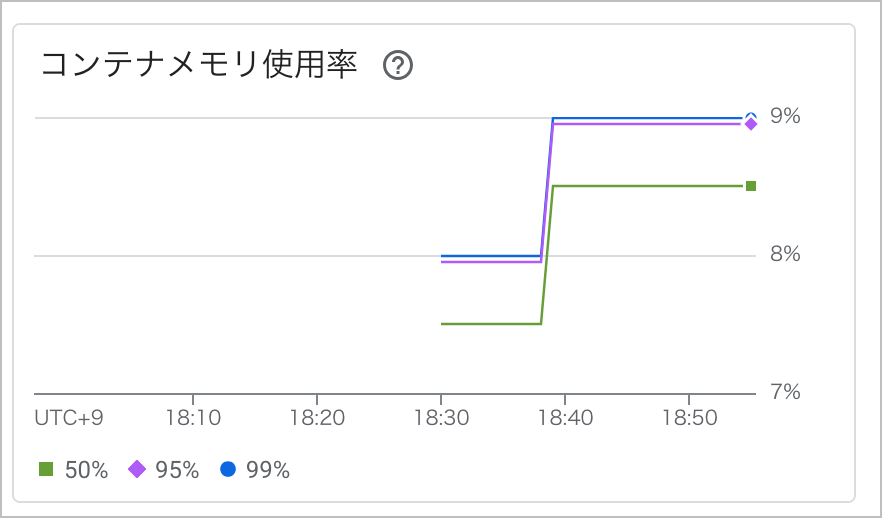
わずかに増えている使用率は、エフェメラルディスクに書き込む前にメモリ上にバッファしたことが理由と考えられます。
この結果から、実際にファイルをダウンロードしてもメモリを消費していないことが確認できました。
エフェメラルディスクのスループットを確認する
エフェメラルディスクのスループットも確認してみます。/benchmark エンドポイントで 512MB のファイルをローカルに書き込み・読み込みし、スループットを計測します。
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" ${DISK_URL}/benchmark
レスポンスとして、以下の結果が返ってきました。
{"directory":"/mnt/data","io_benchmark":{"read_mbps":1749.5,"write_mbps":978.9}}
Write 約 979 MB/s、Read 約 1,750 MB/s という結果になりました。メモリほどではありませんが、一時ストレージとして十分実用的なパフォーマンスが出ているのではないでしょうか。
※メモリとのスループット比較は厳密な比較が難しかったため、今回はディスク側の数値の紹介のみとなります。
まとめ
今回はエフェメラルディスクを実際にマウントして、メモリのケースと比較してみました。
エフェメラルディスクを使うことで、大きなファイルを扱うケースでも割り当てるメモリサイズを抑えることができ、ランニングコストを抑えることができます。
設定自体も非常にシンプルで、追加のパラメータを2つ(--add-volume と --add-volume-mount)設定するだけで、すぐに利用ができる点も嬉しいです。
もちろん、ディスクであるため、スループットはメモリよりは劣ります。ただ、SSD レベルのスループットは確認できており、実際はネットワークのスループットなども影響することが予想されます。そのため、ディスク側のスループットがボトルネックになるケースは限られてくるのではないかと思います。
今後予定されている Cloud Run 上にデプロイしたモデルを Agent Platform で利用するようなユースケースを想定すると、トレーニングジョブを Cloud Run 上で実行するケースも増えてくることが予想されます。大規模なファイルをロードするケースも出てくると思われるので、そういったケースでうまく活用して利用費を抑えていきたいですね。
この記事がどなたかの助けになれば幸いです。以上、すらぼでした!
参考資料










