
AWS의 대표적인 NoSQL 데이터베이스 서비스! Amazon DynamoDB에 입문 해봅시다.
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
안녕하세요, 클래스메서드의 정현재입니다.
올해 4월에 클래스메서드 주식회사에 입사해서 어느덧 4개월정도 시간이 지났는데요, AWS를 하나도 모르던 상태에서 연수를 시작해 여러 가지 경험하고, 배운 것들을 아웃풋 해나가면서 열심히 성장 중에 있습니다. 지금까지 일본어 블로그만 작성하다가 정말 오랜만에 한국어 블로그를 쓰는 감이 있는데 앞으로는 한국어 블로그도 차근차근 쓸 예정이니 잘 부탁드립니다!!
이번 블로그에서는 Amazon DynamoDB에 대해서 이야기 해보려고 합니다. DynamoDB의 개요를 간단히 설명한 후, 실제 테이블을 작성하고 쿼리를 해보는 실습을 통해 보충적인 설명을 하도록 하겠습니다.(실습은 AWS Management Console을 이용합니다.)
Amazon DynamoDB 개요
실습에 들어가기 전에 간단히 DynamoDB에 대한 개요를 설명 드리도록 하곘습니다.
DynamoDB란?
AWS 공식 사이트에서는 DynamoDB를 이렇게 설명하고 있습니다.
규모에 상관없이 빠르고 유연한 완전관리형 NoSQL 데이터베이스 서비스
AWS에서의 "완전관리형"이란 AWS가 해당 리소스를 사용자 대신 관리해준다는 의미입니다. DynamoDB는 서버리스 서비스이기 때문에 관리할 서버가 필요 없고, 용량에 맞게 테이블을 자동으로 확장/축소하는 Auto Scaling 기능을 이용하여 높은 성능을 유지하게 됩니다. Auto Scaling 기능을 통해 규모에 상관없이 사실상 무제한의 처리량, 저장 용량을 제공할 수 있습니다. 물론, 백업 및 복원의 기능도 제공을 합니다.
DynamoDB의 높은 성능을 아주 잘 보여주는 성공 사례로, Amazon Prime Day 2017 이벤트를 예로 들 수 있습니다. 이 이벤트 기간 동안 DynamoDB로의 총 요청 수가 3조 3400억 건, 피크타임에서의 초당 요청 수는 1290만 건을 기록하였습니다. 하지만 DynamoDB는 빠른 확장성, 일관된 성능 및 고가용성으로 인해 "어렵지 않게" 해당 요청들을 모두 수행할 수 있었다고 합니다. 저도 이 부분에 대해서는 이번에 처음 알게 되었는데 다시 한 번 DynamoDB의 성능에 감탄할 수 밖에 없었습니다..
DynamoDB 주요 개념
DynamoDB에서는 데이터를 저장할 때 테이블이라는 개념을 사용합니다.
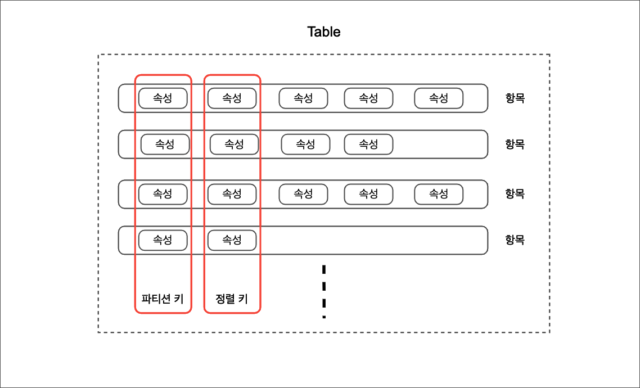
항목 (Item)
테이블에 Insert, Update, Delete 하게 될 속성들의 집합을 의미합니다. RDBMS(관계형 데이터베이스)에서의 행과 유사한 개념입니다.
속성 (Attribute)
항목을 구성하는 각각의 데이터들을 의미합니다. 저장 가능한 데이터 타입은 Amazon DynamoDB 유저가이드에서 참고하실 수 있습니다.
파티션 키 (Partition Key)
테이블을 생성할 때 필수적으로 설정을 해야하는 기본 키입니다. 파티션 키는 물리적 공간인 파티션을 특정 하는 키로, 이 파티션 키에 따라서 저장하는 항목들의 분배가 결정이 됩니다. 쉽게 말해 항목들의 주소로서 역할을 하게 됩니다. 이 파티션 키를 사용함으로써 특정 항목을 조회할 때, 테이블 전체를 조회하는 것이 아닌 특정 파티션 키를 가진 항목만 조회할 수 있어 성능을 대폭 향상 시킬 수 있습니다. 이러한 특징 때문에 파티션 키는 고유 값이 많은 속성으로 설정을 하는 것이 좋습니다.(예를 들어, 고객 ID, 디바이스 ID 등)
정렬 키 (Sort Key)
테이블을 생성할 때 선택적으로 설정할 수 있는 기본 키입니다. 정렬 키는 동일한 파티션 키를 가진 데이터를 정렬할 때 쓰입니다. 정렬 키와 파티션 키를 함께 이용함으로서 <, >, between, contains 등의 연산자를 이용한 범위 검색이 가능해집니다. 예를 들어, DynamoDB를 사용하고 있는 쇼핑몰 사이트가 있다고 가정해봅시다. 사용하고 있는 DynamoDB 테이블의 파티션 키를 고객 ID, 정렬 키를 고객이 물건을 주문한 시간이라고 설정한다면 between 연산자를 이용해 특정 기간 동안 고객이 주문한 물건에 대한 항목들을 검색하는 것이 가능해집니다.
여기서 파티션 키와 정렬 키는 기본 키임으로 생략할 수 없고, 또한 변경을 할 수 없기 때문에 주의 하실 필요가 있습니다.
추가적인 내용들은 실습을 진행하면서 설명을 드리도록 하겠습니다. 그럼 실제로 DynamoDB를 사용해봅시다!!
DynamoDB 실습
이번 블로그에서는 AWS Management Console을 이용하여 실습을 진행합니다.
DynamoDB 테이블 생성
DynamoDB 콘솔에 접속하여 테이블 만들기 버튼을 클릭합니다.
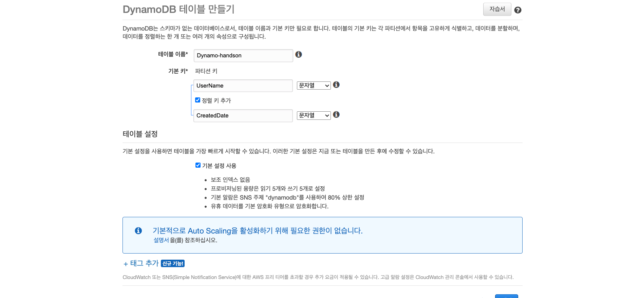
테이블 생성 화면에서 다음과 같이 값을 입력합니다.
- 테이블 이름 : Dynamo-handson
- 파티션 키 : UserName(문자열)
- 정렬 키 : CreatedDate(문자열)
- 테이블 설정 : 기본 설정 사용 체크
입력 후, 생성 버튼을 누르면 테이블이 성공적으로 생성이 완료됩니다.
이번 실습에서는 테이블 설정 항목에서 편의를 위해 기본 설정으로 테이블을 생성 하였습니다만, 테이블 설정 항목 부분에 대해 조금 더 보충적으로 설명 드리도록 하겠습니다. (조금 내용이 길 수 있으니 필요한 부분만 참고 하시면 좋을 것 같습니다)
테이블 설정에서 기본 설정 사용의 체크를 해제하면 다음과 같은 설정 항목들이 나옵니다.
- 보조 인덱스
- 읽기/쓰기 용량 모드
- 프로비저닝된 용량
- Auto Scaling
- 유휴 시 암호화
각 항목들을 하나씩 설명드리도록 하겠습니다.
보조 인덱스
보조 인덱스(Secondary Index)는 데이터를 좀 더 신속하고 유연하게 쿼리를 하기 위해 생성할 수 있습니다. 보조 인덱스의 종류는 GSI와 LSI로 나뉘어집니다.
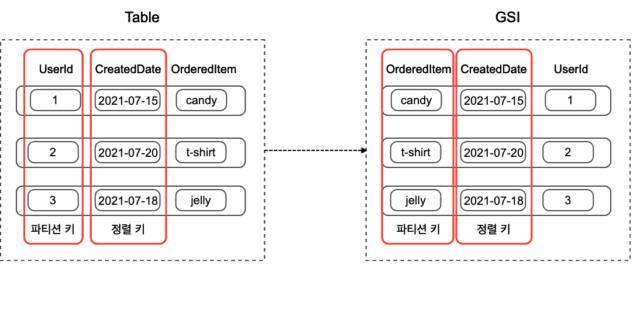
GSI(Global Secondary Index)는 위의 그림과 같이 기존 테이블과 다른 파티션 키, 정렬 키를 사용하여 쿼리를 할 수 있도록 하는 보조 인덱스입니다. 기존 테이블과는 다른 속성을 기준으로 데이터에 액세스 할 수 있어 매우 유연하게 쿼리를 하는 것이 가능합니다. 기존에 생성해놓았던 테이블에서 언제든지 생성, 삭제가 가능하고, 기존 테이블과는 별도의 공간에 생성이 되기 때문에 인덱스의 크기에는 제한이 없습니다. 다만, 별도의 공간에 생성되기 때문에 읽기/쓰기 용량을 별도로 할당을 해야합니다. (읽기/쓰기 용량에 대해서는 밑에서 자세히 설명드립니다)
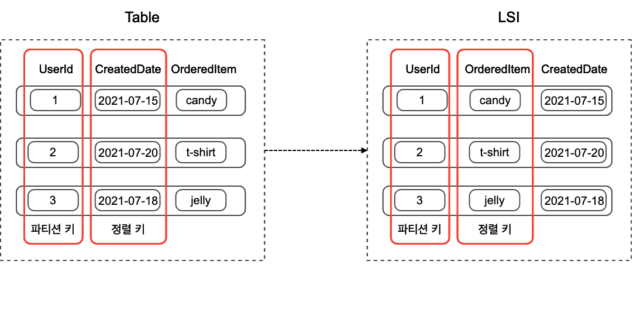
LSI(Local Secondary Index)는 테이블과 동일한 파티션 키를 가지지만, 정렬 키를 변경하여 쿼리를 할 수 있는 보조 인덱스입니다. 위의 그림에서는 알아 보기 쉽도록 GSI와 같이 별도의 공간을 차지하는 것처럼 그려놨지만, LSI는 테이블 내의 저장공간을 차지하며 테이블에 할당 된 읽기/쓰기 용량을 공유하여 소비하게 됩니다. 한 가지 중요한 점은 LSI는 테이블을 생성할 때에만 생성할 수 있고, 기존에 생성해놓았던 테이블을 대상으로 생성, 삭제하는 것이 불가능 합니다.
읽기/쓰기 용량 모드
읽기/쓰기 용량 모드에서 설정할 수 있는 모드는 읽기 및 쓰기 처리량에 대한 청구 방법과 관리 방법에 따라 Provisioned Mode, On-Demand Mode가 있습니다. 각 모드에 대해 설명 드리기 전에 읽기/쓰기 용량이 무엇인지에 대해 먼저 설명 드리도록 하겠습니다.
우선 용량 유닛(Capacity Units)이란 1초당 읽거나 쓸 수 있는 데이터의 단위를 말합니다. 읽기 용량(Read Capacity Unit 줄여서 RCU)은 초당 4KB의 처리 단위로 측정이 되며, 초당 4KB 데이터를 읽어들이는데 1RCU가 소비됩니다. RCU를 계산할 시, 4KB의 배수로 계산을 하기 때문에 1KB의 데이터를 읽는다고 해도 1RCU가 고정적으로 소비됩니다. DynamoDB에서는 데이터를 읽을 때 일관성이 유지되는 정도에 따라 Eventually Consistent Reads, Strongly Consistent Reads 두 가지의 일관성 모델을 지원합니다.
- Eventually Consistent Reads
DynamoDB 테이블에서 데이터를 가져올 때 데이터가 최신 버전이 아닐 가능성이 있는 읽기 일관성 모델입니다. DynamoDB 테이블에 데이터를 쓸 때 약 1초 정도의 지연시간이 있기 때문에, 데이터를 읽은 후 읽기 요청을 한 번 더 반복하여 최신 데이터를 가져올 수 있습니다. 1RCU 당 2회의 읽기 작업을 수행할 수 있습니다. - Strongly Consistent Reads
항상 최신 버전의 데이터를 응답하는 읽기 일관성 모델입니다. 이 모델은 1RCU 당 1회의 읽기 작업을 수행할 수 있습니다. 같은 사이즈의 데이터를 처리하는데 Eventually Consistent Reads 모델보다 더 많은 RCU가 필요함으로 가격이 더 들 수 있고, 읽어들일 때의 지연시간이 더 길 수 있습니다.
예를 들어, 7KB 크기의 항목에 대해 초당 1회 읽기 작업을 수행할 시 Eventually Consistent Reads 모델은 1RCU, Strongly Consistent Reads는 2RCU를 소비하게 됩니다. 적은 RCU를 사용하여 좀 더 많은 데이터를 처리 하고 싶은 경우에는 Eventually Consistent Reads 모델이 더 적합할 수 있겠죠. 아까 보조 인덱스인 GSI, LSI에 대해서 설명드렸습니다만, GSI에서는 Strongly Consistent Reads 모델은 지원하지 않아 Eventually Consistent Reads 모델만 사용이 가능합니다. LSI에서는 두 모델 전부 지원하기 때문에 선택하여 사용할 수 있습니다.
쓰기 용량(Write Capacity Unit 줄여서 WCU)은 초당 1KB 처리 단위로 측정이 되며, 초당 1KB 데이터를 쓰는데 1WCU가 소비됩니다. RCU의 계산 방식과 유사하게 1KB의 배수로 계산을 합니다. 만약 1.5KB의 데이터를 쓸 경우 2WCU가 소비됩니다.
자 그럼, Provisioned Mode, On-Demand Mode는 어떻게 다를까요??
On-Demand Mode는 별도 용량 계획 없이 초당 수천 건의 요청을 처리할 수 있는 유연한 용량 모드입니다. 각 읽기, 쓰기 요청에 대해 요청 당 지불 가격을 제공하여 사용한 만큼에 대해서만 비용을 지불하면 됩니다. On-Demand Mode를 사용하면 사용자가 설정을 하지 않아도 자동으로 트래픽을 모니터링 하고 읽기/쓰기 용량을 확장 또는 축소해줍니다. 애플리케이션의 트래픽이 예측 불가능한 경우, 사용한만큼만 요금을 지불하고 싶은 경우 On-Demand Mode를 사용할 수 있습니다.
Provisioned Mode는 기본 값으로 설정된 용량 모드로, 애플리케이션에 필요한 읽기/쓰기 용량을 지정하여 사용할 수 있습니다. 또한, Auto Scaling 기능을 수동으로 설정을 함으로서 트래픽에 따라 읽기/쓰기 용량을 확장 또는 축소 할 수 있습니다. 애플리케이션의 트래픽이 어느 정도 예상 가능하고, 비용 관리를 위해 용량 요구 사항을 예측할 수 있는 경우 Provisioned Mode를 사용할 수 있습니다. 또한, 프리 티어 요금제가 이용 가능합니다.
읽기/쓰기 용량 모드는 실제 지불할 요금과 관련된 항목이기 때문에 신중히 생각하고 선택할 필요가 있습니다. 각 모드에 대한 요금표는 밑의 링크에서 확인할 수 있습니다.
프로비저닝된 용량, Auto Scaling
읽기/쓰기 용량 모드에서 Provisioned Mode를 선택할 시 설정 해야할 항목들입니다. 프로비저닝된 용량 항목에서는 사용할 읽기 용량 유닛, 쓰기 용량 유닛을 설정합니다. 기본 값은 각각 5개씩이고, 용량 계산기로 한달에 예상되는 비용을 참조하는 것이 가능합니다. Auto Scaling 항목에서는 용량을 확장/축소할 기준, 최소/최대 프로비저닝 용량을 설정하는 것이 가능합니다. 읽기/쓰기 용량 모드에서 On-Demand Mode를 선택했다면 이 두 항목에 대해서는 설정할 필요가 없습니다.
유휴 시 암호화
마지막으로 암호화에 대한 항목입니다. 이 항목에서는 DynamoDB 테이블의 서버 측 암호화 설정을 선택합니다. 선택할 수 있는 항목은 다음과 같습니다.
- 기본값 : 기본적으로 DynamoDB에서 제공하는 암호화
- KMS-고객 관리형 CMK : AWS KMS 고객 마스터 키를 이용해 테이블을 암호화. 사용자의 계정에서 키를 소유 및 관리
- KMS-AWS 관리형 CMK : AWS KMS 고객 마스터 키를 이용해 테이블을 암호화. 사용자의 계정에서 키를 소유, 관리는 AWS KMS에서 수행
테이블 설정에 대한 보충 설명은 이상입니다!! 너무 길어져서 내용을 조금 줄일까 하다가 DynamoDB를 사용할 때 꼭 필요한 내용이어서 좀 길지만 쭉 적어보았습니다.. 실습으로 돌아와서 생성한 테이블에 항목을 생성하고 쿼리를 수행해봅시다!!
DynamoDB 항목 생성 및 쿼리
DynamoDB콘솔에서 아까 생성한 Dynamo-handson 테이블을 클릭하고 항목 탭을 누르면 다음과 같은 화면이 나옵니다. 여기서 항목 만들기 버튼을 클릭해 테이블에 항목을 추가할 수 있습니다.
다음과 같이 값을 입력하여 저장을 클릭합니다. 테이블 생성 시 지정한 파티션 키, 정렬 키 이외의 속성에 대해서는 + 기호를 클릭하여 추가할 수 있습니다.
이 과정을 반복해 다음과 같이 3개의 항목을 만들어보며 항목 생성에 익숙해져 봅시다!!
| UserName | CreatedDate | OrderedItem |
|---|---|---|
| Jung | 2021-07-15 | candy |
| Kim | 2021-07-21 | t-shirt |
| Park | 2021-07-18 | jelly |
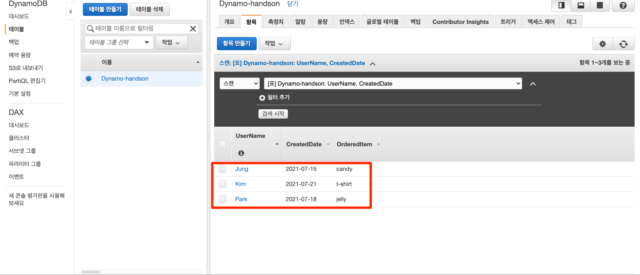
항목 추가 작업을 완료하면 이렇게 저장된 항목에 대해 UserName, CreatedDate로 정렬된 목록을 조회할 수 있습니다. 만약 저장한 데이터를 변경하고 싶을 경우에는 해당 항목을 클릭하고 값을 변경한 후 저장을 누르면 바로 변경이 가능합니다.
그럼 정렬 키인 CreatedDate 속성을 이용하여 범위 검색을 해봅시다!
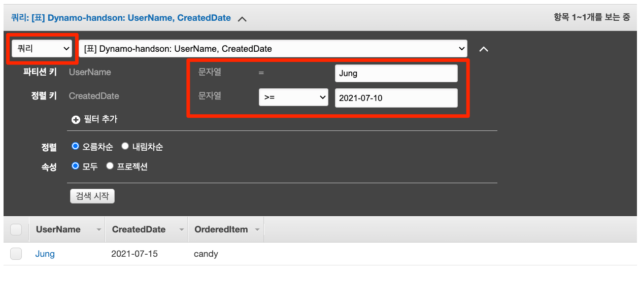
다음과 같이 드롭다운 목록을 쿼리로 변경하고, 파티션 키, 정렬 키를 이용한 조건을 입력합니다. 위의 예에서는 UserName이 Jung이고 CreatedDate가 2021-07-10 이후인 데이터를 조회하는 쿼리를 하고 있습니다. 쿼리 조건에 해당하는 항목이 있기 때문에 밑에 그 항목이 표시가 됩니다.
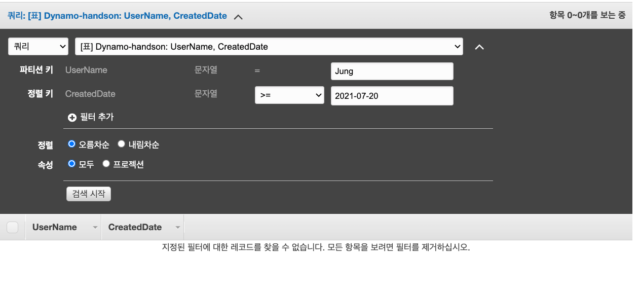
다음과 같이 UserName이 Jung이고 CreatedDate가 2021-07-20 이후의 데이터를 조회하는 쿼리를 하면 해당 조건에 맞는 데이터가 없기 때문에 아무것도 표시가 되지 않는 것을 볼 수 있습니다.
이렇게 항목을 생성하고 항목에 대해 쿼리를 하는 것까지 실습을 해보았습니다만, 여기서 혹시 기존 테이블의 파티션 키, 정렬 키 말고 다른 속성을 이용해서 쿼리를 하고 싶지는 않으신가요?? 그럴 때 필요한게 바로 아까 설명드린 GSI입니다.
DynamoDB GSI 생성 및 쿼리
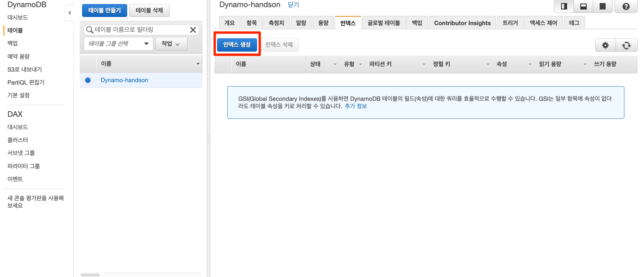
DynamoDB콘솔에서 Dynamo-handson테이블을 클릭하고 인덱스 탭을 클릭합니다. 여기서 인덱스 생성 버튼을 눌러 GSI를 생성할 수 있습니다.
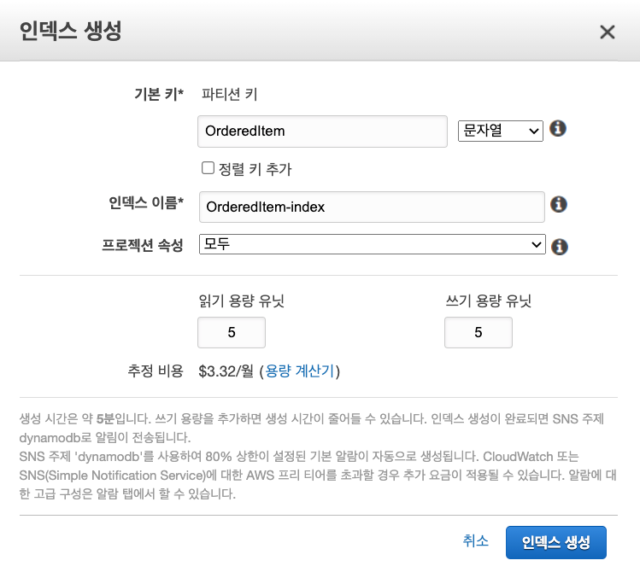
여기서 인덱스에 새롭게 지정할 파티션 키, 정렬 키, 인덱스 이름, 프로젝션 속성, 읽기/쓰기 용량 유닛을 설정하는 것이 가능합니다. 프로젝션 속성이란 인덱스를 이용해 쿼리를 했을 때 반환될 속성을 지정하는 부분입니다. 여기서는 OrderedItem 속성을 파티션 키로 하는 인덱스를 만들고 있습니다. 정렬 키는 생략하고 나머지는 기본값으로 설정을 하겠습니다. 설정이 끝나면 인덱스 생성을 클릭합니다.

잠시 기다리면 생성한 GSI가 활성화 되고, 사용할 준비가 완료됩니다. 그럼 생성한 GSI를 활용하여 쿼리를 해봅시다.
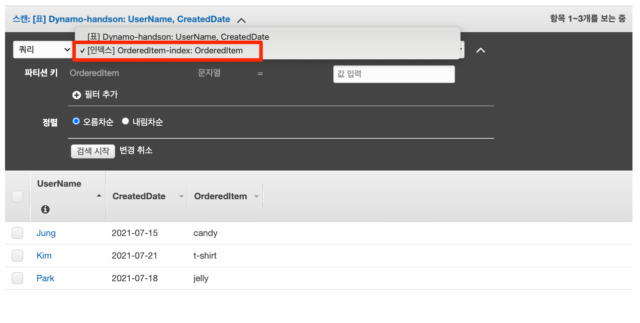
아까와 같이 항목 탭에서 드롭다운 목록을 쿼리로 변경하고 새로 생긴 [인덱스]OrderedItem-index:OrderedItem을 선택합니다.

이제 테이블에서 쿼리를 할 때와 다른 속성으로 쿼리를 하는 것이 가능합니다. 위의 예에서는 방금 GSI의 파티션 키로 지정한 OrderedItem 속성을 이용해 OrderedItem이 jelly인 항목을 쿼리하고 있는 것을 볼 수 있습니다. 아까 테이블에서 쿼리를 할 때는 OrderedItem 속성을 기준으로 쿼리를 하는 것이 불가능했지만, GSI를 만듦으로써 가능해지게 되었습니다. 경우에 따라서는 매우 편리한 기능이겠죠?
마지막으로
지금까지 DynamoDB를 사용한 간단한 실습과 함께 주요 개념을 설명드렸습니다!!
이번 실습에서는 AWS Management Console을 사용했지만, 심화 과정 느낌으로 AWS CLI를 이용해 오늘의 실습 내용을 해보는 것도 좋다고 생각합니다. AWS CLI를 사용하면 AWS Management Console에서 클릭 한 번으로 설정할 수 있었던 작업들을 전부 쉘을 통한 명령어로 수행하기 때문에 입문자 분들이 하기에는 조금 어려울 수도 있습니다. 하지만, 그만큼 수행하고 있는 작업들에 대한 이해도가 높아지는 것도 사실입니다. AWS CLI를 사용하면 작업을 하는데 필요한 파라미터들을 전부 작성 해주어야하기 때문에 각 작업에 어떠한 파라미터가 필요한지 확실히 인지를 하며 작업을 할 수 있겠죠. 그리고 AWS CLI에서만 제공을 하는 기능도 있기 때문에 그 때를 대비하여 미리 익숙해지는 것도 AWS를 공부하는 좋은 방법이라고 생각합니다.
그럼 블로그는 이상입니다!! AWS 입문자 분들이 대충이라도 DynamoDB가 어떤 서비스인지 감을 잡는데 참고가 되었다면 좋겠네요 ㅎㅎ 다음에도 좋은 주제로 찾아뵙도록 하겠습니다. 감사합니다.













