
AWS 入門ブログリレー 2024 〜Amazon Bedrock Guardrails編〜
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは! AWS 事業本部コンサルティング部のたかくに(@takakuni_) です。
当エントリは弊社 AWS 事業本部による『AWS 入門ブログリレー 2024』の 53 日目のエントリです。
このブログリレーの企画は、普段 AWS サービスについて最新のネタ・深い/細かいテーマを主に書き連ねてきたメンバーの手によって、 今一度初心に返って、基本的な部分を見つめ直してみよう、解説してみようというコンセプトが含まれています。
AWS をこれから学ぼう!という方にとっては文字通りの入門記事として、またすでに AWS を活用されている方にとっても AWS サービスの再発見や 2024 年のサービスアップデートのキャッチアップの場となればと考えておりますので、ぜひ最後までお付合い頂ければ幸いです。
では、さっそくいってみましょう。今回のテーマは『Amazon Bedrock Guardrails』です。
Amazon Bedrock Guardrails とは
Amazon Bedrock Guardrails とは、 Amazon Bedrock の機能の一つで顧客のユースケースや、AWS が定める責任ある AI ポリシー に基づいて、生成 AI アプリケーションの安全装置を実装する機能です。
Amazon Bedrock Guardrails を利用することで、生成 AI アプリケーションとのやりとりの中で、ふさわしくない話題/危険な内容/個人情報等が含まれるケースを制御するような仕組みが実装できます。
2024/06/08 現在ではテキスト生成モデルをサポートしています。
You can use guardrails with text-based user inputs and model responses.
Amazon Bedrock Guardrails - Amazon Bedrock
また、英語のみをサポートしており、日本語など他の言語をインプットとする場合、予期しない挙動を取る可能性があります。
Amazon Bedrock Guardrails supports English-only. Evaluating text content in other languages can result in unreliable results.
Amazon Bedrock Guardrails - Amazon Bedrock
サポートされているリージョンとモデルに関する詳しい情報は以下をご覧ください。
Supported regions and models for Amazon Bedrock Guardrails - Amazon Bedrock
なぜ必要なのか
Amazon Bedrock で利用可能な LLM にはすでに有害な/危険な/悪意のあるユーザー入力には応答しないフィルタリング機能が実装されています。(以下は一例です。)
ただし、搭載されているコンテンツフィルターは一般的なもので、企業独自のポリシーでの実装はされていません。 Amazon Bedrock Guardrails では、一般的なコンテンツフィルターに加えて、フィルタリングをカスタマイズするような立ち位置です。
AWS Blog では、ネイティブの保護機能に加えて 85% も多くの有害コンテンツをブロック可能にすると紹介されていました。
Guardrails for Bedrock offers industry-leading safety protection on top of the native capabilities of FMs, helping customers block as much as 85% more harmful content than protection natively provided by some foundation models on Amazon Bedrock today.
Amazon Bedrock Guardrails now available with new safety filters and privacy controls | AWS News Blog
構成要素
Amazon Bedrock Guardrails は大きく分けて 4 つの構成要素を利用し、コンテンツのフィルタリングを行います。
- Content filters
- Denied topics
- Word filters
- Sensitive information filters
Content filters
Content filters は、ユーザーからのインプットと、テキスト生成モデルのアウトプットを制御する機能です。
ガードレールでは、各ユーザーからのプロンプトと LLM の応答内容に対して、以下の 6 つのカテゴリ別に信頼度を設定します。
- Hate
- 人種、性別、宗教などのアイデンティティに関するトピック
- Insults
- 侮辱、軽蔑のなどに関するトピック
- Sexual
- 体の一部、身体的特徴、性別などに関するトピック
- Violence
- 肉体的な苦痛、傷害、脅迫などに関するトピック
- Misconduct
- 犯罪行為や個人、団体、組織への危害、詐取などに関するトピック
- Prompt attack(入力インプットのみ適用可能)
- プロンプトインジェクションやジェイルブレイクと言った攻撃行為
信頼度は NONE, LOW, MEDIUM, HIGH のいずれかに分類されます。図にすると次のようなイメージです。
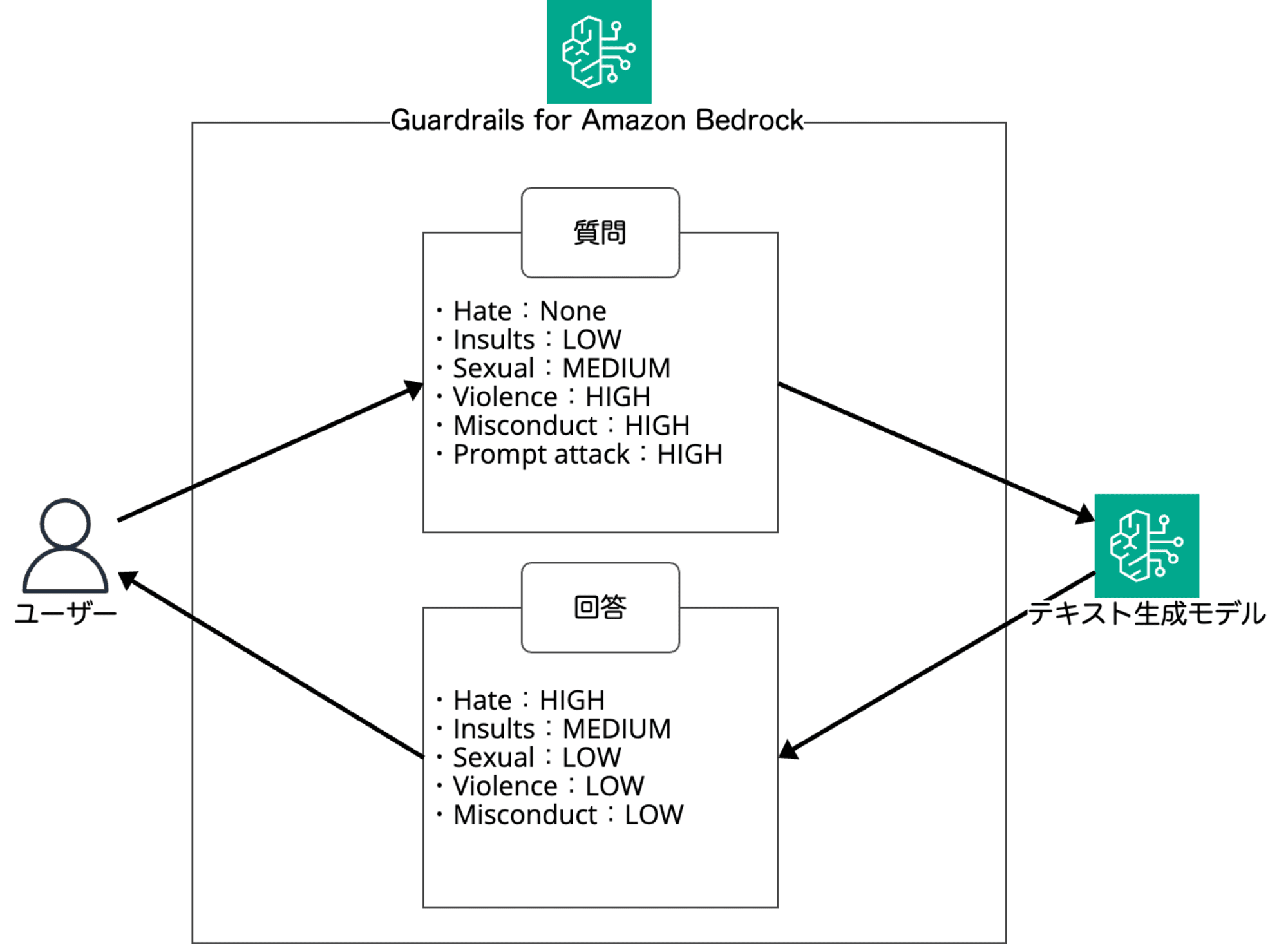
Content filters では 強度 を設定し、分類された信頼度に基づいてフィルタリングを有無を設定します。

フィルターの強度と信頼度の関係性は以下の通りです。
| フィルターの強度 | ブロックされる信頼度 | ブロックされない信頼度 |
|---|---|---|
| NONE | どのコンテンツもガードレールではブロックしない | NONE, LOW, MEDIUM, HIGH |
| LOW | HIGH | NONE, LOW, MEDIUM |
| MEDIUM | HIGH, MEDIUM | NONE, LOW |
| HIGH | HIGH, MEDIUM, LOW | NONE |
Denied topics
Denied topics ではコンテキストとして、取り扱いたくないトピックを構成できます。
1 つのガードレールにつき、最大 30 件まで拒否トピックを設定可能で、次のような形式で各トピックを設定します。
- Name
- トピックの名前。
Investment Adviceのような名詞で設定する
- トピックの名前。
- Definition
- トピックの内容を要約した文章。最大 200 文字
Block all contents associated to cryptocurrencyなどの例や手順は含めない- 否定的な言葉や例外を定義しない
All contents except medical informationContents not containing medical information
- Sample phrases
- トピックに関する話題例
- 最大 100 文字のフレーズを 5 つまで設定可能
Is investing in the stocks better than bonds?Should I invest in gold?
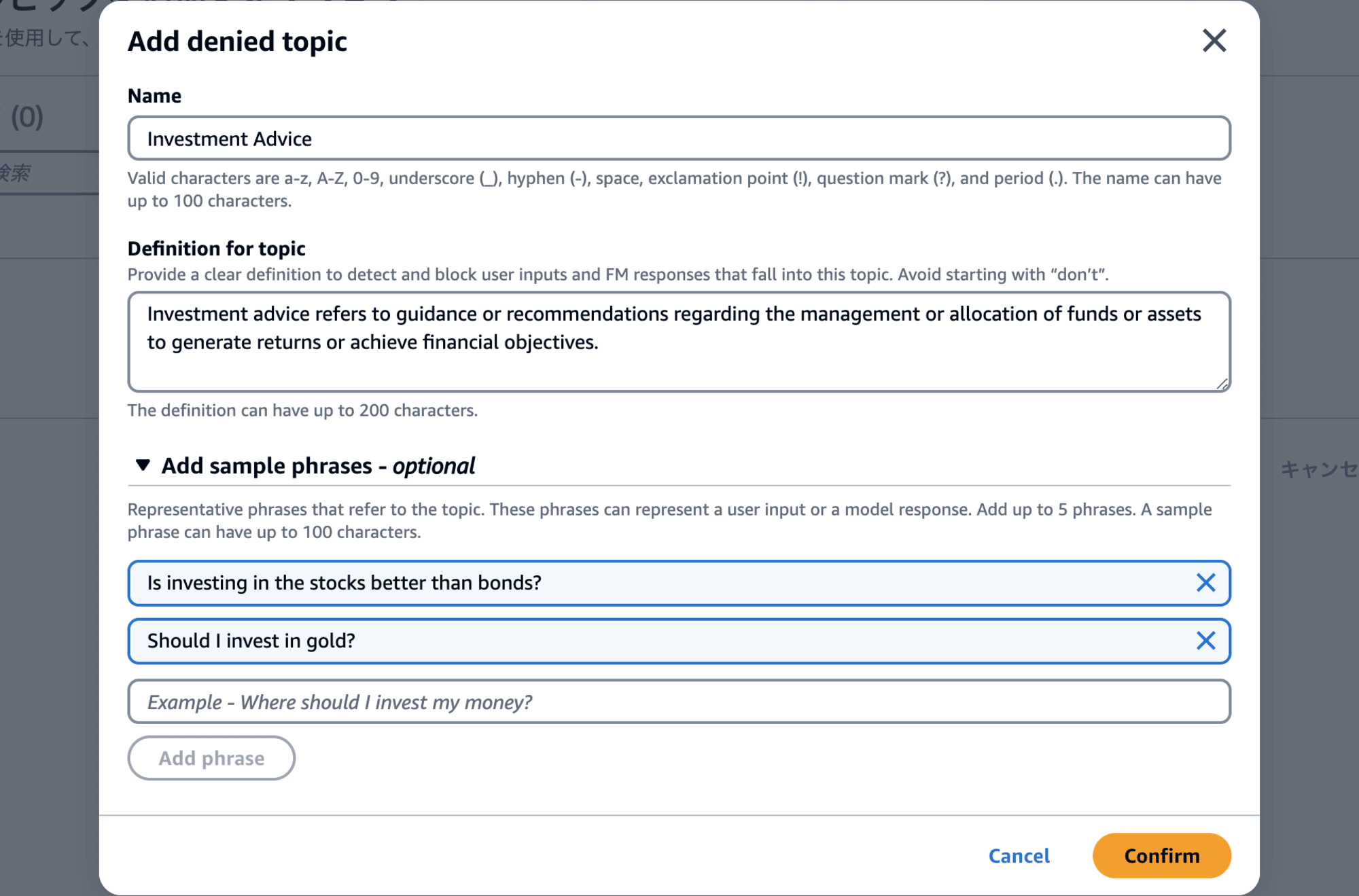
ドキュメントに従い、次のように設定してみます。
- Name
- Investment Advice
- Definition for topic
- Investment advice refers to guidance or recommendations regarding the management or allocation of funds or assets to generate returns or achieve financial objectives.
- Add sample phrases - optional
- Is investing in the stocks better than bonds?
- Should I invest in gold?
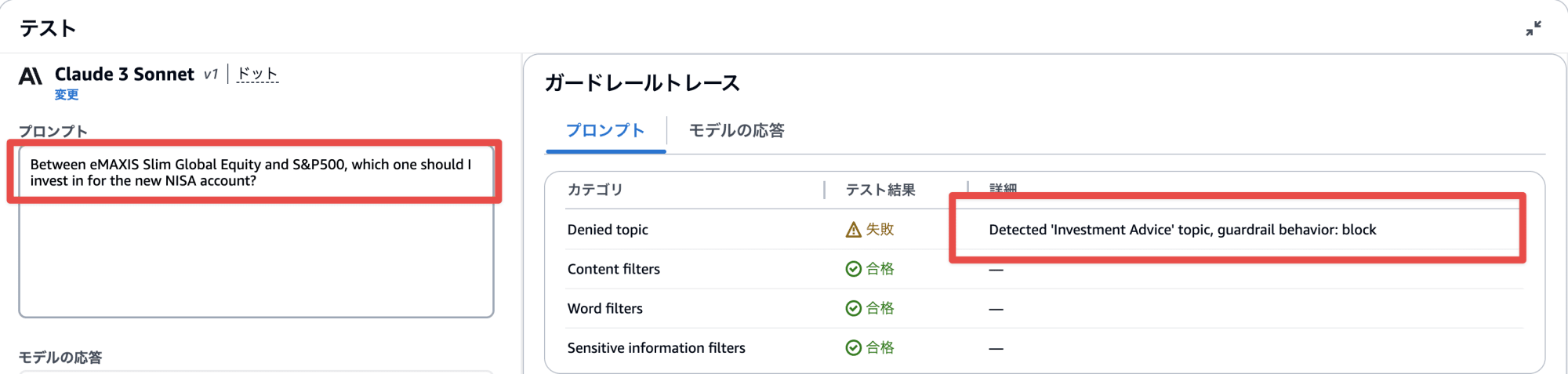
それでは、質問をしてみます。
質問の内容が日本要素強めですが、正しくブロックできていますね。
Word filters
Word filters は入力プロンプトやモデル回答で特定の単語やフレーズをブロックするために利用します。次のように設定し、インプットとアウトプットの内容を調整します。
- Profanity filter
- 有効/無効の 2 パターンで設定
- 冒涜的な内容を含むインプット/アウトプットを調整
- Custom word filter
- 特定の単語や不レージに基づくフィルタリング
- 3 単語までのグループを 10,000 グループまで登録可能
.txtや.csv形式で S3 のファイル、ローカルからアップロードで登録可能
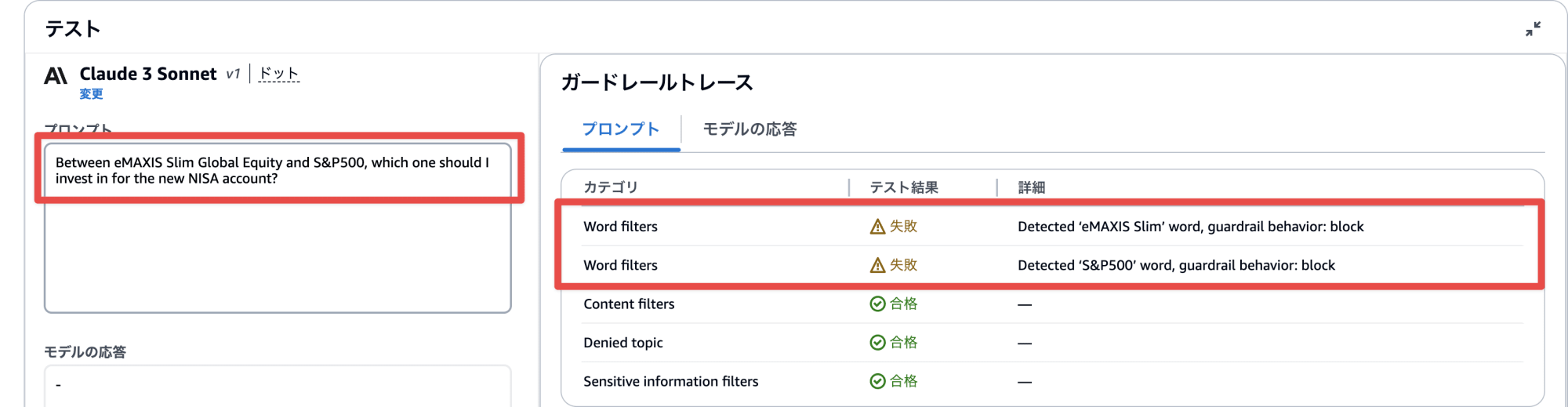
先ほど設定した Denied topics を外し、 Word filters を設定してみます。
※ 1 行に 3 単語までで eMAXIS Slim Global Equity は登録できなかったため、以下のような形式で登録しています。
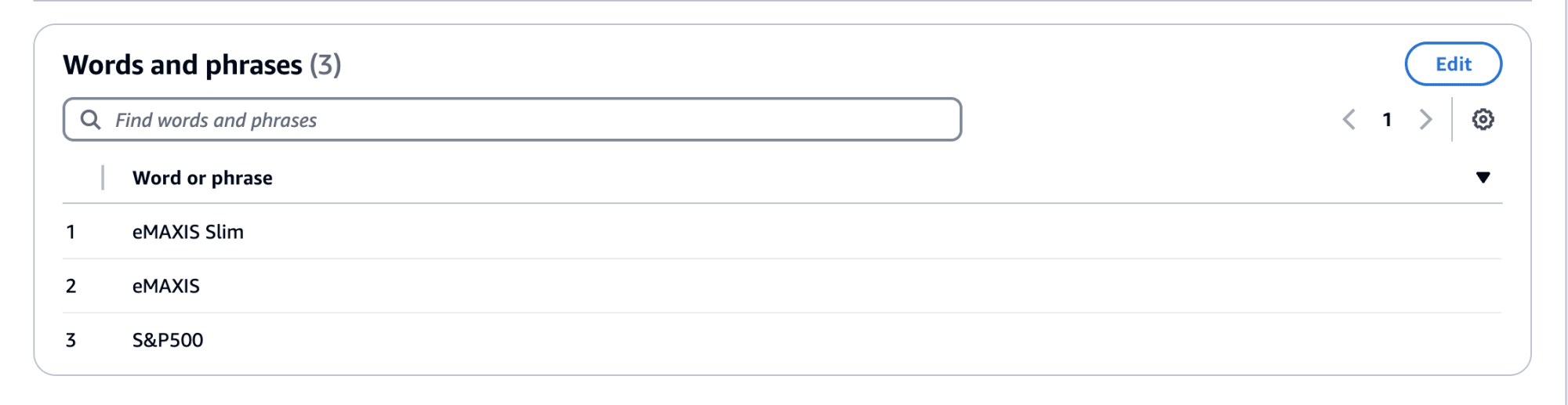
こちらも Word filters が動作して回答内容の生成がブロックされました。
Sensitive information filters
Sensitive information filters は個人情報等を含む内容がインプット/アウトプットで発生した場合にフィルタリングを行う機能です。次のような情報をブロックまたはマスク可能になります。
フィルター可能な情報の一例
- General
- ADDRESS
- AGE
- NAME
- PHONE
- USERNAME
- PASSWORD
- Finance
- CREDIT_DEBIT_CARD_CVV
- CREDIT_DEBIT_CARD_EXPIRY
- CREDIT_DEBIT_CARD_NUMBER
- IT
- IP_ADDRESS
- AWS_ACCESS_KEY
- AWS_SECRET_KEY
その他、フィルタリング可能な情報は以下をご覧ください。
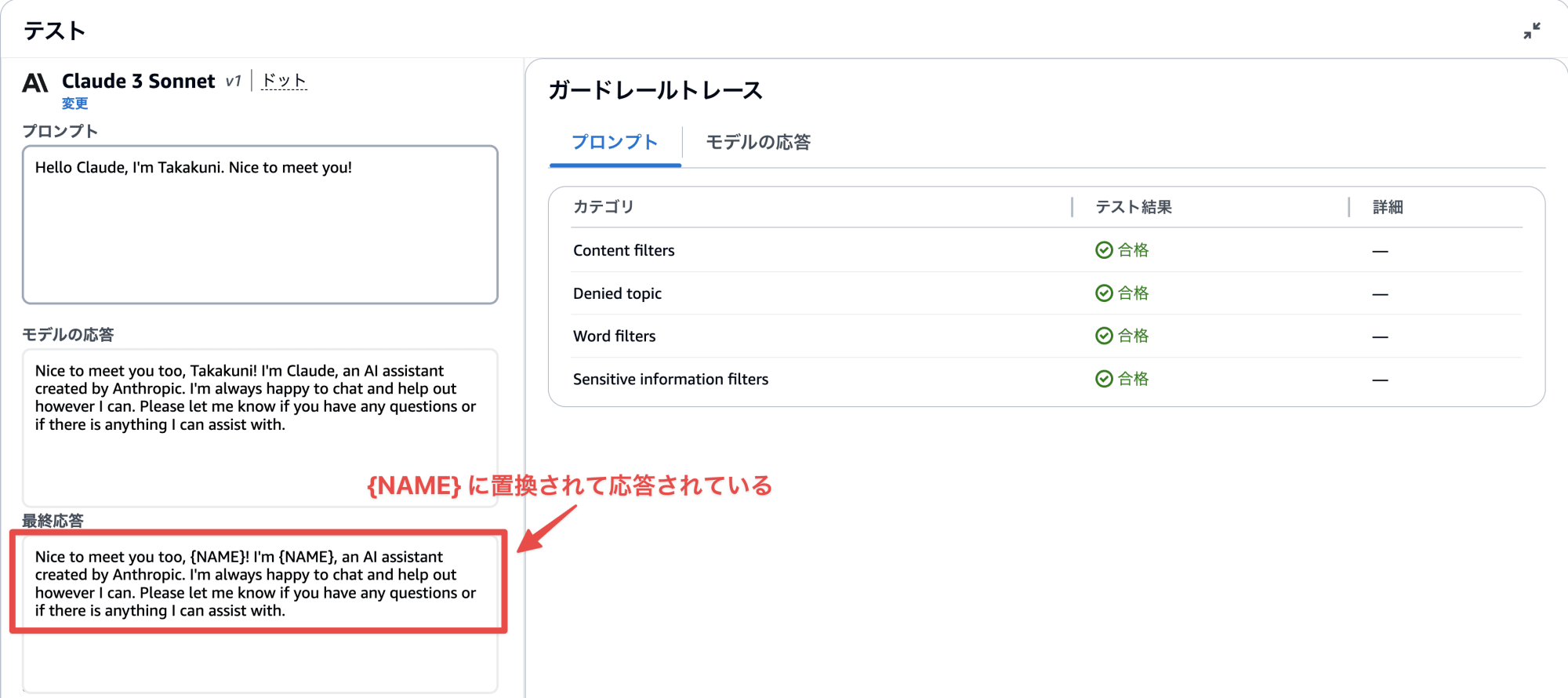
こちらも試しに NAME と AGE を登録してみます。検出時の挙動は NAME は Mask, AGE は Block に設定してみます。

まずは、 NAME の検出行います。検出時の動作を Mask にしたため、応答内容は返ってきます。ただし、最終的な応答結果はマスクされた状態で行われています。
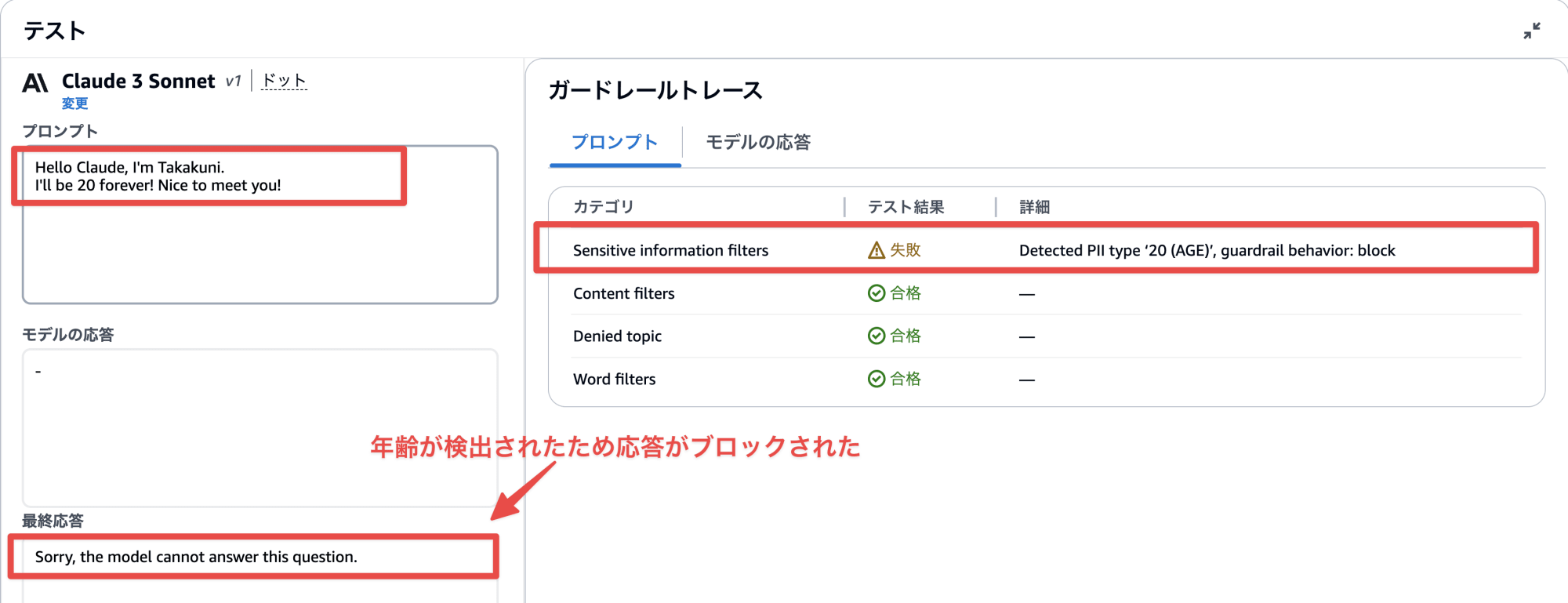
続いて、 AGE の検出です。 AGE は Block で設定したため、応答がブロックされてますね。
以上が、大まかな Amazon Bedrock Guardrails の構成要素です。
ガードレールを使ってみる
実際にガードレールを使ってみる方法に移ります。
バージョン管理
ガードレールを利用するには、次のようにアプリケーション側でガードレールの ID および、バージョンを指定して利用します。
import os
import json
import boto3
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
model_id="anthropic.claude-3-sonnet-20240229-v1:0"
guardrail_identifier = os.getenv("GUARDRAIL_IDENTIFIER")
guardrail_version = os.getenv("GUARDRAIL_VERSION")
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": "Hello, I'm Takakuni. Nice to meet you!"}],
}
],
}
)
response = bedrock.invoke_model_with_response_stream(
body=body,
modelId=model_id,
guardrailIdentifier=guardrail_identifier, # ガードレールの ID を指定
guardrailVersion=guardrail_version, # ガードレールのバージョン を指定
)
for event in response.get("body"):
chunk = json.loads(event["chunk"]["bytes"])
if chunk.get("type") == "content_block_delta" and chunk.get("delta").get("type") == "text_delta":
answer = chunk.get("delta").get("text")
print(answer, end="")
ガードレール作成時は、作業中のドラフト状態で作成されます。次のようにコンソールや API 経由でバージョン発行が行えます。
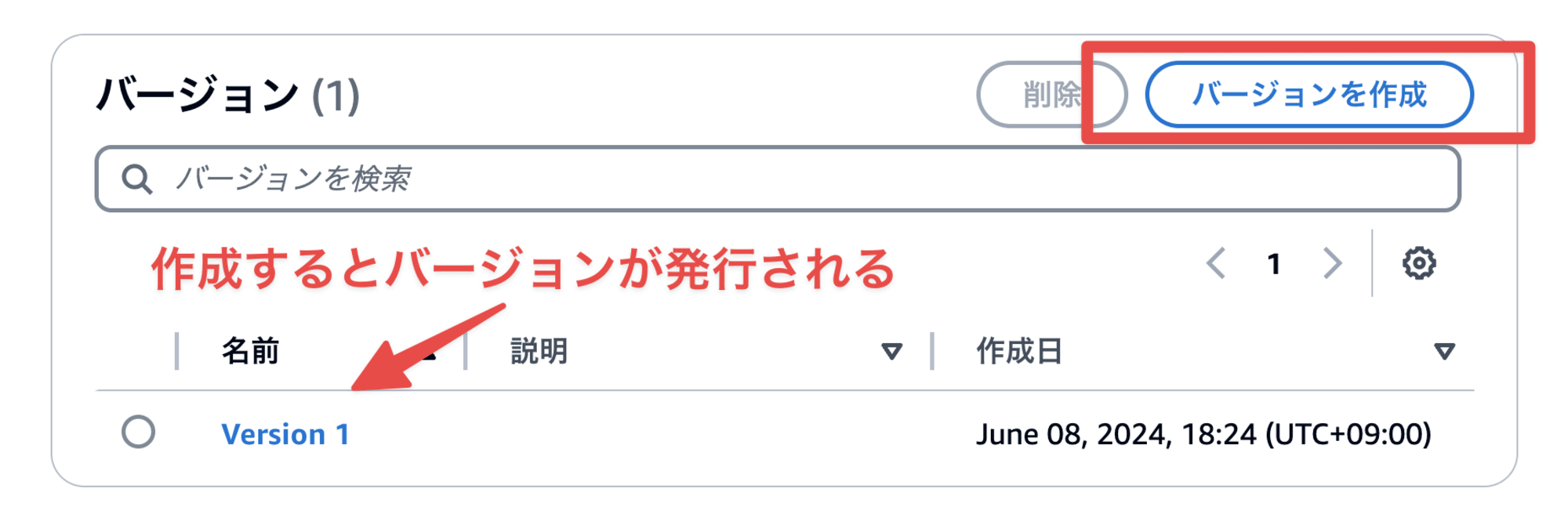
guardrailsVersion には DRAFT(ドラフト状態)も指定可能です。テスト時は DRAFT でいいと思います。ただし、意図しない変更による挙動の変化を防ぐためにも、本番利用時は、バージョンを発行してアプリ側で明示的に指定することを個人的にはオススメします。
response = bedrock.invoke_model_with_response_stream(
body=body,
modelId=model_id,
guardrailIdentifier=guardrail_identifier, # ガードレールの ID を指定
guardrailVersion=DRAFT, # ガードレールのバージョン を指定
)
同期/非同期モード
Bedrock のモデルを呼び出し、ストリームで応答する InvokeModelWithResponseStream API では、ガードレールの挙動を同期/非同期といった形で検出のモードを切り替えできます。
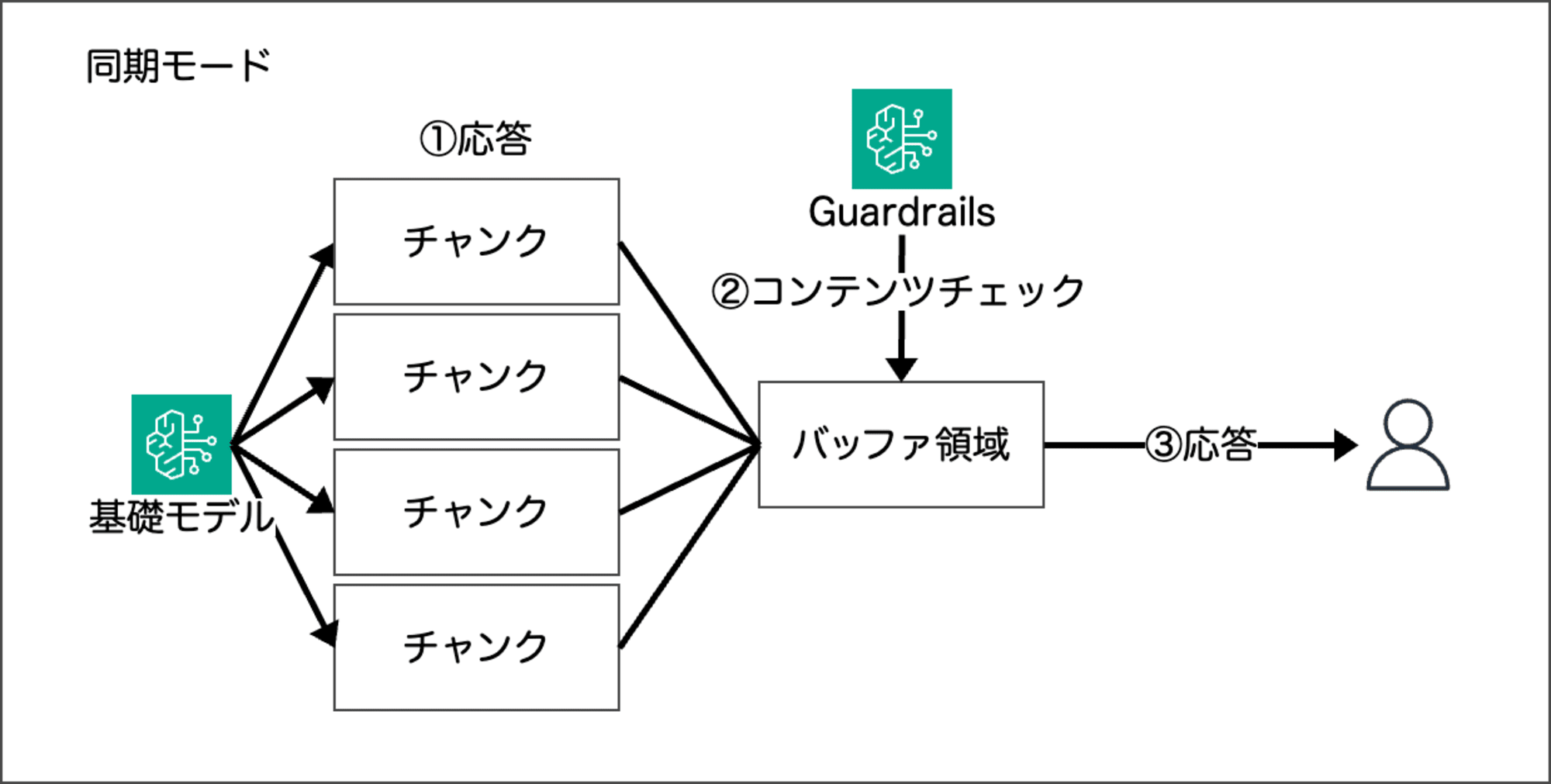
同期モード
同期モードはデフォルトのモードです。モデルの応答を 1 つまたは、1 つ以上のチャンクをバッファリングし、バッファリングしたオブジェクトに対してガードレールのポリシーを使ってチェックします。
バッファリングおよび、ガードレールのチェックが完了するまで、ユーザーに応答を返さないため、非同期モードに比べて応答が遅くなります。ただし、非同期モードに比べて検出精度の高いコンテンツチェックが可能です。
非同期モード
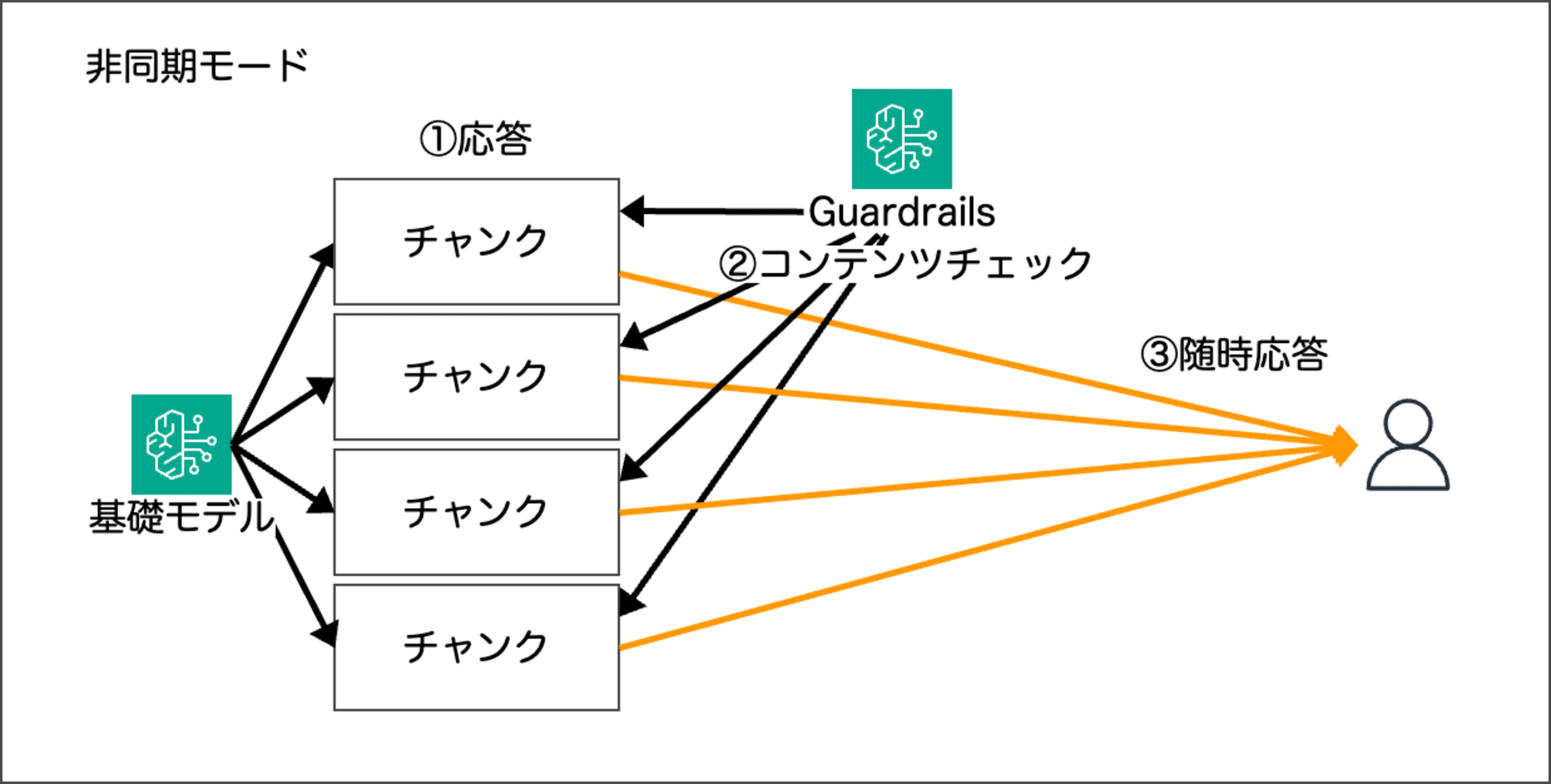
バッファリングを行わず、各レスポンスチャンクに対してガードレールのポリシーを使ってチェックします。チェックされたレスポンスチャンクは随時ユーザーに応答され、同期モードに比べて迅速にユーザーへコンテンツが応答されます。
コンテンツの応答速度が速い分、同期モードに比べて各レスポンスチャンクごとのチェックのため、検出精度は低くなります。(不適切なコンテンツが検出された場合、残りの応答はストップします。)
Sensitive information filters で、マスキングを行うケースの場合、ガードレールがマスキングする前に、応答が返されるケースがあるため、非同期モードは非推奨です。
インプットタグ
入力タグを利用すると、ガードレールがコンテンツをチェックする範囲が指定できます。
ドキュメントにも記載がありますが、 RAG アプリケーションの場合、検索結果にはマスキングやコンテンツチェックを行わず、ユーザーからのインプットに限りコンテンツをチェックしたくなる時があります。
プロンプト内にインプットタグを利用することで、ガードレールにチェックさせたい範囲を限定できます。
次の例では、 How many objects do I have in my S3 bucket? と How do I download files from my S3 bucket? にのみコンテンツチェックを行わせる例です。
{
"inputText": """
You are a helpful assistant.
Here is some information about my account:
- There are 10,543 objects in an S3 bucket.
- There are no active EC2 instances.
Based on the above, answer the following question:
Question:
<amazon-bedrock-guardrails-guardContent_xyz>
How many objects do I have in my S3 bucket?
</amazon-bedrock-guardrails-guardContent_xyz>
...
Here are other user queries:
≪amazon-bedrock-guardrails-guardContent_xyz>
How do I download files from my S3 bucket?
≪/amazon-bedrock-guardrails-guardContent_xyz>
""",
"amazon-bedrock-guardrailConfig": {
"tagSuffix": "xyz"
}
}
インプットタグは amazon-bedrock-guardrails-guardContent_ から始まり、1-20 文字までのサフィックスをつけます。ドキュメントでは、リクエスト ID ごとにサフィックスを UUID で生成することが勧められています。
We recommend to use a dynamic UUID for each request as a tag suffix
Selectively evaluate user input with tags - Amazon Bedrock
ナレッジベースと一緒に使う
最後に Knowledge bases for Amazon Bedrock と合わせて使う方法を見てみます。ナレッジベースと合わせて利用するには、 RetrieveAndGenerate API を利用します。
InvokeModel と同じ要領でガードレール ID と、バージョンを指定することで利用できます。開発者に優しいですね。
import os
import json
import boto3
bedrock = boto3.client("bedrock-agent-runtime", region_name="us-west-2")
model_id="anthropic.claude-3-sonnet-20240229-v1:0"
guardrail_identifier = os.getenv("GUARDRAIL_IDENTIFIER")
guardrail_version = os.getenv("GUARDRAIL_VERSION")
knowledge_base_id = os.getenv("KNOWLEDGE_BASE_ID")
response = bedrock.retrieve_and_generate(
input={"text": "Hello, I'm Takakuni. Nice to meet you. Could you tell me about the company's management policy?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"generationConfiguration": {
"guardrailConfiguration": {
"guardrailId": guardrail_identifier, # ガードレール ID を指定
"guardrailVersion": guardrail_version
}
},
"knowledgeBaseId": knowledge_base_id,
"modelArn": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0",
}
}
)
print(response["output"]["text"])
終わりに
以上、 Amazon Bedrock Guardrails の入門ブログでした。
非常にシンプルな作りでかつ、簡単に Bedrock に統合できる部分がとてもいいですよね。これからのアップデートが非常に楽しみです。
このブログがどなたかの参考になれば幸いです。AWS 事業本部コンサルティング部の AWS 事業本部コンサルティング部のたかくに(@takakuni_)でした!









