![[2025年9月17日号]個人的に気になったModern Data Stack情報まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4c47f61cc8c1b97c00c0efcc68eab01b/ebc4f0c0223a249eae2f9de257dedbcd/eyecatch_moderndatastack_1200_630.jpg?w=3840&fm=webp)
[2025年9月17日号]個人的に気になったModern Data Stack情報まとめ
さがらです。
Modern Data Stack関連のコンサルタントをしている私ですが、Modern Data Stack界隈は日々多くの情報が発信されております。
そんな多くの情報が発信されている中、この2週間ほどの間で私が気になったModern Data Stack関連の情報を本記事でまとめてみます。
※注意事項:記述している製品のすべての最新情報を網羅しているわけではありません。私の独断と偏見で気になった情報のみ記載しております。
Data Extract/Load
Fivetran
FivetranがTobiko Dataを買収
FivetranがTobiko Dataを買収したことを発表しました。
Tobiko Dataは、SQLMeshというdbtの競合製品の開発元兼マネージドサービスを提供している会社です。
Airbyte
AirbyteのライセンスがELv2に変更
1ヶ月ほど前の情報になりますが、AirbyteのライセンスがELv2に変更されました。
dbt Fusionと同じELv2ライセンスになりましたが、AirbyteもELv2ライセンスとなったことで「各ユーザーがOSS版を社内の本番環境に使うことは問題ないが、OSS版をマネージドしたサービスを再販することは禁止する」という仕様に変更となりました。
Omnata
Slackプラグインが無償提供
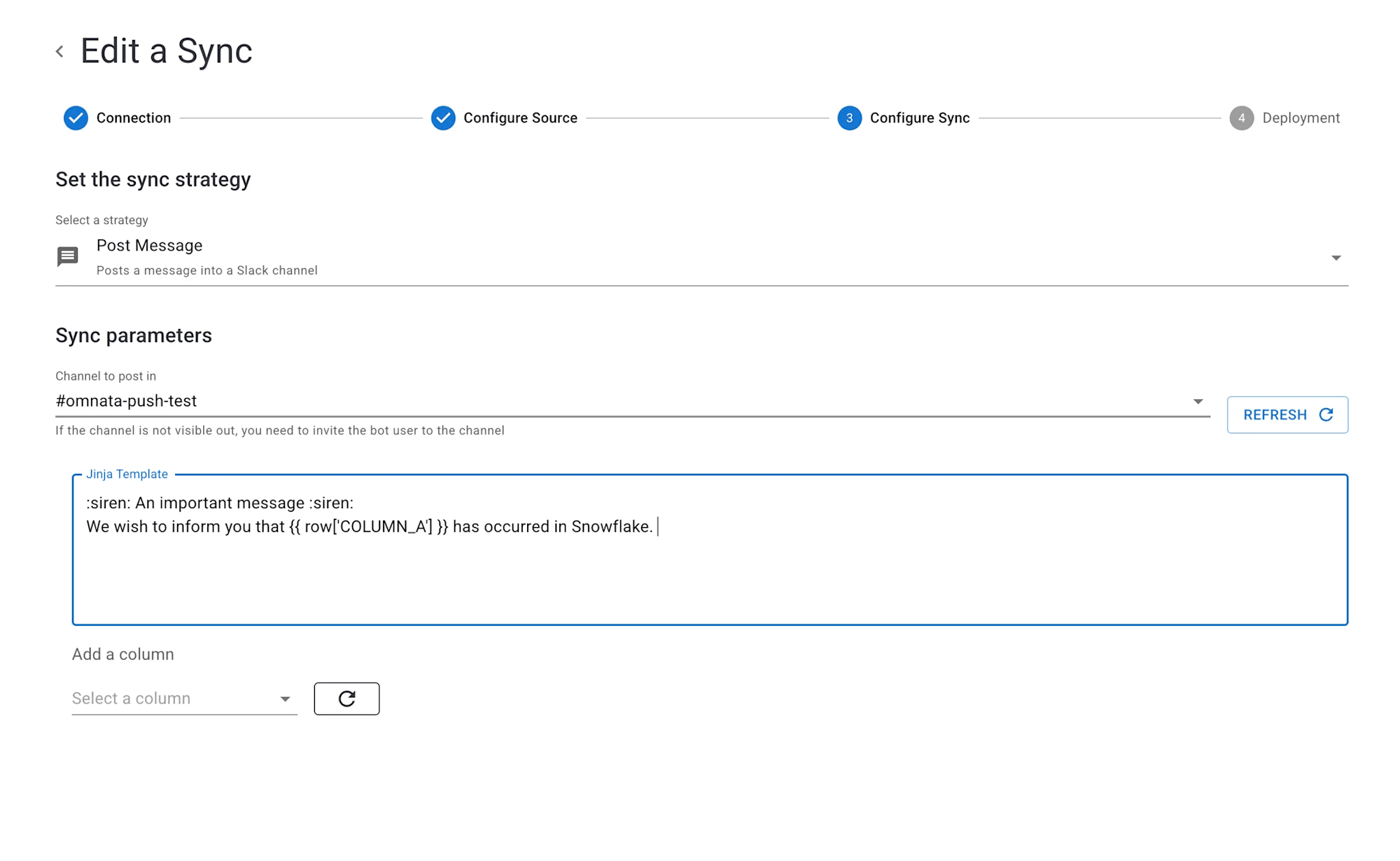
Omnataを介してSnowflakeのデータをSlackに連携できるプラグインが無償提供となりました。
下図のようにJinjaを用いてメッセージの中に動的にカラムの値を入れることができるため、実用性も高い機能となっています。手軽にSlackへのReverseETLを導入したい場合にはぴったりだと思います!
Data Warehouse/Data Lakehouse
Snowflake
Snowflake World Tour 2025 - Tokyoが開催
Snowflake World Tour 2025 - Tokyoが、2025年9月11日~12日に開催されました。弊社もブース展示を行っておりましたが、大盛況でしたね!
弊社ではセッションレポートも数多く執筆しておりますので、ぜひご覧ください。
データ品質に関わる統計情報をSnowsight上で閲覧できるように ※パブリックプレビュー
Snowsightの新機能として、データ品質に関わる統計情報を各テーブルの画面から見ることができるようになりました。
以下のリンク先は私も実際に試してみた際に執筆したブログですが、Data Metric Functionsの実行状況を視覚的にすぐに確認できるため、異常があるデータは一目でわかるようになっています。
terraform-provider-snowflakeの2.7.0がリリース
terraform-provider-snowflakeの最新バージョンとして2.7.0がリリースされました。
Gen2 Warehouseへの対応が主なアップデート内容かと思います。
MotherDuck/DuckDB
DuckDBの最新バージョン1.4.0がリリース
DuckDBの新バージョン1.4.0 "Andium" がリリースされました。本バージョンは初のLTS (Long Term Support)版として1年間のコミュニティサポートが提供されています。
主な新機能は以下の通りです。
- Database Encryption:
AES-256-GCMによるデータベースファイルの暗号化 - MERGE Statement:
upsert処理を柔軟に記述できるMERGE文のサポート - Iceberg Writes:
duckdb-iceberg拡張機能によるIcebergへの書き込み対応 - CLI Progress Bar ETA: コマンドラインに進捗状況のETA(到着予定時刻)を表示
- FILL Window Function: 欠損値を補間する新しいウィンドウ関数
- ソート実装の刷新(Sorting Rework)によるパフォーマンス向上
- Common Table Expressions (CTE)のデフォルトでのマテリアライズ化
pg_duckdbが1.0をリリース
PostgreSQL内でDuckDBを直接利用可能にする拡張機能「pg_duckdb」のバージョン1.0がリリースされました。
以下の記事では、pg_duckdbが特にインデックスを効率的に利用できない分析クエリにおいて、DuckDBのvectorized execution engineを用いてパフォーマンスを劇的に向上させると説明しています。
また、PostgreSQLからS3上のParquetファイル等を直接クエリしたり、MotherDuckと連携して負荷の高い分析処理をサーバーレス環境にオフロードしたりするアーキテクチャについても説明があります。
Data Transform
dbt
Tokyo dbt Meetup #16が開催
「dbt × Anthropic」というテーマで、Tokyo dbt Meetup #16が開催されました。
登壇資料としては吉田さん(@syou6162さん)の資料だけ見つける事ができました。dbt × Claude Codeに取り組みたい方にとっては必読の内容だと思いますので、ぜひご覧ください。
Semantic Layer
Cube
CubeがNarrative BIの買収を発表
CubeがNarrative BIの買収を発表しました。
Narrative BIは私も初耳だったのですが、ざっと調べたところだと「GA4やHubSpotなど特定のデータソースに特化した分析指標とグラフを提供してくれるだけでなく、AIにより洞察した結果をNarrativeとして提供もしてくれるBIツール」という認識となりました。(CSVアップロードやDWHとの接続もできるようですが、どういう使用感となるかまでは調査できていません…)
Business Intelligence
Looker
Looker 25.16のリリースノートが公開
Lookerの最新バージョンである25.16のリリースノートが公開されました。
細かな仕様修正がメインのアップデートとなっております。
Preset
フィルタ操作や列の並べ替えができるピボットテーブル「Interactive Pivot Table」をリリース
Presetが新機能として、フィルタ操作や列の並べ替えができるピボットテーブル「Interactive Pivot Table」をリリースしました。
Data Catalog
Atlan
AtlanにホストされたリモートMCP Serverがリリース
Atlanで管理されたアセットの情報にアクセスするためのMCP Serverがリリースされました。
AtlanからBIのアセットへのアクセスリクエスト機能がリリース
AtlanからBIのダッシュボードなどへのアクセスリクエストを行える機能がリリースされました。
仕様として、Atlanからリクエストを行うとJIRAやServiceNowのチケットを起票したり、Webhookで通知したり、という仕組みとなっています。
Select Star
BigQueryへのDescriptionの同期機能がリリース ※Beta版
Select Starの新機能として、BigQueryへのDescriptionの同期機能がリリースされました。(現時点ではBeta版の機能となっています。)
Data Orchestration
Kestra
Kestra初のメジャーバージョンとなる1.0がリリース
Kestra初のメジャーバージョンとなる1.0がリリースされました。
主な新機能として、以下の機能がリリースされています。
- AI関連機能
- AI Copilot: 自然言語からフローコードを生成・編集するAIアシスタント
- AI Agents: LLMやツールを活用し、自律的にタスクを判断・実行
- AI-Powered Search: RAGとLLMを利用した自然言語でのKestra公式ドキュメント検索
- Official Kestra MCP Server: MCPを介してAI IDEやエージェントフレームワークと連携
- GA(一般提供)となった機能
- Playground: フロー全体を再実行せず、タスクを個別に実行して反復的に開発
- Flow-level SLA: ワークフローごとに実行時間などのSLAルールを定義
- Plugin Versioning (Enterprise): 同じプラグインの複数バージョンを並行して実行し、バージョンを固定
- Unit Tests (Enterprise): フローの振る舞いを検証するユニットテスト機能
Orchestra
繰り返し処理の定義をyaml内で宣言的に定義できる「MetaEngine」を発表
Orchestraの新機能として、繰り返し処理の定義をyaml内で宣言的に定義できる「MetaEngine」を発表しました。
以下のコードは上記のリンク先の記事からの引用ですが、matrixの中に繰り返し処理を行いたいファイルの一覧を記述することで、処理内容の記述を1回で済ませられる機能です。
version: v1
name: MetaEngine
pipeline:
db82b69c-f8b6-499a-b8d6-8cae0f1b40ac:
tasks:
fc7a7a5e-f4b8-469c-bc24-70d95eb39386:
integration: PYTHON
integration_job: PYTHON_EXECUTE_SCRIPT
parameters:
command: python -m sftp
package_manager: PIP
python_version: '3.12'
build_command: pip install -r requirements.txt
environment_variables: '{
"FILE_PATH": "${{MATRIX.files}}"
}'
project_dir: python/integrations
set_outputs: true
depends_on: []
name: Ingest data to S3
tags: []
connection: python__production__blueprints__19239
depends_on: []
name: ''
matrix:
inputs:
files:
- {"database":"postgres", "file":"shipments.json"}
- {"database":"postgres", "file":"skus.json"}
- {"database":"postgres", "file":"orders.json"}
- {"database":"postgres", "file":"refunds.json"}







