
데이터전처리에 코드가 필요없다? GUI로 데이터를 가공하는 서비스 Glue DataBrew
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
안녕하세요 연수가 끝나고 2021년부터 DA부에서 일하게 된 송영진입니다.
오늘의 주제는 데이터전처리를 위한 툴인 AWS Glue DataBrew입니다.
많은 분들이 기계학습이나 데이터 분석을 더 좋게 하기 위해서 데이터를 가공하고 또 가공합니다. 저도 딥러닝을 할 때 이 데이터를 쓰면 더 결과가 좋아질까? 더 의미있는 feature를 어떻게 만들까? 하고 원본 데이터를 깎고 또 깎아서 나중에는 데이터 깎는 노인이 되지 않을까 했는데요, 이 데이터를 가공한다는 것이 한 번에 끝난다면 참 좋을텐데 보통 다른 데이터도 써봐야겠다 싶어서 여러번 하는 경우가 많습니다.
그럴 때마다 SQL, pandas 또는 직접 프로그램을 짜서 데이터를 가공하게 되는데요. 중간중간 맞게 데이터를 가공하고 있는건지 확인하기가 번거롭고 귀찮습니다.
그러던 와중에 지난 2020년 11월에 참 재미있는 서비스가 발표되었는데요.
코드 짜는데 시간 쓰지말고 시각적으로 빠르게 데이터 가공 끝내시고 분석이랑 기계학습에 집중해보세요. 라는 컨셉으로 나온 AWS Glue DataBrew가 바로 그 주인공입니다.
AWS Glue DataBrew란?
AWS Glue DataBrew는 사용자가 코드를 작성하지 않고도 데이터를 정리하고 정규화 할 수있는 시각적 데이터 준비 도구입니다. DataBrew를 사용하면 분석 및 기계 학습 (ML)을 위해 데이터를 준비하는 데 걸리는 시간을 맞춤 개발 된 데이터 준비에 비해 최대 80%까지 줄일 수 있습니다. 250개 이상의 준비된 데이터 변환 중에서 필요한 기능을 선택하여 이상 항목 필터링, 데이터를 표준 형식으로 변환, 잘못된 값 수정과 같은 데이터 전처리 작업을 자동화 할 수 있습니다.
DataBrew를 사용하면 비즈니스 분석가, 데이터 과학자 및 데이터 엔지니어가보다 쉽게 협업하여 원시 데이터에서 통찰력을 얻을 수 있습니다. DataBrew는 서버리스이므로 기술 수준에 관계없이 클러스터를 생성하거나 인프라를 관리 할 필요없이 테라 바이트의 원시 데이터를 탐색하고 변환 할 수 있습니다.
직관적인 DataBrew 인터페이스를 사용하면 원시데이터를 바로 검색, 시각화, 정리 및 변환 할 수 있습니다. DataBrew는 찾기 어렵고 수정하는 데 시간이 많이 걸리는 데이터 품질 문제를 식별하는 부분에서 이런 방식이 좋겠다고 제안을 합니다. DataBrew를 사용하여 데이터를 전처리하면 결과에 따라 조치를 취하고 더 빠르게 반복 하는 데 시간을 사용 할 수 있습니다. 변환을 레시피의 단계로 저장하여 나중에 다른 데이터 세트로 업데이트하거나 재사용하고 지속적으로 배포 할 수 있습니다.
다음은 DataBrew의 흐름을 보여주는 공식 문서의 그림입니다.
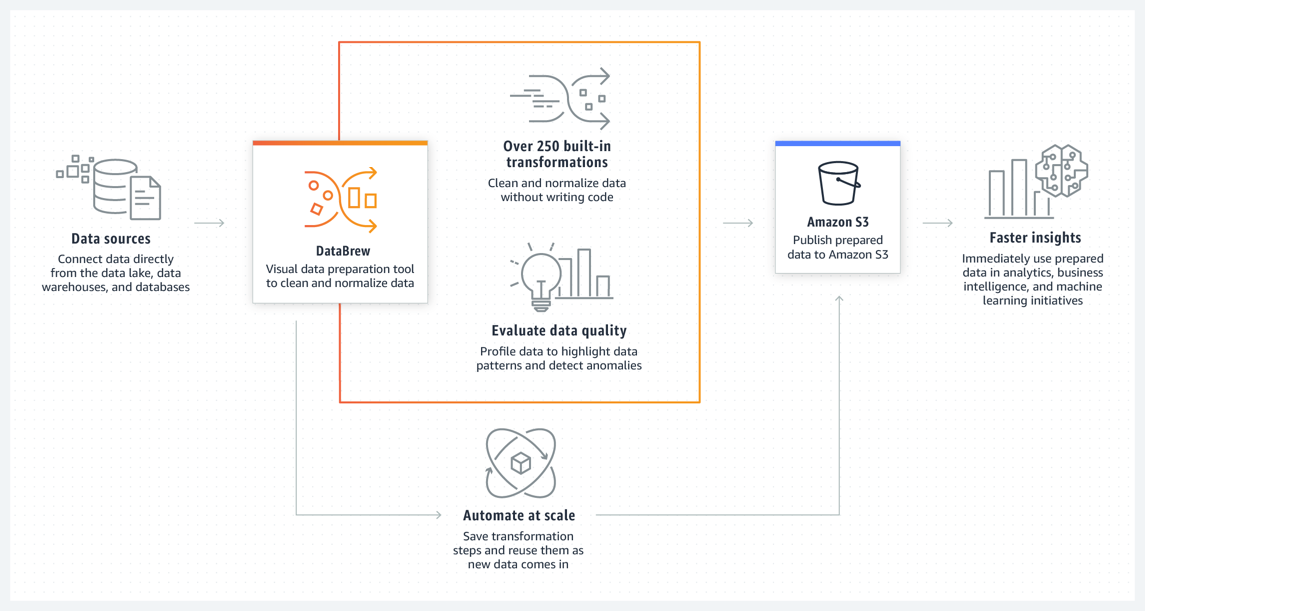
DataBrew를 사용하려면 프로젝트를 만들고 데이터를 연결해야합니다. 프로젝트 작업 공간에서 데이터가 그리드와 같은 시각적 인터페이스로 표시되는 것을 볼 수 있습니다. 여기에서 데이터를 탐색하고 값 분포 및 차트를보고 해당 프로필을 이해할 수 있습니다.
데이터를 준비하기 위해 250 개 이상의 포인트 앤 클릭 변환 중에서 선택할 수 있습니다. 여기에는 null 제거, 누락 된 값 바꾸기, 스키마 불일치 수정, 함수 기반 열 만들기 등이 포함됩니다. 변환을 사용하여 자연어 처리 (NLP) 기술을 적용하여 문장을 구문으로 분할 할 수도 있습니다. 즉시 미리보기에는 변환 전후의 데이터 일부가 표시되므로 전체 데이터 세트에 적용하기 전에 레시피를 수정할 수 있습니다.
DataBrew가 데이터 세트에서 레시피를 실행하면 출력이 Amazon Simple Storage Service (Amazon S3)에 저장됩니다. 정리되고 준비된 데이터 세트가 Amazon S3에 있으면 다른 데이터 스토리지 또는 데이터 관리 시스템에서 데이터를 수집 할 수 있습니다.
현재 DataBrew를 사용할 수 있는 리전은 다음과 같습니다.
- 미국 동부 (버지니아 북부)
- 미국 동부 (오하이오)
- 미국 서부 (오레곤)
- 유럽 (아일랜드)
- 유럽 (프랑크푸르트)
- 아시아 태평양 (도쿄)
- 아시아 태평양 (시드니)
아쉽게도 서울에는 릴리스 되지 않았지만 가까운 도쿄의 리전에서 사용 가능합니다.
데이터 변환
![]()
이렇게 보기 쉬운 UI에서 필요한 기능이 있는 탭을 클릭하여 찾아서 사용하게 됩니다. 레시피의 데이터 변환의 카테고리는 다음과 같습니다.
작업의 흐름
- S3 또는 Glue 데이터 카탈로그 (S3, Redshift, RDS)에서 하나 이상의 데이터 세트를 연결합니다. DataBrew 콘솔에서 S3에 로컬 파일을 업로드 할 수도 있습니다 . CSV, JSON, Parquet 및 .XLSX 형식이 지원됩니다.
- 데이터 세트의 데이터를 시각적으로 탐색, 이해, 결합, 정리 및 정규화 하는 프로젝트를 만듭니다. 여러 데이터 세트를 병합하거나 결합 할 수 있습니다. 콘솔에서 값 분포, 히스토그램, 상자 그림 및 기타 시각화를 사용하여 데이터의 문제를 빠르게 찾을 수 있습니다.
- 프로필 보기 에서 작업을 실행하여 40 개 이상의 통계로 데이터 세트에 대한 풍부한 데이터 프로필을 생성합니다.
- 열(column)을 선택 하면 데이터 품질을 개선하는 방법에 대한 권장 사항이 제공됩니다.
- 250 개 이상의 기본 제공 변환을 사용하여 데이터를 정리하고 정규화 할 수 있습니다 . 예를 들어 null 값을 제거 또는 교체하거나 인코딩을 만들 수 있습니다. 각 변환은 레시피를 작성하는 단계로 자동 추가됩니다.
- 그런 다음 레시피를 저장, 게시 및 버전 지정하고 모든 수신 데이터에 레시피를 적용하여 데이터 준비 작업을 자동화 할 수 있습니다. 대규모 데이터 세트에 레시피를 적용하거나 프로필을 생성하려면 작업을 실행할 수 있습니다.
- 언제든지 데이터 세트가 프로젝트, 레시피, 작업 실행에 연결되는 방식을 시각적으로 추적하고 탐색 할 수 있습니다. 이러한 방식으로 데이터 흐름 방식과 변경 사항을 이해할 수 있습니다. 이 정보를 데이터 연계라고 하며 출력에 오류가있는 경우 근본 원인을 찾는 데 도움이 될 수 있습니다.
위는 AWS 공식 블로그의 내용인데요 글만 봐서는 감이 잘 안오죠? 어떻게 기능이 이루어지는지 직접 해봤습니다.
직접 해봤습니다

프로젝트를 생성해줘야 합니다. databrew-test라는 이름으로 만들었는데요. 아래의 레시피의 이름도 자동으로 작성이 됩니다.
데이터를 선택하고 롤도 선택해주셔야 합니다. 데이터는 이전에 DA부 연수에 사용했던 JSON 데이터의 일부를 사용하였고 롤은 신규로 작성하였습니다.
데이터는 태그마다 블로그가 얼마나 썼는지를 분석하기 위한 데이터입니다.

잠시 기다리면 이러한 콘솔창으로 로드가 됩니다. 데이터가 많으면 자동으로 일부만 샘플링되게 되는데 제 데이터는 큰 구조의 JSON이라서 1개의 row로만 이루어져있네요.
이 데이터는 블로그 developers.io의 RSS 피드를 JSON으로 변환한 데이터입니다. 중요한 데이터는 entries 라는 배열 속에 있는 중첩된 구조의 JSON 데이터라서 변환이 필요합니다.
열의 이름 앞에 타입을 나타내주는 아이콘이 있어서 어떤 타입인지도 알기가 쉽죠 #는 숫자, ABC는 문자, [ ]는 배열, {s}는 구조체 타입이 됩니다.

이 뭉쳐있는 타입을 UNNEST 기능을 사용하여 풀어보겠습니다.

entries라는 이름의 배열 타입의 1개의 행(row)을 entry라는 타입의 여러 행으로 나눠주게 됩니다.

여러 개의 행으로 나뉘었지만 아직도 스트럭트 형태의 여러 데이터가 남아있습니다 마저 UNNEST 해보겠습니다.

entry 1개의 구조체 안에 여러 데이터가 모여있었는데 entry_column의 형태로 데이터가 나뉘어지게 됩니다.
분석에 필요한 열만 남겨보겠습니다.

저희가 필요한건 어떤 태그의 블로그가 쓰였는지 입니다. 그래서 각각의 태그를 얻기 위해 entry_tags 열을 분해하고 필요없는 label, scheme 열은 지우겠습니다.

이렇게 간단한 방법으로 필요한 데이터를 얻게 되었습니다.
여기서 끝나는게 아니라 그룹 기능을 이용하면 여기서 분석을 끝낼 결과까지 만들어 낼 수 있었습니다.

Group by의 집계함수를 지원하기 때문에 이 데이터에서 태그마다 블로그가 몇 개 쓰여졌는지까지 작성이 가능했습니다.
이 결과를 새 테이블로 만드는 작업에 미리보기까지 지원하니 굉장히 빠르고 직관적으로 결과를 예상 할 수 있어서 이 부분이 너무 좋았습니다.

결과로 만들어지는 테이블의 샘플입니다. RSS 피드가 아마 그 시간 기준 최신 30개의 블로그를 집어오는 것으로 기억합니다. 그 30개 중에서 19개가 AWS에 관한 블로그였다! 라는 결과를 보실 수 있습니다.

이렇게 데이터를 변환하는 과정은 레시피에 순서대로 저장이 됩니다. 레시피에 저장된 작업들은 취소하거나 수정도 가능합니다 중간 과정을 바꿀 수도 있습니다. 실수 할 수도 있으니 롤백은 꼭 필요한 기능이죠.
이 레시피대로 잡을 만들어서 실행시키게 되면 결과로 나오는 데이터는 S3에 저장이 됩니다.
레시피를 YAML이나 JSON으로 만들어서 다른 곳에서 재사용하는 방법도 있습니다. 모든 데이터마다 이렇게 할 필요없이 같은 형식 데이터라면 한 번만 레시피를 만들어둔다면 계속 재활용해서 자동화까지 가능하게 됩니다.
끝으로
이렇게 DataBrew 기능의 일부를 제 데이터를 가지고 직접 사용해봤는데요. 마치 엑셀을 다루는 것처럼 생각보다 훨씬 편했습니다. 저 레시피에 있는 과정은 제가 연수 받는동안 Redshift Spectrum을 이용해서 로드한 다음에 JSON을 다루는 쿼리로 했던 과정인데요 이 서비스가 좀 더 일찍 나왔었다면 이걸 이용하는 방법을 찾았을지도 모르겠네요 ㅋㅋㅋㅋ
제가 사용한 기능은 극히 일부며 데이터마다 필요한 기능은 각각 달라지기 때문에 다른 다양한 기능도 꼭 이용할 기회가 있었으면 좋겠습니다.
이와 비슷한 기능이 이번 Re:Invent에서도 발표되었죠? 바로 Amazon SageMaker Data Wrangler입니다. 이 Data Wrangler는 Glue Databrew와 다르게 직접 파이썬 코드가 작성이 되어서 그 코드를 변형하여 재사용이 가능하게 되는데요. 다음 번엔 이 서비스에 관해서 블로그를 써보는 것을 목표로 하면서 열심히 해보겠습니다!











