
【Informatica】Database Ingestion and ReplicationでPostgreSQLのデータを自動取り込み
データ事業本部の川中子(かわなご)です。
データ分析基盤の構築においては、各種システムDBからデータレイクへのデータ連携が必要になります。
特に大量のソースから継続的に同期する場合、手動でのデータ移行は運用負荷が大きくなってしまいます。
今回はそんな大量のソースからのデータ取り込みを簡素化するサービスである、
InformaticaのDatabase Ingestion and Replicationを使用して、
Amazon RDS for PostgreSQLからAmazon S3へのデータ取り込みをやってみました。
Database Ingestion and Replicationとは
Database Ingestion and Replication(以降Database Ingestion)は、
Informaticaのデータ連携サービスであるData Ingestion and Replicationの1つにあたります。
Database Ingestionはその名前の通りデータベースのデータ連携に特化していて、
データベースから様々なターゲットシステムへ効率的にデータを複製することができます。
主に以下のような特徴があり、大規模データの継続的な取り込み処理が可能です。
- 大量データの高速処理:大規模なデータを低レイテンシで効率的に取り込んで複製
- 準リアルタイム同期:初期ロードに加えて、増分データの継続的な同期が可能
- スキーマドリフト検出:ソースデータベースのスキーマ変更を自動検出・対応
- 多様なターゲット:クラウドストレージ、データウェアハウスなどに対応
なおFile Ingestion and Replicationについては既存の記事があるので、こちらもぜひご覧下さい。
Cloud Data Integrationとの使い分け
Informatica社が提供するETLツールとして、Cloud Data Integration(CDI)も存在します。
CDIとの違いや使い分けのイメージを以下の表にしてみました。
| 機能 | Database Ingestion and Replication | Cloud Data Integration |
|---|---|---|
| 主な用途 | データベースの大規模データ複製 | データ変換・統合処理 |
| 処理対象 | 複数テーブルを同時処理 | 個別にデータ処理を実装 |
| 変換処理 | 基本的なデータ抽出のみ可能 | 複雑な変換処理が可能 |
各種システムからデータレイクへの単純なデータ連携にはDatabase Ingestion、
データレイクからDWHへの変換を伴うデータ連携にはCDIを利用するようなケースが想定されます。
システム要件
Database Ingestionを利用するためには、Secure Agentが以下の要件を満たす必要があります。
| 項目 | 要件 |
|---|---|
| CPUコア数 | 最小8コア(大量のソーステーブル処理時は16コア推奨) |
| メモリ | 32GB |
| ディスク容量 | ジョブあたり5GB(行サイズ2KBベース) |
連携対象のテーブル数や各テーブルのサイズに応じて必要スペックは変わってくるため、
対象環境の条件に応じてCPUやディスク容量は調整する必要がありそうです。
PostgreSQLソースの準備と設定
今回はAWS環境でRDS for PostgreSQLをソースとして使用します。
PostgreSQLをソースとする場合の各種設定は以下のドキュメントを参考にしています。
増分ロードに向けた設定
PostgreSQLで増分データの同期を行うにはWAL(Write-Ahead Log)の設定が必要になります。
具体的には、rds.logical_replicationパラメータに1を設定すればこの設定は完了です。
なお今回はRDSでデータベースを管理しているので、AWSのCLIコマンドで設定を実行しています。
# PostgreSQL 15用のカスタムパラメータグループ作成
aws rds create-db-parameter-group \
--db-parameter-group-name [custom-parameter-group-name] \
--db-parameter-group-family postgres15
# rds.logical_replicationパラメータを1に設定
aws rds modify-db-parameter-group \
--db-parameter-group-name [custom-parameter-group-name] \
--parameters "ParameterName=rds.logical_replication,ParameterValue=1,ApplyMethod=pending-reboot"
# DBインスタンスにパラメータグループ適用
aws rds modify-db-instance \
--db-instance-identifier [db-instance-name] \
--db-parameter-group-name [custom-parameter-group-name] \
--apply-immediately
# DB再起動(設定反映のため)
aws rds reboot-db-instance \
--db-instance-identifier [db-instance-name]
データベースユーザーの作成
次に複製ジョブを実行するためのユーザーを作成し、必要な権限を付与しておきます。
-- ユーザーの作成
CREATE USER dbir_user WITH PASSWORD 'your_password';
-- Replicationの権限をユーザーに付与
GRANT rds_replication TO dbir_user;
-- pgoutputプラグイン使用時の追加権限
GRANT CREATE ON DATABASE your_database TO dbir_user;
レプリケーションスロットの作成
データの同期状態を管理するために、レプリケーションスロットとパブリケーションを作成します。
スロット名とパブリケーション名はこの後のInformatica側の設定時に使用します。
-- pgoutputプラグインでレプリケーションスロットを作成
SELECT pg_create_logical_replication_slot('informatica_slot', 'pgoutput');
-- 全テーブル用のパブリケーションを作成
CREATE PUBLICATION informatica_all_pub FOR ALL TABLES;
検証
PostgreSQLのデータ準備
データベースには以下の2つのテーブルを準備しておきました。
なおDatabase Ingestionの利用においては主キーの設定が推奨されていますが、
もしテーブル主キー設定がない場合は、すべての列が主キーとして扱われる仕様になっています。
sample_data_pstgrs テーブル(10件):
ID | name | email | age | created_at
---|----------|----------------------|-----|-------------------------
1 | 田中太郎 | tanaka@example.com | 30 | 2025-06-24 10:30:00.000
2 | 佐藤花子 | sato@example.com | 25 | 2025-06-24 15:45:00.000
3 | 鈴木一郎 | suzuki@example.com | 35 | 2025-06-25 08:20:00.000
4 | 山田美咲 | yamada@example.com | 28 | 2025-06-25 14:15:00.000
5 | 高橋健太 | takahashi@example.com| 42 | 2025-06-25 23:59:59.000
6 | 伊藤学 | ito@example.com | 33 | 2025-06-26 00:00:00.000
7 | 渡辺雅子 | watanabe@example.com | 29 | 2025-06-26 09:30:00.000
8 | 小林大輔 | kobayashi@example.com| 38 | 2025-06-26 18:45:00.000
9 | 加藤明美 | kato@example.com | 31 | 2025-06-27 12:00:00.000
10 | 斉藤隆 | saito@example.com | 45 | 2025-06-28 16:30:00.000
users_20240903 テーブル(6件):
ID | name | age | address
---|-----------|-----|-----------------------------------------------------
1 | 山崎 加奈 | 56 | 香川県新宿区下吉羽41丁目20番3号 クレスト上高野359
2 | 鈴木 結衣 | - | 和歌山県川崎市多摩区四番町4丁目1番13号 脚折町ハイツ979
3 | 小林 太一 | - | 和歌山県文京区丸の内20丁目9番13号 シャルム氏家新田132
4 | 山下 洋介 | 51 | 沖縄県山武郡芝山町湯宮9丁目5番5号 前弥六コーポ806
5 | 伊藤 明美 | 67 | 兵庫県横浜市都筑区西神田23丁目22番16号
6 | 加藤 裕美子| 39 | aaa
コネクタの作成
ソースのPostgreSQL、ターゲットのS3への接続用にコネクタを作成します。
それぞれのコネクタについては以下のドキュメントを参考にしています。
ターゲットになるS3のコネクタを設定する際、Folder Pathの設定には注意が必要です。
私は最初、バケット名のみをFolder Pathとして設定していたのですが、
その状態でDatabase Ingestionをデプロイ、実行したところ以下のようなエラーになりました。
Bucket/Path is invalid :{バケット名}
Folder Pathの設定を{バケット名}/のように末尾にスラッシュを付けて設定したところ
問題なくDatabase Ingestionが動作するようになったため、この設定が必要になるようです。
Database Ingestion and Replicationの設定
次にDatabase Ingestionを作成していきます。
ジョブの基本的な設定方法については以下のドキュメントを参照しています。
「定義」タブでは使用するランタイム環境やロードのタイプを選択します。
今回は継続的なデータ連携を想定しているので初期ロードと増分ロードを選択します。
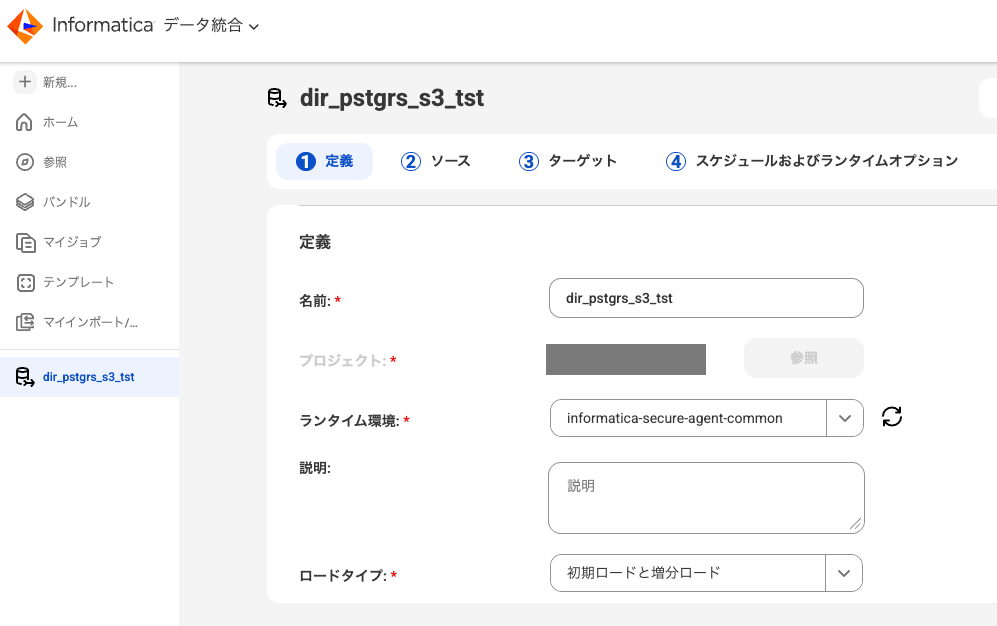
「ソース」タブではソースとなるPostgreSQLの読み込み設定をします。
ここではデータベースのほうで設定したパブリケーションなどの名前を入力しておきます。
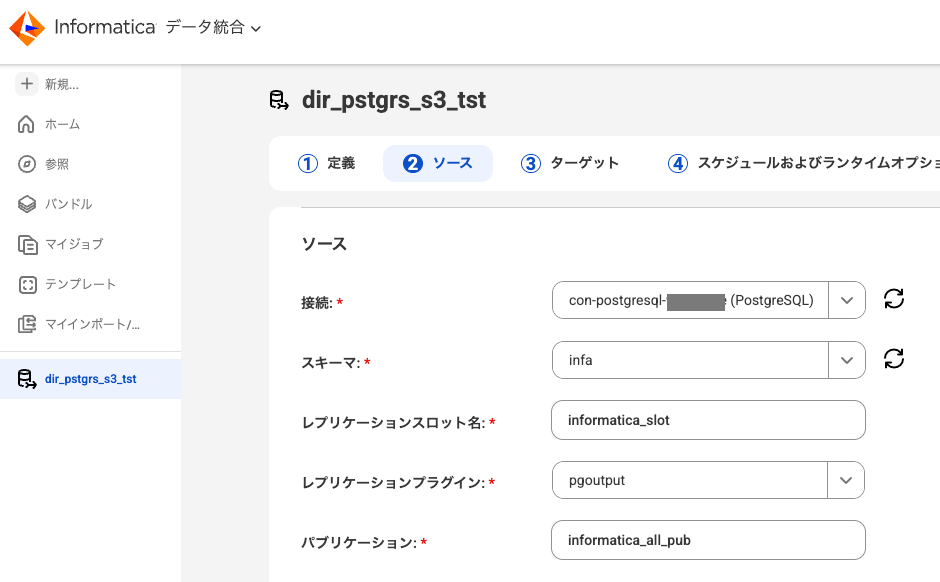
対象とするテーブルは、すべて選択を選択して全テーブルを対象とするか、
テーブルルールを設定して特定のテーブルのみを対象にするかを設定します。
今回はあえて2つのテーブルのみを対象とするようにルールを設定しました。
対象のテーブルが設定できたら、変更履歴を追えるようにするためにCDCスクリプトを実行します。
スクリプトのダウンロードも可能ですが、画像のように画面から直接実行することも可能です。

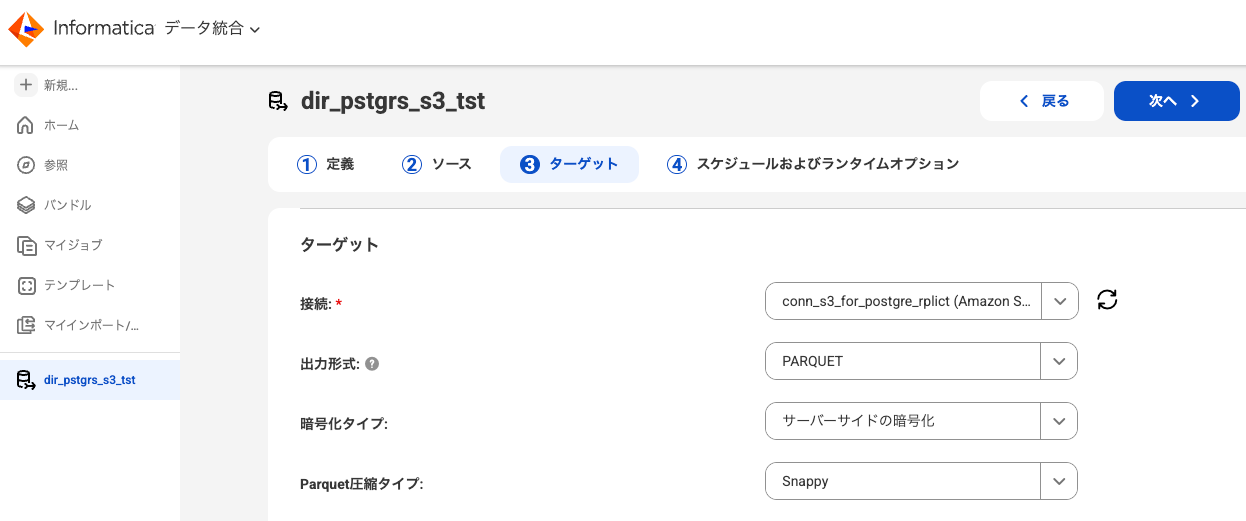
「ターゲット」タブでは出力の形式や詳細な設定を行います。
タスクターゲットディレクトリに出力先のフォルダ名を指定して、他はデフォルトにしました。

「スケジュール」タブは全てデフォルトの状態で、画面右上のデプロイを押下します。
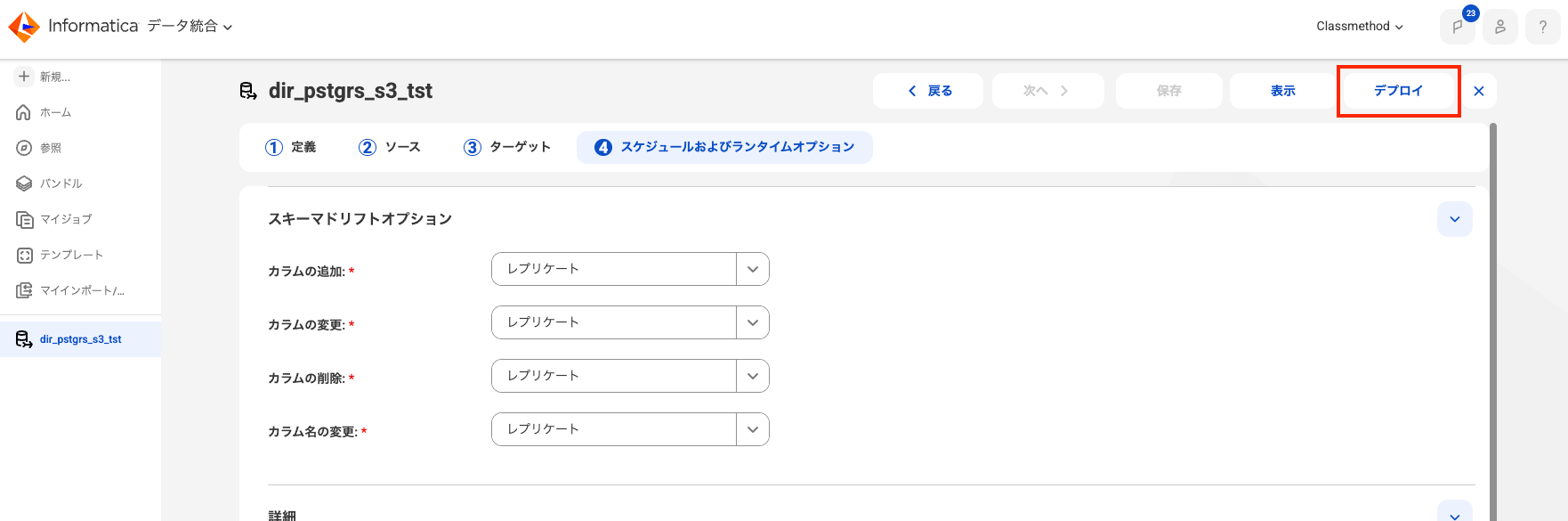
実行
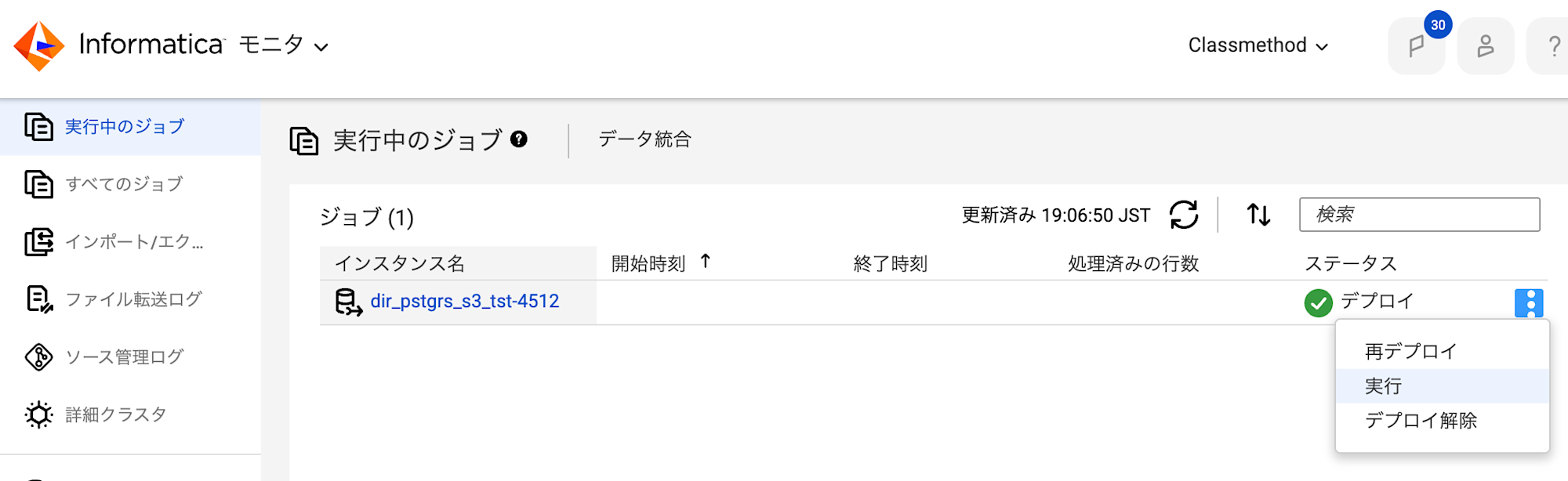
デプロイを行うとモニタ画面にジョブが表示されます。
実行する際は対象のインスタンスのメニューバーから実行ボタンを押下します。
実行後はステータスが稼働中の状態になり初回のデータロードが実行され、
その後も継続的にデータの変更を監視し、スケジュールに合わせてレプリケーションを実行します。
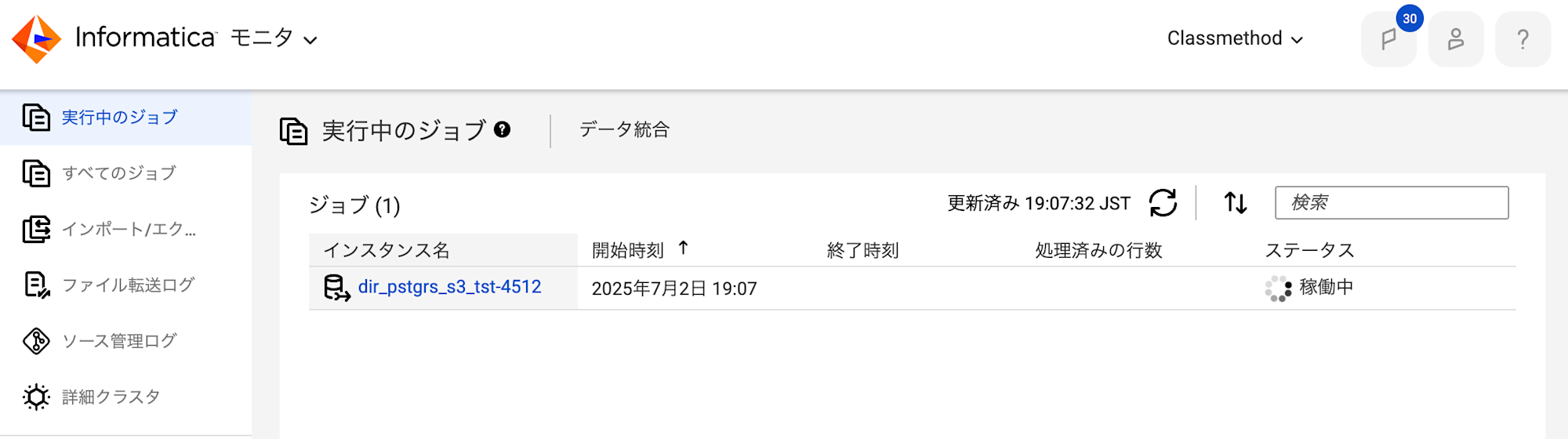
初回ロード
初回ロードの結果、S3には以下のような構造でファイルが出力されました。
フォルダ構造はデフォルト設定のままなので、data/配下に日付フォルダが作成されました。
s3://{バケット}/cm-kawanago-test/infomatica_dir/
├── cycle/
│ ├── completed/
│ │ ├── 2025-07-02-09-09-43/
│ │ │ └── sample_data_pstgrs-Initial-Load-Cycle-2025-07-02-09-09-43.csv
│ │ └── 2025-07-02-09-09-49/
│ │ └── users_20240903-Initial-Load-Cycle-2025-07-02-09-09-49.csv
│ └── contents/
│ ├── 2025-07-02-09-09-43/
│ │ └── sample_data_pstgrs-Initial-Load-Cycle-Contents-2025-07-02-09-09-43.csv
│ └── 2025-07-02-09-09-49/
│ └── users_20240903-Initial-Load-Cycle-Contents-2025-07-02-09-09-49.csv
└── data/
├── sample_data_pstgrs/
│ └── data/
│ └── 2025-07-02-09-09-43/
│ └── sample_data_pstgrs_20250702_090943840.parquet
└── users_20240903/
└── data/
└── 2025-07-02-09-09-49/
└── users_20240903_20250702_090949127.parquet
今回の出力形式だと実行ごとにフォルダが分かれてしまいますが、
データディレクトリの設定次第では以下のようなフォルダ構造にすることも可能です。
myDir1/{スキーマ名}/{テーブル名}
myDir1/myDir2/{スキーマ名}/{YYYY}/{MM}/{テーブル名}_{タイムスタンプ}
myDir1/{toLower(スキーマ名)}/{テーブル名}_{タイムスタンプ}
なおdata/以外のフォルダについてはそれぞれ以下のようなデータが格納されます。
/cycle/completed/: 処理完了のログファイル/cycle/contents/: 処理内容の詳細ログファイル
データ追加と増分ロード
増分データの処理を確認するため以下のデータを追加します。
INSERT INTO infa.sample_data_pstgrs (name, email, age, created_at)
VALUES
('伊藤智子', 'ito@example.com', 29, '2025-07-02 09:15:00'),
('渡辺大輔', 'watanabe@example.com', 33, '2025-07-02 11:30:00'),
('松本優子', 'matsumoto@example.com', 26, '2025-07-02 14:45:00'),
('中村翔太', 'nakamura@example.com', 38, '2025-07-02 16:20:00'),
('小林真理', 'kobayashi@example.com', 31, '2025-07-02 18:10:00');
オブジェクトの詳細画面では、sample_data_pstgrsのINSERTが5件と表示されました。
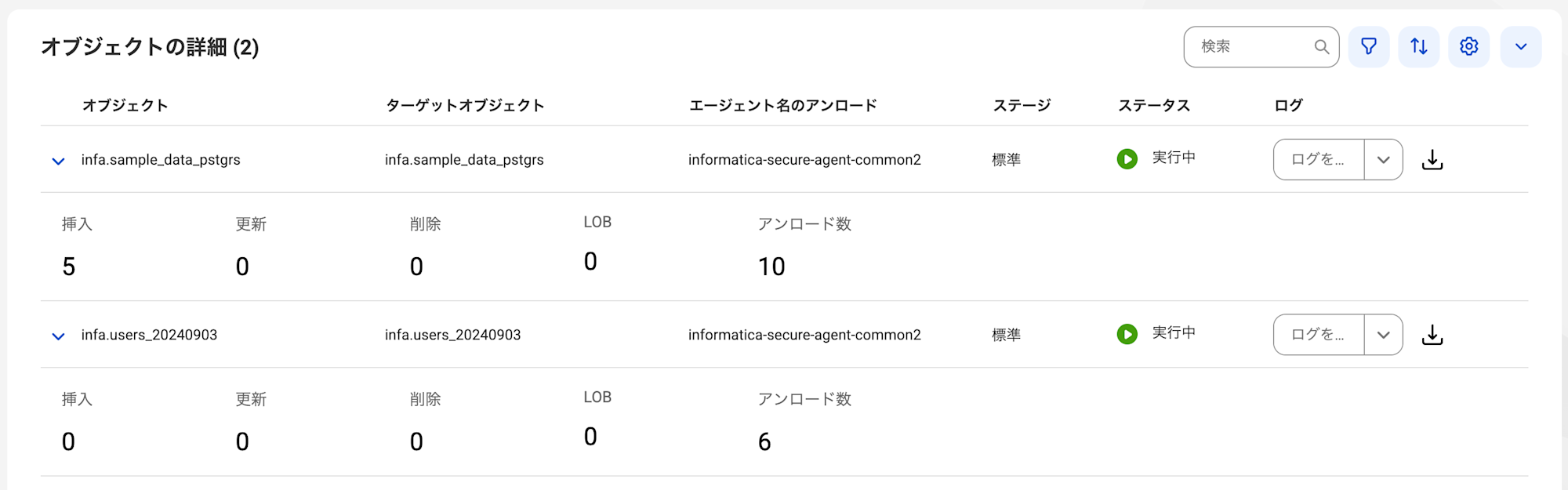
一定時間の経過後に再度S3バケットを確認すると、新しいファイルが生成されていました。
もちろんデータを追加していないusers_20240903にはファイルは追加されていません。
s3://{バケット}/cm-kawanago-test/infomatica_dir/
├── cycle/
│ ├── completed/
│ │ ├── 2025-07-02-09-09-43/
│ │ │ └── sample_data_pstgrs-Initial-Load-Cycle-2025-07-02-09-09-43.csv
│ │ ├── 2025-07-02-09-09-49/
│ │ │ └── users_20240903-Initial-Load-Cycle-2025-07-02-09-09-49.csv
│ │ └── 2025-07-02-09-41-15/ ← 新規追加
│ │ └── Cycle-2025-07-02-09-41-15.csv
│ └── contents/
│ ├── 2025-07-02-09-09-43/
│ │ └── sample_data_pstgrs-Initial-Load-Cycle-Contents-2025-07-02-09-09-43.csv
│ ├── 2025-07-02-09-09-49/
│ │ └── users_20240903-Initial-Load-Cycle-Contents-2025-07-02-09-09-49.csv
│ └── 2025-07-02-09-41-15/ ← 新規追加
│ └── Cycle-Contents-2025-07-02-09-41-15.csv
└── data/
├── sample_data_pstgrs/
│ └── data/
│ ├── 2025-07-02-09-09-43/
│ │ └── sample_data_pstgrs_20250702_090943840.parquet
│ └── 2025-07-02-09-41-15/ ← 新規追加
│ └── sample_data_pstgrs_20250702_094115851.parquet
└── users_20240903/
└── data/
└── 2025-07-02-09-09-49/
└── users_20240903_20250702_090949127.parquet
これで継続的なデータの追加などについても反映されることが確認できました。
まとめ
今回はDatabase Ingestion and Replicationを使用してデータの移行を検証しました。
テーブルデータの変更や追加を継続的に監視してデータ連携を自動化できるため、
システムのデータベースからデータレイクへ大規模データを連携する際は非常に強力です。
ETLツールとしてCDIを使用する場合は各テーブルごとに作成が必要になってしまうため、
特に変換を必要としない単純なデータのレプリケーションであれば、
Database Ingestionを使用することで大幅に開発の工数を削減することが可能です。
Informaticaはデータマネジメントに対応した様々なサービスを展開しているため、
しっかり要件に合ったサービスを選定して、効率的な運用を実現したいですね。
最後まで記事を閲覧いただきありがとうございました。
少しでも参考になれば幸いです。







