
【Iceberg】S3汎用バケットとS3 TablesにおけるIcebergパーティション追加設定の違い
はじめに
データ事業本部の川中子(かわなご)です。
今回はAWSのS3やS3 Tables上で利用できるIceberg形式のテーブルについて、
パーティションの設定方法や稼働するサービスによる違いについて調べてみました。
具体的な検証の観点としては主に以下2点になります。
- テーブル作成後、追加でパーティションを設定できるか
- 汎用バケットとS3 Tablesによる違いはあるのか
準備
検証に必要なテーブルを準備しておきます。
まずはS3の汎用バケット上にiceberg形式のテーブルを作成しておきます。
汎用バケットが英語だとGeneral purpose bucketsだったので、_gpをテーブル名に含めました。
string_columnとtimestamp_columnをパーティションに使用して、
timestamp_columnについては関数を利用して年の部分で階層を分ける仕様になります。
-- 汎用バケット上のiceberg
CREATE TABLE tbl_iceberg_gp (
string_column string,
int_column int,
boolean_column boolean,
timestamp_column timestamp
)
PARTITIONED BY (string_column, year(timestamp_column))
LOCATION 's3://{バケット}/partition_test/iceberg_table/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet',
'write_compression'='snappy'
);
同じスキーマでS3 Tablesの方にもテーブルを作成しておきます。
こちらは末尾に_s3tablesを付けました。
-- s3tables(ネームスペースは省略)
CREATE TABLE tbl_iceberg_s3tables (
string_column string,
int_column int,
boolean_column boolean,
timestamp_column timestamp
)
PARTITIONED BY (string_column, year(timestamp_column))
TBLPROPERTIES (
'table_type'='iceberg',
'write_compression'='zstd'
);
検証
パーティションが反映されるか確認
汎用バケット
汎用バケット上のテーブルに10行分のデータを入れてみます。
-- 汎用バケットの方のIcebergテーブルにデータをINSERT
INSERT INTO tbl_iceberg_gp (string_column, int_column, boolean_column, timestamp_column)
VALUES
('apple', 42, TRUE, TIMESTAMP '2024-01-15 08:30:45'),
('banana', 123, FALSE, TIMESTAMP '2024-02-22 14:25:10'),
('orange', 789, TRUE, TIMESTAMP '2024-03-05 19:12:33'),
('apple', 42, FALSE, TIMESTAMP '2025-01-10 11:45:22'),
('banana', 123, TRUE, TIMESTAMP '2025-02-18 09:30:15'),
('orange', 789, FALSE, TIMESTAMP '2025-03-27 16:20:40'),
('apple', 789, TRUE, TIMESTAMP '2024-01-30 13:15:55'),
('banana', 42, FALSE, TIMESTAMP '2024-02-05 10:05:30'),
('orange', 123, TRUE, TIMESTAMP '2024-03-18 21:40:12'),
('banana', 789, FALSE, TIMESTAMP '2025-01-25 17:35:28');
-- テーブルを確認
select * from "tbl_iceberg_gp" order by timestamp_column;
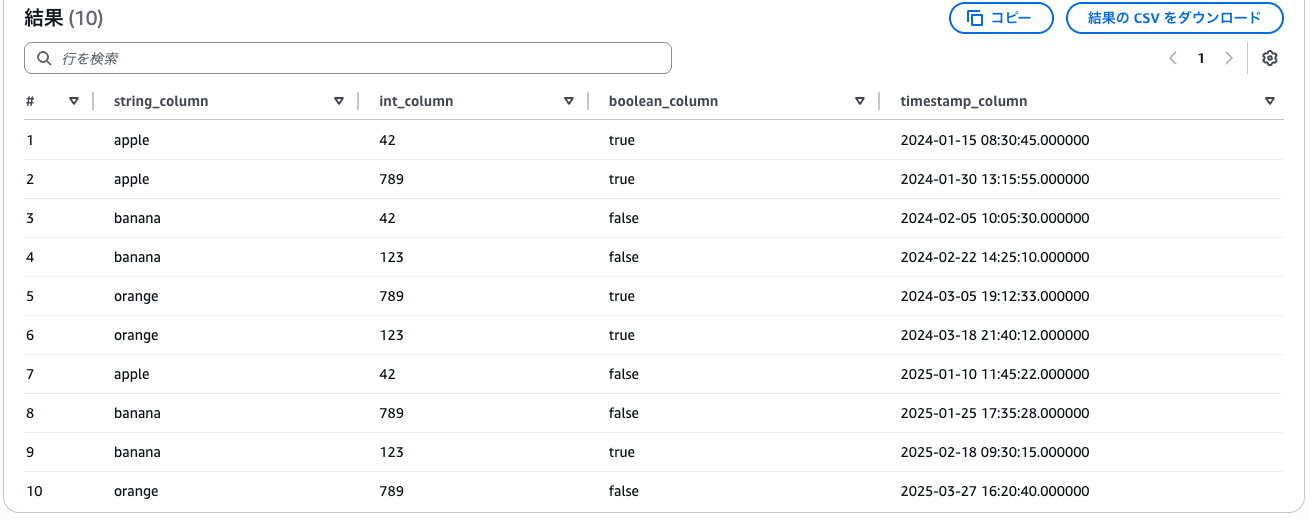
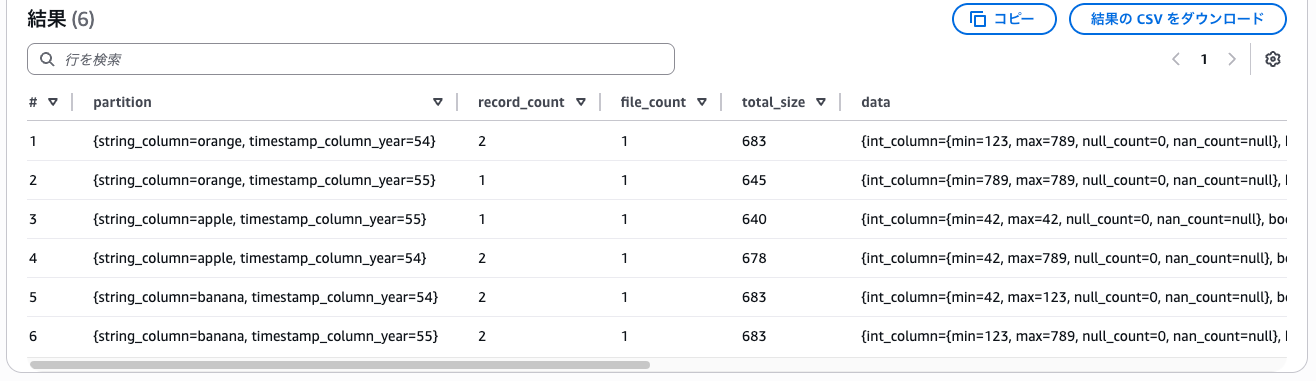
パーティションの情報を見ると、想定通りデータが分配されていることが分かります。
-- パーティションを表示
select * from "tbl_iceberg_gp$partitions";
s3tables
汎用バケットと同様に、S3 Tables上のテーブルに10行分のデータを入れてみます。
-- s3tablesの方のIcebergテーブルにデータをINSERT
INSERT INTO tbl_iceberg_s3tables (string_column, int_column, boolean_column, timestamp_column)
VALUES
('apple', 42, TRUE, TIMESTAMP '2024-01-15 08:30:45'),
('banana', 123, FALSE, TIMESTAMP '2024-02-22 14:25:10'),
('orange', 789, TRUE, TIMESTAMP '2024-03-05 19:12:33'),
('apple', 42, FALSE, TIMESTAMP '2025-01-10 11:45:22'),
('banana', 123, TRUE, TIMESTAMP '2025-02-18 09:30:15'),
('orange', 789, FALSE, TIMESTAMP '2025-03-27 16:20:40'),
('apple', 789, TRUE, TIMESTAMP '2024-01-30 13:15:55'),
('banana', 42, FALSE, TIMESTAMP '2024-02-05 10:05:30'),
('orange', 123, TRUE, TIMESTAMP '2024-03-18 21:40:12'),
('banana', 789, FALSE, TIMESTAMP '2025-01-25 17:35:28');
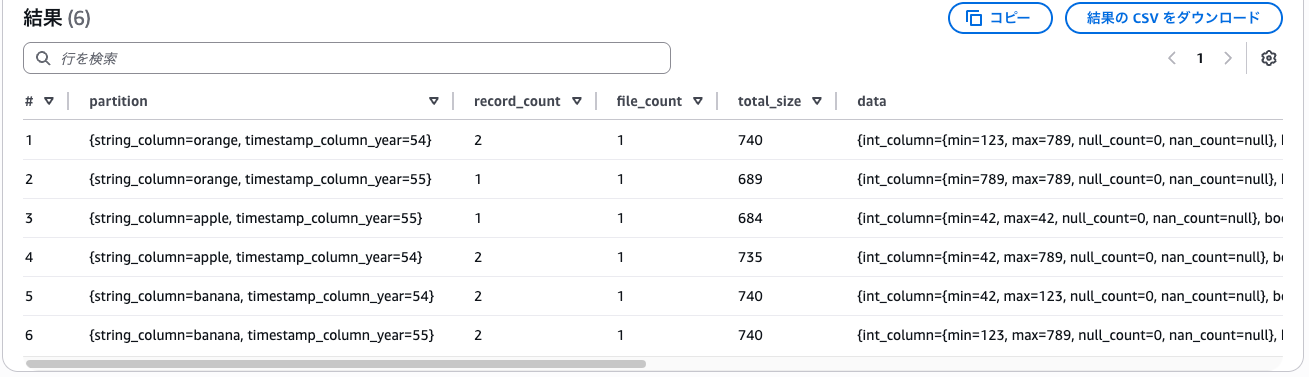
こちらも汎用バケットと同じように、データが分配されていました。
-- パーティションを表示
select * from "tbl_iceberg_s3tables$partitions";
パーティションの追加ができるか確認:Athena
先程も同じリンクを掲載していましたが、どうやら以下のリンクによると、
AthenaではALTER TABLE [] ADD PARTITIONはサポートされていないそうです。
実際にAthenaでALTER TABLE [] ADD PARTITIONを実行すると、やはりエラーになりました。
-- パーティション追加
ALTER TABLE tbl_iceberg_gp ADD PARTITION FIELD boolean_column;
-- 出力
line 1:34: mismatched input 'PARTITION'. Expecting: '.', 'ADD'
ただApache IcebergのドキュメントにはALTER TABLE [] ADD PARTITIONの記載がありました。
またAWSによるQAの記事には、sparkからであれば実行が可能との記載がありました。
パーティションの追加ができるか:spark
sparkからパーティションの追加操作ができるかを確かめるために、
Glueのノートブックからsparkを使って実際に試してみました。
boolean_columnをパーティションに追加するクエリを実行すると、
パーティションのPart 2に追加されたことが確認できました。
spark.sql(f"DESCRIBE TABLE glue_catalog.{database}.{table}").show()
+----------------+--------------------+-------+
| col_name| data_type|comment|
+----------------+--------------------+-------+
| string_column| string| NULL|
| int_column| int| NULL|
| boolean_column| boolean| NULL|
|timestamp_column| timestamp_ntz| NULL|
| | | |
| # Partitioning| | |
| Part 0| string_column| |
| Part 1|years(timestamp_c...| |
+----------------+--------------------+-------+
spark.sql(f"ALTER TABLE glue_catalog.{database}.{table} ADD PARTITION FIELD boolean_column")
spark.sql(f"DESCRIBE TABLE glue_catalog.{database}.{table}").show()
+----------------+--------------------+-------+
| col_name| data_type|comment|
+----------------+--------------------+-------+
| string_column| string| NULL|
| int_column| int| NULL|
| boolean_column| boolean| NULL|
|timestamp_column| timestamp_ntz| NULL|
| | | |
| # Partitioning| | |
| Part 0| string_column| |
| Part 1|years(timestamp_c...| |
| Part 2| boolean_column| |
+----------------+--------------------+-------+
上記は汎用バケット上のIcebergテーブルに対して実行したものですが、
基本的にはS3 Tablesでも同じ挙動であったため省略しています。
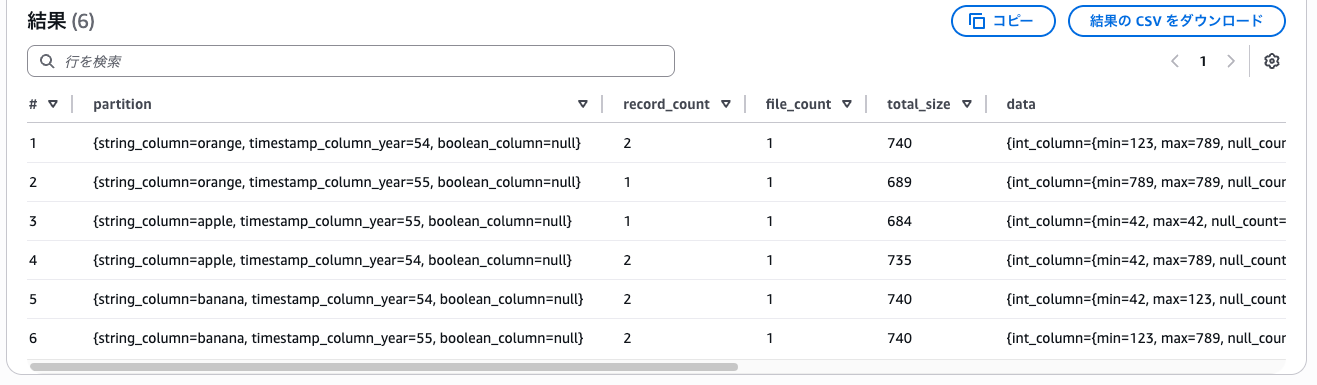
パーティション追加後の状態を確認
Glueからパーティションを追加した後のデータ分配状況を見てみると、
boolean_column=nullになっているので、既存データの振り分けは実行されないようです。
-- パーティションを確認
select * from "tbl_iceberg_s3tables$partitions";
ここで新たに5行分のデータをINSERTしてみます。
-- 追加でINSERT
INSERT INTO tbl_iceberg_s3tables (string_column, int_column, boolean_column, timestamp_column)
VALUES
('apple', 42, TRUE, TIMESTAMP '2024-01-15 08:30:45'),
('banana', 123, FALSE, TIMESTAMP '2024-02-22 14:25:10'),
('orange', 789, TRUE, TIMESTAMP '2024-03-05 19:12:33'),
('grape', 456, FALSE, TIMESTAMP '2024-04-10 11:45:22'),
('cherry', 321, TRUE, TIMESTAMP '2024-05-18 09:30:15');
パーティション追加前からある既存データの再振り分けは実行されず、
新しくINSERTされたデータだけ、新しいパーティションに分配されました。

なおこれらの事象についても、汎用バケットとS3 Tablesにおいて差はありませんでした。
CTASでパーティションを追加する
上記項目で検証したように、既存のテーブルに対してパーティションを追加すると、
既存データの振り分けはされず、一貫性のない状態でデータが保存されることになります。
パーティションを後から追加したい場合には、データやスキーマを引き継ぎつつ、
新たなテーブルとして作成し直すCREATE TABLE ASを使うのが無難な選択になりそうです。
汎用バケット上のテーブルをソースとして、新たに汎用バケット上のテーブル作ります。
パーティションはboolean_columnを含む3つで作成しました。
-- 汎用バケット上のIcebergテーブル
CREATE TABLE tbl_iceberg_gp_ctas
WITH (
format = 'parquet',
location = 's3://{バケット}/partition_test/iceberg_ctas/',
table_type = 'ICEBERG',
is_external = false,
write_compression = 'snappy',
partitioning = ARRAY['string_column', 'year(timestamp_column)', 'boolean_column']
) AS
SELECT * FROM tbl_iceberg_gp;
こちらの方法では想定通りboolean_columnも想定通りパーティショニングされました。
-- パーティションを確認
select * from "tbl_iceberg_gp_ctas$partitions";
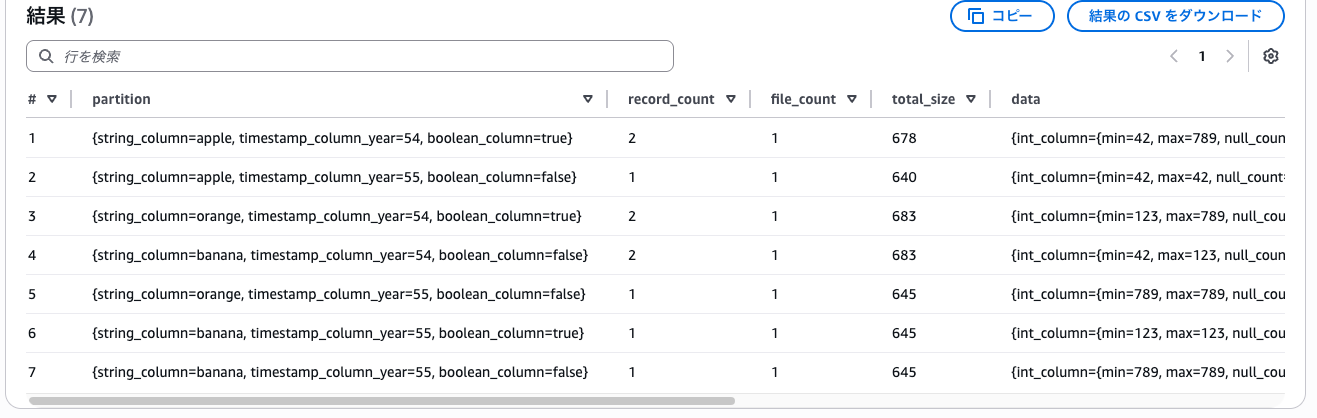
しかしs3tablesの方ではCTAS文はサポートされておらず、この方法は利用できませんでした。
- s3tablesカタログ上のテーブル
CREATE TABLE tbl_iceberg_s3tables_ctas
WITH (
table_type = 'iceberg',
is_external = false,
write_compression = 'zstd',
partitioning = ARRAY['string_column', 'year(timestamp_column)', 'boolean_column']
) AS
SELECT * FROM tbl_iceberg_s3tables;
-- 出力
Queries of this type: CREATE_TABLE_AS_SELECT, are not supported for this catalog
さいごに
本検証から以下のことが分かりました。
- 汎用バケット / S3 Tablesどちらにおいてもパーティション機能は同様に使える
- パーティションの追加はsparkを使えば実行できる
- しかし既存データに対するパーティションの再振り分けは実行されない
- 汎用バケット上のIcebergテーブルであればCTAS文で再作成が望ましい
- S3 TablesのカタログについてはCTAS文をサポートしていない
今回はテーブル作成後のパーティションの追加方法と、
汎用バケットとS3 Tablesにおけるパーティション設定の差について調べてみました。
Iceberg形式のテーブルはパーティションの明示的な操作が不要な分、
テーブル作成時にしっかりパーティション戦略を考えておくことが重要になりそうです。
以上、記事を最後までご閲覧いただきありがとうございました。
少しでも誰かの参考になれば幸いです。








