
MCPサーバーでExcel生成時のデータ改変を防ぐ ― AgentCore/LLMをデータ経路から外す設計
こんにちは、けーま です。
AIエージェントの開発基盤やアーキテクチャ設計に関する案件に取り組んでいて、非常に迷った点について公開しようと思います。この記事では具体的なコードを全部載せるわけではなく、設計としてどういうふうにやっていったかを言語化した内容になります。
1. 背景と要件
今回の案件では、RDSのデータを使ってチャットボットを作る中で、「ユーザーが『Excelファイル作成して』と言ったら、RDSからデータを取得して、あらかじめ用意してあるテンプレートにそのデータを埋め込んでExcelを生成する」というのが要件でした。
その中で一番難しかったのが、RDSのデータをそのままの状態でExcelファイルに書き起こすことです。RDSのデータを一切変えない ― これが今回のポイントでした。RDSのデータを正として顧客に提出するという要件があるので、データの整合性が正しいかどうかをどうチェックするか、というのが工夫したポイントになります。
2. アーキテクチャの検討
案1: AgentCoreのCode InterpreterでExcelを生成する
最初に、AgentCoreのCode Interpreterを使用してExcelファイルを作成しようとしました。
データの流れとしては、AgentCoreからALB経由でECS Fargate上のMCPサーバーにアクセスし、RDSからデータを取得します。そのデータを一度AgentCoreに返して、Code InterpreterでCSV化し、そこからテンプレートに埋め込むという形です。AgentCoreではStrands Agentで実装しています。
ただ、Strands AgentでBedrockのLLMを経由することで、RDSのデータがそのまま保持される保証がありません。また、AgentCoreにRDSのデータを返すためトークンが大きくなってしまうという問題もあり、この設計はやめました。
案2: Code InterpreterからRDSに直接SQLを発行する
次に、もっと整合性を保証するために、Code InterpreterからRDSに直接SQLを発行してテンプレートに埋め込む形を検討しました。
Code Interpreterにこだわった理由は、将来的にいろんなテンプレートや定型的でないSQLにも対応できるよう、柔軟性を持たせたかったからです。
ただ、今回使用していたRDSがOracle RDSだったため、Code InterpreterのプリインストールにOracleのドライバーが含まれていませんでした。ドライバーを入れること自体はできるものの、その管理が大変になるので、こちらの方法も諦めました。
案3(採用): Excel生成専用のMCPサーバーを新たに作る
最終的に、もう1つMCPサーバーを新たに作って、そこに定型的なSQLをいくつか定義し、そのMCPサーバー内でExcelファイルを生成することに決めました。
ユーザーからの質問でファイル作成を検知したら、エージェントがそちらのMCPツールを呼び出してファイルを作成する、という流れです。
テンプレートが決まっているのであれば、MCPサーバーでツールを用意しておくことで決定論的な処理を確実に遂行できる、というのがこの方式の一番のメリットです。加えて、RDSのデータがLLMを経由しないのでトークンが増えすぎる問題が起きないこと、MCPサーバー内でRDSとコネクションプールを張れるので接続のレイテンシーを減らせること、LLMにはPresigned URLだけが返るのでデータの改変リスクがないこと、といった点もあります。
3. 全体構成図
最終的なアーキテクチャはこちらになります。
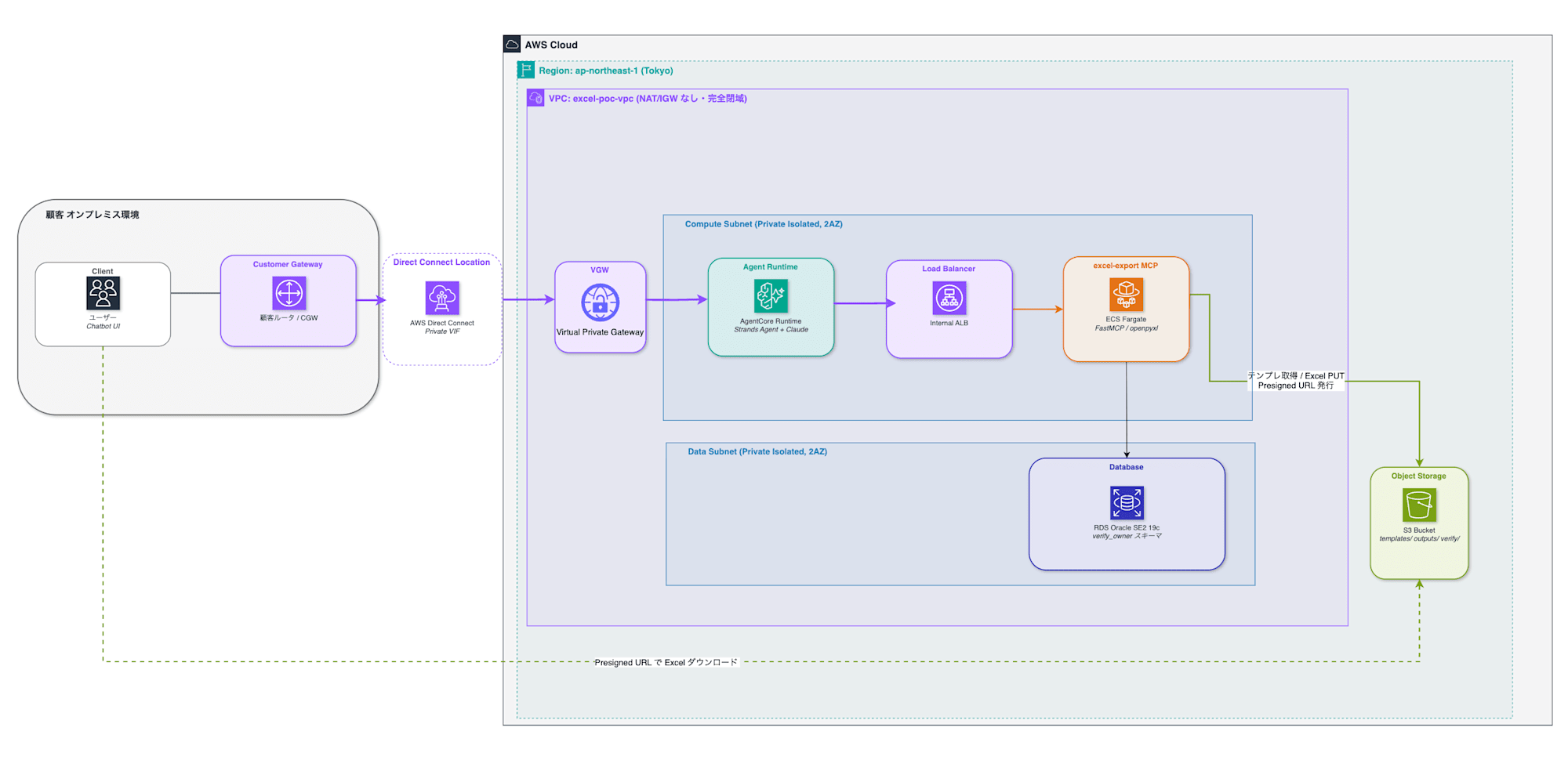
データの流れと責務分担は次の通りです。
- AgentCore Runtime はチャットをするだけでなく、ユーザーからExcelファイルの作成を依頼された際には、MCPサーバーからツールを呼び出します。RDSのデータは一切受け取りません。
- excel-export MCPサーバー(Fargate) がRDSへのSQL発行・Excel生成・ハッシュ検証・S3アップロード・Presigned URL発行までを決定論的に処理します。
- VPCは完全閉域(NAT/IGWなし)で、外部APIアクセスはすべてVPC Endpoint経由です。AgentCore Runtime用のENIもVPC内に配置しています。
AgentCoreからECS Fargate上のMCPサーバーへアクセスし、MCPサーバーがRDSからデータを取得してExcelファイルを生成、S3に格納してPresigned URLを発行します。本来であれば、データ検索用のMCPなど他のMCPもありますが今回は省略しています。
4. Excel生成MCPサーバーの全体像
ディレクトリ構成
Excel生成MCPサーバーのディレクトリ構成はこのようになっています。
mcp-server/
├── main.py # FastMCPエントリーポイント
├── core/
│ ├── db.py # Oracleコネクションプール管理
│ ├── runner.py # テンプレート実行のコアロジック
│ ├── excel_writer.py # openpyxlでのExcel読み書き
│ ├── hash_verify.py # SHA-256によるカラム単位の整合性検証
│ └── s3_publisher.py # S3アップロード & Presigned URL発行
├── tools/ # MCPツール定義
│ ├── product_list.py # 商品一覧Excel生成ツール
│ ├── sales_summary.py # 売上サマリExcel生成ツール
│ └── low_stock.py # 在庫不足Excel生成ツール
├── sql_templates/ # パラメータ付きSQLテンプレート
│ ├── product_list.sql
│ ├── sales_summary.sql
│ └── low_stock.sql
└── column_mappings/ # SQLカラム → Excelカラムの対応定義
├── product_list.yaml
├── sales_summary.yaml
└── low_stock.yaml
SQLテンプレート
sql_templates/ には、WHERE条件などを会話の内容に応じて埋め込めるパラメータ付きSQLが定義されています。
-- sql_templates/product_list.sql
SELECT
PRODUCT_ID, PRODUCT_NAME, CATEGORY, UNIT_PRICE, STOCK_QTY, REGISTERED_AT
FROM verify_owner.PRODUCTS
WHERE 1 = 1
AND (:category IS NULL OR CATEGORY = :category)
AND (:min_price IS NULL OR UNIT_PRICE >= :min_price)
AND (:max_price IS NULL OR UNIT_PRICE <= :max_price)
AND (:name_pattern IS NULL OR PRODUCT_NAME LIKE '%' || :name_pattern || '%')
ORDER BY PRODUCT_ID
:category や :min_price のようにOracleのバインドパラメータ形式で書いていて、ツール呼び出し時に値が注入されます。パラメータが NULL の場合はその条件が無視される設計なので、ユーザーが「カテゴリがCat-1の商品一覧を出して」と言えば category だけに値が入り、残りの条件はスキップされます。
カラムマッピング
column_mappings/ には、SQLのカラムがExcelのどの列に配置されるかをYAMLで定義しています。
# column_mappings/product_list.yaml
template_key: templates/product_list_template.xlsx
sheet_name: ProductList
start_row: 2
column_to_excel_col:
PRODUCT_ID: 1 # → Excel A列
PRODUCT_NAME: 2 # → Excel B列
CATEGORY: 3 # → Excel C列
UNIT_PRICE: 4 # → Excel D列
STOCK_QTY: 5 # → Excel E列
REGISTERED_AT: 6 # → Excel F列
テンプレートごとにシート名や開始行、カラムの対応関係が異なるので、この定義ファイルを差し替えるだけで新しいテンプレートに対応できます。
MCPツールの定義
tools/ には、帳票ごとのMCPツールが定義されています。ユーザーが「カテゴリがCat-1の商品一覧をExcelで出して」と言ったら、LLMが create_product_list_excel ツールを選択し、category="Cat-1" というパラメータを渡して呼び出します。
# tools/product_list.py
def register(mcp: FastMCP) -> None:
@mcp.tool()
def create_product_list_excel(
category: str | None = None,
min_price: float | None = None,
max_price: float | None = None,
name_pattern: str | None = None,
) -> dict[str, Any]:
"""商品一覧のExcelファイルを生成する"""
params: dict[str, Any] = {
"category": category,
"min_price": min_price,
"max_price": max_price,
"name_pattern": name_pattern,
}
return execute_template_tool("product_list", params)
ツールごとに異なるのは受け取るパラメータだけで、その先のSQL実行・Excel生成・ハッシュ検証・S3アップロードは runner.py の execute_template_tool に共通化しています。新しい帳票を追加する場合は、SQLテンプレート・カラムマッピング・ツール定義の3つを追加するだけです。
処理の全体フロー
全体の流れは以下の通りです。
- ツールが呼び出される → SQLテンプレートとカラムマッピングをロード
- SQLを実行 → WHERE条件にパラメータを埋め込んでRDSに問い合わせ、結果を取得
- SQLの結果からハッシュ値を計算 → カラムごとにSHA-256ハッシュを算出して保持
- Excelテンプレートを取得 → S3からテンプレートファイルをダウンロード
- Excelにデータを埋め込む → カラムマッピングに従ってセルに値を書き込む
- Excelから値を読み戻してハッシュ値を再計算 → 書き込んだExcelからセルの値を読み取り、同じくカラムごとにハッシュを算出
- ハッシュ値の比較 → ステップ3とステップ6のハッシュが一致するか検証
- 一致 → S3にアップロードしてPresigned URLを返す / 不一致 → エラー
ここが今回の設計の一番のポイントで、次のセクションで詳しく説明します。
5. ハッシュによるデータ整合性の検証
RDSから取得したデータがExcelに正しく書き込まれたかを保証するために、カラム単位でSHA-256ハッシュを計算して比較する仕組みを入れています。
# core/hash_verify.py
def hash_column(values: list[Any]) -> str:
hasher = hashlib.sha256()
for v in values:
if v is None:
hasher.update(b"\x00<NULL>\x00")
elif isinstance(v, (int, float, Decimal)):
hasher.update(b"\x04")
hasher.update(repr(float(v)).encode("utf-8"))
elif isinstance(v, datetime):
hasher.update(b"\x02")
hasher.update(v.isoformat().encode("utf-8"))
elif isinstance(v, date):
hasher.update(b"\x03")
hasher.update(v.isoformat().encode("utf-8"))
else:
hasher.update(b"\x05")
hasher.update(str(v).encode("utf-8"))
hasher.update(b"\x00")
return hasher.hexdigest()
型ごとにプレフィックスバイトを付けているのは、None と文字列の "None" のような異なる値が同じハッシュにならないようにするためです。
数値の箇所で repr(float(v)) に変換しているのは、openpyxlの挙動に合わせるためです。Oracle RDSから取得した数値は Decimal 型で返ってきますが、openpyxlはExcelに保存・再読み込みすると Decimal を float に変換してしまいます。そのまま比較すると、Decimal("100.50") と float(100.5) で文字列表現が変わってしまいハッシュが不一致になるので、最初から float に揃えてからハッシュを計算しています。
runner.py では、SQL実行直後とExcel書き込み後の2箇所でこのハッシュ計算を呼び出して、一致しているかを検証しています。
# core/runner.py(抜粋)
# --- SQL実行後 ---
sql_hashes = hash_verify.hash_rows_per_column(rows, columns)
# --- Excel書き込み → 読み戻し後 ---
excel_rows = excel_writer.read_back_columns(
workbook, sheet_name, start_row, len(rows), columns, column_to_excel_col,
)
excel_hashes = hash_verify.hash_rows_per_column(excel_rows, columns)
# --- 検証 ---
if sql_hashes != excel_hashes:
raise IntegrityError(
f"Hash mismatch between SQL result and Excel content for template {template_id}"
)
ハッシュが一致しない場合、ユーザーにPresigned URLは返しません。ただし、S3にはExcelを格納するようにしています。これは、失敗した原因を後から確認できるようにログ的な意味で保持しておくためです。
6. 検証結果
在庫不足商品リスト(low_stock)のツールを使って、実際にExcelが正しく生成されるか検証しました。
テンプレート
S3に格納しているテンプレートはこちらです。1行目にタイトル、3行目にヘッダーがあり、4行目以降にデータが埋め込まれる想定です。
RDSのデータ
MCPサーバーが発行したSQLと、その結果は以下の通りです。
SELECT PRODUCT_ID, PRODUCT_NAME, CATEGORY, STOCK_QTY, UNIT_PRICE
FROM verify_owner.PRODUCTS
WHERE STOCK_QTY < 20
AND (NULL IS NULL OR CATEGORY = NULL)
ORDER BY STOCK_QTY ASC, PRODUCT_ID
PRODUCT_ID | PRODUCT_NAME | CATEGORY | STOCK_QTY | UNIT_PRICE
-----------+--------------+------------+-----------+-----------
1 | Widget-A-01 | Category-1 | 0 | 100.0
30 | Widget-J-03 | Category-5 | 1 | 4073.0
59 | Widget-I-06 | Category-4 | 2 | 8046.0
88 | Widget-H-09 | Category-3 | 3 | 2119.0
16 | Widget-F-02 | Category-1 | 4 | 2155.0
45 | Widget-E-05 | Category-5 | 5 | 6128.0
74 | Widget-D-08 | Category-4 | 6 | 201.0
2 | Widget-B-01 | Category-2 | 7 | 237.0
31 | Widget-A-04 | Category-1 | 8 | 4210.0
60 | Widget-J-06 | Category-5 | 9 | 8183.0
89 | Widget-I-09 | Category-4 | 10 | 2256.0
17 | Widget-G-02 | Category-2 | 11 | 2292.0
46 | Widget-F-05 | Category-1 | 12 | 6265.0
75 | Widget-E-08 | Category-5 | 13 | 338.0
3 | Widget-C-01 | Category-3 | 14 | 374.0
32 | Widget-B-04 | Category-2 | 15 | 4347.0
61 | Widget-A-07 | Category-1 | 16 | 8320.0
90 | Widget-J-09 | Category-5 | 17 | 2393.0
18 | Widget-H-02 | Category-3 | 18 | 2429.0
47 | Widget-G-05 | Category-2 | 19 | 6402.0
20件のデータが STOCK_QTY の昇順で取得されています。
生成されたExcel
Presigned URLからダウンロードしたExcelがこちらです。
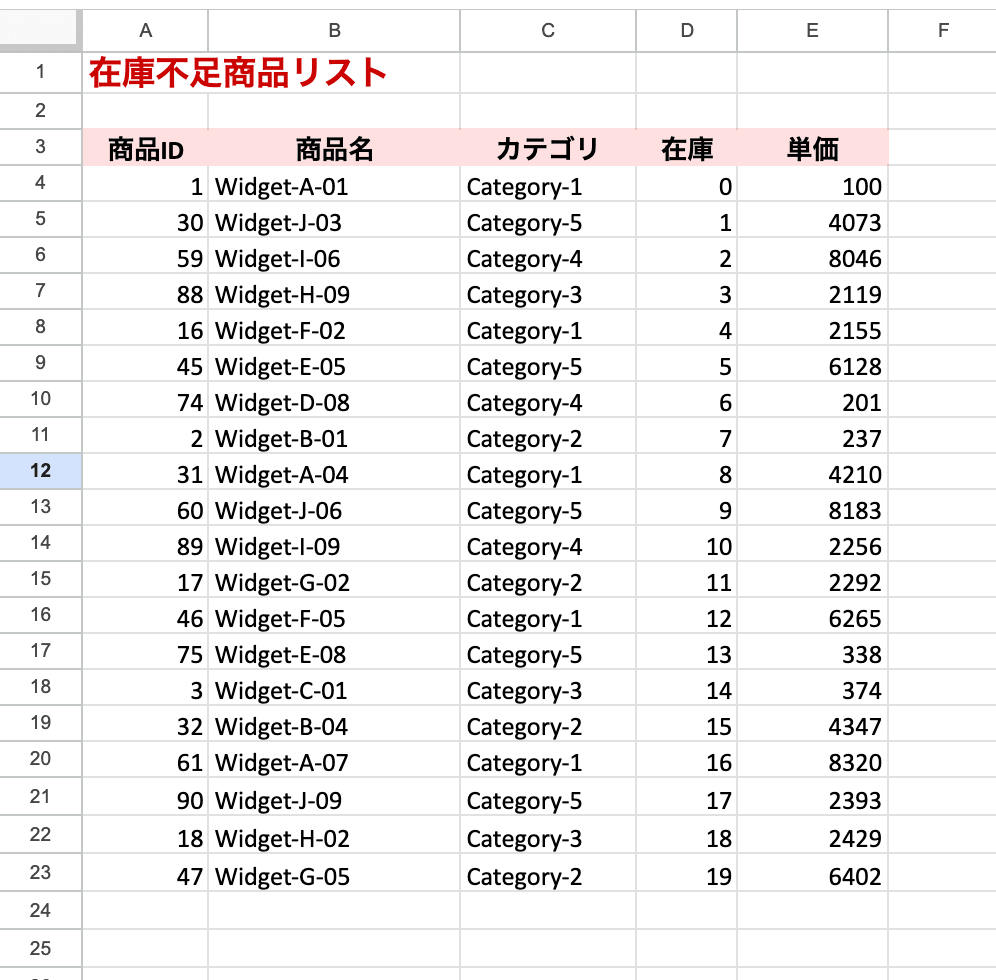
RDSの結果と見比べると、商品ID・商品名・カテゴリ・在庫数・単価のすべてのカラムで値が一致しており、行の順序も同じです。ハッシュ検証もパスしているので、RDSのデータがそのままExcelに反映されていることが確認できました。
7. まとめ
AgentCoreを触っていると、Code Interpreterでファイルを作成したくなりがちで、私はずっとその方向で考えていました。ただ、RDSのデータをそのまま使いたいという要件がある場合、それは決定論的な処理であるべきです。今回のケースでは、LLMを経由させずにMCPサーバー内でSQL実行からExcel生成まで完結させるのが最適でした。
Code Interpreterは柔軟性が高い反面、LLMがデータに介入する余地が生まれます。テンプレートが決まっていてデータの正確性が求められる場面では、MCPサーバーで決定論的に処理する方が確実だったというのが今回の学びです。
8. 今後の課題
今回はMCPツールとしてSELECT文しか定義していないので、運用ルールで事故は防げると思います。ただ、そういった運用ルールがいつ忘れ去られるか分からないので、権限レベルでDELETEやUPDATEなどの更新系を防ぐ仕組みをちゃんと調べて実装していきたいと考えています。
また、Presigned URLはURLを知っていれば誰でもアクセスできてしまうので、以下の対策が必要であると思っています。
- バケットポリシーなどを使ってアクセスできるユーザーを絞る
- URLのTTL(有効期限)を短めに設定して、データが漏洩しないようにする
以上です。ありがとうございました。








