
LLM Wiki を AWS で動かしてみる
Introduction
Andrej Karpathy 氏が公開した LLM Wiki が話題です。
DevIOでもこれを解説した記事がありますが、こちらもDevIO内においてアクセス数上位の記事となっております。
本記事ではこれらをベースに、実際にどのように LLM Wiki が動作するのかを AWS 上でお試し実装してみました。
実際に構築した記録と検証結果を元に解説していきます。
リポジトリはこちらです。
デプロイ手順はこちらを参照してください。
LLM Wiki?
gistや検索でも解説は出てきますが、本記事でも簡単に触れておきます。
LLM Wiki は、典型的な RAG とは構造が異なる compile-first のアプローチです。
RAG (ベクトル検索、Kendra など) は index や learning-to-rank の形で派生データを蓄積しますが、
蓄積されるのは「検索を賢くするための中間データ」で、質問のたびに raw docs (またはそのチャンク) を
retrieval してモデルに渡す構造です。本稿で比較対象とするシンプルな RAG 実装では、
gist で言うところの
「structured, interlinked collection of markdown files」
(entity pages / concept pages / cross-references を含む整理済み md ファイル群)
が自動で生成・維持されることは通常ありません。
LLM Wiki はそこを逆転させ、ソース投入のタイミングで LLM が永続的な markdown wiki にコンパイルしておき、
質問時はその整理済み wiki を読んで答えます。
RAG は質問ごとに答えを re-derive する構造、LLM Wiki は事前に compile once, then keep current する構造です。
The wiki is a persistent, compounding artifact. The cross-references are already there.
The contradictions have already been flagged. The synthesis already reflects everything you've read.
— Karpathy (gist 原文より直接引用)
LLM が wiki を管理する司書として動き、ソースを更新しながら entity ページや topic ページを作って
相互参照を維持してくれる、というイメージです。
本記事では LLM Wiki gist を参考に、以下の処理を実装してみました。
- Ingest: データソース投入 → LLM が wiki を更新(新規 entity / 既存への追記 / 相互リンク)
- Query: wiki を読んで回答 + 「filing back」で良い Q&A を
queries/に自動保存("explorations compound" の実装) - Lint: 矛盾 / 孤立ページ / リンク切れ / 陳腐化を検出のみ("detect, human decides")
- Repair (独自拡張、検証用): Lint の指摘のうち判断不要な部分 (broken link 修正、backlinks 再生成など) だけを "no new facts" 制約で自動適用。矛盾解消はしない。
Environment
| 項目 | 内容 |
|---|---|
| Bedrock モデル | Claude Sonnet 4.6 |
| 実行基盤 | Fargate (oven/bun:1.3.12 / ARM64 / 1 vCPU, 2 GB) |
| 言語ランタイム | Bun 1.3.12 |
| Agent SDK | @anthropic-ai/claude-agent-sdk(Query は Bedrock Runtime 直叩き) |
※ AWS アカウントは Bedrock / S3 / ECS / ALB / SQS 等に必要な権限が付与済みの前提
アーキテクチャ(Fargate + Bun + SQS + S3 Files)
常駐型 + 非同期Queueの構成としました。
全体構成
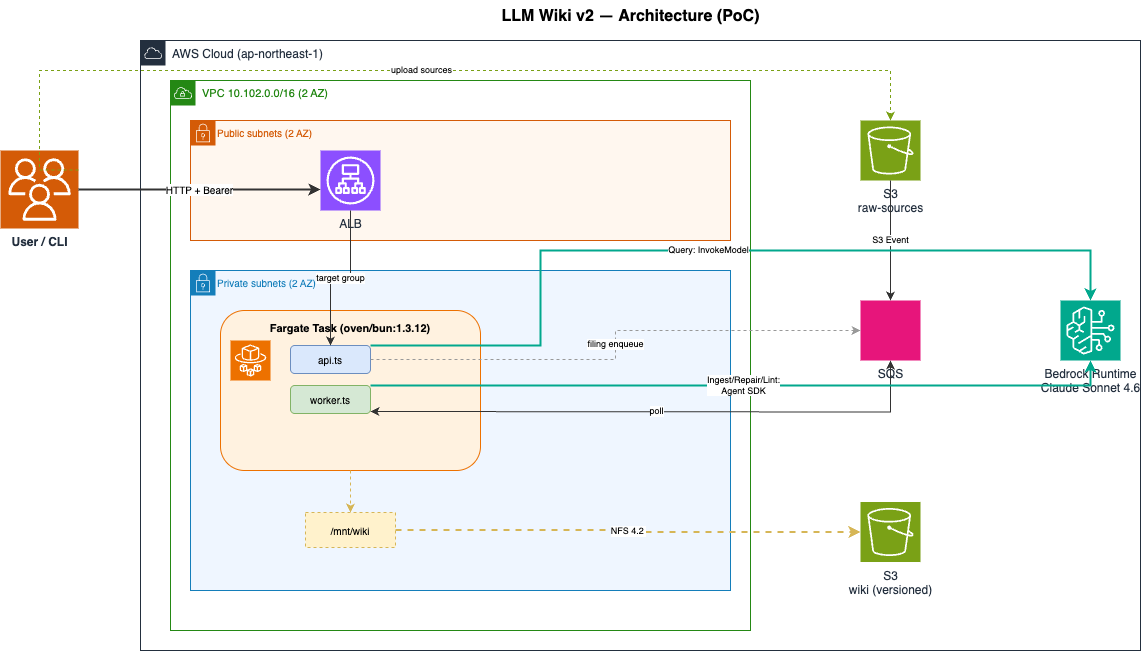
- 1 つの Fargate task に api.ts + worker.ts を同時に実行 (entrypoint.sh で管理)
- S3 → SQS 直結 + custom envelope (
ingest/repair/batch/filing/lint) - S3 Files NFS mount: ALB の 2 AZ 必須要件に合わせて MountTarget をそれぞれ用意
- Query は
@aws-sdk/client-bedrock-runtimeの InvokeModelCommand 実行 (Agent SDK 不使用) - Ingest / Repair / Lint は Agent SDK 使用
- filing back は api → SQS → worker が
queries/<ts>-<slug>.mdを書き込む非同期パス (API レスポンスは即返し、wiki 書き込みは worker に集約して競合を回避)
Query 経路は Bedrock Runtime をそのまま使用
Query (ユーザーからの質問) は Bedrock Runtime の InvokeModelCommand を直接呼びます。
Agent SDK 経由だと毎回 claude_code preset の読み込みでそれなりのトークン消費が発生し、レイテンシが重くなるのを避けるためです。
// src/shared/bedrock-query.ts (抜粋)
const SYSTEM_PROMPT = `You are the LLM Wiki query assistant.
Rules (ABSOLUTE):
- Answer ONLY using the provided retrieved pages (given as JSON array).
- Every factual claim MUST have an inline citation in the form [[page:<page_id>]].
- <page_id> MUST be one of the ids listed in the retrieved array. Do NOT invent page ids.
- If retrieved context is insufficient, reply exactly: INSUFFICIENT_CONTEXT.
- Do NOT add background knowledge beyond the retrieved excerpts.`;
export async function queryBedrock(question, retrieved) {
const res = await client.send(new InvokeModelCommand({
modelId: MODEL_ID,
body: JSON.stringify({
anthropic_version: "bedrock-2023-05-31",
max_tokens: 1024,
system: SYSTEM_PROMPT,
messages: [{ role: "user", content: `Retrieved pages:\n${JSON.stringify(retrieved)}\n\nQuestion: ${question}` }],
}),
}));
// citation validation: invalidCitations と hasValidCitation を返す
}
Ingest / Repair / Lint は multi-turn で wiki を編集するため Agent SDK を使用しています。
SQS envelope を Records[] と type の両方で吸収
S3 event は { Records: [{ eventSource: "aws:s3", ... }] } 形式、
API からの enqueue は
{ type: "ingest" | "repair" | "batch" | "filing" | "lint", ... } 形式。
worker は以下の順で判別して処理を分岐させます。
// src/shared/sqs-envelope.ts (抜粋)
export function classify(raw: string): Job {
const body = JSON.parse(raw);
if (Array.isArray(body.Records) && body.Records[0]?.eventSource === "aws:s3") {
return { kind: "s3", records: body.Records };
}
if (typeof body.type === "string" && KNOWN_TYPES.has(body.type)) {
return { kind: "custom", type: body.type, payload: body };
}
throw new Error(`unclassifiable message: ${raw.slice(0, 200)}`);
}
架空の社内ヘルプデスク:Tickflow
デモ用ドキュメント
LLM Wiki の挙動を検証するため、
架空の社内ヘルプデスク SaaS「Tickflow」の仕様書をベースとした
ドキュメントをAIに作成してもらいました。(題材は全て架空のもの)
用意したのは、実務のドキュメント群によくある以下の5つのカテゴリです。
| カテゴリ | 内容 | 期待する wiki 側の挙動 |
|---|---|---|
| architecture | システム全体構成(1 枚もの) | 複数カテゴリをまたぐハブ的な topic ページになる |
| domain | チケット / 優先度 / SLA / ロール / カテゴリ | 主要な entity ページ群が出る |
| api | tickets / attachments / webhooks | エンドポイントごとの topic が生える |
| ops | エスカレーション / オンコール / インシデント対応 | domain と強く cross-reference する |
| infra | AWS アーキテクチャ / デプロイ手順 | 他カテゴリと独立した topic を作れるか |
相互参照が自然に発生するよう、
意図的にカテゴリ間で重なる概念(priority / SLA / escalation / ticket など)
を記述してあります。
また、「後から事実が変わる」という状況を再現するため、
seed/incremental/2026-Q1-changelog.md を用意しました。
これを最初の ingest の後に追加投入することで、wiki が問題なく更新されるかを確認します。
検証ポイント
| 項目 | 内容 | 検証したいこと |
|---|---|---|
| Alias | 「チケット / 案件 / 問い合わせ / issue」「対応者 / アサイニー / agent」などの同義語 | entity-registry.json に統合されて、日本語 alias での Query が正しく解決できるか |
| Stale | changelog で P1 SLA: 1h → 45min を宣言。sla.md / category.md / escalation.md の更新が取り残される状況を作る |
Lint が「更新漏れ」を stale として検出できるか |
| 意図的な conflict | priority.md「P1 はアサインから 15 分以内 に lead へ通知」 vs escalation.md「P1 は30分以内に agent が未対応で lead にエスカレーション」 |
同じ N 分 + lead の指標だが、別イベントか単純矛盾か文面からは判別困難。Lint が断定せず保留にできるか |
デモ用ドキュメント構成
seed/sources/
├── architecture.md # システム全体構成
├── domain/ # チケット / 優先度 / SLA / ロール / カテゴリ
├── api/ # tickets / attachments / webhooks
├── ops/ # エスカレーション / オンコール / インシデント対応
└── infra/ # AWS アーキテクチャ / デプロイ手順
seed/incremental/
└── 2026-Q1-changelog.md # 後から追加(P1 SLA 短縮 / カテゴリ追加 等)
Raw Resource を一括で ingest
s3 sync でドキュメントを S3 バケットにアップロードします。
これにより、S3 event → SQS → worker で順次処理されます。
aws s3 sync seed/sources/ s3://raw-sources-v2-<ACCOUNT>/sources/
| 指標 | 値 |
|---|---|
| 処理 doc 数 | 14 |
| 合計 duration | 23.7 分 |
| 合計 turns | 241 |
| 平均 per doc | 17 turns / 102 秒 |
実際にアップロードしたところ、↑のような結果になりました。
内訳は以下。
1 turn あたりの時間: 1 doc あたり 17 turns / 102 秒 = 約 6 秒/turn。
- Bedrock Sonnet 4.6 の inference: 2〜4 秒
- Agent SDK のthink + tool 選択オーバーヘッド: ~1 秒
- S3 Files NFS 経由の Read / Write (POSIX I/O): <1 秒
- round-trip + cache read: ~1 秒
1 ファイルを ingest するたびに Agent は
- 対象 source を Read
- 複数の既存 wiki を Read
- 新規 / 既存 entity を更新
entity-registry.json/index.md/backlinks.md/log.md/source-map.jsonを更新
とするため、1 ファイルあたり 17 ターン程度かかっています。
また、後半のファイルほど更新に時間がかかります。
デモ用の raw resource は cross-reference が密なので、後半のファイルほど
既存 wiki の Read 対象が増え、1 ファイルあたりのターン数が伸びます。
(entity-registry.json を毎回フル読みするため entity 数に比例)
gist でも
「wiki が育ってくると index.md 全読みのやり方は限界で、
proper search(qmd 等の BM25 / vector ハイブリッド検索)に切り替える選択肢がある」
と触れられており、本稿で見えている「entity 数に応じて Read 量が増える」特性と同じ見解です。
※ worker を並列化すれば速くなりますが、同一ファイルへの同時書き込みを避けるため本稿では直列にしています。
Query
curl でアクセスしてみました。
curl -X POST http://$ALB/query \
-H "Authorization: Bearer $TOKEN" \
-d '{"question":"Tickflow の P1 SLA は何分以内に初回応答する必要がありますか?"}'
以下のように、wiki を参照した情報がかえってきます。
{
"answer": "Tickflow における P1 チケットの初回応答 SLA は **45分以内** です [[page:sla]][[page:priority]]。
この目標は 2026年1月15日に従来の1時間から45分へ短縮されました。
背景として、2025年Q4の遵守率分析で平均応答時間が38分だったため、目標が引き締められた
とのことです [[page:sla]]。
なお、P1 の SLA カウントは **24/365(暦時間)** で計測されるため、
夜間・休日も含まれます [[page:priority]]。",
"citations": ["sla", "priority", "sla", "priority"],
"invalidCitations": [],
"isInsufficient": false,
"filing": { "state": "enqueued", "slug": "tickflow-p1-sla" },
"usage": { "input_tokens": 2383, "output_tokens": 170 },
"durationMs": 8640
}
いくつか質問を試した結果は以下。
| 質問 | citations | duration | 判定 |
|---|---|---|---|
| Tickflow の P1 SLA は何分以内?(日本語) | sla, priority, sla, priority | 2.9〜8.6s | 複数ページ跨ぎで統合回答 |
| 案件の状態遷移を教えて(alias 経由) | ticket, ticket, ticket | 5.9s | alias 案件 → ticket ページに正しく解決 |
| パリの人口は?(OOS) | — | — | INSUFFICIENT_CONTEXT のみ返し、parametric knowledge を漏らさない |
Q1 の回答に 2026年1月15日に 1 時間 → 45 分 という changelog 由来の情報が出ています。
最初に Read させたドキュメントでは「P1 SLA = 1 時間」でしたが、
その後 changelog を ingest して sla.md が 45 分に更新され、
以後の Query がその値を使うようになりました。
読んだ内容が wiki に反映され、回答に反映されています。
Lint で変化を検出
changelog 投入後に /admin/lint を叩くと、意図通りの検出ができました。
- Stale:
priority.mdが P1=1h のまま取り残されている (changelog 後にsla.mdは 45m に更新済、priority.mdは未更新) - Conflicts:
priority.mdとsla.mdの 1h と 45m の矛盾 - Broken Links: incident 系ページの
P1リンクが誤ってticket.mdを指している (正しくはpriority.md) ― wiki 内ページ名は Ingest 時に Agent が決めるので seed のファイル名とは一致しない - 慎重判定: priority の記述と changelog の記述で違いがある部分に対して「保留」として報告
- Orphan: 8 ページ (attachments-api + topics 群)
Lint の実行コストは 32 turns / 2.6 分でした。
Lint 自体は検出のみで wiki は書き換えません。
運用上は検出結果を人間が確認して wiki を手直しするのが基本です。
wiki の成長タイムライン
処理順に起きたことを並べます。
- 初期 ingest (14 docs, 23.7 分): 19 ページ (entities 13 + topics 6) + alias / index / backlinks が生成
- Q1 を filing: 20 ページに
- changelog を追加 ingest: sla / category / escalation が更新される一方、priority は取り残される
- Lint: 取り残しを stale / conflict として検出
- priority を 45 分に整合: Lint 結果を受けて手直し
- Q2 / Q2b を filing: alias 展開も問題なく動作
raw データを追加するたびに wiki が更新され、以降の Query に反映されます。
(source → wiki → Query の更新ループが回っている状態)
補足: wiki を介さず raw docs を直接プロンプトに渡した場合
14 docs と changelog を 1 つのプロンプトに詰めて、同じ 4 問を投げる構成でも試しました。結果は以下。
- input token は LLM Wiki 側が 4〜8 倍効率的
- Q2 / Q2b / OOS は両方とも正答
- Q1 は raw 側が古い値を返した — 3 ファイル全部プロンプトに入っているのに、LLM が changelog を見落としたようです。LLM Wiki 側は Ingest 時点で
sla.mdを 45 分に更新済みなので、Query は wiki を読むだけで正解が返ります。
事実の最新性を Ingest で確定させておく方が、クエリ時に毎回プロンプトで
「changelog を優先」と書くより安定するようです。
ただし、ここでの比較条件は完全には揃ってないので注意。
raw 側の system prompt には「与えた docs を読んで答えろ」しか書いていない一方、
LLM Wiki 側は Ingest プロンプトで「changelog の影響を該当ページに反映せよ」と明示しています。
差は アーキテクチャ (事前 compile vs クエリ時推論) + プロンプトによるものです。
Summary
gist にある LLM Wiki のパターン (Ingest / Query / Lint) を AWS 上で実装し、
簡単に動作を確認しました。
S3 Files を使うことで LLM が wiki ファイルを POSIX で直接編集でき、
filing back による Q&A 履歴の永続化や、
別セッションの LLM が Lint で wiki をチェックする検証も確認しました。
一方、entity-registry.json や index.md を毎回フル read する方式のため、
entity 数に比例して処理時間とコストが伸び、数百 entity 以上の領域は未検証です。
本稿は gist が想定する moderate scale (〜100 sources) に対して 14 docs (1〜2 割) での実測で、
gist でも「それ以上の規模では hierarchical index / proper search / 検索 script との併用が自然」
と触れている点に注意してください。
本稿で観測した範囲から言えるのは、個人または小規模チームが
限定的な source を整理していく用途には向いている、というところです。
Ingest が 1 doc あたり 1〜2 分かかり、entity-registry.json を毎回フル read する構成なので、
本稿の構造のまま複数人が頻繁に投入する運用に持っていくと、
(1) S3 Files 上で同一ファイルへの同時編集の調停が要る
(2) entity 数に比例して Ingest 時間とコストが伸びる
という 2 点がネックになります。
この 2 点は本稿の観測 (後半ファイルほど turn 数が伸びる / S3 Files で書き込みを直列化している) から
直接出てくる制約なので、手放しで「中規模運用でも OK」とは言い切れません。
ちなみに、S3 Files + Agent SDK + Bedrock Runtime の組み合わせで
「LLM が POSIX ファイルシステムを直接いじる」+「必要に応じて軽量な 1-shot で質問応答」が
AWS 上で素直に書けるようになることは、他にもなにか応用できそうな感じがしました。
References
- Karpathy, "LLM Wiki" (Gist)
- Karpathy の LLM Wiki を解説した DevelopersIO 記事
- Anthropic - Claude Agent SDK
- AWS - S3 Files (NFS access to S3 buckets)
- AWS - ECS Fargate + S3 Files volume
- AWS - Bedrock Inference Profiles
- Anthropic - Prompt Caching on Bedrock
- Bun runtime
Appendix-1:実装時に注意したところ
- S3 bucket は必ず
versioned: true: S3 Files FileSystem は versioning 有効な bucket が必須 - ALB は 2 AZ 必須 → MountTarget も per-AZ で 2 個:
maxAzs: 1で ALB 作ろうとして 1 回目のデプロイが失敗。2 AZ 化に伴い S3 Files MountTarget も両 subnet に作らないと Fargate の再配置で mount できない task が出る - CDK L2 は S3 Files 未対応:
CfnTaskDefinition.addPropertyOverride('Volumes', [...S3FilesVolumeConfiguration])で escape hatch 必須 - retriever の日本語 tokenize は NG: 空白区切りでは日本語の複合語を拾えない → substring match に変更
- Agent SDK の
allowedToolsから Bash 除外: Raw source は外部入力なので prompt injection 耐性のため、Read / Write / Edit / Glob / Grep のみに - source-map.json のフォーマットは Agent の裁量に従う: Agent が
{ sources: [...] }形式で書くのを reader 側で吸収する(配列 / オブジェクト両対応) - Filing dedup は AnswerHash ではなく QuestionHash: 同じ質問の 2 回目は skip、answer 内容が微妙に違っても同じ意図なら重複扱い
Appendix-2: Lambda
本構成に至る前に、まず Lambda + Function URL + EventBridge の最小構成で試作しました。
「LLM Wiki が AWS で動くか」は Lambda でも一通り確認できましたが、
以下の制約を考慮して ECS へ切り替えました。
- Lambda 15 分 timeout: 100+ entities の wiki に incremental ingest する時に timeout が発生
- Function URL
authType=NONE: PoC としてはともかく本番化には IAM か他の認証が必要 - EventBridge → Lambda の中間ホップ: 面倒
reservedConcurrentExecutions=1で直列化: 並列投入してもスループットが上がらない- Query も Agent SDK 経由: トークン効率が悪い
Query 経路を Bedrock Runtime 直叩きに分離したのと、
queue / 常駐 / 認証をそれぞれ SQS / Fargate / ALB + Bearer token で
素直に書ける構成にしたのが本記事で説明してきた現行構成です。












