
Lambda関数(Python)でExcelファイルのシリアル値を日付に変換しつつcsvファイル変換してみた
2025.07.01
データ事業本部のsutoです。
Microsoft Excelファイル(.xlsx)を.csvに変換する際、何も考えずに実行すると日付値がシリアル値で出力されてしまうことがあります。
今回は、Python(pandas利用)で指定の日付フォーマットで出力されるように.xlsx→.csv変換する処理を作成します。
シリアル値とは
シリアル値は、1900年1月1日を1として、何日経過したかを示す数値です。Excelにおいて、日時を計算処理するために使用されます。
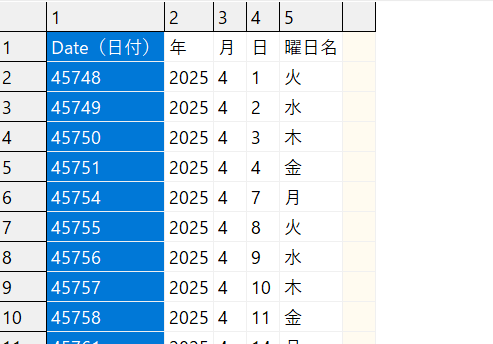
こちらを考慮せずに、単純に.xlsx→.csv変換を行うと以下のようにシリアル値として出力してしまうことがあります。
変換前xlsxファイル
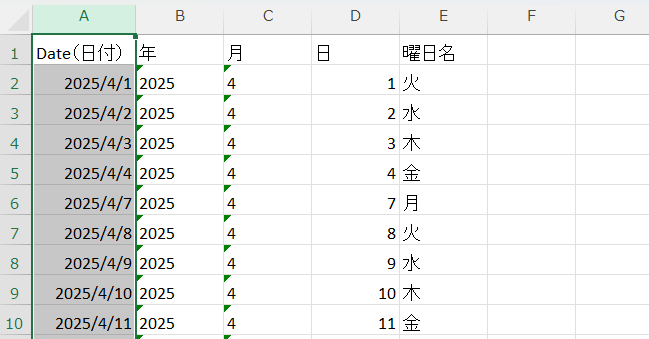
返還後csvファイル
やってみた
今回の前提条件は以下となります。
- .xlsxファイルはS3バケット(source-bucket)に配置されている
- .csvファイルの出力先は.xlsxファイルと同じバケットとする
- Pythonのバージョンは”3.13”とする
- .xlsx→.csv変換に"pandas"ライブラリを使う
Lambdaレイヤー作成
依存ライブラリである”pandas”と”openyxl(pandasがExcelファイルを読み込むために内部で使用)"を含むLambdaレイヤーを作成します。
Linux環境であれば以下のコマンドで作成できます。
# 作業フォルダを作って移動
mkdir python-layer
cd python-layer
mkdir python
# pandas、openpyxlのインストール
pip install pandas openpyxl -t ./python
# フォルダを圧縮
zip -r pandas_layer.zip .
その後、AWSマネジメントコンソールでLambdaの画面を開き、「レイヤー」メニューから「レイヤーの作成」を選択し、作成したpandas_layer.zipをアップロードします。
IAMロールと権限
今回のLambda関数で使用する実行ロールにはS3バケットへのアクセス権限が必要です。関数の実行ロールに以下のようなIAMポリシーをアタッチしてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::source-bucket/*"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "arn:aws:s3:::source-bucket/*"
}
]
}
Lambda関数の作成
今回のLambda関数は以下のパラメータとします。
- タイムアウト:1分
- メモリ:256MB
- 実行ロール:前述で作成したポリシーをアタッチしたIAMロール
今回作成したコードは以下となります。
pandasのto_datetime関数を使うことで対象の日付列にある数値を明示的に日付形式で出力します。
import io
import os
import boto3
import pandas as pd
s3 = boto3.resource('s3')
s3_client = boto3.client('s3')
def lambda_handler(event, context):
# S3にアップロードされたExcelファイルの最初のシートをCSVに変換し、同じバケットの指定パスに出力する。
try:
if 'Records' in event:
# S3イベントトリガーからの実行
data_source_bucket = event['Records'][0]['s3']['bucket']['name'] # Lambda関数呼び出し元バケット名
data_source_key = event['Records'][0]['s3']['object']['key'] # オブジェクトキー取得
else:
# 手動実行 (テストイベント)
data_source_bucket = event['bucket']
data_source_key = event['key']
os.chdir('/tmp')
# S3にPUTされたExcelファイルダウンロード
response = s3_client.get_object(Bucket=data_source_bucket, Key=data_source_key)
file_content = response['Body'].read()
# ローカルで生成するCSVファイル名を生成
base_filename = os.path.splitext(os.path.basename(data_source_key))[0]
csv_filename = f"{base_filename}.csv"
# 出力先S3パスを生成
file_path = "出力させるS3パスをここに入力"
dest_key = f"{file_path}/{csv_filename}"
# pandasでExcelファイルを読み込み (1シート目のみ)
df = pd.read_excel(io.BytesIO(file_content), sheet_name=0)
# 日付の列名のリスト(今回の対象列名は'Date(日付)'とします)
date_columns = ['Date(日付)']
for col in date_columns:
if col in df.columns:
# まず、列を数値型に変換しようと試みる (エラーは無視)。文字列として読み込まれた数値を正しく扱えるため
numeric_col = pd.to_numeric(df[col], errors='coerce')
# 数値に変換できたものだけを対象に、シリアル値を日付に変換
converted_dates = pd.to_datetime(numeric_col, unit='D', origin='1899-12-30', errors='coerce')
# 変換に成功した日付を書式設定し、元の列を更新
mask = converted_dates.notna()
df.loc[mask, col] = converted_dates[mask].dt.strftime('%Y-%m-%d')
print(f"Processed potential date column: {col}")
# DataFrameをCSV形式の文字列に変換
csv_buffer = io.StringIO()
df.to_csv(csv_buffer, index=False, encoding='utf-8-sig')
csv_content = csv_buffer.getvalue()
# CSVファイルアップロード
s3_client.put_object(
Bucket=data_source_bucket,
Key=dest_key,
Body=csv_content
)
print(f"Successfully converted {data_source_key} to {dest_key} in bucket {data_source_bucket}.")
return {
'statusCode': 200,
'body': f'Successfully converted {data_source_key} to {dest_key}'
}
except Exception as e:
print(f"Error processing file {data_source_key} from bucket {data_source_bucket}.")
print(e)
raise e
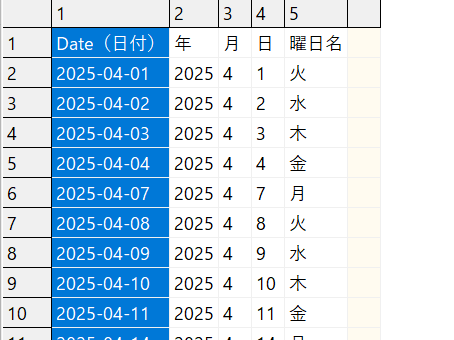
実行結果
実行結果の変換前xlsxファイルとcsvファイルは以下となります。
変換前xlsxファイル
返還後csvファイル
参考記事










