
【Informatica】BigQueryをターゲットとしたCDCをDatabase Ingestion and Replicationで実装してみる
データ事業本部の川中子(かわなご)です。
最近お菓子作りにハマっていて、先日はプリンを作ってみました。
カラメルの火加減やプリン液への火の入れ方がとても難しかったのですが、
なんとか思い描いていた固めで美味しいプリンを作ることができました。
その時に学んだプリン作りのポイントは以下でした。
- C:Caramel(カラメルは焦がしすぎず)
- D:Delicate(デリケートな火加減で蒸して)
- C:Cool(クールダウン=しっかり冷やすのが大事)
しっかり冷やすことでしっかりしたプリンの食感も出ると思います。
この3つのポイントをまとめてCDCと略すことにしました。
ということで今回は、Informaticaを利用したCDCのデータ連携を検証します。
以前Database Ingestion and Replication(以降DIR)を利用して、
S3にテーブルの情報を継続的に出力する検証を行いましたが、
今回はそのターゲットをBigQueryに変更した場合の検証となります。
DIRを利用すれば、ソースのテーブルが大量にあったとしても、
1つのジョブで一気にターゲットへロードすることができるので非常に強力です。
今回利用するソースデータについて
今回はPostgreSQLをソースデータとして検証を行っています。
PostgreSQLをDIRジョブのソースとする場合の事前設定や、
そもそものDIRのサービスの紹介についてはこちらのブログで説明しています。
今回のブログ内では、過去ブログで説明している内容は割愛しているため、
もし必要があれば併せて上記のブログをご参照いただければ幸いです。
事前準備
まずは公式のドキュメントに沿って、BigQueryをターゲットとする場合の準備を行います。
JDBCドライバーの配置
まずBigQuery用のJDBCドライバーをSecure Agentサーバーに配置します。
ドライバーは以下のリンクからダウンロードできます。
最新のバージョンもありましたが、私はドキュメント通りのバージョンを利用しました。
ダウンロードしたzipから必要なファイルのみを所定のディレクトリに配置します。
今回必要なのはGoogleBigQueryJDBC42.jarのみです。
> pwd
/home/infa/infaagent/apps/Database_Ingestion/ext
> ls | grep BigQuery
GoogleBigQueryJDBC42.jar
配置後はSecure Agentを再起動しておきます。
# サービス停止
> ./infaagent.sh shutdown
# サービス開始
> ./infaagent.sh startup
Google Cloud側の設定
コネクタに使用するサービスアカウントを作成し、必要な権限を付与します。
公式ドキュメントに記載のある権限一覧は以下の通りです。
bigquery.datasets.getbigquery.jobs.createbigquery.models.createbigquery.models.deletebigquery.models.exportbigquery.models.getDatabigquery.models.getMetadatabigquery.models.listbigquery.models.updateDatabigquery.models.updateMetadatabigquery.routines.createbigquery.routines.deletebigquery.routines.getbigquery.routines.listbigquery.routines.updatebigquery.routines.updateTagbigquery.tables.createbigquery.tables.deletebigquery.tables.deleteIndexbigquery.tables.deleteSnapshotbigquery.tables.exportbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updatebigquery.tables.updateDatabigquery.tables.updateTagresourcemanager.projects.getstorage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
権限が不足している場合、ジョブにおけるファイル操作の実行時や、
プロジェクトのメタデータ取得を試みる際などにエラーになりました。
コネクタの作成
Informatica側でBigQueryコネクタを作成し、接続テストを行います。
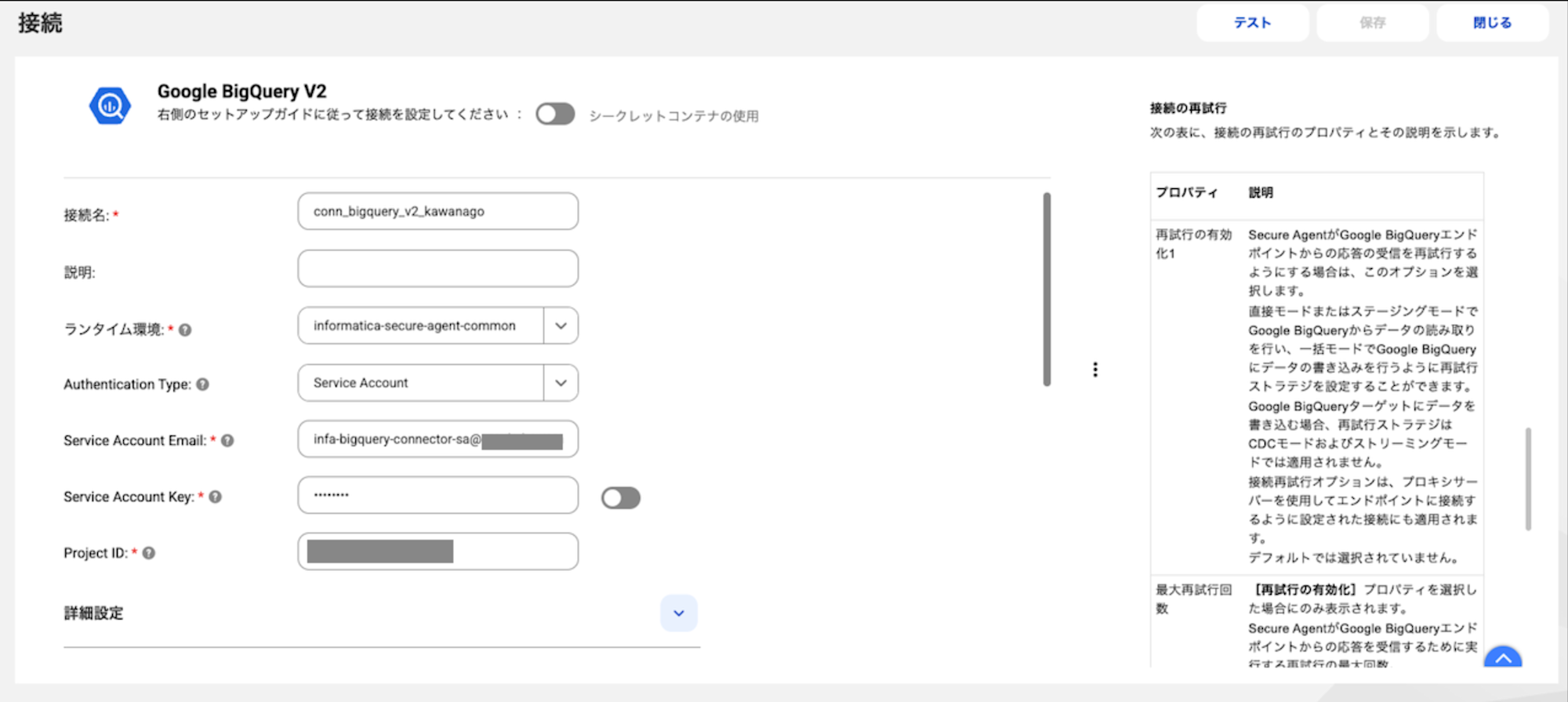
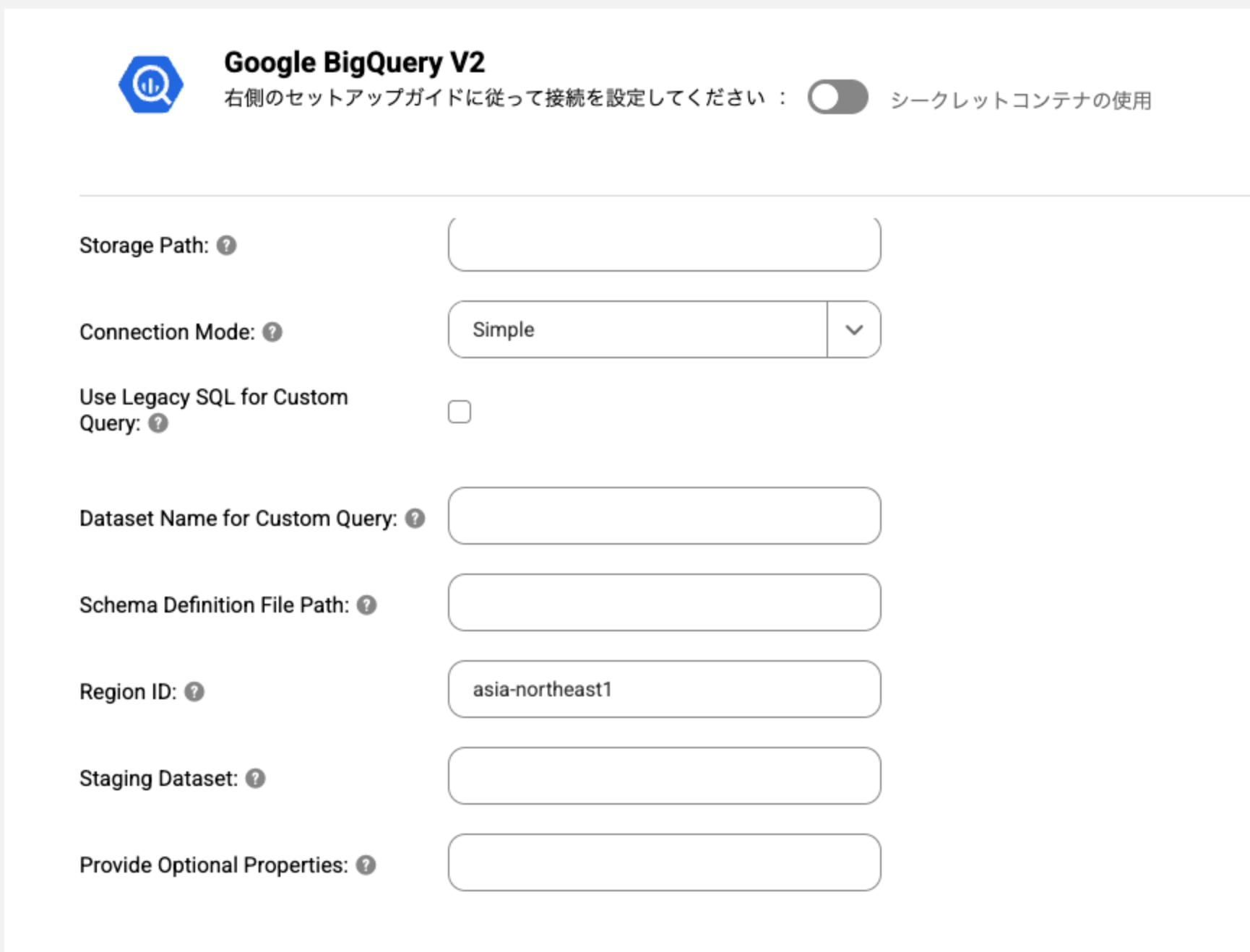
最初の検証時にRegion IDを設定せずにテストしたらエラーになったのですが、
データセットが存在するasia-northeast1を設定したら疎通ができました。
ジョブ作成
ここからはDIRジョブを作成していきます。
BigQueryをターゲットとする場合の詳細は以下のドキュメントで説明されています。
ソース設定
今回はPostgreSQLをソースとして使用していますが、
前述の通りこの部分の詳細については割愛させていただきます。
なお検証を簡略化するため、絞り込みを使ってソーステーブルは1つだけにしています。
ソース設定の画面上でCDCスクリプトの実行を忘れてしまうと、
カラムの追加などのスキーマ変更が反映されないので注意してください。
(一回この実行を忘れて泥沼にハマりかけました)
ターゲット設定
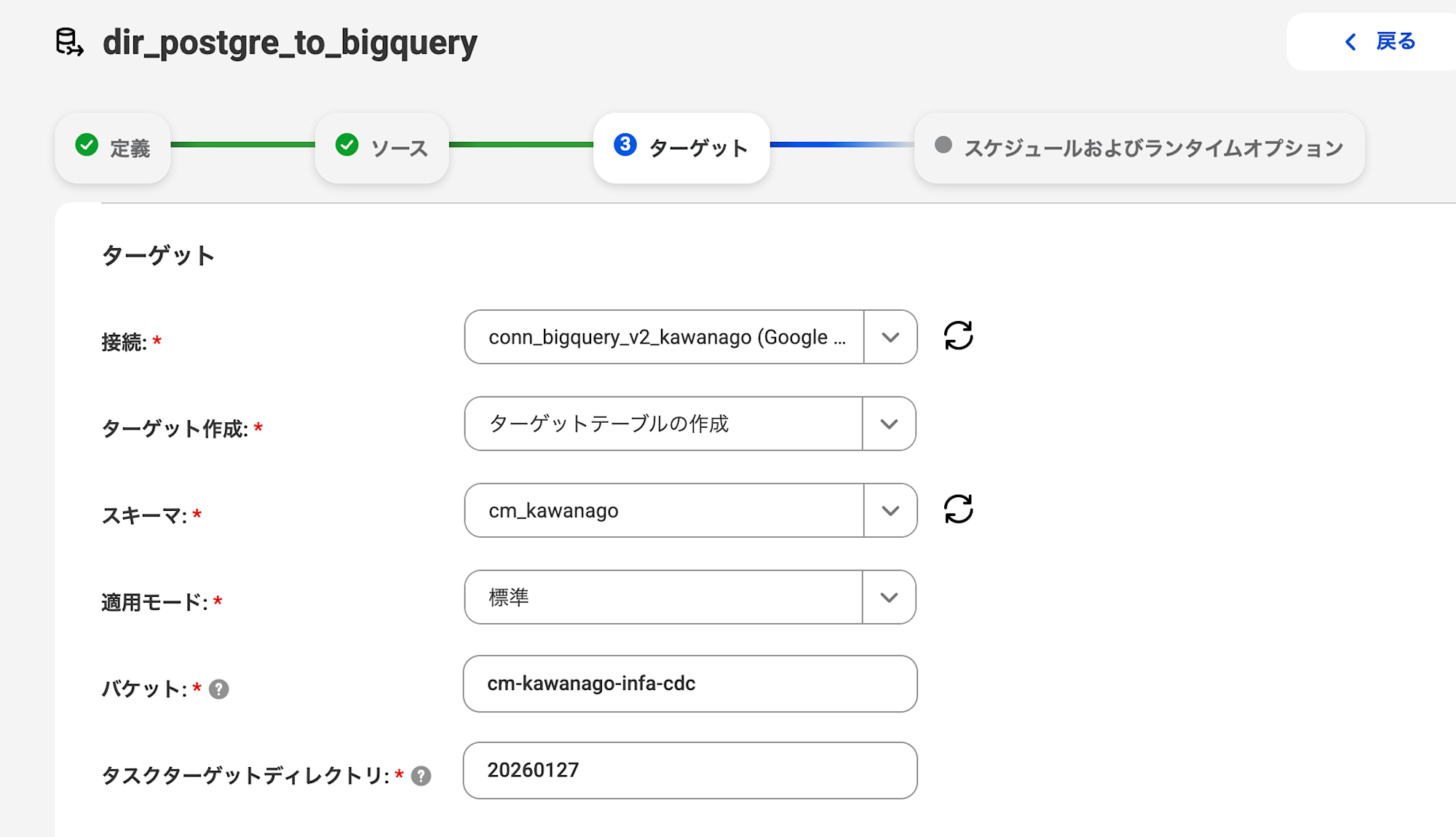
ターゲットの設定は基本的にデフォルトの状態で進めますが、
以下の設定必須の項目についてのみ情報を記載しました。
- 接続:事前に作成したBigQueryコネクタ
- スキーマ:ターゲットのデータセット名
- 適用モード:標準(ソーステーブルの最新状態を反映)
- バケット:ステージングデータを置くGCSバケット名
- タスクターゲットディレクトリ:バケット内のプレフィックス
適用モードには3種類あり、それぞれ以下のような仕様になっています。
- 標準:テーブルの最新状態を反映する
- 監査:ソースの変更履歴を全て反映する
- ソフト削除:データ削除の際に論理削除を実行する
スキーマドリフトの設定
スキーマドリフト(カラムの追加・削除)への対応を設定します。
カラムの追加と削除についてはレプリケートを選択しました。
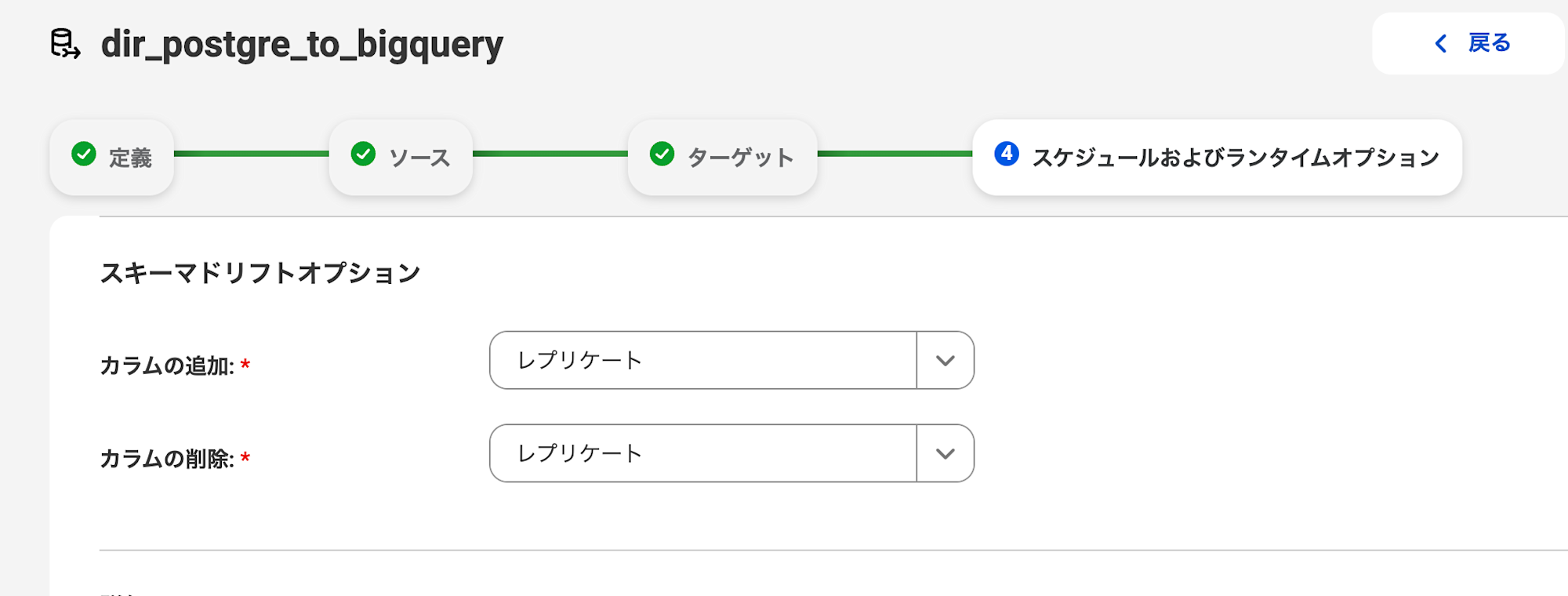
1つ注意点として、BigQueryをターゲットとする場合、
カラム名の変更やカラム定義の変更には対応していないという制限があります。
データを連携してみる
初期連携
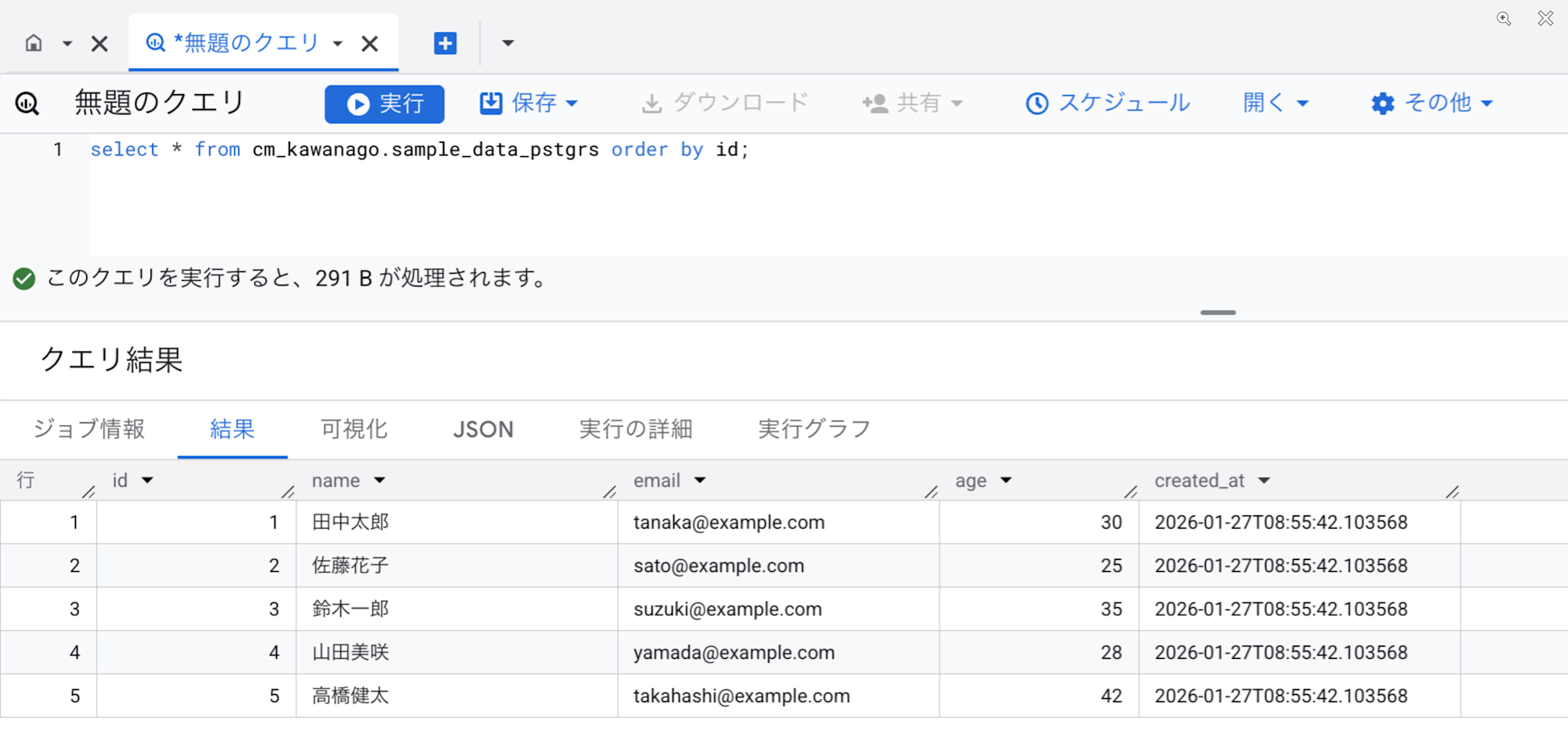
まずPostgreSQL側でテーブルを作成し、テストデータを挿入します。
-- テーブルを作成
CREATE TABLE infa.sample_data_pstgrs (
id serial4 NOT NULL,
"name" varchar(50) NOT NULL,
email varchar(100) NULL,
age int4 NULL,
created_at timestamp DEFAULT CURRENT_TIMESTAMP NULL,
CONSTRAINT sample_data_pstgrs_pkey PRIMARY KEY (id)
);
-- 権限変更
alter table "infa"."sample_data_pstgrs" REPLICA IDENTITY FULL;
-- テストデータ挿入
INSERT INTO infa.sample_data_pstgrs (name, email, age) VALUES
('田中太郎', 'tanaka@example.com', 30),
('佐藤花子', 'sato@example.com', 25),
('鈴木一郎', 'suzuki@example.com', 35),
('山田美咲', 'yamada@example.com', 28),
('高橋健太', 'takahashi@example.com', 42);
数分後BigQuery上にテーブルが作成され、データが入っていることを確認できました。
データ更新
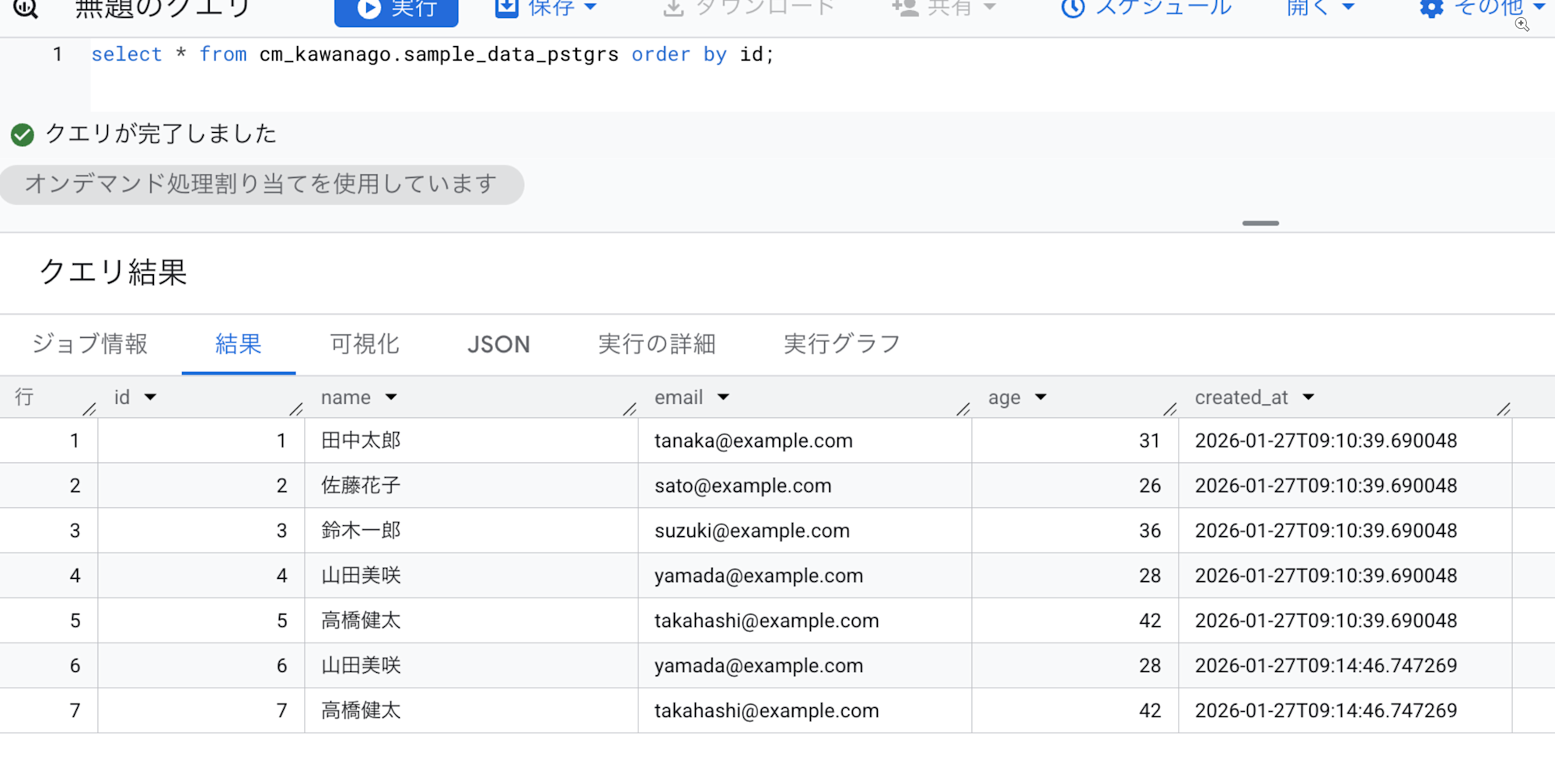
次にデータの更新を試してみます。
-- 3行UPDATE
UPDATE infa.sample_data_pstgrs
SET name = CASE email
WHEN 'tanaka@example.com' THEN '田中太郎'
WHEN 'sato@example.com' THEN '佐藤花子'
WHEN 'suzuki@example.com' THEN '鈴木一郎'
END,
age = CASE email
WHEN 'tanaka@example.com' THEN 31
WHEN 'sato@example.com' THEN 26
WHEN 'suzuki@example.com' THEN 36
END
WHERE email IN (
'tanaka@example.com',
'sato@example.com',
'suzuki@example.com'
);
-- 2行INSERT
INSERT INTO infa.sample_data_pstgrs (name, email, age) VALUES
('山田美咲', 'yamada@example.com', 28),
('高橋健太', 'takahashi@example.com', 42);
こちらも更新内容がBigQuery側に正しく反映されていることを確認できました。
カラム追加
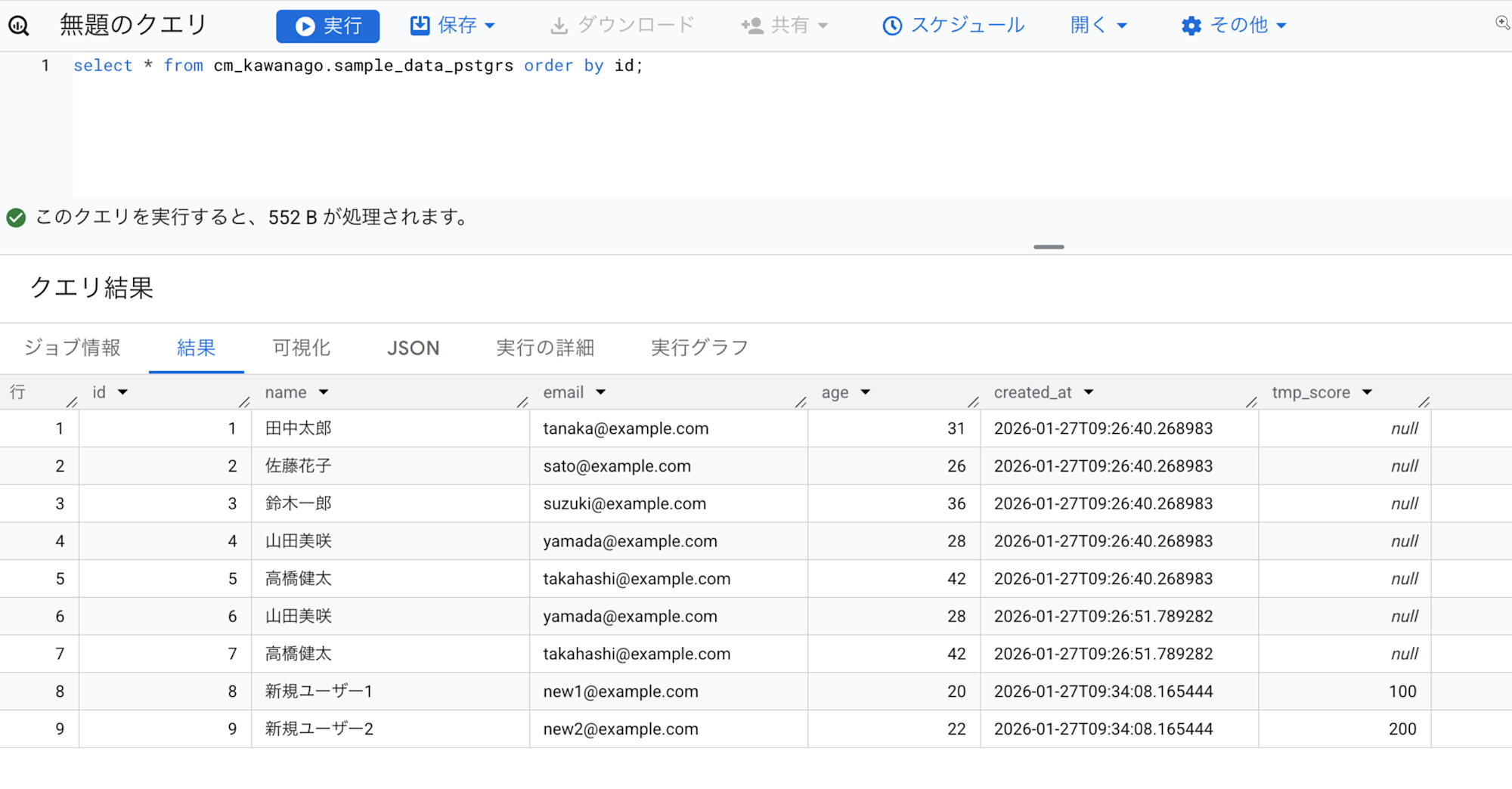
新しいカラムを追加してみます。
-- カラム追加
ALTER TABLE infa.sample_data_pstgrs
ADD COLUMN tmp_score INTEGER;
-- データを入れる
INSERT INTO infa.sample_data_pstgrs (name, email, age, tmp_score) VALUES
('新規ユーザー1', 'new1@example.com', 20, 100),
('新規ユーザー2', 'new2@example.com', 22, 200);
カラムの追加も正常に反映されていますね。
カラム削除
追加したカラムとデータを削除してみます。
-- カラム削除
ALTER TABLE infa.sample_data_pstgrs
DROP COLUMN tmp_score;
-- データ削除
DELETE FROM infa.sample_data_pstgrs
WHERE email IN ('new1@example.com', 'new2@example.com');
こちらも正しく反映されていることを確認できました。
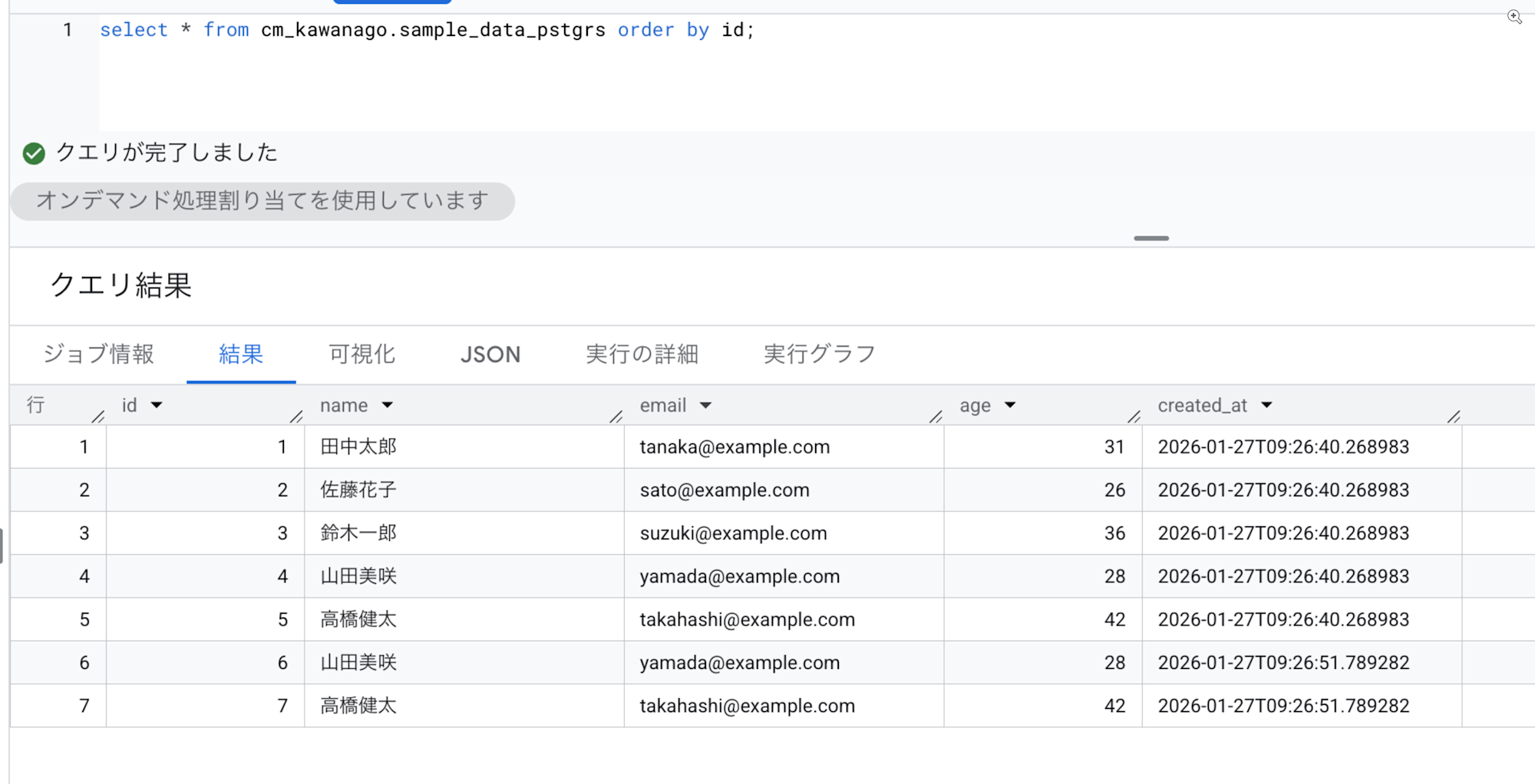
カラム名変更
非対応と説明されていたカラム名の変更を試してみます。
ALTER TABLE infa.sample_data_pstgrs
RENAME COLUMN email TO email_address;
INSERT INTO infa.sample_data_pstgrs (name, email_address, age) VALUES
('新規ユーザー5', 'new1@example.com', 33),
('新規ユーザー6', 'new2@example.com', 44);
上記の結果として、データは挿入されていたのですがリネームは反映されませんでした。
カラム名の変更を反映させるには、ジョブの再同期が必要になります。
実行画面から再同期を実行したところ、最新の状態でデータが反映されました。

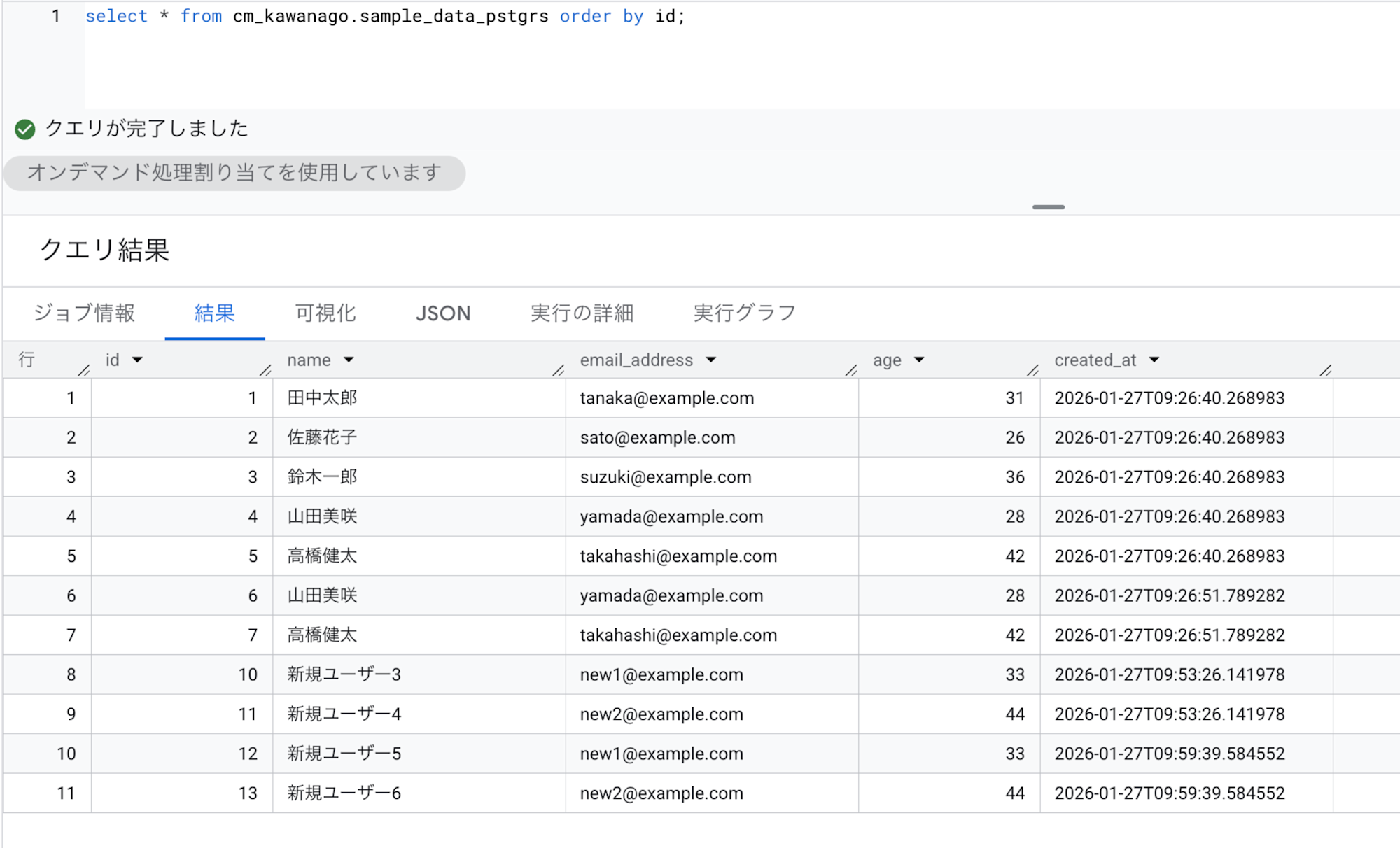
検証から分かったこと
CDCの内部動作
BigQueryのジョブ実行履歴を確認すると、
DIRがBigQuery上でどのようにCDCを実現しているかが分かります。
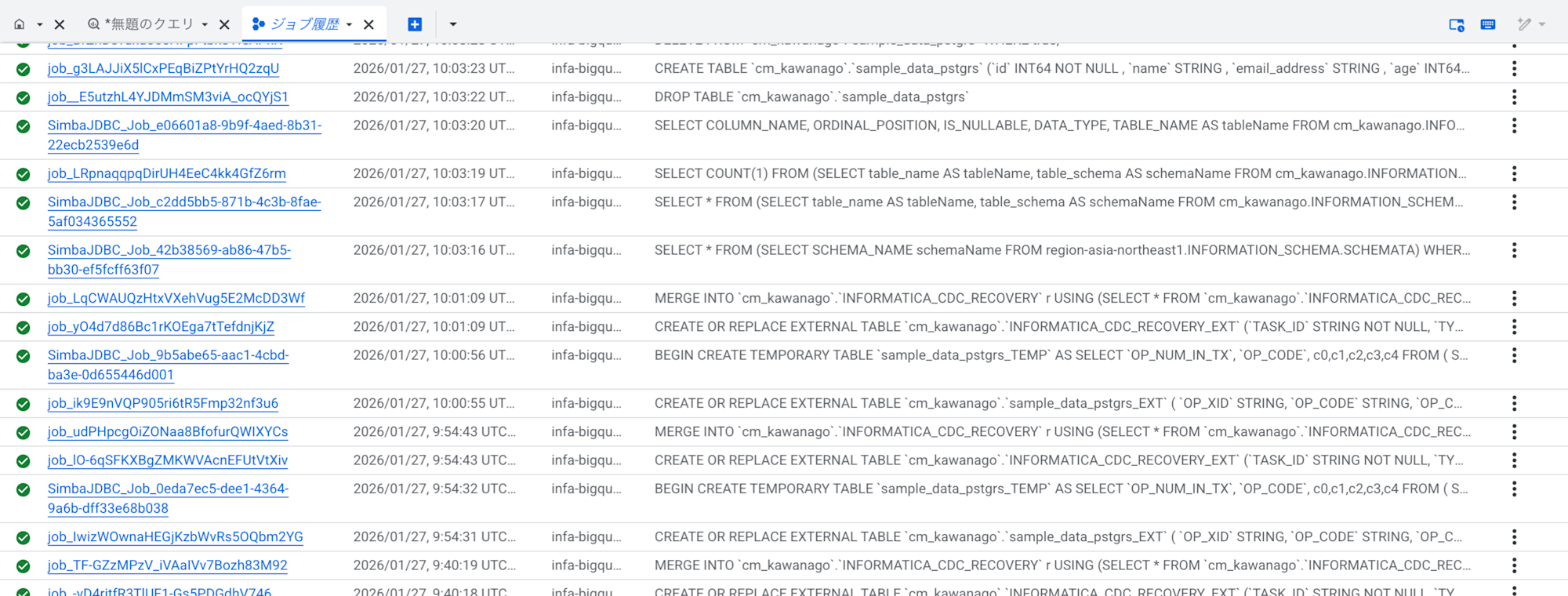
大まかな流れとしては以下のような手順を踏んでいるようです。
- CDC用のCSVファイルを外部テーブルとして読み込む
- キーごとに最新のイベント1行に絞り込む(TEMPテーブル作成)
- MERGEステートメントで本テーブルへINSERT/UPDATE/DELETEを反映
- 処理済み位置(チェックポイント)を更新して次回リカバリ可能にする
この仕組みにより、以下のようなテーブルがBigQuery上に作成されます。
{ターゲットテーブル}:実際のデータテーブル{ターゲットテーブル}_EXT:CDC用外部テーブルINFORMATICA_CDC_RECOVERY:チェックポイント管理テーブルINFORMATICA_CDC_RECOVERY_EXT:チェックポイント用外部テーブル
テーブルメタデータの反映
ソースのテーブルはid列を主キー、id列とname列がNOT NULLとして設定しました。
CREATE TABLE infa.sample_data_pstgrs (
id serial4 NOT NULL,
"name" varchar(50) NOT NULL,
email varchar(100) NULL,
age int4 NULL,
created_at timestamp DEFAULT CURRENT_TIMESTAMP NULL,
CONSTRAINT sample_data_pstgrs_pkey PRIMARY KEY (id)
);
しかしターゲットのテーブルではid列のみがREQUIREDになり、
name列はNULLABLEとして設定されていました。

また主キー設定やパーティションも設定されていませんでした。
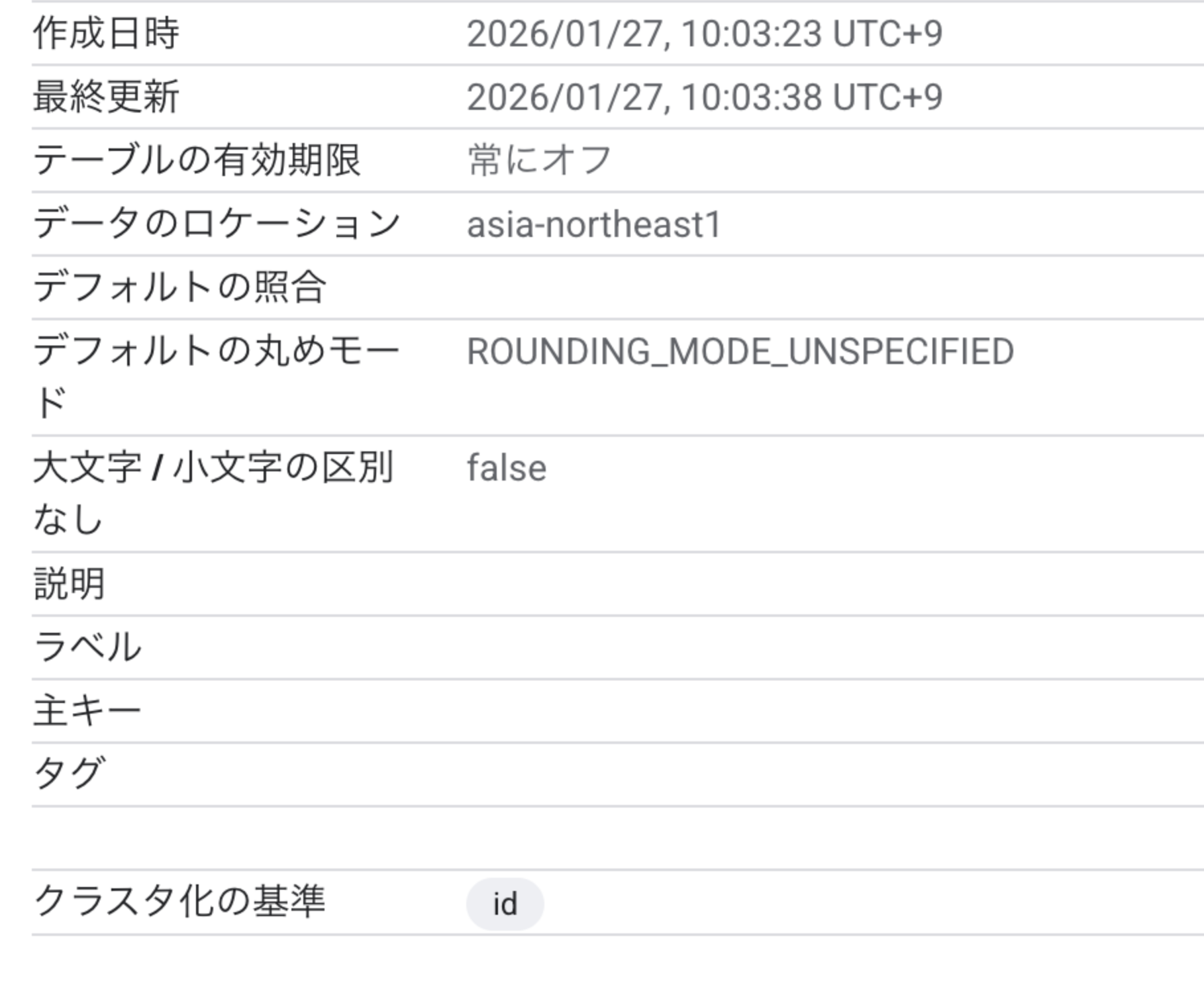
さいごに
今回はDatabase Ingestion and Replication(DIR)を使って、
PostgreSQLのテーブルデータをBigQueryへCDCで連携する検証を行いました。
DIRを使うことで、複数テーブルのBigQueryへのデータ取り込みが非常に簡単になります。
カラムの追加・削除にも自動で対応してくれるため、運用の手間も軽減できます。
一方でカラム名の変更やデータ型の変更にはマニュアルでの再同期実行が必要になる点、
BigQuery側の主キーやパーティションは設定されない点は、運用設計時に考慮が必要です。
少しでも参考になれば幸いです。
最後まで記事を閲覧頂きありがとうございました。









