![[2026年4月15日号]個人的に気になったModern Data Stack情報まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4c47f61cc8c1b97c00c0efcc68eab01b/ebc4f0c0223a249eae2f9de257dedbcd/eyecatch_moderndatastack_1200_630.jpg?w=3840&fm=webp)
[2026年4月15日号]個人的に気になったModern Data Stack情報まとめ
さがらです。
Modern Data Stack関連のコンサルタントをしている私ですが、Modern Data Stack界隈は日々多くの情報が発信されております。
そんな多くの情報が発信されている中、この2週間ほどの間で私が気になったModern Data Stack関連の情報を本記事でまとめてみます。
※注意事項:記述している製品のすべての最新情報を網羅しているわけではありません。私の独断と偏見で気になった情報のみ記載しております。
Data Extract/Load
Airbyte
The Missing Context Layer: Why Your LLM Agent Can't Do More Than Text-to-SQL
Airbyteのエンジニアリングブログに、LLMエージェントと既存のデータ統合アーキテクチャの課題を論じた記事が公開されました。
既存のセマンティックレイヤー(MetricFlow・LookML・Cubeなど)はメトリクス定義には優れていますが、LLMエージェントが必要とするのは「意味を定義する辞書」ではなく「エンティティ同士の関係を示す地図」だという論点が示されています。
たとえば「Stripeの顧客ID 4821」と「ZendeskのアカウントIDのjsmith@acme.com」が同一人物であることをエージェントが自動認識するには、アイデンティティ解決・関係性マッピング・アクション制御を担う「オントロジー層」が必要だと主張しています。
Airbyte v2.1がリリース
Airbyteがv2.1をリリースしました。
主な変更点・新機能は以下の通りです。
- 15分・30分の同期頻度オプション追加: より細かいスケジュール設定が可能に
- エラーとなったレコードの可視化: 接続ステータスページでデータ品質問題を確認できるように
- CDCメタフィールドの自動管理: 設定の不整合によるSync失敗を防止
Data Warehouse/Data Lakehouse
全般
Snowflake vs Databricks ベンチマーク比較
SELECT社が5つの実用的なシナリオでSnowflakeとDatabricksの性能・コストを体系的に比較した記事を公開しました。
結果を要約すると、大規模データ書き込み(CTAS)を除くすべてのシナリオでSnowflakeが優位という結論です。
| シナリオ | 優位 | 差 |
|---|---|---|
| 順序実行クエリ(22件) | Snowflake | 34%高速・17%低コスト |
| 並行クエリ実行(22件) | Snowflake | 38%高速・39%低コスト |
| コールドスタート | Snowflake | 54%高速・11%低コスト |
| CTAS(大規模書き込み) | Databricks | 58%高速・71%低コスト |
| DML操作 | Snowflake | 59%高速・32%低コスト |
Snowflake
Snowflake managed storageのIcebergテーブルがプレビュー提供
SnowflakeがApache Iceberg™テーブルにSnowflake managed storageを使う機能をプレビューで提供しました。
これまでのIcebergテーブルは外部クラウドストレージ(S3・GCS・Azure Blob Storageなど)の設定が必要でしたが、この機能ではSnowflakeがファイルの保存と管理を担うため、外部ストレージへのアクセス設定が不要になります。
- Fail-safeデータ保護: 永続テーブルに対してSnowflake標準のFail-safe保護が適用される
- 相互運用性: Snowflake Horizon Catalogを通じて外部クエリエンジンからもアクセス可能
Budgets for AI featuresが一般提供
AI機能のコスト管理機能「Budgets for AI features」がGAになりました。
Budgets for AI featuresでは、AI Functions・Cortex Code・Cortex Agents・Snowflake IntelligenceのAIクレジット消費をカスタム予算として設定・追跡できます。チームやコストセンター単位での監視も可能で、ユーザーへのビジネスユニットタグ付けによる細かいコスト管理も実現できます。
弊社でも検証してブログを書いています。
標準テーブルへのCHECK制約が一般提供
Snowflakeのリリース10.12(2026年4月3日〜8日)にて、標準テーブルに対するCHECK制約が一般提供となりました。
CHECK制約はテーブル作成・変更時にSQL式で定義し、カラムに挿入・更新できる値の条件を強制できます。制約に違反するINSERT/UPDATE操作はエラーで返されます。
@abe_masanoriさんにより、CHECK制約を設定することで処理速度に影響がないかを検証されたQiita記事も公開されています。こちらも参考になると思います。
Claude DesktopからSnowflake Managed MCP Serverへの連携検証
私の記事で恐縮ですが、Claude Desktop + Microsoft 365コネクタとSnowflakeを組み合わせてPDFと表データを横断分析する構成や、Managed MCP Server経由でCortex Agentに接続する手順についてまとめてみました。
Databricks
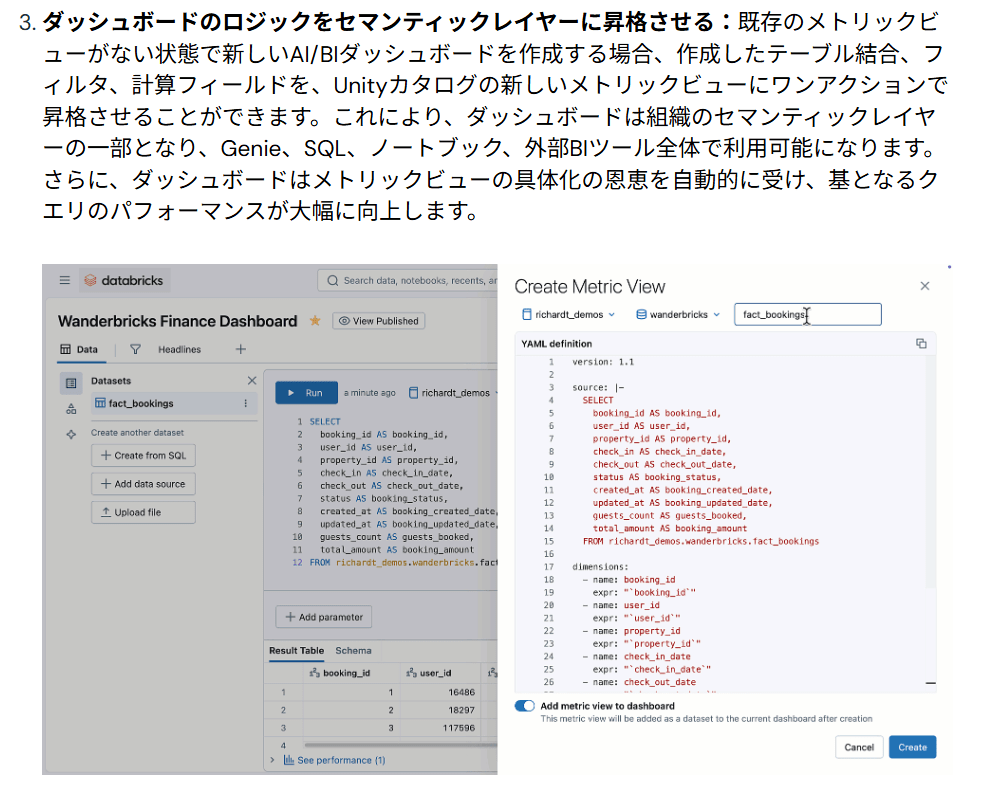
Unity Catalog Business Semanticsが一般提供
Databricksが「Unity Catalog Business Semantics」の一般提供を発表しました。同時にコア実装のオープンソース化も発表されています。
Business Semanticsの中心機能は「Metric Views」です。ビジネスKPI定義・表示名・フォーマット・同義語などのセマンティックメタデータをUnity Catalogで一元管理できます。一度定義した内容を、ダッシュボード・SQLクエリ・ノートブック・AIエージェントから横断的に利用できる設計です。
上記のリンク先からの引用ですが、個人的には以下の「ダッシュボードのSQLで定義したDatasetからMetric Viewを自動生成」が特に気になりました。
Apache Iceberg v3がDatabricksでPublic Previewに
DatabricksがApache Iceberg v3サポートのPublic Previewを発表しました。
主要な新機能は以下の3つです。
- Row Lineage & Deletion Vectors: 各行に永続IDとシーケンス番号が付与され、削除時はファイル再書き込み不要の論理削除で処理できます。従来のcopy-on-writeと比べ最大10倍高速とされています
- VARIANT型: 半構造化データ(ログ・APIレスポンス・クリックストリームなど)をリレーショナルデータと同じテーブルに標準SQLで格納できる新しいカラム型です
- Unity Catalog統合: Snowflake・AWS Glueなど複数プラットフォームへのフェデレーテッドアクセス、UniFormによるDelta Lake/Iceberg相互運用がデータ複製なしで実現
Databricks Runtime 18.0以上・Unity Catalog有効化の環境で利用可能です。
LakebaseでPostgresのデータベースブランチ管理が可能に
DatabricksがLakebaseにおけるPostgresのGit-Styleワークフロー機能を発表しました。copy-on-write方式でデータベースのブランチを秒単位で作成でき、データベースサイズに関わらず一定の時間で完了します。
以下のワークフローパターンに対応します。
- 開発者ごとのブランチ: 各開発者が独立したPostgres環境を持ち、共有のステージング環境が不要になる
- プルリクエストごとのブランチ: CI/CDパイプラインが自動でブランチを作成・削除
- テスト実行ごとのブランチ: 各テストが完全に隔離された環境で実行可能
変更分に比例したストレージコストのみかかる設計で、各ブランチは独立したPostgresエンドポイントを持ちます。
BigQuery
BigQuery Graphがプレビュー
BigQueryにグラフ分析機能「BigQuery Graph」がプレビューで追加されました。既存のテーブルから直接グラフを作成し、ISO GQL標準に基づくGraph Query Language(GQL)を使って関係性の発見やトラバーサルが可能になります。分析結果はBigQuery Studioのノートブックで可視化できます。
主な特徴は以下の通りです。
- SQLとの完全な相互運用性: GQLとSQLを組み合わせて記述でき、既存のSQL知識をそのまま活用可能
- 大規模スケーラビリティ: 数十億のノードとエッジに対応
- AI機能統合: ベクトル検索・全文検索との組み合わせが可能
- Spanner Graphとの統合: リアルタイム処理とバッチ処理を統一して扱える
既存のBigQueryテーブルをそのままグラフのノード・エッジとして扱える設計は実用的で、グラフ分析のためだけに別のデータベースを立てる必要がなくなる点が大きいと感じます。
ClickHouse
clickhousectl: ClickHouse公式CLIがベータ公開
ClickHouseがローカル開発からCloud管理まで統一して扱える公式CLI「clickhousectl」をベータ版として公開しました。
主な機能は以下の通りです。
- バージョン管理:
uvやpnpmに似た方式でClickHouseのバージョン検出・ダウンロードが可能 - ローカルサーバー管理: 複数の独立したインスタンスを並行実行でき、ポート競合時は自動割当
- Cloud管理: 組織管理・サービス作成・スケーリング・バックアップ・APIキー管理に対応
DuckDB/MotherDuck
DuckLake v1.0がリリース
DuckLakeがv1.0をリリースし、本番利用可能(production-ready)であることを宣言しました。
DuckLakeの最大の特徴は、メタデータをファイルではなくSQLデータベースで一元管理する設計です。私もプレビュー版がリリースされた時に検証して記事を書いております、こちらも併せてご覧ください。
Data Transform
dbt
Developer AgentがBetaでリリース
dbt platformでDeveloper AgentがBetaとしてリリースされました。
Developer Agentは、Studio IDE上で自然言語からdbtモデルの作成・リファクタリング・ドキュメント生成・SQL生成まで一気通貫で実行できるエージェント機能です。従来のdbt Copilotが「提案ベース」だったのに対し、Developer Agentは「ファイルの生成・編集まで自律的に実行する」点が大きな進化です。
主な機能は以下の通りです。
- モデル構築・修正: 自然言語で変換ロジックを指示してdbtモデルを生成
- YAML自動生成: テスト・ドキュメント・セマンティックモデル定義を自動作成
- プロジェクト探索: DAGへの質問やカタログ照会にも対応
- 2つの操作モード: 変更を1件ずつ承認する
Ask for approvalと自動適用するEdit files automaticallyを選択可能
弊社でも検証してブログを書いています。
SQLMesh(Fivetran)
SQLMeshをLinux Foundationに寄贈
FivetranがSQLMeshをLinux Foundationに寄贈すると発表しました。FivetranはTobiko Dataの買収を通じてSQLMeshを獲得しており、今回の寄贈でコアのOSSプロジェクトとしてコミュニティに開放します。
Benzinga・CloudKitchens・Harness・Infinite Lambda・Jump AI・Minervaが創設メンバーとして参加し、ソースコードはGitHubで引き続き公開され、外部コントリビューターの参加も可能です。
Business Intelligence
Tableau
TableauファイルのXMLのスキーマ情報が公開
@YusukeNakanish3さんの投稿で私も気づいたのですが、Tableauが公式にGitHubでTableauのワークブック(twb・twbx)の構造を公開していました。
@shinyaa31さんによる考察記事も公開されています。
このスキーマ情報が公開されているのであれば、ある意味Tableauも「BI as Code」的にAIエージェントから開発もできるのでは…と考えてしまいますね。
Omni
Modeling Agentをリリース
自然言語でOmniのSemantic Layerのコードを修正・拡張できるエージェント機能として、Modeling Agentがリリースされました。フィールドの追加・計算指標の定義・JOIN設定などをAIと対話しながら行えます。
Looker / Data Studio
Looker StudioがData Studioに改名
Google CloudがLooker StudioをData Studioに改名すると発表しました。改名に伴い、製品の役割分担も明確化されています。
- Data Studio(旧Looker Studio): 個人向けのデータ探索・アドホック分析ツール。無料版と、有料の
Data Studio Pro版が提供される - Looker: エンタープライズBI・ガバナンス用途
Data Studioは今後、BigQuery会話型エージェント・Colabなどを含むGoogle Data Cloudコンテンツの一元管理場所として機能する方向性が示されています。既存ユーザーはレポート・データソース・ユーザー情報がすべて自動移行され、手動での操作は不要とのことです。
Looker Studioの前の名称に戻った形となるため、日本ではまたデータポータルという名称になるかなど、気になるところです。
※追記:改めてLooker Studioを開くと、「データポータル」となっていました。
Rill
Metrics SQLを発表
Rillが「Metrics SQL」を発表しました。人間とAIエージェントの両方が参照できる、SQL方言ベースのセマンティックレイヤーです。
従来のセマンティックレイヤーは独自のyamlベースの構成を採用するものが多い中、Metrics SQLはSQL標準を採用しています。「すべてのツール・エンジニア・AIモデルがすでに理解している言語で定義する」という方針です。
Hex
Hex CLIを発表
HexがCLIツール「Hex CLI」を公開しました。ターミナルからHexのワークフローを直接操作できるツールで、Claude CodeやCursorなどのコーディングエージェントとの連携を想定した設計になっています。
主な機能は以下の通りです。
- プロジェクト・セルの管理: 作成・編集・削除・実行をコマンドラインから操作
- SQL/Pythonコードの更新: コードを直接編集してプロジェクトに反映
- 複数プロジェクトへの一括変更: 対象テーブルを参照するダッシュボードのSQLを一括更新
Lightdash
SPCSでOSSのLightdashをSnowflake上で動かす手順が公開
@takimiko_gohanさんにより、Snowpark Container Services(SPCS)を使って、OSSのBIツールLightdashをSnowflake上で運用する手順を解説したZenn記事が公開されました。
Lightdash ServiceをSPCSで起動し、メタデータDBとしてSnowflake Postgresを活用する構成となっております。
Snowflake上にLightdashを組み込む構成は、Snowflake上でデータ基盤を完結させたいチームにとって参考になると思います。(私自身としても、大変参考になりありがたいです…!)
Data Orchestration
Dagster
Dagster 1.13及びAgent Skillが公開
Dagster 1.13(コードネーム: Octopus's Garden)がリリースされました。
また、OSSリポジトリ「dagster-io/skills」も公開されています。Claude CodeやOpenAI Codexなどで利用可能なDagster専用スキルで、プロトタイピングから本番環境構築、トラブルシューティングまでをカバーするとされています。







