
「失敗の積み重ね」がLLMを生んだ — 別々の問題を解こうとした人々の80年
はじめに
ChatGPTやClaudeのような大規模言語モデル(LLM)は、「LLMを作ろう」という目標から生まれたものではありません。
数学の限界を証明しようとした人、電話回線のノイズを減らそうとした人、機械翻訳の精度バグを直そうとした人——それぞれが全く別の問題を解いた副産物が、80年かけて積み重なってLLMになりました。
この記事では「その意図せぬ接続がどうなっているか」を順番に追います。ML・数学の知識は前提としません。
きっかけはFireshipのYouTube動画でした。LLMの歴史をコンパクトにまとめた内容に刺激を受け、「それぞれの発明が本当はどんな問題を解こうとしていたのか」をもっと深く掘り下げたくなり、この記事を書くことにしました。
1. 「計算する」とはどういうことか? — Alan Turing (1936)
解こうとした問題
1930年代の数学界には、こんな夢がありました。
「数学のあらゆる命題は、アルゴリズムによって『真か偽か』を決定できるはずだ。」
これは 決定問題(Entscheidungsproblem) と呼ばれ、数学の巨人ヒルベルトが提唱しました。要するに「数学を完全に機械化できるか?」という問いです。
イギリスの数学者アラン・チューリングは、これが本当かどうかを証明しようとしました。
チューリングの翻訳:数学の問いをプログラムの問いへ
チューリングの鮮やかな発想は、問いを別の問いに翻訳したことです。
「数学の命題を決定するアルゴリズム」が存在するとしたら、それはこう動くはずです:
証明を探し続ける → 証明が見つかったら停止する → 見つからなければ永遠にループする
つまり「数学を機械化できるか?」という問いは、「プログラムが停止するかループするかを判定できるか?」という問いと同じになります。
だから、もし停止問題が解けないと証明できれば、数学の機械化も不可能だと証明できる。チューリングはそこを狙いました。
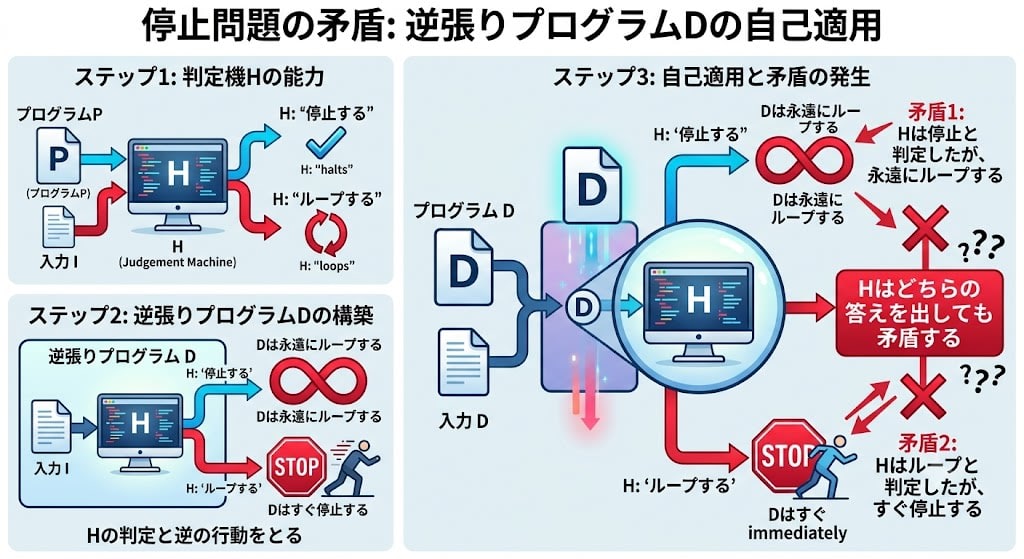
「停止問題」:自己言及が生む矛盾
「どんなプログラムでも、実行前に停止するかループするかを判定できる万能プログラム(判定機H)は作れるか?」
答えはNo。理由は「嘘つきのパラドックス」と同じ構造です。
「この文は偽である。」
→ 真なら偽。偽なら真。どちらも矛盾する。
判定機Hで同じ罠を作れます:
- 判定機Hを使って「逆張りプログラムD」を作る
- Hが「停止する」と言ったら → Dは永遠にループする
- Hが「ループする」と言ったら → Dはすぐ停止する
- DをD自身に適用する(自分で自分を判定させる)
- Hがどちらの答えを出しても矛盾する
これが「嘘をつく文」と同じ構造です。自分自身を参照した瞬間、どんな答えも矛盾する。 判定機Hは原理的に存在できない。
つまり「数学を完全に機械化できるか?」という夢は、不可能であることが証明されました。
意図せぬ副産物:「1台で何でもできる」コンピュータの概念
重要なのは証明の結論ではなく、証明のために必要だったものです。
「停止問題を証明する」ためには、まず「計算するとは何か」を厳密に定義しなければなりませんでした。そのために生まれたのがチューリングマシン——テープに書かれた記号を読み書きし、規則に従って状態を変える抽象的な機械のモデルです。
チューリングはさらに、この機械の決定的な性質に気づきました。プログラム自体もデータである。
どういうことか。
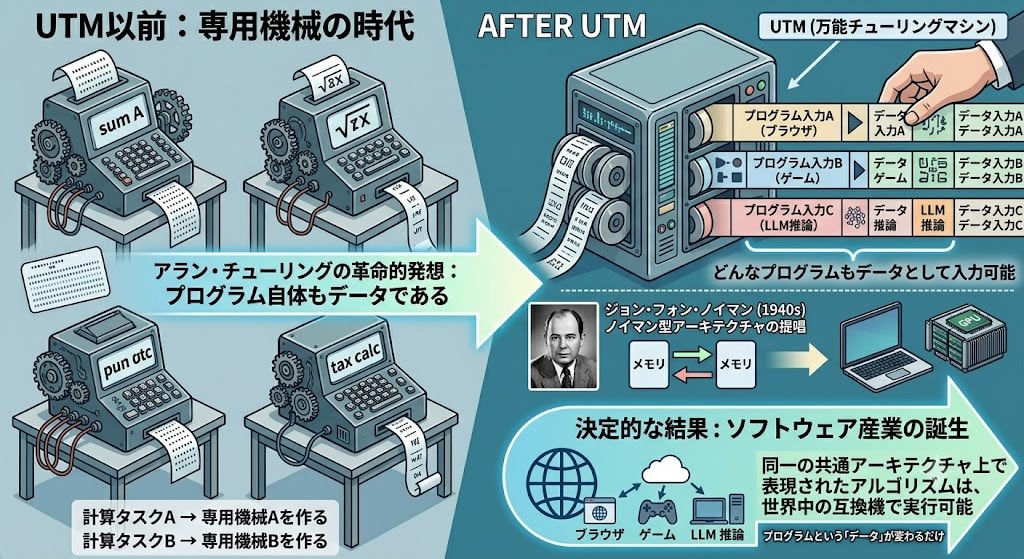
チューリングマシンのテープには「入力データ」を書けます。しかし「どう動くかの手順(プログラム)」も同じテープに書けます。つまり手順もデータの一種です。そうなると——「どんなプログラムの記述でも入力として受け取り、それを実行できる万能機械」が作れる。
これを 万能チューリングマシン(Universal Turing Machine) と言います。
この発想が革命的だった理由は、それ以前の世界と比べるとわかります:
UTM以前: 計算タスクA → 専用機械Aを作る
計算タスクB → 専用機械Bを作る
計算タスクC → 専用機械Cを作る
UTM以後: どんなタスクでも → 同じ1台の機械 + 異なるプログラム(入力)
これがあなたのノートPCです。ブラウザもゲームもLLMの推論も、ハードウェアは変わらない。プログラムという「データ」が変わるだけです。
ジョン・フォン・ノイマンはチューリングの論文を読んで、1940年代にこの概念を実際のコンピュータ設計に落とし込みました(ノイマン型アーキテクチャ)。プログラムをデータと同じメモリに格納する——今のコンピュータすべてがこの設計を踏襲しています。
この設計が業界標準になったことで、決定的なことが起きました。この共通アーキテクチャ上で表現できるアルゴリズムは、対応するどのハードウェアでも動く。 誰でもプログラムを書けば、世界中の互換機で実行できる。特定の専用機を持たなくても、アルゴリズムのアイデアさえあれば参加できる。これがソフトウェア産業の土台であり、LLMの訓練コードが世界中のGPUクラスタで走る理由でもあります。
ただし1936年の証明はもう一つのことも確定させました。チューリング自身が引いた「計算可能性の限界」は、LLMにも適用される。 ChatGPTもClaudeも、原理的に停止問題を解くことはできない——つまり、任意のプログラムが正しいかどうかを完全に保証することは不可能です。コンピュータを生んだ同じ論文が、そのコンピュータ上で動くあらゆるAIの永続的な天井も定義していました。
数学の限界を証明しようとして、「1台で何でもできるコンピュータ」という概念が生まれた。
余談: チューリングはこの14年後の1950年に「機械は考えられるか?」という問いを立て、人間と機械を区別できるかを試すチューリングテストを提案しました。LLMの能力を評価する会話テストの概念的な先祖です。また、コンピュータ科学の最高栄誉賞は**チューリング賞(ACM Turing Award)**と呼ばれ、「コンピュータ科学のノーベル賞」と言われるほどの権威があります。後述しますが、深層学習の立役者たちもこの賞を受賞しています。
2. 「情報」を数学で測れるか? — Claude Shannon (1948)
解こうとした問題
1940年代、ベル研究所の研究者クロード・シャノンには実務的な悩みがありました。
「ノイズだらけの電話回線で、どれだけ正確に情報を送れるか?」
AIとも機械学習とも無関係な、電話工学の問題です。
なぜ「情報とは何か」を定義する必要があったのか
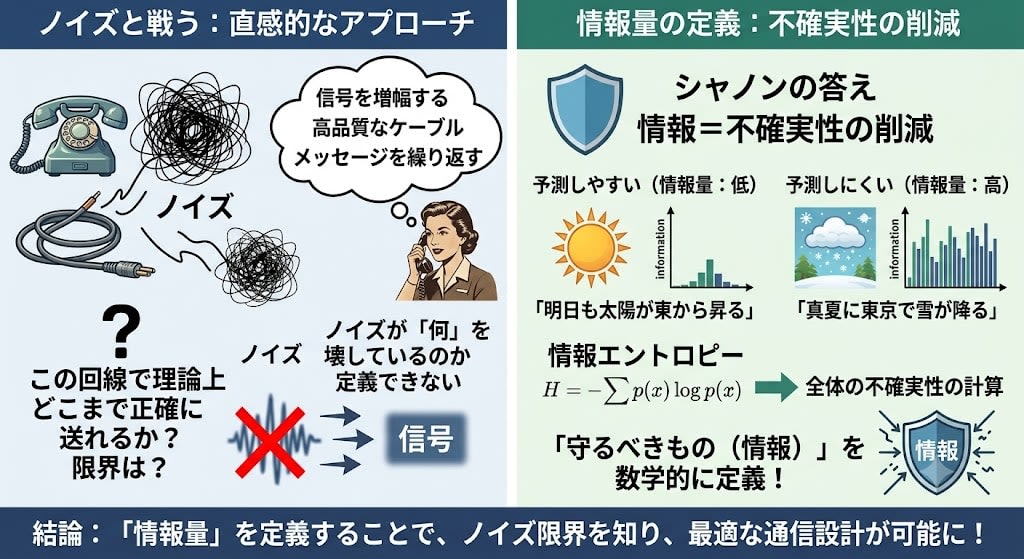
当時の電話技術者たちはノイズに対して直感的に対処していました。信号を増幅する、ケーブルの品質を上げる、メッセージを繰り返す。しかし、ある根本的な問いに答えることができませんでした。
「このノイズだらけの回線で、理論上どこまで正確に情報を送れるか? 限界はどこか?」
答えられない理由はシンプルです。ノイズが何を壊しているのかを数学的に定義できなかったから。
考えてみてください。ノイズは信号を壊します。では、信号の「何」が壊れると困るのか?
例えば「THE CAT SAT ON THE MAT」というメッセージがノイズで一部化けた場合:
- 「CAT」の「C」が消える → 意味が壊れる。致命的。
- 「THE」が「TH_」になる → 読み手が復元できる。問題なし。
- 2回目の「THE」が消える → 読み手はすでに予測している。情報損失は小さい。
ここに重要な発見があります。メッセージのすべての部分が等しい情報を持っているわけではない。 予測しやすい部分は情報が少なく、予測しにくい部分は情報が多い。ノイズが本当に害を与えるのは、情報量が大きい部分を壊したときです。
つまりノイズと戦うには、まず「何を守るべきか」を知る必要がある。守るべきものを知るには、「情報とは何か」を定義する必要がある。
「情報量」を定義する
シャノンの答え:「情報とは、不確実性の削減である。予測できなかったことが起きたほど、情報量が多い。」
「明日も太陽が東から昇る」——誰でも知っている。情報量はほぼゼロ。
「真夏に東京で雪が降る」——予測外。情報量が大きい。
この直感を数式にしたのが情報エントロピーです。「各出来事の起こりやすさ(確率)をもとに、全体の予測しにくさを計算する」式で、予測が難しいほど大きな値になります。
ちなみに「bit(ビット)」という単語もこの時代に登場しますが、シャノン自身が発明したのではありません。0と1という二進数の概念はライプニッツ(1703年)まで遡り、「bit」という単語は同僚のジョン・チューキーが作ってシャノンが論文で広めました。シャノンの本質的な発明は「0か1か」ではなく、情報を定量化する数学そのものです。
余談: AnthropicのAIアシスタント「Claude」は、クロード・シャノンにちなんで名付けられたと広く言われています。情報理論を生んだシャノンの名を冠するAIというのは、なかなか示唆的な選択です。
シャノンの答えが解き放った工学
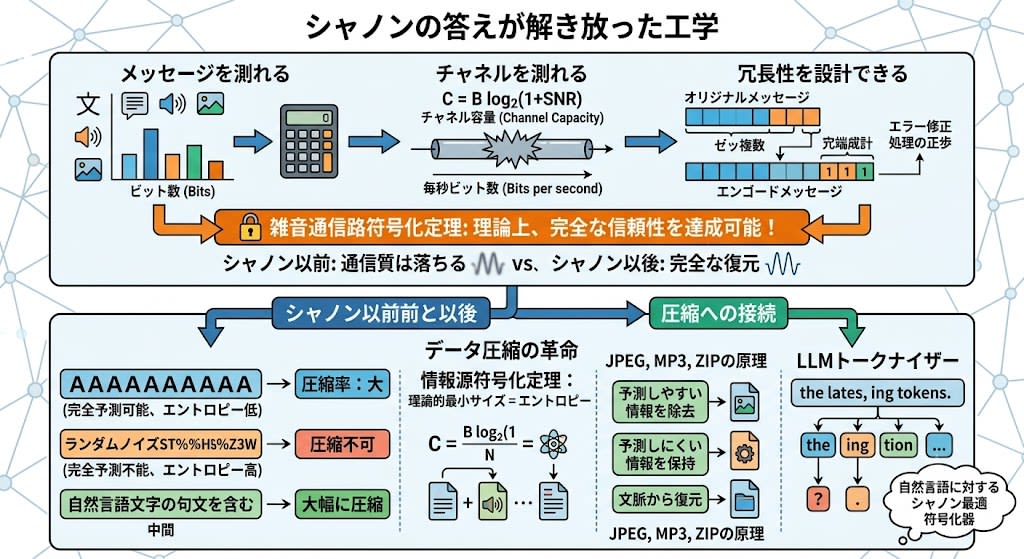
情報を定義したことで、すべてが定量化できるようになりました:
- メッセージを測れる — 何ビットの情報を含んでいるか計算できる
- チャネルを測れる — 回線が毎秒何ビット確実に運べるか(チャネル容量)を計算できる
- 冗長性を設計できる — エラー訂正のために何ビット追加すべきか計算できる
そして最も重要な結果——雑音通信路符号化定理:情報レートがチャネル容量を下回る限り、どれだけノイズが多くても、適切な符号化をすれば事実上エラーなしで通信できる。
シャノン以前、技術者はノイズが多い回線では通信の質が落ちるのは避けられないと考えていました。シャノンはそうではないことを証明した。ノイズは限界を定めるが、その限界以下であれば完全な信頼性は達成可能——正しい符号化さえあれば。
圧縮への接続:情報が少ない部分は捨てられる
シャノンの情報量の定義は、もう一つの革命を生みました——データ圧縮です。
情報源符号化定理によれば、メッセージを圧縮できる理論的な最小サイズは、そのエントロピー(情報量)に等しい。つまり:
- 「AAAAAAAAAA」—— 完全に予測可能、エントロピーほぼゼロ → ほぼゼロまで圧縮できる
- ランダムノイズ —— 完全に予測不能、エントロピー最大 → 圧縮不可能
- 自然言語 —— 中間、パターンが多い → 大幅に圧縮可能
JPEG、MP3、ZIPファイル——すべてこの原理です。予測しやすい(情報量が低い)部分を取り除き、予測しにくい(情報量が高い)部分を保持する。展開時には、文脈から予測可能な部分を復元する。
LLMのトークナイザー(BPE——Byte Pair Encoding)もこの意味で圧縮です。頻出するシーケンス("the"、"ing"、"tion")は1つのトークンになり、稀なシーケンスは文字単位のまま残る。トークナイザーは文字通り、自然言語に対するシャノン最適符号化器です。
LLMへの接続:訓練から推論まで
訓練:クロスエントロピー損失
LLMを訓練するときの核心的な問いは「モデルは次の単語をどれだけ正確に予測できているか?」です。
この「予測の正確さ」を測る指標として使われるのがクロスエントロピー損失——シャノンのエントロピーから直接導かれます。
損失 = -(正解の確率 × log(モデルの予測確率) の合計)
LLMが学習するとき、モデルはひたすらこの数値を小さくしようとします。言い換えれば、次のトークンに対する「驚き」を減らすことが訓練の全目的です。シャノンが定義した「情報 = 不確実性の削減」がそのまま学習目標になっている。
推論:Temperatureはエントロピーのノブ
シャノンの「驚き」の概念は、LLMの出力制御にも直結します。Temperatureパラメータは、出力分布のエントロピーを直接操作するノブです。
P(トークン) = softmax(logit / temperature)
| Temperature | 分布への効果 | シャノンエントロピー |
|---|---|---|
| → 0 | 最高確率のトークンに集中 | エントロピー → 0(驚きゼロ) |
| = 1 | モデル本来の分布 | 自然なエントロピー |
| > 1 | 分布が平坦化、全トークンがより均等 | エントロピー上昇(驚き増加) |
Temperature低い = 最も予測可能(情報量が少ない)トークンを常に選ぶ。Temperature高い = より高エントロピーな分布からサンプリング = 創造的だが一貫性が下がる可能性。
「もっと創造的に書いて」とTemperatureを上げるとき、あなたは文字通り出力のシャノンエントロピーを上げている。
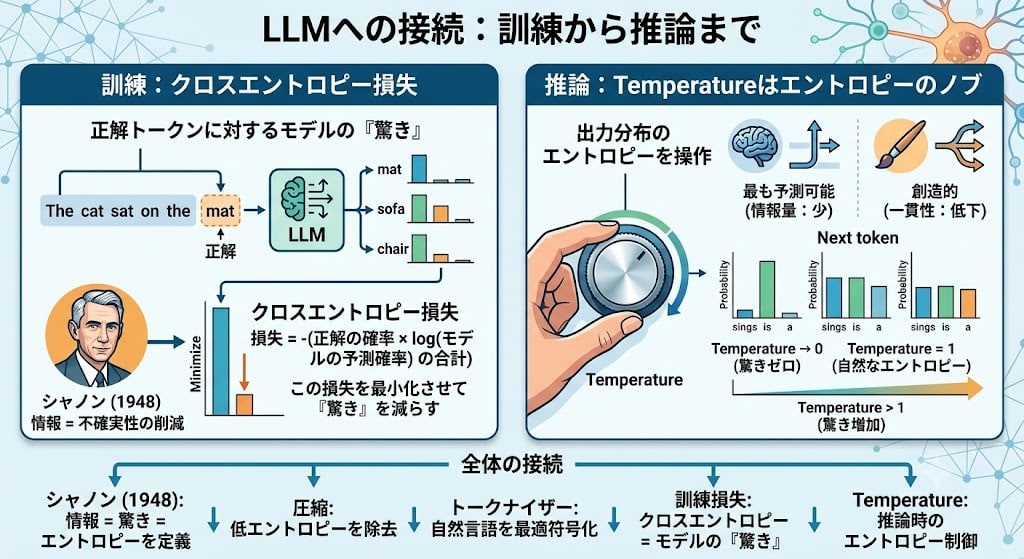
全体の接続
Shannon (1948): 情報 = 驚き = エントロピー を定義
↓
圧縮: 低エントロピー(予測可能)な部分を除去、高エントロピーを保持
↓
トークナイザー: BPEが同じ原理で言語を最適符号化
↓
訓練損失: クロスエントロピー = 正解トークンに対するモデルの「驚き」
↓
Temperature: 推論時に出力分布のエントロピーを制御
一つの数学的フレームワークが、LLMの構築と運用のすべての層に適用されています。電話回線のノイズを減らしたかったシャノンの数学が、80年後にLLMの「賢さの定義」にも「創造性の調整ノブ」にもなっている。
3. 機械は学べるか? — 楽観、挫折、復活
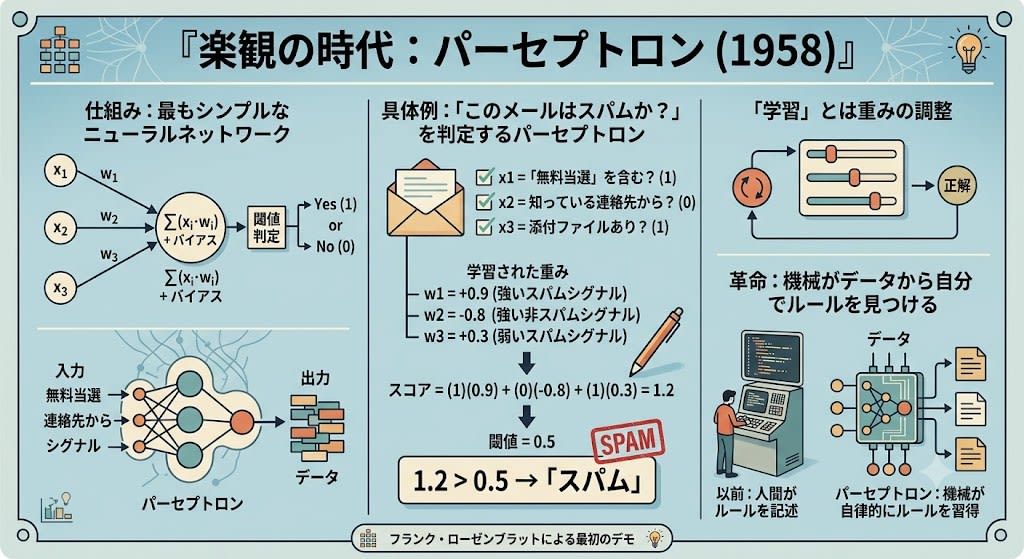
楽観の時代:パーセプトロン (1958)
「機械が学習できる」という最初のデモが、フランク・ローゼンブラットによるパーセプトロンでした。
仕組みはシンプルです。最もシンプルなニューラルネットワーク——「ニューロン」1つだけの回路です。
入力 重み 合計 出力
x1 ----(w1)----\
x2 ----(w2)-----→ Σ(xi·wi) + バイアス → 閾値判定 → 0 か 1
x3 ----(w3)----/
- 複数の入力(数値)を受け取る
- それぞれに「重み」をかけて足し合わせる
- 合計がある閾値を超えたら「Yes(1)」、超えなければ「No(0)」を出力する
具体例で見てみましょう。「このメールはスパムか?」を判定するパーセプトロン:
入力:
x1 = 「無料当選」を含む?(1 or 0)
x2 = 知っている連絡先から?(1 or 0)
x3 = 添付ファイルあり?(1 or 0)
学習された重み:
w1 = +0.9(強いスパムシグナル)
w2 = -0.8(強い非スパムシグナル)
w3 = +0.3(弱いスパムシグナル)
スコア = (1)(0.9) + (0)(-0.8) + (1)(0.3) = 1.2
閾値 = 0.5
1.2 > 0.5 → 「スパム」
「学習」とは、この重みの調整です。最初はランダムな重みで始め、答え合わせをしながら少しずつ重みを修正していく。何千回も繰り返すと、重みが適切な値に収束します。
パーセプトロン以前、すべてのプログラムは人間が手書きしたルールで動いていました。パーセプトロンは機械がデータから自分でルールを見つけるという革命的な概念のデモでした。
ニューヨーク・タイムズはこう報じました。「海軍が、歩いて話して見て書いて自己複製できる機械の胚種を発表した」。楽観的な空気が漂っていました。
挫折:第一次AIの冬 (1969)
マービン・ミンスキーとシーモア・ペパートが、冷水を浴びせました。
パーセプトロンには数学的な限界がある。
ここで一つの疑問が浮かぶかもしれません。「チューリングが1936年に証明したように、万能チューリングマシンはどんな計算でも実行できるはずだ。なぜXORごときが問題になるのか?」
答えは、チューリングの万能性とパーセプトロンの学習は全く別の能力だからです。
- チューリングの万能性: 正しいプログラムを人間が書けば、どんな計算でもできる。XOR?
if文1行で書ける。 - パーセプトロンの約束: 機械がデータから自分でルールを発見する。人間はルールを書かない。
XORが破壊したのは「計算能力」ではなく、「学習メカニズム」そのものです。
具体的に見ましょう。XOR(排他的論理和)は「2つの入力が両方1か両方0なら0、片方だけ1なら1」という単純なルールです。2次元平面にプロットすると:
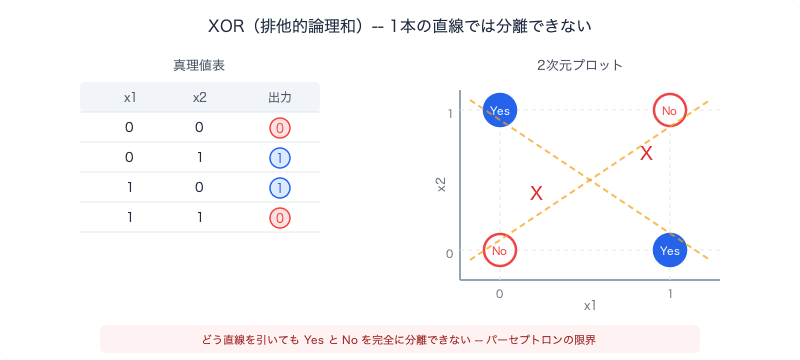
パーセプトロンは1本の直線でYesとNoを分離しようとします。しかし上の図を見れば、●と○を1本の直線で分けることは不可能です。どう線を引いても、必ず混ざります。
これだけなら「じゃあXORは特殊ケースだ」で済むかもしれません。しかしミンスキーとペパートが証明したのは、XORだけの話ではありませんでした。非線形な判定境界を必要とする問題のクラス全体——パリティ判定(偶数・奇数の判別)、対称性の検出、連結性の判定など——がすべてパーセプトロンには不可能だと示しました。XORは最もシンプルで、最も恥ずかしい反例にすぎません。
そしてこれが壊滅的だった理由は、期待と現実のギャップです。メディアは「歩いて話す機械」と報じた。数学者がその機械はXORすら学べないと証明した。資金を出す側の結論は「ニューラルネットワーク=行き止まり」。これが第一次AIの冬のきっかけです。研究資金が凍結され、多くのニューラルネットワーク研究者が職を失いました。

ただし彼らの著書には、一行の注記がありました。
「多層のネットワークならこの問題を解けるかもしれない。ただし、どう訓練するかは不明だ。」
この「ただし」が、次の17年間の研究課題を定義しました。
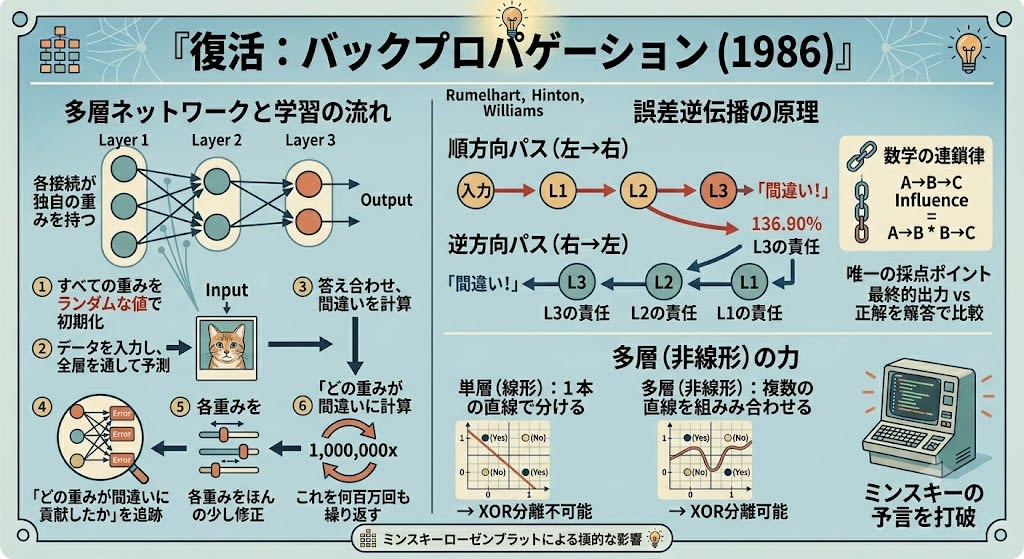
復活:バックプロパゲーション (1986)
「ただし」を解いたのがルメルハート、ヒントン、ウィリアムズによる バックプロパゲーション(誤差逆伝播法) です。
多層ネットワークとは、パーセプトロンを複数つなげたものです。各パーセプトロンがそれぞれ独自の重みを持ち、層ごとにグループ化されています。
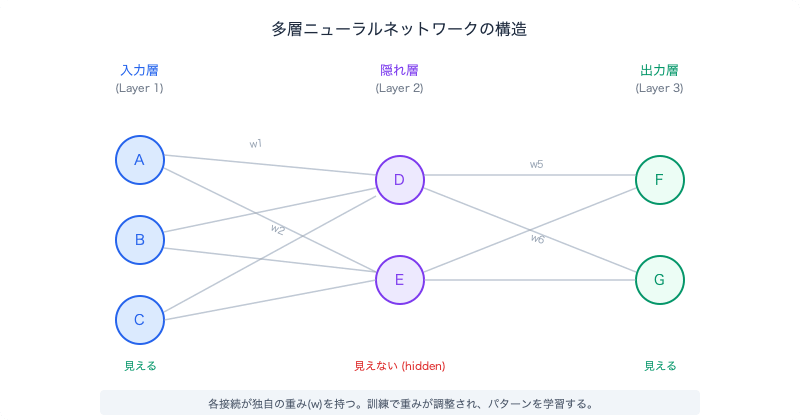
この図で真ん中のLayer 2は隠れ層(hidden layer)と呼ばれます。「隠れ」と言っても、何かを隠しているわけではありません。入力層はユーザーがデータを渡す場所、出力層はユーザーが結果を受け取る場所——どちらもユーザーから「見える」。一方、真ん中の層はユーザーが直接触ることのない内部の作業スペースです。外から見えないから「隠れ(hidden)」。
層が増えるとき、増えるのはこの隠れ層です。入力層と出力層は常に1つずつ。その間に隠れ層を何層積むかが「ネットワークの深さ」であり、これが「ディープ(深層)ラーニング」の「ディープ」の意味です。この「隠れ」という概念は第5章で再登場するので、覚えておいてください。
学習の流れは直感的です:
- すべての重みをランダムな値で初期化する(ランダムでないと全ニューロンが同じことを学んでしまう)
- データを入力し、全層を通して予測を出す(「この画像は猫だ」)
- 答え合わせをして、どれだけ間違えたかを計算する
- 「どの重みがこの間違いに貢献したか」を出力から入力方向へ逆向きに追跡する
- 貢献度に応じて各重みをほんの少し修正する(重みは上書きされる。スナップショットは残らない)
- これを何百万回も繰り返す
答えの正解を知っているのは最終出力だけです。途中の層が「正しく何を出すべきか」は誰にもわかりません。「猫の画像に対するLayer 1の正しいエッジ検出結果」なんて、正解がない。
Input → [Layer1] → [Layer2] → [Layer3] → 出力 vs 正解
↑
唯一の採点ポイント
だから、誤差信号を出力から逆向きに伝えます。数学の 連鎖律(チェーンルール) を使って、「AがBに影響し、BがCに影響するなら、AがCに与える影響は二つの効果の掛け算で求まる」という原理で、各層の責任を順番に計算していきます。
順方向パス(左→右):
入力 → Layer1 → Layer2 → Layer3 → 出力 → 「間違い!」
逆方向パス(右→左):
「間違い!」 → Layer3の責任 → Layer2の責任 → Layer1の責任
「Layer3、あなたの責任は40% → 重みを40%分調整」
「Layer2、あなたの責任は35% → 重みを35%分調整」
「Layer1、あなたの責任は25% → 重みを25%分調整」
誤差が逆方向に伝播する——だからバックプロパゲーション(誤差逆伝播法)。
多層ネットワークをこの方法で訓練できることが示され、ミンスキーたちが「不明だ」と言った問題が解決しました。
なぜ多層にすると解けるのか? 核心は線形か非線形かの違いです。パーセプトロン(単層)は直線1本しか引けない——これが線形の限界です。多層ネットワークでは、各層がそれぞれ直線を引き、それらを組み合わせることで曲線や複雑な形の判定境界を作れます。これが非線形です。
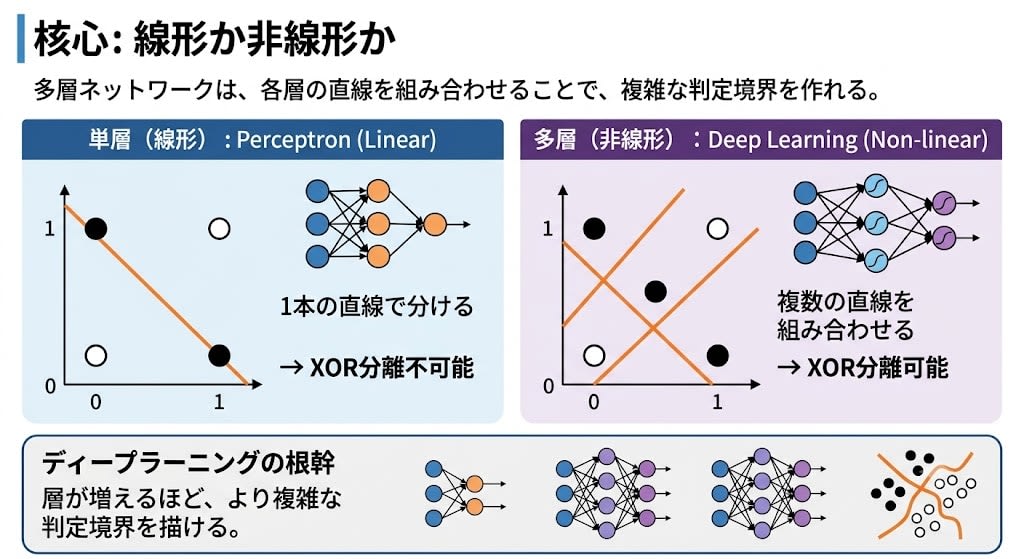
層が増えるほど、より複雑な判定境界を描ける。これがディープラーニング(深層学習)の根幹です。
しかし理論と実用の間には大きな壁がありました。多層ネットワークの訓練には膨大な計算量が必要で、1980〜90年代のハードウェアでは実用的な速度で訓練を回すことができなかったのです。
速度の壁を破る:GPUの登場 (2012)
バックプロパゲーションが確立されても、多層ネットワークはしばらく実用から遠い存在でした。データが足りない。計算が遅い。
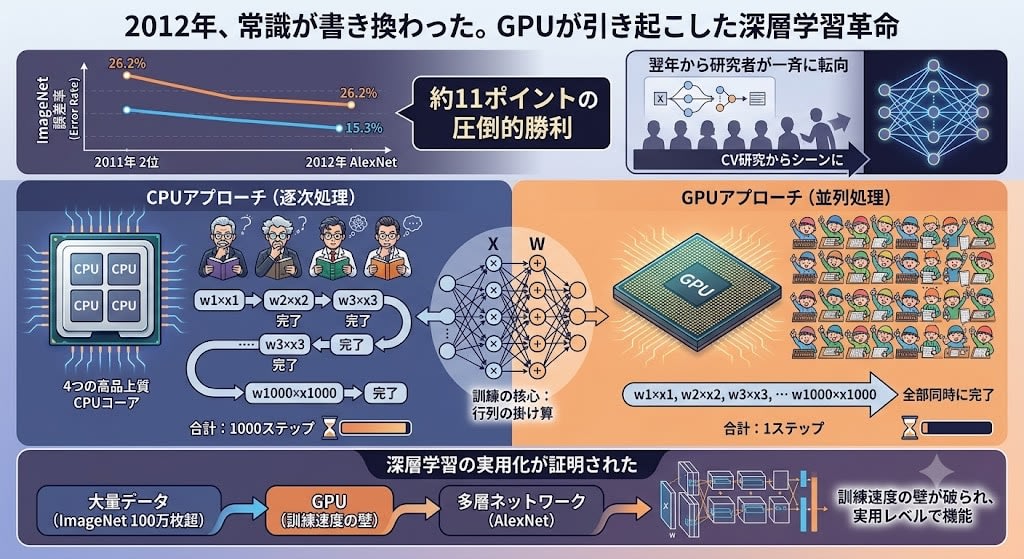
2012年、ImageNet(100万枚超の画像を1000カテゴリに分類するコンテスト)でその状況が一変しました。AlexNetというモデルが圧倒的な成績を叩き出したのです。2位の誤差率26.2%に対し、AlexNetは15.3%——差にして約11ポイント。機械学習の世界では前年比で1〜2ポイントの改善が普通で、11ポイントは「他を圧倒した」と表現してもなお控えめな数字でした。コンピュータビジョン研究者の多くが翌年から一斉に深層学習へ転向し、業界の常識が書き換わりました。
AlexNetが使ったのは**GPU(グラフィックスチップ)**です。なぜGPUがこれほど効果的だったのか? それまでの訓練はCPUで行われていましたが、CPUとGPUでは設計思想が根本的に異なります。
CPUは少数の高性能コア(4〜16個)を持ち、複雑なタスクを逐次的にこなす設計です。一方、GPUは数千の単純なコア(4000個以上)を持ち、シンプルな計算を大量に同時実行する設計です。
CPU: 4人の熟練数学者が、複雑な問題を順番に解く
GPU: 4000人の小学生が、足し算をいっせいに解く
ニューラルネットワークの訓練は、その大部分が行列の掛け算——何千もの重みと何千もの入力を掛け合わせて足すという単純な計算の繰り返しです。そして各掛け算は互いに独立しており、w3×x3の結果はw1×x1の結果を待つ必要がありません。
CPUアプローチ(逐次処理):
w1×x1 → 完了 → w2×x2 → 完了 → w3×x3 → 完了 → ... → w1000×x1000 → 完了
合計: 1000ステップ
GPUアプローチ(並列処理):
w1×x1, w2×x2, w3×x3, ... w1000×x1000 → 全部同時に完了
合計: 1ステップ
AlexNetの訓練はCPUでは数週間〜数ヶ月かかるところ、GPUでは数日で完了しました。同じ数学、同じ結果——ただ大規模に並列化しただけです。GPUによって訓練速度の壁が破られ、「GPU + 大量データ + 多層ネットワーク」の組み合わせが実用レベルで機能することが証明されました。
ただし、AlexNetは8層のネットワークでした。「もっと深く(層を増やせば)もっと賢くなる」はずですが、層を深くしようとすると別の壁が立ちはだかります。
余談: AlexNetの著者の一人、ジェフリー・ヒントンは、1986年のバックプロパゲーション論文にも名前があります。AIの冬を越えて、同じ人物が26年後に深層学習の復活を主導した。ヒントンは2018年にヤン・ルカン、ヨシュア・ベンジオとともにチューリング賞を受賞し、3人まとめて「ディープラーニングの父たち」と呼ばれています。
余談: GPUを作っていたNVIDIAは、元々ゲーム用グラフィックスの会社でした。ゲームの3D描画も「大量のピクセルに対して同じ計算を並列実行する」という処理であり、これがニューラルネットワークの行列演算と構造的に同じだったのです。AIブームによりNVIDIAは世界で最も価値のある企業の一つになりました——ゲーム用チップがAI訓練の最適ツールになるというのも、この記事で追ってきた「意図せぬ接続」のひとつです。
さらに深く:勾配消失の克服 (2010s)
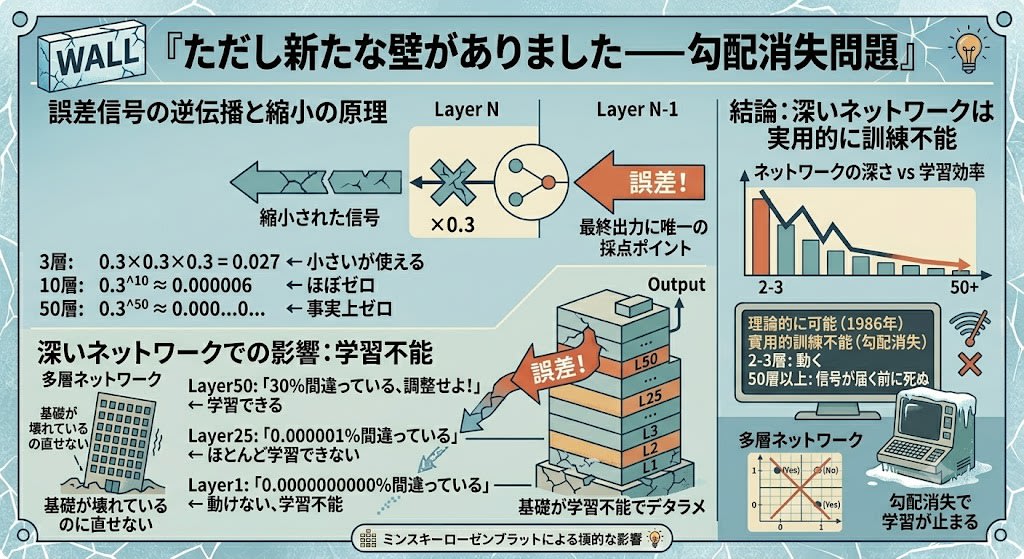
GPUが速度の問題を解決しても、ネットワークを深くすること自体に別の壁がありました——勾配消失問題です。
バックプロパゲーションで見たように、唯一の採点ポイントは最終出力にしかありません。誤差信号は逆方向に層を遡るしかない。そして各層を通過するたびに、信号は掛け算で縮小されます。各掛け算の係数は典型的に1未満(例:0.3)なので、小さな数を繰り返し掛けると急速にゼロに近づきます。
3層: 0.3 × 0.3 × 0.3 = 0.027 ← 小さいが使える
10層: 0.3^10 ≈ 0.000006 ← ほぼゼロ
50層: 0.3^50 ≈ 0.00000000000000000000000... ← 事実上ゼロ
最終層に近いほどフィードバックが強く、最初の層ほどフィードバックが消えていく:
Layer1 Layer2 Layer3 ... Layer50 出力
←×0.3← ←×0.3← ←×0.3← ... ←×0.3← 誤差!
Layer50: 「30%間違っている、調整せよ!」 ← 学習できる
Layer25: 「0.000001%間違っている」 ← ほとんど学習できない
Layer1: 「0.0000000000%間違っている」 ← 動けない、学習不能
これは建物の基礎が壊れているのに直せないようなものです。Layer 1は基本的な特徴(エッジ、単純なパターン)を学ぶべき層ですが、フィードバックが届かないので学習できない。基礎がデタラメなままでは、その上に何を積み上げても意味がありません。
この壁は、複数の技法の組み合わせで段階的に克服されました。
先ほど各層の掛け算の係数が「0.3」のように1未満だと説明しました。この係数はどこから来るのでしょうか? 答えは活性化関数——各ニューロンが出力をどう変換するかの関数です。
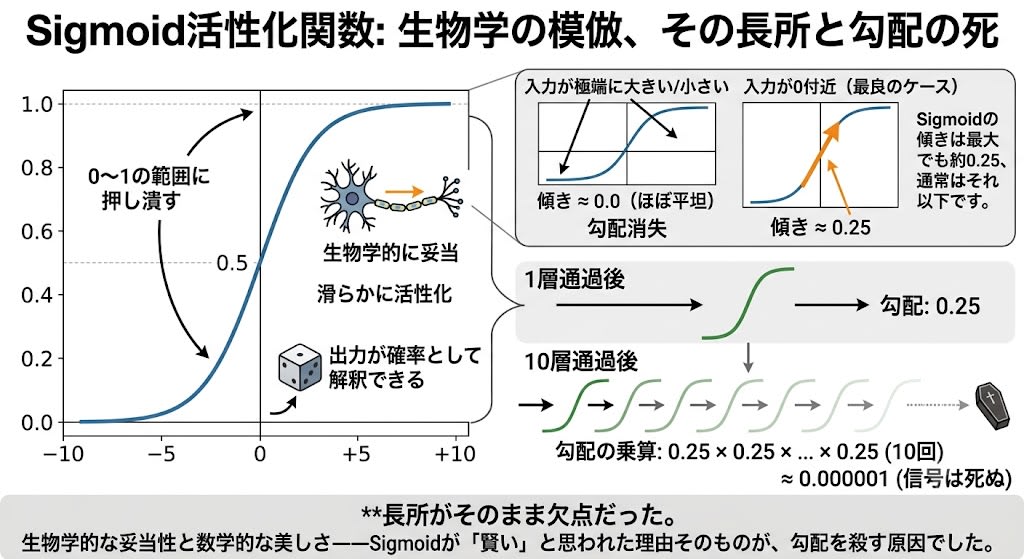
長年使われていたのがSigmoidです。Sigmoidは生物のニューロンを模倣して設計されました。実際のニューロンは単純なオン・オフではなく、刺激の強さに応じてなめらかに活性化します。Sigmoidはこれを再現する滑らかなS字カーブで、どんな入力も0〜1の範囲に変換します。
しかしバックプロパゲーションでは、各層の「責任の係数」はこの活性化関数の 傾き(勾配) で決まります。Sigmoidの傾きは最大でも約0.25、通常はそれ以下です。
Sigmoidの傾き:
入力が極端に大きい/小さい → 傾き ≈ 0.0(ほぼ平坦)
入力が0付近(最良のケース)→ 傾き ≈ 0.25
各層の最良ケース: ×0.25
10層通過後: 0.25^10 ≈ 0.000001 → 信号は死ぬ
生物学的な妥当性と数学的な美しさ——Sigmoidが「賢い」と思われた理由そのものが、勾配を殺す原因でした。長所がそのまま欠点だった。
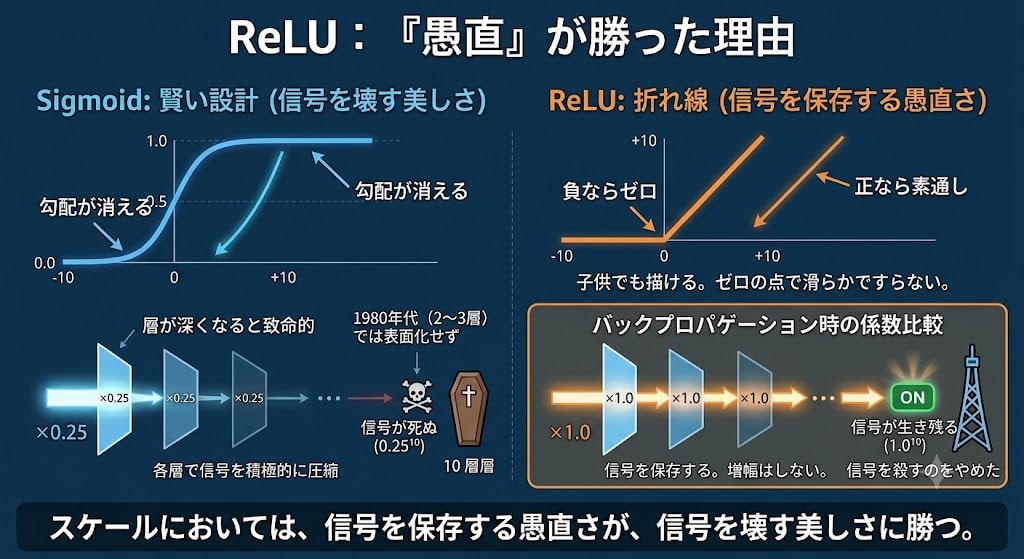
ReLU:「愚直」が勝った理由
ReLU(Rectified Linear Unit) は驚くほど単純です。「正なら素通し、負ならゼロ」——それだけ。
数学者は当初これを軽視しました。粗雑すぎる。微分不可能な点がある。ニューロンとは似ても似つかない。
しかしReLUの正の値に対する傾きはちょうど1.0です。0.25ではなく、0.1でもなく、1。
バックプロパゲーション時の係数比較:
Sigmoid: ×0.25 → ×0.25 → ×0.25 → ... → 信号が死ぬ
10層後: 0.25^10 = 0.000001
ReLU: ×1.0 → ×1.0 → ×1.0 → ... → 信号が生き残る
10層後: 1.0^10 = 1.0
ReLUは信号を「増幅」するわけではありません。殺すのをやめただけです。Sigmoidは各層で信号を積極的に圧縮していた。ReLUはそのまま通す。
1980年代にはネットワークが2〜3層しかなく、Sigmoidの問題は表面化しませんでした。層が深くなって初めて、「賢い設計」の隠れたコストが致命的になったのです。スケールにおいては、信号を保存する愚直さが、信号を壊す美しさに勝つ。
ただしSigmoidは「間違い」だったわけではありません。正しかったが、スケールに耐えられなかったのです。自転車の補助輪のようなもので、初心者には正しい設計だが、レーサーには邪魔になる。実際、今でもSigmoidは特定の用途——出力層でのYes/No分類(0〜1の確率が必要な場面)や、記憶セル内のゲート制御——で使われています。ただし深いネットワークの隠れ層では、もはやReLUが標準です。
残差接続(ResNet, 2015):もう一つの解決策
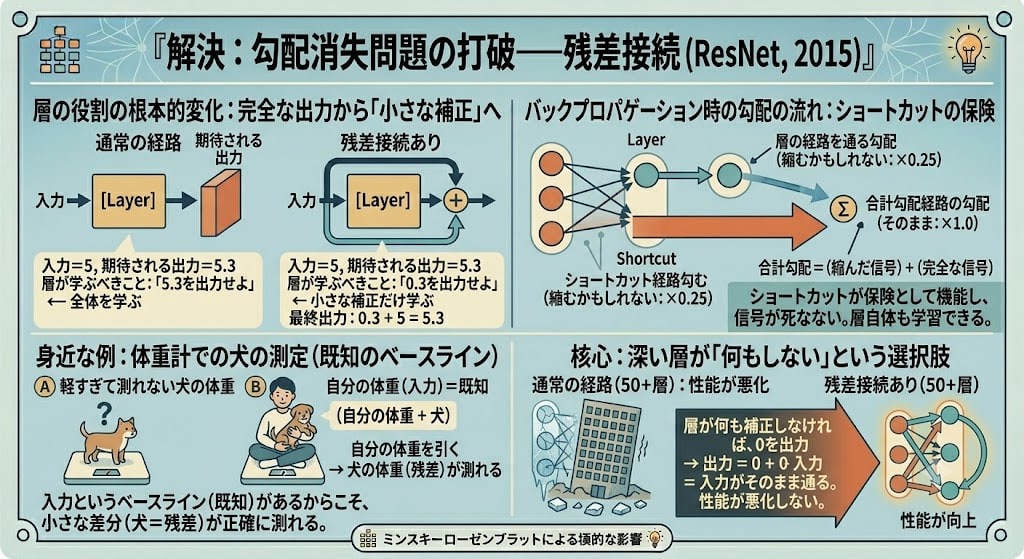
ReLUが各層の信号減衰を抑えたのに対し、**残差接続(ResNet)**は全く別のアプローチで勾配消失に挑みました。
通常のネットワークでは、各層が「入力を受け取り、完全な出力を生成する」ことを求められます。残差接続では、入力がショートカット経路を通って出力にそのまま加算されます。
通常の経路: 入力 → [Layer] → 出力
残差接続あり: 入力 → [Layer] → Layer結果 + 入力 = 出力
│ ↑
└────────────────────────────┘
ショートカット(入力がそのまま加算される)
これが何を変えるのか? 層の仕事が根本的に変わります。
残差接続なし:
入力 = 5, 期待される出力 = 5.3
層が学ぶべきこと: 「5.3を出力せよ」 ← 全体を学ぶ
残差接続あり:
入力 = 5, 期待される出力 = 5.3
出力 = 層の結果 + 入力
層が学ぶべきこと: 「0.3を出力せよ」 ← 小さな補正だけ学ぶ
最終出力: 0.3 + 5 = 5.3
層の役割が「完全な出力を生成する」から「入力に対する小さな補正(残差)を学ぶ」に変わります。だから 残差(Residual)接続 と呼ばれるのです。
身近な例で考えると、体重計に乗っても軽すぎて測れない犬の体重を量りたいとき——犬を抱っこして一緒に体重計に乗り、自分の体重を引けば犬の体重がわかります。自分の体重(入力)という既知のベースラインがあるからこそ、小さな差分(犬=残差)が正確に測れる。残差接続も同じで、入力というベースラインを保持することで、層が学ぶべき小さな補正が検出可能になります。
そして勾配にとっても決定的な違いがあります。バックプロパゲーションでは、勾配は両方の経路を通って流れます:
逆方向パス:
層の経路を通る勾配(縮むかもしれない: ×0.25)
╱
合計勾配 =
╲
ショートカット経路の勾配(そのまま: ×1.0)
合計 = (縮んだ信号)+(完全な信号)
層の経路で勾配が0.001に縮んでも、ショートカット経路が1.0を加算します。合計は約1.001。ショートカットが保険として機能し、信号が死なない。 そして層の経路にも勾配は流れるので、層自体も学習できます——フィードバックが消えないからです。
もし層が何も有用な補正を見つけられなければ? 0を出力すればよい。出力 = 0 + 入力 = 入力がそのまま通る。層が「何もしない」という選択肢を持てるため、深い層を追加しても性能が悪化しない。
ResNetはこの仕組みで152層のネットワークを訓練して成功を収め、ImageNet 2015で優勝しました。
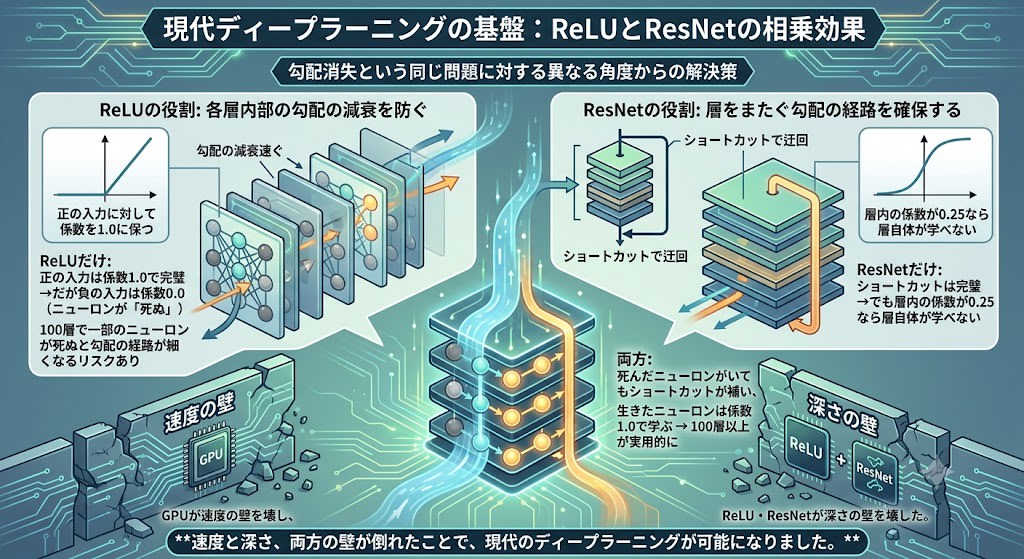
ReLUとResNet:異なるアプローチ、同じ目標
ReLUとResNetは勾配消失という同じ問題に対する異なる角度からの解決策です。ReLUは各層内部の勾配減衰を防ぎ(係数を1.0に保つ)、ResNetは層をまたぐ勾配の迂回路を確保する。現代のディープラーニングでは両方を組み合わせることで、100層以上のネットワークが実用的になりました。
GPUが速度の壁を壊し、ReLU・ResNetが深さの壁を壊した。速度と深さ、両方の壁が倒れたことで、現代のディープラーニングが可能になりました。
4. 言葉を数字にするとは? — 意味の幾何学
コンピュータは数字しか扱えない
ここまでの話は「いかに正確に学習させるか」でした。そしてここまでの成功例はすべて、最初から数字だったデータを扱っていました。画像はピクセルの数値(各ピクセルが0〜255の色情報)。音声は波形の数値。株価、気温、センサーデータ——すべて最初から数字です。ニューラルネットワークにそのまま入力できます。
しかし言葉は数字ではありません。 「猫」「経済」「美しい」——これらは記号であり、そのままではニューラルネットワークの行列計算に入力できません。LLMを作るためには、「言葉をどう数字に変換するか?」という根本的な問題をまず解く必要がありました。
最もシンプルな方法:「猫=1、犬=2、空=3…」と番号を割り振る。しかしこれでは「猫」と「犬」の間に意味的な関係がありません。「猫と犬は似ている」「猫と宇宙船は遠い」という情報が数字に入っていない。
Word2Vec:意味を空間の座標に (2013)
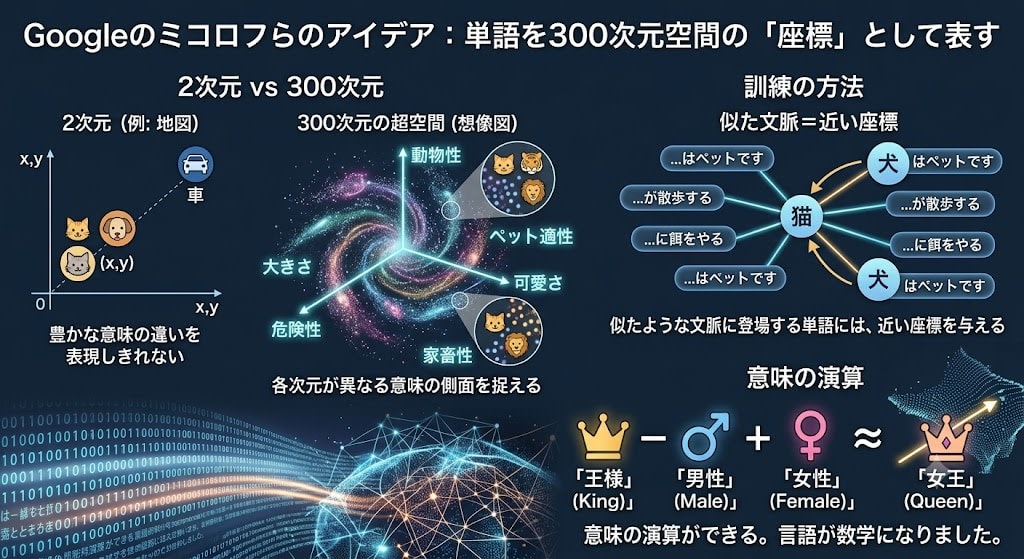
Googleのミコロフらが示したアイデア:単語を高次元空間の「座標(ベクトル)」として表す。
「高次元」とはどういうことか。私たちが日常で使う地図は2次元(東西・南北)、建物の中なら3次元(+上下)です。Word2Vecでは1つの単語を300次元の座標で表します。人間には300次元の空間を想像することはできませんが、数学的には2次元や3次元と同じように距離や方向を計算できます。
なぜ300次元も必要なのか? 言語の意味は多面的だからです。「猫」という単語は「動物か?」「ペットか?」「大きさは?」「危険か?」「可愛いか?」など無数の軸で特徴づけられます。2〜3次元ではこの豊かな意味の違いを表現しきれません。300次元あれば、各次元がそれぞれ異なる意味の側面を捉えることができます。
訓練の方法はシンプルです。「似たような文脈に登場する単語には、近い座標を与える」ように学習させる。「猫」と「犬」はどちらも「ペット」「餌」「散歩」といった文脈で使われるので、座標が近くなる。
結果として生まれた「意味の地図」には驚くべき性質がありました:
「王様」の座標 − 「男性」の座標 + 「女性」の座標 ≈ 「女王」の座標
意味の演算ができる。言語が数学になりました。
余談: 「意味は関係性の中にある」という発想には先行者がいます。1998年、スタンフォードの大学院生ラリー・ペイジとセルゲイ・ブリンは論文 "The Anatomy of a Large-Scale Hypertextual Web Search Engine" でPageRankを提案しました。当時の検索エンジンはページ内のキーワード出現頻度で順位を決めていましたが、PageRankは他のページからどれだけリンクされているか——つまりWebの構造的な関係性——で重要度を測りました。「コンテンツそのものより、周囲との関係が本質を表す」という考え方は、Word2Vecの「単語の意味は周囲の文脈(共起する単語)で決まる」と驚くほど似ています。そしてこのPageRankから生まれたGoogleが、後にGoogle Brainを設立し、2017年の "Attention Is All You Need"(Transformer)論文を生み出すことになります。検索エンジンの会社がLLMの中核アーキテクチャを発明した——これもまた「意図せぬ接続」のひとつです。
「近い」をどう測るか? — コサイン類似度
「猫と犬は近い」「猫と宇宙船は遠い」と言いましたが、300次元空間で「近い」とはどういう意味でしょうか?
直感的には、2点間の距離(ユークリッド距離)を使いたくなります。しかし高次元空間では、距離よりも方向のほうが意味の類似性をうまく捉えます。
理由を具体例で見ましょう。「猫」に関する長い文書と短い文書があるとします。
短い文書: 「猫」が5回出現 → ベクトルの大きさ: 小
長い文書: 「猫」が50回出現 → ベクトルの大きさ: 大(5回の文書の10倍方向に伸びる)
両者のユークリッド距離: 大きい(遠い)
両者の向いている方向: 同じ
どちらも「猫について書かれた文書」なのに、距離で測ると「遠い」と判定されてしまいます。方向で測れば「同じ」——これが正しい。
コサイン類似度は、2つのベクトルがどれだけ同じ方向を向いているかを測ります。
コサイン類似度:
完全に同じ方向 → 1.0(同じ意味)
直角(無関係)→ 0.0
正反対 → -1.0(反対の意味)
例(イメージ):
「犬」 ↗ ← 「猫」とほぼ同じ方向 → コサイン類似度 ≈ 0.9
「猫」 →
「宇宙船」 ↓ ← 全然違う方向 → コサイン類似度 ≈ 0.1
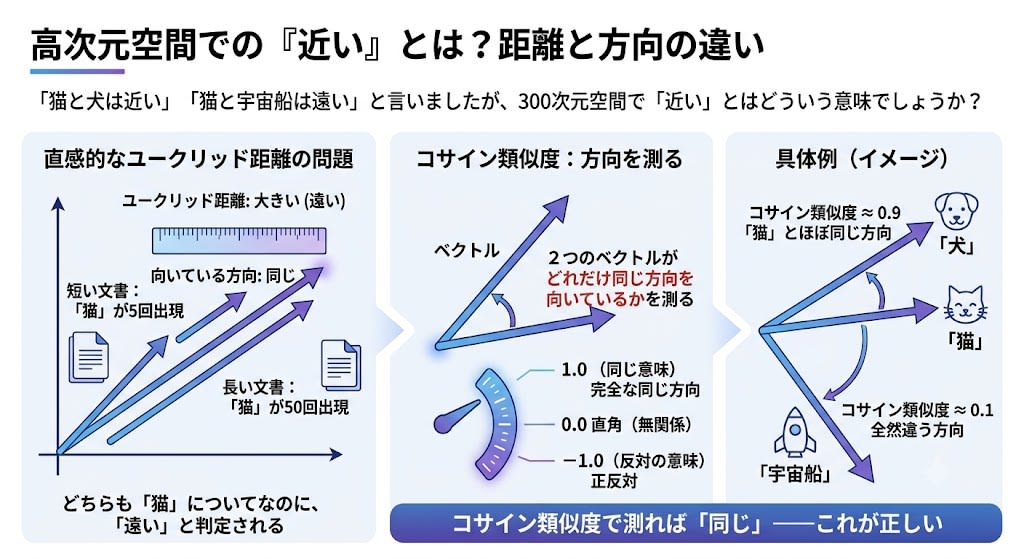
これが現在のRAG(検索拡張生成)やセマンティック検索の基盤です。ユーザーの質問をベクトル化し、データベース内のドキュメントのベクトルとコサイン類似度を計算し、最も方向が近いドキュメントを取得する。Word2Vecから始まった「意味を方向で測る」というアイデアが、今のAIアプリケーションの検索エンジンになっています。
この技術は** Embedding(埋め込み)** と呼ばれます。
EmbeddingがなぜLLMに不可欠なのか
Embeddingの重要性はRAGや検索だけではありません。LLMが言語を処理するための入口そのものです。
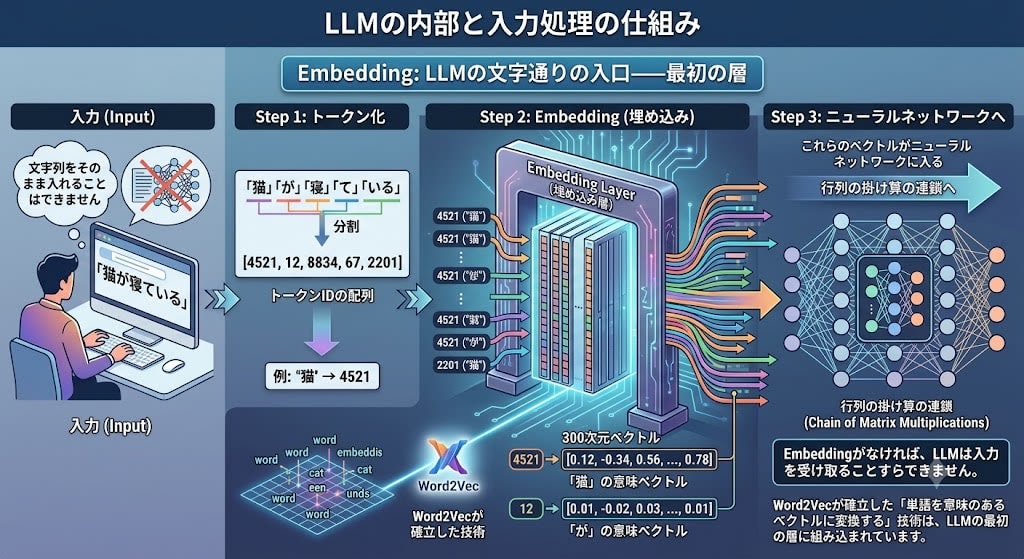
LLMの内部はニューラルネットワーク——つまり行列の掛け算の連鎖です。行列の掛け算には数値のベクトルが必要です。「猫」という文字列をそのままニューラルネットワークに入れることはできません。
「猫が寝ている」という文をLLMに入力するとき:
Step 1: トークン化
「猫」「が」「寝」「て」「いる」 → [4521, 12, 8834, 67, 2201]
Step 2: Embedding(各トークンIDを300次元のベクトルに変換)
4521 → [0.12, -0.34, 0.56, ..., 0.78] ← 「猫」の意味ベクトル
12 → [0.01, -0.02, 0.03, ..., 0.01] ← 「が」の意味ベクトル
...
Step 3: これらのベクトルがニューラルネットワークに入る
Embeddingがなければ、LLMは入力を受け取ることすらできません。Word2Vecが確立した「単語を意味のあるベクトルに変換する」技術は、LLMの文字通りの入口——最初の層——に組み込まれています。
ここまでで「単語を数値にする方法」は解決しました。しかし次の問題が待っています。単語をベクトルに変換しただけでは、 単語の並び順(文脈) が失われます。「犬が猫を追いかけた」と「猫が犬を追いかけた」——単語のベクトルは同じでも、意味は正反対です。
文脈をどう扱うか? この問いが次の章のテーマです。そしてこの問いに最初に本気で取り組んだのが、機械翻訳の研究者たちでした。
5. 文脈をどう扱うか? — Attentionの誕生
注記: この章で登場するLSTM(1997年)やRNN自体の研究は、時系列としてはAlexNet(2012年)やWord2Vec(2013年)より前に始まっています。しかし「なぜ順序のあるデータが難しいのか」を理解するには、第3章(ニューラルネットワークの訓練と深さの壁)と第4章(単語をベクトルに変換する方法)の知識が前提になるため、この順番で扱っています。
なぜ機械翻訳が主戦場だったのか
2010年代前半、NLP(自然言語処理)の研究者たちがもっとも力を注いでいた応用分野は機械翻訳でした。
理由は単純です。翻訳は「言語を本当に理解しているか」を最も厳しくテストするタスクだからです。単語を一つずつ置き換えるだけでは翻訳できません。語順が変わり、文法が変わり、文化的なニュアンスが変わる。文全体の意味を理解し、別の言語で再構成する必要がある。
英語: The cat sat on the mat.
日本語: 猫がマットの上に座った。
単語の置き換えだけ: The=その cat=猫 sat=座った on=の上に the=その mat=マット
→ 「その猫座ったの上にそのマット」 ← 意味不明
正しい翻訳には語順の再構成、助詞の追加、冠詞の削除が必要
→ 文全体の意味の理解が前提
だから「機械がどこまで言語を扱えるか」の限界は、翻訳で最も早く露呈しました。そしてそのボトルネックを解消するために生まれた技術が、後にLLM全体の基盤になります。
翻訳モデルのボトルネック:RNNの構造的限界 (2014年頃)
当時の翻訳モデルは RNN(Recurrent Neural Network・再帰型ニューラルネットワーク) を使っていました。RNNは文脈を扱うための、当時の最善手です。
RNNは新しい発明ではなく、これまで見てきた部品の組み合わせです。内部のニューロン・重み・層・バックプロパゲーションは第3章と同じ。入力として受け取るのは第4章のEmbeddingベクトル。RNNの唯一の新しいアイデアを理解するには、まず通常のニューラルネットワークの限界を知る必要があります。
ここまでニューラルネットワークが成功してきたのは、画像のような一度に全体を入力できるデータでした。AlexNetが猫の写真を分類するとき、100万個のピクセルは同時に入力層に入ります。「まず左上のピクセルを見て、次に右隣のピクセルを見て…」と順番に処理するわけではありません。全体が一発で入力されるから、「前を覚えておく」必要がそもそもない。
しかし言語は本質的に順番に並んだデータです。「猫がマットの上に座った」の意味は、単語の順序に依存します。「マットが猫の上に座った」は同じ単語でも全く違う意味です。そして文の後半を理解するには、前半で何が言われたかを覚えている必要がある。
画像: [100万ピクセル全部] → 同時に入力 → 「猫の写真」
順序なし。記憶不要。
言語: 「猫」→「が」→「マット」→「の上に」→「座った」
順序あり。「座った」を理解するには「猫が」を覚えている必要あり。
この問題を身近な例えで言うと、講義を聞きながらノートを取る状況に似ています。
- 通常のネットワーク = 講義を聞くが、ノートを取らない。1文聞くたびに忘れる。今聞いた文にしか反応できない。
- RNN(これから説明します)= 1ページだけのメモ帳にノートを取りながら講義を聞く。メモ帳がいっぱいになると、古いメモを上書きして新しい内容を書く。講義が終わったとき、手元にはその1ページだけが残る。
この例えを頭に入れて、技術的な仕組みを見ていきましょう。
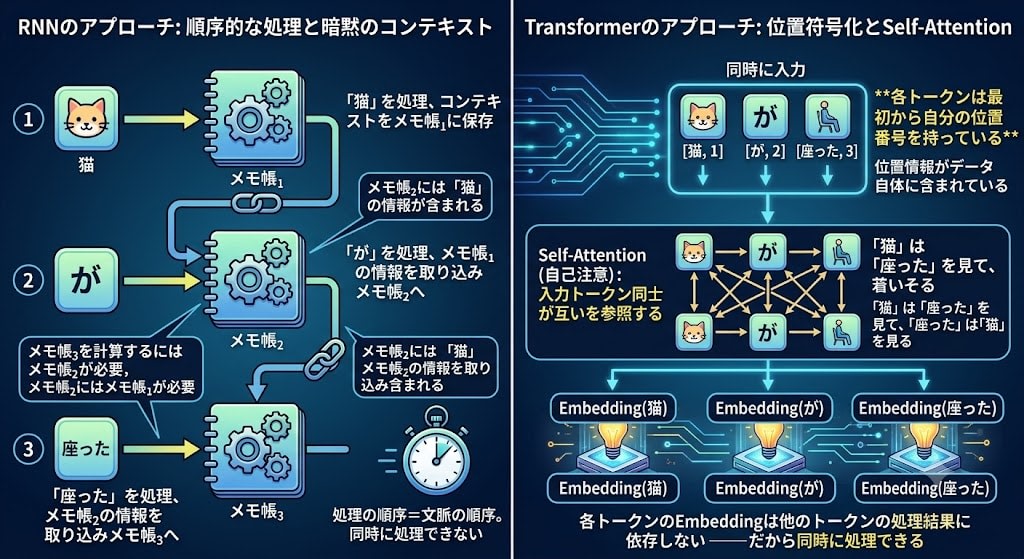
では、通常のニューラルネットワークで文を処理しようとするとどうなるでしょうか。
通常のネットワークで文を処理しようとすると(ノートを取らない):
「猫」→ [入力層]→[隠れ層]→[出力層] → 結果₁ ← 処理完了、ネットワークはリセット
「が」→ [入力層]→[隠れ層]→[出力層] → 結果₂ ← 「猫」の痕跡はゼロ
「マット」→ [入力層]→[隠れ層]→[出力層] → 結果₃ ← 「猫が」の痕跡もゼロ
「各層は前の層の出力を受け取るのだから、情報は引き継がれるのでは?」と思うかもしれません。しかしそれは1つの入力が複数の層を通る流れ(空間的な流れ)の話です。「猫」が入力層→隠れ層→出力層と流れるのは、1つの単語が深い層へ進む過程。
問題は時間的な流れです。「猫」の処理が終わって「が」の処理が始まるとき、ネットワークは完全にリセットされます。隠れ層に「猫」の痕跡は一切残っていません。だから「座った」を処理するとき、「何が座ったのか(猫が)」を知る手段がない。
空間的な流れ(1つの入力が複数の層を通る)← これは通常ネットワークでもある
「猫」→ [Layer 1] → [Layer 2] → [Layer 3] → 出力
時間的な流れ(複数の入力が順番に処理される)← これが通常ネットワークにない
時点1: 「猫」→ 処理 → 完了 → リセット
時点2: 「が」→ 処理 → 完了 → リセット ← 「猫」を覚えていない
時点3: 「マット」→ 処理 → 完了 → リセット ← 「猫が」を覚えていない
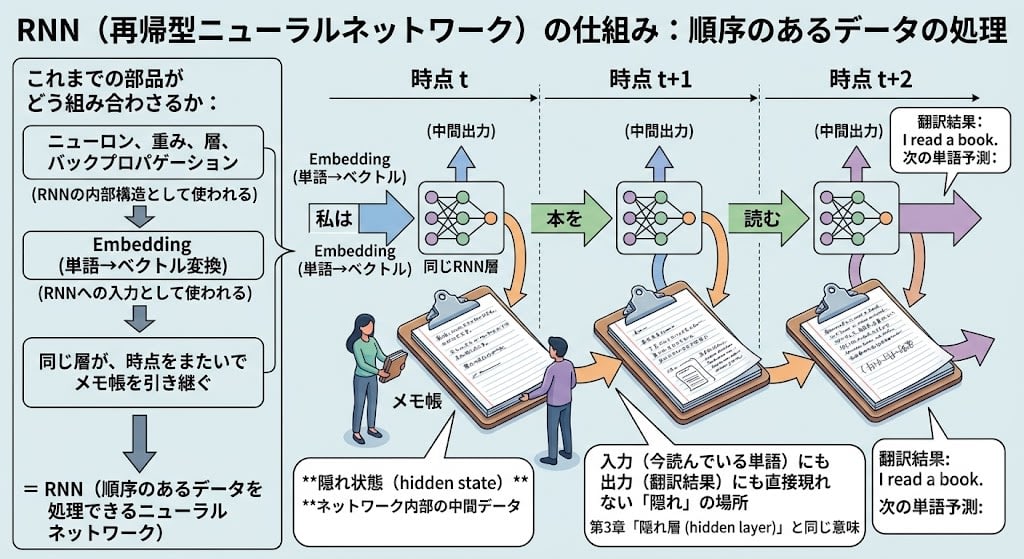
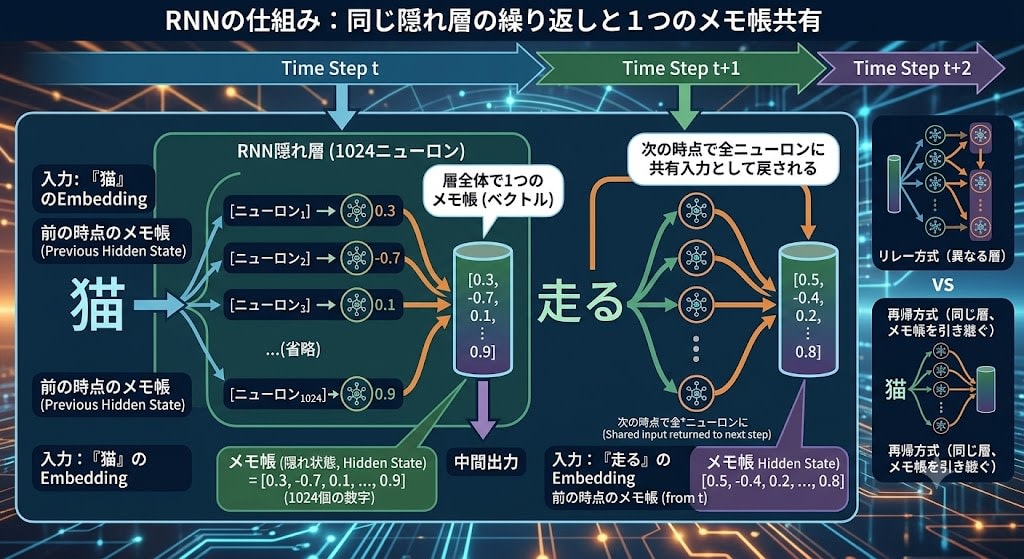
RNNの解決策:同じ層が記憶を持ち越す
RNNのアイデアは、同じ層が異なる時点のトークンを順番に処理し、その際に内部の状態(メモ帳)を次の時点に引き継ぐことです。
これまでの部品がどう組み合わさるか:
第3章の部品: ニューロン、重み、層、バックプロパゲーション
↓(RNNの内部構造として使われる)
第4章の部品: Embedding(単語→ベクトル変換)
↓(RNNへの入力として使われる)
第5章の新要素: 同じ層が、時点をまたいでメモ帳を引き継ぐ
↓
= RNN(順序のあるデータを処理できるニューラルネットワーク)
この「メモ帳」を、専門用語では 隠れ状態(hidden state) と呼びます。第3章で「隠れ層(hidden layer)」を覚えているでしょうか——入力層と出力層の間にある、ユーザーからは見えない内部の作業スペースでした。RNNの「隠れ状態」も同じ「隠れ」です。入力(今読んでいる単語)にも出力(翻訳結果)にも直接現れない、ネットワーク内部の中間データだから「隠れ」と呼ばれます。
通常のネットワークと比較してみましょう:
通常のネットワーク:
時点1: 「猫」 → [隠れ層] → 出力₁ 隠れ層の状態はリセット
時点2: 「が」 → [隠れ層] → 出力₂ 「猫」の痕跡なし
RNN:
時点1: 「猫」 → [隠れ層] → 出力₁
↓
メモ帳₁ =「猫の情報」を保存 → 次の時点に引き継ぐ
↓
時点2: 「が」+メモ帳₁ → [同じ隠れ層] → 出力₂
↓
メモ帳₂ =「猫が…」に更新 → 次の時点に引き継ぐ
↓
時点3: 「マット」+メモ帳₂ → [同じ隠れ層] → 出力₃
↓
メモ帳₃ =「猫がマット…」に更新
...
ポイントは、RNNでは同じ隠れ層が繰り返し(Recurrent=再帰的に)使われることです。異なる層のリレーではなく、1つの層が時点ごとに繰り返し動き、メモ帳を引き継ぐことで「前に何を読んだか」を覚えていられます。
そしてメモ帳はニューロンごとに個別に持つものではなく、層全体で1つです。隠れ層に1024個のニューロンがあるなら、各ニューロンが1つの数字を出力し、それら1024個の数字をまとめたベクトルが「メモ帳」になります。次の時点では、この1024個の数字が層全体に共有入力として戻されます。
隠れ層(1024ニューロン)の1つの時点:
入力: 「猫」のEmbedding + 前の時点のメモ帳
↓
[ニューロン₁] → 0.3 ─┐
[ニューロン₂] → -0.7 ─┤
[ニューロン₃] → 0.1 ─┼→ メモ帳 = [0.3, -0.7, 0.1, ..., 0.9](1024個の数字)
... │
[ニューロン₁₀₂₄] → 0.9 ┘
↓
このメモ帳が次の時点で全ニューロンに共有される
Reactを知っている読者なら、RNNの隠れ状態は
useRefに近いと考えるとわかりやすいかもしれません。ref.currentはレンダリングをまたいで値を保持し、更新してもre-renderをトリガーしない——つまりReactのシステムからは「見えない(hidden)」内部状態です。RNNのメモ帳も同じで、各時点(トークン処理)をまたいでref.currentが上書き更新されていき、常に最新の状態だけを保持します。古い値は上書きされて消える。const memo = useRef(new Float32Array(1024)); function processToken(embedding) { memo.current = computeNewState(embedding, memo.current); // 古いmemo.currentは上書きされて消える } processToken(embed("猫")); // memo.current = [猫の情報] processToken(embed("が")); // memo.current = [猫が…の情報] processToken(embed("座った")); // memo.current = [猫が…座った の情報]
各ステップでRNNが使えるのは2つだけ——「今読んでいるEmbeddingベクトル」と「前のステップから渡されたメモ帳」。前の単語に戻って読み返すことはできません。読み終わった情報は、メモ帳の中にしか存在しない。講義の例えで言えば、1ページのメモ帳に書き続けていて、講義を巻き戻すことはできない状態です。
直感的には、各ニューロンが自分専用のメモ帳を持つ方が自然に思えます。しかしRNNのメモ帳が層全体で共有される理由は、各ニューロンの出力が他のニューロンの文脈になるからです。
「猫が座った」を処理するとき、あるニューロンが「主語は猫だ」という情報を検出し、別のニューロンが「動詞は過去形だ」を検出したとします。次のトークンを処理する際、「過去形の動詞の主語は猫」という複合的な理解が必要です。これは1つのニューロンだけでは持てない——複数のニューロンの出力を組み合わせて初めて成立する情報です。
メモ帳を全ニューロンの出力をまとめたベクトル(1024個の数字)として共有し、次の時点で全ニューロンに入力することで、各ニューロンは他のニューロンが前の時点で何を検出したかを参照できます。ニューロンごとに独立したメモ帳では、この「横の情報共有」ができません。
ニューロンはメモ帳をどう使うのか
各ニューロンは各時点で、「今のトークンのEmbedding」と「前の時点のメモ帳」を連結した1つのベクトルを入力として受け取り、第3章と同じ掛け算と足し算を行います。ニューロン自体は「どこまでがトークンでどこからがメモ帳か」を知りません。しかし訓練を通じて、トークン用の重みとメモ帳用の重みが異なる役割を学習します。例えば「現在のトークンが動詞なら、メモ帳の中で主語に相当する情報を重視する」というようなパターンが、重みの値として自然に現れます。
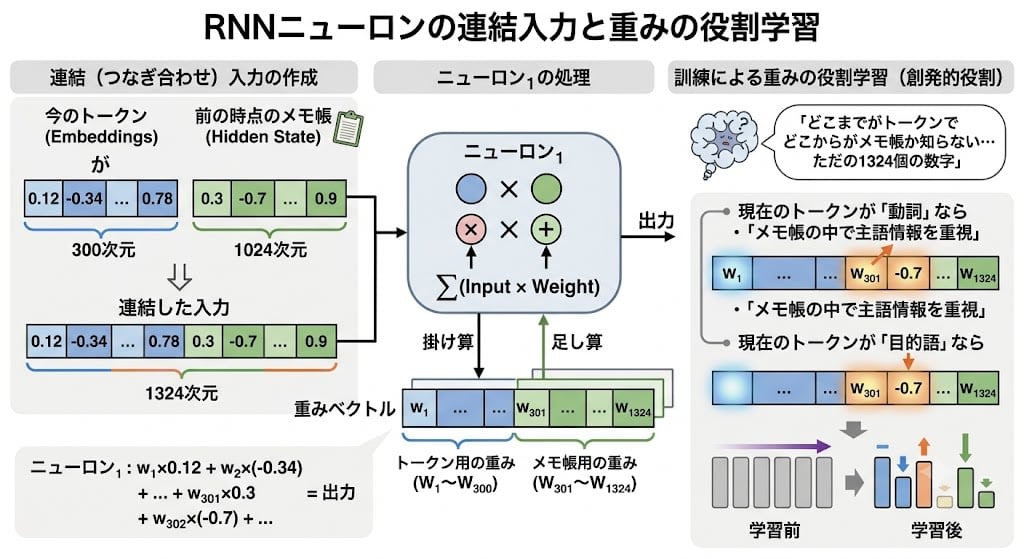
各ニューロンがどんなパターンを学ぶかは事前に決まっていません。訓練の過程で、各ニューロンが「次のトークンの予測に役立つ何らかのパターン」を自分で見つけます。そのパターンは人間には解釈できない抽象的なものかもしれません。これがニューラルネットワークが「ブラックボックス」と呼ばれる理由の一つです。
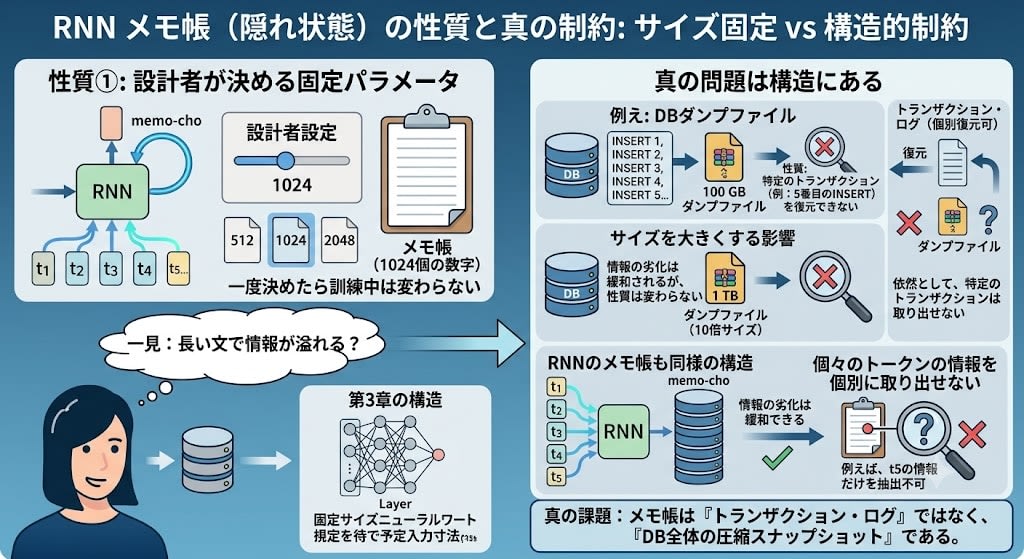
RNNの本当のボトルネック:スナップショットには問い合わせできない
メモ帳のサイズ(1024個の数字)は設計者が訓練前に決めるパラメータです。512でも2048でもかまいませんが、一度決めたら変わらない——これはニューロンの層が固定数の入力を期待するためです(第3章の構造を思い出してください)。
「サイズが固定だから長い文で情報が溢れる」——一見これが問題に見えます。しかし本当の問題はサイズではなく、データ構造です。
メモ帳は**データベースのスナップショット(ダンプ)**に似ています。ダンプファイルには過去のすべてのトランザクションの累積結果が反映されていますが、特定のINSERT文を復元することはできません。サイズを10倍にしても1000倍にしても、この性質は変わらない。
RNNのメモ帳も同じです。すべての過去のトークンが現在の状態に貢献していますが、個々のトークンの情報を個別に取り出せないという構造的制約は、メモ帳をどれだけ大きくしても変わりません。
翻訳モデルでは、入力文を全部読み終わってから出力文を生成し始めます。
入力文 → [RNN: 1単語ずつ読んでメモ帳を更新] → 最終メモ帳(スナップショット)→ [出力RNN] → 翻訳文
出力RNNが翻訳文を生成するとき、手元にあるのは最終スナップショットだけです。例えば「彼女は市場に行った。そこで彼女は友人の彼女に会った」を翻訳するとき——出力RNNが3番目の「彼女」を訳すには、それが「友人の恋人」であることを確認するために入力文の対応する箇所を参照したい。しかし個々のトークンはスナップショットに溶け込んでいる。ピンポイントで取り出す手段がありません。
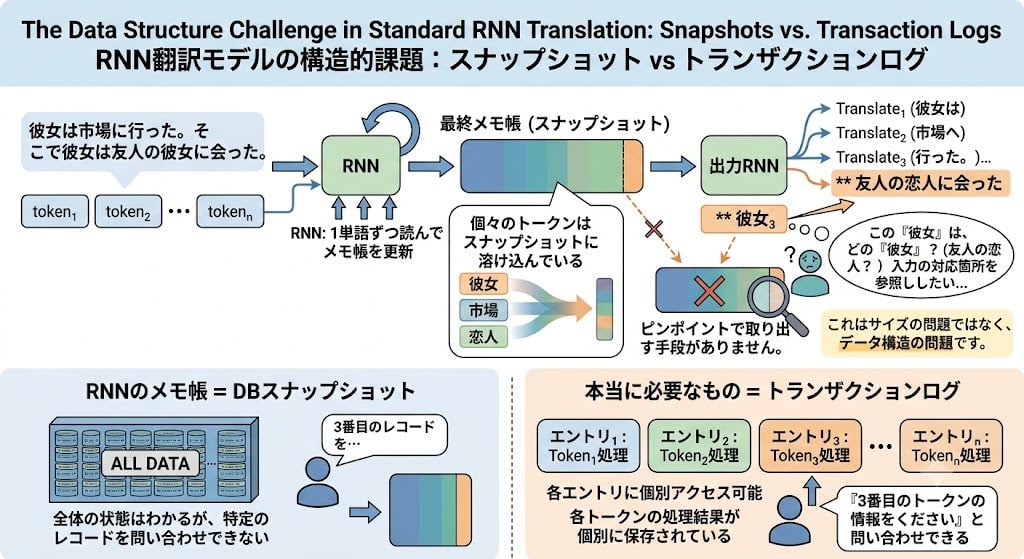
本当に必要なのは、スナップショットではなくトランザクションログ——各トークンの処理結果が個別に保存され、問い合わせできるデータ構造です。この転換が、後で登場するAttentionの核心になります。
第3章のデジャヴ:勾配消失、再び
RNNの問題は情報の溢れだけではありません。学習そのものにも壁がありました。
第3章で、バックプロパゲーション(誤差逆伝播)の仕組みを見ました。出力を正解と比較し、誤差信号を逆方向に伝えて各層の重みを調整する——「どの重みがどれだけ間違いに貢献したか」を追跡する「blame(責任追及)」の仕組みです。
RNNでも同じ仕組みが使われます。しかし第3章では誤差信号が層をまたいで逆方向に流れたのに対し、RNNでは時点をまたいで逆方向に流れます。
第3章の勾配消失(空間方向):
Layer₁ ← Layer₂ ← Layer₃ ← ... ← Layer₅₀ ← 誤差!
信号が層を通るたびに ×0.25 → 最初の層に届かない
RNNの勾配消失(時間方向):
メモ帳₁ ← メモ帳₂ ← メモ帳₃ ← ... ← メモ帳₅₀ ← 誤差!
信号が時点を遡るたびに ×0.25 → 最初のトークンに届かない
例えば50番目のトークンで予測を間違えたとき、「1番目のトークンの処理の仕方が悪かったのが原因」かもしれません。しかし誤差信号はメモ帳の連鎖を49回遡る必要があり、各ステップで信号が縮小される。結果、初期のトークンに対するフィードバックがゼロに近くなり、重みが調整されない——つまりネットワークは「文の冒頭をうまく処理する方法」を学習できません。
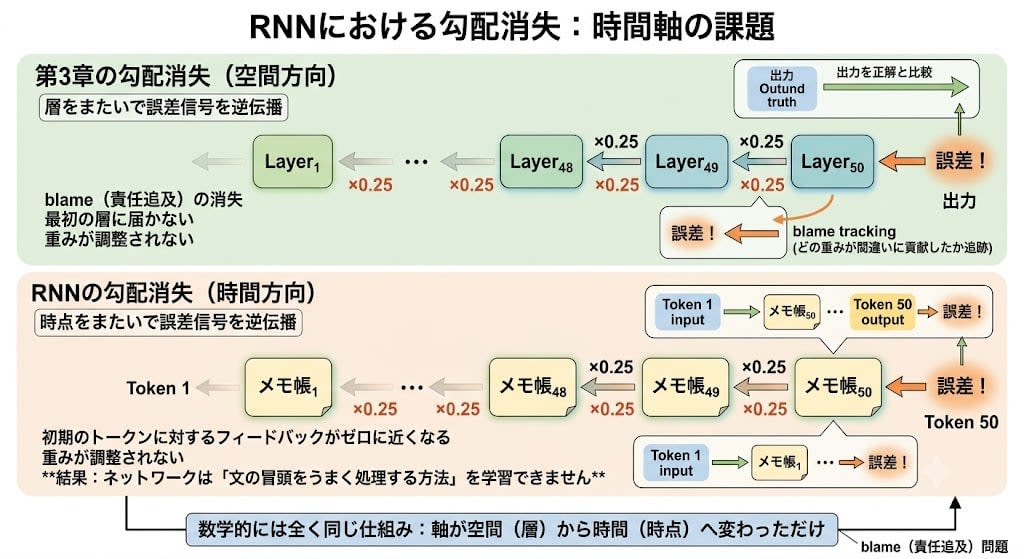
数学は全く同じです。第3章では深い層を通るたびに信号が消えた。RNNでは長い時間を遡るたびに信号が消える。軸が空間から時間に変わっただけで、同じ問題が再び現れたのです。
LSTM:時間方向のResNet (1997年発明、2014年〜翻訳の主力に)
第3章では、層方向の勾配消失を ResNet(残差接続) が解決しました。入力をショートカットで出力に加算し、勾配が直接流れる「高速道路」を作る仕組みです。
では時間方向の勾配消失には? 実は、ResNet(2015年)より18年も前の1997年に、同じ発想の解決策が提案されていました。ホッホライターとシュミットフーバーによる**LSTM(Long Short-Term Memory・長短期記憶)**です。長年ニッチな存在でしたが、2014年頃に深層学習ブームとGPUの普及が重なり、機械翻訳の主力アーキテクチャとして花開きました。
LSTMの核心は、通常のメモ帳に加えてセル状態(cell state)というもう1つの記憶を持つことです。このセル状態は、時点間でほぼそのまま素通りする高速道路です。
通常のRNN:
メモ帳₁ →[複雑な変換]→ メモ帳₂ →[複雑な変換]→ メモ帳₃
勾配 ×0.25 勾配 ×0.25
→ 信号が縮む → さらに縮む
LSTM:
セル状態₁ ──────────────→ セル状態₂ ──────────────→ セル状態₃
ほぼ素通し(+加算のみ) ほぼ素通し
勾配 ≈ 1.0 勾配 ≈ 1.0
→ 信号が生き残る → まだ生き残る
ResNetとの対応を見てみましょう:
ResNet: 入力 ──→ [Layer] ──→ 出力
│ ↑
└── skip connection ─┘ ← 勾配の高速道路(層をまたぐ)
LSTM: セル状態ₜ ──→ [ゲート] ──→ セル状態ₜ₊₁
│ ↑
└── cell state highway ────┘ ← 勾配の高速道路(時点をまたぐ)
同じアイデア: 「勾配が減衰せずに通れる近道を用意する」
異なる軸: ResNet = 空間方向(層)、LSTM = 時間方向(トークン)
LSTMにはさらにゲートという仕組みがあります。「忘却ゲート」「入力ゲート」「出力ゲート」の3つが、セル状態に対して「何を忘れるか」「何を書き込むか」「何を読み出すか」を制御します。これにより、重要な情報を長期間保持しつつ、不要な情報を捨てることができます。
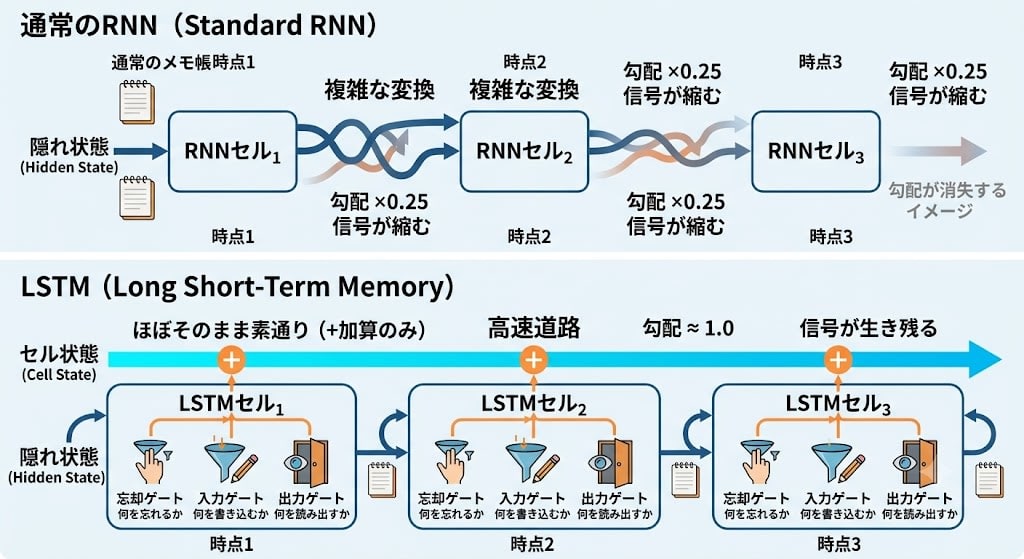
LSTMはRNNの記憶問題を大幅に改善し、2014年〜2017年頃の機械翻訳で主力として使われました。しかし根本的な制約は残っていました——逐次処理です。トークン1を処理してからトークン2、トークン2を処理してからトークン3。どんなにメモリが改善されても、GPUの並列計算を活かせない。
バグへのパッチ:Attention(注意機構)
バダナウらの解決策は、先ほどの「スナップショットからトランザクションログへ」の転換そのものでした。
ステップ1:スナップショットをトランザクションログにする
RNNは入力を処理するとき、各ステップでメモ帳(スナップショット)を更新します。従来はこの最終スナップショットだけを出力RNNに渡していました。バダナウらのアイデアは、各ステップのスナップショットを全部、独立したコピーとして保存しておくことでした。
重要なのは、保存されるのは差分(デルタ)ではなく、各時点の完全なスナップショットです。5トークンを処理したら、1024個の数字が5セット——合計5120個の数字が保存されます。
従来のRNN(スナップショット1つ):
メモ帳₁ → メモ帳₂ → メモ帳₃ → メモ帳₄ → メモ帳₅(最終)→ [出力RNN]
(途中のメモ帳は上書きされて消える) ↑
これだけ使う
Attention付きRNN(トランザクションログ):
メモ帳₁ → メモ帳₂ → メモ帳₃ → メモ帳₄ → メモ帳₅
↓ ↓ ↓ ↓ ↓
[コピー₁] [コピー₂] [コピー₃] [コピー₄] [コピー₅] ← 各時点の完全なスナップショット
↓ ↓ ↓ ↓ ↓
[全部保持 → 出力の各ステップからアクセス可能]
↓
[出力RNN]
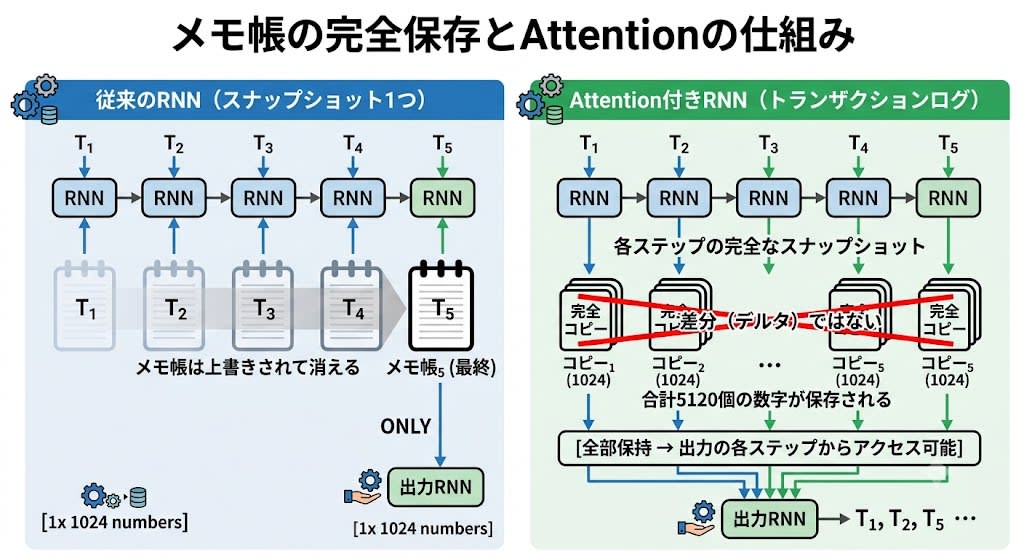
React的に言えば、Attentionは
ref.currentを上書きする前にhistory.push([...memo.current])でスプレッドコピーを保存しておくようなものです。出力時にはhistory[i]で任意の時点の状態にアクセスできます。
講義の例えに戻ると、Attentionは講義を録音することに相当します。ノート(最終メモ帳)だけに頼るのではなく、講義の各時点の録音が残っている。
しかし録音があるだけでは不十分です。2時間の講義の録音を毎回全部聴き直すわけにはいきません。「今、どの部分を聴き直すべきか」を判断する仕組みが必要です。これがAttentionの核心部分です。
ステップ2:どのスナップショットに注目するかを学習する
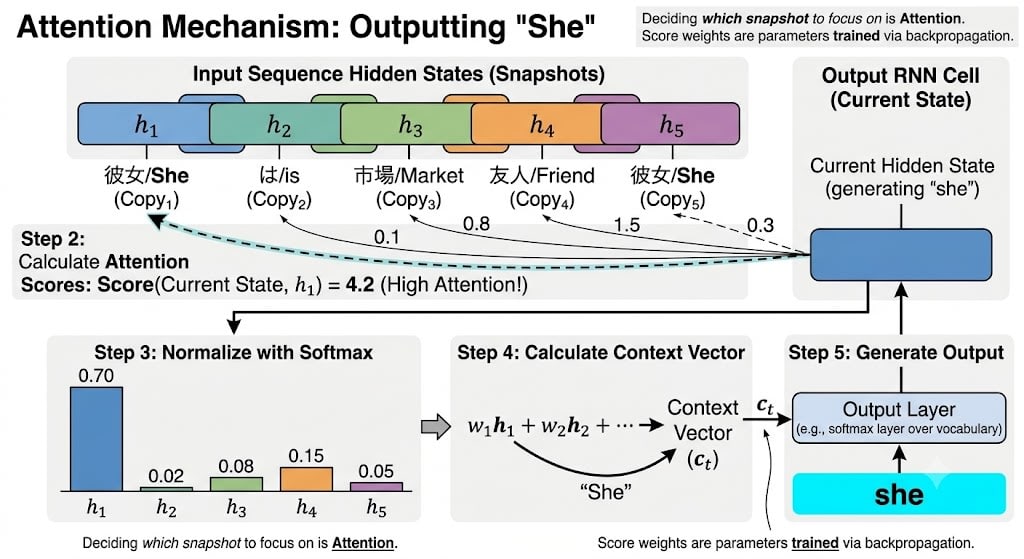
出力RNNが翻訳の各単語を生成するとき、以下のプロセスが走ります:
- 出力RNNの現在の状態(「今、何を訳そうとしているか」)を取る
- 保存された全スナップショットそれぞれとの関連度スコアを計算する
- スコアをsoftmaxで正規化して、合計が1.0になる重みに変換する
- 重みに応じてスナップショットの加重平均を取り、文脈ベクトルを作る
- この文脈ベクトルを使って出力単語を生成する
出力RNNが「she」を生成しようとしている場面:
保存されたスナップショット:
コピー₁(「彼女」処理後) コピー₂(「は」処理後) コピー₃(「市場」処理後)
コピー₄(「友人」処理後) コピー₅(「彼女」処理後)
ステップ2 — 関連度スコアを計算:
score(現在の状態, コピー₁) = 4.2 ← 高い!最初の「彼女」が関連
score(現在の状態, コピー₂) = 0.1
score(現在の状態, コピー₃) = 0.8
score(現在の状態, コピー₄) = 1.5
score(現在の状態, コピー₅) = 0.3
ステップ3 — softmaxで正規化(合計 = 1.0):
重み = [0.70, 0.02, 0.08, 0.15, 0.05]
ステップ4 — 加重平均:
文脈 = 0.70×コピー₁ + 0.02×コピー₂ + 0.08×コピー₃ + 0.15×コピー₄ + 0.05×コピー₅
= コピー₁(最初の「彼女」)に強く偏ったベクトル
ステップ5 — この文脈を使って「she」を生成
この「どのスナップショットにどれだけ注目するか」を決める重み——これが **Attention(注意)**の 名前の由来です。人間が文章を読むとき、すべての単語に均等に注意を払うのではなく、今の文脈に関連する部分に注意を集中させます。Attentionメカニズムはまさにこれを数値的に再現しています。
そしてスコア計算に使われる重みも、バックプロパゲーションで訓練されるパラメータです。「動詞を訳すときは主語のスナップショットに高いスコアをつける」というようなパターンを、データから自動的に学びます。
Attentionは勾配消失も改善する
Attentionのもう一つの重要な効果があります。出力から各スナップショットへの直接的な接続が、勾配にとってのショートカットになるのです。
RNNのみ(勾配はメモ帳チェーンを遡る):
出力 ← メモ帳₅₀ ← メモ帳₄₉ ← ... ← メモ帳₁
勾配は50ステップ遡る → 消失する
Attention付きRNN(勾配のショートカット):
出力 ← メモ帳₅₀ ← メモ帳₄₉ ← ... ← メモ帳₁ (RNNチェーン経由:遠い)
出力 ← コピー₁ (Attention経由:直結!)
出力 ← コピー₂ (Attention経由:直結!)
勾配はAttentionのショートカットを通って、任意のトークンに1ステップで到達できる
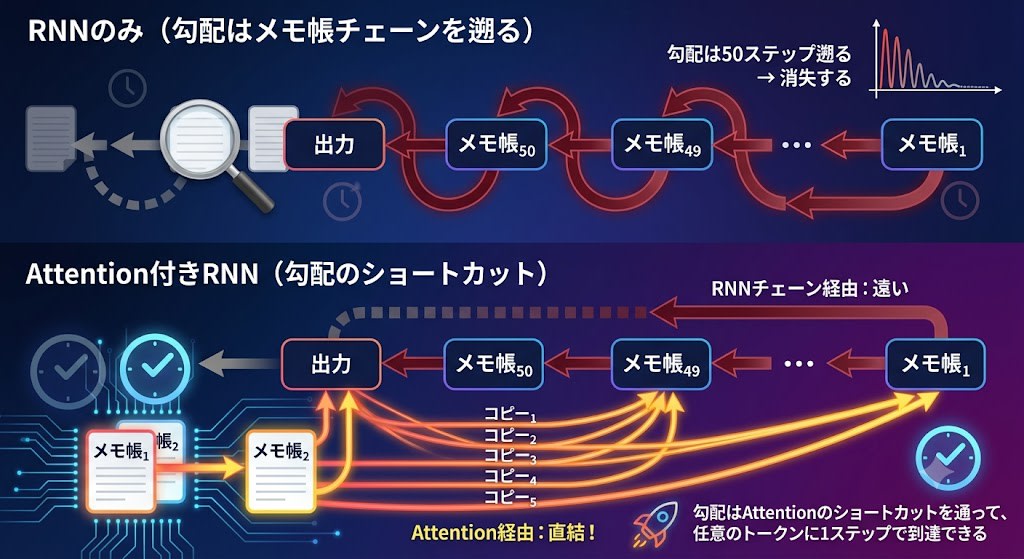
勾配はAttentionの直結路を通って任意のトークンに1ステップで到達できるため、RNNチェーンを遡る必要がなくなり、勾配消失が大幅に緩和されます。
これはグランドビジョンではありませんでした。翻訳の長文精度が落ちるというバグへの、工学的なパッチです。しかし結果として、スナップショットの制約(特定のトークンに問い合わせできない)を解決し、さらに勾配消失まで改善しました。
パッチがアーキテクチャになった:Transformer (2017)
バスワニらが立てた問い:「そもそもRNN(逐次処理の仕組み)は必要か? Attentionだけで翻訳できるのでは?」
ここまでの改善を振り返ると、Attention+RNNでもRNN部分の制約は残っていました——スナップショットの生成が逐次処理です。
Attention+RNNでは、参照(読み返し)は並列化できますが、スナップショットの生成は依然としてRNNが担当しています。各スナップショットは前のスナップショットに依存するため、順番にしか作れません。
Attention + RNN: 参照は改善されたが、スナップショット生成は逐次のまま
snapshot₁ = f("猫", 空) ← まずこれを計算
snapshot₂ = f("が", snapshot₁) ← snapshot₁が完成しないと計算できない
snapshot₃ = f("マット", snapshot₂) ← snapshot₂が完成しないと計算できない
各snapshotが前のsnapshotに依存 → チェーン → 並列化不可能
バスワニらの洞察は、このチェーン(メモ帳の連鎖)そのものを捨てることでした。
RNNなしでどう文脈を理解するか
RNNでは、トークンの順序はメモ帳の連鎖によって暗黙的に表現されていました。「猫」を処理してから「が」を処理するからこそ、「が」の時点のメモ帳に「猫」の情報が含まれる。処理の順序=文脈の順序。
Transformerは全く別のアプローチを取ります。各トークンは最初から自分の位置番号を持っている。
位置情報がデータ自体に含まれているので、全トークンを同時に処理しても順序が失われません。そして各トークンが他のすべてのトークンを参照する——これがTransformerの Self-Attention(自己注意) です。
先ほどのAttentionでは「出力RNNが入力のスナップショットを参照する」仕組みでした。Self-Attentionでは、入力トークン同士が互いを参照する。「猫」は「座った」を見て、「座った」は「猫」を見る——すべて同時に。
RNNでは「メモ帳₃を計算するにはメモ帳₂が必要、メモ帳₂にはメモ帳₁が必要」という依存チェーンがありました。Transformerにはこのチェーンがありません。各トークンのEmbeddingは他のトークンの処理結果に依存しない——だから同時に処理できるのです。
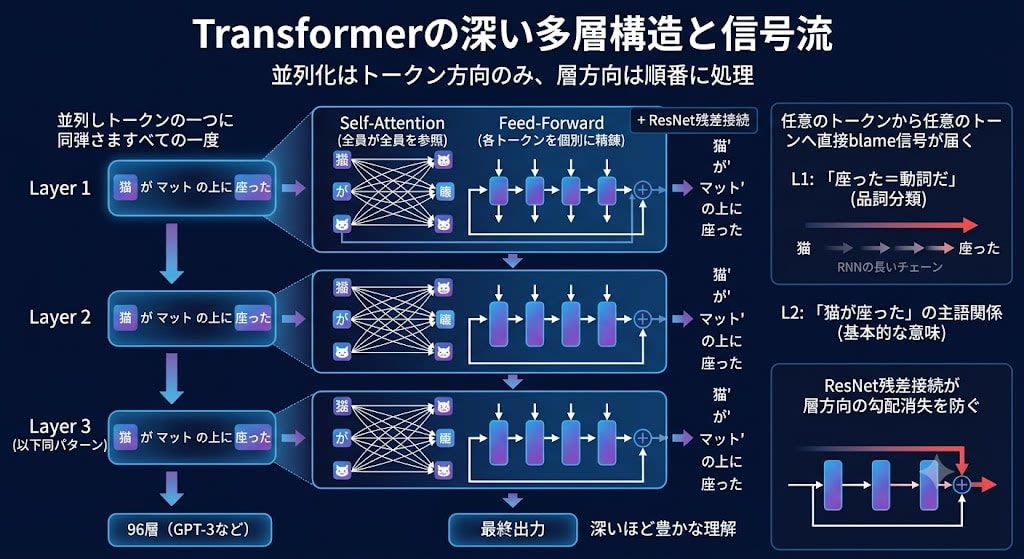
「全トークンを同時に処理」と聞くと、ネットワークが「平ら」になったように聞こえるかもしれません。しかし Transformerは依然として深い多層構造 です。GPT-3は96層あります。
並列化されたのはトークン方向だけです。層方向は依然として順番に処理します。
各層が表現を精錬していきます。Layer 1は「座った=動詞だ」を学び、Layer 2は「猫が座ったの主語だ」を学び、さらに深い層は複雑な意味関係を学ぶ。深いほど豊かな理解——第3章と同じ原理です。
バックプロパゲーション(blame)も第3章と同じ仕組みで層を逆方向に流れます。加えて、Self-Attentionの接続を通じて、任意のトークンから任意のトークンへ直接blame信号が届く——RNNのような長いチェーンを遡る必要がないので、勾配消失が大幅に緩和されます。そしてResNet残差接続が、層方向の勾配消失を防ぎます。
処理時間:なぜTransformerが速いのか
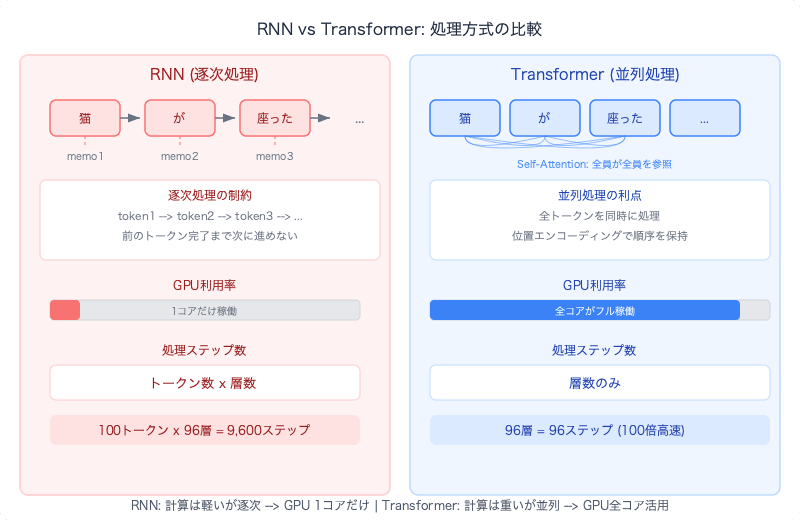
RNNとTransformerの処理時間を比較すると:
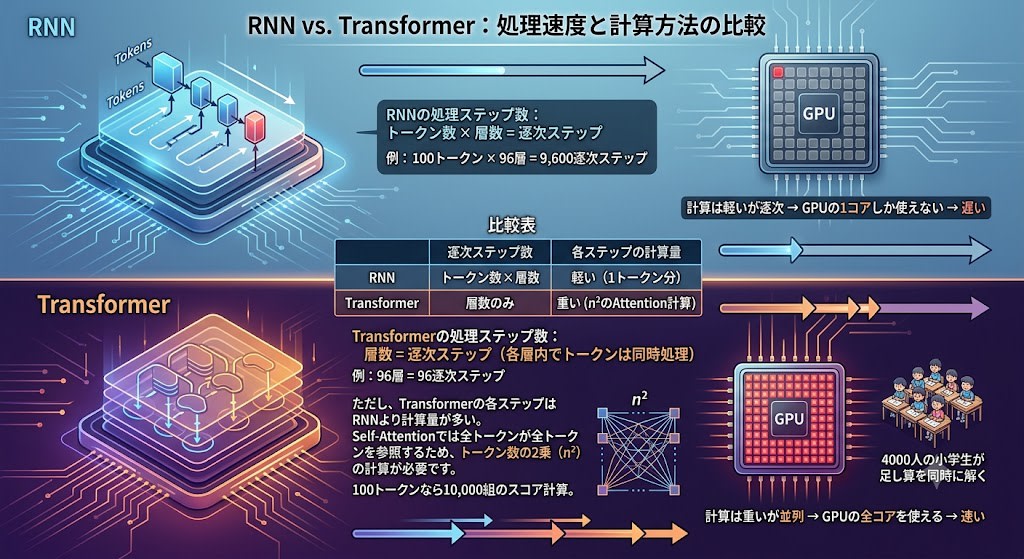
RNNの処理ステップ数:
トークン数 × 層数 = 逐次ステップ
例: 100トークン × 96層 = 9,600逐次ステップ
Transformerの処理ステップ数:
層数 = 逐次ステップ(各層内でトークンは同時処理)
例: 96層 = 96逐次ステップ
ただし、Transformerの各ステップはRNNより計算量が多い。Self-Attentionでは全トークンが全トークンを参照するため、トークン数の2乗(n²)の計算が必要です。100トークンなら10,000組のスコア計算。
| 逐次ステップ数 | 各ステップの計算量 | |
|---|---|---|
| RNN | トークン数 × 層数 | 軽い(1トークン分) |
| Transformer | 層数のみ | 重い(n²のAttention計算) |
合計の計算量はTransformerの方が多いこともあります。しかし重い計算はGPUで並列化できる。これは第3章のAlexNetと同じ構造です——4000人の小学生が足し算を同時に解く。n²のスコア計算は互いに独立しているため、GPUの数千コアで同時に実行できます。
一方、RNNの逐次ステップはどんなに高性能なGPUがあっても並列化できません。前のステップが完了しないと次に進めないからです。
結果として、Transformerはこの章で見てきた問題をすべて同時に解決しました:
| RNN | LSTM | Attention+RNN | Transformer | |
|---|---|---|---|---|
| スナップショット問題 | ✗ | ✗ | ✓ (ログ化) | ✓ |
| 勾配消失(時間方向) | ✗ | ✓ (高速道路) | ✓ (ショートカット) | ✓ (直結) |
| 並列処理 | ✗ | ✗ | ✗ (RNN部分が残る) | ✓ |
RNNを捨ててAttentionだけにした結果、訓練が劇的に速くなりました。速くなるということは、より大きいモデルをより多くのデータで訓練できるということです。
翻訳の速度改善を目的としたアーキテクチャが、スケールを可能にすることでLLM全体の基盤になりました。
6. 大きくすれば賢くなるか? — スケールと創発
スケール則の発見 (2020)
「モデルを大きくすれば性能が上がる」は経験則として知られていました。OpenAIのカプランらが、これを数式で示しました:
性能は、パラメータ数・データ量・計算量の3つに対して、なめらかで予測可能な法則に従って改善する。
3つの変数を具体的に見てみましょう:
| 変数 | 意味 | 増やす方法 |
|---|---|---|
| パラメータ数 (N) | モデルの重みの総数 | 層を深くする、各層のノード数を増やす |
| データ量 (D) | 訓練に使うトークン数 | より多くのテキストを収集する(Web、書籍、コードなど) |
| 計算量 (C) | 訓練中にGPUが実行する演算の総量(FLOPs) | より多くのGPUで、より長い時間訓練する |
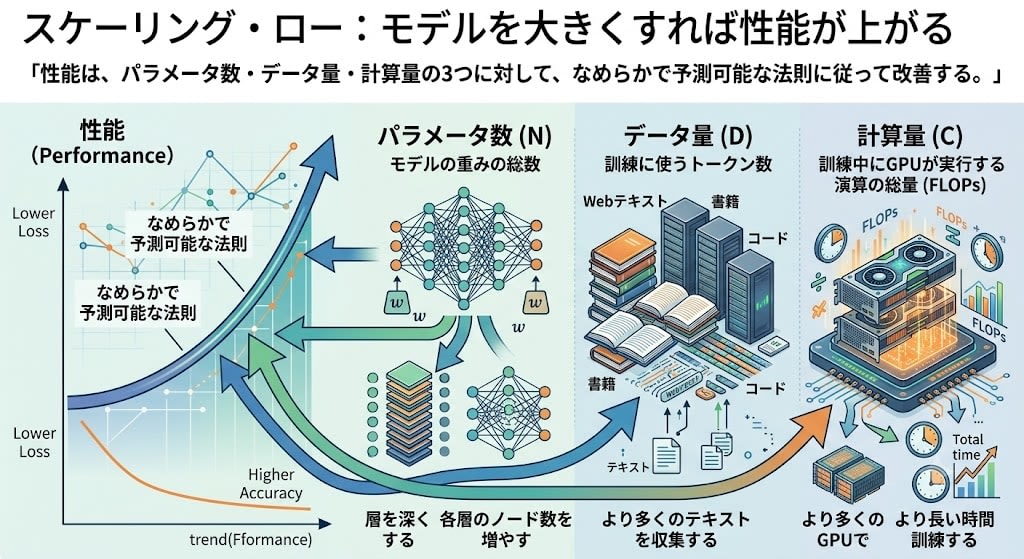
パラメータ数とデータ量は直感的ですが、計算量は少し説明が必要です。
計算量とは、訓練中にGPUが実行する浮動小数点演算(FLOP: Floating Point Operation)の総数です。モデルが1つのバッチを処理するたびに、順伝播と逆伝播で大量の行列演算が走ります。その演算の累計が計算量です。
カプランらは、この3つの関係を近似式で示しました:
つまり計算量はパラメータ数とデータ量の積にほぼ比例します。計算量は独立した第3の変数というより、投入できる総予算です。予算が決まれば、モデルをどこまで大きくし、データをどれだけ食わせるかが決まります。
計算量を増やす方法はシンプルです——GPUの数 × 訓練時間。GPT-3の訓練には約3.14×10²³ FLOPsが費やされました。これは数千基のGPUを数週間走らせた結果です。つまり計算量を増やすとは、端的に言えばお金と時間を投入するということです。
補足:Chinchilla則 (2022)
カプランのスケール則は「計算予算が増えたら、モデルを大きくする方に多く配分すべき」と示唆しました。しかし2022年、DeepMindのホフマンらは「データ量にもっと配分すべき」と修正しました(Chinchilla則)。同じ計算予算でも、配分の最適比率が異なるという発見です。両者が一致しているのは、計算量が根本的な制約資源であるという点です。
これは「地図」でした。「このサイズのモデルをこれだけのデータで訓練すれば、これくらいの性能になる」と事前に予測できる。結果が見えるなら、大規模投資の判断ができます。
Transformerから「GPT」へ——目的の転換
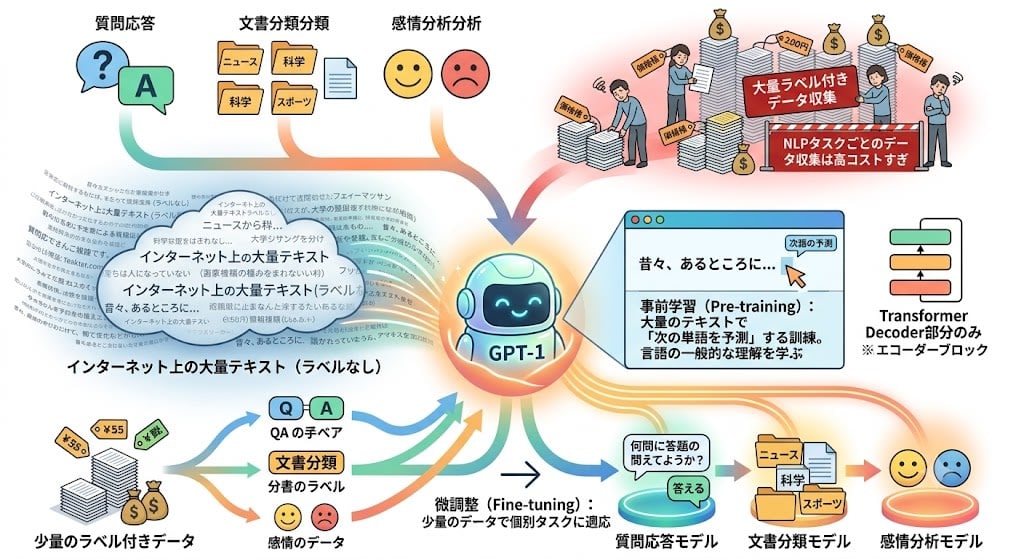
Transformerは翻訳のために生まれました。しかしGPT(Generative Pre-trained Transformer——生成型の事前学習済みTransformer)は、翻訳とは別の問題を解こうとしていました。
2018年、OpenAIのラドフォードらが直面していた問題はこうです:
NLPには多様なタスク(質問応答、文書分類、感情分析など)があるが、それぞれのタスクごとにラベル付きデータを大量に集めるのは高コストすぎる。
ラベルなしテキスト(インターネット上の文章)は大量にある。これを使って「言語の一般的な理解」を先に学び、少量のラベル付きデータで個別タスクに適応させれば良いのではないか?
これがGPT-1の核心アイデアです:
- 事前学習(Pre-training):大量のテキストで「次の単語を予測する」だけの訓練をする
- 微調整(Fine-tuning):個別タスク用の少量データで重みを調整する
アーキテクチャはTransformerのDecoder部分だけを使いました。翻訳のためのEncoder-Decoder構造は不要で、「テキストを読んで続きを予測する」というシンプルな構造で十分だったからです。
GPT-1 → GPT-2 → GPT-3:同じ設計図、異なるスケール
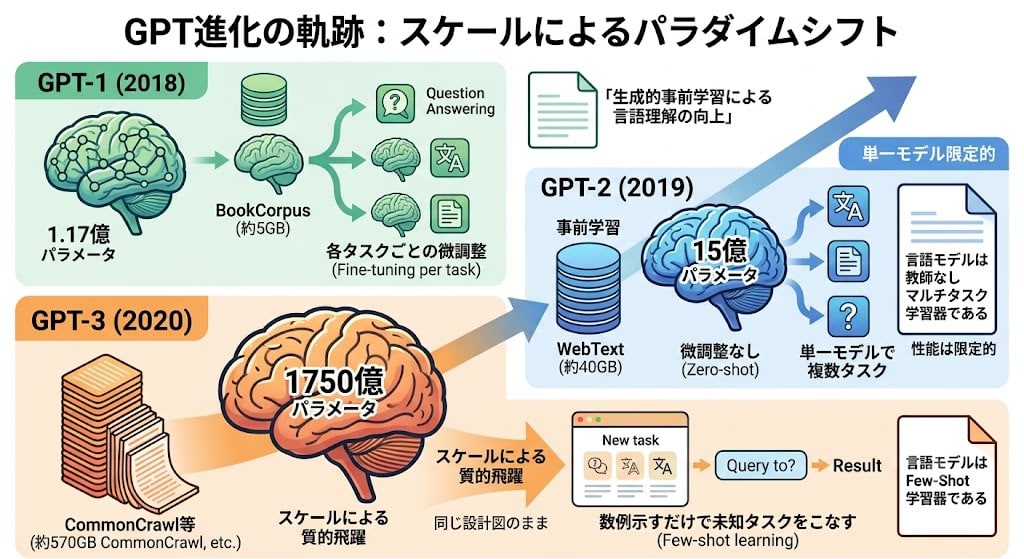
ここが重要です。GPT-1、GPT-2、GPT-3はアーキテクチャがほぼ同じです。 基本設計を変えず、スケールだけを変えて何が起きるかを観察した——これが3世代の本質です。
| GPT-1 (2018) | GPT-2 (2019) | GPT-3 (2020) | |
|---|---|---|---|
| パラメータ数 | 1.17億 | 15億 | 1750億 |
| 訓練データ | BookCorpus(約5GB) | WebText(約40GB) | CommonCrawl等(約570GB) |
| 核心の発見 | 事前学習 + 微調整が有効 | 微調整なしでもタスクが解ける(Zero-shot) | 数例示すだけで未知のタスクをこなす(Few-shot) |
| 論文タイトルが語る思想 | "Improving Language Understanding by Generative Pre-Training" | "Language Models are Unsupervised Multitask Learners" | "Language Models are Few-Shot Learners" |
GPT-1は「事前学習+微調整」の有効性を示しました。しかしタスクごとに微調整が必要でした。
GPT-2はモデルを13倍に大きくし、データも増やしました。すると、微調整なしでも一部のタスクをこなせるようになりました(Zero-shot)。論文タイトルの通り「言語モデルは教師なしのマルチタスク学習器である」という発見です。ただし性能はまだ限定的でした。
GPT-3はさらに117倍に大きくしました。アーキテクチャの変更はごくわずか(Sparse Attentionの部分導入程度)です。同じ設計図のまま、スケールだけで質的な飛躍が起きました。
ここで読者が抱きやすい疑問に答えます。
「Few-shotは訓練の一部なのか? それとも訓練の後に起きることなのか?」
答えは訓練の後です。Few-shotは推論時(ユーザーがモデルを使う時)のテクニックです。
GPT-3の訓練プロセスを整理すると:
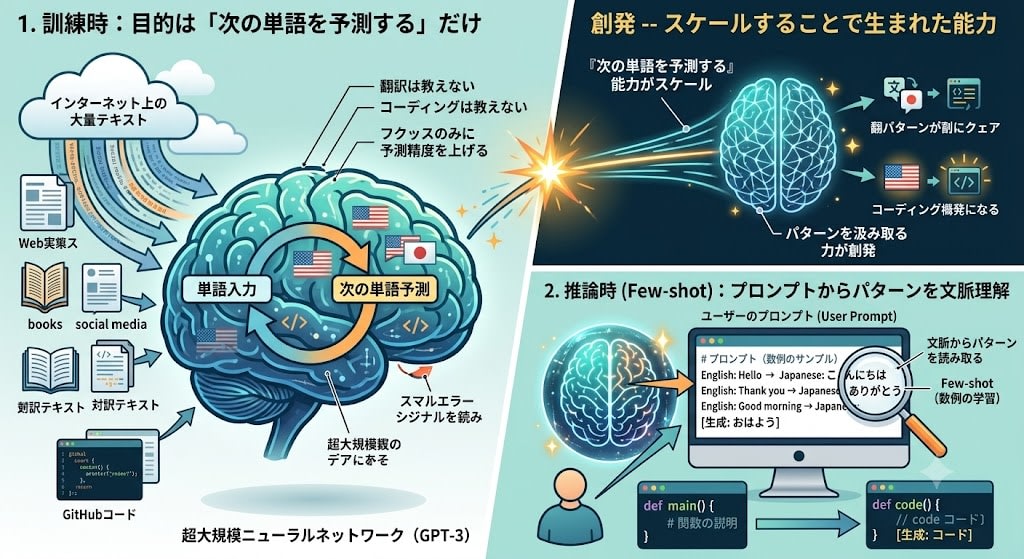
- 訓練時:インターネットから集めた大量のテキストで「次の単語を予測する」だけを学ぶ。翻訳を教えたわけでも、コーディングを教えたわけでもない。目的は一つだけ——次の単語の予測精度を上げる
- 推論時(Few-shot):ユーザーがプロンプトに数例のサンプルを示す。モデルはそのパターンを文脈から読み取り、同じパターンで続きを生成する
GPT-3は翻訳を明示的に訓練されていません。しかし訓練データに英日の対訳テキストが含まれていたため、「次の単語を予測する」能力がスケールすることで、パターンを汲み取って正しく続ける力が創発しました。
コード生成も同じです。GitHubのコードが訓練データに含まれていたので、「関数の説明 → コード」というパターンを数例示すだけで、見たことのない関数を書けるようになりました。
なぜGPT-3で「ビッグバン」が起きたのか?
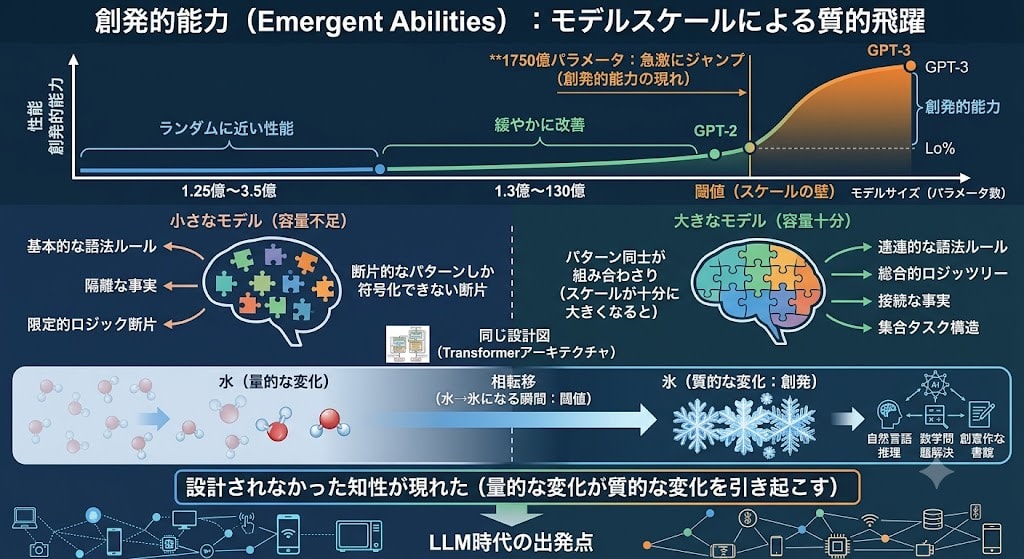
GPT-2でもZero-shotは部分的に動いていました。では、GPT-3で何が変わったのか?
答えは閾値の突破です。
多くのタスクで、モデルサイズと性能の関係はこう推移しました:
- 1.25億~3.5億パラメータ:ランダムに近い性能
- 13億~130億パラメータ:緩やかに改善
- 1750億パラメータ:急激にジャンプ
これが**創発的能力(Emergent Abilities)**です。物理学の相転移(水が氷になる瞬間)のように、量的な変化がある閾値を超えると質的な変化を引き起こす。GPT-2はその閾値の手前にいて、GPT-3はその先にいました。
なぜ閾値が存在するのか? 訓練中、モデルは「次の単語を予測する」ために、テキストに含まれるあらゆるパターン(文法、論理、事実、タスク構造)を内部に符号化していきます。小さなモデルでは容量が足りず、個別パターンの断片しか学べない。しかしスケールが十分に大きくなると、パターン同士が組み合わさり、明示的に訓練していない能力として表面化する——これが創発の正体です。
GPT-3は新しいアーキテクチャで知性を設計したのではありません。同じ設計図を、閾値を超えるまでスケールさせた結果、設計されなかった知性が現れたのです。これが現在のLLM時代の出発点です。
7. 賢くなった後の課題 — 微調整から整列へ、そしてスケールの先
GPT-3は驚くほど多才でしたが、使いにくかった。人種差別的な文章を生成したり、質問に答える代わりに無関係な文章を続けたり、嘘を自信満々に語ったりしました。「次の単語を予測する」能力と「人間に役立つ回答をする」能力は、同じではなかったのです。
ここから先の歴史は、3つの段階に分けられます。
微調整(Fine-tuning)の仕組み
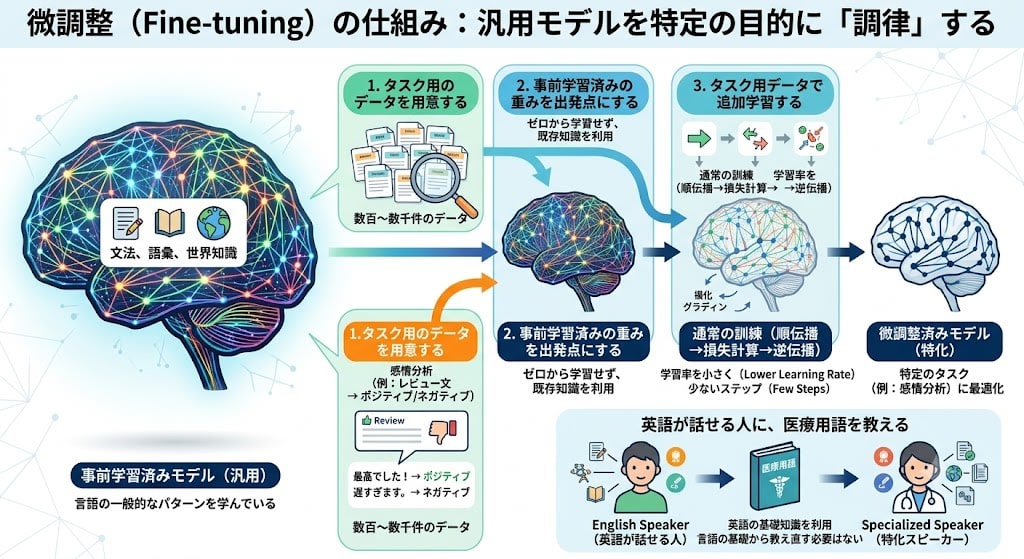
GPT-1で登場した微調整を、もう少し詳しく見てみましょう。
事前学習済みモデルは、言語の一般的なパターンを学んでいますが、特定のタスク(感情分析、質問応答など)に最適化されていません。微調整は、この汎用モデルを特定の目的に「調律」するプロセスです。
仕組みはシンプルです:
- タスク用のデータを用意する:例えば「レビュー文 → ポジティブ/ネガティブ」のペアを数百〜数千件
- 事前学習済みの重みを出発点にする:ゼロから学習するのではなく、すでに言語を理解している重みから始める
- タスク用データで追加学習する:通常の訓練と同じ仕組み(順伝播→損失計算→逆伝播)だが、学習率を小さくし、少ないステップで済ませる
なぜ少量のデータで効くのか? 事前学習で文法・語彙・世界知識をすでに獲得しているからです。微調整は「英語が話せる人に、医療用語を教える」ようなもので、言語の基礎から教え直す必要はありません。
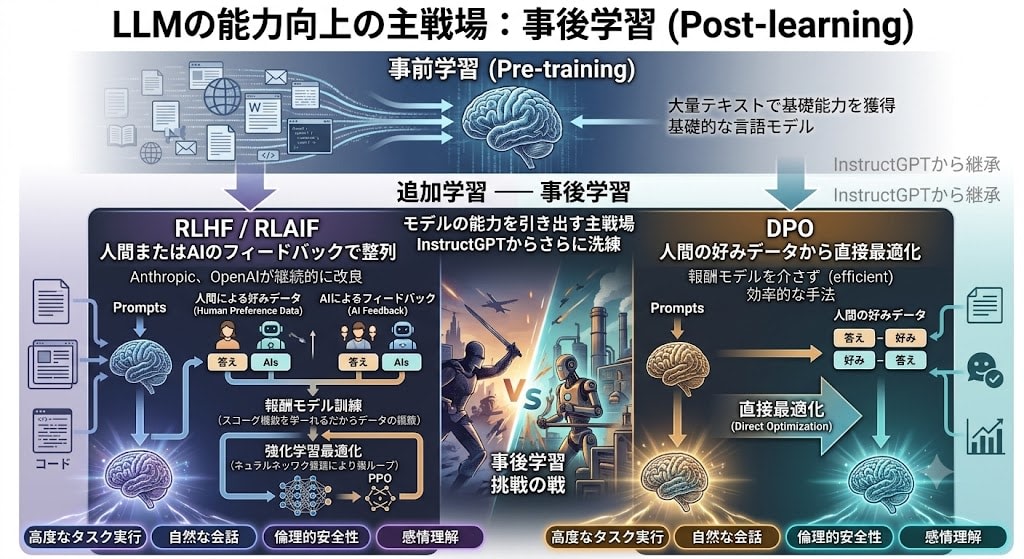
InstructGPT:人間のフィードバックで「整列」させる (2022)
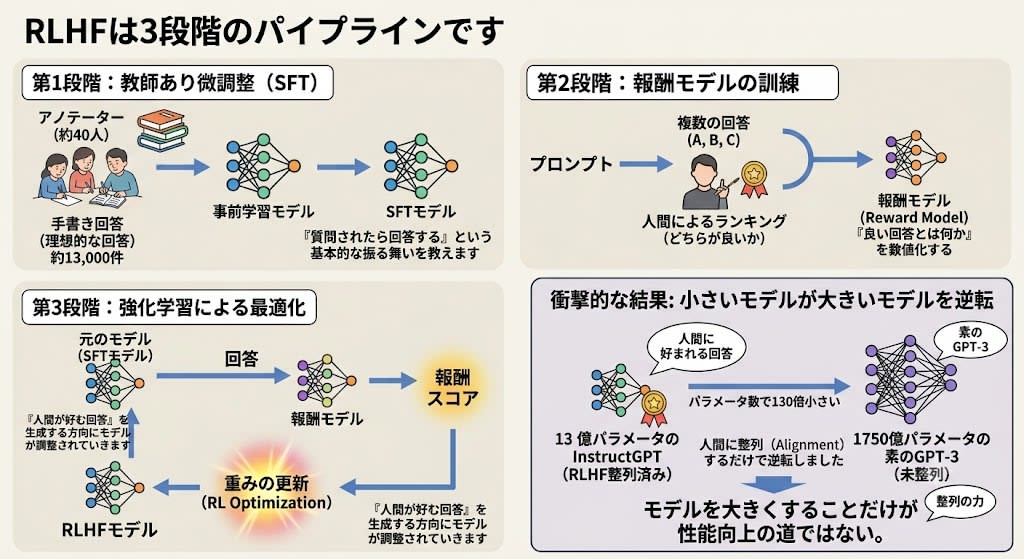
GPT-3の問題は「賢いが、人間の意図に沿わない」ことでした。OpenAIはこれを解決するために、微調整の概念を発展させた RLHF(Reinforcement Learning from Human Feedback——人間のフィードバックによる強化学習) を開発しました。
RLHFは3段階のパイプラインです:
第1段階:教師あり微調整(SFT)
人間のアノテーター(約40人)が、プロンプトに対する「理想的な回答」を手書きで約13,000件作成しました。これで通常の微調整を行い、「質問されたら回答する」という基本的な振る舞いを教えます。
第2段階:報酬モデルの訓練
同じプロンプトに対してモデルが複数の回答を生成し、人間がそれらを「どちらが良いか」でランク付けします。このランキングデータから、「良い回答とは何か」を数値化する 報酬モデル(Reward Model) を訓練します。
第3段階:強化学習による最適化
元のモデルが回答を生成し、報酬モデルがスコアをつけ、そのスコアを使って元のモデルの重みを更新します。「人間が好む回答」を生成する方向にモデルが調整されていきます。
結果は衝撃的でした。13億パラメータのInstructGPTが、1750億パラメータの素のGPT-3より人間に好まれる回答を生成したのです。パラメータ数で130倍小さいモデルが、「整列」するだけで逆転しました。
これは重要な教訓です:モデルを大きくすることだけが性能向上の道ではない。
微調整の現在地:いつ必要で、いつ不要か?
GPT-1の時代は、すべてのタスクに微調整が必須でした。GPT-3でFew-shotが使えるようになり、さらにInstructGPTでゼロショットでも指示に従えるようになった今、微調整の役割は変わりました。
| 微調整が不要なケース | 微調整が必要なケース | |
|---|---|---|
| 典型例 | メール作成、要約、一般的なQ&A | 医療診断支援、法律文書レビュー、社内用語の理解 |
| 理由 | 汎用モデルのプロンプトで十分な品質 | 専門用語・特定フォーマット・コンプライアンス要件が厳密 |
ラベル付きデータは依然として重要です——ただし用途が変わりました。GPT-1時代は「タスクを教える」ために必要でしたが、現在は主に「モデルの振る舞いを整列させる」ために必要です。RLHFの人間によるランキングデータがその典型です。
また、LoRA(Low-Rank Adaptation)やQLoRAといった パラメータ効率的微調整(PEFT) の登場により、全パラメータを更新せずとも、わずかなパラメータの追加だけで微調整できるようになりました。微調整のコストは2020年代前半と比べて90%以上削減されています。
スケールの先へ:LLMは今どう進化しているか?
「パラメータ・データ・計算量を増やせば賢くなる」——スケール則はGPT-3の成功を説明しました。しかし2024年頃から、この戦略は壁に直面しています。
壁1:データの枯渇
インターネット上の高品質なテキストデータは有限です。2026年現在、人間が書いた高品質テキストはほぼ使い尽くされたと言われています。
壁2:コストの限界
より大きなモデルの事前学習には数億ドル規模の投資が必要で、収穫逓減が見え始めています。
NeurIPS 2024で、OpenAI共同創設者のイリヤ・サツキヴァーはこう宣言しました:
「私たちが知っている形の事前学習は終わりを迎える。2010年代はスケールの時代だった。今は驚きと発見の時代に戻った。」
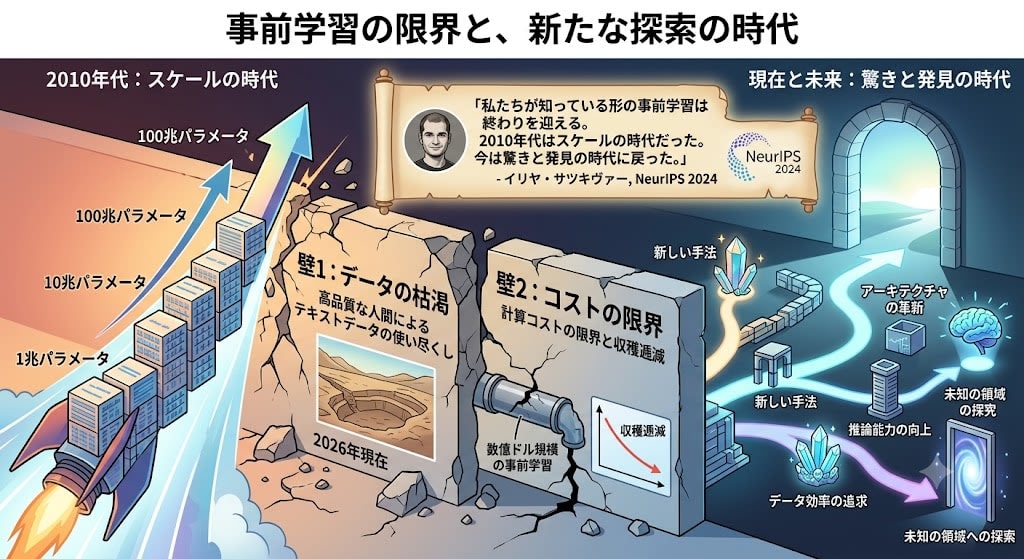
では、スケール以外にどんな進化の軸があるのか? 現在の主要なアプローチを整理します。
軸1:事後学習(Post-training)の深化
InstructGPTで始まったRLHFは、現在さらに洗練されています。事前学習(大量テキストで基礎能力を獲得)の後に行う追加学習——事後学習——が、モデルの能力を引き出す主戦場になりました。
- RLHF / RLAIF:人間またはAIのフィードバックで整列(Anthropic、OpenAIが継続的に改良)
- DPO(Direct Preference Optimization):報酬モデルを介さず、人間の好みデータから直接最適化する効率的な手法
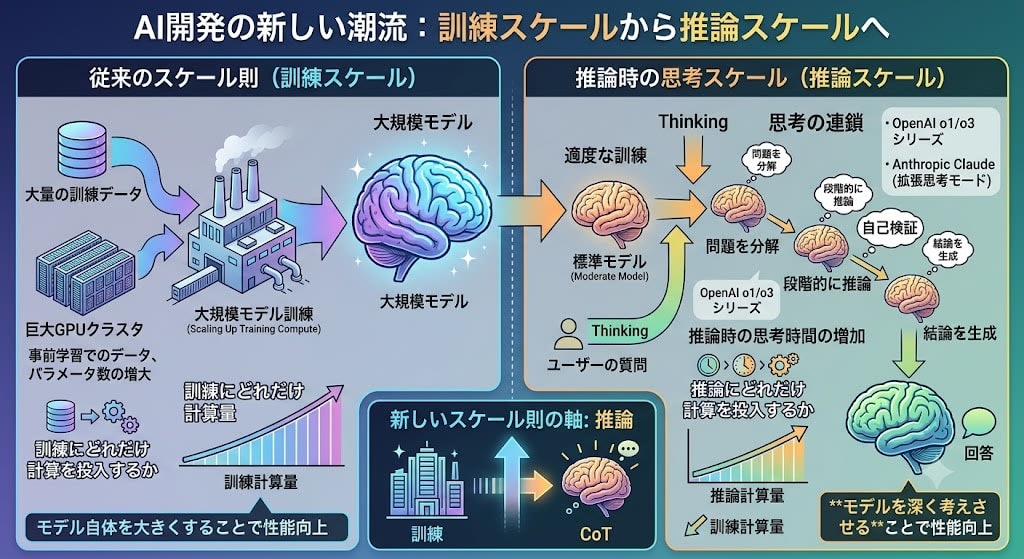
軸2:推論時計算(Test-time Compute)
訓練を大きくする代わりに、推論時にもっと考えさせるというアプローチです。
OpenAIのo1/o3シリーズやAnthropicのClaude(拡張思考モード)が代表例です。モデルが回答する前に「思考の連鎖(Chain of Thought)」を生成し、段階的に推論する。訓練時の計算量を増やす代わりに、推論時の計算量を増やすことで性能を上げます。
スケール則が「訓練にどれだけ計算を投入するか」の法則だったのに対し、これは「推論にどれだけ計算を投入するか」という新しい軸です。
軸3:合成データと蒸留
人間のデータが枯渇するなら、AIにデータを作らせる。
- 蒸留(Distillation):大きなモデル(教師)が生成した回答で、小さなモデル(生徒)を訓練する。DeepSeek-R1の蒸留版やLlamaの派生モデルがこの手法で作られています
- Self-Play:モデルが自分自身と対話し、問題を出し合い、解き合うことで能力を向上させる
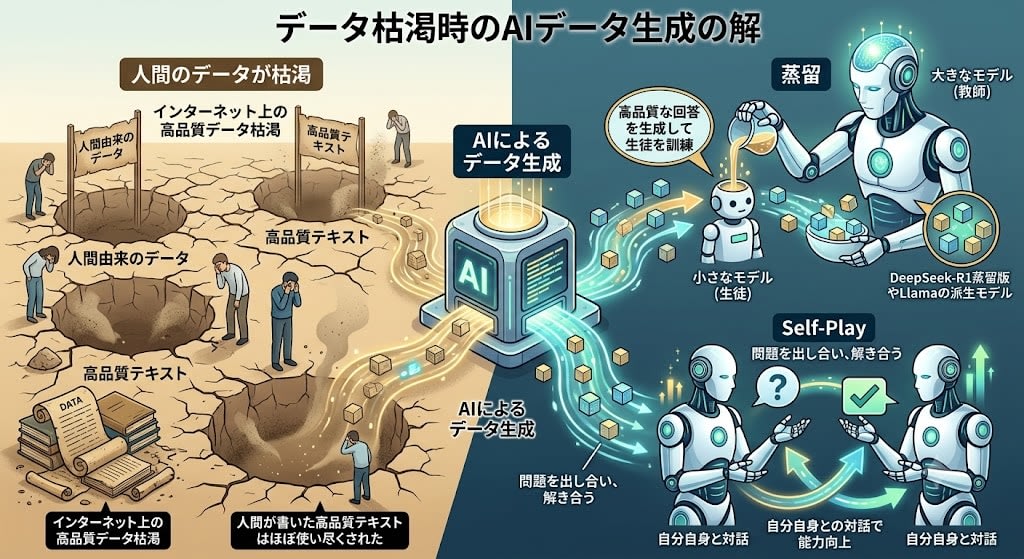
2026年の典型的なワークフローでは、200件の種データを人間が書き、それをフロンティアモデルで数万件に拡張し、品質フィルタをかけて小型モデルを訓練します。
まとめ:3つの時代
| 時代 | 主な戦略 | 代表例 |
|---|---|---|
| スケールの時代 (〜2023) | パラメータ・データ・計算量を増やす | GPT-3, PaLM, LLaMA |
| 整列の時代 (2022〜) | 事後学習で人間の意図に合わせる | InstructGPT, Claude, ChatGPT |
| 効率の時代 (2024〜) | 推論時計算・合成データ・蒸留で賢くする | o1/o3, DeepSeek-R1, Claude拡張思考 |
これらは互いに排他的ではなく、現在のフロンティアモデルは3つすべてを組み合わせています。しかし重心は明確に移動しました——「大きくすれば賢くなる」から「賢く使えば小さくても強い」へ。
まとめ:設計されなかったLLM
LLMは誰もLLMを目指していなかった時代に、別々の問題への解答として積み重なってきた概念の集積です。

| 人物 | 元々の目的 | 解こうとした問題 | 意図せぬ副産物 |
|---|---|---|---|
| Turing (1936) | 数学の限界の証明 | アルゴリズムで解けない問題は存在するか? | コンピュータという概念の誕生 |
| Shannon (1948) | 通信ノイズの削減 | 情報をどう正確に送るか? | 情報エントロピー → LLMの損失関数 |
| Rosenblatt (1958) | 学習する機械の実装 | 機械は学べるか? | パーセプトロン(最初のニューラルネット) |
| Minsky & Papert (1969) | NNの数学的解析 | パーセプトロンの能力と限界は? | 限界の証明 → 多層ネットワークへの要件定義 |
| Rumelhart et al. (1986) | 多層NNの訓練 | 深いネットワークをどう学習させるか? | バックプロパゲーション |
| Krizhevsky et al. (2012) | 画像認識の精度向上 | 計算速度が足りない | GPU活用 → 訓練速度の壁を突破 |
| He et al. (2015) | さらに深いネットワーク | 層を深くすると勾配が消失する | 残差接続(ResNet) → 深さの壁を突破 |
| Mikolov et al. (2013) | より良い単語表現 | テキストをどう数値化するか? | 意味の幾何学(Embedding) |
| Hochreiter & Schmidhuber (1997) | RNNの長期記憶 | 時間方向の勾配消失をどう解決するか? | LSTM → 時間方向のResNet |
| Bahdanau et al. (2014) | 翻訳の長文精度 | 固定長ベクトルの情報損失を防ぐには? | Attentionメカニズム |
| Vaswani et al. (2017) | 翻訳の高速化 | RNNの逐次処理の遅さを解決するには? | Transformer(並列化可能なアーキテクチャ) |
| Radford et al. (2018) | ラベル付きデータ不足の解消 | 少量のラベルデータで多様なNLPタスクを解くには? | GPT-1:事前学習+微調整パラダイム |
| Radford et al. (2019) | 汎用言語モデルの探求 | 微調整なしでタスクを解けるか? | GPT-2:Zero-shot能力の萌芽 |
| Kaplan et al. (2020) | 計算コストの最適化 | スケールと性能の関係は? | スケール則 → 大規模訓練の根拠 |
| Brown et al. (2020) | 大規模モデルの能力調査 | スケールアップすると何が起きる? | GPT-3・Few-shot学習の創発 |
| Ouyang et al. (2022) | モデルの安全性と有用性の改善 | 賢いモデルを人間の意図に沿わせるには? | RLHF → 小さくても「整列」で逆転 |
それぞれの研究者は自分の目の前の問題だけを見ていた。設計図なしに、80年余りかけて部品が揃いました。
今この瞬間も、誰かが全く別の問題に行き詰まり、その壁を越えるために書いている論文が、10年後のAIの部品になっているかもしれません。










