
【備忘録】SageMaker Pipelines と Step Functions の使い分けを考える
歴史シミュレーションゲーム好きのくろすけです!
最近 エッジAI について学習したいなと思っており、どうせならと思い MLOps まで含めた AI システムの全体像まで調べています。
以前、SageMaker や Step Functions を使った MLOps の構築を行ったのですが、当時は完全手探りで、時間も経っているため改めて調査しました。
今回は AWS における MLOps を実現するサービス SageMaker Pipelines と Step Functions の使い分けについて、機械学習開発プロセス視点で私なりの考えを備忘録的に書いてみようと思います。
あくまで、機械学習開発プロセス視点での使い分けです。今回サービス仕様的な、技術的な比較はあまりしていないので、ご了承ください。
MLOps とは
機械学習オペレーション (MLOps) は、機械学習 (ML) のワークフローとデプロイを自動化および簡素化する一連のプラクティスです。機械学習と人工知能 (AI) は、現実世界の複雑な問題を解決し、お客様に価値を提供するために実装できる中核機能です。MLOps は、ML アプリケーション開発 (Dev) と ML システムのデプロイおよび運用 (Ops) を統合する ML カルチャーとプラクティスです。組織は MLOps を使用して ML ライフサイクル全体のプロセスを自動化および標準化できます。これらのプロセスには、モデル開発、テスト、統合、リリース、およびインフラストラクチャ管理が含まれます。
簡単に言うと、機械学習モデルを「作って終わり」ではなく、本番環境で継続的に動かし続けるための仕組みづくりですね。
データサイエンティストが作ったモデルを、どうやって安全かつ効率的に本番環境にデプロイして、運用し続けるか...というのが MLOps の肝になります。
蛇足
完全に蛇足ですが、LLM においては、MLOps とは別に FMOps や LLMops という概念もあるようです。
LLM の エッジAI への組み込みも興味がある(できるかどうかすら知らない)ので、こちらも別途調べたら記事にしたいと思います。
AWS における MLOps の選択肢
AWS で MLOps を構築しようとすると、いくつかの選択肢があります。
代表的なところだと下記です。結局どれがいいのだろう?選定基準は?というのが今回の本題です。
ちなみに今回は、SageMaker Pipelines と Step Functions についてのみ調査しています。
- Amazon SageMaker Pipelines
- Amazon Managed Workflows for Apache Airflow
- AWS Step Functions
結論
結論としては、状況次第! です!
個人検証においての汎用的な使い分けとしては、下記がいいかなとイメージしています。
- SageMaker Pipelines:PoC(機械学習部分の検証)フェーズ
- Step Functions:システム本番稼働フェーズ
また、選定においては下記が影響が大きいと考えています。
- 機械学習モデルやシステムの仕様
- 開発体制・フェーズ
機械学習モデルやシステムの仕様
複数モデルのアンサンブルや前処理・後処理が複雑など、推論ロジックが複雑なモデルにおいては、そもそも SageMaker 自体の恩恵をあまり受けられないというケースもあります。
その場合、GPUインスタンス目的で SageMaker を使用することもあります。
SageMaker に寄りかかれないことを考えると MLOps 部分は、他のサービスとの連携がしやすい Step Functions のメリットが目立つ結果になるかと思います。
各サービスとの連携については、一番大きな違いかと思います。
Step Functions は他の AWS サービスとの連携がしやすいため、他のサービスとの連携を重視する場合は Step Functions が適していると考えます。
開発体制・フェーズ
開発体制・フェーズで重要なのは、各担当者が開発、保守運用しやすいツール、サービスかどうかという点です。
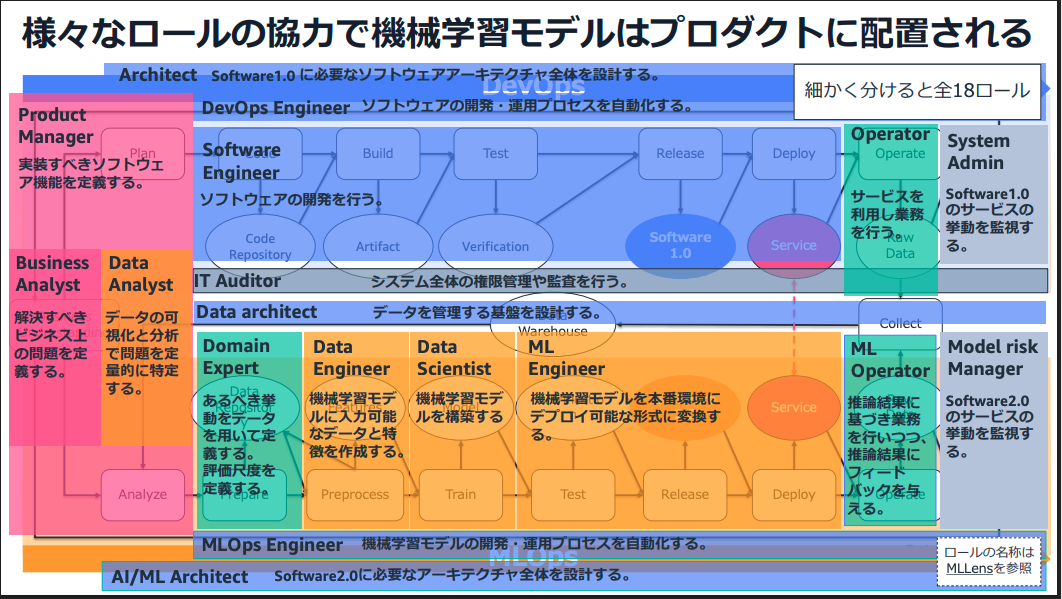
データサイエンティストや機械学習エンジニア視点
すばやくモデルを作成し、検証することが重要です。
そのため、SageMaker と親和性の高い SageMaker Pipelines が適していると考えられます。
MLOpsエンジニアやインフラエンジニア視点
開発のしやすさに加えて保守運用も重要です。
SageMaker で完結するシステムだと、データサイエンティストや機械学習エンジニアなど担当者間でブラックボックスになってしまう場合があります。
この場合、MLOpsエンジニアやインフラエンジニアが開発段階で関わる余地が少なくなります。
システムのオートマティックな安定稼働を考える場合、保守運用担当者にスムーズに引き継げることが重要です。
各担当者のスキルセットにも寄りますが、この点においては一般的には Step Functions の方が少し有利と考えられます。
ちなみにこの引き継ぎがうまくいかないと、データサイエンティストや機械学習エンジニアが保守運用を担うことになり、研究開発がミッションである部門の負担ともなります。
場合によっては、モデルの作成を責任分解点とするのもありかと思います。
- モデル作成、更新まで:データサイエンティストや機械学習エンジニア
- モデルのデリバリー:MLOpsエンジニアやインフラエンジニア
この場合は、責任分解点を基準に SageMaker Pipelines と Step Functions (もしくは他のサービスもありかも) を分けるということも考えられます。
また、保守運用では堅牢性も重要と考えます。
データサイエンティストや機械学習エンジニアが研究開発で使用する SageMaker Studio で、SageMaker Pipelines が変更できてしまうのは意図しない変更により、本番環境へ影響を与えるリスクとなります。
これは環境を分けることも考えられますが、各担当者の管理コスト的にサービスベースで分離してしまうのがいいのではないかと考えています。(ここは好みもあるかもしれません。)
あとがき
今回は、SageMaker Pipelines と Step Functions の使い分けについて、私なりの考えを備忘録的に書いてみました。
実際の選定は状況次第、好みも大きいと思います。
個人的には、個人検証での汎用的な使い分けとしては、下記がいいかなというところでした。
- SageMaker Pipelines:PoC(機械学習部分の検証)フェーズ
- Step Functions:システム本番稼働フェーズ
他にご意見あればぜひ教えてください!
以上、くろすけでした!
参考









