
Linderaで日本語を形態素解析してPostgreSQLの全文検索を最小限の努力で動かす
Lindera はRustで実装された形態素解析ライブラリです。全文検索エンジンMeilisearchでもCJK言語のトークナイザーとして採用されています。
Lindera を Python から呼び出す機会、より具体的には、検索の前処理として形態素解析で単語をスペース区切りにし、PostgreSQLの to_tsvector 方式の全文検索を動作させる機会があったので、共有します。
シンプルなアプローチですが、最小限の努力で日本語の全文検索に対応できます。
形態素解析のモチベーション
全文検索システムでは、文書を検索可能な単語(トークン)に分割し、単語がどのドキュメントのどの位置に出現するかという転置インデックスを作成することが多いです。
日本語と単語分割
"I live in Tokyo." のような英文の場合、文章を空白や記号で分割すれば簡単に単語分割できます。
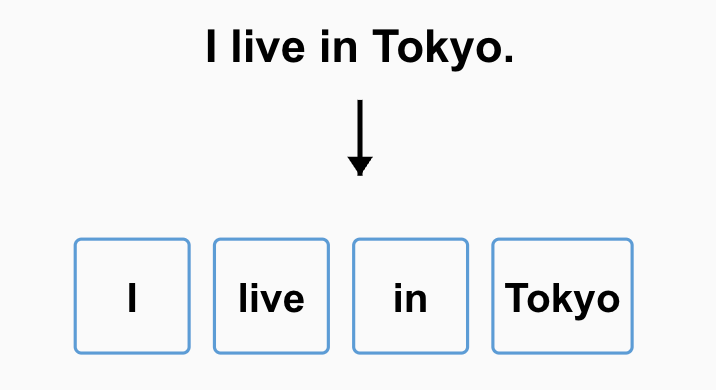
日本語・中国語・韓国語のように単語の区切りがない言語の場合、主に2つのアプローチがあります。
1. N-gram方式
N-gramは文字列を文字単位で分割する方法です。
Nは文字数が入り、N=2の場合はbi-gram、N=3の場合はtri-gramと呼びます。
N=3 で「全文検索エンジン」を分割する場合は、次のようになります。
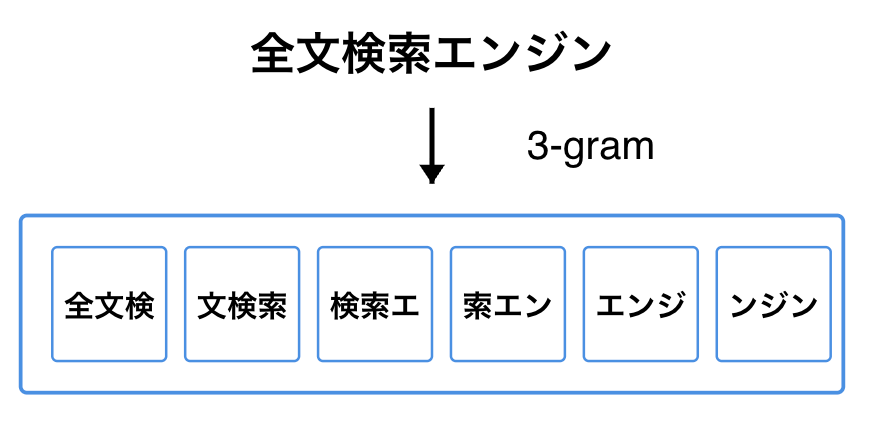
この例では、「全文検」や「ンジン」のような文字列で検索するとマッチします。
2. 形態素解析方式
形態素解析は辞書と文法規則を使って、文章を単語で分割する方法です。
「全文検索エンジン」を 形態素解析 で分析する場合は、次のようになります。
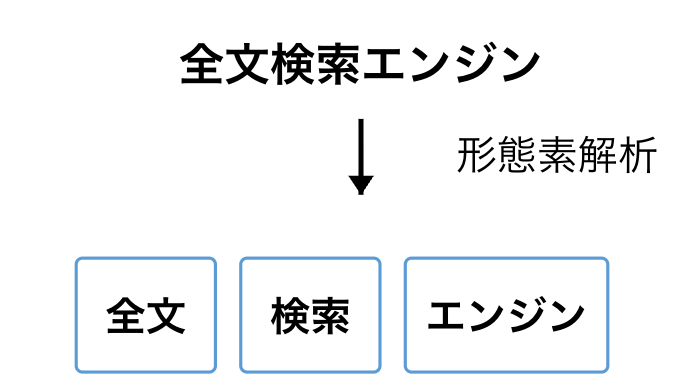
N-gram 方式は文字単位で処理すればよいですが、形態素解析の場合、辞書が必要になります。
日本語の形態素解析用の辞書として IPADic や 国立国語研究所がメンテナンスしている UniDic などが有名です。
形態素解析の前処理を挟んで PostgreSQLのto_tsvectorで日本語を全文検索させる
PostgreSQLで全文検索する場合、単語分割は以下の様なアプローチがあります。
- スペース分割
- 形態素解析
- 未対応
- N-Gram
N-Gram 系であれば期待通りに動作するでしょう。
一方で、to_tsvector 方式は日本語・中国語などの検索で注意が必要です。
Amazon Bedrock Knowledge BasesでPostgreSQLをバックエンドにした場合のハイブリッド検索の全文検索もこの方式です。
to_tsvector 関数は引数に言語を指定することで、より言語に親和性のある単語分割が可能です。
# デフォルトの 'simple'
select to_tsvector('simple', 'i have a pen.') ;
to_tsvector
------------------------------
'a':3 'have':2 'i':1 'pen':4
(1 row)
# 英語モードの 'english'. stop wordも除去
select to_tsvector('simple', 'i have a pen.') ;
to_tsvector
-------------
'pen':4
(1 row)
ただし、日本語ロケール(ja) が存在せず、デフォルトの simple では日本語文字列をうまく単語分割できません。
# 日本語をうまく分割できない
select to_tsvector('simple', 'LinderaはRust製の形態素解析ライブラリです');
to_tsvector
-----------------------------------------------
'linderaはrust製の形態素解析ライブラリです':1
(1 row)
1文で一つのトークンとして扱われ、このような状態でインデクシング(gin)されると、 "lindera" や "形態素" や "ライブラリ" ではマッチせず、 "linderaはrust製の形態素解析ライブラリです" 一文を検索キーワードしないと、マッチしません。
そこで、Linderaによる形態素解析の前処理を挟み、テキストをあらかじめ単語分割してスペースを挿入することで to_tsvector がパースできるようにお膳立てするのが、本記事の趣旨です。
SELECT to_tsvector('simple', 'Lindera は Rust 製 の 形態素 解析 ライブラリ です');
to_tsvector
---------------------------------------------------------------------------------------
'lindera':1 'rust':3 'です':9 'の':5 'は':2 'ライブラリ':8 '形態素':6 '製':4 '解析':7
(1 row)
もう少し見やすくします
SELECT
lexeme AS word,
pos AS position
FROM
unnest(to_tsvector(
'simple',
'Lindera は Rust 製 の 形態素 解析 ライブラリ です'
)) AS u(lexeme, positions),
unnest(positions) AS pos
ORDER BY
pos;
word | position
------------+----------
lindera | 1
は | 2
rust | 3
製 | 4
の | 5
形態素 | 6
解析 | 7
ライブラリ | 8
です | 9
(9 rows)
このように前処理しておけば、 GIN(generalized inverted index)インデックスやこの転置インデックスを利用した全文検索も直感通りに動作します。
Lindera を Python から使ってみる
Lindera は Rust 製です。
本記事では、辞書込みの Pythonバインディングの使い方を紹介します。
インストール
uvを使用してLindera Pythonをインストールします。
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ source $HOME/.local/bin/env
$ uv init -p 3.13 lindera-test
Initialized project `lindera-test` at `/home/ubuntu/lindera-test`
$ cd lindera-test
$ uv add lindera-python-ipadic # IPAdic辞書を使用する場合
Lindera-Python は Lindera 単体(lindera-python)でのインストールも可能ですが、形態素解析用の辞書も組み込まれたパッケージでインストールするのが楽でしょう。
lindera-python-ipadic: IPAdic 版lindera-python-unidic: 国立国語研究所が管理する UniDic版
などがあります。
基本的な使用例
以下のコードで、日本語テキストを形態素解析できます。
from lindera import TokenizerBuilder
# トークナイザーの設定と構築
builder = TokenizerBuilder()
builder.set_mode("normal") # 解析モードを設定
builder.set_dictionary("embedded://ipadic") # IPAdic辞書を使用
tokenizer = builder.build()
text = "LinderaはRust製の形態素解析ライブラリです"
tokens = tokenizer.tokenize(text)
for token in tokens:
print(token)
$ uv run main.py を実行
$ uv run main.py
{'byte_end': 7, 'byte_start': 0, 'part_of_speech': 'UNK', 'surface': 'Lindera', 'word_id': 4294967295}
{'base_form': 'は', 'byte_end': 10, 'byte_start': 7, 'conjugation_form': '*', 'conjugation_type': '*', 'part_of_speech': '助詞', 'part_of_speech_subcategory_1': '係助詞', 'part_of_speech_subcategory_2': '*', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'ワ', 'reading': 'ハ', 'surface': 'は', 'word_id': 57063}
{'byte_end': 14, 'byte_start': 10, 'part_of_speech': 'UNK', 'surface': 'Rust', 'word_id': 4294967295}
{'base_form': '製', 'byte_end': 17, 'byte_start': 14, 'conjugation_form': '*', 'conjugation_type': '*', 'part_of_speech': '名詞', 'part_of_speech_subcategory_1': '接尾', 'part_of_speech_subcategory_2': '一般', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'セイ','reading': 'セイ', 'surface': '製', 'word_id': 339290}
{'base_form': 'の', 'byte_end': 20, 'byte_start': 17, 'conjugation_form': '*', 'conjugation_type': '*', 'part_of_speech': '助詞', 'part_of_speech_subcategory_1': '連体化', 'part_of_speech_subcategory_2': '*', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'ノ', 'reading': 'ノ', 'surface': 'の', 'word_id': 55831}
{'base_form': '形態素', 'byte_end': 29, 'byte_start': 20, 'conjugation_form': '*', 'conjugation_type': '*', 'part_of_speech': '名詞', 'part_of_speech_subcategory_1': '一般', 'part_of_speech_subcategory_2': '*', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'ケイタイソ', 'reading': 'ケイタイソ', 'surface': '形態素', 'word_id': 210978}
{'base_form': '解析', 'byte_end': 35, 'byte_start': 29, 'conjugation_form': '*', 'conjugation_type': '*', 'part_of_speech': '名詞', 'part_of_speech_subcategory_1': 'サ変接続', 'part_of_speech_subcategory_2': '*', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'カイセキ', 'reading': 'カイセキ', 'surface': '解析', 'word_id': 345571}
{'base_form': 'ライブラリ', 'byte_end': 50, 'byte_start': 35, 'conjugation_form': '*', 'conjugation_type': '*', 'part_of_speech': '名詞', 'part_of_speech_subcategory_1': '一般', 'part_of_speech_subcategory_2': '*', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'ライブラリ', 'reading': 'ライブラリ', 'surface': 'ライブラリ', 'word_id': 101073}
{'base_form': 'です', 'byte_end': 56, 'byte_start': 50, 'conjugation_form': '特殊・デス', 'conjugation_type': '基本形', 'part_of_speech': '助動詞', 'part_of_speech_subcategory_1': '*', 'part_of_speech_subcategory_2': '*', 'part_of_speech_subcategory_3': '*', 'pronunciation': 'デス', 'reading': 'デス', 'surface': 'です', 'word_id': 47494}
テキストをスペース区切りに変換
今回の目的は、テキストを一度単語分割し、スペース区切りのテキストを作ることです。各トークンのsurfaceを取り出して連結します。
from lindera import TokenizerBuilder
builder = TokenizerBuilder()
builder.set_mode("normal")
builder.set_dictionary("embedded://ipadic")
tokenizer = builder.build()
def prep(text: str) -> str:
"""単語をスペース区切りにして出力"""
tokens = tokenizer.tokenize(text)
return " ".join(token["surface"] for token in tokens)
text = "LinderaはRust製の形態素解析ライブラリです"
print(prep(text))
実行してみましょう。
$ uv run test.py
Lindera は Rust 製 の 形態素 解析 ライブラリ です
期待通りの出力を得られました。
このようにテキストの単語の区切りが明確になっていると、後工程のナイーブなパーサーでも単語分割しやすくなります。
まとめ
トークナイザーが欧米系言語前提の全文検索システムで日本語を扱いたいとき、Linderaを使えば簡単に対応できます。
def prep(text: str) -> str:
tokens = tokenizer.tokenize(text)
return " ".join(token['surface'] for token in tokens)
たった3行のコードで、日本語テキストをスペース区切りに変換できます。このような前処理を施してインデクシングすれば、既存のスペースによる単語分割ベースの全文検索システムを大きく変更することなく、日本語検索に対応できます。










