
【アップデート】MIG(マネージドインスタンスグループ)でヘルスチェック失敗時の自動修復を無効にできるようになりました
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
2026年6月26日、Compute Engine のマネージドインスタンスグループ(MIG)でヘルスチェック失敗時の VM 修復(オートヒーリング)を個別に無効化する機能が一般提供(GA)になりました。
MIG はデフォルトで障害 VM を自動修復(再作成)する仕組みを持っていますが、トラブルシューティング中の VM に対して再作成が走ると障害の調査が困難になるケースがあります。今回の GA により、修復全体を無効にするか、オートヒーリングのみを無効にするかをきめ細かく制御できるようになりました。
本記事では、MIG の VM 修復無効化機能の概要と設定手順をご紹介します。
MIG の修復とオートヒーリングの違い
MIG が提供する自動修復には2種類あります。
| 種類 | トリガー | 設定フィールド |
|---|---|---|
| VM 修復(Failed VM repair) | VM が失敗(FAILED)状態になった場合 | defaultActionOnFailure |
| オートヒーリング | アプリケーションヘルスチェックが失敗した場合 | onFailedHealthCheck |
デフォルトでは両方ともREPAIRになっています。今回の機能では、これらを独立して DO_NOTHING(何もしない)に設定できます。
無効化が有効なユースケース
無効化が有効なユースケースとしては、以下のようなことが考えられます。
- トラブルシューティング: 障害 VM を再作成せず、ログやプロセス状態を保ったまま調査したい場合
- 独自修復ロジック: MIG の自動修復を使わず、外部システムで修復を制御したい場合
- ヘルスモニタリングのみ: ヘルスチェックを監視目的で使い、異常時の再作成は行いたくない場合
制限事項
以下の設定をしている MIG では VM 修復の無効化(defaultActionOnFailure: DO_NOTHING)は使用することはできません
- オートスケーラーが設定されている MIG
- サスペンドまたは停止中の VM を含む MIG
実際に試してみる
前提条件
compute.instanceGroupManagers.update権限が付与されていること(roles/compute.adminなど)- Google Cloud CLI(gcloud)がインストール・設定済みであること
事前準備: リソースの作成
今回の検証で使用するリソースを作成します。最初に使用するゾーンを変数にセットしておきます。
export ZONE=asia-northeast1-b
1. インスタンステンプレートの作成
ヘルスチェックのプローブを受け入れるためのネットワークタグ(allow-health-check)を付与します。また、スタートアップスクリプトで Apache HTTP サーバーを起動することで、インスタンスが HEALTHY 状態に到達できるようにします。
gcloud compute instance-templates create mig-repair-test-template \
--machine-type=e2-micro \
--image-family=debian-12 \
--image-project=debian-cloud \
--tags=allow-health-check \
--metadata=startup-script='#! /bin/bash
apt-get update
apt-get install -y apache2
systemctl start apache2'
Created [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/global/instanceTemplates/mig-repair-test-template].
NAME: mig-repair-test-template
MACHINE_TYPE: e2-micro
PREEMPTIBLE:
CREATION_TIMESTAMP: 2026-06-29T22:35:42.270-07:00
2. HTTP ヘルスチェックの作成
gcloud compute health-checks create http mig-repair-test-hc \
--port=80 \
--request-path=/ \
--check-interval=10s \
--unhealthy-threshold=3 \
--global
Created [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/global/healthChecks/mig-repair-test-hc].
NAME: mig-repair-test-hc
PROTOCOL: HTTP
3. ファイアウォールルールの作成
ヘルスチェックのプローブは Google のシステム(35.191.0.0/16、130.211.0.0/22)から送信されます。ファイアウォールルールを作成してプローブがインスタンスに到達できるようにします。
gcloud compute firewall-rules create fw-allow-health-check \
--network=default \
--action=allow \
--direction=ingress \
--source-ranges=130.211.0.0/22,35.191.0.0/16 \
--target-tags=allow-health-check \
--rules=tcp:80
Creating firewall...working..Created [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/global/firewalls/fw-allow-health-check].
Creating firewall...done.
NAME: fw-allow-health-check
NETWORK: default
DIRECTION: INGRESS
PRIORITY: 1000
ALLOW: tcp:80
DENY:
DISABLED: False
4. MIG の作成(ヘルスチェック付き)
ヘルスチェックを設定した状態で MIG を作成します。--initial-delay は VM 起動後にヘルスチェックを開始するまでの猶予時間(秒)です。Apache のインストールと起動に時間がかかるため、180 秒に設定します。
gcloud compute instance-groups managed create mig-repair-test \
--template=mig-repair-test-template \
--size=1 \
--health-check=mig-repair-test-hc \
--initial-delay=180 \
--zone=${ZONE}
Created [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/zones/asia-northeast1-b/instanceGroupManagers/mig-repair-test].
NAME: mig-repair-test
LOCATION: asia-northeast1-b
SCOPE: zone
BASE_INSTANCE_NAME: mig-repair-test
SIZE: 0
TARGET_SIZE: 1
INSTANCE_TEMPLATE: mig-repair-test-template
AUTOSCALED: no
MIG一覧
ステップ1: ヘルスチェックの失敗とオートヒーリングの挙動を確認する
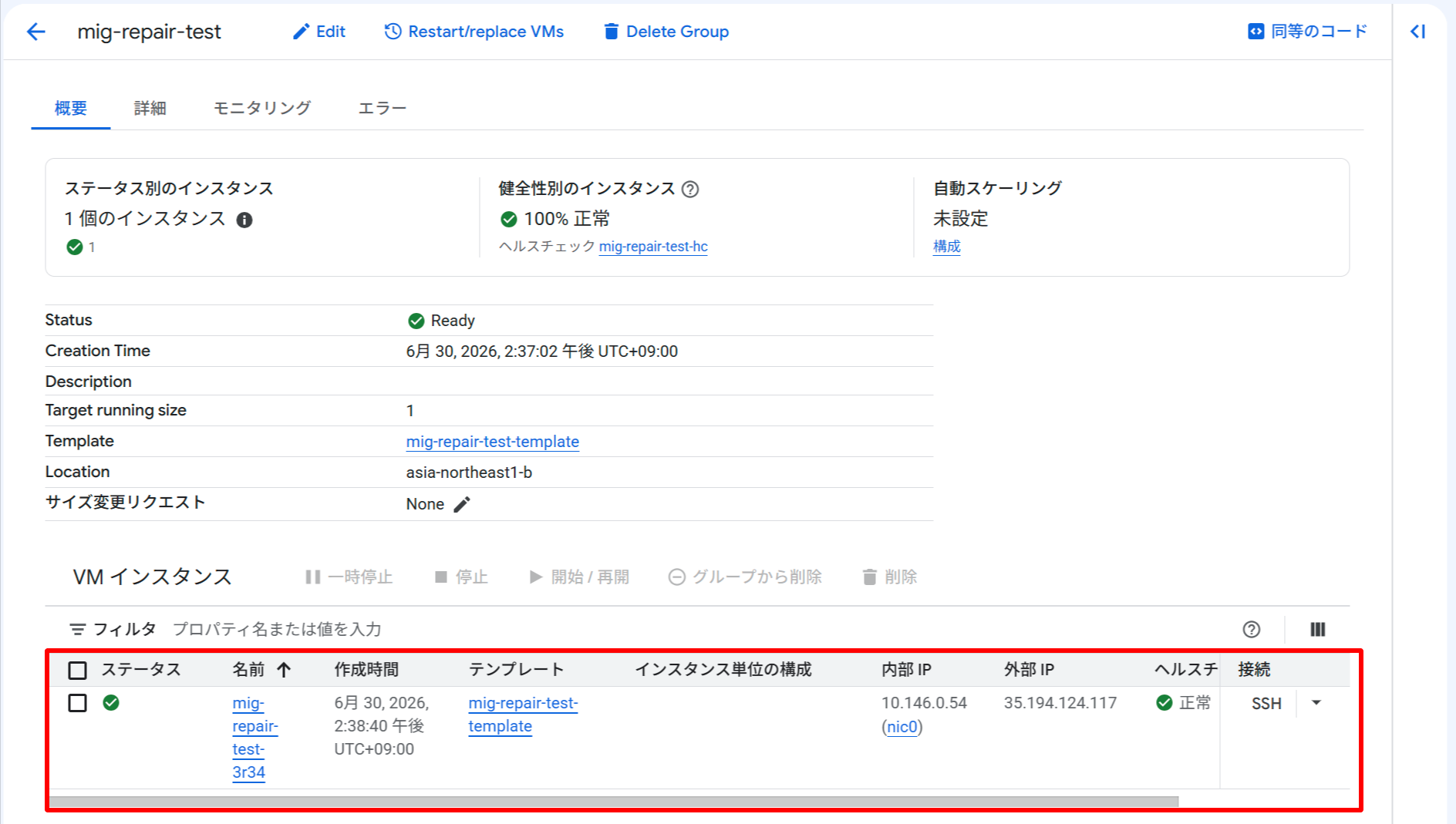
MIG 作成後、Apache が起動すると HEALTH_STATE: HEALTHY になります。まず HEALTHY 状態になったことを確認します。
gcloud compute instance-groups managed list-instances mig-repair-test \
--zone=${ZONE}
NAME: mig-repair-test-3r34
ZONE: asia-northeast1-b
STATUS: RUNNING
HEALTH_STATE: HEALTHY
ACTION: NONE
INSTANCE_TEMPLATE: mig-repair-test-template
VERSION_NAME:
LAST_ERROR:
コンソールでは「健全性別のインスタンス」が 100% 正常 と表示されます。
HEALTHY状態
HEALTHY を確認したら、ファイアウォールルールを削除してヘルスチェックを意図的に失敗させます。
gcloud compute firewall-rules delete fw-allow-health-check
The following firewalls will be deleted:
- [fw-allow-health-check]
Do you want to continue (Y/n)? Y
Deleted [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/global/firewalls/fw-allow-health-check].
ファイアウォール削除後、check-interval=10s × unhealthy-threshold=3 で約 30 秒後に HEALTH_STATE: TIMEOUT に変化します。TIMEOUT は「ヘルスチェックのエンドポイントに到達できない状態」であり、UNHEALTHY と同様にオートヒーリングのトリガーになります。
gcloud compute instance-groups managed list-instances mig-repair-test \
--zone=${ZONE}
NAME: mig-repair-test-3r34
ZONE: asia-northeast1-b
STATUS: RUNNING
HEALTH_STATE: TIMEOUT
ACTION: RECREATING
INSTANCE_TEMPLATE: mig-repair-test-template
VERSION_NAME:
LAST_ERROR:
gcloud compute instance-groups managed list-instances mig-repair-test \
--zone=${ZONE}
NAME: mig-repair-test-3r34
ZONE: asia-northeast1-b
STATUS: TERMINATED
HEALTH_STATE: UNKNOWN
ACTION: RECREATING
INSTANCE_TEMPLATE: mig-repair-test-template
VERSION_NAME:
LAST_ERROR:
また、describe コマンドで現在の instanceLifecyclePolicy 設定も確認しておきます。
gcloud compute instance-groups managed describe mig-repair-test \
--zone=${ZONE} \
--format="yaml(instanceLifecyclePolicy)"
instanceLifecyclePolicy:
defaultActionOnFailure: REPAIR
forceUpdateOnRepair: NO
onFailedHealthCheck: DEFAULT_ACTION
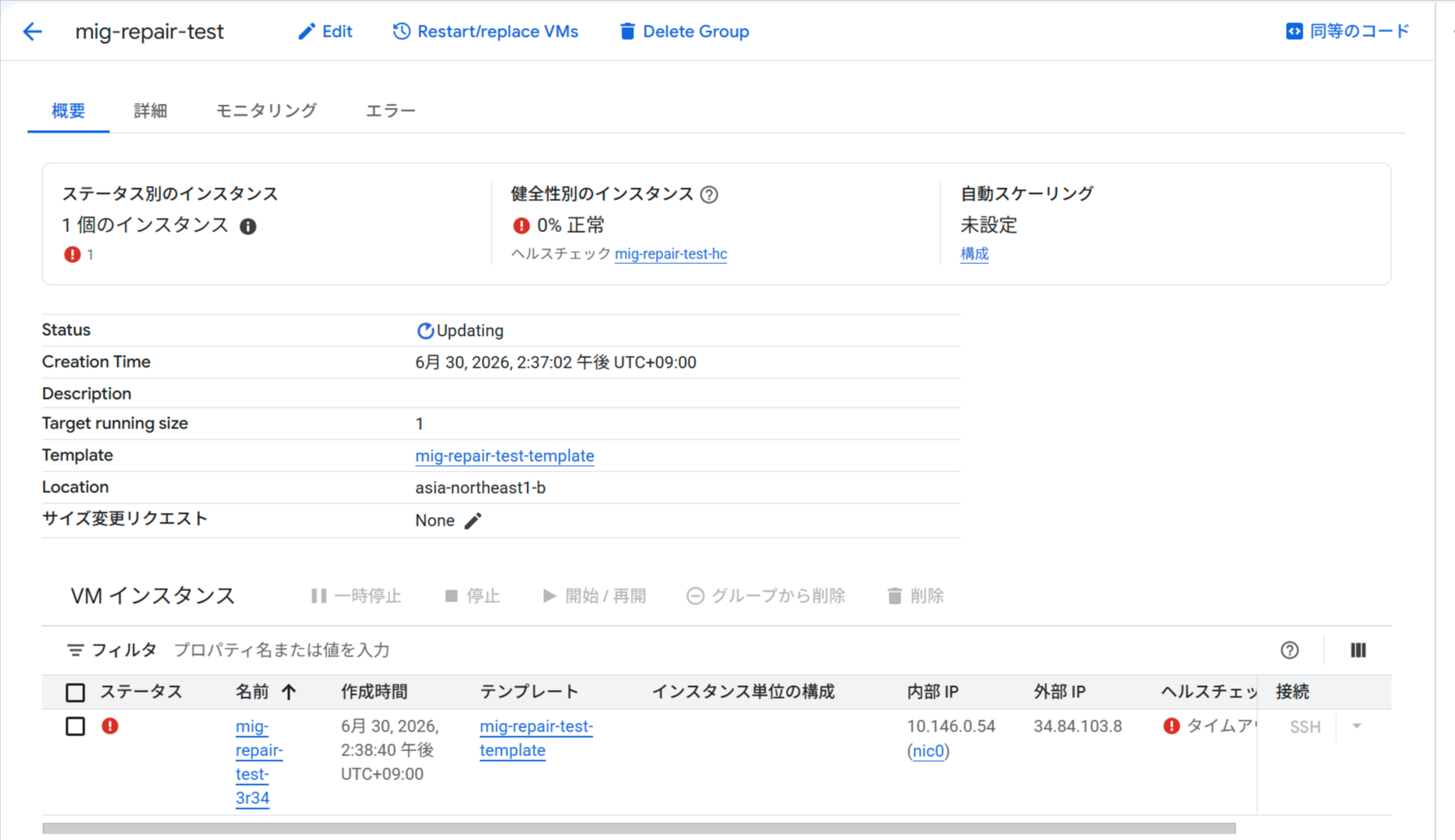
コンソールでも状態の変化を確認できます。ファイアウォールを削除してヘルスチェックが失敗し始めると、MIG の Status が Updating になり、「健全性別のインスタンス」が 0% 正常 に変わります。これはデフォルトのオートヒーリング(REPAIR)が動作して MIG がインスタンスの修復(再作成)を試みていることを示しています。
ステップ2: VM 修復とオートヒーリングを両方無効にする
まずファイアウォールルールを復元します。
gcloud compute firewall-rules create fw-allow-health-check \
--network=default \
--action=allow \
--direction=ingress \
--source-ranges=130.211.0.0/22,35.191.0.0/16 \
--target-tags=allow-health-check \
--rules=tcp:80
Creating firewall...working..Created [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/global/firewalls/fw-allow-health-check].
Creating firewall...done.
NAME: fw-allow-health-check
NETWORK: default
DIRECTION: INGRESS
PRIORITY: 1000
ALLOW: tcp:80
DENY:
DISABLED: False
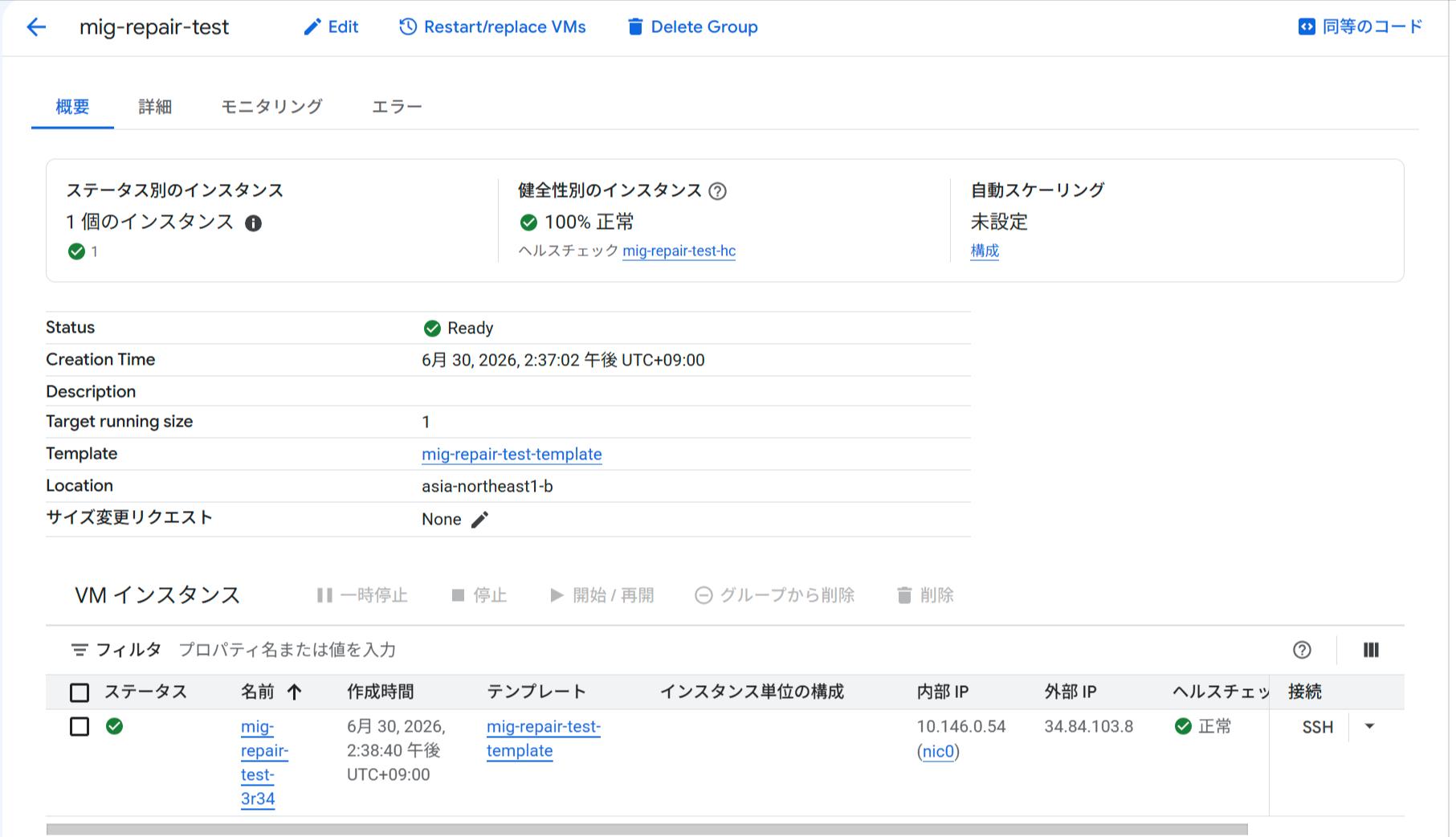
インスタンスが再度 HEALTHY 状態になりました。
gcloud compute instance-groups managed list-instances mig-repair-test \
--zone=${ZONE}
NAME: mig-repair-test-3r34
ZONE: asia-northeast1-b
STATUS: RUNNING
HEALTH_STATE: HEALTHY
ACTION: NONE
INSTANCE_TEMPLATE: mig-repair-test-template
VERSION_NAME:
LAST_ERROR:
コンソールで「100% 正常」に戻ったことを確認します。インスタンス名(mig-repair-test-3r34)と作成時間(2:38:40)はステップ1から変わっていません。
HEALTHY を確認したら、修復を無効化します。ヘルスチェック失敗時も含め、すべての自動修復を無効にします。
gcloud compute instance-groups managed update mig-repair-test \
--default-action-on-vm-failure=do-nothing \
--zone=${ZONE}
Updated [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/zones/asia-northeast1-b/instanceGroupManagers/mig-repair-test].
リージョン MIG の場合は --zone の代わりに --region=REGION を使用します。
設定を確認します。
gcloud compute instance-groups managed describe mig-repair-test \
--zone=${ZONE} \
--format="yaml(instanceLifecyclePolicy)"
instanceLifecyclePolicy:
defaultActionOnFailure: DO_NOTHING
forceUpdateOnRepair: NO
onFailedHealthCheck: DEFAULT_ACTION
再度ファイアウォールルールを削除して TIMEOUT を発生させます。
gcloud compute firewall-rules delete fw-allow-health-check
The following firewalls will be deleted:
- [fw-allow-health-check]
Do you want to continue (Y/n)? Y
Deleted [https://www.googleapis.com/compute/v1/projects/YOUR_PROJECT_ID/global/firewalls/fw-allow-health-check].
ステップ3: 無効化後の挙動を確認する
DO_NOTHING に設定した後、再度インスタンスの状態を確認します。HEALTH_STATE が TIMEOUT のままでも ACTION が NONE になっていれば、ヘルスチェックが失敗していても MIG がインスタンスを再作成しなくなったことが確認できます。
gcloud compute instance-groups managed list-instances mig-repair-test \
--zone=${ZONE}
NAME: mig-repair-test-3r34
ZONE: asia-northeast1-b
STATUS: RUNNING
HEALTH_STATE: TIMEOUT
ACTION: NONE
INSTANCE_TEMPLATE: mig-repair-test-template
VERSION_NAME:
LAST_ERROR:
コンソールでもデフォルト動作との違いがわかります。ステップ1では TIMEOUT になると Status が Updating に変わりましたが、DO_NOTHING 設定後は Ready のままです。また、インスタンス名(mig-repair-test-3r34)と作成時間(2:38:40)がステップ1から一切変わっていないことから、インスタンスが再作成されていないことが確認できます。VM ステータスのアイコンは緑(RUNNING)のままで、ヘルスチェックのアイコンのみエラー表示になっている点も注目です。
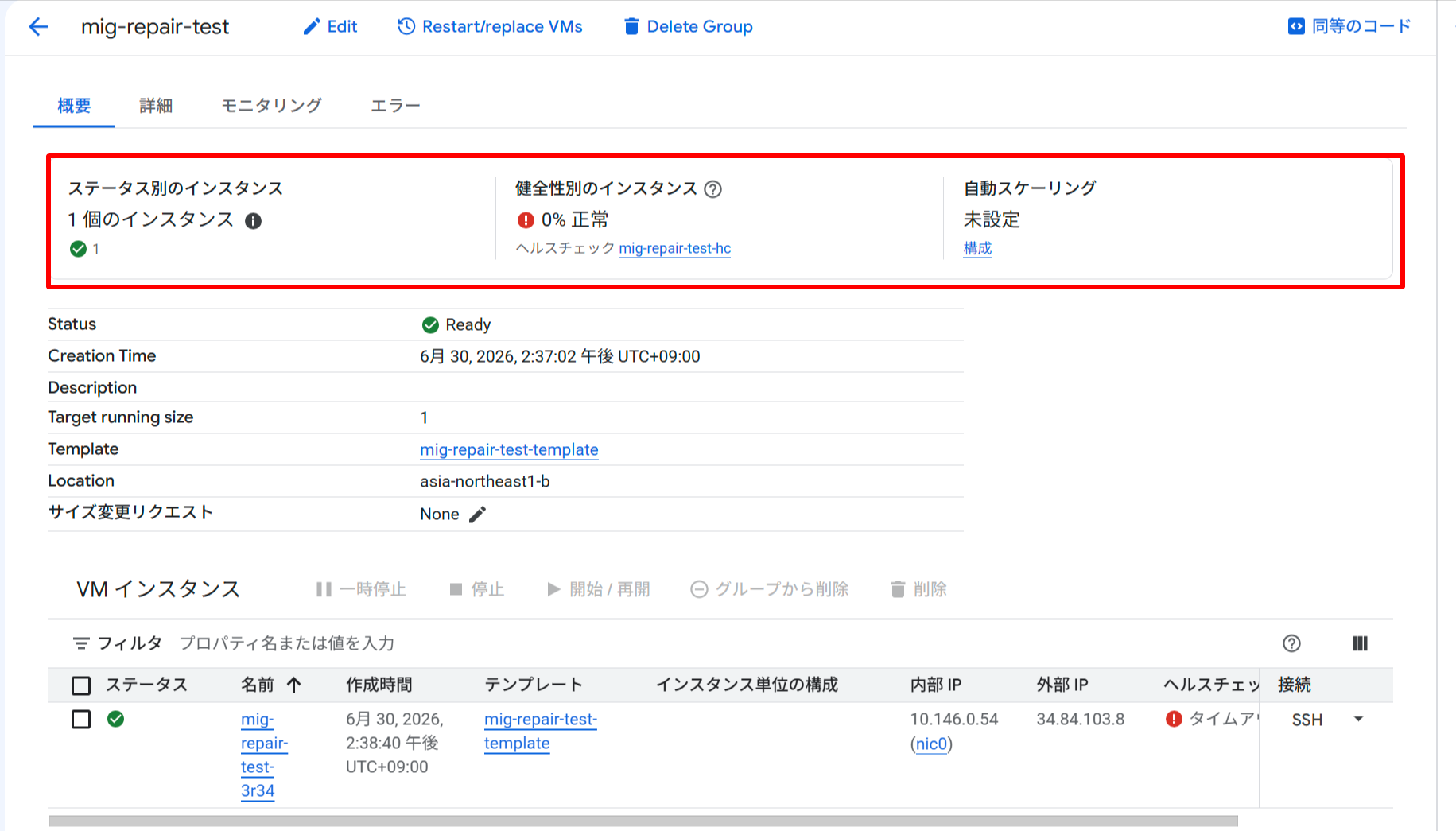
まとめ
今回の GA により、MIG における VM 修復とオートヒーリングを独立して制御できるようになりました。これにより、本番環境のトラブルシューティング中に MIG が自動的に VM を再作成してしまう問題を防ぎ、障害調査に必要な時間を確保できます。
この機能は、独自の監視・修復基盤を持つチームや、VM の状態をステートフルに管理したいユースケースでも活用できます。ヘルスチェックを「監視」として使いながら、修復処理は別のオーケストレーターで行うといった構成も実現しやすくなります。
なお、オートスケーラーが設定されている MIG では DO_NOTHING が使用できない点に注意が必要です。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!








