
LLM に文書の保守を任せたらどうなるかという論文の話
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
少し前に「Karpathy 氏が言語化した『LLM Knowledge Base』というパターン」という記事を書きました。raw な素材を LLM に渡して構造化された wiki にコンパイルさせる、という発想を実際に取り入れてみたら気持ちよく回り始めた、という内容です。
その記事を公開した直後に Microsoft Research から「LLMs Corrupt Your Documents When You Delegate」という論文(arXiv:2604.15597v1、Laban / Schnabel / Neville、2026 年 4 月 17 日)が出ているのを SNS で共有いただきました。タイトルだけで察しがつくとおり、Karpathy 氏のような「LLM に保守を任せる」発想に水を差す?ような内容です。
読んでみると、否定するための否定ではなく、「短期的にうまく動くからといって、長期間任せ続けたときの劣化を測ったら無視できない量だった」という地に足のついた指摘でした。前回紹介した発想を一度立ち止まって見直すためにも、内容と含意を整理しておこうと思います。
論文の主張をひとことで
論文の主張はシンプルです。
Current LLMs are unreliable delegates: they introduce sparse but severe errors that silently corrupt documents, compounding over long interaction.
(現在の LLM は信頼できる委譲先ではない。疎ながら重大なエラーを持ち込み、長期インタラクションを通じて静かに文書を破損させ、それが複合化していく)
具体的には、最先端モデル 3 種(Gemini 3.1 Pro / Claude 4.6 Opus / GPT 5.4)の 52 領域平均で、20 インタラクション後には文書の 25% が破損していたという結果です。「インタラクション」とは LLM に文書を編集させる 1 回のやり取りで、論文では延長実験で 100 ラウンドまで進めても劣化が止まらないことを確認しています。
実測値を 3 モデル並べると、20 インタラクション時点で Gemini 3.1 Pro 80.9% / Claude 4.6 Opus 73.1% / GPT 5.4 71.5% という Reconstruction Score になります。
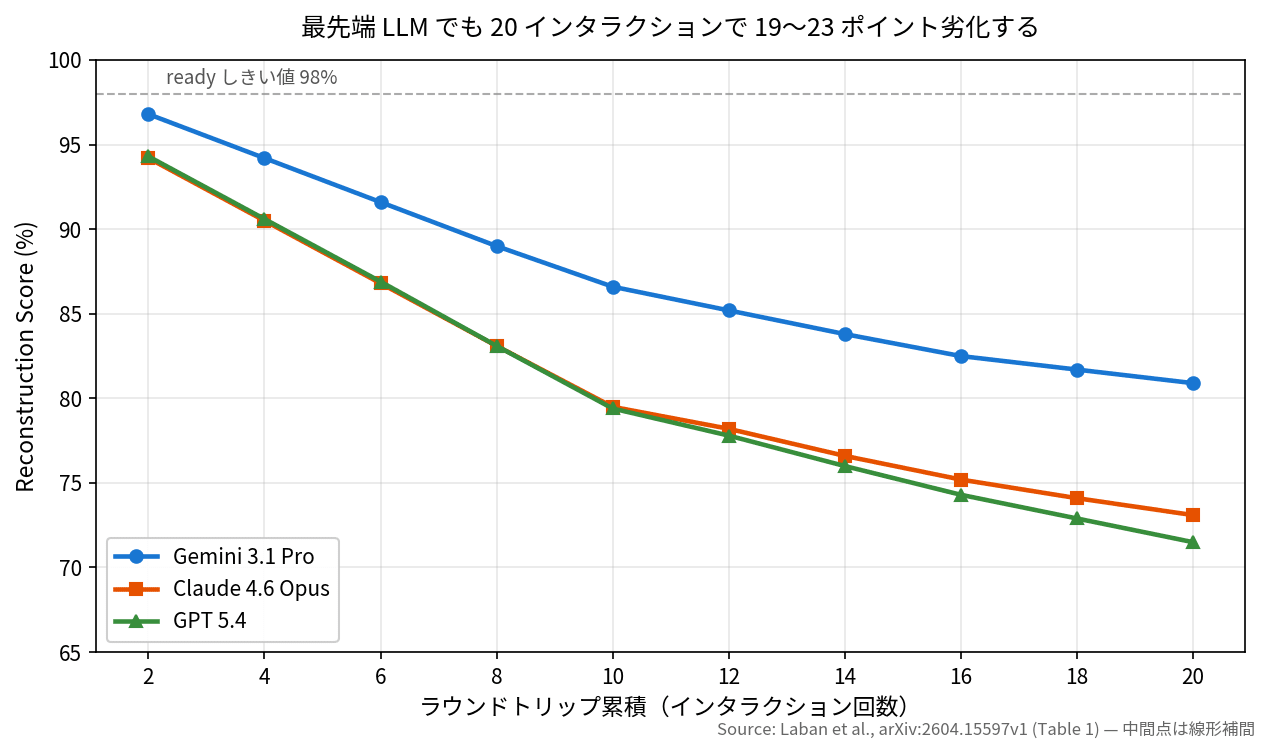
3 モデルの劣化曲線(出典: Laban et al. 2026, Table 1)
短期と長期で景色がだいぶ違うのが分かるかと思います。2 インタラクション時点ではどのモデルも 94〜97% で誰が見ても合格ラインですが、20 インタラクションでは 71〜81% まで落ちる。論文はこの「短期テストでは長期パフォーマンスを予測できない」という点を強調していて、ベンチマーク設計そのものへの再考も促しています。
DELEGATE-52 と round-trip 評価
数字の裏側にある実験設計が論文のもう一つの核です。
著者らは DELEGATE-52 という新しいベンチマークを作りました。Python・Docker・Makefile といったコード系から、結晶構造、音楽記譜、レシピ、家系図、ライブラリ目録まで 52 の専門領域・合計 310 の作業環境を集めたものです。それぞれ 2〜5k トークンの実文書(合成データではなく Web 上の本物)と、5〜10 個の編集タスクを含んでいます。
評価には back-translation の round-trip という、機械翻訳の世界で使われていた手法を持ち込んでいます。
Forward : t = LLM(s; x→)
Backward : ŝ = LLM(t; x←)
Score : RS = sim(s, ŝ)
要は、「カテゴリ別にファイル分割して」という前向き編集と、「時系列で 1 ファイルに統合して」という後ろ向き編集を交互に繰り返したとき、最終的に元の文書に戻れるかを測るというものです。誤差ゼロのモデルなら sim(s, ŝ) = 1 になる。正解アノテーションが要らないからこそ、52 領域に展開できたわけです。
汎用の類似度(Levenshtein や埋め込み距離)では拾えない劣化を見るために、ドメインごとに専用パーサと加重類似度を実装しているのも丁寧な設計だと感じました。たとえばレシピなら、材料 40%、調理手順 40%、コツ 20% の重み付けで、200g → 800g のような数値の改変も厳密に検出する仕組みになっています。
6 つの劣化要因
論文を読んでいて見過ごせないと感じた劣化要因が 6 つあります。
1. 累積エラー(compounding errors)
ラウンドを重ねるごとに減点が積み重なり、長期になっても収束しません。短期テストで 95% を越えていたモデルでも、ラウンドが伸びれば線形的に下がっていきます。
2. 文書サイズとラウンド数の相互作用
1k トークンの文書なら 20 インタラクション後も 91.4%。ところが 4k で 79.0%、10k では 59.9% まで落ちます。論文では GPT 5.4 を例に「1,000 トークン増えるごとの劣化幅が 2 ラウンドで 0.7%、20 ラウンドで 3.6%」と、約 5 倍に増幅される計算を示しています。
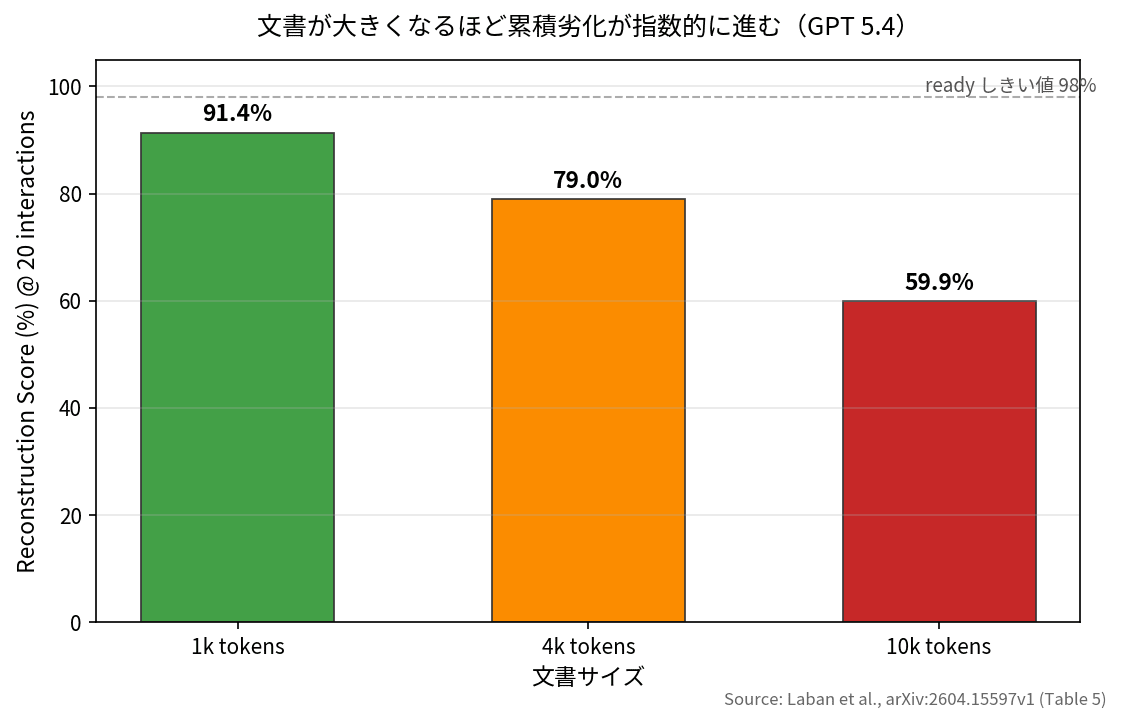
文書サイズが大きくなるほど累積劣化が指数的に進む(出典: Laban et al. 2026, Table 5)
3. ツール使用は改善しない、むしろ悪化
ファイル読み書きとコード実行ツールを与えたエージェント構成にすると、4 モデル平均で simulation 終端時点でさらに 6 ポイント悪化しました。入力トークンが 2.1〜4.6 倍に膨らみ、長文脈処理の弱さが顔を出します。直感的には「Lint ツールで補正できそう」と思いがちですが、論文の文脈ではむしろ追い打ちです。
4. ディストラクタ(無関係文書)の影響
周辺に話題は近いが当該タスクには使わない文書を置くと、最初は 0.4〜4% の影響だったものが 20 ラウンドでは 2〜8% に拡大します。wiki が成長するほど効いてくる性質です。
5. 領域間の極端な格差
52 領域のうち、首位の Gemini 3.1 Pro でも「ready(RS@20 ≥ 98%)」と認められたのは 11 領域だけ。Python はほぼ全モデルで合格圏内(19 モデル中 17 が ready)でしたが、結晶構造、音楽記譜、家系図のような領域はほぼ全モデルで合格に届きませんでした。
6. 削除より「改変」が支配的になる
弱いモデルは内容を消すので人間が気づきやすい。一方、最先端モデルは内容を書き換えてしまうので、git diff を眺めても異常に見えづらい。論文が「sparse but severe(疎だが重大)」と表現しているのはこの感触です。
なぜ LLM 自身は劣化に気づけないのか
ここで一度、論文の数値を LLM の素の仕組みに引き戻して考えてみます。
LLM は本質的には「次の語を確率で予測する」モデルで、文書の意味を理解した上で編集しているわけではありません。受け取ったコンテキストから、もっともらしい続きを確率的に生成しているだけです。これが文書編集と組み合わさると、「らしく見える」改変は通るのに、具体的な数値や固有名詞のような情報量の高いトークンほど確率分布の谷間に落ちて、静かに別物へ置き換わる、ということが起きます。論文が「sparse but severe」と表現する感触は、この仕組みの裏返しとして読み解けそうです。
そして厄介なのは、LLM 自身がこの劣化を見抜きにくいという点です。Lint や自己レビューを LLM に任せても、結局は同じ「確率的に書く」エンジンが「確率的にチェックする」だけで、ground truth と照合する手段を内側に持ちません。論文でツール使用が改善につながらなかった結果も、確率分布の上で動いている事実が変わらない以上、当然と言えば当然のように見えてきます。
「LLM の外側」に再コンパイル可能な raw sources や round-trip のような物差しを置く価値は、まさにここにあるのだと思います。
Karpathy パターンへの含意
ここからが本題です。論文の指摘は Karpathy 氏の LLM Knowledge Base パターンにそのまま跳ね返るのか、それとも構造的にかわせるのか。整理してみます。
直撃する点はいくつかあります。まず Karpathy パターンの Query を filing back する仕組み、つまり質問への回答を wiki に書き戻して育てる挙動は、論文が劣化を測った「複数ラウンド編集」そのものです。「LLM が退屈な保守タスクを引き受ける」という言い回しも、論文視点では「人間が監視していない時間に疎な改変が入る」というやや怖い裏返しの読み方になってしまいます。Lint のようなツール起動型の解決を期待したくなるところですが、論文は「ツール使用で 6 ポイント悪化」とむしろ追い打ちをかけてきます。
一方で留保すべき点もあります。Karpathy の 3 層構造では raw / schema / wiki が分かれていて、raw sources だけは人間がキュレートする領域として不変に保たれます。wiki が腐っても捨てて再コンパイルできる設計なので、catastrophic な損失にはなりにくい構造になっています。Python・インフラ・AI 系といった論文で「ready」とされた領域(19 モデル中 17 が合格)に主題を寄せている wiki であれば、52 領域平均より楽観的に見ても構わない部分もありそうです。それと、著者ら自身が Limitations で各ステップを独立 single-turn で実験している点を認めていて、マルチターン対話で git diff を確認しながら編集する現実のフローには、そのまま当てはまらないかもしれません。
論文を Karpathy 否定の道具として使うのは、公平ではないと思います。一方で、「LLM に保守を任せれば良い」とふんわり構えていた感覚を、論文を読んでしまった以上はそのままにしておけない、というのが正直なところです。
劣化を抑える運用アイデア
論文の数値をそのまま受け止めると、「LLM に保守を任せきり」のままでは厳しそうです。一方で、Karpathy の 3 層構造を活かしながら安全装置を組み合わせれば、ある程度カバーできそうな気もします。実装まで踏み込まずに、考えられる方向性を 3 つほど挙げてみます。
一定ラウンドごとのフルリビルド
N ラウンドごとに wiki 全体を捨てて raw から再コンパイルし直す運用です。20 ラウンドで 25% 壊れるなら、その半分の 10 ラウンドでも数値次第で 10〜15% 程度の劣化は見込まれます。5〜10 ラウンドに 1 回は更地に戻すくらいが安全圏かなと思います。raw sources を不変に保つ 3 層構造の延長として、自然に組み込めるはずです。
filing back のラウンド上限ガード
回答を wiki に書き戻した回数をカウントして、しきい値を超えたら強制的にリビルドを促す仕組みです。LLM に書き戻しを任せきりにすると、気付かないうちにラウンドが伸びて知らない間に閾値を越えていた、ということになりかねません。運用ツール側で見張ってあげる発想ですね。
round-trip 風の回帰チェック
既存の Lint はリンク切れや矛盾検出が中心で、「同じ raw から再コンパイルしたら、いまの wiki と意味的に同じか」までは見ません。論文の round-trip 法をそのまま運用に持ち込むのは大げさですが、たとえば「直近 10 件の Query を抜き打ちで選んで、現 wiki と再生成 wiki の両方から同じ回答が出るか」を確認するくらいなら、現実的に組み込めそうです。
どれも実装してみないと効くか分からないところがあります。それでも、論文の数値があるおかげで「何を測ればいいか」「どの頻度でリビルドすべきか」の手がかりになるのはありがたいです。
まとめ
論文を読み終わって思ったのは、「LLM Knowledge Base は壊れているからやめよう」という結論ではなく、壊れることを前提に、再生可能性と監視を組み込んで使おうという線でした。Karpathy 氏も gist で「intentionally abstract」と書いて決定版の運用フローを押し付けない構えを取っているので、その上に安全装置を継ぎ足していく余地はまだ十分にあります。
20 インタラクションで 25% という数字は、知識作業に持ち込むには確かに重い。一方で、その損失を見える化したベンチマークが世に出てきたこと自体、このパラダイムが真面目に研究対象になりつつあることの裏返しだとも思います。委譲するならそれに見合う安全装置を一緒に育てる。当たり前のようでいて、つい忘れがちな視点を改めて意識させてくれる論文でした。
論文と Karpathy gist のあいだを行ったり来たりしながら、LLM Knowledge Base のような考え方をどう育てていくか。引き続き、考えながら手を動かしていきたいと思います。
参考
- Laban, P., Schnabel, T., Neville, J. (2026). LLMs Corrupt Your Documents When You Delegate. arXiv:2604.15597v1. https://arxiv.org/abs/2604.15597
- Karpathy, A. (2026). LLM Knowledge Bases (gist). https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
- 前編記事: Karpathy 氏が言語化した「LLM Knowledge Base」というパターン









