![[2025年1月8日号]個人的に気になったModern Data Stack情報まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4c47f61cc8c1b97c00c0efcc68eab01b/ebc4f0c0223a249eae2f9de257dedbcd/eyecatch_moderndatastack_1200_630.jpg?w=3840&fm=webp)
[2025年1月8日号]個人的に気になったModern Data Stack情報まとめ
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
Modern Data Stack関連のコンサルタントをしている私ですが、Modern Data Stack界隈は日々多くの情報が発信されております。
そんな多くの情報が発信されている中、この3週間ほどの間で私が気になったModern Data Stack関連の情報を本記事でまとめてみます。
※注意事項:記述している製品のすべての最新情報を網羅しているわけではありません。私の独断と偏見で気になった情報のみ記載しております。
Modern Data Stack全般
The Future of Data Engineering: DEW's 2025 Predictions
Data Engineering Weeklyにて、2025年のデータエンジニアリングの動向を予測する記事が出ていました。
主に以下の内容について言及しています。昨今のAI開発の激化がどのようにデータエンジニアリングに影響を与えるのか、広い視点で書かれてあり参考になります。
- 各社が開発するAIチップ市場の激化やNeuromorphic chipsなどの新しいチップの技術革新による、コンピューティングの進化
- ドメイン固有のLLMや、固有のデータセットに併せて微調整されてコスト効率に優れたSmall Language Model(SLM)の台頭
- AI agentの導入に伴い、AI orchestratorsが登場してくる(タスクを最適なAI agentに振り分け、その出力を統合して洞察を得るようなイメージ)
- lakebyte.aiのような、データエンジニアのための新しいIDEの登場
- LakeDBの登場(LakeHouseを進化させたもので、より堅牢なデータベースのような機能がデータレイクに直接もたらされ、「オブジェクトストレージの拡張性と柔軟性」と「従来のデータベースのパフォーマンスと使いやすさ」と組み合わされていくイメージ)
- 記事中では、書き込み操作に外部エンジンを使用しない、バッファリングとキャッシング、トランザクション管理、自動のデータ圧縮などの最適化、ベクトル検索のサポート、などの機能を記載
- Zero ETLやフェデレーテッドアーキテクチャの採用で社内のデータのやり取りが容易になってくることで、データメッシュアーキテクチャやData Contractsの採用も必要になってくる
Strategic Priorities for Data and AI Leaders in 2025
Databricks社のブログより、「Strategic Priorities for Data and AI Leaders in 2025」というタイトルで2025年にデータとAIのリーダーが何を優先していくべきかをまとめた記事が出ていました。
AIエージェントの話や、AI活用のためのデータのインフラやガバナンス周りについて言及があります。
Data Extract/Load
dlt
2024年のdltの活動・アップデートに関するまとめ記事
dltHub社の公式ブログより、2024年のdltの活動・アップデートに関するまとめ記事が出ていました。
2024年はdltのv1.0がリリースされたり、Dagsterとの連携などの実際の活用に関する記事も多く投稿されたり、dltが活発だった1年であったことがわかります。
Data Warehouse/Data Lakehouse
Snowflake
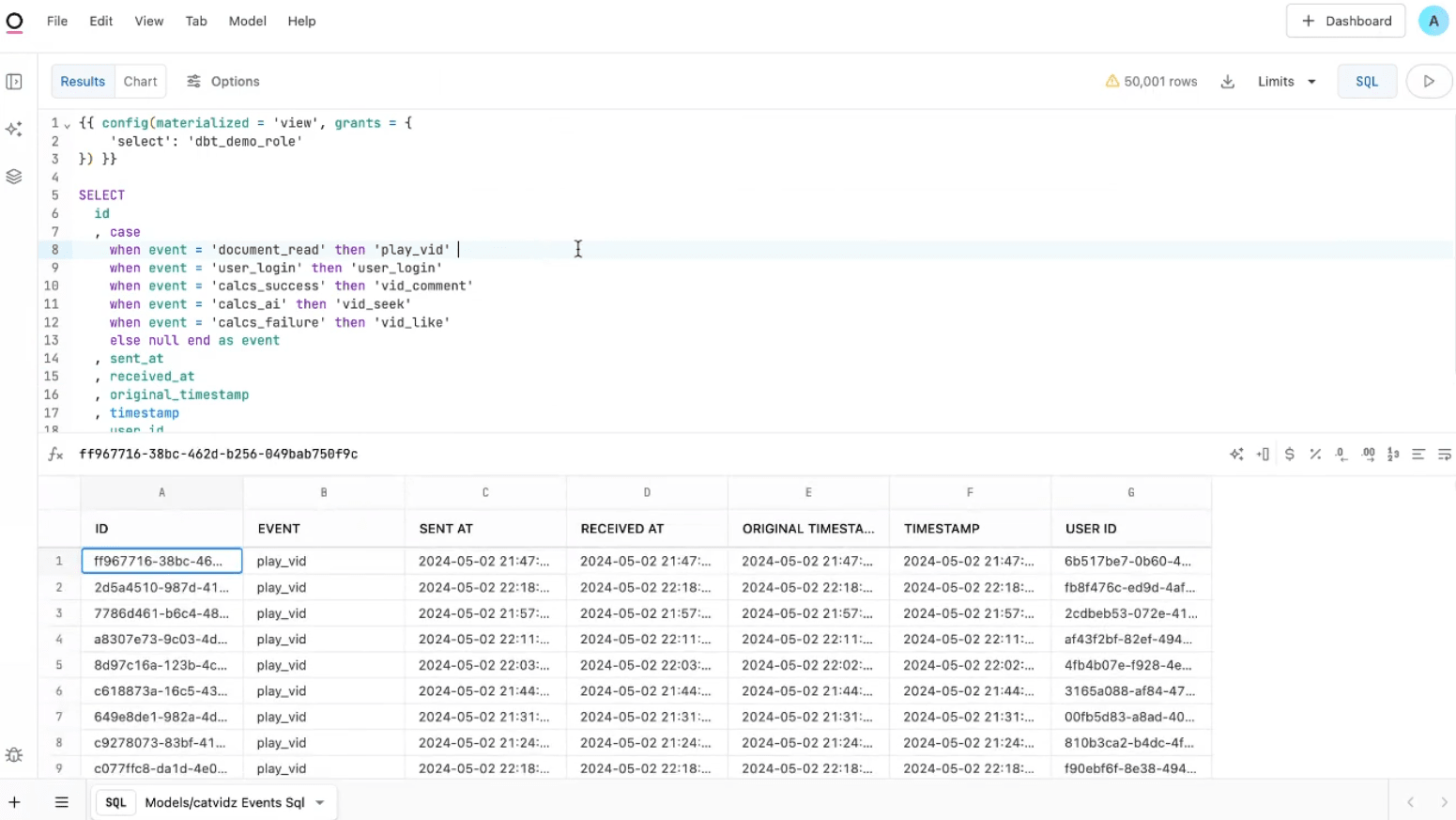
cortex.complete関数の結果を異なるLLMのモデル同士で比較できるCortex Playgroundがパブリックプレビュー
cortex.complete関数の結果を、異なるLLMのモデル同士で比較できるCortex Playgroundがパブリックプレビューになりました。
下図は私がSnowflakeのサンプルデータでざっと試してみた例です。
キーペアの作製・紐づけの自動化に関する記事
Mediumで、キーペアの作製・紐づけの自動化を行った記事が出ていました。
関連するコードは下記のリポジトリに保存されています。このリポジトリのbaseフォルダではSnowflake CLIとSnowpark Pythonを用いた開発環境のコンテナを立ち上げるための各ファイルもまとめられています。
Databricks
Databricks Assistantが出来ることのまとめ記事
Databricks社のブログより、Databricks AssistantというDatabricksのAIアシスタント機能について現在何が出来るのかをまとめた記事が出ていました。
以下の機能について言及があります。
- エディターでのオートコンプリート
- コードエラーの診断と修正内容の提案
- ジョブのエラーの診断
- 自然言語によるダッシュボードの作製
- すべてのデータ処理がDatabricksアカウント内に留まるようにセキュリティ強化
- Catalog Explorerでのメタデータに基づいた自然言語での問い合わせ
- 非効率なSQLの改善
Data Transform
dbt
dbt microbatchがもたらす変化と実装のベストプラクティス
pei0804さんにより、dbt-core v1.9で追加されたIncremental Modelのmicrobatch strategyについて詳しく検証された記事が出ていました。
従来のIncremental Modelと比較して、microbatch strategyだと実装方法と処理内容がどう変わるかなど詳しくまとめられており、とても参考になります。(ありがとうございます!!)
Dataform
DataplexでDataformリポジトリを管理できるようになりました
DataplexでDataformリポジトリを管理できるようになり、メタデータもDataplexで使用できるようになりました。
ドキュメントによると、下記のメタデータを自動でリポジトリから収集できるようです。
- Data asset name
- Data asset parent
- Data asset location
- Data asset type
- Corresponding Google Cloud project
- Third-party repository source
- Service account
Business Intelligence
Omni
IDE上でdbtのリポジトリを表示し、Modelの編集・プレビュー実行ができるように
OmniのIDE上でdbtのリポジトリの内容を表示し、編集・実行ができる機能が発表されました。
どういったUIとなっているかは、下記のリンク先が参考になります。元々OmniはdbtのModelとしてプッシュできる機能がありましたが、その機能を用いてリモートリポジトリへプッシュも可能のようです。