![[2025年4月30日号]個人的に気になったModern Data Stack情報まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4c47f61cc8c1b97c00c0efcc68eab01b/ebc4f0c0223a249eae2f9de257dedbcd/eyecatch_moderndatastack_1200_630.jpg?w=3840&fm=webp)
[2025年4月30日号]個人的に気になったModern Data Stack情報まとめ
さがらです。
Modern Data Stack関連のコンサルタントをしている私ですが、Modern Data Stack界隈は日々多くの情報が発信されております。
そんな多くの情報が発信されている中、この2週間ほどの間で私が気になったModern Data Stack関連の情報を本記事でまとめてみます。
※注意事項:記述している製品のすべての最新情報を網羅しているわけではありません。私の独断と偏見で気になった情報のみ記載しております。
Modern Data Stack全般
GitHubリポジトリのWikiを自動生成してくれる「DeepWiki」
Devinを開発しているCognition社から、GitHubリポジトリのURLのドメイン部分をdeepwikiに変えるだけでそのリポジトリのWikiを生成してくれる「DeepWiki」が発表されました。
@satoshihiroseさんがXで共有していた内容を私も見たのですが、、Modern Data Stack関係でいうと、例えば以下はdbt Labs社のサンプルリポジトリであるjaffle-shopのリポジトリに対してDeepWikiで生成したものですが、データフロー図やER図なども自動で生成してくれます。これはすごいですね…
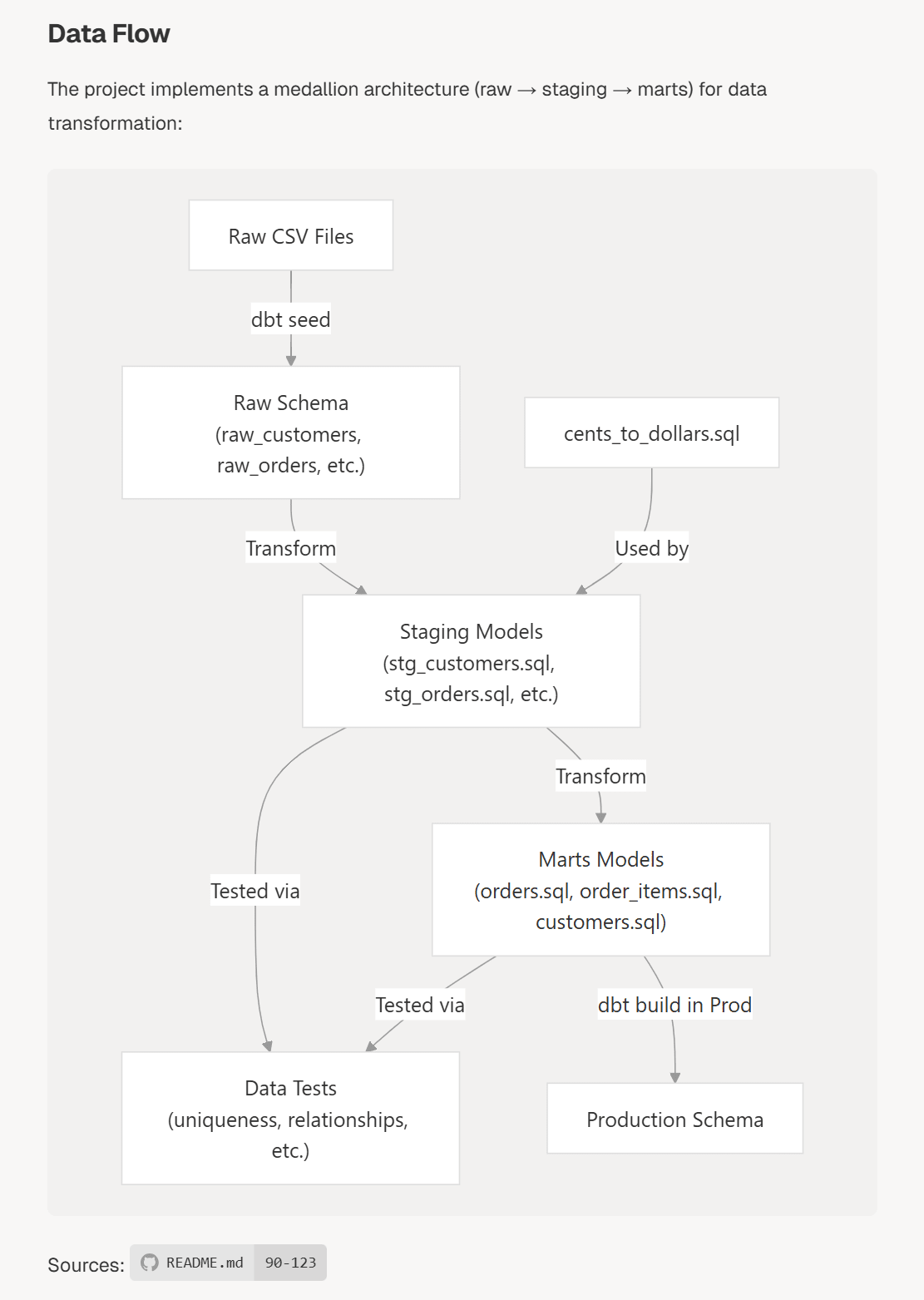
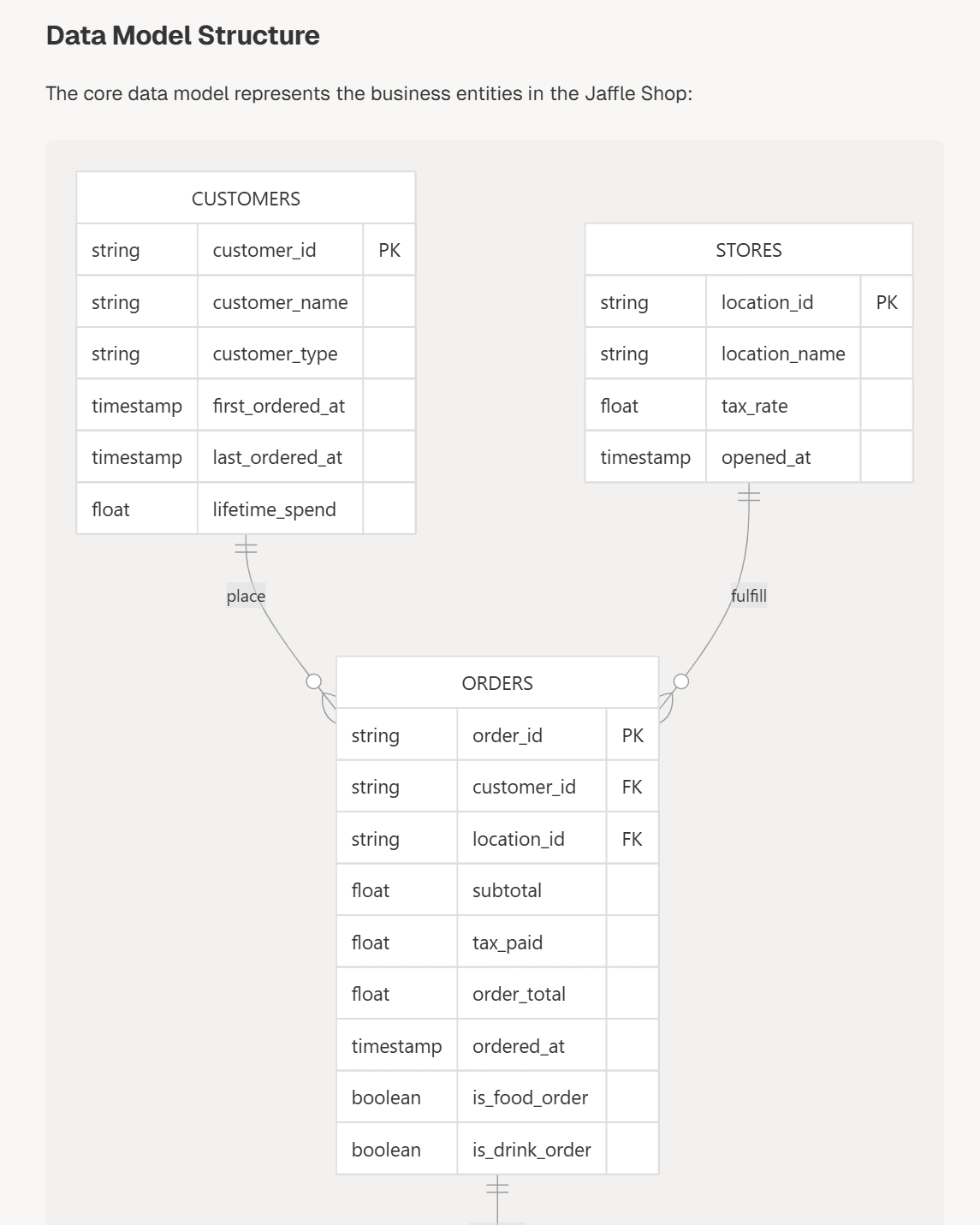
他にも、DuckDB、Airbyte、Airflow、Dagsterなど、OSSで提供されているサービスのリポジトリもDeepWikiに取り込ませることで、各サービスの全体像を知ることができるWikiが生成されます。
Bauplanが750万USDの資金調達を発表
私も初めて聞く企業だったのですが、Bauplanが750万USDの資金調達を発表しました。
Bauplanですが、以下のドキュメントを見るとこのように書いており、PythonをベースにS3上でデータプラットフォームを展開できるサービスのようです。
Bauplan is a Pythonic data platform that provides functions as a service for large-scale data pipelines and git-for-data over S3 data lakes. Bauplan handles tasks that would typically require an entire infrastructure team. Our goal is to allow you and your team to run large-scale ML workflows, AI applications and data transformation pipelines in the cloud without managing any data infrastructure.
例として、BauplanとOrchestraを用いたパイプラインの構築について以下の記事で説明がされています。
Data Extract/Load
Airbyte
Icebergの形式で出力するS3 Data Lake Destinationをリリース
Airbyteの新しいDestinationとして、Icebergの形式で出力するS3 Data Lake Destinationがリリースされました。
dlt
dltの2025年ロードマップについてまとめられた記事
dltHub社の創業者兼CTOのMarcin氏により、dltの2025年ロードマップについてまとめられた記事が出ていました。
記事からの引用ですが、以下の内容について注力していくとのことです。
- Increasing Quality of Life, enabling LLM assisted coding
- Accessing and transforming loaded data
- Support for nested types
- Unifying data normalizers and make them faster
- Pipeline state and schema storage abstraction
- Full data lineage and schema abstraction
Data Warehouse/Data Lakehouse
Snowflake
ML Jobsがリリース
Snowflakeの新機能としてSPCSのCompute Poolリソースを用いたPython処理が容易に実行できる「ML Jobs」がリリースされました。
Snowflake社のエンジニアである高田さんからもML Jobsを用いた記事が出ており、こちらも参考になると思います。
5月上旬にリリース予定の9.12で、MFAの認証方法としてパスキーとTOTPをサポート
Snowflakeの5月上旬にリリース予定である9.12のリリースノートで、MFAの認証方法としてパスキーとTOTP(時間ベースのワンタイムパスワード)をサポートすることが言及されていました。これは待っていた方も多いのではないでしょうか…!
terraform-provider-snowflakeのv2.0.0がリリースかつGAとなり、公式にサポート開始
terraform-provider-snowflakeのv2.0.0がリリースかつGAとなり、公式にサポート開始となりました。これにより、v2.0.0以降についてはサポートチケットで問い合わせができるようになっております。
Databricks
GA4のRaw Dataに対応したコネクタを発表 ※パブリックプレビュー
Databricksが新しいコネクタとして、GA4のRaw Dataに対応したコネクタを発表しました。 ※パブリックプレビュー
BigQueryにExportされたデータを取得する仕様のようです。
MotherDuck/DuckDB
クエリを編集しながらクエリ実行結果のプレビューがリアルタイムで行われる「Instant SQL」がリリース
MotherDuckとDuckDB Local UIの新機能として、クエリを編集しながらクエリ実行結果のプレビューがリアルタイムで行われる「Instant SQL」がリリースされました。
従来のSQL開発では「書く→実行→待つ→修正」というサイクルで開発を進めるのが一般的でしたが、この機能により「待つ」というプロセスをなくすことができます。
実際にどれだけのデータ量に対して待ち時間なくプレビューされるのかまではわかっておりませんが、これまでの製品にはないユニークな機能だと感じました!
Onehouse
Onehouseプラットフォーム上で任意のOSSエンジンを起動できる「Open Engines」を発表
Onehouseが新機能として、Onehouseのプラットフォーム上で任意のOSSエンジンを起動できる「Open Engines」を発表しました。
最初はApache Flink™(ストリーム処理)、Trino(BIと分析)、Ray(AI/ML、データサイエンス)の3つをリリースするようで、下記画像のようにOnehouse上からどのOSSエンジンのリソースを立ち上げるか選択できるようです。
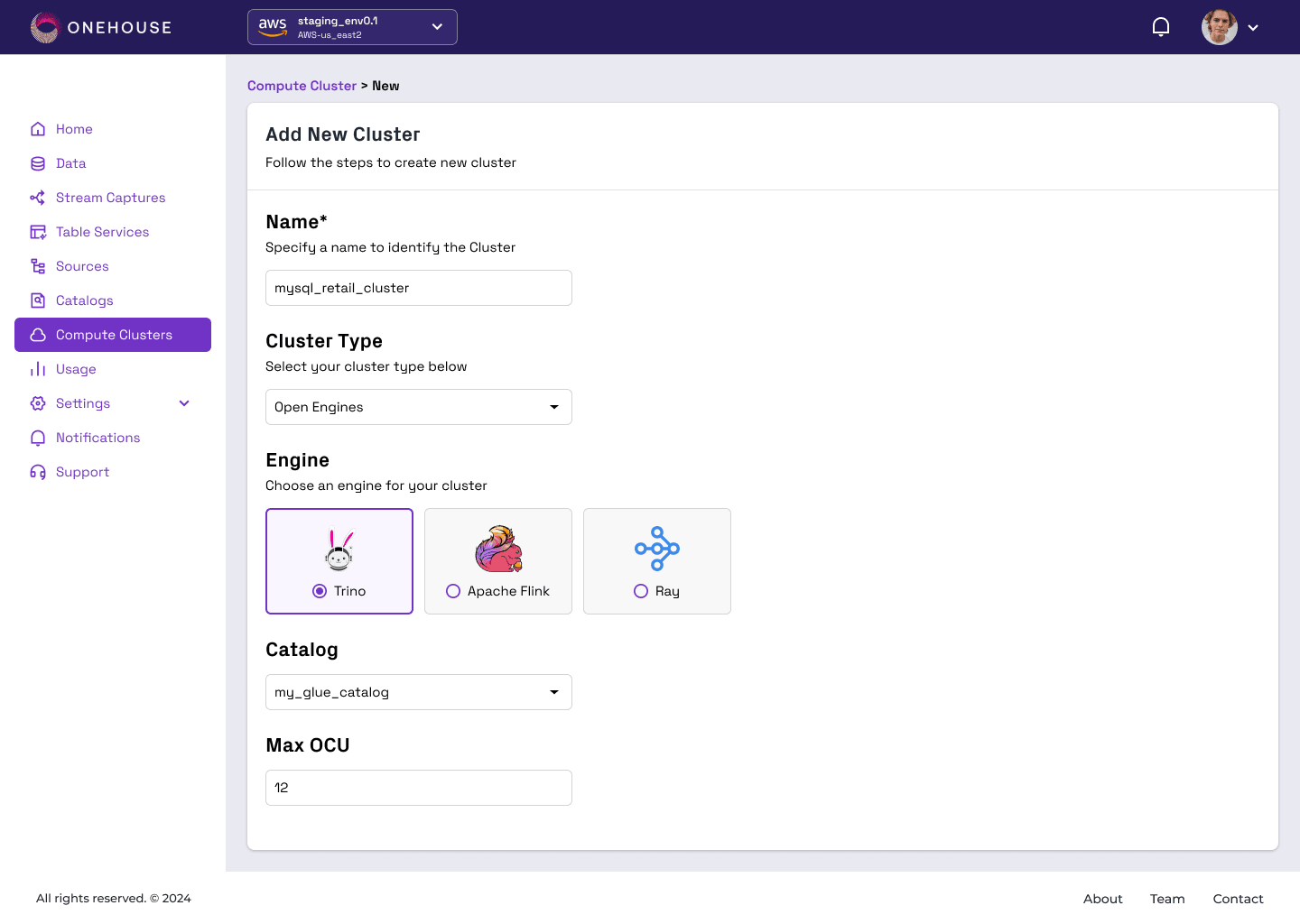
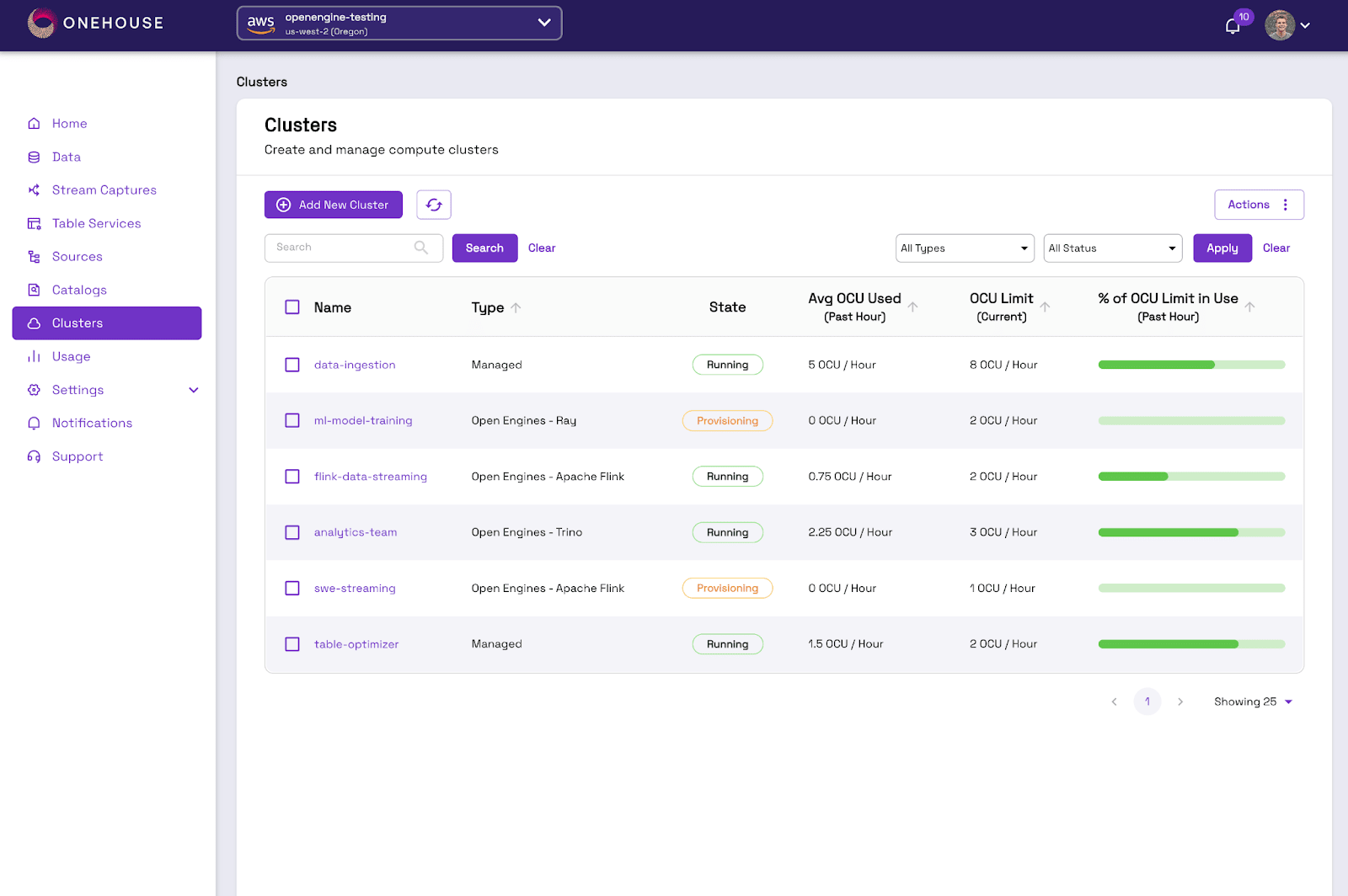
Data Transform
dbt
dbt Labs社公式のMCP Serverが公開
dbt Labs社から、MCP Serverが公開されました、GitHub上で公開されています。現時点ではExperimentalのリリースです。
実際に弊社でも試しており、モデルの一覧取得、モデルに書かれたSQLのコード解析、メトリクスの一覧取得、といったことが現時点では可能となっております。
2025/5/28と2025/5/29に開催されるdbt Launch Showcaseにおいて、このMCP Serverについても言及があるようです。
Business Intelligence
Looker
新しいメジャータイプ「period_over_period」がリリース ※プレビュー
Lookerの新しいメジャータイプとして、「period_over_period」がリリースされました。個人的には待望の機能です!!
追記:実際に試した内容を以下のブログにまとめました。
Omni
Databricks VenturesがOmniに投資
Databricks VenturesがOmniに投資したことを発表しました。以下の記事によると、これがDatabricks社による初めてのビジネスインテリジェンス分野への投資となるようです。
Data Catalog
OpenMetadata
OpenMetadata 1.7とManaged版であるCollate 1.7をリリース
OpenMetadataの最新版である1.7と、Managed版であるCollate 1.7がリリースされました。
個人的にはCollate 1.7で追加されたAutoPilotとReverse Metadataが気になっております。
- AutoPilot
- 以下の4つのエージェント機能を総称したもの
- Metadata Ingestion Agent:データソースから包括的なメタデータを自動抽出
- Documentation Agent:データの形状に基づいてDescriptionを自動生成し、自然言語リクエストからSQLクエリを生成
- Tiering Agent:組織のテーブル使用状況とリネージを分析し、データアセットのビジネス重要度を判断
- Data Quality Agent:テーブルのパターンと制約を検証し、データ品質テストを作成
- Reverse Metadata
- Collateで収集されたDescription、タグ、Ownership情報をデータソースに送信可能
- サポートされるシステムには、Athena、BigQuery、Clickhouse、Databricks、Microsoft SQL Server、MySQL、Oracle、Postgres、Redshift、Snowflake、Unity Catalogなどが含まれる
Data Quality・Data Observability
Metaplane
Datadog社がMetaplane社を買収したことを発表
Datadog社がMetaplane社を買収したことを発表しました。
現在Metaplaneのお客様に対しては当面変更なく、「Metaplane by Datadog」として製品提供が行われるようです。
Recce
dbtに特化したデータ変更の検知・影響範囲の分析に役立つ「Recce」がv1.0をリリースし、併せてSaaS版をBetaでリリース
dbtに特化したデータ変更の検知・影響範囲の分析に役立つ「Recce」がv1.0をリリースし、併せてSaaS版をBetaでリリースしました。







