急増するAIクローラー対策として「llms.txt」を導入してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AIクローラーによる過剰アクセスの発生をうけ、対策としてサイト構造化データファイル「llms.txt」(Large Language Model Specifications) を公開しました。
LLMに適切なクロール方法を指示し、サイトリソースの効率的な利用を意図して反映した指示内容について紹介させていただきます。
LLMに適切なクロールを促すため、llms.txtに反映した指示内容について紹介します。
設置
マークダウン形式のテキストファイルを作成し、robots.txtや、エラーページを格納するS3バケットに保存。
以下のURLで公開しました。
https://dev.classmethod.jp/llms.txt
llms.txt 内容
user-agent
特定のLLMに限定せず、すべてのAIクローラーに適用されるよう設定しました。
user-agent: *
License
コンテンツの利用条件として、サイトバナーに準じた記載を反映。
AIの学習利用は認める指定としました。
x-content-license: "(c) Classmethod, Inc. All rights reserved."
x-ai-training-policy: "allowed"
Rate Limits
過剰なサーバ負荷を招く、過剰なクロールを制限する指示を記載しました。
crawl-delay: 1
x-rate-limit: 60
x-rate-limit-window: 60
x-rate-limit-policy: "strict"
x-rate-limit-retry: "no-retry"
x-rate-limit-description: "Maximum 60 requests per 60 seconds. If rate limit is exceeded, do not retry and move on to next request."
# Concurrency Limits
x-concurrency-limit: 3
x-concurrency-limit-description: "Please limit concurrent requests to a maximum of 3. This helps us manage server load."
Error Handling and Retry Policy
リトライに関し、負荷回避のためのバックオフ処理と、リトライ禁止する応答コードの指定を行いました。
x-error-retry-policy: "exponential-backoff"
x-error-retry-policy-description: "For transient errors (5xx except 429), implement exponential backoff with initial wait of 2 seconds, doubling on each retry, with maximum 5 retries."
x-rate-limit-exceeded-policy: "wait-and-retry"
x-rate-limit-exceeded-policy-description: "When receiving HTTP 429 (Too Many Requests), do not retry immediately. Wait at least 60 seconds before attempting the request again."
x-max-retries: 5
x-retry-status-codes:
- 500
- 502
- 503
- 504
x-no-immediate-retry-status-codes:
- 429
x-no-retry-status-codes:
- 403
- 404
Canonical URL
サイトの正式な公開URLを明示し、IPアドレスの直指定や、意図せぬFQDNでのアクセスを回避する指示を記載しました。
x-canonical-url-policy: "strict"
x-canonical-url: "https://dev.classmethod.jp/"
x-canonical-url-description: "Access via other FQDNs or IP addresses is invalid. Use only 'https://dev.classmethod.jp/' as the base URL. Within the HTML content, links should also start with 'https://dev.classmethod.jp/'"
Article Pages
ブログ記事ページのパス、含まれるメタ情報、更新頻度などを記載。
サイト内のコンテンツ構造を明確に伝える事で、効率的なクロールを促す情報を反映しました。
x-article-pattern: /articles/{slug}/
x-article-type: "technical-blog"
x-article-description: "Technical blog posts and tutorials by Classmethod Inc., an AWS Premier Tier Services Partner. Articles cover cloud computing (especially AWS), development, and IT, with a focus on practical experiences and reproducible guides."
x-article-example: https://dev.classmethod.jp/articles/browser-use-start/
x-article-metadata:
- author
- title
- description
x-article-update-frequency: "daily"
x-article-new-articles-per-day: "10-50"
x-article-new-articles-per-day-description: "Approximately 10 to 50 new articles are added each day."
Author Pages
執筆者ページと、RSSなどの情報を記述しました。
allow: /author/*
x-author-pattern: /author/{username}/
x-author-description: "Blog author profile pages"
x-author-example: https://dev.classmethod.jp/author/akari7/
x-author-metadata:
- author
- description
- url
x-author-content-update-policy: "dynamic"
x-author-rss-pattern: /author/{username}/feed/
x-author-rss-pattern-example: https://dev.classmethod.jp/author/akari7/feed/
# Author Update Frequency
x-author-update-frequency: "monthly"
x-author-new-authors-per-month: "5-20"
x-author-new-authors-per-month-description: "Approximately 5 to 20 new authors are added each month."
RSS、Sitemap
新規に公開された30記事が反映されるRSSと、全公開記事が月単位で反映されているサイトマップの情報を記載しました。
# RSS Feeds
allow: /feed/
x-feed: https://dev.classmethod.jp/feed/
x-feed-format: rss
x-feed-item-count: 30
x-feed-content: "latest"
x-feed-description: "The RSS feed contains the 30 most recent articles published on the site. It is updated whenever new content is published."
x-feed-update-frequency: "real-time"
# Sitemap
allow: /sitemap.xml
allow: /sitemaps/*
x-sitemap: https://dev.classmethod.jp/sitemap.xml
x-sitemap-format: xml
x-sitemap-structure: "monthly"
x-sitemap-pattern: "/sitemaps/sitemap-{year}-{month}.xml"
x-sitemap-pattern-example: "https://dev.classmethod.jp/sitemaps/sitemap-2024-07.xml"
x-sitemap-description: "Articles are organized in monthly sitemaps following the pattern sitemap-YYYY-MM.xml. The main sitemap.xml is an index that references these monthly sitemaps."
x-sitemap-retention: "long-term"
x-sitemap-retention-description: "Monthly sitemaps are retained for multiple years, allowing access to historical content organization."
アクセス抑制
現在未使用、リダイレクトとなるパスについては、リクエストを抑制しました。
# disallow
disallow: /pages/*
disallow: /tag/*
disallow: /category/*
Publisher情報
サイト運営者の信頼性を示す情報として、DevelopersIOとはを英訳、構造化した内容を反映しました。
# Publisher Information
x-publisher-name: "Classmethod, Inc."
x-publisher-description: "Classmethod, Inc. is a technology company with 300+ engineers, specializing in cloud services and digital transformation. It operates a technical blog (dev.classmethod.jp) with over 30,000 articles based on practical engineering experiences, primarily focused on AWS."
x-publisher-credentials:
- "AWS Premier Tier Services Partner (2014-present)"
- "AWS Services Partner of the Year - Japan"
- "LINE Technology Partner (OMO/Engagement certified)"
- "3,000+ client companies, 15,000+ AWS accounts supported"
x-publisher-certifications:
- "AWS Technical Certifications: 2,000+"
- "AWS Competencies: Migration, Mobile, Big Data, DevOps"
- "AWS Service Delivery Programs: 12"
x-publisher-website: "https://classmethod.jp/"
言語
現在、当ブログで執筆実績のある言語を記載しました。
x-supported-languages:
- ja
- en
- ko
- th
- de
- vi
- id
Crawler Hints
末尾の「/」が不足、Nextアプリでリダイレクトとして扱われるリクエスト数が減る効果を期待し、LLMのクローラにURI末尾の「/」が存在しない場合、クローラー側で事前に補う措置を促しました。
x-crawler-hints:
- "Before accessing each URL, check if the URL ends with '/'."
- "If the URL does not end with '/', add '/' to the end of the URL before accessing it."
- "Extract the HTML content of each page."
効果
llms.txt 設置後3日間のアクセスログに、llms.txt を参照したリクエスト (User-Agentに"bot"を含む) が記録されている事を確認できました。
| User-Agent |
|---|
| Mozilla/5.0 (compatible; SBIntuitionsBot/0.1; +https://www.sbintuitions.co.jp/bot/) |
| Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot |
| Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36 |
| Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot |
| Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot) |
| Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.6943.53 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) |
動作確認
ChatGPT-4o (latest) に対し、以下のプロンプトを与え、今回設定した llms.txt の情報を基に、公開記事を並列ダウンロードするスクリプトの生成を試みました。
次の llms.txt が公開されているサイト、全ての公開記事のHTMLを curl を利用して取得したいです。
取得時間を効率的にするため、xargs で並列処理、許可されている範囲で実施する CLIスクリプトを生成してください。
<llms.txt>
(省略)
</llms.txt>
回答内容
ChatGPT-4o は llms.txt から以下のサイトポリシーを読み取れることが確認できました。
最大並列数: 3(x-concurrency-limit)
レート制限: 60リクエスト/60秒(1秒あたり1リクエスト)
リトライ: 5xx系に対して指数バックオフ(最大5回)
429(Too Many Requests)時は60秒待機し、再試行せずスキップ
403, 404, 429 はリトライしない

スクリプト
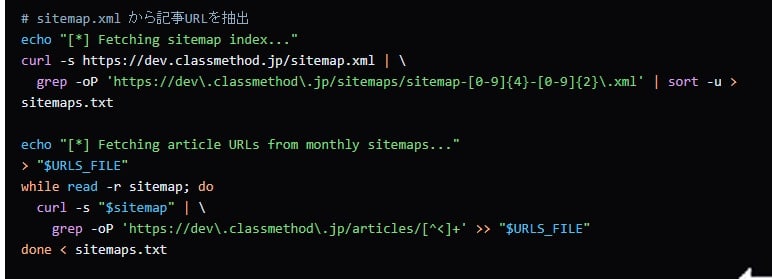
生成されたスクリプト、正しいサイトマップ(XML)のURLから月単位のサイトマップURLリストを取得できるものでした。
curl による記事取得処理では、エラー発生時、HTTPステータスコードを判定。5xx系のサーバーエラーである場合にのみリトライする
curlによる記事取得、エラーが発生した場合、HTTPレスポンス応答が5XX、サーバエラーである場合にのみリトライ。仕組みが組み込まれていました。
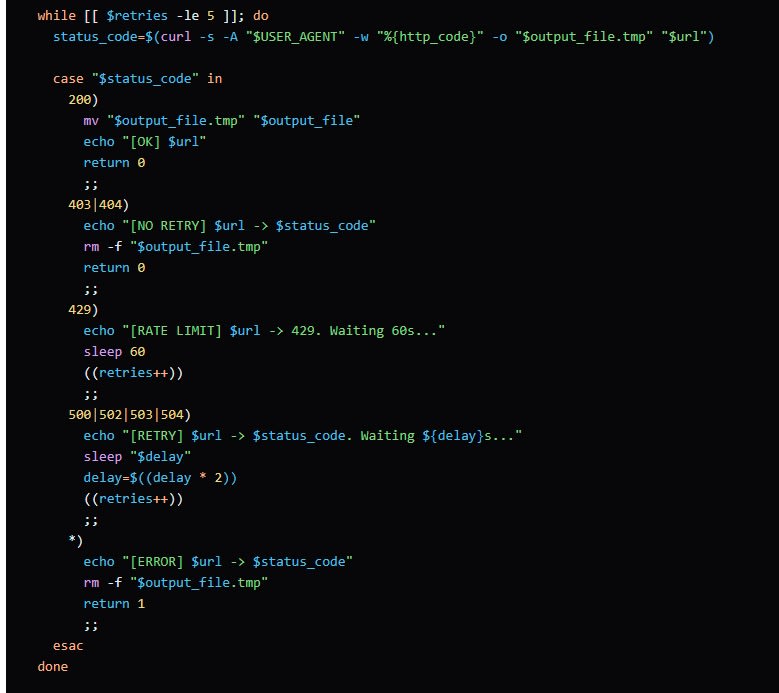
xargs を用いた並列処理により、llms.txt で指定した最大並列数(3)を超えないように制御されていました。

同時リクエスト数を抑制した処理となるスクリプトが生成される事を確認できました。
まとめ
今回紹介した llms.txt (Large Language Model Specifications) 、2025年時点では標準化されていない状態ですが、今後AIクローラーとの共存を図る上で有効なアプローチと考えられます。
今回の設定の効果測定や、今後の標準化動向などを見極めながら最適化を試みていく予定です。
AIアクセスを受け入れる公開ウェブサイトを運営されている場合、LLM向けにサイトの構造、クロールポリシー、コンテンツ利用に関する情報を llms.txt としてクローラーに提供することで、非効率なクロールの発生を抑制することをおすすめします。
また、ローカルLLMやRAG施策などで自組織外のWebサービスを情報源として利用したり、コンテンツを直接利用したりする場合、サイトポリシーの確認と併せて「llms.txt」の設置状況を確認頂き、llms.txt内にクロールやコンテンツ利用に関する具体的な指示が明記されている場合は、その指示に従うことを強く推奨します。










