
Cloud Asset InventoryでGoogle Cloud環境のアセット情報を収集・分析・可視化する
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
Google Cloud環境の組織配下のすべてのリソースを収集、可視化、分析したいと思ったことはありませんか?
Cloud Asset InventoryとBigQueryを利用することでこれを実現することができます。
Cloud Asset Inventoryを利用することで、Google Cloud組織配下の以下のような情報を取得することができます。
- Cloud SQLのインスタンスタイプや、ディスク容量などの各サービスのスペック情報
- サービスアカウントキーの一覧
- 基本ロールを持っているプリンシプルの特定など
また、セキュリティ上リスクになるサービスアカウントキーの発行状況の棚卸や、組織としてコスト最適化をする上で必須な確約利用割引を利用するための事前調査に役立ちます。
Cloud Asset Inventoryとは
Cloud Asset Inventoryは、Google Cloudのメタデータを一元管理するグローバルメタデータインベントリサービスです。Google Cloud環境のアセット情報の表示、検索、エクスポート、モニタリング、分析を可能にし、最大35日間の履歴を保持することができる機能です。
Cloud Asset Inventoryで取得することができるコンテンツタイプの一覧を以下にまとめます。
リソース情報だけではなく、組織ポリシーやOSインベントリなど様々な情報を収集することができます。
| タイプ | 説明 |
|---|---|
| ACCESS_POLICY | Access Context Managerの設定 |
| IAM_POLICY | リソースの権限バインディング |
| ORG_POLICY | 組織ポリシーメタデータ |
| OS_INVENTORY | ランタイムOS情報 (VM Managerの設定が必須) |
| RELATIONSHIP | リソース間の関係(SCC Premium/Enterprise、Gemini Cloud Assistが必要) |
| RESOURCE | リソースメタデータ |
アセット情報をBigQueryへエクスポートする
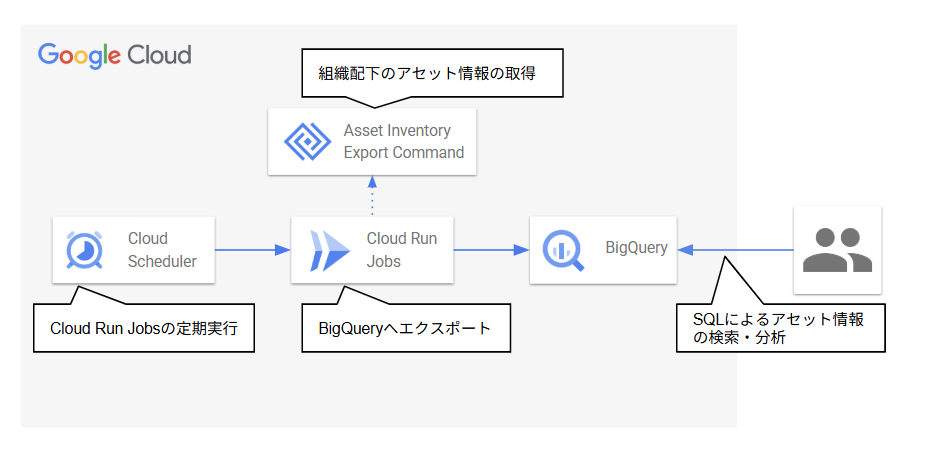
アーキテクチャ
Cloud Schedulerから日時でCloud Run Jobsを定期実行し、Cloud Run JobsでCloud Asset InventoryをBigQueryへエクスポートするコマンドを呼び出して、アセット情報をBigQueryへ収集するアーキテクチャとします。
BigQueryへエクスポートされたアセット情報は、ユーザが検索や分析に利用することができます。
リソースの作成
リソースの作成はTerraformで行いました。
興味のある方は、以下のtfファイルをご確認ください。
terraform
$ tree -l
.
├── bigquery.tf
├── cloud_run_jobs.tf
├── cloud_scheduler.tf
├── enable_api.tf
├── outputs.tf
├── terraform.tfstate
├── terraform.tfstate.backup
├── terraform.tfvars.example
├── variables.tf
└── versions.tf
variable "project_id" {
description = "Google Cloud Project ID"
type = string
}
variable "organization_id" {
description = "Google Cloud Organization ID"
type = string
}
variable "region" {
description = "Google Cloud Region"
type = string
default = "asia-northeast1"
}
variable "dataset_id" {
description = "BigQuery Dataset ID for Asset Inventory"
type = string
default = "asset_inventory"
}
variable "table_id" {
description = "BigQuery Table ID for Asset Inventory"
type = string
default = "resources"
}
variable "dataset_location" {
description = "BigQuery Dataset Location"
type = string
default = "asia-northeast1"
}
variable "schedule" {
description = "Cloud Scheduler cron schedule (default: daily at 9:00 AM JST)"
type = string
default = "0 9 * * *"
}
variable "time_zone" {
description = "Time zone for Cloud Scheduler"
type = string
default = "Asia/Tokyo"
}
terraform {
required_version = ">= 1.13"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
# Enable required APIs
resource "google_project_service" "services" {
for_each = toset([
"cloudasset.googleapis.com",
"bigquery.googleapis.com",
"run.googleapis.com",
"cloudscheduler.googleapis.com",
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
# BigQuery Dataset
resource "google_bigquery_dataset" "asset_inventory" {
dataset_id = var.dataset_id
project = var.project_id
location = var.dataset_location
description = "Dataset for Google Cloud Asset Inventory exports"
labels = {
environment = "production"
managed_by = "terraform"
}
depends_on = [google_project_service.services]
}
# Service Account for Asset Inventory Export
resource "google_service_account" "asset_exporter" {
account_id = "asset-inventory-exporter"
display_name = "Asset Inventory Exporter Service Account"
project = var.project_id
description = "Service account for exporting asset inventory to BigQuery"
}
# Grant Cloud Asset Viewer role at organization level
resource "google_organization_iam_member" "asset_viewer" {
org_id = var.organization_id
role = "roles/cloudasset.viewer"
member = "serviceAccount:${google_service_account.asset_exporter.email}"
}
# Grant BigQuery Data Editor role
resource "google_bigquery_dataset_iam_member" "data_editor" {
dataset_id = google_bigquery_dataset.asset_inventory.dataset_id
role = "roles/bigquery.dataEditor"
member = "serviceAccount:${google_service_account.asset_exporter.email}"
project = var.project_id
}
# Grant BigQuery Job User role
resource "google_project_iam_member" "bigquery_job_user" {
project = var.project_id
role = "roles/bigquery.jobUser"
member = "serviceAccount:${google_service_account.asset_exporter.email}"
}
# Cloud Run Job for Asset Inventory Export
resource "google_cloud_run_v2_job" "asset_exporter" {
name = "asset-inventory-exporter"
location = var.region
project = var.project_id
template {
template {
service_account = google_service_account.asset_exporter.email
containers {
image = "gcr.io/google.com/cloudsdktool/google-cloud-cli:latest"
command = ["/bin/bash"]
args = [
"-c",
<<-EOT
for content_type in resource iam-policy org-policy access-policy os-inventory
do
gcloud asset export \
--organization=${var.organization_id} \
--content-type=$${content_type} \
--bigquery-table=projects/${var.project_id}/datasets/${var.dataset_id}/tables/$${content_type} \
--output-bigquery-force
done
EOT
]
resources {
limits = {
cpu = "1"
memory = "512Mi"
}
}
}
max_retries = 3
timeout = "3600s"
}
}
depends_on = [
google_project_service.services,
google_organization_iam_member.asset_viewer,
google_bigquery_dataset_iam_member.data_editor,
google_project_iam_member.bigquery_job_user
]
lifecycle {
ignore_changes = [
template[0].template[0].containers[0].image
]
}
}
# Cloud Scheduler Job
resource "google_cloud_scheduler_job" "asset_export" {
name = "asset-inventory-export-schedule"
description = "Scheduled job to export asset inventory to BigQuery"
schedule = var.schedule
time_zone = var.time_zone
region = var.region
project = var.project_id
attempt_deadline = "320s"
retry_config {
retry_count = 3
}
http_target {
http_method = "POST"
uri = "https://${var.region}-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/${var.project_id}/jobs/${google_cloud_run_v2_job.asset_exporter.name}:run"
oauth_token {
service_account_email = google_service_account.scheduler.email
}
}
depends_on = [
google_project_service.services,
google_cloud_run_v2_job_iam_member.invoker
]
}
# Service Account for Cloud Scheduler
resource "google_service_account" "scheduler" {
account_id = "asset-export-scheduler"
display_name = "Asset Export Scheduler Service Account"
project = var.project_id
description = "Service account for Cloud Scheduler to invoke Cloud Run Job"
}
# Grant Cloud Run Invoker role to Scheduler Service Account
resource "google_cloud_run_v2_job_iam_member" "invoker" {
project = var.project_id
location = var.region
name = google_cloud_run_v2_job.asset_exporter.name
role = "roles/run.invoker"
member = "serviceAccount:${google_service_account.scheduler.email}"
}
output "bigquery_dataset_id" {
description = "BigQuery Dataset ID"
value = google_bigquery_dataset.asset_inventory.dataset_id
}
output "asset_exporter_service_account_email" {
description = "Service Account email for Asset Exporter"
value = google_service_account.asset_exporter.email
}
output "scheduler_service_account_email" {
description = "Service Account email for Cloud Scheduler"
value = google_service_account.scheduler.email
}
output "cloud_run_job_name" {
description = "Cloud Run Job name"
value = google_cloud_run_v2_job.asset_exporter.name
}
output "cloud_run_job_url" {
description = "Cloud Run Job URL"
value = "https://console.cloud.google.com/run/jobs/details/${var.region}/${google_cloud_run_v2_job.asset_exporter.name}"
}
output "cloud_scheduler_job_name" {
description = "Cloud Scheduler Job name"
value = google_cloud_scheduler_job.asset_export.name
}
output "schedule" {
description = "Cloud Scheduler cron schedule"
value = var.schedule
}
output "next_scheduled_run" {
description = "Information about the schedule"
value = "Check Cloud Scheduler console for next scheduled run time"
}
本アーキテクチャを作成する場合は、以下のAPIを有効化する必要があります。
cloudasset.googleapis.combigquery.googleapis.comrun.googleapis.comcloudscheduler.googleapis.com
今回は、Cloud Asset Inventoryによるエクスポートスコープを組織にしているため、Cloud Run Jobsに付与するサービスアカウントを組織のIAMにroles/cloudasset.viewerのロールを付与して登録する必要があります。

定刻の時間になるとCloud SchedulerからCloud Run Jobsへリクエストが送られ、Cloud Run Jobsが実行されます。
ジョブが正常終了しました。
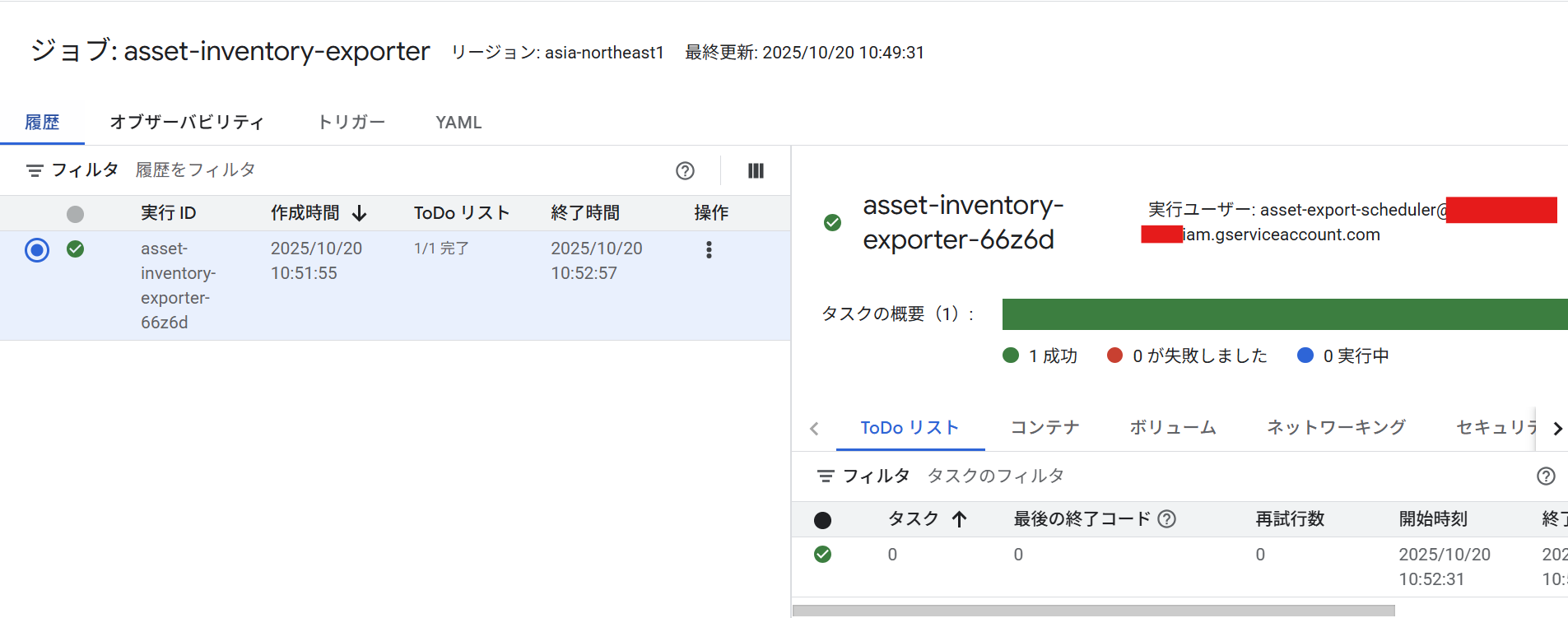
Cloud Run Jobsの実行ログを確認すると、RESOURCE、IAM_POLICY、ORG_POLICY、ACCESS_POLICY、OS_INVENTORYの5つのタイプのBigQueryへのエクスポートが完了していることが確認できます。
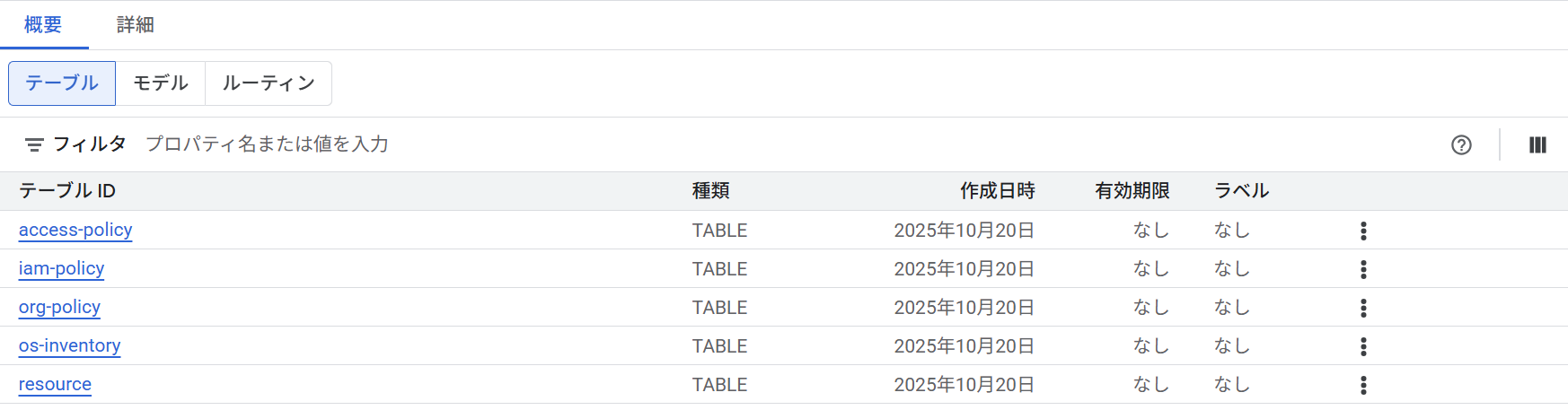
実際に、BigQueryのコンソール画面を確認すると、5つのタイプそれぞれのテーブルが作成されていることが確認できます。
Cloud Asset InventoryのBigQueryエクスポート時にエクスポート先のテーブルがない場合は自動的に作成されます。また、テーブルが既に存在する場合は最新のデータに上書きされます。
BigQueryでアセット情報の検索
Asset Inventoryで組織配下のアセット情報がBigQueryへエクスポートされたので、BigQuery上からSQLを用いてリソースの検索や可視化を行うことができるようになりました。
ここでは4つほど、どのような情報が取得することができるのかSQLを用いて紹介したいと思います。
- 組織配下のすべてのCompute Engineを取得
SELECT
resource.name,
resource.asset_type,
resource.resource.location,
JSON_VALUE(resource.resource.data, '$.machineType') AS machine_type,
JSON_VALUE(resource.resource.data, '$.status') AS status,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', resource.update_time) AS update_time
FROM
`xxxxxxxxxxxxxxx`.`asset_inventory`.`resource` AS resource
WHERE
resource.asset_type = 'compute.googleapis.com/Instance'
ORDER BY
resource.update_time DESC;
組織配下のすべてのCompute Engineの情報を取得することができます。
ここではマシンタイプや、ステータス情報を取得していますが、SQLのクエリを適宜修正することによってほかの情報も取得することができます。
確約利用割引の見積もりや、リソース情報の棚卸に役立ちます。
- 組織配下の基本ロールを持っているプリンシプルを取得
SELECT
DISTINCT member
FROM
`xxxxxxxxxxxxxxx`.`asset_inventory`.`iam-policy` AS t,
UNNEST(t.iam_policy.bindings) AS bindings,
UNNEST(bindings.members) AS member
WHERE
bindings.role IN ('roles/owner',
'roles/editor',
'roles/viewer');
組織配下の基本ロールを持っているプリンシプルを取得することができます。
基本ロールの付与はGoogle Cloudでは推奨されていないため、基本ロールが付与されているプリンシプルを一覧化し、是正対応を促すことに役立ちます。
- 特定プロジェクトのVPCを取得
SELECT
DISTINCT resource.name
FROM
`xxxxxxxxxxxxxxx`.`asset_inventory`.`resource` AS resource
WHERE
resource.asset_type = 'compute.googleapis.com/Network'
AND resource.name LIKE '%projects/xxxxxxxxxxxxxxx%'
ORDER BY
resource.name;
SQLクエリを工夫することで、組織配下だけではなく、特定のプロジェクトのVPCやリソースを洗い出すことも可能です。
- 組織配下のサービスアカウントキーの一覧を取得
SELECT
DISTINCT resource.name,
resource.asset_type,
resource.resource.version,
resource.resource.discovery_document_uri,
resource.resource.discovery_name,
resource.resource.parent,
resource.resource.data,
resource.ancestors,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', resource.update_time) AS update_time
FROM
`xxxxxxxxxxxxxxx`.`asset_inventory`.`resource` AS resource
WHERE
resource.asset_type = 'iam.googleapis.com/ServiceAccountKey'
ORDER BY
update_time DESC;
組織配下のサービスアカウントキーの一覧を取得することができます。
基本的にサービスアカウントキーの作成は推奨されていません(Workload Identityが推奨)が、やむなく作成しなければいけない状況もあると思います。サービスアカウントキーを作成後にそのまま放置されていることがよく発生するので、定期的に棚卸をすることをお勧めします。
最後に
Cloud Asset InventoryとBigQueryを組み合わせることによって、組織配下のアセット情報を検索・分析することができました。
本アーキテクチャを実装することにより、Google Cloud組織配下のガバナンス強化や棚卸、コスト最適化への施策につなげていただければ幸いです。
本アーキテクチャの月額コストはデータ量にもよりますが、ほぼ無料枠の金額範囲になる見積もりです。
- BigQuery Storage: データ量による (最初の10GB無料)
- BigQuery Query: クエリ量による (月1TB無料)
- Cloud Run Job: 実行時間による (月200万リクエスト無料)
- Cloud Scheduler: $0.10/job/月
お手軽ですので、是非実装してみてください。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!









