
Lambda Durable Functionsを利用してRedshiftに対しクエリ実行と結果のポーリングをしてみた
データ事業本部のueharaです。
今回は、Lambda Durable Functionsを利用してRedshiftに対しクエリ実行と結果のポーリングをしてみたいと思います。
はじめに
Lamndaには 15分 という最大実行時間の制限があります。
これまで、Redshiftに対し実行に15分以上かかるクエリを実行するには以下のような対応を取る必要がありました。
- Glue Python Shell/ECSなど実行時間制限の無い(緩い)コンピューティングリソースからクエリを同期的に実行
- Step FunctionsとLambdaを組み合わせて、非同期でクエリの実行・結果のポーリング
前者の場合だとクエリ実行の完了を待つ間、すなわちコンピューティングリソースのアイドル時間に対し不必要なコストが発生するデメリットがあります。(加えて、ECSの場合はLambdaやGlue Python Shellと比較しイメージの作成・管理の手間もあります)
後者の場合はStep Functionsの学習コストに加え、ステート間の連携を意識して構築する必要があり、やりたいことに対し少々構築の手間が大きい印象があります。
そこで、今回はre:Invent 2025で新しく発表された Lambda Durable Functions を利用して、15分以上かかるクエリ実行を想定した環境構築を行いたいと思います。(2025/12より東京リージョンでも利用可能となっております)
Durable Functionsを利用して、後者をLambda単体で完結させるようなイメージです。
前提
今回、Redshiftは既に構築済みであることを想定します。(私の手元ではRedshift Serverlessを利用します)
利用するテーブルのサンプルとして、以下のように orders テーブルを用意しています。
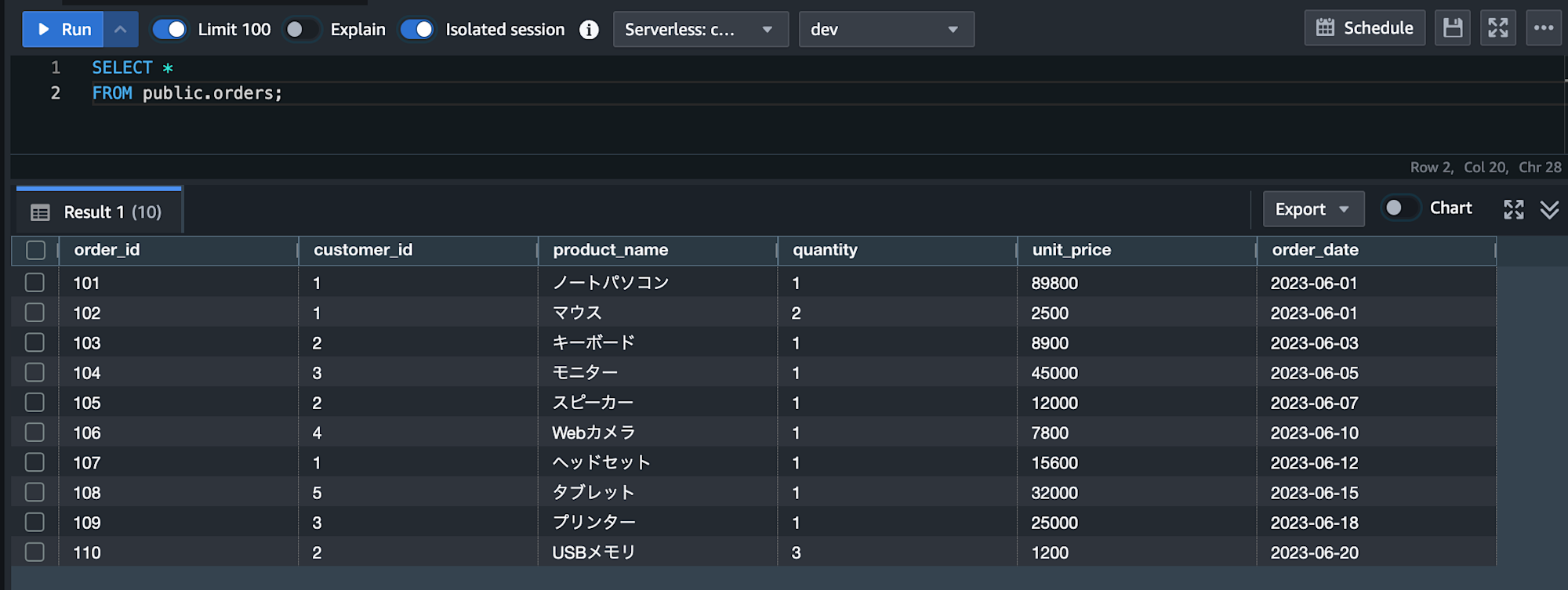
今回Lambdaから発行するクエリは、上記 orders テーブルをソースとしたマートテーブルの洗い替え(DELETE → INSERT)をするものとします。
また、テーブルへのアクセスにはIAM認証を利用し、今回登場するLambdaのIAMロールに対し必要なテーブルへのアクセス権限等は別途付与されていることを想定します。
ファイルの準備
今回、環境はAWS SAMで作成することにします。
※AWS SAM CLIのバージョン 1.150.0 からDurable Functionsがサポートされています。
ディレクトリ構成は以下の通りです。
.
├── handler
│ └── sample
│ ├── query.sql
│ └── redshift_batch_executor.py
├── layers
│ └── dependencies
│ └── requirements.txt
├── samconfig.toml
└── template.yaml
まず、 samconfig.toml は以下の通りです。
version = 0.1
[default]
region = "ap-northeast-1"
[default.build.parameters]
debug = true
[default.deploy.parameters]
stack_name = "<YOUR_STACK_NAME>"
s3_bucket = "<YOUR_S3_BUCKET>"
s3_prefix = "<YOUR_S3_PREFIX>"
capabilities = "CAPABILITY_NAMED_IAM"
confirm_changeset = true
スタック名やデプロイ用のS3バケットに関する設定は適宜ご自身の環境に合わせて下さい。
次に、リソースを定義した template.yaml は以下の通りです。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: "Redshift Query Executor with Lambda Durable Functions"
Parameters:
RedshiftWorkgroupName:
Type: String
Description: "Redshift Serverless Workgroup Name"
Default: "<YOUR_WORKGROUP_NAME>"
RedshiftDatabaseName:
Type: String
Description: "Redshift Database Name"
Default: "<YOUR_DB_NAME>"
DurableExecutionTimeout:
Type: Number
Description: "Durable Functions Execution Timeout (seconds)"
Default: 3700
Globals:
Function:
Timeout: 180
MemorySize: 128
Resources:
# Lambda Layer
DependenciesLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: "uehara-redshift-durable-functions-layer"
Description: "Dependencies for Redshift Durable Functions"
ContentUri: layers/dependencies/
CompatibleRuntimes:
- python3.14
CompatibleArchitectures:
- x86_64
Metadata:
BuildMethod: python3.14
BuildArchitecture: x86_64
# Lambda
RedshiftQueryFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: "uehara-redshift-durable-functions"
Role: !GetAtt RedshiftQueryFunctionRole.Arn
CodeUri: handler/sample/
Handler: redshift_batch_executor.lambda_handler
Runtime: python3.14
Architectures:
- x86_64
Timeout: 60
Layers:
- !Ref DependenciesLayer
Environment:
Variables:
WORKGROUP_NAME: !Ref RedshiftWorkgroupName
DATABASE_NAME: !Ref RedshiftDatabaseName
DurableConfig:
ExecutionTimeout: !Ref DurableExecutionTimeout
# Lambda Role
RedshiftQueryFunctionRole:
Type: AWS::IAM::Role
Properties:
RoleName: "uehara-redshift-durable-functions-role"
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
- arn:aws:iam::aws:policy/AmazonRedshiftFullAccess
- arn:aws:iam::aws:policy/AmazonRedshiftDataFullAccess
Policies:
- PolicyName: "DurableFunctionsPolicy"
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- lambda:CheckpointDurableExecution
- lambda:SendDurableExecutionCallbackSuccess
- lambda:SendDurableExecutionCallbackFailure
Resource: !Sub "arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:uehara-redshift-durable-functions*"
リソースとしては、以下の3つを定義しています。
- Lambda Layer
- Lambda (Durable Functions)
- Lambda用のIAMロール
Lambda Layerは後述する requirements.txt からSAMのビルドコマンドを用いて作成します。
Redshift Serverlessのワークグループ名やDB名はパラメータとしており、Lambdaの環境変数として設定するようにしています。
また、Lambdaの DurableConfig はDurable Functionsの実行設定となっており、 ExecutionTimeout は最大は366日まで設定可能なDurable Functionsの実行時間の設定値になりますが、今回は3700秒(1時間+バッファの100秒)としています。
その他、Lambda用のIAMロールに関して、今回は検証用のためRedshiftの利用に関する権限は強めのマネージドポリシーを設定しています。
handler/sample/query.sql はLambdaからRedshiftに対し発行するクエリファイルになります。
今回は前述の「前提」に記載の通り、サンプルとしてマートテーブルを洗い替えで作成するようなクエリとしています。
DELETE FROM public.mart_customer_summary;
INSERT INTO public.mart_customer_summary (
customer_id,
total_orders,
total_amount,
last_order_date,
updated_at
)
SELECT
customer_id,
COUNT(DISTINCT order_id) AS total_orders,
SUM(quantity * unit_price) AS total_amount,
MAX(order_date) AS last_order_date,
CURRENT_TIMESTAMP AS updated_at
FROM
orders
GROUP BY
customer_id;
handler/sample/redshift_batch_executor.py は今回キモとなるLambda関数(Durable Functions)のスクリプトファイルになりますが、以下の通りです。
import os
from pathlib import Path
import boto3
import sqlparse
from aws_durable_execution_sdk_python import (
DurableContext,
StepContext,
durable_execution,
durable_step,
)
from aws_durable_execution_sdk_python.config import Duration
# 環境変数
WORKGROUP_NAME = os.environ.get("WORKGROUP_NAME")
DATABASE_NAME = os.environ.get("DATABASE_NAME")
# Redshift Data APIクライアント
redshift_data = boto3.client("redshift-data")
def load_sql_statements(sql_file_path: str) -> list[str]:
"""SQLファイルを読み込み、個別のステートメントに分割する
Args:
sql_file_path (str): SQLファイルのパス
Returns:
list[str]: 分割されたSQLステートメントのリスト
Raises:
FileNotFoundError: SQLファイルが存在しない場合
"""
with open(sql_file_path, "r", encoding="utf-8") as f:
sql_content = f.read()
# sqlparseでSQLを分割
statements = sqlparse.split(sql_content)
# 空のステートメントを除外
return [stmt.strip() for stmt in statements if stmt.strip()]
@durable_step
def execute_batch_query(step_context: StepContext, statements: list) -> str:
"""Redshiftにバッチクエリを実行する
Args:
step_context (StepContext): Durable Functionsのステップコンテキスト
statements (list): 実行するSQLステートメントのリスト
Returns:
str: クエリ実行ID
"""
step_context.logger.info(f"Executing batch query with {len(statements)} statements")
response = redshift_data.batch_execute_statement(
WorkgroupName=WORKGROUP_NAME,
Database=DATABASE_NAME,
Sqls=statements,
)
query_id = response["Id"]
step_context.logger.info(f"Batch query started with ID: {query_id}")
return query_id
@durable_step
def check_query_status(step_context: StepContext, query_id: str) -> dict:
"""クエリの実行状態を確認する
Args:
step_context (StepContext): Durable Functionsのステップコンテキスト
query_id (str): クエリ実行ID
Returns:
dict: クエリ状態情報
"""
step_context.logger.info(f"Checking query status for ID: {query_id}")
response = redshift_data.describe_statement(Id=query_id)
status = response["Status"]
step_context.logger.info(f"Query status: {status}")
if status in ("FAILED", "ABORTED"):
error_message = response.get("Error", "Unknown error")
raise Exception(f"Query failed with status {status}: {error_message}")
return {"status": status, "completed": status == "FINISHED"}
@durable_execution
def lambda_handler(event: dict, context: DurableContext) -> dict:
"""SQLファイル内の全ステートメントをバッチ実行するLambdaハンドラー
Args:
event (dict): Lambdaイベント
context (DurableContext): Durable Functionsのコンテキスト
Returns:
dict: 実行結果を含むレスポンス
"""
# SQLファイルのパスを取得(デフォルトは同ディレクトリのquery.sql)
sql_file_path = event.get(
"sql_file_path",
str(Path(__file__).parent / "query.sql")
)
statements = load_sql_statements(sql_file_path)
context.logger.info(f"Loaded {len(statements)} statements from {sql_file_path}")
# バッチでクエリ実行
query_id = context.step(execute_batch_query(statements))
context.logger.info(f"Batch query submitted with ID: {query_id}")
# ポーリングでクエリ完了を待機(10秒間隔、最大360回 = 1時間)
max_attempts = 360
for attempt in range(max_attempts):
status_result = context.step(check_query_status(query_id))
if status_result["completed"]:
context.logger.info("Batch query completed successfully")
break
# 10秒待機
context.wait(Duration.from_seconds(10))
else:
raise Exception(f"Query timed out after {max_attempts * 10} seconds")
return {
"statusCode": 200,
"body": {
"message": "All queries executed successfully",
"query_id": query_id,
"statement_count": len(statements),
"status": status_result["status"],
},
}
各関数の処理についてはdocstringに記載の通りになりますが、簡単に説明するとクエリ実行はBoto3経由でRedshift Data APIの BatchExecuteStatement を利用しています。(参考)
※ BatchExecuteStatement においてSQL文は単一のトランザクションとして実行され、配列の順序に従って順次実行されます。
SQLのステートメントは分割したリストの状態で渡す必要があるため、SQLファイルの読み込み時に sqlparse モジュールを利用して分割を行っています。
check_query_status 関数がクエリの実行結果をポーリングするためのチェック関数になっており、クエリの実行結果がエラーだった場合はエラーメッセージと共に例外を発生させるようにしています。
このチェック関数の実行をステップとして、10秒毎に呼び出しを行っています。
Lambda Layerを作成するための layers/dependencies/requirements.txt は以下の通りです。
boto3==1.42.23
sqlparse==0.5.0
aws-durable-execution-sdk-python==1.1.0
今回の実行に必要なPythonモジュールを記載しています。
デプロイ
今回はLambda Layerもあるので、まずビルドを行います。
$ sam build --use-container
--use-container はコンテナを利用するオプションになっており、Docker等のコンテナ実行環境を事前に整備しておく必要があります。
※ public.ecr.aws/sam/build-python3.14:latest-x86_64 といったイメージが取得され、その中でビルドが行われるイメージです。
ビルドが完了すると、 .aws-sam 配下にビルドで生成されたファイルが出力されます。
無事ビルドができたら、デプロイを行います。
$ sam deploy
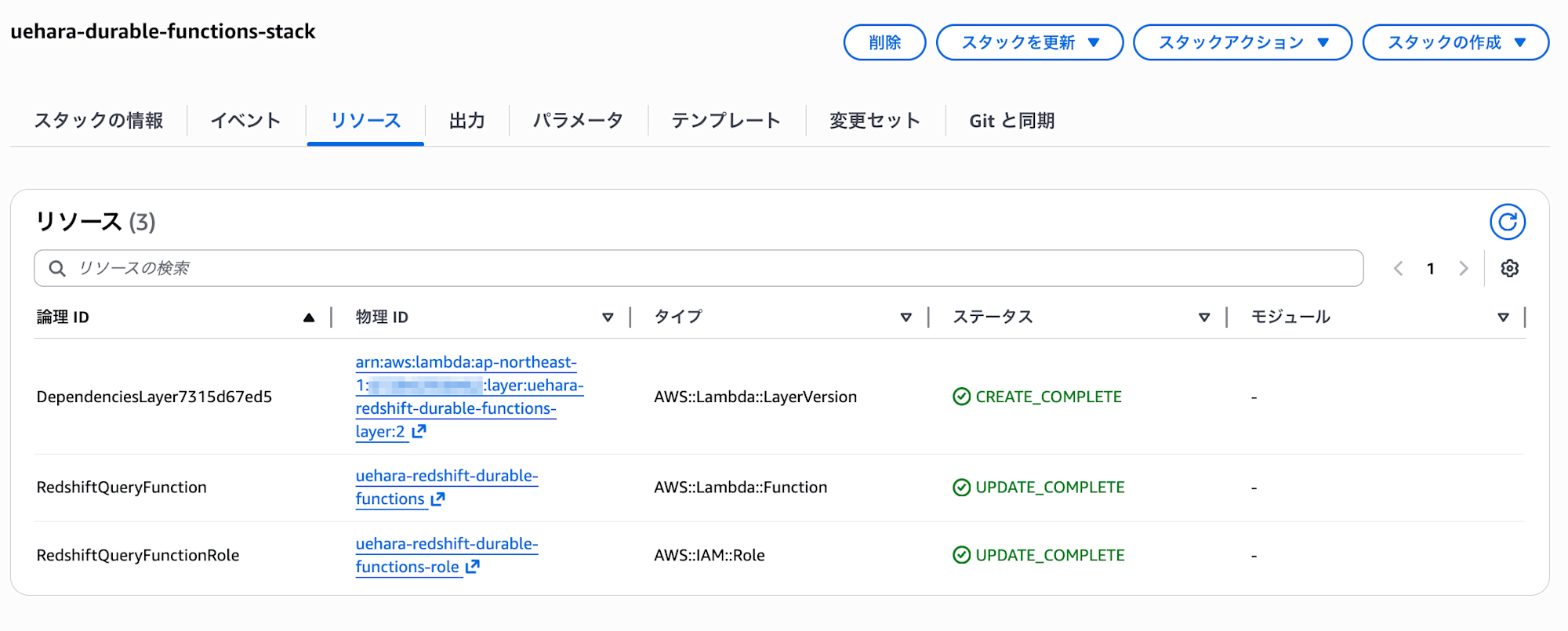
スタックが作成されていればデプロイ完了です。
実行確認
作成したLambda関数について、呼び出しタイプを「非同期」で実行します。
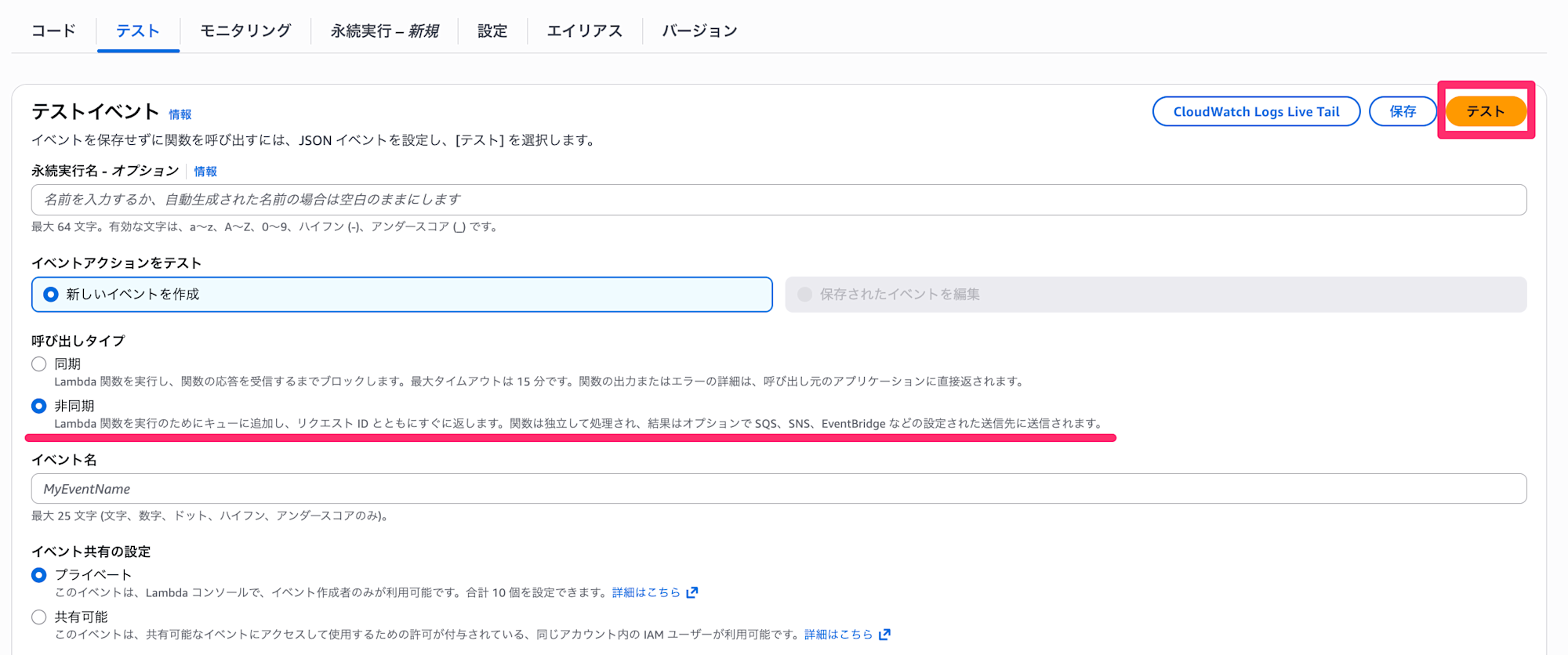
※呼び出しタイプを同期にすると、15分以上実行できません。(公式ドキュメントに記載あり)
実行結果を確認すると、以下のように execute_batch_query 関数を実行した後、10秒間隔で check_query_status 関数をCallしていることが分かります。
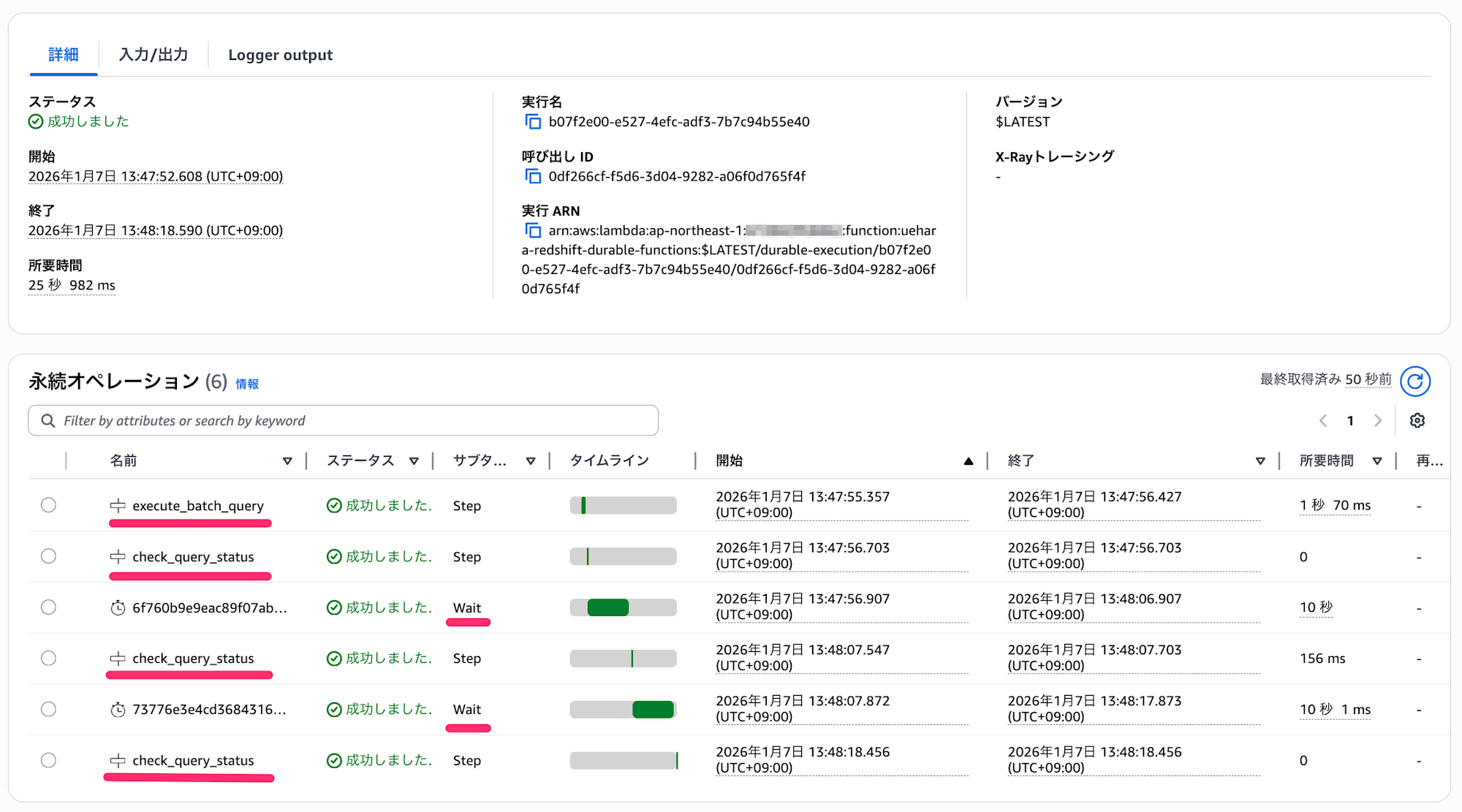
Step毎にログを確認すると、期待した挙動になっておりました。
▼ 実行ステータスが未完了
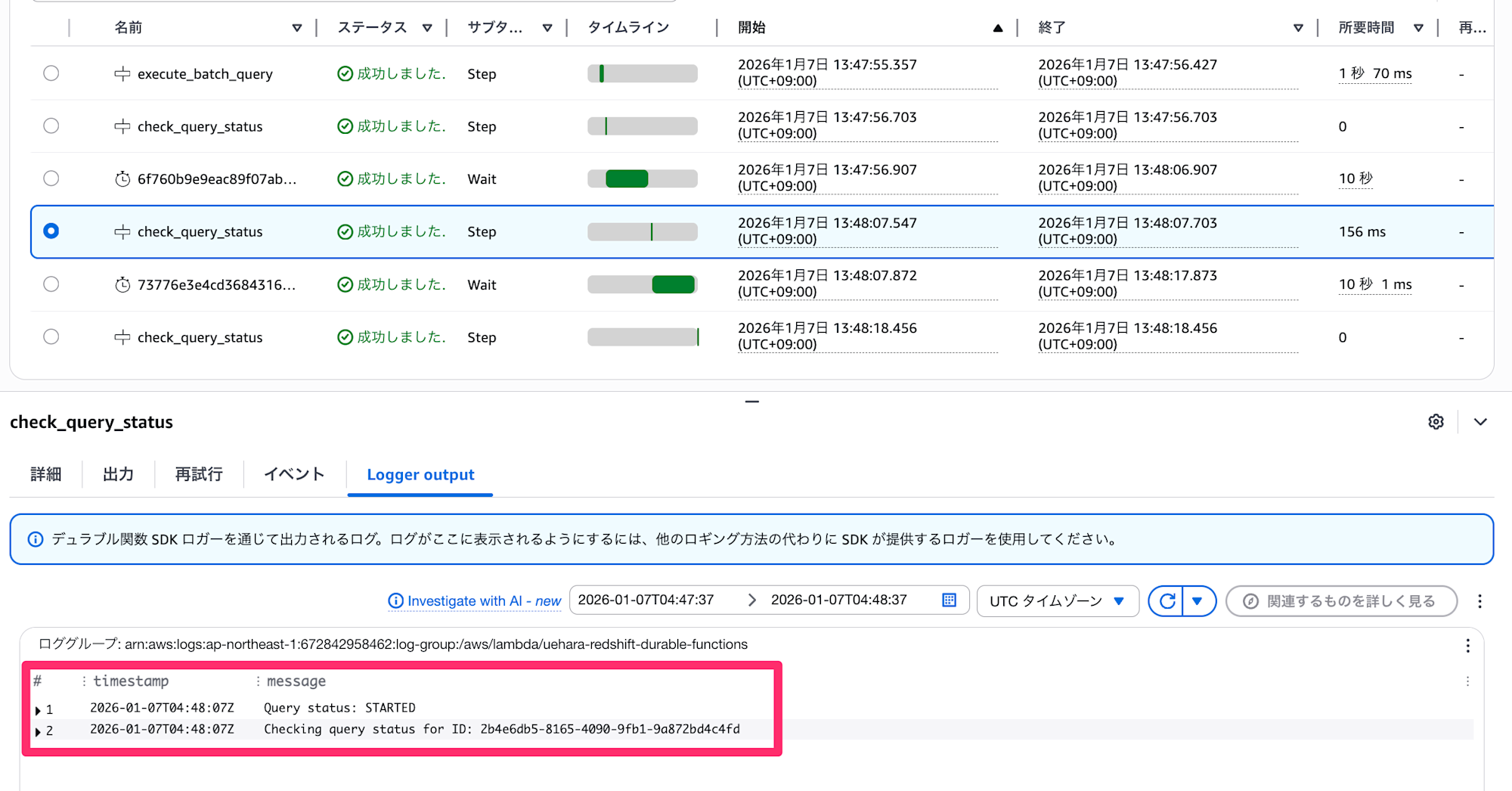
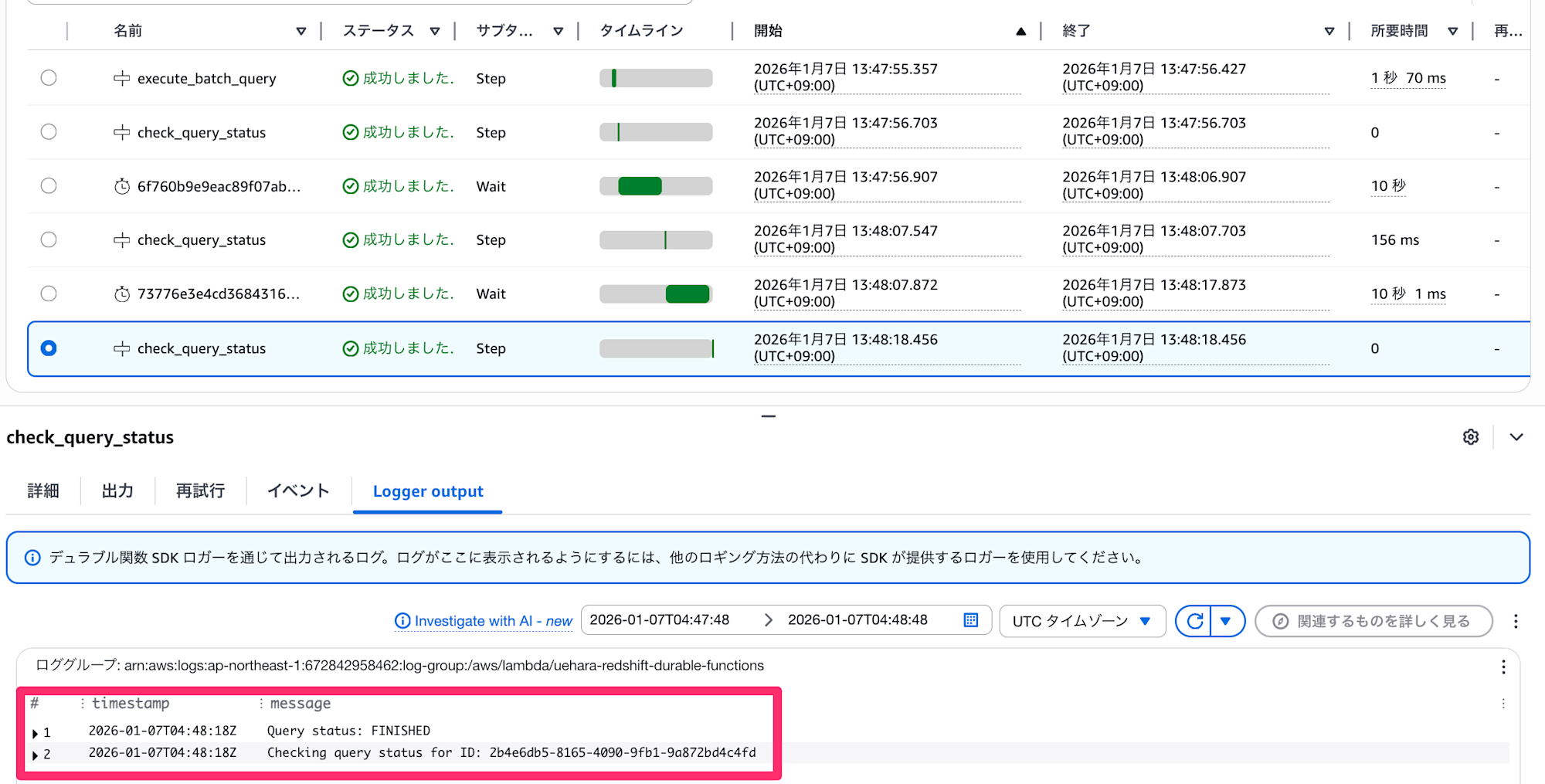
▼ 実行ステータスが完了
念のためマートテーブルが作成されたかも確認してみます。
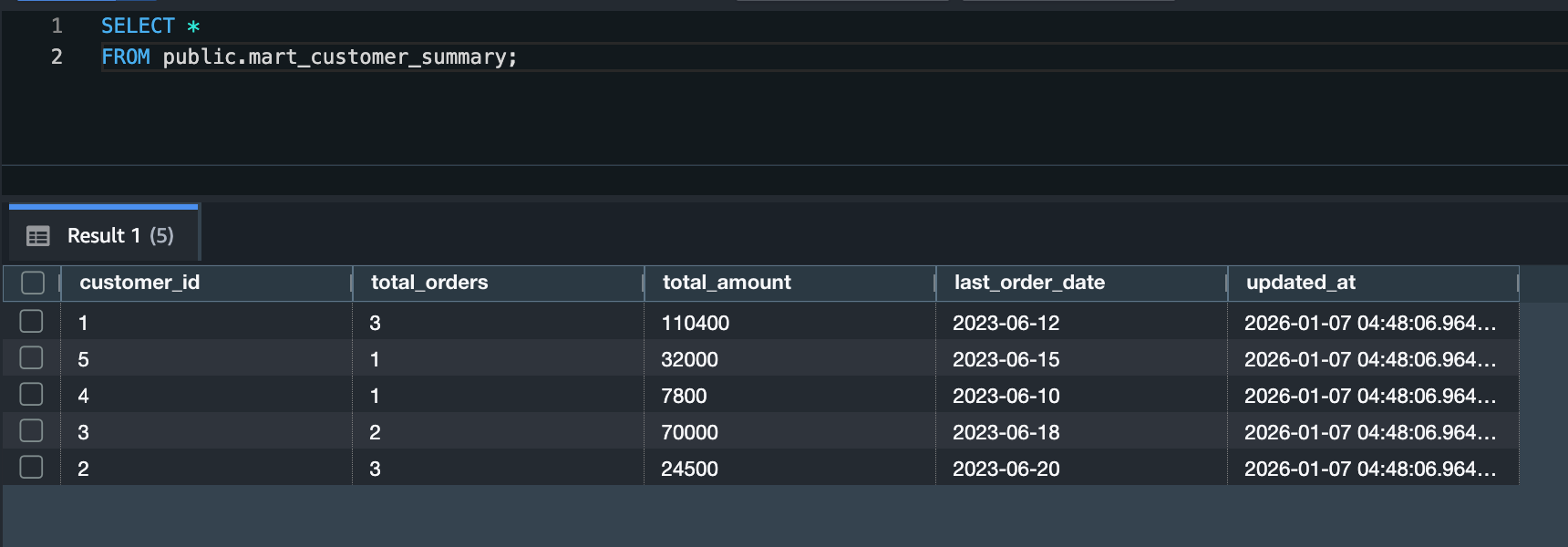
無事データの確認ができました。
最後に
今回は、Lambda Durable Functionsを利用してRedshiftに対しクエリ実行と結果のポーリングをしてみました。
参考になりましたら幸いです。









