
【Informatica】Database Ingestion and ReplicationのS3出力オプションの詳細を検証した
データ事業本部の川中子(かわなご)です。
今回は、以前検証したInformaticaのDatabase Ingestion and Replicationについて、
追加で検証した内容をまとめたブログ記事となっています。
前回はほぼデフォルトの設定で試していたので、
以下のドキュメントをもとにターゲット出力の設定を一通り確認しました。
なお今回の検証も前回に引き続き、ソースをPostgreSQLのテーブル、
ターゲットをS3へのファイル出力としています。
検証してみる
検証用アセットについて
前回と同様に、主に検証は以下の定義のテーブルを対象に行います。
CREATE TABLE infa.sample_data_pstgrs (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
age INT,
created_at TIMESTAMP
);
ターゲットに使用するコネクタでは以下のように設定しています。
- 接続名:
conn_s3_for_postgre_rplict (Amazon S3 v2) - Folder Path:
<バケット名>/
①CSV形式 + メタデータ列追加
設定
まずは出力をgzipで圧縮したCSV形式にして検証します。
詳細設定の項目は全て有効化しました。
ターゲット設定
| 項目名 | 設定値 |
|---|---|
| 接続 | conn_s3_for_postgre_rplict (Amazon S3 v2) |
| 出力形式 | CSV |
| CSVファイルへのヘッダーの追加 | 有効 |
| ファイル圧縮タイプ | gzip |
| 暗号化タイプ | サーバーサイドの暗号化 |
| ディレクトリの追加 | 無効 |
| タスクターゲットディレクトリ | cm-kawanago-test/blog_20250806_a |
| 親としてのディレクトリ | 有効 |
| データディレクトリ | {TaskTargetDirectory}/data/{TableName}/data |
| スキーマディレクトリ | {TaskTargetDirectory}/data/{TableName}/schema |
| サイクル完了ディレクトリ | {TaskTargetDirectory}/cycle/completed |
| サイクルコンテンツディレクトリ | {TaskTargetDirectory}/cycle/contents |
| データディレクトリにサイクルのパーティション化を使用してください | 無効 |
| サマリディレクトリにサイクルのパーティション化を使用してください | 無効 |
| コンテンツ内の個々のファイルを一覧表示します | 有効 |
詳細設定
| 項目名 | 設定値 |
|---|---|
| 操作タイプの追加 | 有効 |
| 操作時間の追加 | 有効 |
| 操作トランザクションIDの追加 | 有効 |
| 前のイメージを追加 | 有効 |
初回ロード:フォルダ構造
初回ロードを実行すると、以下のような構造でファイルが出力されました。
各テーブルごとのフォルダにスキーマファイルとgzipのファイルが作成されています。
s3://<バケット名>/
└── cm-kawanago-test/
└── blog_20250806_a/
└── data/
├── sample_data_pstgrs/
│ └── data/
│ ├── sample_data_pstgrs.schema
│ └── sample_data_pstgrs_20250806_013756241.gzip
└── users_20240903/
└── data/
├── users_20240903.schema
└── users_20240903_20250806_013757260.gzip
出力のフォルダ構造は主に以下の設定項目によって制御されています。
| 項目名 | 設定値 |
|---|---|
| タスクターゲットディレクトリ | cm-kawanago-test/blog_20250806_a |
| 親としてのディレクトリ | 有効 |
| データディレクトリ | {TaskTargetDirectory}/data/{TableName}/data |
各項目はドキュメントにて以下のように説明されています。
タスクターゲットディレクトリ:出力先フォルダ構造のルートを定義する親としてのディレクトリ:コネクタのFolder Pathに設定したパスを親ディレクトリとして使用するデータディレクトリ:実際のデータファイルが出力されるフォルダ構造を定義する
親としてのディレクトリは日本語表記だと少し理解が難しいですが、
英語表記の Connection Directory as Parentだと直感的に分かりやすいと思います。
有効化するとタスクターゲットディレクトリの親ディレクトリとしてコネクタ設定のフォルダが適用されます。
今回は 親としてのディレクトリを有効化しているので、
最終的に {TaskTargetDirectory}は以下のような流れで決まっています。
- 親としてのディレクトリ:有効(コネクタの
Folder Pathのパスを使用する)- →
<バケット名>/
- →
- タスクターゲットディレクトリ:
cm-kawanago-test/blog_20250806_a- →
<バケット名>/cm-kawanago-test/blog_20250806_a
- →
- データディレクトリ:
{TaskTargetDirectory}/data/{TableName}/data- →
<バケット名>/cm-kawanago-test/blog_20250806_a/data/{TableName}/data
- →
データディレクトリでは {TableName}を使用しているため、
テーブルごとにこの変数が展開されて、最終的なフォルダが構成されています。
初回ロード結果:ファイル出力
出力されたファイルを確認すると、メタデータ列が追加されていることが分かります。
| infa_operation_type | infa_versioned_sortable_sequence | infa_operation_time | infa_transaction_id | id_OLD | id_NEW | name_OLD | name_NEW | email_OLD | email_NEW | age_OLD | age_NEW |
|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 001...000 | 20250806103755...456 | 1 | - | - | - | - | - | - | - | - |
| I | 001...000 | 20250806103755...456 | 1 | - | 1 | - | 田中太郎 | - | tanaka@example.com | - | 30 |
| I | 001...000 | 20250806103755...456 | 1 | - | 2 | - | 佐藤花子 | - | sato@example.com | - | 25 |
出力ファイルに含まれるメタデータカラムは以下の設定によって制御されています。
| 項目名 | 設定値 | 対応カラム |
|---|---|---|
| 操作タイプの追加 | 有効 | infa_operation_type |
| 操作時間の追加 | 有効 | infa_operation_time |
| 操作トランザクションIDの追加 | 有効 | infa_transaction_id |
| 前のイメージを追加 | 有効 | *_OLD / *_NEW |
各メタデータ列の説明は以下の通りです。
infa_operation_type:レコードの操作タイプ(I=INSERT, U=UPDATE, D=DELETE)infa_versioned_sortable_sequence:バージョン管理用のシーケンス番号infa_operation_time:操作が実行された時刻infa_transaction_id:トランザクションID*_OLD,*_NEW:前のイメージ機能による変更前後の値
infa_versioned_sortable_sequenceについては対応するオプションがなく、
基本的にDatabase IngestionからS3に出力する場合は追加される列のようです。
初回ロードはinfa_operation_type=Tの行が1行分挿入され、
そのレコードはメタデータ以外が空データで入ってしまうので、注意が必要ですね。
増分ロード結果:フォルダ構造
次にsample_data_pstgrsに3行分のUPDATEを実行して、増分ロードの動作を確認します。
増分ロードが実行されると、新たにcycleディレクトリが作成されました。
このフォルダにCDCの情報が出力されていきます。
s3://<バケット名>/
└── cm-kawanago-test/
└── blog_20250806_a/
├── cycle/
│ ├── completed/
│ │ └── Cycle-2025-08-06-02-00-57.csv
│ └── contents/
│ └── Cycle-Contents-2025-08-06-02-00-57.csv
└── data/
├── sample_data_pstgrs/
│ ├── data/
│ │ ├── sample_data_pstgrs.schema
│ │ ├── sample_data_pstgrs_20250806_013756241.gzip # 初回ロード
│ │ └── sample_data_pstgrs_20250806_020057347.gzip # 増分ロード
│ └── schema/
│ └── v1/
│ └── sample_data_pstgrs.schema
└── users_20240903/
└── data/
├── users_20240903.schema
└── users_20240903_20250806_013757260.gzip
増分ロード結果:ファイル出力
UPDATEの内容は以下のように出力されました。
変更されていないレコードの*_OLDは-で表現されています。
| infa_operation_type | infa_versioned_sortable_sequence | infa_operation_time | infa_transaction_id | id_OLD | id_NEW | name_OLD | name_NEW | email_OLD | email_NEW | age_OLD | age_NEW | created_at_OLD | created_at_NEW |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U | 000...000 | 20250806021223154 | 88536 | - | 1 | - | 田中太郎 | tanaka@example.com | updated@example.com | 30 | 99 | - | 2025-06-24 10:30:00.000000 |
| U | 000...000 | 20250806021223154 | 88536 | - | 2 | - | 佐藤花子 | sato@example.com | updated@example.com | 25 | 99 | - | 2025-06-24 15:45:00.000000 |
| U | 000...000 | 20250806021223154 | 88536 | - | 3 | - | 鈴木一郎 | suzuki@example.com | updated@example.com | 35 | 99 | - | 2025-06-25 08:20:00.000000 |
ちなみに詳細設定の項目を全て無効で実行すると以下のような出力になります。
| infa_operation_type | infa_versioned_sortable_sequence | id | name | age | created_at | |
|---|---|---|---|---|---|---|
| U | 000...000 | 1 | 田中太郎 | updated@example.com | 99 | 2025-06-24 10:30:00.000000 |
| U | 000...000 | 2 | 佐藤花子 | updated@example.com | 99 | 2025-06-24 15:45:00.000000 |
| U | 000...000 | 3 | 鈴木一郎 | updated@example.com | 99 | 2025-06-25 08:20:00.000000 |
UPDATEの場合は、UPDATE後のデータがレコードとして出力されるため、
このデータをソースにUPSERTの処理に流すことはできそうです。
②Parquet形式 + データディレクトリ変更
設定内容
次にSnappyで圧縮したParquet形式の出力を試してみました。
詳細設定の項目は全て無効化して、データディレクトリの設定を少し変更しています。
ターゲット設定
| 項目名 | 設定値 |
|---|---|
| 接続 | conn_s3_for_postgre_rplict (Amazon S3 v2) |
| 出力形式 | PARQUET |
| 暗号化タイプ | サーバーサイドの暗号化 |
| Parquet圧縮タイプ | Snappy |
| ディレクトリの追加 | 無効 |
| タスクターゲットディレクトリ | cm-kawanago-test/blog_20250806_c |
| 親としてのディレクトリ | 有効 |
| データディレクトリ | {TaskTargetDirectory}/project/database_name/{TableName}/data |
| スキーマディレクトリ | {TaskTargetDirectory}/project/database_name/{TableName}/schema |
| サイクル完了ディレクトリ | {TaskTargetDirectory}/cycle/completed |
| サイクルコンテンツディレクトリ | {TaskTargetDirectory}/cycle/contents |
| データディレクトリにサイクルのパーティション化を使用してください | 無効 |
| サマリディレクトリにサイクルのパーティション化を使用してください | 無効 |
| コンテンツ内の個々のファイルを一覧表示します | 有効 |
詳細設定
| 項目名 | 設定値 |
|---|---|
| 操作タイプの追加 | 有効 |
| 操作時間の追加 | 有効 |
| 操作トランザクションIDの追加 | 有効 |
| 前のイメージを追加 | 有効 |
初回ロード結果:フォルダ構造
出力のフォルダ構造にデータディレクトリの設定が適用されました。
またCSV形式ではないので、*.schemaファイルが出力されていません。
s3://<バケット名>/
└── cm-kawanago-test/
└── blog_20250806_c/
└── project/
└── database_name/
├── sample_data_pstgrs/
│ └── data/
│ └── sample_data_pstgrs_20250806_045304766.parquet
└── users_20240903/
└── data/
└── users_20240903_20250806_045310161.parquet
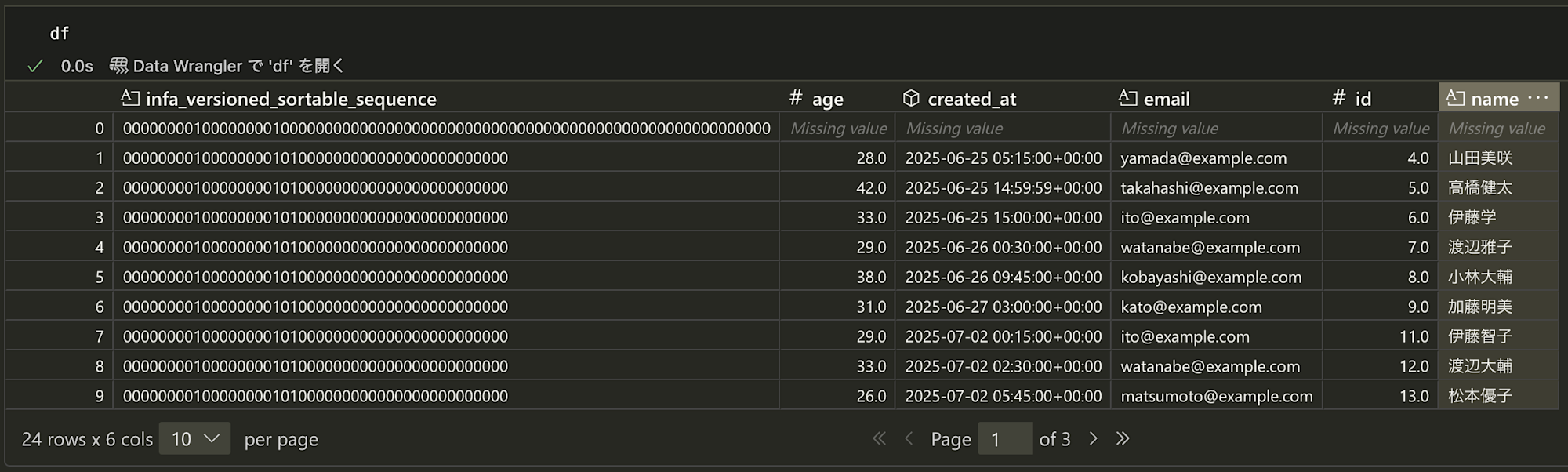
初回ロード結果:ファイル出力
pythonでファイルを読み込んでみました。
出力のカラム情報はCSVの場合と差はありません。
増分ロード結果:フォルダ構造
sample_data_pstgrsにデータを追加して増分ロードを実行すると、
csv形式の時と同様にcycleディレクトリが追加され、以下の構造になりました。
schema用のディレクトリがないので全体的にスッキリしていますね。
s3://<バケット名>/
└── cm-kawanago-test/
└── blog_20250806_c/
├── cycle/
│ ├── completed/
│ │ └── Cycle-2025-08-06-04-54-21.csv
│ └── contents/
│ └── Cycle-Contents-2025-08-06-04-54-21.csv
└── project/
└── database_name/
├── sample_data_pstgrs/
│ └── data/
│ ├── sample_data_pstgrs_20250806_045304766.parquet # 初回ロード
│ └── sample_data_pstgrs_20250806_045421141.parquet # 増分ロード
└── users_20240903/
└── data/
└── users_20240903_20250806_045310161.parquet
③パーティション設定の有効化
設定
次にフォルダのパーティション関連の設定を有効化してみました。
パーティション関連の設定は以下の項目が対応しています。
ターゲット設定
| 項目名 | 説明 |
|---|---|
| ディレクトリの追加 | 各パーティションフォルダ名にdt=をつける |
| データディレクトリにサイクルのパーティション化を使用してください | データディレクトリをパーティション化する |
| サマリディレクトリにサイクルのパーティション化を使用してください | cycleディレクトリをパーティション化する |
フォルダ構造
以下は前回の検証ブログのdataディレクトリ出力の再掲ですが、
実行ごとにタイムスタンプのフォルダが作成されていることが分かります。
s3://{バケット}/cm-kawanago-test/infomatica_dir/
└── data/
├── sample_data_pstgrs/
│ └── data/
│ ├── 2025-07-02-09-09-43/
│ │ └── sample_data_pstgrs_20250702_090943840.parquet
│ └── 2025-07-02-09-41-15/
│ └── sample_data_pstgrs_20250702_094115851.parquet
└── users_20240903/
└── data/
└── 2025-07-02-09-09-49/
└── users_20240903_20250702_090949127.parquet
前回の検証時はディレクトリの追加を有効化してなかったのですが、
これを有効化すると各パーティションのフォルダ名が以下のように変わります。
- 無効:
2025-07-02-09-09-43/ - 有効:
dt=2025-07-02-09-09-43/
④プレースホルダーの利用
設定
データディレクトリの設定ではプレースホルダーが利用できます。
検証として日付関連のプレースホルダーを設定して実行してみました。
| 項目名 | 設定値 |
|---|---|
| データディレクトリ | {TaskTargetDirectory}/{TableName}/data/{YYYY}{MM}{DD}/ |
フォルダ構造
どうやら{MM}や{DD}が1桁の場合、01のように0は追加されず、
そのまま1桁の値が代入される仕様のようです。
s3://<バケット名>/
└── cm-kawanago-test/
└── blog_20250806_e/
├── sample_data_pstgrs/
│ └── data/
│ └── 202586/
│ └── sample_data_pstgrs_20250806_081332832.parquet
└── users_20240903/
└── data/
└── 202586/
└── users_20240903_20250806_081338490.parquet
なお出力のファイルはデフォルトで{TableName}_{Timestamp}の形式になっており、
{Timestamp}はyyyymmdd_hhmissmsのような形式になっています。
他にもスキーマ名を代入できる{SchemaName}や、
文字列操作関数としてtoUpper()とtoLower()が利用可能です。
さいごに
今回はPostgreSQL → S3におけるDatabase Ingestion and Replicationの、
ターゲット設定の詳細設定についていくつか検証してみました。
出力のフォルダ構造を自由に設定することができるので、
後続システムで想定しているフォルダ構造が存在する場合でも柔軟に対応できそうです。
ただ出力されるファイルにメタデータ列が追加されるため、
そのカラムについては後続の処理の中で考慮する必要があります。
システムからデータレイクへの連携を大幅に効率化することができるツールなので、
大規模なデータを運用している基盤ほど、このサービスは有効だと思います。
少しでも参考になれば幸いです。
最後まで記事を閲覧いただきありがとうございました。







