![[レポート] Leaving no operational issues behind に参加してきました! #COP311 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] Leaving no operational issues behind に参加してきました! #COP311 #AWSreInvent
こんにちは!
運用イノベーション部の大野です。
re:Invent 2025 の「Leaving no operational issues behind」に参加してきましたので、内容をご紹介いたします。
セッション概要

セッションタイトル COP311-R | Leaving no operational issues behind
説明
クラウド運用において、インシデント対応時間は非常に重要です。ログデータには何が起こったかについての真実が含まれていますが、何百万ものイベントの中から適切なシグナルを見つけ出すことは、干し草の山から針を探すようなものです。そこで登場するのが、自然言語クエリを通じてCloudTrailログや運用データの分析方法を変革する「Kiro CLI with MCP server」です。インテリジェントなログ分析を備えたAmazon CloudWatchの調査機能を活用し、トラブルシューティングの時間を短縮して、根本原因をより迅速に特定する方法をご紹介します。
スピーカー
- Brad Gilomen(Prin. Specialist, AWS)
- Snehal Nahar(Principal Technical Account Manager, Amazon Web Services (AWS))
セッションカテゴリなど
- Type: Chalk talk
- Level: 300 – Advanced
- Features: Interactive
- Topic: Cloud Operations
- Area of Interest: Management & Governance, Monitoring & Observability
- Role: IT Professional / Technical Manager, Solution / Systems Architect, System Administrator
- Services: Amazon Q, AWS CloudTrail
セッションサマリ
本セッションのポイントをまとめます。
- ダウンタイムコストは甚大であり、ITICの調査によると企業の90%が1時間のダウンタイムで30万ドル以上のコストに直面
- AIOpsとは生成AI、機械学習、ビッグデータを活用して運用プロセスを自動化・強化するアプローチ
- CloudWatch Investigationsは2025年6月にGAとなり、AIを活用したアシスト型の調査で根本原因の仮説を自動生成
- MCPサーバーによりAIエージェントがCloudWatchやApplication Signalsのデータにアクセス可能に
- アシスト型調査(CloudWatch Investigations)と自律型調査(MCP+AIエージェント)の2つのアプローチが存在
ダウンタイムのコスト
セッションの冒頭で、ダウンタイムがビジネスに与える影響について説明がありました。

Information Technology Intelligence Consulting(ITIC)の調査によると、
- 90%の企業が1時間のダウンタイムで30万ドル以上のコストに直面
- 41%の企業は1時間あたり100万〜500万ドルのコストが発生
これはビジネスへの直接的な影響だけでなく、運用チームへのストレス、リーダーシップへの報告、RCA(Root Cause Analysis)作成など、多くの付随作業も含まれます。
AIOps(AI Operations)とは
AIOpsとは、生成AI(Generative AI)、機械学習(Machine Learning)、ビッグデータを活用して運用プロセスを自動化・強化するアプローチです。

AWSのAIOpsへの取り組みは、CloudTrail LakeへのAIクエリ機能から始まりました。「過去24時間のすべての変更を表示」といった自然言語でのクエリが可能になり、運用効率が大幅に向上しました。
現在では、CloudWatch Investigationsやアラームの要約、トレンド分析など、多くのAI機能が運用ツールに統合されています。
アシスト型 vs 自律型エージェント
セッションでは、AIエージェントの2つのアプローチが紹介されました。

アシスト型調査(Assisted Investigation)
- CloudWatch Investigationsがこのカテゴリに該当
- AIが観察結果を提示し、オペレーターが正しいかどうかを判断
- データを収集し、仮説を生成するが、最終判断は人間が行う
- 現時点では多くの組織に適したアプローチ
自律型調査(Autonomous Investigation)
- AIエージェント+MCPサーバーがこのカテゴリに該当
- 許可されたツールとデータソースを使用してインシデントを調査
- 計画、推論、実行、仮説構築をすべて自動で行う
- 環境が整っていれば自動修復も可能
CloudWatch Investigations
概要
CloudWatch Investigationsは、2024年のre:Inventでプレビュー発表され、**2025年6月に一般提供(GA)**が開始されました。生成AIを活用してインシデントの根本原因分析を自動化し、DevOpsチームのトラブルシューティングをガイドする機能です。
主な機能
自動仮説生成
アラームがトリガーされると、CloudWatch Investigationsが自動的に調査を開始し、根本原因の仮説を生成します。
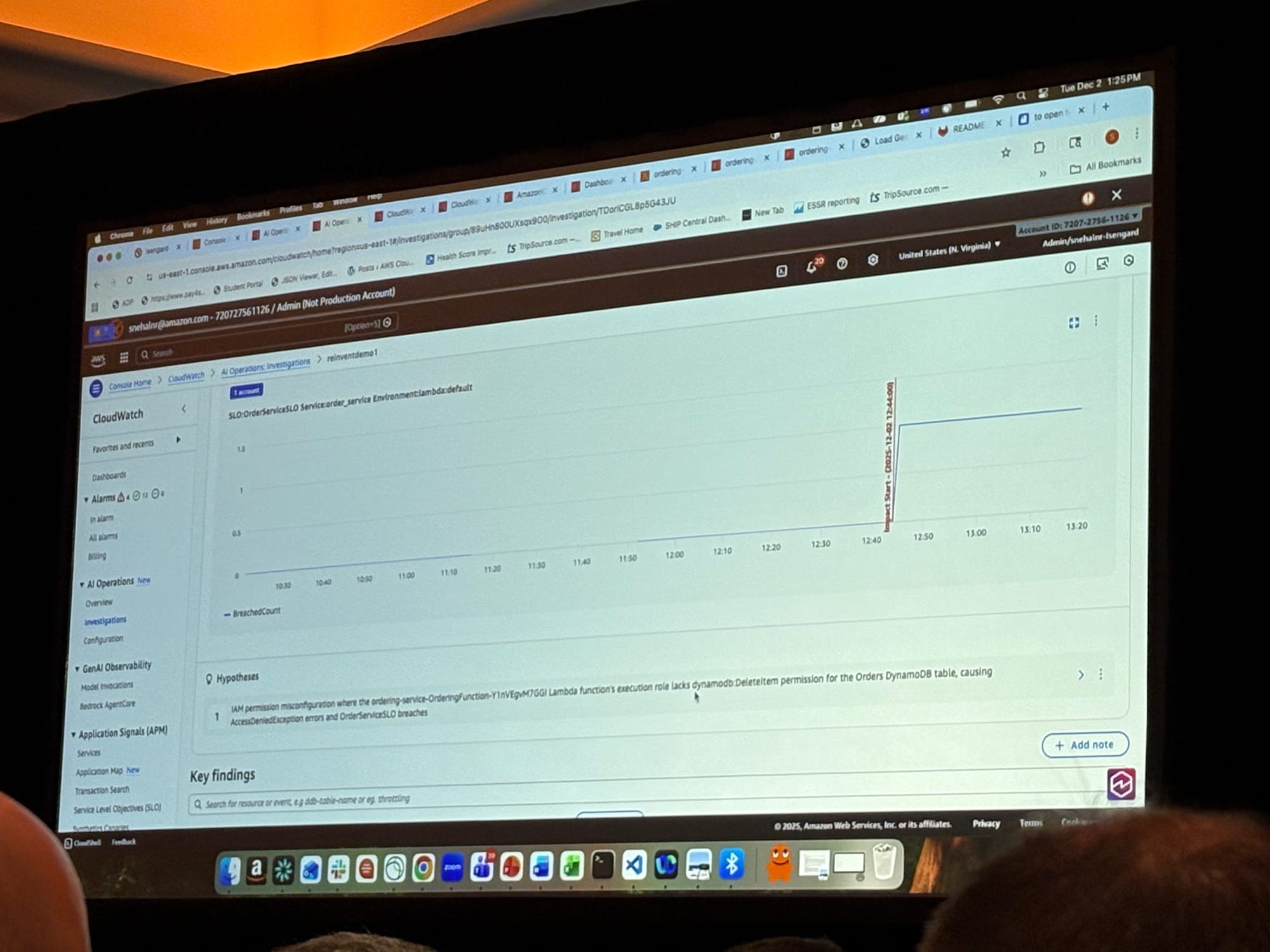
上の画像は、OrderServiceのSLO違反が検知された際の調査画面です。AIが自動的にデータを分析し、仮説を提示します。
詳細な仮説レポート
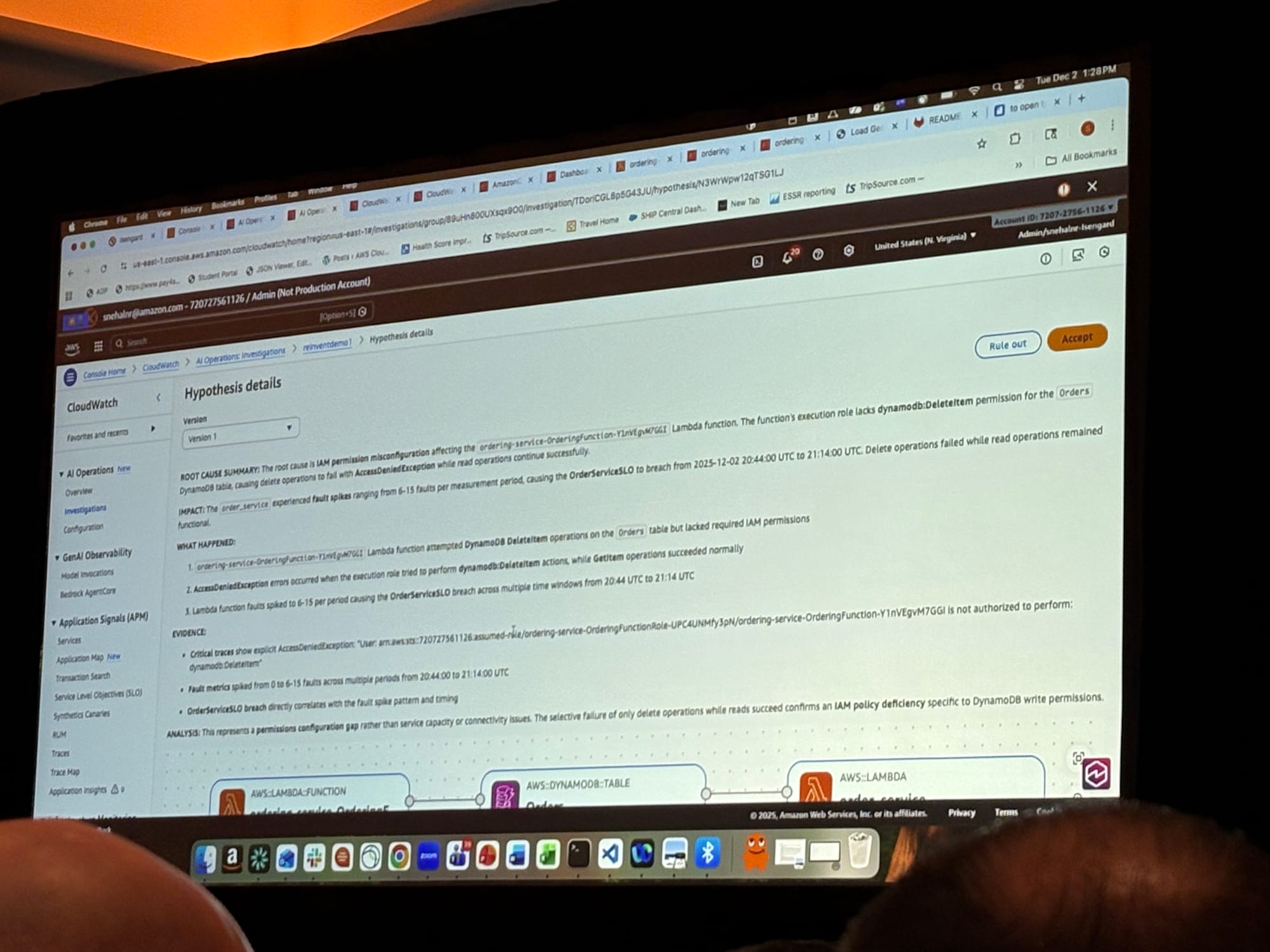
仮説の詳細画面では以下の情報が表示されます。
- ROOT CAUSE SUMMARY: 根本原因の要約
- IMPACT: サービスへの影響範囲
- WHAT HAPPENED: 時系列での事象説明
- EVIDENCE: 証拠となるメトリクス、ログ、トレース
- ANALYSIS: 問題の分析結果
デモでは、Lambda関数のIAMロールにdynamodb:DeleteItem権限が不足していたことが根本原因として特定されました。
インシデントレポート生成(2025年新機能)
2025年10月に追加された機能として、インタラクティブなインシデントレポート生成があります。ワンクリックでインシデントサマリを生成でき、AWSが内部で使用している**「5 Whys」分析ワークフロー**も統合されています。
これにより、以下が自動的に収集・相関付けされます。
- テレメトリデータ(メトリクス、ログ、トレース)
- デプロイメント情報
- 構成変更履歴
- 調査中のアクションとテキスト
サポートされるデータソース
CloudWatch Investigationsは以下のデータソースをサポートしています。
- CloudTrail
- CloudWatch Logs
- CloudWatch Metrics
- Amazon EKS
- VPC Flow Logs
- コンテナログ
- Database Insights(RDS向け)
データを多く提供するほど、AIの分析精度が向上します。
外部サービスとの連携
2025年には、以下の外部サービスとのコネクタが追加されました。
- Microsoft Teams
- ServiceNow
- PagerDuty
- Grafana
これにより、既存のインシデント管理ワークフローとの統合が可能になっています。
Model Context Protocol(MCP)
**Model Context Protocol(MCP)**は、Anthropicが2024年後半に発表したオープンプロトコルで、アプリケーションがLLM(大規模言語モデル)にコンテキストを提供する方法を標準化します。
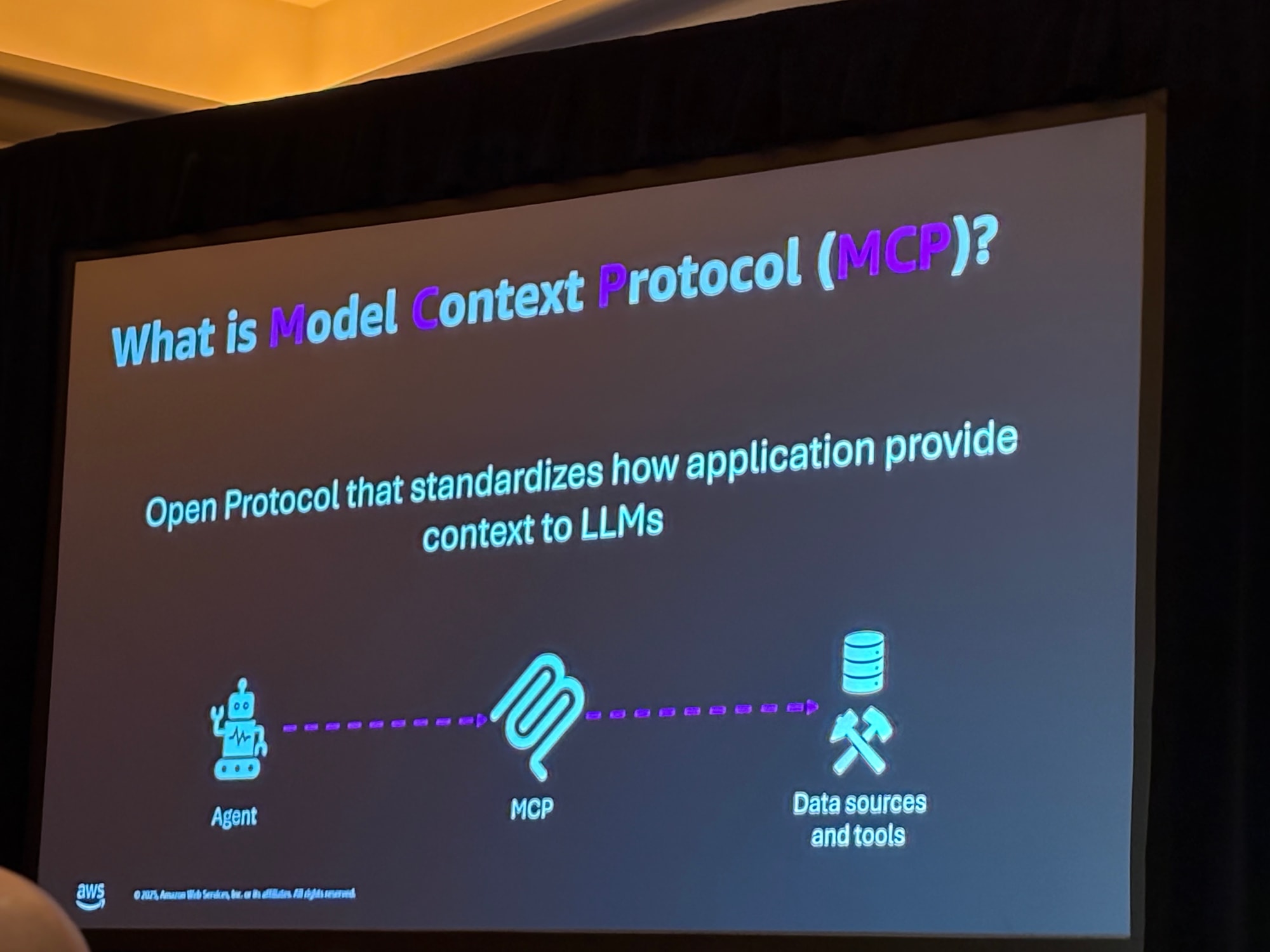
MCPにより、AIエージェントは様々なデータソースやツールと標準化された方法で連携できるようになります。
CloudWatchとApplication Signals MCPサーバー
AWSは、CloudWatchとApplication Signals用のMCPサーバーを提供しています。これにより、Amazon Q Developer、Claude、GitHub Copilotなど様々なAIアシスタントからオブザーバビリティデータに自然言語でアクセスできます。

CloudWatch MCPサーバーのツール
| ツール名 | 機能 |
|---|---|
analyze_log_group |
ロググループの分析 |
cancel_logs_insight_query |
Logs Insightsクエリのキャンセル |
describe_log_groups |
ロググループの一覧取得 |
execute_log_insights_query |
Logs Insightsクエリの実行 |
get_active_alarms |
アクティブなアラームの取得 |
get_alarm_history |
アラーム履歴の取得 |
get_logs_insight_query_results |
クエリ結果の取得 |
get_metric_data |
メトリクスデータの取得 |
get_metric_metadata |
メトリクスメタデータの取得 |
get_recommended_metric_alarms |
推奨アラームの取得 |
Application Signals MCPサーバーのツール
| ツール名 | 機能 |
|---|---|
get_service_detail |
サービス詳細の取得 |
get_slo |
SLO情報の取得 |
list_monitored_services |
監視対象サービスの一覧 |
list_slis |
SLI一覧の取得 |
query_sampled_traces |
サンプルトレースのクエリ |
query_service_metrics |
サービスメトリクスのクエリ |
search_transaction_spans |
トランザクションスパンの検索 |
Application Signals
Amazon CloudWatch Application Signalsは、AWSでアプリケーションを自動的に計測し、サービスの状態を監視するための機能です。
主な特徴
- SLO/SLI管理: サービスレベル目標を定義し、レイテンシーやエラー率などのメトリクスを自動追跡
- コード変更不要: AWS Distro for OpenTelemetry SDKを使用した自動計装
- 自動ダッシュボード: ボリューム、可用性、レイテンシー、エラーなどの標準メトリクスを視覚化
- サービスマップ: アプリケーション、サービス、依存関係を統合ビューで表示
- クロスアカウント対応: 複数AWSアカウントにまたがるアプリケーションの監視が可能
対応言語・プラットフォーム
- Java
- Python
- .NET(バージョン1.6.0以降)
- Node.js(ランタイムメトリクスは収集されない)
デモ:MCPサーバーを使った自律型調査
セッションでは、Amazon Q Developer CLIとMCPサーバーを使用した自律型調査のデモが行われました。
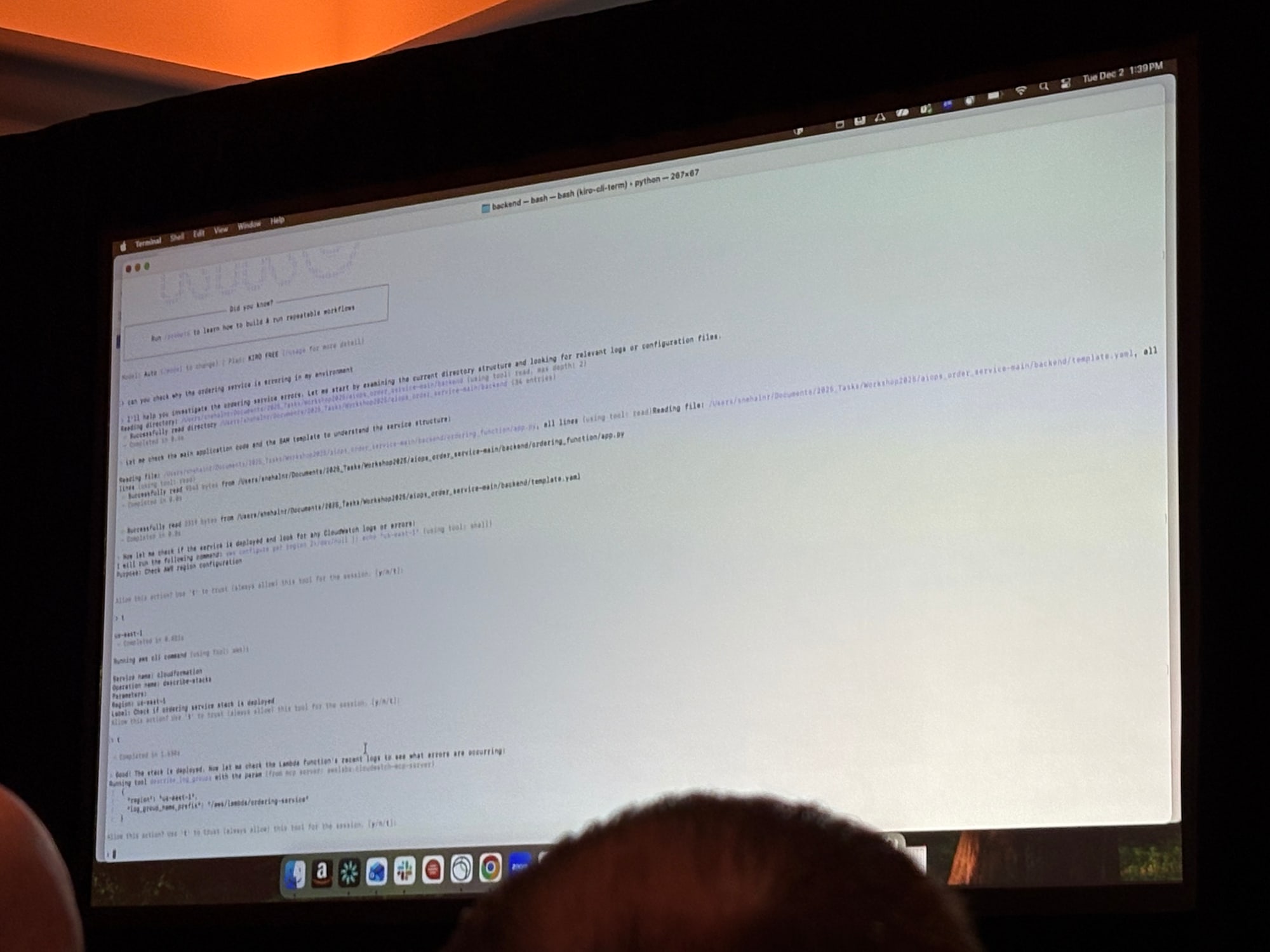
デモの流れ
- 問題の検知: OrderServiceでエラーが発生
- 自然言語での問い合わせ: 「order_serviceで何が起きているか確認して」
- AIによる調査: MCPサーバーを通じてCloudWatchログ、メトリクス、トレースを自動収集
- 根本原因の特定: Lambda関数のIAMポリシーにDynamoDBへのDeleteItem権限が不足
- 修正の提案と実行: AIが修正方法を提案し、承認後に自動修正
スピーカーによると、従来であれば数時間かかっていたトラブルシューティングが、この方法では約20分で完了したとのことです。
信頼性とセキュリティ
デモでは、AIが各アクションの前に「このツールを使用してよいか?」と確認を求めていました。
自律型でありながらも、重要な操作には人間の承認が必要という設計になっています。
MSPでの活用事例
セッションでは、MSP(Managed Service Provider)での活用事例も紹介されました。
- 従来: 1人のエンジニアが5〜10件の顧客を担当
- 現在: CloudWatch InvestigationsとMCPサーバーの活用により、1人のエンジニアが15〜20件の顧客を担当可能に
これは、調査時間の短縮と自動化により、エンジニアの生産性が大幅に向上した結果です。
まとめ
本セッションのポイントをまとめます。
- ダウンタイムコストは甚大であり、1時間あたり30万〜500万ドルの損失が発生し得る
- CloudWatch Investigationsは2025年6月にGAとなり、AIによる根本原因分析の自動化が可能になった
- MCPサーバーにより、CloudWatchとApplication SignalsのデータにAIエージェントが直接アクセス可能になった
- 段階的なアプローチが推奨される。まずはCloudWatch Investigationsでアシスト型から始め、慣れてきたらMCPサーバーを使った自律型へ移行
感想
AIを活用したインシデント調査は、障害対応をされている方にとっては必ず思い描く理想系ですよね。
(規模によらず既に導入されている現場もあるかと思います。)
今回のセッションはそれを具体化するための一歩として勉強になる内容でした。
個人的にAmazon Q DeveloperやClaude CodeなどのAIエージェントは日常的によく使用するのですが、CloudWatch Investigationsは使用したことがなかったため、これを機に触ってみようと思います。
これだけ多種多様なAIサービスが出てくると、アラート調査に限定しても最適な選択に頭を悩ませますね...
情報のインプットだけに留めず、色々検証した上で個別の最適解を模索して、またブログでアウトプットいたします!
以上、大野でした!
参考リンク
- Amazon CloudWatch Investigations - AWS公式ドキュメント
- Amazon CloudWatch Application Signals
- AWS MCP Servers - GitHub
- Enhance your AIOps: Introducing Amazon CloudWatch and Application Signals MCP servers
- 2025 Top 10 Announcements for AWS Cloud Operations
- Building AIOps with Amazon Q Developer CLI and MCP Server








