![[プレビュー] Knowledge Bases for Amazon BedrockがS3以外のデータソースにも対応しました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[プレビュー] Knowledge Bases for Amazon BedrockがS3以外のデータソースにも対応しました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
みなさん、こんにちは!
福岡オフィスの青柳です。
Amazon BedrockでRAGを実現する機能である「Knowledge Bases for Amazon Bedrock」が、S3以外のデータソースをサポートしました。
なお、記事執筆時点 (2024.07.11) ではプレビュー機能となっています。
新たに対応したデータソースの種類
従来のKnowledge Bases for Amazon Bedrockはデータソースとして「S3」のみに対応していましたが、今回のアップデート (プレビュー) で新たに4種類のデータソースに対応するようになりました。
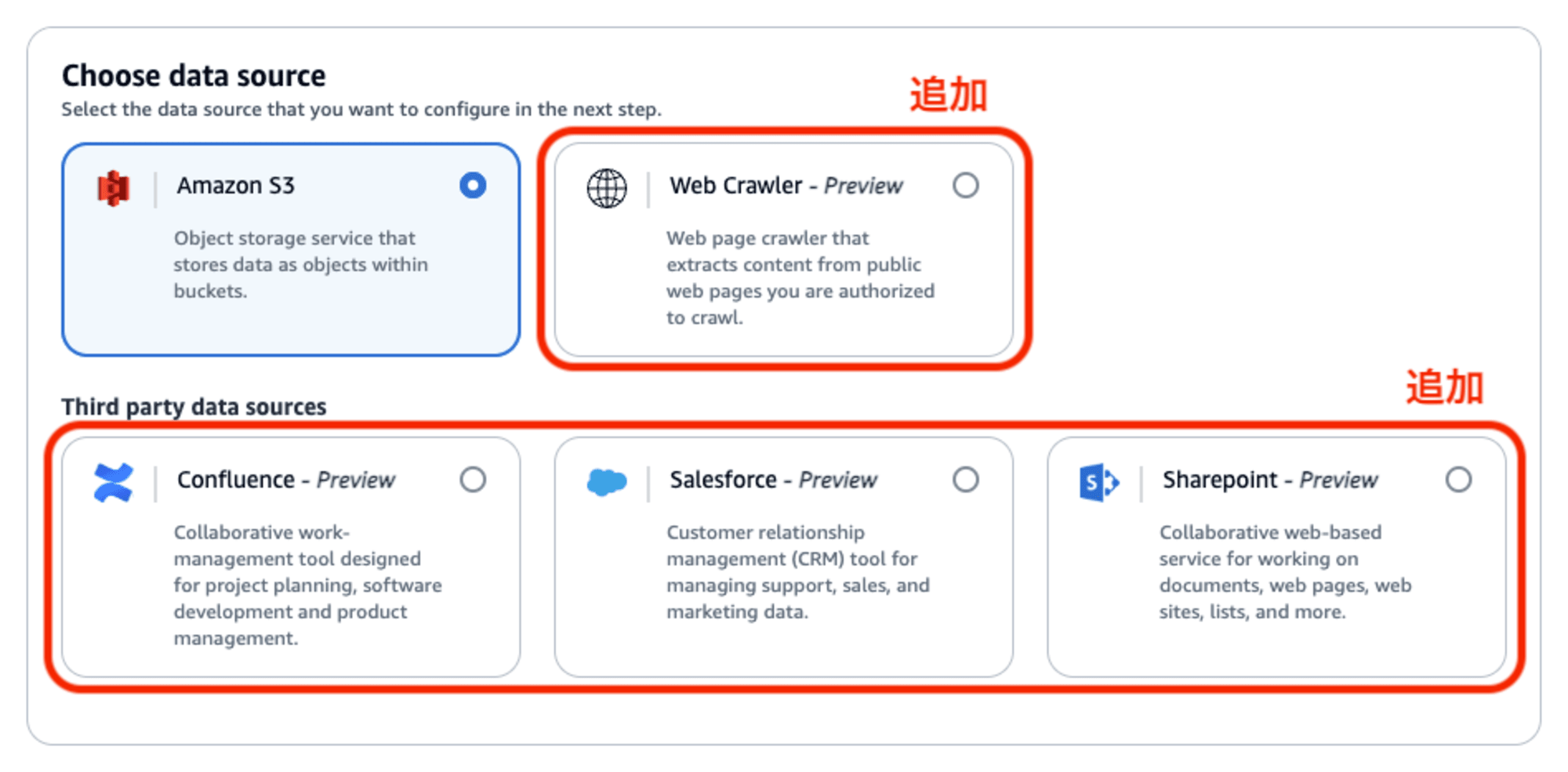
新たに対応したデータソースの種類:
- Webクローラー
- Atlassian Confluence
- Microsoft SharePoint
- Salesforce
今回の記事では、これらのうち「Webクローラー」について実際に使ってみましたので、設定方法を紹介したいと思います。
データソース「Webクローラー」の設定方法
データソースはナレッジベースを作成した後で追加登録することもできますが、ここでは、ナレッジベースを新規作成する際にデータソースとして「Webクローラー」を設定する手順を紹介します。
なお、今回は「東京リージョン」を使用しています。
データソースの種類の選択
ナレッジベース作成のウィザード画面で、最初のページでデータソースを選択する項目が追加されています。
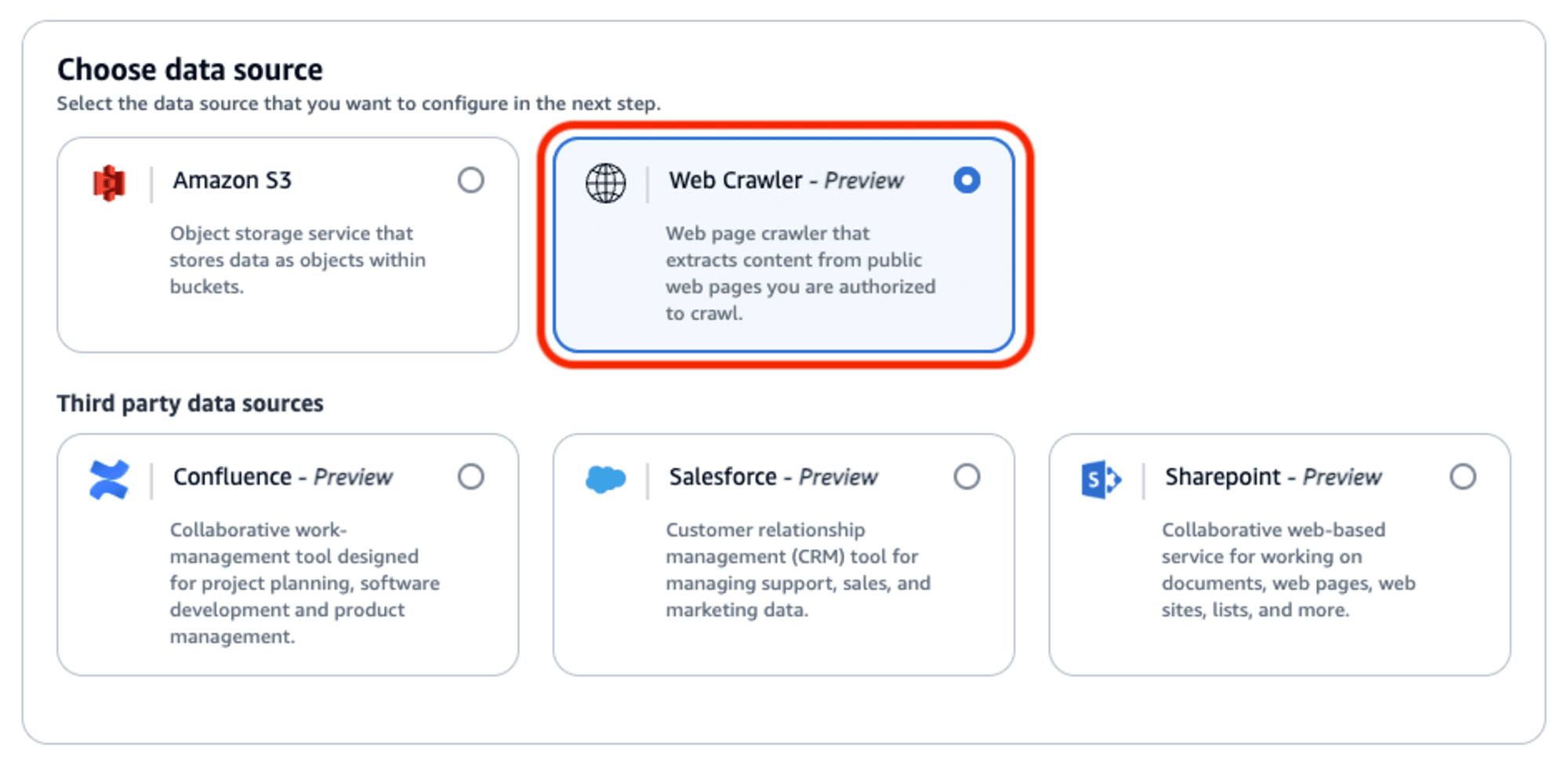
ここで「Web Crawler」を選択します。
データソース「Webクローラー」に関する設定
次のページで、データソース「Webクローラー」に関する設定を行なっていきます。
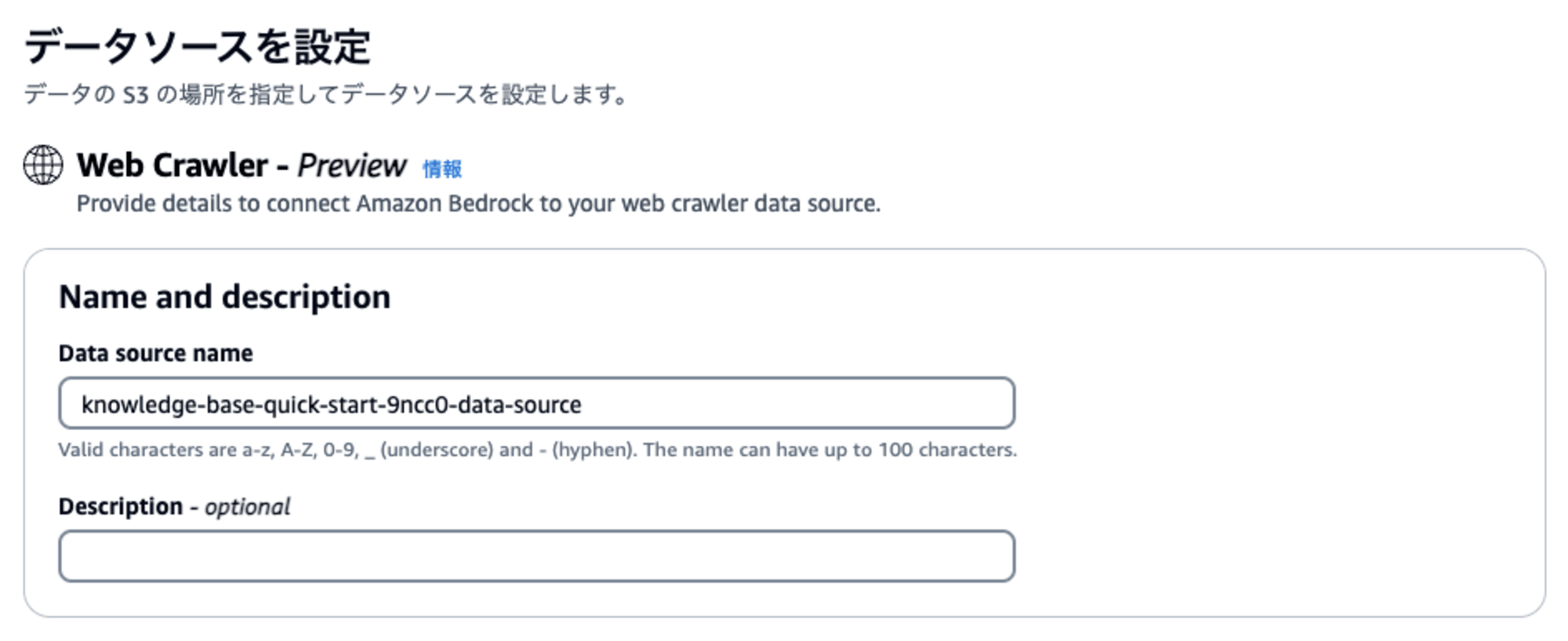
最初に、データソースの名前と説明を入力します。(これは従来と同じ)
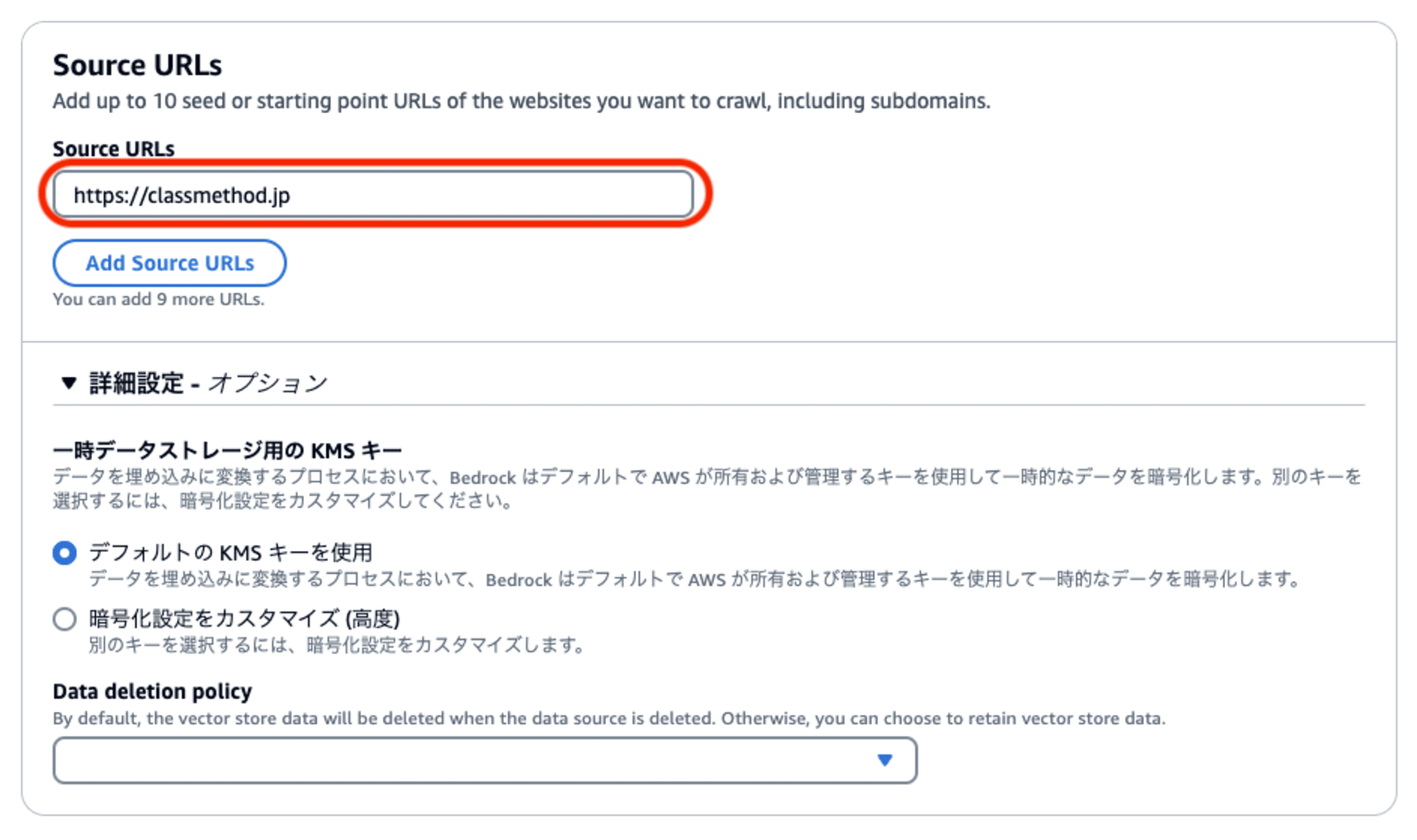
Webクローリング実行対象の基準となる「ソースURL」を指定します。最大で10個まで設定できます。
「詳細設定」を展開すると、「データ取り込み中に使用する一時データストレージ」の暗号化について設定できます。
ここでは、初期値の「デフォルトのKMSキーを使用」のままにしました。
暗号化設定をカスタマイズする場合は、KMSへアクセスするためのポリシー設定が必要になります。
データインジェスト時の一時データストレージの暗号化
続いて、データソースの「同期 (Sync)」について設定します。
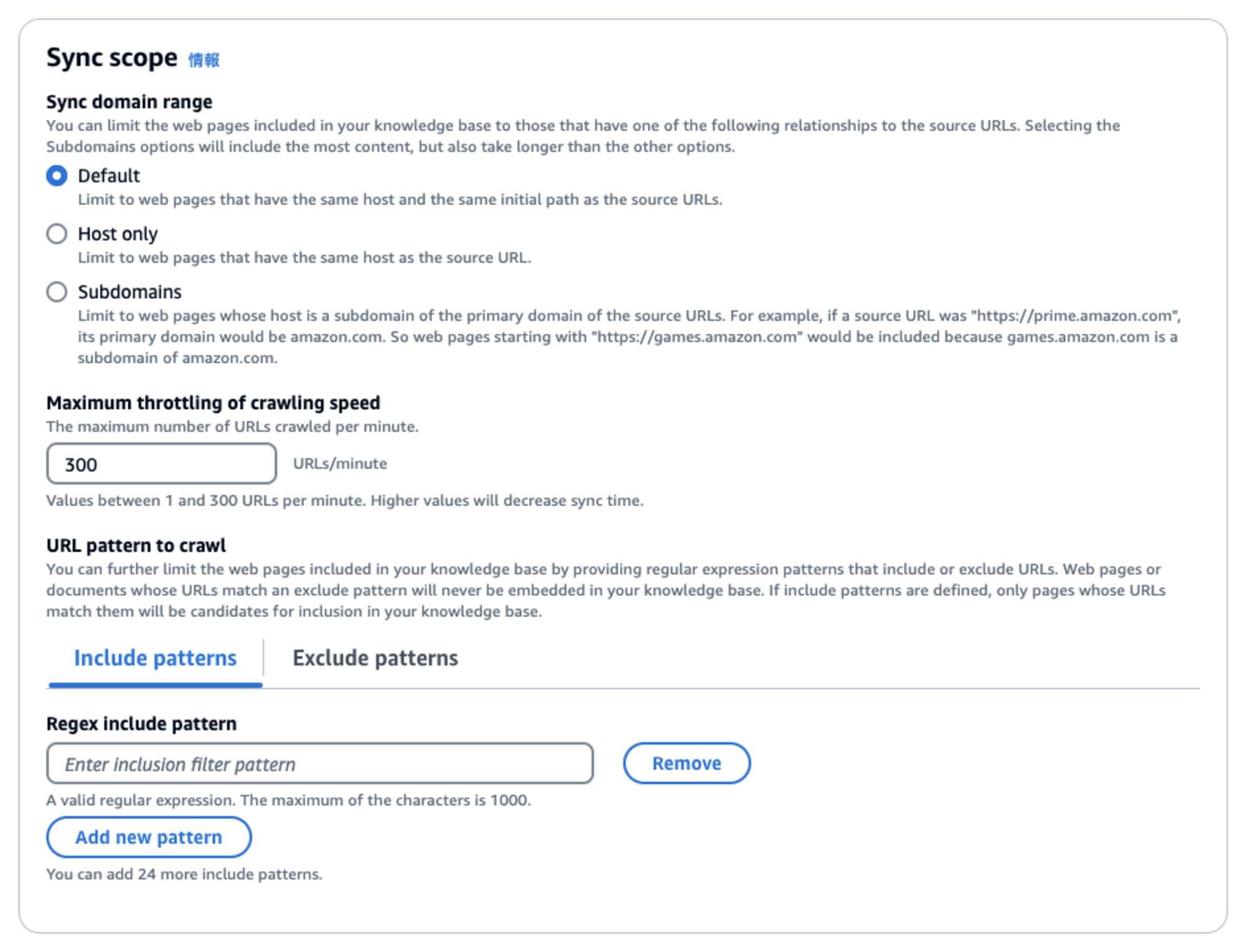
項目 「同期ドメイン (Sync domain range)」 で、クロール対象の範囲を指定します。
- Default: ソースURLとパスが一致するWebページ
- Host only: ソースURLとドメインが一致するWebページ
- Subdomains: ソースURLとプライマリドメインが一致するWebページ
選択オプションの説明が少し分かり辛いので、例で説明しましょう。
ソースURLが https://www.example.com/aaa/ の場合、選択オプションによってクロール対象範囲は以下のようになります。
| WebページのURL | Default | Host only | Subdomains |
|---|---|---|---|
https://www.example.com/aaa/bbb(ソースURLとパスが一致) |
対象 | 対象 | 対象 |
https://www.example.com/foo/bar(ソースURLとパスが異なるがドメインは一致) |
対象外 | 対象 | 対象 |
https://support.example.com/(ソースURLとプライマリドメインが一致) |
対象外 | 対象外 | 対象 |
「Default」→「Host only」→「Subdomains」といくにつれてクロール対象範囲が広がりますが、その分、クロールの所要時間も長くなります。
ここでは、初期値の「Default」のままにしました。
項目 「クローリング速度の最大スロットリング (Maximum throttling of crawling speed)」 で、1分間にクローリングを行う頻度を指定します。
- 設定可能値: 1 〜 300 (URLs/分)
クローリング速度を速く (数値を小さく) するほどクロール実行の所要時間を短縮することができますが、クロール対象のWebサイトに与える負荷を十分に考慮して設定すべきかと思います。
ここでは、初期値の「300 URLs/分」のままにしました。
項目 「URLパターン (URL pattern to crawl)」 では、クロール対象に「含める」または「含めない」URLのパターンパターンを正規表現で指定できます。
初期値では「含めるパターン」「含めないパターン」共に未設定です。
ここでは、未設定のままにします。
データソースに関する最後の設定項目は、「コンテンツの分割とチャンキング戦略」についての設定です。
今回はデフォルト設定のままにしています。
こちらの項目をカスタマイズする場合は、以下のブログなどを参考にするとよいでしょう。
埋め込みモデルとベクトルデータベースの指定
ここは、従来 (S3をデータソースに設定) と同様に設定していきます。
今回は、以下のように指定しました。
- 埋め込みモデル: Titan Embeddings G1 - Text v1.2
- ベクトルデータベース: Amazon OpenSearch Serverless を新規作成
なお、現時点ではデータソースに「Webクローラー」を指定する場合は、ベクトルデータベースとして「Amazon OpenSearch Serverless」のみが選択可能であるようです。
(ベクトルデータベースをPineconeで作成したところ、データソースの登録でエラーになってしまいました)

全ての設定が終わったら、ナレッジベースの作成を開始します。
データソースの同期を行う
ナレッジベースの作成は数分で終わると思います。
作成が完了しましたら、データソースの初回の「同期」を行う必要があります。
データソースの一覧から対象データソースの行を選択して、右上の「同期」をクリックします。

今回、弊社のWebサイト (https://classmethod.jp) をクロール対象にしましたが、初回の同期の所要時間は約30分間でした。(条件によって所要時間は変わると思いますので、あくまで目安にしてください)

同期が完了しましたが、いくつか (2つ) のURLでクロールに失敗したようでした。とりあえず、今回はエラーを無視してこのまま続けます。
WebクロールをデータソースとしたRAGを試してみる
それでは、実際にRAGを試してみましょう。
まず、比較対象として「RAGを使わずに回答生成」してみます。
「プレイグラウンド」の「チャット」を開いて質問します。ここではナレッジベースは使われずにLLMが持つ情報のみで回答が生成されます。
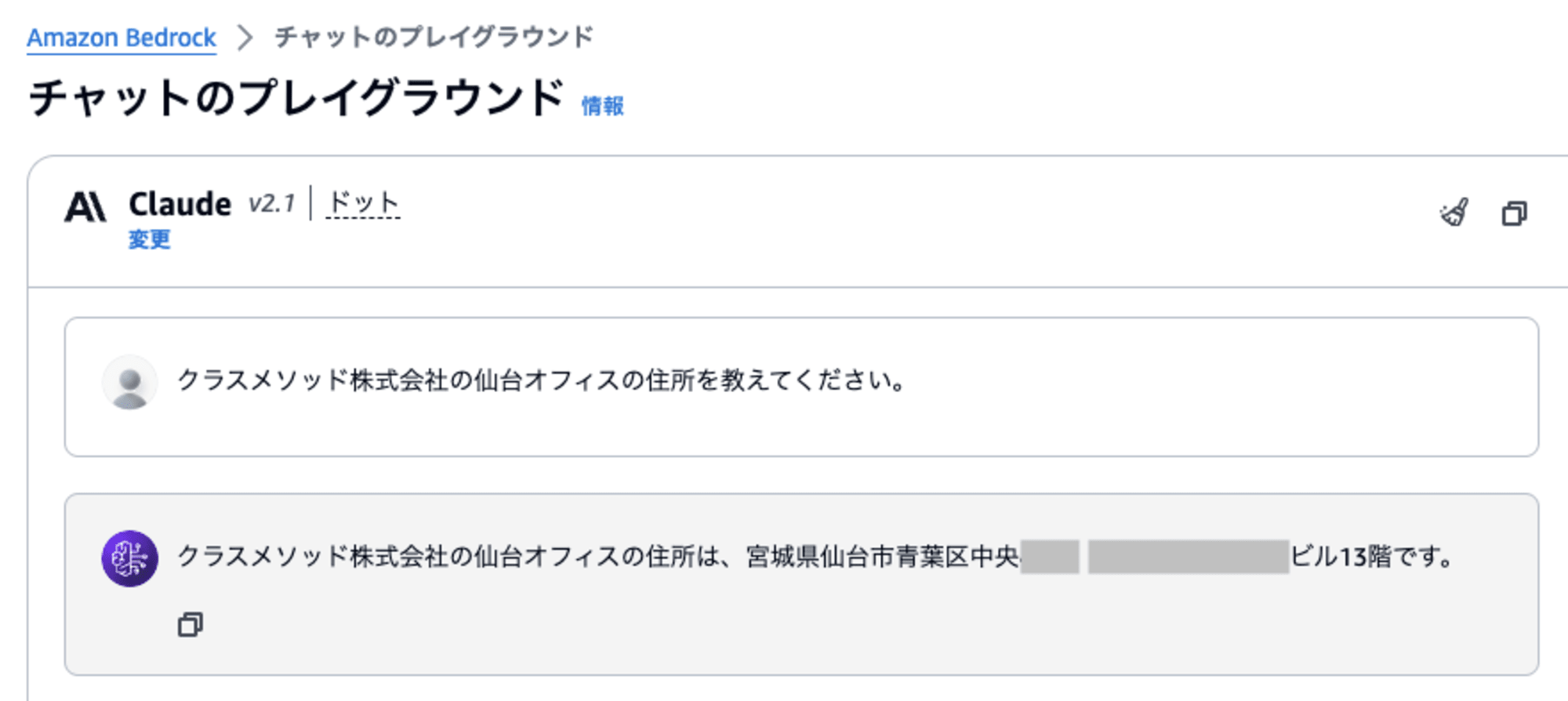
クラスメソッドの「仙台オフィス」は最も最近できたオフィスですが、LLM (Claude v2.1) では正しく答えることができませんでした。(それっぽい住所が返ってきましたが間違っています)
(※ 実在する住所かもしれませんので念のために一部マスクしています)
次に、「WebクローラーをデータソースとしたRAGを使って、回答生成」してみます。
「ナレッジベース」画面で「ナレッジベースをテスト」を開いて質問します。
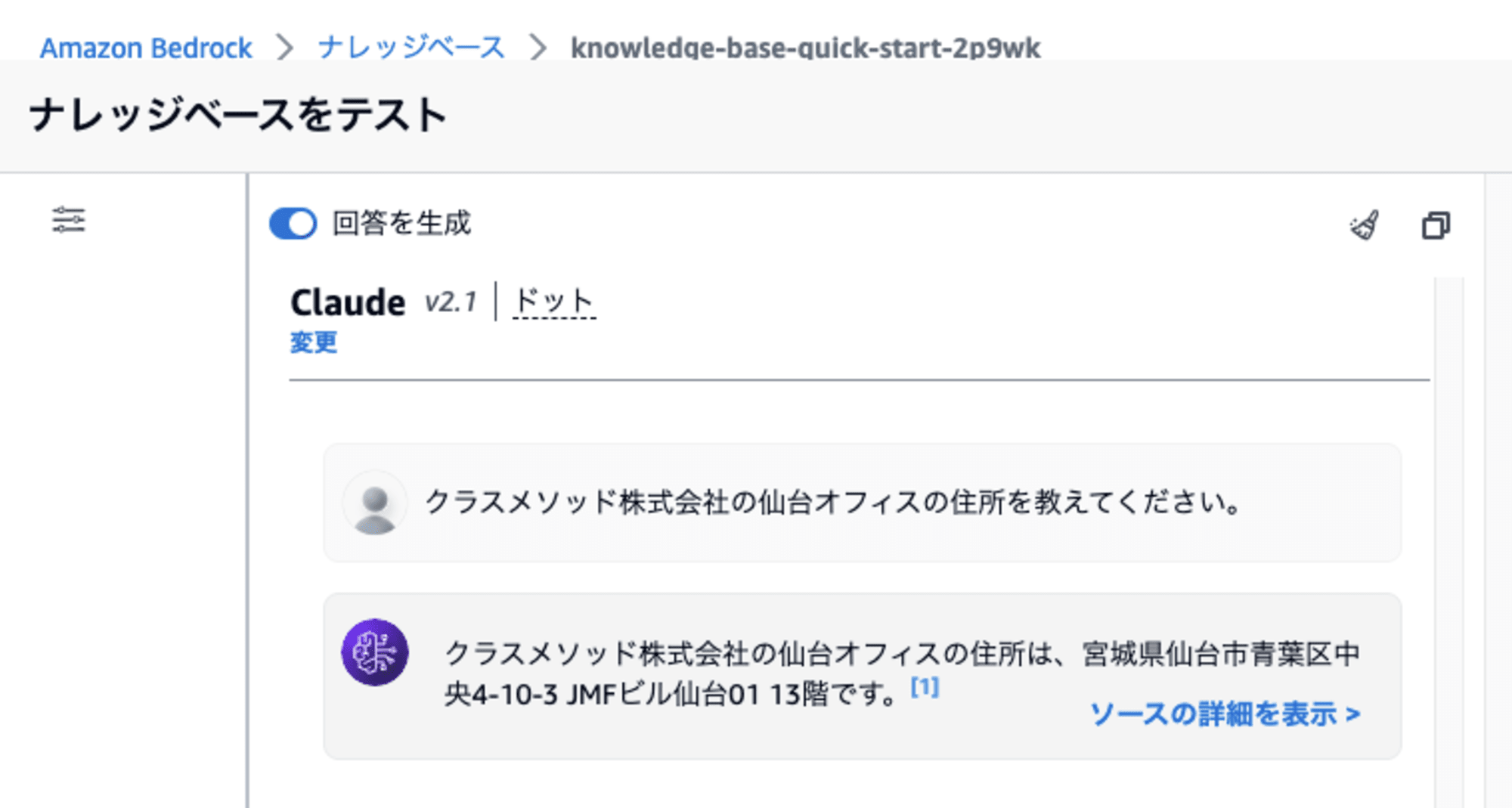
今度は、正しい「クラスメソッド仙台オフィス」の住所が回答されました。
確かに、Webクローラーが収集した情報に基づいてRAGが行われたことが確認できました。
おわりに
これまでは、Amazon Bedrockで「Webの情報を用いたRAG」を行おうとした場合、Amazon Kendraを利用することが多かったかと思います。
Kendraは高機能なエンタープライズ検索サービスではありますが、利用コストが高めなのがネックです。
今回、Knowledge Bases for Amazon Bedrockのデータソースが「Webクローラー」に対応したことで、選択肢が広がるのではないかと思います。
現時点ではベクトルデータベースとして利用可能であるのがOpenSearch Serverlessに限られるためコスト面のメリットはあまり無いような気もしますが、GAの際には複数のベクトルデータベースが利用可能になっていることを期待したいです。
今回ご紹介できなかった「SharePoint」など他のデータソースの種類についても試してみたいと思います。








